2023/05/01(月) [n年前の日記]
#1 [nitijyou] 自宅サーバ止めてました
雷が鳴ったので、16:55 - 18:50の間、自宅サーバを止めてました。申し訳ないです。
いきなり近くで雷が落ち始めてヒヤヒヤしました…。
いきなり近くで雷が落ち始めてヒヤヒヤしました…。
[ ツッコむ ]
#2 [cg_tools][gimp][krita] Paint.NET、GIMP、CLIP STUDIO PAINT、Kritaについて調べてた
Paint.NET、GIMP、CLIP STUDIO PAINT、Krita について、色々調べてた。
◎ Paint.NET + G'MICプラグインの設定について :
Paint.NET + G'MICプラグインで、複数レイヤーを出力するフィルタを利用した際、複数の画像ファイルを保存させられるあたりが気になった。設定で回避できないのかなと調べていたのだけど、現状では無理らしい。
Paint.NETは、複数の入力レイヤーをフィルタに渡すことも、フィルタから複数の出力レイヤーを受け取ることも ―― フィルタが新規レイヤーを作成することすら許さない仕様だそうで。
_G'MIC (2023-04-28) - Page 3 - Plugins - Publishing ONLY! - paint.net Forum
そんな制限が付いて回るものだから、Paint.NET + G'MIC で、上と下の2つのレイヤーを渡して処理させる場合、アクティブレイヤーを下のレイヤー、クリップボード内のデータを上のレイヤーとして扱って処理をするらしい。
一々手作業で、クリップボードにレイヤーをコピーして、アクティブレイヤーを変更してからG'MICを呼ばないといけないなんて、不便過ぎる…。Paint.NETは、どうしてそんなストイックなフィルタ仕様にしてしまったのだろう…。
Paint.NETは、複数の入力レイヤーをフィルタに渡すことも、フィルタから複数の出力レイヤーを受け取ることも ―― フィルタが新規レイヤーを作成することすら許さない仕様だそうで。
_G'MIC (2023-04-28) - Page 3 - Plugins - Publishing ONLY! - paint.net Forum
そんな制限が付いて回るものだから、Paint.NET + G'MIC で、上と下の2つのレイヤーを渡して処理させる場合、アクティブレイヤーを下のレイヤー、クリップボード内のデータを上のレイヤーとして扱って処理をするらしい。
一々手作業で、クリップボードにレイヤーをコピーして、アクティブレイヤーを変更してからG'MICを呼ばないといけないなんて、不便過ぎる…。Paint.NETは、どうしてそんなストイックなフィルタ仕様にしてしまったのだろう…。
◎ GIMPのスレッド数設定 :
GIMP 2.10.34 Portable を導入したものの、画像ファイルを開く際になんだか数秒待たされる感じがして、改善できないのかなと調べていたところ、GIMPが使用するスレッド数の指定を1にすると改善する時期もあった、という話を見かけた。
_RyzenのSMTを無効化したらGIMPの動作が良くなった。 | 迷惑堂本舗
_GIMP:フリーズする場合の設定 | うっかりやっちゃうブログ
_GIMP slow and unrespsonsive when working with AMD CPU (#4979) - Issues - GNOME / GIMP - GitLab
_Slow import times on CPUs with high core/thread count (on Windows) (#8358) - Issues - GNOME / GIMP - GitLab
全体的なパフォーマンスは悪くなるけれど、例えば色調補正フィルタ等を利用した際にフリーズする症状も改善されるのだとか。
ただ、GIMP 2.10.34 では改善されたとか、GIMP起動直後はフリーズしないが長時間起動しっぱなしにして作業しているとフリーズしやすくなる、という話もあるようで…。
GIMP 2.10.34 で改善されてるなら、特に設定を変えなくてもいいかな…。
ちなみに、自分の環境は、CPU が AMD Ryzen 5 5600X (6コア12スレッド)。GIMPが使用するスレッド数は、12にしてある状態。
余談。昔はスレッド数じゃなくてCPUの個数を指定する仕様だったっぽい…。CPUコア数じゃなくてCPUの数、というのがややこしい…。
_tangram_pieces: GIMPの環境設定でのプロセッサ数について(2015-Dec-8: 追記)
_RyzenのSMTを無効化したらGIMPの動作が良くなった。 | 迷惑堂本舗
_GIMP:フリーズする場合の設定 | うっかりやっちゃうブログ
_GIMP slow and unrespsonsive when working with AMD CPU (#4979) - Issues - GNOME / GIMP - GitLab
_Slow import times on CPUs with high core/thread count (on Windows) (#8358) - Issues - GNOME / GIMP - GitLab
全体的なパフォーマンスは悪くなるけれど、例えば色調補正フィルタ等を利用した際にフリーズする症状も改善されるのだとか。
ただ、GIMP 2.10.34 では改善されたとか、GIMP起動直後はフリーズしないが長時間起動しっぱなしにして作業しているとフリーズしやすくなる、という話もあるようで…。
GIMP 2.10.34 で改善されてるなら、特に設定を変えなくてもいいかな…。
ちなみに、自分の環境は、CPU が AMD Ryzen 5 5600X (6コア12スレッド)。GIMPが使用するスレッド数は、12にしてある状態。
余談。昔はスレッド数じゃなくてCPUの個数を指定する仕様だったっぽい…。CPUコア数じゃなくてCPUの数、というのがややこしい…。
_tangram_pieces: GIMPの環境設定でのプロセッサ数について(2015-Dec-8: 追記)
◎ CLIP STUDIO PAINTの自動着色機能 :
GIMP 2.10.34 + G'MICプラグインで、Colorize [Interactive] を使って色の塗り分け作業をしていた際、「そういえば CLIP STUDIO PAINT にはこういった機能は無いのだろうか」と気になった。ググってみたら、そもそも自動着色機能があるそうで、気になったので試用してみた。CLIP STUDIO PAINT PRO 1.13.2 で動作確認。
_クリスタ自動彩色機能の使い方解説!メリットやデメリットについて - イラスト・マンガ教室なび|おすすめ専門学校一覧
_クリップスタジオ自動彩色やり方とコツ!面白いから試してみよう | コンテアニメ工房
_自動彩色を活用した着色 by iroha_ - お絵かきのコツ | CLIP STUDIO TIPS
AIで自動着色してくれるらしい。スゴイな…。
ただ、データをセルシスのサーバに送信して、サーバ側で着色処理をして返してくるそうで。インターネット接続環境が無いと使えないし、セルシスが倒産しても使えなくなるなと…。いやまあ、会社が無くなったら、そもそもアクティベーションできない状態になって、CLIP STUDIO PAINT自体が使えなくなるのだから、そのあたりを気にしてみても無意味か…。
感想としては…。期待した塗りには程遠い結果が出てきて、なんというか、うーん。 *1 あらかじめ指定色(ヒント画像)を置いておく方法もあるけれど、それでも…。うーん。
パーツ毎の塗り分け領域を自動生成してくれるだけでも助かりそうな気もするのだけど、それよりレベルの高い処理をして、しかし今一つな結果になって、これではなんだかもったいない気もする。一歩手前の状態で止めておけば、十分ありがたいのに…。もっとも、この自動着色機能も、見た目はグラデーションがかかってるけど、魔法の杖でクリックすればパーツ毎の選択領域を得られるようだから、この状態でも結構助かるところがあるのかもしれない。
_クリスタ自動彩色機能の使い方解説!メリットやデメリットについて - イラスト・マンガ教室なび|おすすめ専門学校一覧
_クリップスタジオ自動彩色やり方とコツ!面白いから試してみよう | コンテアニメ工房
_自動彩色を活用した着色 by iroha_ - お絵かきのコツ | CLIP STUDIO TIPS
AIで自動着色してくれるらしい。スゴイな…。
ただ、データをセルシスのサーバに送信して、サーバ側で着色処理をして返してくるそうで。インターネット接続環境が無いと使えないし、セルシスが倒産しても使えなくなるなと…。いやまあ、会社が無くなったら、そもそもアクティベーションできない状態になって、CLIP STUDIO PAINT自体が使えなくなるのだから、そのあたりを気にしてみても無意味か…。
感想としては…。期待した塗りには程遠い結果が出てきて、なんというか、うーん。 *1 あらかじめ指定色(ヒント画像)を置いておく方法もあるけれど、それでも…。うーん。
パーツ毎の塗り分け領域を自動生成してくれるだけでも助かりそうな気もするのだけど、それよりレベルの高い処理をして、しかし今一つな結果になって、これではなんだかもったいない気もする。一歩手前の状態で止めておけば、十分ありがたいのに…。もっとも、この自動着色機能も、見た目はグラデーションがかかってるけど、魔法の杖でクリックすればパーツ毎の選択領域を得られるようだから、この状態でも結構助かるところがあるのかもしれない。
◎ Kritaの自動塗り分けマスク機能を試用 :
Windows10 x64 22H2 + Krita 5.1.5 64bit版で、自動塗り分けマスク編集ツールを試用してみた。結構長い間、Krita を使ってなくて知らなかったのだけど、こんな機能を持っていたのね…。
_Krita 4: 自動塗り分けマスクの使い方 - Kritaでぐるぐるお絵かきブログ
G'MICプラグインや CLIP STUDIO PAINT と同様、指定色を線画の上に描き込んでいくことで、領域を判定して塗り分けてくれた。更に、領域毎に別レイヤーに分割してくれる機能もありがたい。サクサク作業が出来そう。さすがKrita。お絵描き用を意識して機能を揃えているなあ、と…。
_Krita 4: 自動塗り分けマスクの使い方 - Kritaでぐるぐるお絵かきブログ
G'MICプラグインや CLIP STUDIO PAINT と同様、指定色を線画の上に描き込んでいくことで、領域を判定して塗り分けてくれた。更に、領域毎に別レイヤーに分割してくれる機能もありがたい。サクサク作業が出来そう。さすがKrita。お絵描き用を意識して機能を揃えているなあ、と…。
*1: もっとも、絵描きさん達の色塗りを超える結果をポンと出したら炎上必至だろうし、あえて本気を出してないのかも。絵描きさんのプライドを傷つけない程度の出力結果に抑えるというのも面倒臭い話だなと…。
[ ツッコむ ]
2023/05/02(火) [n年前の日記]
#1 [pc] HDMIセレクターを導入してみたけど正常動作せず
弟から貰ったHDMIセレクター、GREENHOUSE GH-HSWB3-BK を箱から出して動作確認してみた。HDMI入力が3つ、HDMI出力が1つ。4K2K 2160p映像対応、と謳っている製品。リモコン付き。
_セレクタ, セレクタ(切替機) | GH-HSWB3-BK | GREEN HOUSE グリーンハウス
液晶ディスプレイ MITSUBISHI MDT243WG-SB と、Intel Core i5-2500機(Ubuntu Linux 18.04 LTS、画面表示は内蔵GPU使用) の間に入れてみたけど、Ubuntu Linux が起動する際のVGA前後の解像度なら問題無く映ったものの、1920x1200のデスクトップ画面が出てきたあたりで、盛大なノイズだらけの画面になってしまった…。
ケーブルコネクタの接触不良を疑って、入力と出力のケーブルを何度か抜き差ししてみたり、電流が足りてない可能性を疑って、付属のUSB接続ケーブルで給電してみたけれど、改善はしなかった。
HDMIセレクター自体は、4K対応を謳っているぐらいだから、スペック的には問題無さそうな気もする。手持ちのHDMIケーブルが低品質で、伝送に失敗してるのだろうか…。それとも、1920x1200という解像度が異質なのだろうか。
レビューをググってみたところ、数ヶ月使っていたらノイズが出始めたという事例がチラホラ。弟が使っていた中古品だし、ノイズが出てしまう状態に劣化している可能性もありそう…。
_セレクタ, セレクタ(切替機) | GH-HSWB3-BK | GREEN HOUSE グリーンハウス
液晶ディスプレイ MITSUBISHI MDT243WG-SB と、Intel Core i5-2500機(Ubuntu Linux 18.04 LTS、画面表示は内蔵GPU使用) の間に入れてみたけど、Ubuntu Linux が起動する際のVGA前後の解像度なら問題無く映ったものの、1920x1200のデスクトップ画面が出てきたあたりで、盛大なノイズだらけの画面になってしまった…。
ケーブルコネクタの接触不良を疑って、入力と出力のケーブルを何度か抜き差ししてみたり、電流が足りてない可能性を疑って、付属のUSB接続ケーブルで給電してみたけれど、改善はしなかった。
HDMIセレクター自体は、4K対応を謳っているぐらいだから、スペック的には問題無さそうな気もする。手持ちのHDMIケーブルが低品質で、伝送に失敗してるのだろうか…。それとも、1920x1200という解像度が異質なのだろうか。
レビューをググってみたところ、数ヶ月使っていたらノイズが出始めたという事例がチラホラ。弟が使っていた中古品だし、ノイズが出てしまう状態に劣化している可能性もありそう…。
[ ツッコむ ]
2023/05/03(水) [n年前の日記]
#1 [nitijyou] 弟が帰省
夕方頃、自分が犬の散歩に行ってた間に到着したらしい。
PCパーツを色々持ってきてくれた。ありがたい…。2.5インチSSD x 1、3.5インチHDD x 4、2.5インチHDD x 2、HDDケース x 2。弟と話し合って、外付けHDDは親父さんにプレゼントしよう、という話に。
PCパーツを色々持ってきてくれた。ありがたい…。2.5インチSSD x 1、3.5インチHDD x 4、2.5インチHDD x 2、HDDケース x 2。弟と話し合って、外付けHDDは親父さんにプレゼントしよう、という話に。
◎ お袋さん用ノートPCをメンテナンス :
せっかく茶の間に居るのだからと、弟と近況報告をしつつ、お袋さん用のノートPC(DELL製)をメンテナンス。案の定、バッテリーが切れかけていた。とりあえずバッテリーを100%まで充電。充電できたということは、まだバッテリーは完全死亡してない、ということかな…。
Windows10も、21H2 から 22H2 にアップデートしておいた。
Windows10も、21H2 から 22H2 にアップデートしておいた。
[ ツッコむ ]
2023/05/04(木) [n年前の日記]
#1 [pc] デフラグが終わらない
一般的にSSDはデフラグをする必要はないと言われているのだけど、SSDも空き領域の断片化は解消したほうが良い、という話をどこかで見かけて、メインPC(Windows10 x64 22H2)のCドライブのSSD、Crucial MX500 CT500MX500SSD1JP 500GB をデフラグしてみようと思い立った。
Auslogics Disk Defrag 8.0.24.0 を起動して、「SSDの最適化」を選択。
しかし、やたらと時間がかかる。総ファイル数は、1,797,136ファイル。5時間経っても、6%ぐらいしか最適化できてない。これはおかしい。SSDなのに…。何故こんなに遅いのか…。
もう一つ積んであるSSD、PLEXTOR PX-256M2P 256GB に対して、以前同じ処理をした際は、数分で終わった記憶がある。SSDをデフラグする場合、本来であればそのくらいの時間で終わるのでは…?
もしかすると、ひっきりなしにCドライブにアクセスして、ファイルを書き込んでるプロセスが居るのではないか。一度止めて調べてみたほうがいいのだろうか。いや、ここまでやってしまったのだから、いっそこのまま続けてみよう…。
Auslogics Disk Defrag 8.0.24.0 を起動して、「SSDの最適化」を選択。
しかし、やたらと時間がかかる。総ファイル数は、1,797,136ファイル。5時間経っても、6%ぐらいしか最適化できてない。これはおかしい。SSDなのに…。何故こんなに遅いのか…。
もう一つ積んであるSSD、PLEXTOR PX-256M2P 256GB に対して、以前同じ処理をした際は、数分で終わった記憶がある。SSDをデフラグする場合、本来であればそのくらいの時間で終わるのでは…?
もしかすると、ひっきりなしにCドライブにアクセスして、ファイルを書き込んでるプロセスが居るのではないか。一度止めて調べてみたほうがいいのだろうか。いや、ここまでやってしまったのだから、いっそこのまま続けてみよう…。
◎ 2023/05/05追記 :
20時間38分かかって処理が終わった。長かった。しかし、おかしい…。SSDなのに…。
「SSDの最適化」だけでは、空き領域がほとんどまとまってくれなかった。そのまま続けて、「デフラグ 最適化 (遅い/週1回使用)」を選んで処理をさせたところ、今度は20分ぐらいで空き領域も奇麗にまとめてくれたように見えた。
「SSDの最適化」だけでは、空き領域がほとんどまとまってくれなかった。そのまま続けて、「デフラグ 最適化 (遅い/週1回使用)」を選んで処理をさせたところ、今度は20分ぐらいで空き領域も奇麗にまとめてくれたように見えた。
[ ツッコむ ]
#2 [nitijyou] 弟が仙台に戻った
19:20頃出発。21:20頃到着したと電話があったらしい。
[ ツッコむ ]
2023/05/05(金) [n年前の日記]
#1 [windows] Windows10の回復ドライブを作成してみた
Windows10 x64 22H2機の、CドライブのSSDに対してデフラグをかけた際、異様に時間がかかっていた点が気になる。もしかすると、Windowsのセーフモード云々でデフラグをかけたらサクサクと処理してくれたりしないか。
そのあたりを調べてみたら、回復ドライブを作ってそこからPCを起動すれば、コマンドプロンプトだけが起動している状態にできると知った。そのコマンドプロンプト上で defrag.exe を実行すれば状況が変わるだろうか。まずは回復ドライブを作成してみないと…。
机の引き出しから、16GBの、USB3.0メモリを発掘。貼ってある紙には、20H1と書いてある。コレの中身を更新して使おう…。
PCケースが古いので、前面にはUSB2.0ポートしかない。せっかくのUSB3.0対応メモリだけど、USB2.0ポートで使うことにする。しかし、そのまま差したら「認識できない」と言われてしまった。仕方ないのでUSB2.0ハブを経由して差し込んでみた。
USBメモリを差しておいた状態で、Windwos10左下の検索欄に、「回復ドライブの作成」と打ち込んで検索して起動。後はウィザード形式で尋ねてくる。ちなみに、USBメモリはフォーマットされて、中身が全消去される。
1時間30分ほどかかって、回復ドライブを作成できた。
そのあたりを調べてみたら、回復ドライブを作ってそこからPCを起動すれば、コマンドプロンプトだけが起動している状態にできると知った。そのコマンドプロンプト上で defrag.exe を実行すれば状況が変わるだろうか。まずは回復ドライブを作成してみないと…。
机の引き出しから、16GBの、USB3.0メモリを発掘。貼ってある紙には、20H1と書いてある。コレの中身を更新して使おう…。
PCケースが古いので、前面にはUSB2.0ポートしかない。せっかくのUSB3.0対応メモリだけど、USB2.0ポートで使うことにする。しかし、そのまま差したら「認識できない」と言われてしまった。仕方ないのでUSB2.0ハブを経由して差し込んでみた。
USBメモリを差しておいた状態で、Windwos10左下の検索欄に、「回復ドライブの作成」と打ち込んで検索して起動。後はウィザード形式で尋ねてくる。ちなみに、USBメモリはフォーマットされて、中身が全消去される。
1時間30分ほどかかって、回復ドライブを作成できた。
◎ defrag.exeは無かった :
PCのBIOS起動時にF12キーを押してブートメニューを表示。ちなみにどのキーでブートメニューが出てくるかはマザーボードによって違う。
起動に使うUSBメモリを選び、回復ドライブから起動して、コマンドプロンプトのみの画面にすることはできた。IMEを選んで、「トラブルシューティング」→「詳細オプション」→「コマンドプロンプト」を選ぶのだったかな…。ちょっと記憶が怪しい。
_Windows 10が起動しない時の修復方法 | パソコン工房 NEXMAG
ただ、回復ドライブ内に defrag.exe は入ってなくて、デフラグの動作確認はできなかった。chkdsk は入っていたのだけど…。
起動に使うUSBメモリを選び、回復ドライブから起動して、コマンドプロンプトのみの画面にすることはできた。IMEを選んで、「トラブルシューティング」→「詳細オプション」→「コマンドプロンプト」を選ぶのだったかな…。ちょっと記憶が怪しい。
_Windows 10が起動しない時の修復方法 | パソコン工房 NEXMAG
ただ、回復ドライブ内に defrag.exe は入ってなくて、デフラグの動作確認はできなかった。chkdsk は入っていたのだけど…。
◎ 回復ドライブを作る際に必要な容量が分からない :
巷の解説記事を眺めると、「回復ドライブの作成には32GB以上のUSBメモリが必要」と書いてある場合が多いのだけど。
自分の環境で、以前、回復ドライブ作成を試した際は、何故か32GBのUSBメモリだと作成に失敗してしまって、16GBのUSBメモリなら作成に成功する、という症状に見舞われた記憶があって…。 *1
どういう環境なら、32GBが必要と言われてしまうのだろう…? 自分の環境では、そもそも回復ドライブ作成ツールが、途中で「16GB以上が必要」と言ってきて、「32GB以上が必要」とは言ってこないのだよな…。でも、どの解説ページも、「32GB以上が必要」と書いてるし。これはどういうことなのだろう。
自分の環境で、以前、回復ドライブ作成を試した際は、何故か32GBのUSBメモリだと作成に失敗してしまって、16GBのUSBメモリなら作成に成功する、という症状に見舞われた記憶があって…。 *1
どういう環境なら、32GBが必要と言われてしまうのだろう…? 自分の環境では、そもそも回復ドライブ作成ツールが、途中で「16GB以上が必要」と言ってきて、「32GB以上が必要」とは言ってこないのだよな…。でも、どの解説ページも、「32GB以上が必要」と書いてるし。これはどういうことなのだろう。
*1: 回復ドライブを作成するために、わざわざ32GBのUSBメモリを新規購入したのに、そういう結果になってしまって、「なんだそりゃ」「16GBで済むならそう言ってくれ」「手元にあったUSBメモリでも間に合ったじゃんよ」と憤慨した記憶が…。
[ ツッコむ ]
#2 [pc] 弟から貰ったPCパーツについてメモ
弟が帰省した際に譲ってくれたPCパーツの型番をメモ。メモしておかないと絶対に忘れるので…。
_価格.com - 東芝 CANVIO DESK HD-ED20TK [ブラック] スペック・仕様
_価格.com - crucial CT512M550SSD1 スペック・仕様
_ハイエンド並みの性能を発揮――「Crucial M550 SSD」徹底検証:注目SSD速攻レビュー(1/2 ページ) - ITmedia PC USER
_価格.com - 東芝 MD03ACA400 [4TB SATA600 7200] スペック・仕様
_東芝(TOSHIBA)製HDD_リテール品_MD03ACAシリーズ
_価格.com - 東芝 DT01ACA300 [3TB SATA600 7200] スペック・仕様
_DT01 シリーズ | 東芝デバイス&ストレージ株式会社 | 日本
_価格.com - HGST HTS721010A9E630 [1TB 9.5mm] スペック・仕様
_価格.com - HGST HTS541515A9E630 [1.5TB 9.5mm] スペック・仕様
_eSATA活してUSB3.0 (CCA-ESU3) - 株式会社センチュリー
_Owltech ドライブケース OWL-EGP35/EU ガチャポンパッ! (WebArchive)
_オウルテック、ネジ不要のHDDケース「3ステップケース ガチャポンパッ! 」
- USB3.0接続外付けHDD TOSHIBA CANVIO DESK HD-ED20TK (2TB, TOSHIBA DT01ABA200, Cache 32MB, SATA600, 5700rpm, 使用時間188時間)
- 2.5インチSSD crucial M550 CT512M550SSD1 (2.5インチ, 512GB, MLC, SATA600, 初期ファームウェア MU01)
- 3.5インチHDD TOSHIBA MD03ACA400 (3.5インチ, 4TB, SATA600, 7200rpm, Cache 64MB) x 2
- 3.5インチHDD TOSHIBA DT01ACA300 (3.5インチ, 3TB, SATA600, 7200rpm, CMR, Cache 64MB)
- 2.5インチHDD HGST 7K1000-1000 HTS721010A9E630 (2.5インチ, 1TB, SATA600, 7200rpm, 9.5mm)
- 2.5インチHDD HGST 5K1500-1500 HTS541515A9E630 (2.5インチ, 1.5TB, SATA600, 5400rpm, 9.5mm, Cache 32MB)
- HDDリムーバブルケーストレイ RATOC REX-SATA SA-RC1 (3.5インチSATA HDD対応)
- eSATA USB3.0変換アダプタ センチュリー eSATA活してUSB3.0 CCA-ESU3
- 3.5インチHDDケース 型番不明だけどおそらく オウルテック 3ステップケース ガチャポンパッ! OWL-EGP35/EU (3.5インチHDD対応、eSATA, USB2.0, 側面にファン付, 色はシルバー, ※ 同じ見た目の OWL-EGP35/CEU はSATAとIDEの両方に対応。OWL-EGP35/EU はSATAのみ対応)
_価格.com - 東芝 CANVIO DESK HD-ED20TK [ブラック] スペック・仕様
_価格.com - crucial CT512M550SSD1 スペック・仕様
_ハイエンド並みの性能を発揮――「Crucial M550 SSD」徹底検証:注目SSD速攻レビュー(1/2 ページ) - ITmedia PC USER
_価格.com - 東芝 MD03ACA400 [4TB SATA600 7200] スペック・仕様
_東芝(TOSHIBA)製HDD_リテール品_MD03ACAシリーズ
_価格.com - 東芝 DT01ACA300 [3TB SATA600 7200] スペック・仕様
_DT01 シリーズ | 東芝デバイス&ストレージ株式会社 | 日本
_価格.com - HGST HTS721010A9E630 [1TB 9.5mm] スペック・仕様
_価格.com - HGST HTS541515A9E630 [1.5TB 9.5mm] スペック・仕様
_eSATA活してUSB3.0 (CCA-ESU3) - 株式会社センチュリー
_Owltech ドライブケース OWL-EGP35/EU ガチャポンパッ! (WebArchive)
_オウルテック、ネジ不要のHDDケース「3ステップケース ガチャポンパッ! 」
◎ HDD-SCANで不良セクタが無いかチェック :
USB3.0接続外付けHDD TOSHIBA CANVIO DESK HD-ED20TK は、親父さんに渡す予定なので、渡す前に不良セクタがないか一応チェック。今回は HDD-SCAN 2.0 というツールを利用させてもらった。
_世界で一番使いやすいハードディスク故障診断ソフトHDD-Scan
_HDD-SCANのインストールと使い方を解説!不良セクタのチェックができるフリーソフト | 名古屋市パソコン修理専門店「かおるや」のブログ
USB3.0接続、2TB、5700rpmのHDDで、約4時間半ほどかかった。初回利用時はログを保存する段階で不正終了してしまった。
チェック中のHDDの温度は48度。ちょっと怖いな…。経験的にHDDは、60度を超えると転送エラーをガンガン出し始めるので、50度を超えそうだと、少しハラハラしてくる。
余談。チェックする前に、「ディスクの管理」から「ボリュームの削除」「シンプルボリュームの作成」(クイックフォーマット付き)をしておいてから、該当ドライブのプロパティ → セキュリティ、で、ユーザとして Everyone を追加してフルコントロールを指定。かつ、所有者を Everyone にしておいた。
もしかすると、こういうことはやらなくていいのかもしれないけど、昔、普段使ってるPCとは違うPCに外付けHDDを繋いだら、ファイルやフォルダの書き換えができなかったことがあるので…。一応念のため。それと、「コンテンツにインデックスをつける」のチェックも外しておいた。
_世界で一番使いやすいハードディスク故障診断ソフトHDD-Scan
_HDD-SCANのインストールと使い方を解説!不良セクタのチェックができるフリーソフト | 名古屋市パソコン修理専門店「かおるや」のブログ
USB3.0接続、2TB、5700rpmのHDDで、約4時間半ほどかかった。初回利用時はログを保存する段階で不正終了してしまった。
チェック中のHDDの温度は48度。ちょっと怖いな…。経験的にHDDは、60度を超えると転送エラーをガンガン出し始めるので、50度を超えそうだと、少しハラハラしてくる。
余談。チェックする前に、「ディスクの管理」から「ボリュームの削除」「シンプルボリュームの作成」(クイックフォーマット付き)をしておいてから、該当ドライブのプロパティ → セキュリティ、で、ユーザとして Everyone を追加してフルコントロールを指定。かつ、所有者を Everyone にしておいた。
もしかすると、こういうことはやらなくていいのかもしれないけど、昔、普段使ってるPCとは違うPCに外付けHDDを繋いだら、ファイルやフォルダの書き換えができなかったことがあるので…。一応念のため。それと、「コンテンツにインデックスをつける」のチェックも外しておいた。
◎ eSATAをUSB3.0に変換できるアダプタについて :
今回貰ったパーツの中に、「センチュリー eSATA活してUSB3.0 CCA-ESU3」という製品があって、「そんな変換アダプタがあるのか…」と驚いた。
こういったアダプタを使えば、自分の部屋で埃を被っている、eSATA + USB2.0 の外付けHDDケース数台も、まだまだ有効活用できそう。eSATA接続ならともかく、USB2.0接続で数TBのHDDを使うのは厳しいわけだけど、自分の手持ちのPC群は、もはやeSATA接続端子が無くなっているわけで…。
しかし、値段を調べて悩んでしまった。新品のUSB3.0接続外付けHDDケースと同じくらいの値段なのね…。だったら外付けHDDケースを買ってしまったほうが話が早いのでは…。
いや、昔の外付けHDDケースにはファンがついてたりするから、冷却面を考えると、eSATA-USB3.0変換アダプタを使ったほうがマシかもしれないか…。冷却ファン付きのHDDケースって、今ではもう数種類しか販売されてない状態だし。
とは言え、この変換アダプタ、他のUSB3.0ポートを塞いでしまうぐらいに横幅があるのはちょっとアレだなと…。かと言って、USB3.0延長ケーブルを使うとエラーが出そうだし…。
こういったアダプタを使えば、自分の部屋で埃を被っている、eSATA + USB2.0 の外付けHDDケース数台も、まだまだ有効活用できそう。eSATA接続ならともかく、USB2.0接続で数TBのHDDを使うのは厳しいわけだけど、自分の手持ちのPC群は、もはやeSATA接続端子が無くなっているわけで…。
しかし、値段を調べて悩んでしまった。新品のUSB3.0接続外付けHDDケースと同じくらいの値段なのね…。だったら外付けHDDケースを買ってしまったほうが話が早いのでは…。
いや、昔の外付けHDDケースにはファンがついてたりするから、冷却面を考えると、eSATA-USB3.0変換アダプタを使ったほうがマシかもしれないか…。冷却ファン付きのHDDケースって、今ではもう数種類しか販売されてない状態だし。
とは言え、この変換アダプタ、他のUSB3.0ポートを塞いでしまうぐらいに横幅があるのはちょっとアレだなと…。かと言って、USB3.0延長ケーブルを使うとエラーが出そうだし…。
◎ HDDケース OWL-EGP35/EUにHDDを入れた :
オウルテック OWL-EGP35/EU に、4TB HDD、TOSHIBA MD03ACA400 を入れてみた。
HDDケースの型番が分かる情報はどこにもついてないのだけど、ググった感じではおそらくこの製品だろうなと…。
最初、開け方が分からなかったけど、USB端子やeSATA端子がある側に、ロック用のスライドスイッチがあって、そこを動かせばスポンと抜ける模様。スライドスイッチを動かしたら物凄い勢いで下にスポーンと抜けて、中身が床の上にゴンッと落ちてしまった…。ケース前面に傷がついてしまったかもしれない…。
脇のプラスチックパーツを開け閉めすることで、ネジ不要でHDDを固定できる。HDDの取付作業は物凄く簡単。イイ感じ。
「センチュリー eSATA活してUSB3.0 CCA-ESU3」を経由させてeSATAをUSB3.0に変換して、サブPC(Windows10 x64 22H2機、CPU: Athlon 5350 Quad-Core (2GHz, 4core, TDP 25W))に繋いでみた。
CrystalDiskInfo 8.17.14 x64 で確認したところ、「SATA/150 | SATA/600」と表示された。中のHDDは SATA/600 だけど、HDDケースのインターフェイスは SATA/150、ということかな…。HDDケース側が古くてSATA/150になってしまうのか、それともUSB3.0接続は大体SATA/150になってしまうのか。あるいは変換アダプタを通すとそうなるのだろうか。
とりあえず、HDD-Scan V2.0 を使って不良セクタが無さそうかチェック開始。12時間ぐらいかかると表示されてる。2TBのHDDをチェックした時は4時間半で済んだけど、それと比べると遅い気がする。eSATAとUSB3.0の変換をしているから遅くなってるのか、それともサブPCのCPUがメインPCのCPUと比べると圧倒的に非力だから遅いのだろうか。
HDDケースの型番が分かる情報はどこにもついてないのだけど、ググった感じではおそらくこの製品だろうなと…。
最初、開け方が分からなかったけど、USB端子やeSATA端子がある側に、ロック用のスライドスイッチがあって、そこを動かせばスポンと抜ける模様。スライドスイッチを動かしたら物凄い勢いで下にスポーンと抜けて、中身が床の上にゴンッと落ちてしまった…。ケース前面に傷がついてしまったかもしれない…。
脇のプラスチックパーツを開け閉めすることで、ネジ不要でHDDを固定できる。HDDの取付作業は物凄く簡単。イイ感じ。
「センチュリー eSATA活してUSB3.0 CCA-ESU3」を経由させてeSATAをUSB3.0に変換して、サブPC(Windows10 x64 22H2機、CPU: Athlon 5350 Quad-Core (2GHz, 4core, TDP 25W))に繋いでみた。
CrystalDiskInfo 8.17.14 x64 で確認したところ、「SATA/150 | SATA/600」と表示された。中のHDDは SATA/600 だけど、HDDケースのインターフェイスは SATA/150、ということかな…。HDDケース側が古くてSATA/150になってしまうのか、それともUSB3.0接続は大体SATA/150になってしまうのか。あるいは変換アダプタを通すとそうなるのだろうか。
とりあえず、HDD-Scan V2.0 を使って不良セクタが無さそうかチェック開始。12時間ぐらいかかると表示されてる。2TBのHDDをチェックした時は4時間半で済んだけど、それと比べると遅い気がする。eSATAとUSB3.0の変換をしているから遅くなってるのか、それともサブPCのCPUがメインPCのCPUと比べると圧倒的に非力だから遅いのだろうか。
[ ツッコむ ]
#3 [ubuntu][linux] Ubuntu 22.04 LTSのパーティションサイズを縮小
Ubuntu Linux 22.04 LTS をインストールしてあるサブPC(Intel Core i3-6100T機)のHDDに対して、パーティションサイズを480GBから240GBに縮小しようとした。いつかSSDに引っ越しできる程度のサイズにしておきたい。
ただ、GParted を使えばパーティションサイズの縮小ができるものと思い込んでいたけど、これがすんなり行かなくて。
結論を先に書くと、GParted の公式サイトから gparted-live-1.5.0-1-i686.iso を入手して、USBメモリに Unetbootin を使って書き込んで、起動時に VGA 云々と表示されている項目を選んで起動したら、パーティションサイズを縮小することができた。
_GParted -- Download
以下は失敗した手順。
たしか以前、別PCでパーティションサイズの縮小をした際も、GParted公式版じゃないと作業できなかった記憶があるので、この手の作業をする場合は GParted公式版を使ったほうがいいのかも。
ただ、GParted を使えばパーティションサイズの縮小ができるものと思い込んでいたけど、これがすんなり行かなくて。
結論を先に書くと、GParted の公式サイトから gparted-live-1.5.0-1-i686.iso を入手して、USBメモリに Unetbootin を使って書き込んで、起動時に VGA 云々と表示されている項目を選んで起動したら、パーティションサイズを縮小することができた。
_GParted -- Download
以下は失敗した手順。
- Ubuntu Linux 22.04 LTS に入ってる GParted は、Ubuntu が使ってる最中のパーティションに対して処理ができないので、これで作業をするのは無理。何か方法があるのかもしれないけど…。
- UBCD (Ultimate Boot CD) 5.3.9 の中に入っている GParted を使ったら、パーティションサイズを縮小する段階でエラーが出て失敗した。縮小処理をする際に、最初に動かすべきプログラムがあるらしいけど、そのプログラムが存在しないか、もしくはエラーを出していたように見えた。
- KNOPPIX 9.1 に入ってる GParted を使ったら、こちらもエラー。UBCD に入ってる版よりは先まで処理が進んだけど、それでも途中でエラーが出る。
- GParted 公式サイトからDLした版も、初回起動時はデスクトップ画面(X Window)が表示されなくて失敗。再チャレンジした際、最初にVGA云々を選んだら、デスクトップ画面が表示される状態になった。
たしか以前、別PCでパーティションサイズの縮小をした際も、GParted公式版じゃないと作業できなかった記憶があるので、この手の作業をする場合は GParted公式版を使ったほうがいいのかも。
◎ デスクトップ画面が表示されない問題 :
GParted公式版を利用した際、最初の起動時はデスクトップ画面が表示されなかったのだけど。それについては、ひょっとすると Intel製CPUの内蔵GPU用ドライバに何か問題があるのかもしれない。別PCではデスクトップ画面がすんなり表示された記憶があるので…。
Intel Core i3-6100T の内蔵GPUは、Intel HD Graphics 530。ググってみたら、Linux を動かすには少し問題がありそうな…。i3-6100T は TDP 35W のCPUだから、この不具合を踏んでたりするのだろうか…?
_Intel graphics - ArchWiki
_Dell XPS 15 (9550) - ArchWiki
_Gentoo Linux で Intel Core i5-6500 の Intel HD Graphics 530 を使うメモ - Yuichiro_S の Twitterでは文字数が足りないもの
Intel Core i3-6100T の内蔵GPUは、Intel HD Graphics 530。ググってみたら、Linux を動かすには少し問題がありそうな…。i3-6100T は TDP 35W のCPUだから、この不具合を踏んでたりするのだろうか…?
_Intel graphics - ArchWiki
低消費電力 Intel CPU でクラッシュ/フリーズ
低消費電力 Intel プロセッサやノート PC プロセッサは、低消費電力 Intel チップで使用されている電源管理機能に関する問題によりランダムにハングアップ/クラッシュする傾向にあります。そのようなクラッシュが発生する場合、この問題を報告するログは見られないでしょう。以下のカーネルパラメータを追加することで、この問題を解決できるかもしれません。
ノート: 以下のカーネルパラメータを3つすべて一緒に使用することは推奨されません。
intel_idle.max_cstate=1
i915.enable_dc=0
ahci.mobile_lpm_policy=1
_Dell XPS 15 (9550) - ArchWiki
ブートパラメータ
以下のカーネルパラメータを使用することで解決できる問題があります:
i915.edp_vswing=2 i915.preliminary_hw_support=1 intel_idle.max_cstate=1 acpi_backlight=vendor acpi_osi=Linux
i915.edp_vswing=2 画面のちらつきを抑えます。
i915.preliminary_hw_support=1 Intel Graphics の問題を解決します。
intel_idle.max_cstate=1 CPU の C ステート が 1 より大きくならなくなります。
acpi_backlight=vendor acpi_osi=Linux バックライトが制御できるようになります。
_Gentoo Linux で Intel Core i5-6500 の Intel HD Graphics 530 を使うメモ - Yuichiro_S の Twitterでは文字数が足りないもの
[ ツッコむ ]
2023/05/06(土) [n年前の日記]
#1 [ubuntu][linux] Ubuntu LinuxでHDDに不良セクタが無いかチェックした
Ubuntu Linux 22.04 LTS を使って、4TB 3.5インチHDD、TOSHIBA MD03ACA400 に不良セクタがないかチェックしたい。ちなみにHDDは、外付けHDDケースを使わず、M/BにSATAで接続してある。
*1
ググってみたら、badblocks というツールがあるらしい。
_Linuxでディスクのエラーや不良セクタのチェックと修正をする方法 - Ubuntu入門
_LinuxでHDDの不具合を特定する作業の覚え書き -- ぺけみさお
_badblocks - ArchWiki
_badblocks - Ubuntu入門
_似非管理者の寂しい夜:ubuntu 12.04でbadblocksコマンドを使う - livedoor Blog(ブログ)
_Linux - HDD 不良セクタのチェック等! - mk-mode BLOG
これを使えばいいのだな…。
Ubuntu Linux 22.04 LTS上で、GParted を起動して、対象とするHDD(/dev/sdb)に対して、パーティションを新規作成。ext4でフォーマット。
hdparm を使って、HDDの情報を確認。
badblocks を実行。
5時間ぐらいかかってチェック終了。不良セクタは無い、と言ってきた。
もし不良セクタがあった場合は、そのセクタを使わないようにマークをつけてやる必要があるらしい。そのあたりは前述の参考ページで解説されてる。
ググってみたら、badblocks というツールがあるらしい。
_Linuxでディスクのエラーや不良セクタのチェックと修正をする方法 - Ubuntu入門
_LinuxでHDDの不具合を特定する作業の覚え書き -- ぺけみさお
_badblocks - ArchWiki
_badblocks - Ubuntu入門
_似非管理者の寂しい夜:ubuntu 12.04でbadblocksコマンドを使う - livedoor Blog(ブログ)
_Linux - HDD 不良セクタのチェック等! - mk-mode BLOG
これを使えばいいのだな…。
Ubuntu Linux 22.04 LTS上で、GParted を起動して、対象とするHDD(/dev/sdb)に対して、パーティションを新規作成。ext4でフォーマット。
hdparm を使って、HDDの情報を確認。
$ sudo hdparm -i /dev/sdb1
/dev/sdb1:
Model=TOSHIBA DT01ACA300, FwRev=MX6OABB0, SerialNo=xxxxxxxxx
Config={ HardSect NotMFM HdSw>15uSec Fixed DTR>10Mbs }
RawCHS=16383/16/63, TrkSize=0, SectSize=0, ECCbytes=56
BuffType=DualPortCache, BuffSize=unknown, MaxMultSect=16, MultSect=16
CurCHS=16383/16/63, CurSects=16514064, LBA=yes, LBAsects=5860533168
IORDY=on/off, tPIO={min:120,w/IORDY:120}, tDMA={min:120,rec:120}
PIO modes: pio0 pio1 pio2 pio3 pio4
DMA modes: mdma0 mdma1 mdma2
UDMA modes: udma0 udma1 udma2 udma3 udma4 udma5 *udma6
AdvancedPM=yes: disabled (255) WriteCache=enabled
Drive conforms to: unknown: ATA/ATAPI-2,3,4,5,6,7
* signifies the current active mode
badblocks を実行。
sudo badblocks -s -o badblocks-DT01ACA300.txt /dev/sdb1
- -s : スキャンの進捗を表示
- -o hoge.txt : 不良セクタの場所をテキストファイルに保存
5時間ぐらいかかってチェック終了。不良セクタは無い、と言ってきた。
もし不良セクタがあった場合は、そのセクタを使わないようにマークをつけてやる必要があるらしい。そのあたりは前述の参考ページで解説されてる。
*1: サブPCの5インチベイにリムーバブルケースを入れてあるので、そこにHDDを差し込んだ。
[ ツッコむ ]
#2 [ubuntu] Ubuntu Linux 22.04 LTSを動かしてるサブPCにカーネルオプションを指定
Ubuntu Linux 22.04 LTS を動かしてるサブPCには、Intel Core i3-6100T が載ってる。内蔵GPUは、Intel HD Graphics 530。このGPUについてググってたら、カーネルオプションとやらを渡すと不具合が解決する、という話を見かけたので、一応そのあたりを設定してみた。
_Dell XPS 15 (9550) - ArchWiki
自分のサブPCは、Dell XPS 15 (9550) ではないけれど、Intel HD Graphics 530 が入ってるCPUという点は同じであろう気がする。grub の設定で、このあたりの指定を追加してみた。バックライト云々は関係ないから、それ以外の3つを列挙してみよう…。
「Intel HD Graphics 530 では、*-video-intel ドライバを使えば良い」と書いてあるので、パッケージ、xserver-xorg-video-intel もインストール。ただ、これは既にインストール済みだった。
_Dell XPS 15 (9550) - ArchWiki
ブートパラメータ
以下のカーネルパラメータを使用することで解決できる問題があります:
i915.edp_vswing=2 i915.preliminary_hw_support=1 intel_idle.max_cstate=1 acpi_backlight=vendor acpi_osi=Linux
i915.edp_vswing=2 画面のちらつきを抑えます。
i915.preliminary_hw_support=1 Intel Graphics の問題を解決します。
intel_idle.max_cstate=1 CPU の C ステート が 1 より大きくならなくなります。
acpi_backlight=vendor acpi_osi=Linux バックライトが制御できるようになります。
グラフィック設定
Dell XPS 15 9550 は Intel HD Graphics 530 内蔵グラフィックを搭載しています。モデルによっては Nvidia GeForce GTX 960 カードが接続されていたりハイブリッド構成になっています。
内蔵グラフィックしか存在しないコンピュータでは、xf86-video-intel ドライバーをインストールしてください。
自分のサブPCは、Dell XPS 15 (9550) ではないけれど、Intel HD Graphics 530 が入ってるCPUという点は同じであろう気がする。grub の設定で、このあたりの指定を追加してみた。バックライト云々は関係ないから、それ以外の3つを列挙してみよう…。
sudo vi /etc/default/grub
... GRUB_CMDLINE_LINUX_DEFAULT="noquiet nosplash i915.edp_vswing=2 i915.preliminary_hw_support=1 intel_idle.max_cstate=1" ...
sudo update-grub
「Intel HD Graphics 530 では、*-video-intel ドライバを使えば良い」と書いてあるので、パッケージ、xserver-xorg-video-intel もインストール。ただ、これは既にインストール済みだった。
sudo apt install xserver-xorg-video-intel
[ ツッコむ ]
2023/05/07(日) [n年前の日記]
#1 [pc] HDDに不良セクタがないかチェック
3.5インチHDD、TOSHIBA MD03ACA400 (4TB, SATA600, 7600rpm)に不良セクタが無いかチェックしておいた。
7時間10分ほどかかって処理終了。不良セクタ数は0。問題無し。
ちなみに、CrystalDiskInfo で調べたところ、「SATA/600 | SATA/600」「使用時間 9871時間」と表示されていた。9,000時間以上動いていたなら、すぐに壊れてしまう個体では無さそう。
- OS : Windows10 x64 22H2
- CPU : AMD Ryzen 5 5600X
- HDDスタンド : Logitec LGB-1BSTU3 (USB3.0接続)
- ツール : HDD Scan V2.0
7時間10分ほどかかって処理終了。不良セクタ数は0。問題無し。
ちなみに、CrystalDiskInfo で調べたところ、「SATA/600 | SATA/600」「使用時間 9871時間」と表示されていた。9,000時間以上動いていたなら、すぐに壊れてしまう個体では無さそう。
◎ OWL-EGP35/EUとの比較 :
今回、USB3.0接続のHDDスタンドを使って作業したわけだけど。別PC + HDDケース オウルテック OWL-EGP35/EU + センチュリー eSATA活してUSB3.0 CCA-ESU3 を使って、同じ型番のHDDをチェックした時は12時間ぐらいかかっていたので、それと比べると結構早い。前回と比べて、約6割程度の時間で処理が終わった。
今回、「SATA/600 | SATA/600」と表示されていたので、HDDもインターフェイスもSATA/600として検出されているらしい。前述の OWL-EGP35/EU + CCA-ESU3 の場合は「SATA/150 | SATA/600」と表示されていたので…。USB3.0で接続すると、必ず SATA/150 になってしまう、というわけではなさそう。USB3.0接続でも、SATA/600 として検出される場合もあるらしい。というか、ソレがフツーなのかもしれない。
やはり、OWL-EGP35/EU + CCA-ESU3 を使うと、フツーのUSB3.0接続外付けHDDケースより速度が遅くなってしまうようだなと。インターフェイスの種類も古くなるし、アクセス速度も約1.7倍ぐらい余計に時間がかかってしまう。HDDケースが古くてそうなるのか、それとも eSATA - USB3.0変換アダプタを使うとそうなるのかは分からんけど。
今回、「SATA/600 | SATA/600」と表示されていたので、HDDもインターフェイスもSATA/600として検出されているらしい。前述の OWL-EGP35/EU + CCA-ESU3 の場合は「SATA/150 | SATA/600」と表示されていたので…。USB3.0で接続すると、必ず SATA/150 になってしまう、というわけではなさそう。USB3.0接続でも、SATA/600 として検出される場合もあるらしい。というか、ソレがフツーなのかもしれない。
やはり、OWL-EGP35/EU + CCA-ESU3 を使うと、フツーのUSB3.0接続外付けHDDケースより速度が遅くなってしまうようだなと。インターフェイスの種類も古くなるし、アクセス速度も約1.7倍ぐらい余計に時間がかかってしまう。HDDケースが古くてそうなるのか、それとも eSATA - USB3.0変換アダプタを使うとそうなるのかは分からんけど。
[ ツッコむ ]
2023/05/08(月) [n年前の日記]
#1 [cg_tools] 画像生成AIをまた触り始めた
画像生成AI、Stable Diffusion web UI をまた触り始めた。いくつか気になる拡張やLoRA(追加学習データ)の話を見かけたので。
◎ flatを試した :
flatというLoRAを使うと、画像のディティールを細かくすることができるらしい。本来は、生成画像をフラットに、というか、のっぺりした感じにしてくれるものだけど、マイナス値を指定することで逆にフラット感を減らしてくれるのだとか。
_【Stable Diffusion】LoRAだけで手軽に画質をUPできるflat | ジコログ
_「flat」 LoRA による画風の変化と画像の精緻化【Stable Diffusion web UI】
_イラストに精緻なディテールを追加できる「flat LoRA」の紹介【Stable Diffusion】 | くろくまそふと
実写寄りのモデルデータで試してみたけど、違いがよく分からない…。イラスト/アニメ風のモデルデータで試さないと効果のほどが分かりづらいのかな…。
_【Stable Diffusion】LoRAだけで手軽に画質をUPできるflat | ジコログ
_「flat」 LoRA による画風の変化と画像の精緻化【Stable Diffusion web UI】
_イラストに精緻なディテールを追加できる「flat LoRA」の紹介【Stable Diffusion】 | くろくまそふと
実写寄りのモデルデータで試してみたけど、違いがよく分からない…。イラスト/アニメ風のモデルデータで試さないと効果のほどが分かりづらいのかな…。
◎ LowRAを試した :
LowRAというLoRAを使うと、生成画像を暗めな感じにしてくれるらしい。
_【LoRA】重厚感のあるローキー画像を生成できるLowRA | ジコログ
試してみたけど、たしかにダークな感じの生成画像が得られた。しかし、顔が崩れたり、手足その他がおかしくなる確率が上がってしまう気がする…。なかなか厳しい。
_【LoRA】重厚感のあるローキー画像を生成できるLowRA | ジコログ
試してみたけど、たしかにダークな感じの生成画像が得られた。しかし、顔が崩れたり、手足その他がおかしくなる確率が上がってしまう気がする…。なかなか厳しい。
◎ Ultimate SD Upscaleを試した :
Ultimate SD Upscale という拡張機能を使うと、画像の高解像度化が早く、かつ、元画像より崩れにくくなるらしい。
_Ultimate SD Upscale【拡張機能のアップスケーラー】 | ジコログ
_【Stable Diffusion】「Ultimate SD Upscaler」を使って生成したAIイラストを高画質化する方法!【img2img】 | 悠々ログ
たしかにそれらしい画像が得られた。
ただ、画像を分割して処理していくので、分割した画像内で別人を生成してしまったりもするそうで。そんな時は ControlNet (tile_resample) と組み合わせると解決できる可能性があるのだとか。
_ControlNetとUltimate SD Upscaleを使った画像の高画質化 | ジコログ
_Ultimate SD Upscale【拡張機能のアップスケーラー】 | ジコログ
_【Stable Diffusion】「Ultimate SD Upscaler」を使って生成したAIイラストを高画質化する方法!【img2img】 | 悠々ログ
たしかにそれらしい画像が得られた。
ただ、画像を分割して処理していくので、分割した画像内で別人を生成してしまったりもするそうで。そんな時は ControlNet (tile_resample) と組み合わせると解決できる可能性があるのだとか。
_ControlNetとUltimate SD Upscaleを使った画像の高画質化 | ジコログ
◎ Loopback Scalerを試した :
Loopback Scaler という拡張機能を利用することで、高解像度の生成画像を得ることもできるらしい。
_Loopback Scalerによる画像の解像度・品質UP | ジコログ
_【Stable Diffusion】img2imgで簡単に高画質化できる拡張機能「Loopback scaler」の使い方を紹介! | 悠々ログ
試したところ、目標の画像サイズまで、少しずつ画像を拡大して生成していくようで…。たしかに目標の画像サイズにはなったものの、何度も何度も img2img を繰り返すせいか、元画像から随分とかけ離れた結果になった。まあ、これはこれで、予測不能な結果が出てくるから、何か使い道があるのかもしれない。
_Loopback Scalerによる画像の解像度・品質UP | ジコログ
_【Stable Diffusion】img2imgで簡単に高画質化できる拡張機能「Loopback scaler」の使い方を紹介! | 悠々ログ
試したところ、目標の画像サイズまで、少しずつ画像を拡大して生成していくようで…。たしかに目標の画像サイズにはなったものの、何度も何度も img2img を繰り返すせいか、元画像から随分とかけ離れた結果になった。まあ、これはこれで、予測不能な結果が出てくるから、何か使い道があるのかもしれない。
◎ Clip skipを変更できるようにした :
学習モデルデータによっては、Clip skip なる値を変更するとイイ感じの結果が得られたりすることもあるらしい。ただ、Stable Diffusion web UIは標準で、その値を変更できるようになってない。設定を変更して、Clip skipを変更できるようにした。
_Stable Diffusion Clip Skipについて: 設定方法と影響 | Gift by Gifted
_stable-diffusion-webui を素早く使いこなすためのtips - Qiita
結果は…。何が変わったのかちょっとよく分からないな…。
_Stable Diffusion Clip Skipについて: 設定方法と影響 | Gift by Gifted
_stable-diffusion-webui を素早く使いこなすためのtips - Qiita
結果は…。何が変わったのかちょっとよく分からないな…。
[ ツッコむ ]
#2 [pc] HDDに不良セクタがないかチェックその2
2.5インチHDDに不良セクタが無いかチェックしてた。
各HDDは、HDDスタンド Logitec LGB-1BSTU3 (2.5/3.5インチSATA接続HDD対応, USB3.0接続) に差して、メインPC(Windows10 x64 22H2)上で HDD-Scan V2.0 を起動してチェックした。
エラーは無し。不良セクタはまだ無いっぽい。
1.5TBのほうは、5時間前後でチェックが終わった。
2TBの3.5インチHDD + USB3.0接続の場合、4時間半で終わっていたので…。2.5インチHDDは、3.5インチHDDよりもアクセス速度が遅いことが、実測でも再認識できた。
さて、このHDD、どうしようか…。自分、2.5インチHDDケースを何も持ってないので、このままでは常用できない…。何かケースを買うしかないわな…。
以前、Logitec LGB-PBPU3 というHDDケースを持ってたこともあるのだけど、使っているうちに壊れてしまったのだよな…。おそらくはコントローラが死んでしまったのだろうと思うけど。できれば壊れにくいHDDケースが欲しいところだけど、どの製品も五十歩百歩なのでは、という予感も…。
- 2.5インチHDD HGST 7K1000-1000 HTS721010A9E630 (2.5インチ, 1TB, SATA600, 7200rpm, 9.5mm, 使用時間17321時間)
- 2.5インチHDD HGST 5K1500-1500 HTS541515A9E630 (2.5インチ, 1.5TB, SATA600, 5400rpm, 9.5mm, Cache 32MB, 使用時間328時間)
各HDDは、HDDスタンド Logitec LGB-1BSTU3 (2.5/3.5インチSATA接続HDD対応, USB3.0接続) に差して、メインPC(Windows10 x64 22H2)上で HDD-Scan V2.0 を起動してチェックした。
エラーは無し。不良セクタはまだ無いっぽい。
1.5TBのほうは、5時間前後でチェックが終わった。
2TBの3.5インチHDD + USB3.0接続の場合、4時間半で終わっていたので…。2.5インチHDDは、3.5インチHDDよりもアクセス速度が遅いことが、実測でも再認識できた。
さて、このHDD、どうしようか…。自分、2.5インチHDDケースを何も持ってないので、このままでは常用できない…。何かケースを買うしかないわな…。
以前、Logitec LGB-PBPU3 というHDDケースを持ってたこともあるのだけど、使っているうちに壊れてしまったのだよな…。おそらくはコントローラが死んでしまったのだろうと思うけど。できれば壊れにくいHDDケースが欲しいところだけど、どの製品も五十歩百歩なのでは、という予感も…。
[ ツッコむ ]
2023/05/09(火) [n年前の日記]
#1 [pc] 「排紙トレイが閉じている」とエラーが出る
親父さんからPC相談を受けた。親父さんが使っているインクジェットプリンタ、Canon PIXUS PRO-100S で、印刷しようとするとエラーが出るそうで。
エラーメッセージは以下。
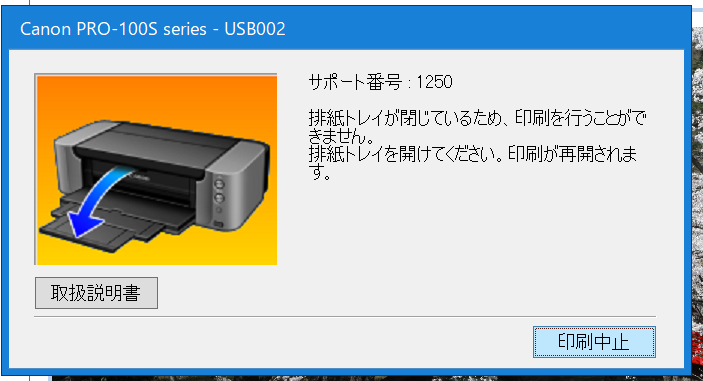
_キヤノン:PIXUS マニュアル|PRO-100S series|1250
もちろん、排紙トレイはちゃんと開けてある。
ググってみたところ、Canon製プリンタには、排紙トレイが閉じているか/開いているかを検出するセンサがついていて、そのセンサの位置がおかしくなって正常に検出できない状態になると、こういったエラーメッセージが表示されて詰んでしまうらしい…。
_canon PiXUS 排紙トレイが閉じているため、印刷を行うことができません。 - パソコン出張サポート、パソポート代表の気まま日記
_インクジェットプリンタ徒然日記 レビュー PIXUS ip4100の修理 (WebArchive)
_『排紙トレーが閉じています』のエラーが出て印刷できないときの対処 | 使える無料ソフト&無料サービス
_『排紙トレイが閉じているため...』とは何だ?プリンターの不具合編1: Automatic
_PIXUS ip4200の自力修理を強行!『排紙トレイが閉じているため...』とは何だ?プリンターの不具合編2<解決版>: Automatic
iP4xxxx番台の製品なら、情報もそこそこあって、大体このあたりにセンサがあると分かるから、自力でどうにか解決できそうな気配があるのだけど。Canon PRO-100S という製品は、A3ノビまで印刷可能、8色インクと、ちょっとグレードが高い製品なので、関連情報は皆無。排紙トレイの周辺を眺めてみたけど、これがそのセンサだろう、というものは全く見つからなかった。
修理に出すしかなさそうだな…。
ちなみに、先日弟が帰省した際もこの問題は発生していて…。弟が少しググって調べたけれど、「センサの位置も種類も分からんから手詰まり」という結論になっていた。自分も今回調べてみたけど、やはり弟と同じ結論になってしまったなと…。
エラーメッセージは以下。
サポート番号 : 1250 排紙トレイが閉じているため、印刷を行うことができません。 排紙トレイを開けてください。印刷が再開されます。
_キヤノン:PIXUS マニュアル|PRO-100S series|1250
もちろん、排紙トレイはちゃんと開けてある。
ググってみたところ、Canon製プリンタには、排紙トレイが閉じているか/開いているかを検出するセンサがついていて、そのセンサの位置がおかしくなって正常に検出できない状態になると、こういったエラーメッセージが表示されて詰んでしまうらしい…。
_canon PiXUS 排紙トレイが閉じているため、印刷を行うことができません。 - パソコン出張サポート、パソポート代表の気まま日記
_インクジェットプリンタ徒然日記 レビュー PIXUS ip4100の修理 (WebArchive)
_『排紙トレーが閉じています』のエラーが出て印刷できないときの対処 | 使える無料ソフト&無料サービス
_『排紙トレイが閉じているため...』とは何だ?プリンターの不具合編1: Automatic
_PIXUS ip4200の自力修理を強行!『排紙トレイが閉じているため...』とは何だ?プリンターの不具合編2<解決版>: Automatic
iP4xxxx番台の製品なら、情報もそこそこあって、大体このあたりにセンサがあると分かるから、自力でどうにか解決できそうな気配があるのだけど。Canon PRO-100S という製品は、A3ノビまで印刷可能、8色インクと、ちょっとグレードが高い製品なので、関連情報は皆無。排紙トレイの周辺を眺めてみたけど、これがそのセンサだろう、というものは全く見つからなかった。
修理に出すしかなさそうだな…。
ちなみに、先日弟が帰省した際もこの問題は発生していて…。弟が少しググって調べたけれど、「センサの位置も種類も分からんから手詰まり」という結論になっていた。自分も今回調べてみたけど、やはり弟と同じ結論になってしまったなと…。
[ ツッコむ ]
2023/05/10(水) [n年前の日記]
#1 [pc] ダイソーのHDMIケーブルを入手しでHDMIセレクタの動作確認をした
ダイソーでHDMIケーブルを購入。300円商品。パッケージには「4K対応」とあちこちに印刷されてる。長さは1.5m。
コレを使って、HDMIセレクタ(HDMI切替器) GREEN HOUSE GH-HSWB3-BK の動作確認をしたい。先日動作確認した際は、Linuxのデスクトップ画面がノイズだらけになってしまって、HDMIケーブルがダメなのかなと気になったわけで…。
手持ちのHDMIケーブルは3つ。
接続した機器は以下。
結論を書くと、ダメだった。HDMIケーブルの組み合わせを色々変えてみたり、USB端子からHDMIセレクタの電源を取ってみたり、等々やってみたけど、ノイズは消えてくれないし、画面がそもそも映らなかったりで…。
どのHDMIケーブルも、ディスプレイと機器の間で、HDMIセレクタを介さずに直接繋げると、ちゃんとすんなり画面が映る。HDMIセレクタを通すとダメ。となると、HDMIケーブルには問題が無いと思われる。
コレも相性問題なのだろうか。それとも、HDMIセレクタが壊れているのだろうか。ググった感じでは、このHDMIセレクタ、数ヶ月でノイズが増えてきてそのまま壊れたという報告事例もチラホラ見かけるのだよな…。何をどうしたら正常動作しているのか、それとも壊れているのかが判別できるのだろう。
コレを使って、HDMIセレクタ(HDMI切替器) GREEN HOUSE GH-HSWB3-BK の動作確認をしたい。先日動作確認した際は、Linuxのデスクトップ画面がノイズだらけになってしまって、HDMIケーブルがダメなのかなと気になったわけで…。
手持ちのHDMIケーブルは3つ。
- 今回ダイソーで購入したHDMIケーブル。
- ELECOM製スリムタイプ HDMIケーブル。
- 弟から貰った謎のHDMIケーブル。
接続した機器は以下。
- 液晶ディスプレイ MITSUBISHI MDT243WG-SB
- Intel Core i5-2500機 (Ubuntu Linux 18.04 LTS)
- Raspberry Pi Zero W (Raspberry Pi OS, Debian系だったはず)
結論を書くと、ダメだった。HDMIケーブルの組み合わせを色々変えてみたり、USB端子からHDMIセレクタの電源を取ってみたり、等々やってみたけど、ノイズは消えてくれないし、画面がそもそも映らなかったりで…。
どのHDMIケーブルも、ディスプレイと機器の間で、HDMIセレクタを介さずに直接繋げると、ちゃんとすんなり画面が映る。HDMIセレクタを通すとダメ。となると、HDMIケーブルには問題が無いと思われる。
コレも相性問題なのだろうか。それとも、HDMIセレクタが壊れているのだろうか。ググった感じでは、このHDMIセレクタ、数ヶ月でノイズが増えてきてそのまま壊れたという報告事例もチラホラ見かけるのだよな…。何をどうしたら正常動作しているのか、それとも壊れているのかが判別できるのだろう。
[ ツッコむ ]
#2 [pc] 親父さんがプリンタを修理に出した
親父さんが使っているインクジェットプリンタ、Canon PIXUS PRO-100S が、「排紙トレイが閉じている」とエラーメッセージを出して印刷できない状態になっている問題について。
_「排紙トレイが閉じている」とエラーが出る - mieki256's diary
今日、親父さんが、ケーズデンキにプリンタを持ち込んで、メーカーに修理してもらうよう頼んできたらしい。
とりあえず、持っていく前に、自分も底面を眺めてセンサらしきものがないか調べてみたのだけど、残念ながらソレらしいものは見当たらず。一体どこにセンサがあるんだ…。
修理代は23,100円かかるらしい。修理料金が19,800円、配送が3,300円。プリンタの型番によって代金は違う。
_【インクジェットプリンター】 修理料金について
_「排紙トレイが閉じている」とエラーが出る - mieki256's diary
今日、親父さんが、ケーズデンキにプリンタを持ち込んで、メーカーに修理してもらうよう頼んできたらしい。
とりあえず、持っていく前に、自分も底面を眺めてセンサらしきものがないか調べてみたのだけど、残念ながらソレらしいものは見当たらず。一体どこにセンサがあるんだ…。
修理代は23,100円かかるらしい。修理料金が19,800円、配送が3,300円。プリンタの型番によって代金は違う。
_【インクジェットプリンター】 修理料金について
◎ 新しいプリンタを買ったほうが良さそうなのだけど :
価格.comで調べてみたら、A3ノビ印刷可能なCanon製プリンタとして、PIXUS iX6830、PIXUS iP8730 もあるようで。発売日は2014年。約10年前から売られている製品。お値段は、24,000 - 26,000円台。
PRO-100S の修理代を考えたら、新しいプリンタを買ってしまったほうがいいのでは…?
もっとも、PRO-100Sと比べてお安い分、当然スペックは違う。上記の2つは、インクが5色、6色らしい。PRO-100Sは8色だから、2〜3色分は我慢することになる。
もっとも、PRO-100S の印刷解像度は 4800 x 2400 dpi。上記の2つは 9600 x 2400 dpi。PRO-100Sより最小インク滴サイズとやらが小さいから、インク数が少ない分は解像度の高さでカバー、と捉えることもできそう。
大体にして、A3等で印刷して壁に飾ってある写真に、わざわざ顔を近づけて、「あー、インクジェットの粒々が見えちゃうなあ。コイツはダメだ」なんて言い出すヤツはまず居ない…。それに、親父さんは目が悪くなって、せっかくの一眼レフデジカメでピンボケ写真ばかり撮ってる状態。インクジェットプリンタの粒々なんて、もう視認できないし、そんなところを気にするぐらいなら、まず写真のピンボケを気にするべきで…。
そんなわけで、「新しいプリンタを買ったほうがいいのではないか」「どうせ PRO-100Sは色々くたびれてきてるから、この後もまた壊れて修理に出す羽目になるかもしれない」とアドバイスしてみたのだけど。「PRO-100S用のインクを買ったばかりだからもったいない」と言い出して…。
まあ、修理するにしても、新品を買うにしても、同程度の出費は必須なので、今回は修理に出すことにした模様。
A3で印刷しなければならない機会がどのくらいあるのかと考えると、無駄な出費のような気もするのだけど…。
PRO-100S の修理代を考えたら、新しいプリンタを買ってしまったほうがいいのでは…?
もっとも、PRO-100Sと比べてお安い分、当然スペックは違う。上記の2つは、インクが5色、6色らしい。PRO-100Sは8色だから、2〜3色分は我慢することになる。
もっとも、PRO-100S の印刷解像度は 4800 x 2400 dpi。上記の2つは 9600 x 2400 dpi。PRO-100Sより最小インク滴サイズとやらが小さいから、インク数が少ない分は解像度の高さでカバー、と捉えることもできそう。
大体にして、A3等で印刷して壁に飾ってある写真に、わざわざ顔を近づけて、「あー、インクジェットの粒々が見えちゃうなあ。コイツはダメだ」なんて言い出すヤツはまず居ない…。それに、親父さんは目が悪くなって、せっかくの一眼レフデジカメでピンボケ写真ばかり撮ってる状態。インクジェットプリンタの粒々なんて、もう視認できないし、そんなところを気にするぐらいなら、まず写真のピンボケを気にするべきで…。
そんなわけで、「新しいプリンタを買ったほうがいいのではないか」「どうせ PRO-100Sは色々くたびれてきてるから、この後もまた壊れて修理に出す羽目になるかもしれない」とアドバイスしてみたのだけど。「PRO-100S用のインクを買ったばかりだからもったいない」と言い出して…。
まあ、修理するにしても、新品を買うにしても、同程度の出費は必須なので、今回は修理に出すことにした模様。
A3で印刷しなければならない機会がどのくらいあるのかと考えると、無駄な出費のような気もするのだけど…。
◎ ドライバの作りで回避できそうな気もする :
ググったところ、Canon製プリンタにおいて「排紙トレイが閉じてますエラー」は結構な頻度で発生してしまう故障らしいけど、こんなに故障が多いなら、センサの検出結果を無視する機能をドライバにつけておいてもいいのではないかと思えてきた。
例えば、エラーメッセージダイアログに、「強制的に印刷を続ける」ボタンでも追加してあれば…。あるいは、レジストリを弄るとセンサ結果を無視して動くようになるとか…。
大体にして、これから印刷しようとしてるのに、排紙トレイを閉じているユーザのほうがおかしい。うっかり閉じていて、紙が中でグシャグシャになっても、それこそ自己責任だろう…。トイレに入って大をするなら、誰でもパンツを下ろすわけで、パンツを履いたまま大をして「どうしてくれる!」と怒り出すほうがおかしい。パンツを下ろしてないお前が悪い。
でもまあ、そういった、センサの検出結果を無視する機能をつけないことで、Canonさんは修理代金を貰えるわけだし。ただでさえプリンタ本体は赤字覚悟で販売してるのだから、少しでも別の何かで儲ける仕組みを作らないとアレだよな…。
いや、でも、この手の修理を引き受けるのも、それはそれで結構面倒臭くないのだろうか…。修理不要な状態に近づけていくことも、コスト削減の一環だったりしないか…。
例えば、エラーメッセージダイアログに、「強制的に印刷を続ける」ボタンでも追加してあれば…。あるいは、レジストリを弄るとセンサ結果を無視して動くようになるとか…。
大体にして、これから印刷しようとしてるのに、排紙トレイを閉じているユーザのほうがおかしい。うっかり閉じていて、紙が中でグシャグシャになっても、それこそ自己責任だろう…。トイレに入って大をするなら、誰でもパンツを下ろすわけで、パンツを履いたまま大をして「どうしてくれる!」と怒り出すほうがおかしい。パンツを下ろしてないお前が悪い。
でもまあ、そういった、センサの検出結果を無視する機能をつけないことで、Canonさんは修理代金を貰えるわけだし。ただでさえプリンタ本体は赤字覚悟で販売してるのだから、少しでも別の何かで儲ける仕組みを作らないとアレだよな…。
いや、でも、この手の修理を引き受けるのも、それはそれで結構面倒臭くないのだろうか…。修理不要な状態に近づけていくことも、コスト削減の一環だったりしないか…。
[ ツッコむ ]
2023/05/11(木) [n年前の日記]
#1 [linux] Linux MintとiPhoneをケーブル接続して画像を取り出したい
Linux Mint と iPhone をケーブル接続して iPhone からファイルを取り出したい、という相談を受けた。そんなこと、できるのだろうか…?
ググってみたら、フツーにできるっぽい。Linux、スゴイな…。そんなこともできるぐらいに整備されていたとは…。
_iphone→debianへ写真をUSB経由でコピーする - Super Action Shooting Game 4
_iPhone 7(iOS12)をUbuntu 19.10でmountしてデータコピー - matoken's meme
_#linux iPhoneが再接続できないときの対症療法 - Kotet's Personal Blog
_iOS - ArchWiki
_Ubuntu18.04からiPhone(iOS 10.2)にアクセスする - Qiita
_LinuxでiPhoneを接続して写真などを転送する方法 - Qiita
_LinuxMint でiPhoneのバックアップをする方法【画像、動画、音楽、書類など】 - meotoblog
せっかくだから、以下の環境で、iPhone 5 をケーブル接続して試してみた。
ググってみたら、フツーにできるっぽい。Linux、スゴイな…。そんなこともできるぐらいに整備されていたとは…。
_iphone→debianへ写真をUSB経由でコピーする - Super Action Shooting Game 4
_iPhone 7(iOS12)をUbuntu 19.10でmountしてデータコピー - matoken's meme
_#linux iPhoneが再接続できないときの対症療法 - Kotet's Personal Blog
_iOS - ArchWiki
_Ubuntu18.04からiPhone(iOS 10.2)にアクセスする - Qiita
_LinuxでiPhoneを接続して写真などを転送する方法 - Qiita
_LinuxMint でiPhoneのバックアップをする方法【画像、動画、音楽、書類など】 - meotoblog
せっかくだから、以下の環境で、iPhone 5 をケーブル接続して試してみた。
- VMware Player 17.0.2 build-21581411 + Linux Mint 21.1 "Vera" Cinnamon 64bit
- 実機(CPU: AMD A6-3500) + Linux Mint 21.1 "Vera" Cinnamon 64bit
◎ 事前準備 :
まず、必要なソフトウェアをインストールしないといけない。ifuse と libimobiledevice-utils が必要らしい。端末上で以下を打つ。
ただ、Linux Mint 21.1 の場合、どちらも最初からデフォルトで入っていた。このインストール作業をする必要は無さそう。
次に、USB機器関連サービス、usbmuxd.service とやらが動作してるのか確認。
「Active」のところで、「inactive (dead)」と出てきた。コレって動いてるの…? どうなの? 「dead」って出てるから死んでるんじゃないの?
よく分からないけど、とりあえず、該当サービスを再起動して、もう一度状態を確認。
「active (running)」と表示されてる。たぶん動いているんだろう…。ちなみに、そのままだとログの一部を表示して止まるので、qキーを叩いて抜ける。
とりあえず、このあたりの動作が不安定な時は、usbmuxd.service を再起動すると状況が変わるらしい。
sudo apt install ifuse libimobiledevice-utils
ただ、Linux Mint 21.1 の場合、どちらも最初からデフォルトで入っていた。このインストール作業をする必要は無さそう。
$ sudo apt list --installed | grep -e 'ifuse' -e 'imobile' ifuse/jammy,now 1.1.4~git20181007.3b00243-1 amd64 [インストール済み] libimobiledevice-utils/jammy,now 1.3.0-6build3 amd64 [インストール済み] libimobiledevice6/jammy,now 1.3.0-6build3 amd64 [インストール済み]
次に、USB機器関連サービス、usbmuxd.service とやらが動作してるのか確認。
sudo systemctl status usbmuxd.service
$ sudo systemctl status usbmuxd.service
○ usbmuxd.service - Socket daemon for the usbmux protocol used by Apple devices
Loaded: loaded (/lib/systemd/system/usbmuxd.service; static)
Active: inactive (dead)
Docs: man:usbmuxd(8)
「Active」のところで、「inactive (dead)」と出てきた。コレって動いてるの…? どうなの? 「dead」って出てるから死んでるんじゃないの?
よく分からないけど、とりあえず、該当サービスを再起動して、もう一度状態を確認。
sudo systemctl restart usbmuxd.service sudo systemctl status usbmuxd.service
$ sudo systemctl status usbmuxd.service
● usbmuxd.service - Socket daemon for the usbmux protocol used by Apple devices
Loaded: loaded (/lib/systemd/system/usbmuxd.service; static)
Active: active (running) since Thu 2023-05-11 19:54:32 JST; 2s ago
Docs: man:usbmuxd(8)
Main PID: 1853 (usbmuxd)
Tasks: 2 (limit: 4512)
Memory: 940.0K
CPU: 2ms
CGroup: /system.slice/usbmuxd.service
└─1853 /usr/sbin/usbmuxd --user usbmux --systemd
5月 11 19:54:32 linuxmintonvm systemd[1]: Started Socket daemon for the usbmux protocol used by Apple devices.
5月 11 19:54:33 linuxmintonvm usbmuxd[1853]: [19:54:33.023][3] usbmuxd v1.1.1 starting up
5月 11 19:54:33 linuxmintonvm usbmuxd[1853]: [19:54:33.023][3] Successfully dropped privileges to 'usbmux'
5月 11 19:54:33 linuxmintonvm usbmuxd[1853]: [19:54:33.023][3] Using libusb 1.0.25
5月 11 19:54:33 linuxmintonvm usbmuxd[1853]: [19:54:33.024][3] Initialization complete
5月 11 19:54:33 linuxmintonvm usbmuxd[1853]: [19:54:33.024][3] Enabled exit on SIGUSR1 if no devices are attac>
「active (running)」と表示されてる。たぶん動いているんだろう…。ちなみに、そのままだとログの一部を表示して止まるので、qキーを叩いて抜ける。
とりあえず、このあたりの動作が不安定な時は、usbmuxd.service を再起動すると状況が変わるらしい。
◎ 接続してみる :
iPhone 5 と Linux Mint を、ケーブルで接続してみる。
Linux Mint のデスクトップ画面に、「〜がロックされてる」的なメッセージが表示された。「再試行」をクリックすればいいのだけど、その前に、iPhone の画面上に「接続を許可するか?」「このコンピュータを信頼するか?」的なポップアップが表示されているはずなので、「許可」や「信頼」をタップ。
ちなみに、このポップアップ、一定時間が経過すると、「ずっと放置されるってことは、この相手は信頼できないってことですかね?」的に、自動で不許可/ブロック扱いにしてくれる模様。だから、iPhone の画面をちゃんと監視して、ポップアップが出たら即座に対応しないといけない。
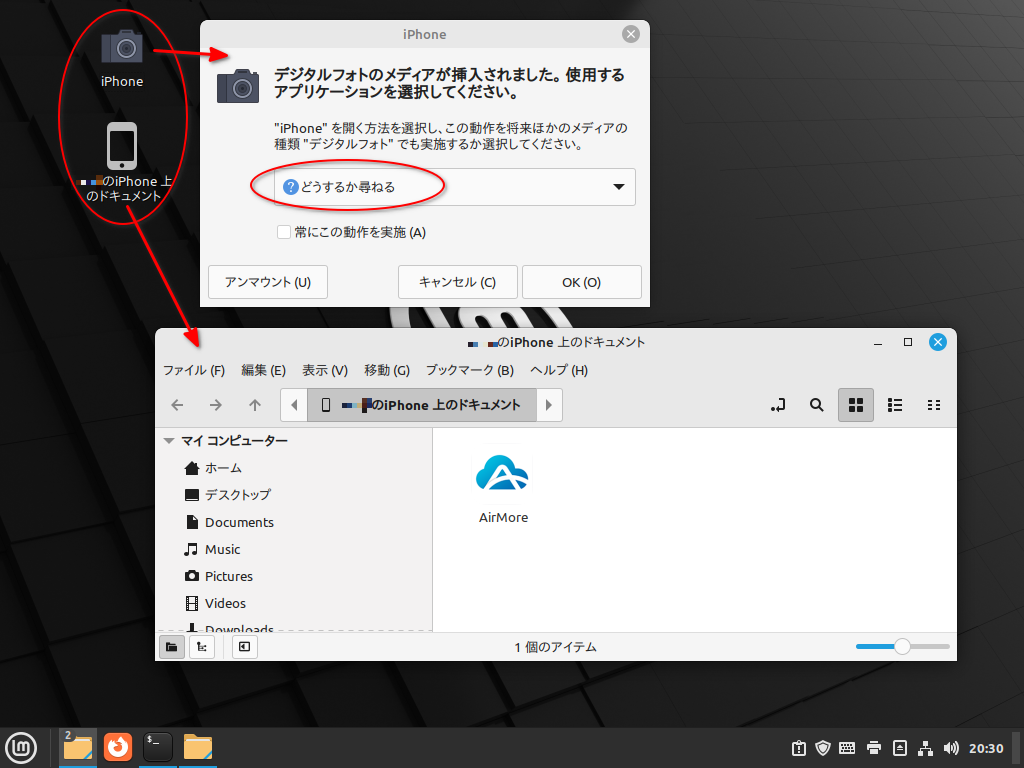
Linux Mint のデスクトップに、スマホっぽい形のアイコンが1つ表示された。ただ、この状態では正常に繋がってないっぽい。
iPhone からケーブルを外して、再度ケーブルを差し込んで接続。
Linux Mint のデスクトップ画面に、スマホっぽい形のアイコンと、カメラっぽいアイコン(iPhoneと書いてある)が表示された。この状態が正常らしい。同時に、ファイルマネージャのウインドウが一つ、画像フォルダの扱いをどうするか尋ねてくるウインドウが一つ、自動で表示された。
画像フォルダをどう扱うか尋ねてきたウインドウに対して、「フォルダーを開く」を選択して「OK」をクリックすると…。
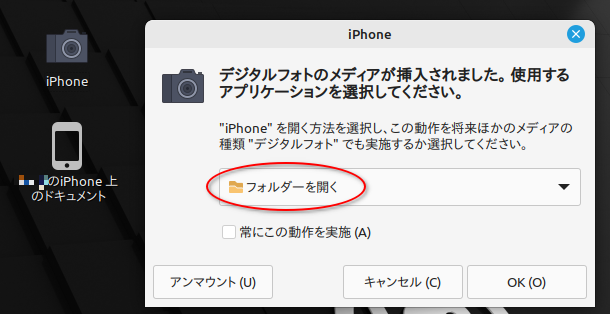
「画像が入っている『DCIM』というフォルダがあるよ」的なウインドウが開く。「DCIM」は、「Digital Camera IMage」の略なんだろうか?
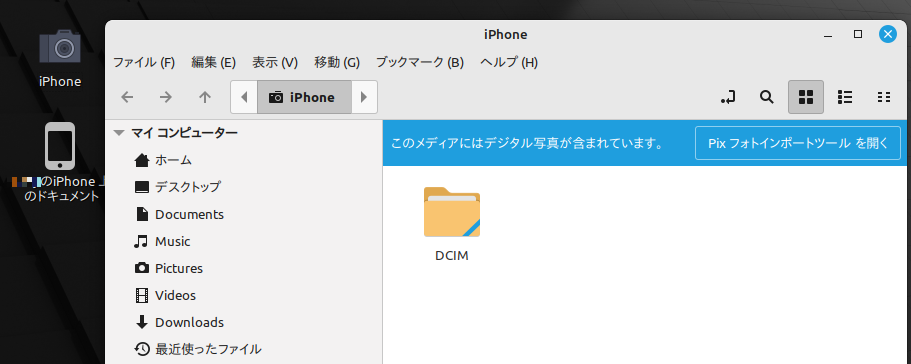
DCIMをダブルクリックして中に入ると、100APPLE というフォルダがあって、更にその中に入ると、iPhoneで撮影した画像ファイルの一覧が表示される。
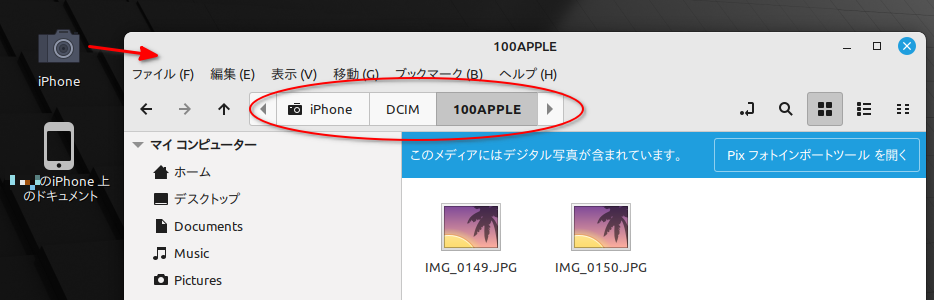
「Pix フォトインポートツールを開く」というボタンが気になる…。クリックしてみた。
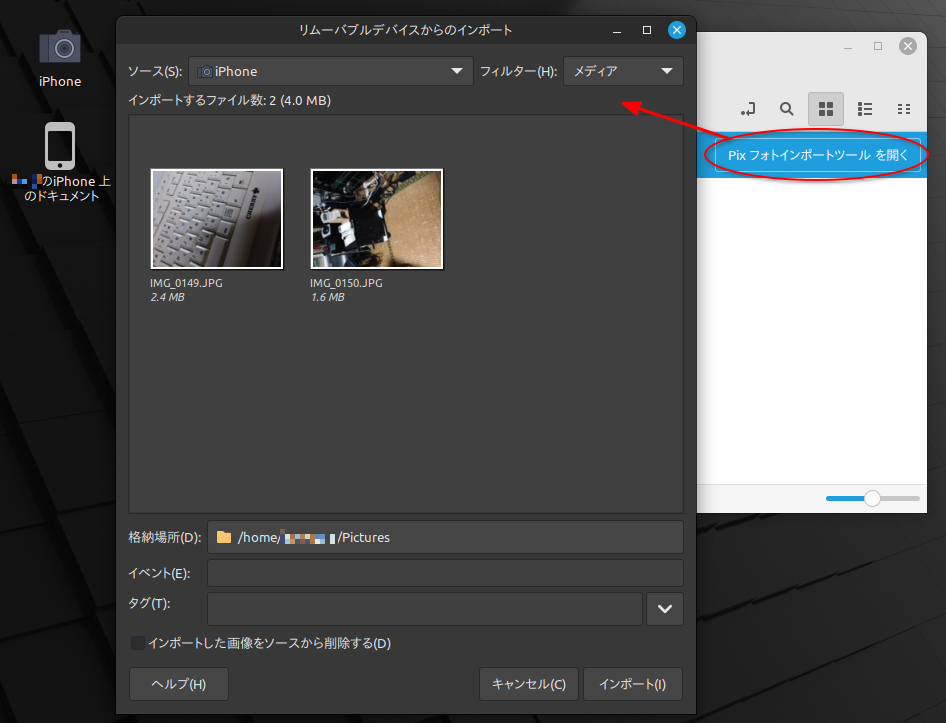
画像ファイルをインポートできる専用ツールが起動してくれた。これを使って、iPhone の中の画像ファイルを、Linux Mint側の任意のフォルダにインポートできるらしい。Linux Mint、至れり尽くせりだな…。
Linux Mint のデスクトップ画面に、「〜がロックされてる」的なメッセージが表示された。「再試行」をクリックすればいいのだけど、その前に、iPhone の画面上に「接続を許可するか?」「このコンピュータを信頼するか?」的なポップアップが表示されているはずなので、「許可」や「信頼」をタップ。
ちなみに、このポップアップ、一定時間が経過すると、「ずっと放置されるってことは、この相手は信頼できないってことですかね?」的に、自動で不許可/ブロック扱いにしてくれる模様。だから、iPhone の画面をちゃんと監視して、ポップアップが出たら即座に対応しないといけない。
Linux Mint のデスクトップに、スマホっぽい形のアイコンが1つ表示された。ただ、この状態では正常に繋がってないっぽい。
iPhone からケーブルを外して、再度ケーブルを差し込んで接続。
Linux Mint のデスクトップ画面に、スマホっぽい形のアイコンと、カメラっぽいアイコン(iPhoneと書いてある)が表示された。この状態が正常らしい。同時に、ファイルマネージャのウインドウが一つ、画像フォルダの扱いをどうするか尋ねてくるウインドウが一つ、自動で表示された。
画像フォルダをどう扱うか尋ねてきたウインドウに対して、「フォルダーを開く」を選択して「OK」をクリックすると…。
「画像が入っている『DCIM』というフォルダがあるよ」的なウインドウが開く。「DCIM」は、「Digital Camera IMage」の略なんだろうか?
DCIMをダブルクリックして中に入ると、100APPLE というフォルダがあって、更にその中に入ると、iPhoneで撮影した画像ファイルの一覧が表示される。
「Pix フォトインポートツールを開く」というボタンが気になる…。クリックしてみた。
画像ファイルをインポートできる専用ツールが起動してくれた。これを使って、iPhone の中の画像ファイルを、Linux Mint側の任意のフォルダにインポートできるらしい。Linux Mint、至れり尽くせりだな…。
◎ 切断してみる :
画面の右下のタスクトレイ(?)に、「リムーバブルドライブ」のアイコンが増えている。
クリックすると、「iPhone」と「xxxxのiPhone上のドキュメント」の2つがリスト表示される。右側の、上向きの三角をクリックすれば、それぞれアンマウントすることができる。まあ、iPhoneからケーブルを抜いちゃったほうが早い気もするけど…。
そんなわけで、Linu Mint に iPhone 5 をケーブル接続して、中の画像ファイルを取り出すことができそうだと分かった。
クリックすると、「iPhone」と「xxxxのiPhone上のドキュメント」の2つがリスト表示される。右側の、上向きの三角をクリックすれば、それぞれアンマウントすることができる。まあ、iPhoneからケーブルを抜いちゃったほうが早い気もするけど…。
そんなわけで、Linu Mint に iPhone 5 をケーブル接続して、中の画像ファイルを取り出すことができそうだと分かった。
◎ 問題点 :
どうも一発で認識してくれない時がある…。そんな時は…。
ちゃんと接続できるかどうか、成功率は半々な印象。
- iPhone側でケーブルを何度か抜き差ししてみる。
- ケーブルを外した状態で、sudo systemctl restart usbmuxd.service を実行して usbmuxd.service を再起動してから試してみる。
ちゃんと接続できるかどうか、成功率は半々な印象。
◎ 他の方法 :
ケーブル接続を使わなくても、iPhone の中のファイルを取り出すことはできる。例えば自分は AirMore というアプリを iPhone 5 にインストールして使ってる。
この AirMore を起動すると、PC側のWebブラウザから iPhone にアクセスして、画像ファイルその他を取り出せる。
_「AirMore - PCに接続」をApp Storeで
Apowersoft Limited という会社(?)が作ってる点に注意。Apple Store で「airmore」で検索すると、別作者の別アプリがリストアップされる…。怪しい…。
また、本来はPC側Webブラウザで、 _http://web.airmore.com/ にアクセスするとQRコードが表示され、それをiPhoneでスキャンすれば利用できるはずが…。ここ最近、QRコードが表示されない状態で…。その際は、iPhone側右上の「…」をタップしてIPアドレスを確認後、PC側Webブラウザのアドレスバーに直接打ち込めばいいらしい。
_AirMoreに繋がらない→IPアドレスで接続する方法 | TeraDas
ちなみに、Windows10 + Firefox/GoogleChrome の他に、Linux Mint + Firefox でもiPhoneにアクセスできることを確認できた。今時のWebブラウザさえ動けば、PC側のOS種類を問わない点はメリットかなと。
この AirMore を起動すると、PC側のWebブラウザから iPhone にアクセスして、画像ファイルその他を取り出せる。
_「AirMore - PCに接続」をApp Storeで
Apowersoft Limited という会社(?)が作ってる点に注意。Apple Store で「airmore」で検索すると、別作者の別アプリがリストアップされる…。怪しい…。
また、本来はPC側Webブラウザで、 _http://web.airmore.com/ にアクセスするとQRコードが表示され、それをiPhoneでスキャンすれば利用できるはずが…。ここ最近、QRコードが表示されない状態で…。その際は、iPhone側右上の「…」をタップしてIPアドレスを確認後、PC側Webブラウザのアドレスバーに直接打ち込めばいいらしい。
_AirMoreに繋がらない→IPアドレスで接続する方法 | TeraDas
ちなみに、Windows10 + Firefox/GoogleChrome の他に、Linux Mint + Firefox でもiPhoneにアクセスできることを確認できた。今時のWebブラウザさえ動けば、PC側のOS種類を問わない点はメリットかなと。
[ ツッコむ ]
2023/05/12(金) [n年前の日記]
#1 [cg_tools] 画像生成AIで漫画画像を実写っぽくしたかったけど難しそう
画像生成AI、Stable Diffusion web UIを使って実験中。白黒で描かれた漫画っぽい画像の1コマを入力して実写っぽい画像を出力できたりしないものかな、と…。
ちょっと作業した感じでは、いくつか問題点がありそうだなと思えてきた。
問題その1。吹き出しや擬音をどうするか問題。
イラストならともかく、漫画の場合は吹き出しや擬音が描き込まれているので、漫画の1コマをそのまま画像生成AIに入力、と言うわけにはいかないよなと。AIは、ここが吹き出し、ここは擬音、などと判別できないのだろうから、そのあたりを奇麗に除去した画像を渡してやらないといかん気がする。
ということで、既存の画像編集ツールを起動して、吹き出しや擬音を消して、それらの後ろにあったのかもしれない何かしらを描き加えていく、という作業が発生してしまって…。これでは全然お手軽ではないよなあ、と…。
問題その2。線には色んな種類がある問題。
自分達は、線と言うと、形状の輪郭線を表現するために描かれた線ばかりを想像してしまうけど。漫画の場合、それ以外の線も多数描き込まれているわけで…。
漫画と言うメディアの表現力を増すために、漫画家さんが創意工夫で考案して、せっせと描き込まれた様々な種類の線が、AIに処理させる際には単に盛大なノイズになってしまうこの状況は、なんだか興味深いものがあるなと…。先人達の発明品を特に使ってない、漫画としてはダメダメな漫画絵ほど、AIにとっては処理しやすいかもしれない、という…。
問題その3。各コマの縦横比問題。
現状の画像生成AIは、512x512、1:1という縦横比で画像を学習してるわけだけど。漫画の各コマは、縦横比がバラエティに富んでいるわけで…。1:1にする際に、足りない部分はどうするか、という問題が…。
そんなわけで、少し試してみただけでも、白黒漫画をサクッと実写風に、というのは結構面倒臭い作業が発生するなと思えてきた。漫画という表現の、技の豊かさを再認識したというか…。似たようなものとして扱われがちだけど、只のイラストとは全然違うのですよ。みたいな。
それにしても、何でもそうだけど実際に手を動かして試してみると、そこでようやく色々な問題が見えてくるものなんだなと思ったりもして…。「そんなのAI任せでワンクリック」なんてまだまだ遠いなと。
ちょっと作業した感じでは、いくつか問題点がありそうだなと思えてきた。
問題その1。吹き出しや擬音をどうするか問題。
イラストならともかく、漫画の場合は吹き出しや擬音が描き込まれているので、漫画の1コマをそのまま画像生成AIに入力、と言うわけにはいかないよなと。AIは、ここが吹き出し、ここは擬音、などと判別できないのだろうから、そのあたりを奇麗に除去した画像を渡してやらないといかん気がする。
ということで、既存の画像編集ツールを起動して、吹き出しや擬音を消して、それらの後ろにあったのかもしれない何かしらを描き加えていく、という作業が発生してしまって…。これでは全然お手軽ではないよなあ、と…。
問題その2。線には色んな種類がある問題。
自分達は、線と言うと、形状の輪郭線を表現するために描かれた線ばかりを想像してしまうけど。漫画の場合、それ以外の線も多数描き込まれているわけで…。
- 陰影や色の違いを表現するためのハッチングの線。
- 汗だの動作だのを表現する漫符的な線。
漫画と言うメディアの表現力を増すために、漫画家さんが創意工夫で考案して、せっせと描き込まれた様々な種類の線が、AIに処理させる際には単に盛大なノイズになってしまうこの状況は、なんだか興味深いものがあるなと…。先人達の発明品を特に使ってない、漫画としてはダメダメな漫画絵ほど、AIにとっては処理しやすいかもしれない、という…。
問題その3。各コマの縦横比問題。
現状の画像生成AIは、512x512、1:1という縦横比で画像を学習してるわけだけど。漫画の各コマは、縦横比がバラエティに富んでいるわけで…。1:1にする際に、足りない部分はどうするか、という問題が…。
そんなわけで、少し試してみただけでも、白黒漫画をサクッと実写風に、というのは結構面倒臭い作業が発生するなと思えてきた。漫画という表現の、技の豊かさを再認識したというか…。似たようなものとして扱われがちだけど、只のイラストとは全然違うのですよ。みたいな。
それにしても、何でもそうだけど実際に手を動かして試してみると、そこでようやく色々な問題が見えてくるものなんだなと思ったりもして…。「そんなのAI任せでワンクリック」なんてまだまだ遠いなと。
[ ツッコむ ]
2023/05/13(土) [n年前の日記]
#1 [cg_tools] 画像生成AIを触ってる
画像生成AI Stable Diffusion web UI で、白黒漫画を実写画像っぽくできないものかなと実験中。
キャラが床に寝転がってる系の画像を入力すると、とんでもない結果が出てくるなと…。それはまあ、当然のような気もする。巷で公開されてる実写画像/写真の類は、頭が上、足が下になっているものが大多数なので…。頭が下、足が上になっている画像を渡してみても、学習データの中にそんな構図の画像は無いから、それでも無理矢理画像を作ろうとして、ホラー画像が生成されてしまうのだろう…。
ならばと、入力画像を180度回転して、天地が逆になっている状態にして渡してみたのだけど、これまたとんでもない画像が生成された。おそらくは人物のポーズがよくあるポーズではなくて、漫画らしい特殊なポーズだから、ホラー画像になってしまうのだろう…。
結局のところ、AIは、学習してない構図やポーズは出力できませんよ、ということだろうなと。人間のように、「3次元的にはこういう物体がそこに存在しているのだろうから、ソレをこっちから見たらおそらくこんな形で見えるはずだよね」みたいな類推は、まだほとんどできないのだろう。
となると、人間の絵描きさんがAIに勝つための道も、なんだかうっすら見えてくる。AIが苦手な構図、苦手なポーズは、まだまだたくさんあるはずで。こういう構図、こういうポーズは、やっぱり人間じゃないと描けないよなあ、などと感心される場面は絶対にあるよなと。
キャラが床に寝転がってる系の画像を入力すると、とんでもない結果が出てくるなと…。それはまあ、当然のような気もする。巷で公開されてる実写画像/写真の類は、頭が上、足が下になっているものが大多数なので…。頭が下、足が上になっている画像を渡してみても、学習データの中にそんな構図の画像は無いから、それでも無理矢理画像を作ろうとして、ホラー画像が生成されてしまうのだろう…。
ならばと、入力画像を180度回転して、天地が逆になっている状態にして渡してみたのだけど、これまたとんでもない画像が生成された。おそらくは人物のポーズがよくあるポーズではなくて、漫画らしい特殊なポーズだから、ホラー画像になってしまうのだろう…。
結局のところ、AIは、学習してない構図やポーズは出力できませんよ、ということだろうなと。人間のように、「3次元的にはこういう物体がそこに存在しているのだろうから、ソレをこっちから見たらおそらくこんな形で見えるはずだよね」みたいな類推は、まだほとんどできないのだろう。
となると、人間の絵描きさんがAIに勝つための道も、なんだかうっすら見えてくる。AIが苦手な構図、苦手なポーズは、まだまだたくさんあるはずで。こういう構図、こういうポーズは、やっぱり人間じゃないと描けないよなあ、などと感心される場面は絶対にあるよなと。
[ ツッコむ ]
2023/05/14(日) [n年前の日記]
#1 [cg_tools] ControlNet+OpenPoseでちょっとハマった
画像生成AI Stable Diffusion web UI 上で、天地が逆になってるポーズの指定って本当にできないのかなと気になって、そのあたりを試してた。
OpenPose を使えば、棒人間? 棒人形? 相当を使ってポーズを指定できるはずなので…。Openpose Editor という拡張機能を使って、ポーズを作って、ControlNet に転送して、ということをやっていたのだけど…。生成画像にポーズが全く反映されなくて悩んでしまった。ControlNetを最新版にアップデート等々、アレコレやってみたけど改善されず。
何のことはない。ControlNet のプリプロセッサで、OpenPose関係を選んで指定するという、トホホなミスをしていた…。
プリプロセッサの OpenPose 云々は、写真やイラストから、OpenPose を抽出するために指定するものであって…。この場合、既に自分でOpenPose画像を用意しているのだから、プリプロセッサは「None」にして、モデルデータだけ OpenPose を選ばないといけなかった。
そんなわけで、OpenPose で指定したポーズが反映される状態にはなったのだけど…。予想通り、天地が逆になったポーズは、見た瞬間悲鳴を挙げたくなるような、とんでもない画像を生成してしまう…。そういったポーズの学習データが皆無なんだろう…。そりゃまあ、そうだよな。そんな奇天烈な構図/ポーズでわざわざ写真を撮る人なんて居るわけないし。写真がほぼ存在しないのだから、学習するはずもない。
学習していないものをAIは出せない、と再認識。
OpenPose を使えば、棒人間? 棒人形? 相当を使ってポーズを指定できるはずなので…。Openpose Editor という拡張機能を使って、ポーズを作って、ControlNet に転送して、ということをやっていたのだけど…。生成画像にポーズが全く反映されなくて悩んでしまった。ControlNetを最新版にアップデート等々、アレコレやってみたけど改善されず。
何のことはない。ControlNet のプリプロセッサで、OpenPose関係を選んで指定するという、トホホなミスをしていた…。
プリプロセッサの OpenPose 云々は、写真やイラストから、OpenPose を抽出するために指定するものであって…。この場合、既に自分でOpenPose画像を用意しているのだから、プリプロセッサは「None」にして、モデルデータだけ OpenPose を選ばないといけなかった。
そんなわけで、OpenPose で指定したポーズが反映される状態にはなったのだけど…。予想通り、天地が逆になったポーズは、見た瞬間悲鳴を挙げたくなるような、とんでもない画像を生成してしまう…。そういったポーズの学習データが皆無なんだろう…。そりゃまあ、そうだよな。そんな奇天烈な構図/ポーズでわざわざ写真を撮る人なんて居るわけないし。写真がほぼ存在しないのだから、学習するはずもない。
学習していないものをAIは出せない、と再認識。
[ ツッコむ ]
#2 [anime] 「劇場版 マジンガーZ / INFINITY」を視聴
BS12で放送されていたので視聴。ロボットアニメの名作、マジンガーZを、CGでリメイクしたアニメ映画。キャラは手描きで、マジンガーZ等の巨大ロボットを、おそらくはセルルックに近いCGで描写してる。
*1
今の時代に合わせて設定を作り込んでいる印象を受けた。それら設定の説明シーンが結構長くてちょっとアレだったけど、そういったお膳立て/下準備 が終わったら、いよいよ血沸き肉躍る戦闘シーンに突入、そしてそのままラストに、という構成なので、見た人の満足度は高かったのではないかなと想像できた。
CGで描かれたマジンガーZの映像はなかなかイイ感じ。この線密度を手描きで動かそうとしたら、手描きアニメーターさん達が次々と病院送りになるだろうなと…。CG万歳。
ただ、この手のCGによる戦闘シーンのあるあるだけど、何をやってるかさっぱり分らないカットも多々…。ギュンギュン動かして派手にはなるのだけど…。大まかな流れは止めず、しかし、「コイツラ、ここでこういうことやってますよ」と、その都度伝える演出上の手管が必要になると思うのだけど、そこらへんは今一つな印象を受けた。
プールの底が開いて発進するシーンや、ジェットスクランダーが発進するシーンは、もうちょっと何か付け加えてほしかった気もする。いやまあ、あえてオリジナル版の流れを踏襲して見せてるのだろうとは想像したのだけど、今の感覚でコンテを切ったら、もっと細かい、リアリティを感じさせる描写も多々入れられるよなと。もっとも、どこを変えるか、どこを変えないかの判断は難しいだろうし…。
光子力云々の設定は、聞いててなんだかもやもやした。もしかして、原子力を比喩していたつもりなんだろうか…。2017年〜2018年に公開されていた作品らしいので、東日本大震災のソレは取り入れた設定/脚本ではあるのだろうなと。ただ、ググってみたら、企画自体は2008年頃から始まっているとのことで…。途中で路線変更等があったのか、それとも元々こういう設定だったのか…。
何にせよ、CGのマジンガーZがガンガン動くだけで、個人的には満足。こんな映像を作れる時代になったんじゃのう…。眼福眼福。みたいな。
今の時代に合わせて設定を作り込んでいる印象を受けた。それら設定の説明シーンが結構長くてちょっとアレだったけど、そういったお膳立て/下準備 が終わったら、いよいよ血沸き肉躍る戦闘シーンに突入、そしてそのままラストに、という構成なので、見た人の満足度は高かったのではないかなと想像できた。
CGで描かれたマジンガーZの映像はなかなかイイ感じ。この線密度を手描きで動かそうとしたら、手描きアニメーターさん達が次々と病院送りになるだろうなと…。CG万歳。
ただ、この手のCGによる戦闘シーンのあるあるだけど、何をやってるかさっぱり分らないカットも多々…。ギュンギュン動かして派手にはなるのだけど…。大まかな流れは止めず、しかし、「コイツラ、ここでこういうことやってますよ」と、その都度伝える演出上の手管が必要になると思うのだけど、そこらへんは今一つな印象を受けた。
プールの底が開いて発進するシーンや、ジェットスクランダーが発進するシーンは、もうちょっと何か付け加えてほしかった気もする。いやまあ、あえてオリジナル版の流れを踏襲して見せてるのだろうとは想像したのだけど、今の感覚でコンテを切ったら、もっと細かい、リアリティを感じさせる描写も多々入れられるよなと。もっとも、どこを変えるか、どこを変えないかの判断は難しいだろうし…。
光子力云々の設定は、聞いててなんだかもやもやした。もしかして、原子力を比喩していたつもりなんだろうか…。2017年〜2018年に公開されていた作品らしいので、東日本大震災のソレは取り入れた設定/脚本ではあるのだろうなと。ただ、ググってみたら、企画自体は2008年頃から始まっているとのことで…。途中で路線変更等があったのか、それとも元々こういう設定だったのか…。
何にせよ、CGのマジンガーZがガンガン動くだけで、個人的には満足。こんな映像を作れる時代になったんじゃのう…。眼福眼福。みたいな。
*1: 完全なセルルックではなくて、光沢等をグラデーションで反映させてるスタイルに見えたけど…。ただ、輪郭線はあるので、一見するとセルルックに近い印象を受けた。
[ ツッコむ ]
2023/05/15(月) [n年前の日記]
#1 [cg_tools] OpenPoseについて少し調べてた
画像生成AI Stable Diffusion web UIでは、ControlNetという拡張機能とOpenPose画像を使うと、任意のポーズを指定できるけど、その OpenPose の各点が何と対応しているのか分からなくて少し調べてた。
以下のページが参考になった。
_ヨガポーズのクラス分類 - なるように、なる
_機械の目が見たセカイ -コンピュータビジョンがつくるミライ(47) 人物の姿勢推定(1)- OpenPose | TECH+ (テックプラス)
_OpenPose はどこまでの画像に耐えられるのか Pose Estimation の紹介 - Qiita
_Learn "Openpose" from scratch with MobileNetv2 + MS-COCO and deploy it to OpenVINO/TensorflowLite (Inference by OpenVINO/NCS2) Part.2 - Qiita
肩や首の点はなんとなく分かったけど、顔の点が分からなかったわけで…。鼻が1つ、目が2つ、耳が2つ、だったのだな…。ただ、それぞれ、鼻や目の中央を示しているのか、それとも各パーツの上端や先端なのか、そのあたりがまだ分からない。
以下のページが参考になった。
_ヨガポーズのクラス分類 - なるように、なる
_機械の目が見たセカイ -コンピュータビジョンがつくるミライ(47) 人物の姿勢推定(1)- OpenPose | TECH+ (テックプラス)
_OpenPose はどこまでの画像に耐えられるのか Pose Estimation の紹介 - Qiita
_Learn "Openpose" from scratch with MobileNetv2 + MS-COCO and deploy it to OpenVINO/TensorflowLite (Inference by OpenVINO/NCS2) Part.2 - Qiita
肩や首の点はなんとなく分かったけど、顔の点が分からなかったわけで…。鼻が1つ、目が2つ、耳が2つ、だったのだな…。ただ、それぞれ、鼻や目の中央を示しているのか、それとも各パーツの上端や先端なのか、そのあたりがまだ分からない。
[ ツッコむ ]
2023/05/16(火) [n年前の日記]
#1 [cg_tools] 学習モデルデータの特徴を調べ直してた
画像生成AI Stable Diffusion web UIの学習モデルデータについて、それぞれ特徴を調べ直してた。ググってるうちに目に入って良さそうだなと思ったら即ダウンロードしてたけど、どのデータがどういう属性なのか忘れてしまって…。アニメ系なのか実写系なのかすら忘れてしまったりして…。
ファイル名を頼りに、以下のページを参考にしつつ、Evernote に種類を書き込んでおいた、とメモ。
_リアル系モデル比較・雑感 - NovelAI 5ch Wiki
_モデルについて - としあきdiffusion Wiki*
_【Stable Diffusion】イラスト生成AIのモデル一覧。どれがお好み?
_【2023年版】Stable Diffusion モデルまとめ | BLOG CAKE
_StableDiffusionのおすすめ最新モデルを紹介 | アニメ調イラストのクオリティを劇的に向上させるカスタムモデル | Murasan Lab
_【Stable Diffusion】美少女イラスト生成におすすめのモデルデータまとめ30選+α【実写(フォトリアル) 2.5D アニメイラスト】 | 悠々ログ
_StableDiffusion実写リアル系モデルおすすめ12選|川瀬ゆうえんち
_StableDiffushionモデル25種類×5枚ずつで比較メモ|川瀬ゆうえんち
_AOM3系のモデル比較 - 動かざることバグの如し
_画像生成ai【Stable Diffusion web ui】 モデルまとめ - BLOGWORK by Wis-Labo
_#StableDiffusion で 実写風女性画像生成に適したモデル3選 と モデルのマージ #ControlNet による姿勢の指定に便利な openpose-editor | Digital Life Innovator
_AIグラビア画像 違う顔 の作り方Stable Diffusion - ぶいろぐ
ファイル名を頼りに、以下のページを参考にしつつ、Evernote に種類を書き込んでおいた、とメモ。
_リアル系モデル比較・雑感 - NovelAI 5ch Wiki
_モデルについて - としあきdiffusion Wiki*
_【Stable Diffusion】イラスト生成AIのモデル一覧。どれがお好み?
_【2023年版】Stable Diffusion モデルまとめ | BLOG CAKE
_StableDiffusionのおすすめ最新モデルを紹介 | アニメ調イラストのクオリティを劇的に向上させるカスタムモデル | Murasan Lab
_【Stable Diffusion】美少女イラスト生成におすすめのモデルデータまとめ30選+α【実写(フォトリアル) 2.5D アニメイラスト】 | 悠々ログ
_StableDiffusion実写リアル系モデルおすすめ12選|川瀬ゆうえんち
_StableDiffushionモデル25種類×5枚ずつで比較メモ|川瀬ゆうえんち
_AOM3系のモデル比較 - 動かざることバグの如し
_画像生成ai【Stable Diffusion web ui】 モデルまとめ - BLOGWORK by Wis-Labo
_#StableDiffusion で 実写風女性画像生成に適したモデル3選 と モデルのマージ #ControlNet による姿勢の指定に便利な openpose-editor | Digital Life Innovator
_AIグラビア画像 違う顔 の作り方Stable Diffusion - ぶいろぐ
[ ツッコむ ]
#2 [nitijyou] 親父さんのスマホに地図アプリをインストールしておいた
親父さんが喜多方のほうまで写真撮影に行っていたらしいのだけど、カーナビの示す道が現状と合ってなくて、道に迷って困った、と愚痴っていたので、親父さんのAndroidスマホに Google Map と Yahoo! Map をインストールして、最低限の使い方を説明しておいた、とメモ。親父さんの車のカーナビよりは、スマホアプリのほうが、まだ多少は新しい地図データを見れるんじゃないのかなと…。目的地の入力も、スマホなら音声入力が使えるから多少は楽だろうし。
もっとも、親父さんのことだから、それらアプリをインストールしたことを、3日後にはすっかり忘れてそうな気もする…。というか、自分もそのうち忘れそう。一応こうしてメモしておくことで、自分の記憶に多少は残ってくれることを期待…。
もっとも、親父さんのことだから、それらアプリをインストールしたことを、3日後にはすっかり忘れてそうな気もする…。というか、自分もそのうち忘れそう。一応こうしてメモしておくことで、自分の記憶に多少は残ってくれることを期待…。
[ ツッコむ ]
2023/05/17(水) [n年前の日記]
#1 [cg_tools][blender] blenderでOpenPoseのアニメーションを作ってみたい
無料で利用できる3DCGソフト、blender を使って、OpenPose のアニメーションを作成できないものかなと思いついた。そういうことができれば、画像生成AIに、その OpenPose動画を渡して、動画を生成できるんじゃないのかなと。
ググってみたら、挑戦してる方々が居るらしい。
_ControlNetで使うカラフル棒人間を簡単に作れる Blenderアドオン 導入&使用方法紹介 - 7mm blog
_Blender+ControlNetを用いたアニメーションの作り方
_Blenderで好きなポーズつけてControlNetで出力させる|rockreef|pixivFANBOX
_toyxyz - ControlNet M2M Brief Workflow ... / Twitter
_Stable Diffusion WebUIのControlNetのm2mでショート動画を作ってみた | 鷹の目週末プログラマー
自分も少し試してみたい。環境は、Windows10 x64 22H2。CPU は AMD Ryzen 5 5600X。GPU は NVIDIA GeForce GTX 1060 6GB。
ググってみたら、挑戦してる方々が居るらしい。
_ControlNetで使うカラフル棒人間を簡単に作れる Blenderアドオン 導入&使用方法紹介 - 7mm blog
_Blender+ControlNetを用いたアニメーションの作り方
_Blenderで好きなポーズつけてControlNetで出力させる|rockreef|pixivFANBOX
_toyxyz - ControlNet M2M Brief Workflow ... / Twitter
_Stable Diffusion WebUIのControlNetのm2mでショート動画を作ってみた | 鷹の目週末プログラマー
自分も少し試してみたい。環境は、Windows10 x64 22H2。CPU は AMD Ryzen 5 5600X。GPU は NVIDIA GeForce GTX 1060 6GB。
◎ モデルデータとアドオンを入手 :
以下のページから、こういった作業をするためのモデルデータとアドオンを入手できる模様。入手にはメールアドレスの入力が必要。
_Character bones that look like Openpose for blender _ Ver_9 Depth+Canny+Landmark+MediaPipeFace+finger
0を入力すれば無料でDLできるけど、支援したい方は好きな代金を入力して寄付してほしい、とのこと。
ダウンロードページには、過去バージョンから現行バージョンまで並んでいたけれど、今回は現行バージョンらしい OpenPoseBones_v9.zip というファイルをDLしてみた。
ちなみに、「Blender 3.5 以上じゃないと動かないよ」と書かれていたので…。blender 3.5.1 x64 (blender-3.5.1-windows-x64.zip) を入手して、任意のフォルダに解凍して、blender.exe を実行して、動かせるようにしておいた。できれば blender LTS版で動くバージョンが欲しかった…。自分、手元の環境に、LTS版しかインストールしてなかったので…。
OpenPoseBones_v9.zip を解凍すると、中には2つのファイルが入っている。
blender 3.5.1 x64 を起動して、設定画面を開いて、rig_tools_3.68.12.zip をアドオンとしてインストール。
その後、Openpose_bones_ver_09.blend を開くと、ザ・OpenPose って感じのモデルデータが現れる。
これを別名保存して、作業をしていく。
_Character bones that look like Openpose for blender _ Ver_9 Depth+Canny+Landmark+MediaPipeFace+finger
0を入力すれば無料でDLできるけど、支援したい方は好きな代金を入力して寄付してほしい、とのこと。
ダウンロードページには、過去バージョンから現行バージョンまで並んでいたけれど、今回は現行バージョンらしい OpenPoseBones_v9.zip というファイルをDLしてみた。
ちなみに、「Blender 3.5 以上じゃないと動かないよ」と書かれていたので…。blender 3.5.1 x64 (blender-3.5.1-windows-x64.zip) を入手して、任意のフォルダに解凍して、blender.exe を実行して、動かせるようにしておいた。できれば blender LTS版で動くバージョンが欲しかった…。自分、手元の環境に、LTS版しかインストールしてなかったので…。
OpenPoseBones_v9.zip を解凍すると、中には2つのファイルが入っている。
- Openpose_bones_ver_09.blend : OpenPoseの見た目を再現してるモデルデータ。
- rig_tools_3.68.12.zip : OpenPoseモデルデータをリグで動かすためのアドオン。
blender 3.5.1 x64 を起動して、設定画面を開いて、rig_tools_3.68.12.zip をアドオンとしてインストール。
その後、Openpose_bones_ver_09.blend を開くと、ザ・OpenPose って感じのモデルデータが現れる。
これを別名保存して、作業をしていく。
◎ ポーズをつけてみる :
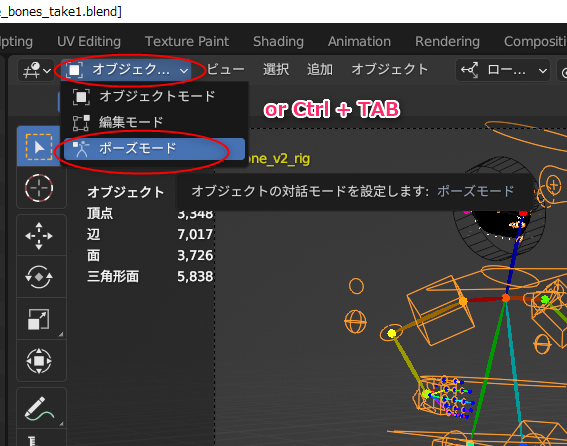
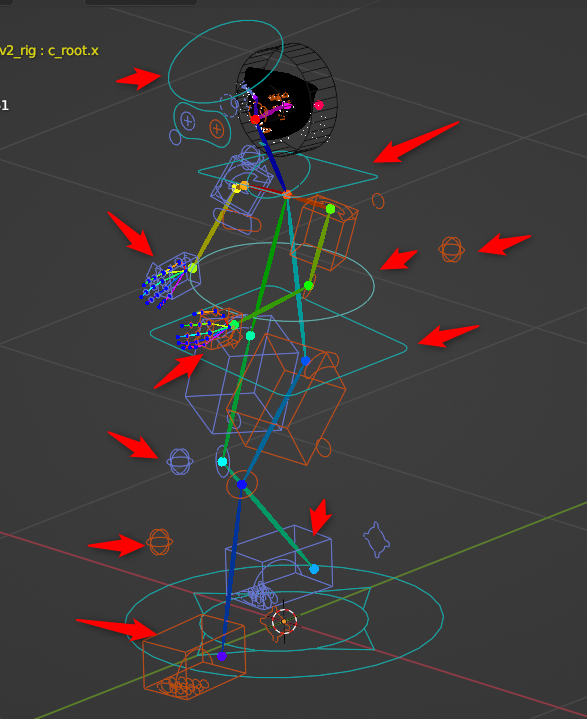
OpenPoseモデルを左クリックして選択してから、ポーズモードに切り替える。ウインドウ左上の選択メニューから選んでもいいし、Ctrl + TABキーを押して切り替えてもいい。
関節をクリックしても回転させることができなくて、どうやってポーズをつけていけばいいのか分らなくてちょっと悩んだけれど。どうやら既にIKが指定してあって、手足の先の箱や、腰や頭の周りにある輪っかを左クリックで選択してから、移動したり回転させたりすることで、ポーズをつけていけるようだと分かった。
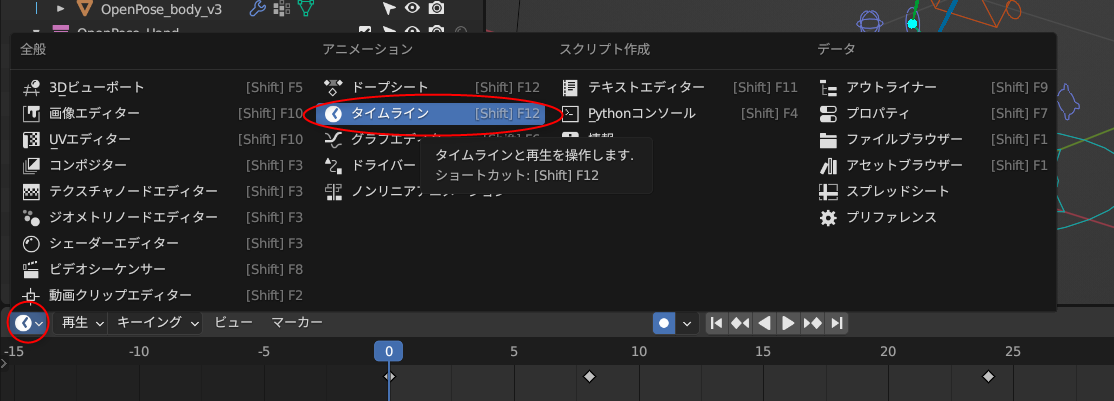
アニメーションにしたいので、画面の下のほうのウインドウを、タイムラインにする。各ウインドウの、左上隅のアイコンをクリックすれば、ウインドウの種類を変更できる。
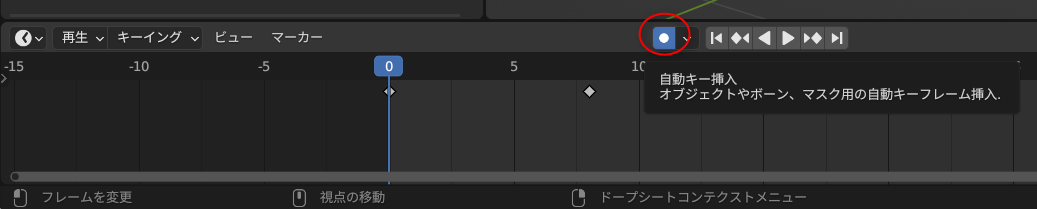
タイムラインウインドウの真ん中あたりにある丸アイコンをクリックして有効にすれば、自動キー挿入が有効になって、ポーズを変更する度に、自動でキーフレームを挿入/上書きしてくれる。
そんな感じで、8FPSを前提にして、アニメーションをつけてみたのだけど…。試しにプレビュー再生してみたら、左上に出ている表示FPSが…。
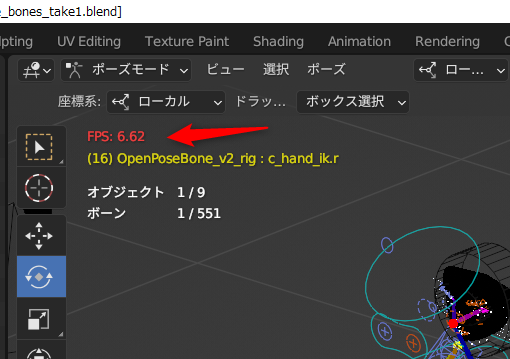
8FPSで設定してあるのに、6FPSしか出てない…。blender、重い…。これではどんなアニメになったのか、よく分からない…。いや、自分の環境が非力なのかもしれんけど。AMD Ryzen 5 5600X + NVIDIA GeForce GTX 1060 ではこんなものなのか…。
でもまあ、ワイヤーフレーム表示にしたら8FPSが出てくれたので、どうにかなりそう。
何にせよ、アニメーションをプレビュー再生する時は、左上に出ている表示FPSをチェックして、本来のFPSが出てるのかどうか気にしながら作業していきたい。
関節をクリックしても回転させることができなくて、どうやってポーズをつけていけばいいのか分らなくてちょっと悩んだけれど。どうやら既にIKが指定してあって、手足の先の箱や、腰や頭の周りにある輪っかを左クリックで選択してから、移動したり回転させたりすることで、ポーズをつけていけるようだと分かった。
アニメーションにしたいので、画面の下のほうのウインドウを、タイムラインにする。各ウインドウの、左上隅のアイコンをクリックすれば、ウインドウの種類を変更できる。
タイムラインウインドウの真ん中あたりにある丸アイコンをクリックして有効にすれば、自動キー挿入が有効になって、ポーズを変更する度に、自動でキーフレームを挿入/上書きしてくれる。
そんな感じで、8FPSを前提にして、アニメーションをつけてみたのだけど…。試しにプレビュー再生してみたら、左上に出ている表示FPSが…。
8FPSで設定してあるのに、6FPSしか出てない…。blender、重い…。これではどんなアニメになったのか、よく分からない…。いや、自分の環境が非力なのかもしれんけど。AMD Ryzen 5 5600X + NVIDIA GeForce GTX 1060 ではこんなものなのか…。
でもまあ、ワイヤーフレーム表示にしたら8FPSが出てくれたので、どうにかなりそう。
何にせよ、アニメーションをプレビュー再生する時は、左上に出ている表示FPSをチェックして、本来のFPSが出てるのかどうか気にしながら作業していきたい。
◎ レンダリングしてみる :
F12キーを押して、レンダリングしてみる。
なんだか変な画像がレンダリングされた…。ナニコレ…。
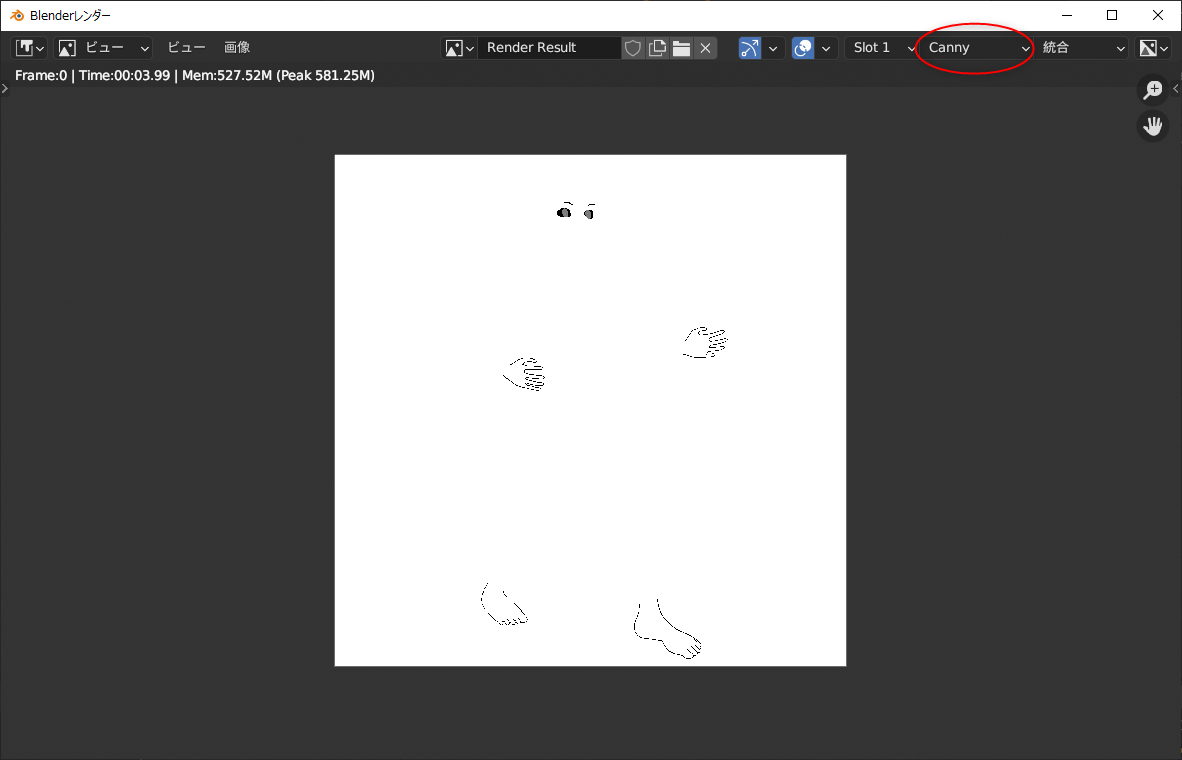
右上のほうで、出力画像の種類を選ぶことができるらしい。最初に出ていたのは canny 用で、OpenPose を見たかったら、種類を選べ直せばいい。
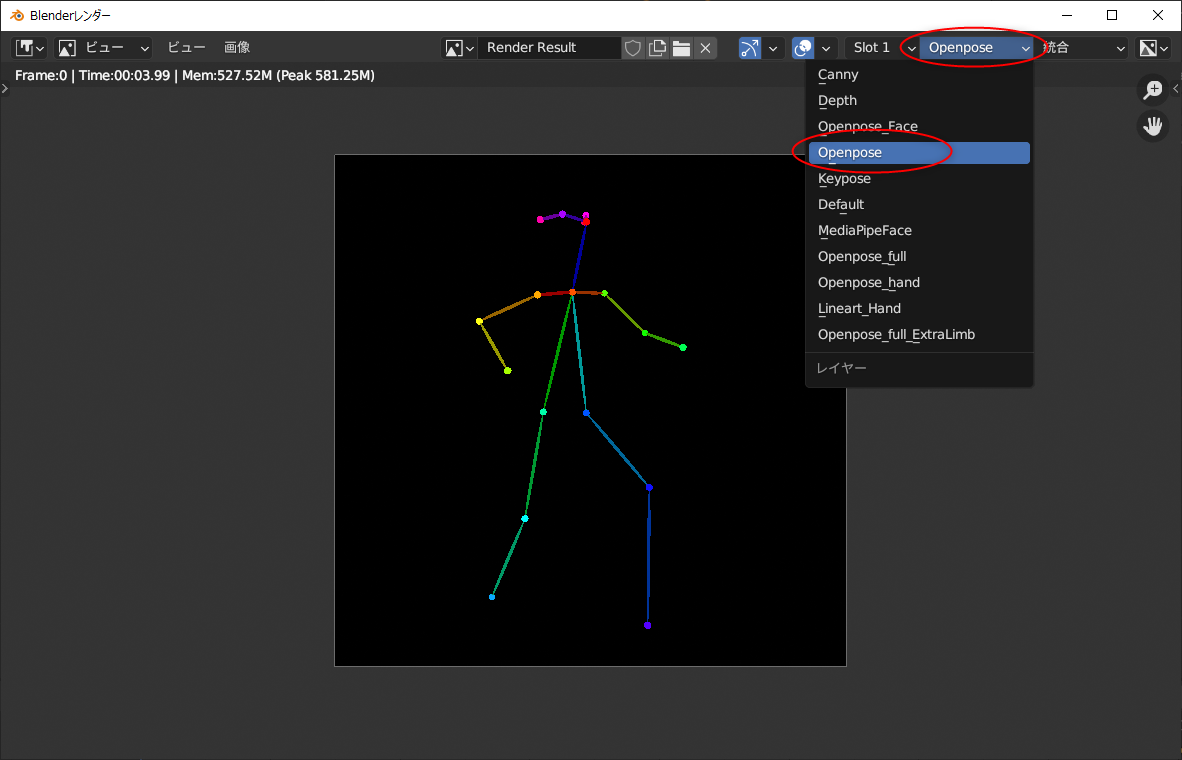
これらのレンダリング画像は、.blend ファイルの保存場所に、MultiControlnet というフォルダが作られて、その中に種類別フォルダも作成されて、それら各フォルダ内に画像が保存されていく模様。
ちなみに、MultiControlnet\ フォルダの中には、以下のフォルダが作られていた。
つまり、OpenPose画像が欲しかったら、MultiControlnet 内の openposeフォルダの中を探せばいい。
なんだか変な画像がレンダリングされた…。ナニコレ…。
右上のほうで、出力画像の種類を選ぶことができるらしい。最初に出ていたのは canny 用で、OpenPose を見たかったら、種類を選べ直せばいい。
これらのレンダリング画像は、.blend ファイルの保存場所に、MultiControlnet というフォルダが作られて、その中に種類別フォルダも作成されて、それら各フォルダ内に画像が保存されていく模様。
ちなみに、MultiControlnet\ フォルダの中には、以下のフォルダが作られていた。
canny depth keypose Lineart MediaPipe_face openpose openpose_face openpose_full openpose_full_Extra_Limb openpose_hand
つまり、OpenPose画像が欲しかったら、MultiControlnet 内の openposeフォルダの中を探せばいい。
◎ 動画でレンダリングしてみる :
blender の上のほうのメニューの中から、レンダリング → アニメーション、を選んで、動画をレンダリングしてみる。
.blend の保存場所に、canny用の連番画像が大量に生成されてしまった…。これは…要らないなあ…。
一応、MultiControlnet\openpose\ 以下に、OpenPoseの連番画像も出力された。これを使って動画を作ればいいか…。
ffmpeg を利用して、連番画像から動画を生成する。
8fps、40フレームのmp4動画が得られた。
.blend の保存場所に、canny用の連番画像が大量に生成されてしまった…。これは…要らないなあ…。
一応、MultiControlnet\openpose\ 以下に、OpenPoseの連番画像も出力された。これを使って動画を作ればいいか…。
ffmpeg を利用して、連番画像から動画を生成する。
ffmpeg -framerate 8 -i MultiControlnet\openpose\Image%04d.png -vcodec libx264 -pix_fmt yuv420p -r 8 out_openpose.mp4 -y
- -framerate 8 : 入力する連番画像のフレームレートを指定。ここでは 8FPS を指定している。
- -i hoge%04d.png : hoge0000.png - hogeXXXX.png を入力画像として渡す。%04d と書けば、0000 - 9999 まで対応できる。
- -vcodec libx264 -pix_fmt yuv420p : Webブラウザでも再生できるmp4動画を指定。
- -r 8 : 出力動画のフレームレートを指定。8FPSにしている。
- out_openpose.mp4 : 出力ファイル名。
- -y : 既に出力ファイルが存在していたら上書きする。
8fps、40フレームのmp4動画が得られた。
◎ Stable Diffusion web UIに渡してみる :
得られた OpenPose動画を、画像生成AI Stable Diffusion web UIに渡して、動画を生成してみたい。
ControlNet には、ControlNet m2m というスクリプトが付属している。このスクリプトを選んで動画を渡してやれば、動画の1フレームを取り出して、ControlNet に転送して、画像生成して ―― これを動画の全フレーム分繰り返してくれる。
ただ、Stable Diffusion web UIの設定画面 → ControlNet で、スクリプトからの操作を許可しておかないといけない。この設定が必要なことを知らなくて、実行してみたら「ControlNetに画像が指定されてないぞ」とエラーが出て悩んでしまった。
設定については以下が参考になった。ありがたや。
_【ControlNet m2m】動画を直接Aiに渡す!【Stable Diffusion】 | 謎の技術研究部
_ControlNet - としあきdiffusion Wiki*
"Allow other script to control this extension" にチェックを入れておくらしい。
他に、ググって分かったことをメモ。
そんな感じで、txt2img で試してみたのだけど…。1枚生成するのに58秒 = 約1分。それが40フレームあるので、フツーに40分ぐらいかかった。
生成された画像は、以下の場所に保存されていた。
そんなわけで、連番画像からmp4動画を生成してみたけれど…。
うーん。予想通りではあるけれど、各フレームの連続性というか、一貫性が皆無…。元のOpenPose動画の動きがビミョーすぎて、こういう実験に不向きなせいもありそうだけど、現状ではまだまだ色々と厳しいものがあるなと…。
それはそれとして、これを書いてる段階でトホホなミスをしていることに気が付いた。
アニメを作りたいなら、24コマ/秒で3コマベース、8fpsでOpenPose動画を作っておけばいいのかなと安易に思って作業してしまったけれど。だったら最後に、アニメ系と言うか、手描きに見える学習モデルデータを使って画像生成しないと…。実写系の学習モデルデータ、ChilloutMix系で生成しちゃダメじゃん…。実写系の画像を、ジャパニメーションのリミテッドアニメ風フレームレートで動かすとか、自分、何をやってるんだか…。
ControlNet には、ControlNet m2m というスクリプトが付属している。このスクリプトを選んで動画を渡してやれば、動画の1フレームを取り出して、ControlNet に転送して、画像生成して ―― これを動画の全フレーム分繰り返してくれる。
ただ、Stable Diffusion web UIの設定画面 → ControlNet で、スクリプトからの操作を許可しておかないといけない。この設定が必要なことを知らなくて、実行してみたら「ControlNetに画像が指定されてないぞ」とエラーが出て悩んでしまった。
設定については以下が参考になった。ありがたや。
_【ControlNet m2m】動画を直接Aiに渡す!【Stable Diffusion】 | 謎の技術研究部
_ControlNet - としあきdiffusion Wiki*
"Allow other script to control this extension" にチェックを入れておくらしい。
他に、ググって分かったことをメモ。
- txt2img, img2img のどちらでも、ControlNet m2m を使って動画を作れる。
- img2imgで出力したほうが背景が崩れにくい、らしい。
- 出力する時は、seed を固定して、似た画像が出やすい状態にする。
- プロンプトにも、服装や背景等、固定しやすくなるワードを多々打ち込んでおく。
- ControlNet m2m を使う時は、ControlNet の画像指定欄は空欄にしておく。そこは m2m から各フレームが入力されるので。
- ControlNet m2m の Duration という設定項目は、1フレームあたりの表示時間をミリ秒で指定する。らしい。8fpsなら125ms。12fpsなら83〜84ms。24fpsなら41〜42ms。おそらくアニメgifを生成する際に使われる値ではなかろうか。
- ControlNet の Control Weight は大き目の数値にしておくといいらしい。1.6とか。
そんな感じで、txt2img で試してみたのだけど…。1枚生成するのに58秒 = 約1分。それが40フレームあるので、フツーに40分ぐらいかかった。
生成された画像は、以下の場所に保存されていた。
- outputs\txt2img-images\日付\ : いつもの保存場所。
- outputs\txt2img-images\controlnet-m2m\ : アニメgifファイルが保存されている。
- outputs\txt2img-images\tmp\ : 生成画像が連番画像として保存されていた。もしかするとアニメgifを作るための仮保存場所…?
そんなわけで、連番画像からmp4動画を生成してみたけれど…。
うーん。予想通りではあるけれど、各フレームの連続性というか、一貫性が皆無…。元のOpenPose動画の動きがビミョーすぎて、こういう実験に不向きなせいもありそうだけど、現状ではまだまだ色々と厳しいものがあるなと…。
それはそれとして、これを書いてる段階でトホホなミスをしていることに気が付いた。
アニメを作りたいなら、24コマ/秒で3コマベース、8fpsでOpenPose動画を作っておけばいいのかなと安易に思って作業してしまったけれど。だったら最後に、アニメ系と言うか、手描きに見える学習モデルデータを使って画像生成しないと…。実写系の学習モデルデータ、ChilloutMix系で生成しちゃダメじゃん…。実写系の画像を、ジャパニメーションのリミテッドアニメ風フレームレートで動かすとか、自分、何をやってるんだか…。
◎ 2023/05/18追記 :
せっかくだから、アニメ系の学習モデルデータ、MeinaMix を使って試してみた。更に今回は、txt2imgではなくて、img2imgで生成してみた。
うーん。これは…どうなんだ…。まあ、色々と厳しいのは間違いない…。
うーん。これは…どうなんだ…。まあ、色々と厳しいのは間違いない…。
[ ツッコむ ]
2023/05/18(木) [n年前の日記]
#1 [cg_tools] OpenPose動画を作りたい
blenderを使ってOpenPose動画を作成する手順は分かったけれど、手作業でポーズを指定してアニメーションを作らないといけないあたりが面倒臭い。既存の動画を分析してOpenPose動画を生成することはできないものだろうか。というか、本来のOpenPoseって、現実に存在する人体の動きを解析して作るものだろうし…。
そんなわけで、OpenPose動画を生成するためのツールがあるのかどうかググってみた。
環境は、Windows10 x64 22H2。CPU : AMD Ryzen 5 5600X。GPU : NVIDIA GeForce GTX 1060 6GB。
以下のページが参考になりそう。ありがたや。
_OpenPoseを使って手っ取り早く姿勢推定をしてみる(Windows10) | 技術的特異点
_OpenPose による姿勢推定(Windows 上)
_OpenPose 1.7.0 のインストール,デモの実行(Windows 上)
_OpenPose の使い方 - nomlab
_Advent Calendar | 濱川研究室Webページ
_OpenPoseの使い方メモ - .com-pound
よく分からんけど、OpenPoseDemo.exe なるものを動かせば OpenPose画像/動画が得られるようだなと…。
そんなわけで、OpenPose動画を生成するためのツールがあるのかどうかググってみた。
環境は、Windows10 x64 22H2。CPU : AMD Ryzen 5 5600X。GPU : NVIDIA GeForce GTX 1060 6GB。
以下のページが参考になりそう。ありがたや。
_OpenPoseを使って手っ取り早く姿勢推定をしてみる(Windows10) | 技術的特異点
_OpenPose による姿勢推定(Windows 上)
_OpenPose 1.7.0 のインストール,デモの実行(Windows 上)
_OpenPose の使い方 - nomlab
_Advent Calendar | 濱川研究室Webページ
_OpenPoseの使い方メモ - .com-pound
よく分からんけど、OpenPoseDemo.exe なるものを動かせば OpenPose画像/動画が得られるようだなと…。
◎ OpenPoseのバイナリを入手 :
以下のページから、OpenPoseを生成できる、Windows用のバイナリが入手できるらしい。
_GitHub - CMU-Perceptual-Computing-Lab/openpose: OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation
_Releases - CMU-Perceptual-Computing-Lab/openpose - GitHub
OpenPose v1.7.0 を入手。CPUを使って処理する版と、GPUを使って処理する版があるらしいけど、よく分からないので両方DLしておいた。
解凍して任意の場所に置く。今回は、D:\aiwork\openpose\cpu\ と、D:\aiwork\openpose\gpu\ に置いてみた。
_GitHub - CMU-Perceptual-Computing-Lab/openpose: OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation
_Releases - CMU-Perceptual-Computing-Lab/openpose - GitHub
OpenPose v1.7.0 を入手。CPUを使って処理する版と、GPUを使って処理する版があるらしいけど、よく分からないので両方DLしておいた。
- openpose-1.7.0-binaries-win64-cpu-python3.7-flir-3d.zip : CPU使用版
- openpose-1.7.0-binaries-win64-gpu-python3.7-flir-3d_recommended.zip : GPU使用版
解凍して任意の場所に置く。今回は、D:\aiwork\openpose\cpu\ と、D:\aiwork\openpose\gpu\ に置いてみた。
◎ 学習モデルデータをダウンロード :
動かすには、学習モデルデータを入手しないといけない。modelsフォルダの中に入って、getBaseModels.bat を実行すると、拡張子が .caffemodel のファイルがいくつかDLされる。全部で400MBほどのファイルがDLされた。
◎ サンプル画像やサンプル動画 :
examples\media\ というフォルダの中に、動作確認用のサンプル画像、サンプル動画が入っていた。jpgファイルが20ファイル、aviファイルが1ファイル入ってる。
◎ 動かしてみる :
とりあえず、動かしてみる。GPU使用版は何か色々必要になりそうなので、まずはCPU使用版を使ってみる。
サンプル画像の中の COCO_val2014_000000000328.jpg だけを、test\ というフォルダを作って、その中にコピー。
bin\ の中に実行バイナリ、OpenPoseDemo.exe が入ってるらしいので、ソレを実行。
--write_images OUTDIR をつければ、結果画像を保存できるらしい。outputsフォルダを作成して、指定してみる。
outputs\ の中にpng画像が保存された。元画像の上に、OpenPose が描き込まれている状態の画像が得られた。ちゃんと人体姿勢を検出できてる。スゴイ。
ただ、OpenPose画像だけを取得したいのだけど…。そんなことはできるのだろうか。
以下のページで、該当オプションが解説されてた。
_openpose/01_demo.md at master - CMU-Perceptual-Computing-Lab/openpose - GitHub
--disable_blending をつけてやると、元画像との合成を無効にしてくれるらしい。
OpenPoseだけが描き込まれた画像が得られた。
解析結果を数値で欲しい場合は、.yml か .json で書き出すことができる模様。--write_keypoint OUTDIR か --write_json OUTDIR を使う。
サンプル画像の中の COCO_val2014_000000000328.jpg だけを、test\ というフォルダを作って、その中にコピー。
bin\ の中に実行バイナリ、OpenPoseDemo.exe が入ってるらしいので、ソレを実行。
bin\OpenPoseDemo.exe --image_dir test--image_dir INDIR を指定すれば、画像が入ってるフォルダを指定できる。ファイル単位で指定できるわけではなくて、フォルダ単位でしか指定できないようだなと…。
> bin\OpenPoseDemo.exe --image_dir test Starting OpenPose demo... Configuring OpenPose... Starting thread(s)... ---------------------------------- WARNING ---------------------------------- We have introduced an additional boost in accuracy in the CUDA version of about 0.2% with respect to the CPU/OpenCL versions. We will not port this to CPU given the considerable slow down in speed it would add to it. Nevertheless, this accuracy boost is almost insignificant so the CPU/OpenCL versions can be safely used. -------------------------------- END WARNING -------------------------------- OpenPose demo successfully finished. Total time: 3.299756 seconds.3.299756秒かかって、OpenPose が描き込まれた感じの画像ウインドウが一瞬表示されて消えてしまった。ひとまず、動いてはいるようだなと…。CPU使用版でもちゃんと動いてくれる。しかし、結果画像がどこにも保存されてない気がする…。
--write_images OUTDIR をつければ、結果画像を保存できるらしい。outputsフォルダを作成して、指定してみる。
bin\OpenPoseDemo.exe --image_dir test --write_images outputs
outputs\ の中にpng画像が保存された。元画像の上に、OpenPose が描き込まれている状態の画像が得られた。ちゃんと人体姿勢を検出できてる。スゴイ。
ただ、OpenPose画像だけを取得したいのだけど…。そんなことはできるのだろうか。
以下のページで、該当オプションが解説されてた。
_openpose/01_demo.md at master - CMU-Perceptual-Computing-Lab/openpose - GitHub
--disable_blending をつけてやると、元画像との合成を無効にしてくれるらしい。
bin\OpenPoseDemo.exe --image_dir test --write_images outputs --disable_blending
OpenPoseだけが描き込まれた画像が得られた。
解析結果を数値で欲しい場合は、.yml か .json で書き出すことができる模様。--write_keypoint OUTDIR か --write_json OUTDIR を使う。
bin\OpenPoseDemo.exe --image_dir test --write_images outputs --disable_blending --write_keypoint outputs --write_json outputs
◎ 2023/05/19追記 :
[ ツッコむ ]
#2 [nitijyou] 暑い
昨日、今日と、気温が30度超え。暑い。さすがにエアコンを入れた。
5月中旬なのにこの暑さ…。どうなってしまうのか…。
5月中旬なのにこの暑さ…。どうなってしまうのか…。
[ ツッコむ ]
2023/05/19(金) [n年前の日記]
#1 [cg_tools] OpenPose動画を作りたい。その2
_昨日
の続き。OpenPoseの静止画像を作成することはできたので、今度は動画を生成したい。
環境は、Windows10 x64 22H2。CPU : AMD Ryzen 5 5600X。GPU : NVIDIA GeForce GTX 1060 6GB。
OpenPoseDemo.exe は、CPU使用版。
環境は、Windows10 x64 22H2。CPU : AMD Ryzen 5 5600X。GPU : NVIDIA GeForce GTX 1060 6GB。
OpenPoseDemo.exe は、CPU使用版。
◎ サンプル動画を入手 :
OpenPose のバイナリと一緒に、examples\media\video.avi というサンプル動画も入っているけれど。今回は、ソレとは別の動画を渡して処理してみたい。
今回は、以下の動画を使わせてもらうことにした。25fpsの動画。1920x1080版をDL。
_Video Of Person Running In The Park Free Stock Video Footage, Royalty-Free 4K & HD Video Clip
ちなみに、以下のサイトで検索して探したのだけど…。何故にどの動画もスローモーションなのか…。
_Running Videos, Download The BEST Free 4k Stock Video Footage & Running HD Video Clips
今回は、以下の動画を使わせてもらうことにした。25fpsの動画。1920x1080版をDL。
_Video Of Person Running In The Park Free Stock Video Footage, Royalty-Free 4K & HD Video Clip
ちなみに、以下のサイトで検索して探したのだけど…。何故にどの動画もスローモーションなのか…。
_Running Videos, Download The BEST Free 4k Stock Video Footage & Running HD Video Clips
◎ 512x512に加工 :
後々、画像生成AI Stable Diffusion web UI に渡したいので、元動画を、512x512の動画に加工したい。
今回は、Avidemux 2.7.8 を使って作業した。ちなみに、現行版は 2.8.1 の模様。
_Avidemux のダウンロードと使い方 - k本的に無料ソフト・フリーソフト
フィルターを設定。1:1にトリミングしてから、512x512に拡大縮小。人物が出ていない時間(?)ができてしまったので、動画の前後を削除。
大体以下のような雰囲気の動画になった。これは256x256に縮小してるけど…。
今回は、Avidemux 2.7.8 を使って作業した。ちなみに、現行版は 2.8.1 の模様。
_Avidemux のダウンロードと使い方 - k本的に無料ソフト・フリーソフト
フィルターを設定。1:1にトリミングしてから、512x512に拡大縮小。人物が出ていない時間(?)ができてしまったので、動画の前後を削除。
大体以下のような雰囲気の動画になった。これは256x256に縮小してるけど…。
◎ OpenPose動画を作成 :
動画を解析して、OpenPose動画を出力する。
このままだと、MotionJPEG の avi なので、Webブラウザでも再生できるように、ffmpeg 6.0 を使ってmp4に変換した。
こんな感じの動画になった。動きをバッチリ抽出できてる。
bin\OpenPoseDemo.exe --video test\src.mp4 --write_video outputs\dst.avi --disable_blending
- --video IN.avi : 入力動画。一般的には .avi を渡すようだけど、.mp4 もイケた。
- --write_video OUT.avi : 出力動画。MotionJPEGで保存されるっぽい。
- --disable_blending : OpenPose部分のみを出力。
このままだと、MotionJPEG の avi なので、Webブラウザでも再生できるように、ffmpeg 6.0 を使ってmp4に変換した。
ffmpeg -i dst.avi -vcodec libx264 -pix_fmt yuv420p dst.mp4
こんな感じの動画になった。動きをバッチリ抽出できてる。
◎ 連番画像として出力 :
後々、Stable Diffusion web UI で作業をする際に、OpenPose の静止画像があったほうが調整しやすいはずなので、ffmpeg を使って、動画を連番画像として出力。
ffmpeg -i results.avi seq\%04d.png or ffmpeg -i results.avi -vcodec png -r 25 %04d.png
- -i IN.avi : 入力動画
- -vcodec png : 出力フォーマットをpngにする
- -r N : フレームレート
- %04d.png : 4桁の数字で示された連番画像として保存
◎ 形が違うことに気づいた :
今頃になって気づいたけれど、Stable Diffusion web UI で指定する OpenPose と、OpenPoseDemo.exe が生成する OpenPose は、形がちょっと違う…。
_Windows への OpenPose導入手順【2018/12/30追記】 - Qiita
_Windows10にてGPU版OpenPoseを動かしてみた - Qiita
どうやら、1.3.0 から 1.4.0 になった時点で、形が変わったように見える。
であれば、OpenPose 1.3.0 のバイナリを入手すれば、Stable Diffusion web UI のソレに一致させることができるのだろうか。しかし、そう上手くはいかないようで。
_Releases - CMU-Perceptual-Computing-Lab/openpose - GitHub
1.3.0までは、GPU版しかなくて、1.4.0からCPU版のバイナリも公開されるようになったっぽい。CPU版を使いたいのだけど、困った…。
GPU版 OpenPose 1.3.0 を動かすためには、CUDA 8.0、cuDNN 5.1 が必要になるようで…。自分の環境は、Stable Diffusion web UI を動かすために、CUDA 11.8 をインストール済みなんだよな…。異なるバージョンをインストールすることってできるのかな…。
前述のページを書いた方が、コメント欄でCPU版を公開してくれているので、DLして実行してみたけれど、以下の .dll が無いと言われてしまった…。
どうやら CUDA の複数バージョンを共存させる方法を実現して、GPU版を使うしかないようだなと…。
- Stable Diffusion web UI + ControlNet : 首から足の根元まで2本の線が出てる。
- OpenPose 1.7.0 : 首から腰まで1本の線になっている。
_Windows への OpenPose導入手順【2018/12/30追記】 - Qiita
_Windows10にてGPU版OpenPoseを動かしてみた - Qiita
どうやら、1.3.0 から 1.4.0 になった時点で、形が変わったように見える。
であれば、OpenPose 1.3.0 のバイナリを入手すれば、Stable Diffusion web UI のソレに一致させることができるのだろうか。しかし、そう上手くはいかないようで。
_Releases - CMU-Perceptual-Computing-Lab/openpose - GitHub
1.3.0までは、GPU版しかなくて、1.4.0からCPU版のバイナリも公開されるようになったっぽい。CPU版を使いたいのだけど、困った…。
GPU版 OpenPose 1.3.0 を動かすためには、CUDA 8.0、cuDNN 5.1 が必要になるようで…。自分の環境は、Stable Diffusion web UI を動かすために、CUDA 11.8 をインストール済みなんだよな…。異なるバージョンをインストールすることってできるのかな…。
前述のページを書いた方が、コメント欄でCPU版を公開してくれているので、DLして実行してみたけれど、以下の .dll が無いと言われてしまった…。
cublas64_80.dll cudart64_80.dll curand64_80.dll
どうやら CUDA の複数バージョンを共存させる方法を実現して、GPU版を使うしかないようだなと…。
◎ COCOモデルを使えばいいらしい :
調べてみたら、現行版の OpenPose 1.7.0 でも、COCOモデルなるものを使えば、Stable Diffusion web UI + ControlNet と同じ形状で OpenPose を出力できそうだと分かった。
COCOモデルを使うには、OpenPoseインストールフォルダ\models\ 内で、getCOCO_and_MPII_optional.bat を実行して、モデルデータを追加ダウンロードする必要がある。
また、OpnePoseDemo.exe には、--model_pose COCO を渡してやる。
Stable Diffusion web UI + ControlNet + OpenPose で利用できる形状のソレを得ることができた。
しかし、そもそも、Stable Diffusion web UI で、動画に基づいて各ポーズを指定したいだけなら、ControlNet のプリプロセッサで OpenPose を通せば良いのではないか。わざわざ別途、OpenPoseDemo.exe を動かす必要も無いのでは…。
COCOモデルを使うには、OpenPoseインストールフォルダ\models\ 内で、getCOCO_and_MPII_optional.bat を実行して、モデルデータを追加ダウンロードする必要がある。
また、OpnePoseDemo.exe には、--model_pose COCO を渡してやる。
bin\OpenPoseDemo.exe --image_dir test --write_images outputs --model_pose COCO
bin\OpenPoseDemo.exe --video src.mp4 --write_video dst.avi --model_pose COCO --disable_blending
Stable Diffusion web UI + ControlNet + OpenPose で利用できる形状のソレを得ることができた。
しかし、そもそも、Stable Diffusion web UI で、動画に基づいて各ポーズを指定したいだけなら、ControlNet のプリプロセッサで OpenPose を通せば良いのではないか。わざわざ別途、OpenPoseDemo.exe を動かす必要も無いのでは…。
この記事へのツッコミ
[ ツッコミを読む(1) | ツッコむ ]
#2 [nitijyou] ワサビ作戦失敗
ウチでは、電動アシスト自転車が車の横に止めてあるのだけど、風が強い日に倒れてしまって、車の側面を傷つけてしまったことがあって。それ以来、100円ショップで買ったフック付きゴム紐を使って、自転車を縁側に固定してる。
しかし、飼い犬が、稀にそのゴム紐を齧り切ってしまって…。昨日も噛み切られてしまった…。もう10回ぐらいは噛み切られている気がする…。どうにか齧らないようにできないものかな…。
ググってみたら、テーブルの足、椅子の足等、犬に齧られると困る部分にワサビを塗っておく策を考えた方が居るようで。一般的には、ワサビの刺激臭が犬にとってはキツイらしい。
もちろん刺激物なので、犬に日常的に食べさせるなんてもってのほか。下手すると犬の内臓を痛めてしまう可能性があるらしいけど。そもそも犬が嫌がるなら、食べることもないだろう…。
そんなわけで、試しに、買ってきたばかりのゴム紐にワサビを塗りつけてみた。
しかし、朝になったら、また噛み切られていた…。しかも、普段は買ってきたばかりのゴム紐を齧ることなんてなかったのに、交換した途端にやらかしてくれるとは…。そんなにも齧りたくなる匂いだったのか…。
稀に居るらしいけど、どうやらウチの犬も、ワサビ大好きな個体だったようだなと…。作戦失敗。
しかし、飼い犬が、稀にそのゴム紐を齧り切ってしまって…。昨日も噛み切られてしまった…。もう10回ぐらいは噛み切られている気がする…。どうにか齧らないようにできないものかな…。
ググってみたら、テーブルの足、椅子の足等、犬に齧られると困る部分にワサビを塗っておく策を考えた方が居るようで。一般的には、ワサビの刺激臭が犬にとってはキツイらしい。
もちろん刺激物なので、犬に日常的に食べさせるなんてもってのほか。下手すると犬の内臓を痛めてしまう可能性があるらしいけど。そもそも犬が嫌がるなら、食べることもないだろう…。
そんなわけで、試しに、買ってきたばかりのゴム紐にワサビを塗りつけてみた。
しかし、朝になったら、また噛み切られていた…。しかも、普段は買ってきたばかりのゴム紐を齧ることなんてなかったのに、交換した途端にやらかしてくれるとは…。そんなにも齧りたくなる匂いだったのか…。
稀に居るらしいけど、どうやらウチの犬も、ワサビ大好きな個体だったようだなと…。作戦失敗。
[ ツッコむ ]
2023/05/20(土) [n年前の日記]
#1 [cg_tools] OpenPoseで画像生成したい
_一昨日、
_昨日
と、OpenPose動画を得るための実験をしていたけれど。画像生成AI Stable Diffusion web UIに、OpenPose動画を渡して画像を生成したいだけなら、そもそも元動画をControlNetに渡してしまって、OpenPoseのプリプロセッサを通せば話が早いのではと気づいてしまって…。その方向でアニメーションを作成できそうか実験。
*1
環境は、Windows10 x64 22H2。CPU AMD Ryzen 5 5600X。GPU NVIDIA GeForcet GTX1060 6GB。RAM 16GB。
環境は、Windows10 x64 22H2。CPU AMD Ryzen 5 5600X。GPU NVIDIA GeForcet GTX1060 6GB。RAM 16GB。
◎ 元動画 :
元動画は、以下のような雰囲気の動画。上半身裸の黒人おじさんがランニングをしている。これは256x256に縮小してあるけれど、実際に作業に使った動画は512x512。25fps。全31フレーム。
元々のオリジナル動画は以下から入手できる。
_Video Of Person Running In The Park Free Stock Video Footage, Royalty-Free 4K & HD Video Clip
元々のオリジナル動画は以下から入手できる。
_Video Of Person Running In The Park Free Stock Video Footage, Royalty-Free 4K & HD Video Clip
◎ テストその1 :
txt2img上で、ControlNet m2m スクリプトを使ってアニメーションを作成。ControlNet でプリプロセッサと学習モデルデータに openpose を指定。
学習モデルデータは、animelike25D_animelike25DV11Pruned.safetensors を使わせてもらった。
こんな感じになった。24fps。全31フレーム。
一応ランニングしてるように見えなくもないけど、それはそれとして、背景が1フレーム毎にパカパカ変わってしまって、とても見辛い…。この背景はどうにかしたい…。
学習モデルデータは、animelike25D_animelike25DV11Pruned.safetensors を使わせてもらった。
parameters 1 girl, solo, black short hair, red camisole, red miniskirt, black globes, white sneakers, running, (((background is simple and flat and white))), ((masterpiece, bets best quality)), Negative prompt: (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, (monochrome), (grayscale), bad anatomy, extra arms, extra legs, missing arms, missing legs, bad arms, bad legs, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 1434010576, Size: 512x512, Model hash: 4f24a26d75, Model: animelike25D_animelike25DV11Pruned, Clip skip: 2, ControlNet 0: "preprocessor: openpose, model: control_v11p_sd15_openpose [cab727d4], weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 64, 64)"
こんな感じになった。24fps。全31フレーム。
一応ランニングしてるように見えなくもないけど、それはそれとして、背景が1フレーム毎にパカパカ変わってしまって、とても見辛い…。この背景はどうにかしたい…。
◎ テストその2 :
ネガティブプロンプトに与えるワードを色々試して、背景をスッキリさせられないか試行錯誤してみた。
white background, no background を指定してみたり、ネガティブプロンプトに、時々出現する謎物体を分かる範囲で指定してみたり、人物が2人出現しないように、思いつくワードを入れてみたり。
そんなわけで、こうなった。24fps。全31フレーム。
かなり背景をスッキリさせることができた。しかし、これでも時々妙な物体が描かれる…。なんだろうコレは…。言葉で説明できる物体なら、ネガティブプロンプトに追加することで消せるかもしれないけど…。
さておき。フツーの手描きアニメは、フィルム時代の名残りで、24コマ/秒で作られてるけど、1秒間につき24枚の動画を真面目に描いてるカットは稀だったりする。例えば、ディズニーの手描きアニメですら、動画1枚を2コマ撮影していて ―― 2コマベース、12fpsを基本として作られてるので…。1枚ずつ間引いて、12fps、全15フレームにしてみた。
12fpsにしたことで、ちょっとは手描きアニメっぽい雰囲気に近づいた気がする。
ちなみに、日本のアニメは、鉄腕アトムの頃から3コマベース、8fpsを基本として作られているので、2枚ずつ間引いて8fps、全11フレームにしてみた。
これでもまあ、そこそこアニメーションっぽい感じにはなるなと…。
もっとも…。
それでも、例えばミュージックビデオ等の1カットでチラッと流してみるとか、エヴァTV版の最終回近辺のように、混乱しているキャラの精神世界を表現、といった使い方なら、こういう動画もイケそうな気もする。
それはそれとして。黒人のおじさんが走ってる動画から、こういう動画を生成できてしまうという点は、結構悪くないのではないかと。
parameters ((1girl is running)), black short hair, black camisole, red miniskirt, (from front:1.2), ((masterpiece, best quality)), (white background:1.3), (no backgorund:1.3), (no effects:1.4), Negative prompt: (worst quality:1.4), (low quality:1.4), lowers, (monochrome), (grayscale), bad anatomy, extra arms, extra legs, missing arms, missing legs, bad arms, bad legs, ((background)), ((two shot)), ((groups)), ((2girl)), ((ribbon, scarf, science fiction, mecha, shield, cloth, umbrella)), (long hair:1.4), ((hair)), Steps: 25, Sampler: DPM++ 2M Karras, CFG scale: 9, Seed: 4217096040, Size: 512x512, Model hash: 4f24a26d75, Model: animelike25D_animelike25DV11Pruned, Clip skip: 2, ControlNet 0: "preprocessor: openpose, model: control_v11p_sd15_openpose [cab727d4], weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: True, control mode: Balanced, preprocessor params: (512, 64, 64)"
white background, no background を指定してみたり、ネガティブプロンプトに、時々出現する謎物体を分かる範囲で指定してみたり、人物が2人出現しないように、思いつくワードを入れてみたり。
そんなわけで、こうなった。24fps。全31フレーム。
かなり背景をスッキリさせることができた。しかし、これでも時々妙な物体が描かれる…。なんだろうコレは…。言葉で説明できる物体なら、ネガティブプロンプトに追加することで消せるかもしれないけど…。
さておき。フツーの手描きアニメは、フィルム時代の名残りで、24コマ/秒で作られてるけど、1秒間につき24枚の動画を真面目に描いてるカットは稀だったりする。例えば、ディズニーの手描きアニメですら、動画1枚を2コマ撮影していて ―― 2コマベース、12fpsを基本として作られてるので…。1枚ずつ間引いて、12fps、全15フレームにしてみた。
12fpsにしたことで、ちょっとは手描きアニメっぽい雰囲気に近づいた気がする。
ちなみに、日本のアニメは、鉄腕アトムの頃から3コマベース、8fpsを基本として作られているので、2枚ずつ間引いて8fps、全11フレームにしてみた。
これでもまあ、そこそこアニメーションっぽい感じにはなるなと…。
もっとも…。
- 相変わらず、フレーム間の一貫性が皆無。
- 一時停止してコマ送りすると全フレームが作画崩壊状態。
それでも、例えばミュージックビデオ等の1カットでチラッと流してみるとか、エヴァTV版の最終回近辺のように、混乱しているキャラの精神世界を表現、といった使い方なら、こういう動画もイケそうな気もする。
それはそれとして。黒人のおじさんが走ってる動画から、こういう動画を生成できてしまうという点は、結構悪くないのではないかと。
◎ テストその3 :
ここ最近の ControlNet には、reference_only というプリプロセッサが追加されて、ソレを通すと、1枚の画像に沿った感じの生成画像を得ることができるらしい。もしかして、ソレを使えば、フレーム間に一貫性があるアニメーション動画が作れたりするのでは…?
そんなわけで試してみたのだけど…。
生成された画像の画質が何故か盛大に荒れてしまった…。まるで、VHS3倍録画でダビングを繰り返したような低画質ぶり…。どうしてこんなことになるんだろう…。
そんなわけで試してみたのだけど…。
parameters 1 girl, solo, black short hair, red camisole, red miniskirt, black globes, white sneakers, running, (((background is simple and flat and white))), ((masterpiece, bets best quality)), Negative prompt: (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, (monochrome), (grayscale), bad anatomy, extra arms, extra legs, missing arms, missing legs, bad arms, bad legs, Steps: 15, Sampler: DDIM, CFG scale: 9, Seed: 1434010576, Size: 512x512, Model hash: 4f24a26d75, Model: animelike25D_animelike25DV11Pruned, Clip skip: 2, ControlNet 0: "preprocessor: openpose, model: control_v11p_sd15_openpose [cab727d4], weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 64, 64)", ControlNet 1: "preprocessor: reference_only, model: None, weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: True, control mode: Balanced, preprocessor params: (64, 0.8, 64)"
生成された画像の画質が何故か盛大に荒れてしまった…。まるで、VHS3倍録画でダビングを繰り返したような低画質ぶり…。どうしてこんなことになるんだろう…。
◎ 余談。OpenPoseを使うメリット :
OpenPoseを経由させることで、元動画に含まれていた、人物の性別、年齢、人種と言った情報は削除されるので…。OpenPoseには、元動画とは異質な「ガワ」を動かすことに使えるというメリットがありそうだなと…。
もっとも、そうして得られるかもしれない成果物に新規性は無さそうでもあり。そういったことは、モーションキャプチャ+3DCGで、随分前から実現しちゃってるので…。
更に、OpenPose は3D的なモーションキャプチャと違って、2Dの情報しか得られないあたりはデメリットかもしれない。OpenPoseによって得られた2D座標から、3D的にはどういう状態になっているのかを推測し直す処理が、本来は必要になるのではないかなと…。
ただ、逆に考えると、OpenPoseは2D座標しか得られないが故に、手描きアニメとの類似性が出てくるメリットもありそうな気もしていて…。手描きアニメは、3Dで厳密に計算して描かれているものではなく、2D的な見た目を模倣して描かれているものだから…。あくまで2Dでしか処理できない点は、手描きアニメに近づけたいという目的があった場合、逆に美味しかったりしないかと。
もっとも、そうして得られるかもしれない成果物に新規性は無さそうでもあり。そういったことは、モーションキャプチャ+3DCGで、随分前から実現しちゃってるので…。
更に、OpenPose は3D的なモーションキャプチャと違って、2Dの情報しか得られないあたりはデメリットかもしれない。OpenPoseによって得られた2D座標から、3D的にはどういう状態になっているのかを推測し直す処理が、本来は必要になるのではないかなと…。
ただ、逆に考えると、OpenPoseは2D座標しか得られないが故に、手描きアニメとの類似性が出てくるメリットもありそうな気もしていて…。手描きアニメは、3Dで厳密に計算して描かれているものではなく、2D的な見た目を模倣して描かれているものだから…。あくまで2Dでしか処理できない点は、手描きアニメに近づけたいという目的があった場合、逆に美味しかったりしないかと。
◎ 余談。アニメのフレームレートについて :
手描きアニメのフレームレートは12fps、もしくは8fpsと書いてしまったけど、実際はそう単純ではなくて。
瞬間瞬間によって、1コマで動かしたり、3〜4コマで動かしたりするのが手描きアニメ。いわば、24fpsを上限とした可変フレームレートに近いと言えるのかもしれない。
例えば、板野サーカスで有名な板野一郎さんのインタビュー記事を読むと、「ミサイルがカメラに近い時は1コマで、少し離れた位置なら2コマで、遠くを飛んでる時には3〜4コマで動かしてる」といった発言があったりするし。
あるいは、宮崎駿監督にとっての先輩アニメーター、故・大塚康生さんは、生前、「今の日本のTVアニメは大半がフルアニメになってるから、フルアニメなんて言葉は現状では死語」的なことを発言してたりする。 *2
そんな状況なので、手描きアニメだから12fps、あるいは8fps、ということではないのだけど…。ただ、コンピュータで自動的に作った何かしらの映像を、手描きアニメの雰囲気に少しでも近づけたいと思った時、安易ではあるのだけど、12fpsや8fpsにしてしまうのは、結構有効だよなと。
しかし、だからと言って、たったそれだけで手描きアニメにクリソツになるわけでもない、ということは意識しておかないといけないよなと。手描きアニメを舐めるなよ。瞬間瞬間で、人間の感覚でしっくりくるよう、臨機応変に表現しているのが手描きアニメなんじゃい。みたいな。
更に余談。3DCGアニメスタジオのオレンジの社長さんが、「3DCGのセルルック映像を手描きアニメに近づけようと3コマベースにしたらなんだかガクガク動いてるように見えた」「2コマベースにしたら、何故か手描きアニメの動きに近づいたような気がした」と発言してたことがあって。
もしかすると、コンピュータで自動生成した映像は、8fpsより12fpsにしたほうが手描きアニメ風になるのだろうか、という疑問が湧いたりもして。実際、前述の動画でも、8fpsより12fpsのほうが、なんだかちょっとそれらしい動きに見える感じもする…。
瞬間瞬間によって、1コマで動かしたり、3〜4コマで動かしたりするのが手描きアニメ。いわば、24fpsを上限とした可変フレームレートに近いと言えるのかもしれない。
例えば、板野サーカスで有名な板野一郎さんのインタビュー記事を読むと、「ミサイルがカメラに近い時は1コマで、少し離れた位置なら2コマで、遠くを飛んでる時には3〜4コマで動かしてる」といった発言があったりするし。
あるいは、宮崎駿監督にとっての先輩アニメーター、故・大塚康生さんは、生前、「今の日本のTVアニメは大半がフルアニメになってるから、フルアニメなんて言葉は現状では死語」的なことを発言してたりする。 *2
そんな状況なので、手描きアニメだから12fps、あるいは8fps、ということではないのだけど…。ただ、コンピュータで自動的に作った何かしらの映像を、手描きアニメの雰囲気に少しでも近づけたいと思った時、安易ではあるのだけど、12fpsや8fpsにしてしまうのは、結構有効だよなと。
しかし、だからと言って、たったそれだけで手描きアニメにクリソツになるわけでもない、ということは意識しておかないといけないよなと。手描きアニメを舐めるなよ。瞬間瞬間で、人間の感覚でしっくりくるよう、臨機応変に表現しているのが手描きアニメなんじゃい。みたいな。
更に余談。3DCGアニメスタジオのオレンジの社長さんが、「3DCGのセルルック映像を手描きアニメに近づけようと3コマベースにしたらなんだかガクガク動いてるように見えた」「2コマベースにしたら、何故か手描きアニメの動きに近づいたような気がした」と発言してたことがあって。
もしかすると、コンピュータで自動生成した映像は、8fpsより12fpsにしたほうが手描きアニメ風になるのだろうか、という疑問が湧いたりもして。実際、前述の動画でも、8fpsより12fpsのほうが、なんだかちょっとそれらしい動きに見える感じもする…。
[ ツッコむ ]
#2 [nitijyou] 日記をアップロード
2023/05/01を最後に日記をアップロードしてなかったのでアップロード。
[ ツッコむ ]
2023/05/21(日) [n年前の日記]
#1 [python] PythonとImageHashを使って画像を比較
Pythonを使って、画像を比較して類似度を調べたい。ググってみたら ImageHash というモジュールが使えそうなので試してみる。
環境は、Windows10 x64 22H2 + Python 3.10.6。
環境は、Windows10 x64 22H2 + Python 3.10.6。
◎ 参考ページ :
_【Python】画像の類似度比較が可能なImageHashのインストール | ジコログ
_Python 類似ハッシュ用いて 類似画像を削除する方法 imagehash Pillow | FascodeNetwork Blog
_Python の類似画像ライブラリ ImageHash を Windows で使う | Aqua Ware つぶやきブログ
_ImageHash - PyPI
_GitHub - JohannesBuchner/imagehash: A Python Perceptual Image Hashing Module
_imagehash/setup.py at master - JohannesBuchner/imagehash - GitHub
_Python 類似ハッシュ用いて 類似画像を削除する方法 imagehash Pillow | FascodeNetwork Blog
_Python の類似画像ライブラリ ImageHash を Windows で使う | Aqua Ware つぶやきブログ
_ImageHash - PyPI
_GitHub - JohannesBuchner/imagehash: A Python Perceptual Image Hashing Module
_imagehash/setup.py at master - JohannesBuchner/imagehash - GitHub
◎ 必要なモジュールをインストール :
setup.py を眺めた感じでは、以下のモジュールも必要になるらしい。
pipでインストールする。
numpy scipy pillow PyWavelets
pipでインストールする。
pip install numpy -U pip install scipy -U pip install pillow -U pip install PyWavelets -U pip install ImageHash -U
> pip list | grep -e "numpy" -e "scipy" -e "Pillow" -e "PyWavelets" -e "ImageHash" ImageHash 4.3.1 numpy 1.24.3 Pillow 9.5.0 PyWavelets 1.4.1 scipy 1.10.1
◎ 使い方 :
使い方のサンプルは、前述のページを参考に。
同じ画像ならハッシュの差は0になるし、違う画像ならハッシュの差は0以外になるっぽい。画像内容がどのくらいかけ離れていたらどんな値が出てくるのかはちょっとよく分からない。
from PIL import Image import imagehash file1 = "images/src/RE4IqsU_1920x1080.jpg" file2 = "images/dst/RE4IqsU_1920x1080.jpg" # file2 = "images/dst/RE4NSAw_1920x1080.jpg" hash_src = imagehash.average_hash(Image.open(file1)) hash_dst = imagehash.average_hash(Image.open(file2)) print(hash_src == hash_dst) print(hash_src - hash_dst)
同じ画像ならハッシュの差は0になるし、違う画像ならハッシュの差は0以外になるっぽい。画像内容がどのくらいかけ離れていたらどんな値が出てくるのかはちょっとよく分からない。
◎ ディレクトリ単位で比較 :
二つのディレクトリを渡して、同じファイル名のjpgがあったら、中身も似てるのかどうか確認して結果を出してみるスクリプトを書いてみた。
_imgdircmp.py
python imgdircmp.py DIR1 DIR2
_imgdircmp.py
import sys
import os
import re
from PIL import Image
import imagehash
def get_files(dirpath):
files = {}
for file in os.listdir(dirpath):
if re.search("\.jpg$", file):
path = os.path.join(dirpath, file)
if os.path.isfile(path):
files[file.lower()] = file
return files
def main():
if len(sys.argv) != 3:
print("Error: usage python script.py DIR1 DIR2")
_ = input("\nPush any key")
sys.exit()
srcdir = sys.argv[1]
dstdir = sys.argv[2]
print("Dir A: %s" % srcdir)
print("Dir B: %s" % dstdir)
files_a = get_files(srcdir)
files_b = get_files(dstdir)
for file in files_a.keys():
if file in files_b:
rfile_a = files_a[file]
rfile_b = files_b[file]
path_a = os.path.join(srcdir, rfile_a)
path_b = os.path.join(dstdir, rfile_b)
hash_a = imagehash.average_hash(Image.open(path_a))
hash_b = imagehash.average_hash(Image.open(path_b))
if hash_a - hash_b == 0:
print("Same image : %s" % rfile_a)
else:
print("Different image : %s" % rfile_a)
_ = input("\nPush any key")
if __name__ == '__main__':
main()
[ ツッコむ ]
2023/05/22(月) [n年前の日記]
#1 [cg_tools] FILMでフレーム補間ができそうか試してみた
FILM (Frame Interpolation for Large Motion) という、AIでフレーム補間をしてくれるプログラムがあるらしい。Googleが開発したそうで、2枚の画像を与えると中間画像を生成してくれるのだとか。
_GitHub - google-research/frame-interpolation: FILM: Frame Interpolation for Large Motion, In ECCV 2022.
_【フレーム補間】2枚の画像から動画を生成できるFILMのインストール | ジコログ
_StableDiffusionとFILM( Frame Interpolation for Large Motion)を使ってアニメーション生成プログラムを作ってみた - Qiita
_[FILM] 動かしながらざっくり理解するフレーム間の中間画像生成 - TeDokology
_【フレーム補間】FILMを使ってフレーム補間を実装する - つくもちブログ ?Python&AIまとめ?
_画像をぬるぬる動かすFrame Interpolation for Large Motion【FILM】 | FarmL
気になったので、ローカルで動かせないか試してみた。環境は以下。
_GitHub - google-research/frame-interpolation: FILM: Frame Interpolation for Large Motion, In ECCV 2022.
_【フレーム補間】2枚の画像から動画を生成できるFILMのインストール | ジコログ
_StableDiffusionとFILM( Frame Interpolation for Large Motion)を使ってアニメーション生成プログラムを作ってみた - Qiita
_[FILM] 動かしながらざっくり理解するフレーム間の中間画像生成 - TeDokology
_【フレーム補間】FILMを使ってフレーム補間を実装する - つくもちブログ ?Python&AIまとめ?
_画像をぬるぬる動かすFrame Interpolation for Large Motion【FILM】 | FarmL
気になったので、ローカルで動かせないか試してみた。環境は以下。
- Windows10 x64 22H2
- Python 3.9.13 64bit, Python 3.10.6 64bit
- CPU : AMD Ryzen 5 5600X
- GPU : NVIDIA GeForce GTX1060 6GB
- RAM : 16GB
◎ 必要なもの :
解説ページによると、FILM を動かすためには、ffmpeg に加えて、Python のモジュール、TensorFlow が必要になるらしい。
そして、その TensorFlow は、CUDA と cuDNN が必要になるそうで…。tensorflow 2.6.0 - 2.11.0 を動かす際は、CUDA 11.2、cuDNN 8.1 のバージョンで決め打ちされてるらしい。
_【フレーム補間】2枚の画像から動画を生成できるFILMのインストール | ジコログ
つまり、以下が必要になる。
ffmpeg は以下から入手できる。自分の環境には ffmpeg 6.0 をインストール済み。
_Download FFmpeg
そして、その TensorFlow は、CUDA と cuDNN が必要になるそうで…。tensorflow 2.6.0 - 2.11.0 を動かす際は、CUDA 11.2、cuDNN 8.1 のバージョンで決め打ちされてるらしい。
_【フレーム補間】2枚の画像から動画を生成できるFILMのインストール | ジコログ
つまり、以下が必要になる。
- ffmpeg
- Python 3.x
- TensorFlow
- CUDA 11.2
- cuDNN 8.1
ffmpeg は以下から入手できる。自分の環境には ffmpeg 6.0 をインストール済み。
_Download FFmpeg
◎ CUDAの異なるバージョンの共存 :
自分の手元の環境では、画像生成AI Stable Diffusion web UI を動かすために、CUDA 11.8 がインストール済み。TensorFlow を動かすための CUDA 11.2 とはバージョンが一致してない。ここはバージョンが異なる CUDA を共存させないといけない。
ただ、CUDAは環境変数を変更するだけで共存させて利用できる、という話を見かけた。
_異なるバージョンのCUDAを使い分ける単純な方法 - Qiita
_CUDA複数バージョンインストール後のシステム環境変数の変更 | きんたろうのIT日記
であればと、CUDA 11.2 と cuDNN 8.1 を追加でインストールしてみた。
CUDA と cuDNN は以下から入手できる。入手にはNVIDIAのアカウントが必要。
_CUDA Toolkit Archive | NVIDIA Developer
_cuDNN Archive | NVIDIA Developer
以下の2つのファイルを入手。
CUDA 11.2.2 のセットアップファイルを実行してインストール。今回は、D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\ にインストールした。
cuDNNのzipファイルを解凍。中に入ってた cuda というフォルダを、CUDA 11.2.2 のインストール場所にコピーしてインストールする。
CUDA、cuDNN関係の環境変数としては、以下が作成されていた。
更に、環境変数PATHの最初のほうに、以下のようなパスが追加された。
また、以下のページによると、環境変数PATHに、もう少しパスを追加しないといけないらしい。
_frame-interpolation/WINDOWS_INSTALLATION.md at main - google-research/frame-interpolation - GitHub
こういった環境変数については、今回、setenv.bat というBATファイルを作成して対応することにした。
今後、FILM関係の実験をする時は、DOS窓の中で setenv.bat を実行して、必要な環境変数を上書き設定してから実験することにした。尚、DOS窓を終了すれば上書き設定した環境変数は消えて、いつもの状態に戻る。
setenv.bat
ただ、CUDAは環境変数を変更するだけで共存させて利用できる、という話を見かけた。
_異なるバージョンのCUDAを使い分ける単純な方法 - Qiita
_CUDA複数バージョンインストール後のシステム環境変数の変更 | きんたろうのIT日記
であればと、CUDA 11.2 と cuDNN 8.1 を追加でインストールしてみた。
CUDA と cuDNN は以下から入手できる。入手にはNVIDIAのアカウントが必要。
_CUDA Toolkit Archive | NVIDIA Developer
_cuDNN Archive | NVIDIA Developer
以下の2つのファイルを入手。
- cuda_11.2.2_461.33_win10.exe
- cudnn-11.2-windows-x64-v8.1.1.33.zip
CUDA 11.2.2 のセットアップファイルを実行してインストール。今回は、D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\ にインストールした。
cuDNNのzipファイルを解凍。中に入ってた cuda というフォルダを、CUDA 11.2.2 のインストール場所にコピーしてインストールする。
CUDA、cuDNN関係の環境変数としては、以下が作成されていた。
CUDA_PATH=D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8 CUDA_PATH_V11_2=D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2 CUDA_PATH_V11_8=D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8 CUDNN_PATH=D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8
更に、環境変数PATHの最初のほうに、以下のようなパスが追加された。
D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\bin D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\libnvvp D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\libnvvp
また、以下のページによると、環境変数PATHに、もう少しパスを追加しないといけないらしい。
_frame-interpolation/WINDOWS_INSTALLATION.md at main - google-research/frame-interpolation - GitHub
Add the following paths to your 'Advanced System Settings' > 'Environment Variables ...' > Edit 'Path', and add:
<INSTALL_PATH>\NVIDIA GPU Computing Toolkit\CUDA\v11.2\bin
<INSTALL_PATH>\NVIDIA GPU Computing Toolkit\CUDA\v11.2\libnvvp
<INSTALL_PATH>\NVIDIA GPU Computing Toolkit\CUDA\v11.2\include
<INSTALL_PATH>\NVIDIA GPU Computing Toolkit\CUDA\v11.2\extras\CUPTI\lib64
<INSTALL_PATH>\NVIDIA GPU Computing Toolkit\CUDA\v11.2\cuda\bin
こういった環境変数については、今回、setenv.bat というBATファイルを作成して対応することにした。
今後、FILM関係の実験をする時は、DOS窓の中で setenv.bat を実行して、必要な環境変数を上書き設定してから実験することにした。尚、DOS窓を終了すれば上書き設定した環境変数は消えて、いつもの状態に戻る。
setenv.bat
set CUDA_PATH=%CUDA_PATH_V11_2% set CUDNN_PATH=%CUDA_PATH_V11_2% set ADDPATH=%CUDA_PATH%\bin;%CUDA_PATH%\libnvvp;%CUDA_PATH%\include;%CUDA_PATH%\extras\CUPTI\lib64;%CUDA_PATH%\cuda\bin set PATH=%ADDPATH%;%PATH%
◎ FILMをgitで取得 :
FILM のプロジェクトファイル群を、github からクローンしてくる。今回は、D:\aiwork\film\ というディレクトリを作成して、その中にクローンしてみた。
_GitHub - google-research/frame-interpolation: FILM: Frame Interpolation for Large Motion, In ECCV 2022.
D:\aiwork\film\ の中に、frame-interpolation というディレクトリが作られて、その中にファイル群が入っている状態になった。
_GitHub - google-research/frame-interpolation: FILM: Frame Interpolation for Large Motion, In ECCV 2022.
git clone https://github.com/google-research/frame-interpolation.git
D:\aiwork\film\ の中に、frame-interpolation というディレクトリが作られて、その中にファイル群が入っている状態になった。
◎ Pythonの仮想環境を作成 :
さて、ここからPythonのモジュールをインストールしていくのだけど…。膨大な数のモジュールが必要になるらしいので、そのまま作業をしていくと、普段使ってるPython環境がグチャグチャになるだろうなと…。
また、自分が普段使ってる Python 3.10 で FILM を利用しようとすると色々なエラーが出てしまう。そもそも、FILM が使う、TensorFlow 2.6.2 がインストールできない。FILM が推奨している Python 3.9 なら、TensorFlow 2.6.2 もインストールできたし、エラーの数がかなり少なくなった。
そんなわけで、Python 3.9 の仮想環境を venv で作成して、その中に各モジュールをインストールしていくことにする。
ちなみに、Windows上で Python 3.9 の仮想環境を作るためには、おそらく事前に Python 3.9 のインストールが必要。また、異なるバージョンの Python を使い分ける際は、py -3.9 や py -3.10 と打てばいい。
今回は、D:\aiwork\film\frame-interpolation\ 以下に pyvenv39 というディレクトリを作成して、その中にPythonの仮想環境を入れることにした。
仮想環境に切り替える時は以下を打つ。
抜ける時は、以下を打つ。
また、自分が普段使ってる Python 3.10 で FILM を利用しようとすると色々なエラーが出てしまう。そもそも、FILM が使う、TensorFlow 2.6.2 がインストールできない。FILM が推奨している Python 3.9 なら、TensorFlow 2.6.2 もインストールできたし、エラーの数がかなり少なくなった。
そんなわけで、Python 3.9 の仮想環境を venv で作成して、その中に各モジュールをインストールしていくことにする。
ちなみに、Windows上で Python 3.9 の仮想環境を作るためには、おそらく事前に Python 3.9 のインストールが必要。また、異なるバージョンの Python を使い分ける際は、py -3.9 や py -3.10 と打てばいい。
> py -3.9 -V Python 3.9.13 > py -3.10 -V Python 3.10.6
今回は、D:\aiwork\film\frame-interpolation\ 以下に pyvenv39 というディレクトリを作成して、その中にPythonの仮想環境を入れることにした。
cd /d D:\aiwork\film\frame-interpolation mkdir pyvenv39 py -3.9 -m venv pyvenv39
仮想環境に切り替える時は以下を打つ。
pyvenv39\Scripts\activate.bat
抜ける時は、以下を打つ。
pyvenv39\Scripts\deactivate.bat
◎ Pythonモジュールをインストール :
仮想環境に入った状態で、pip を使ってモジュールをインストールしていく。
git で clone してきた FILM のファイル群の中に、必要なPythonモジュールが列挙された requirements.txt というファイルがあるので、本来であれば、コレを指定するだけでインストールできるはずなのだけど…。
ところが、このファイル、各モジュールのバージョンが指定されていて…。
ちなみに、ググってたら、以下のような話も…。
_pipを使用してTensorFlowをインストールします
つまり、TensorFlow を Python 3.10 + GPU で使いたいなら、TensorFlow 2.10以前で使えそうなバージョンを探さないといけない。最新版の TensorFlow 2.12.0 をインストールしたらGPUが使えなかったので、おかしいと思った…。ちなみに、2.10以前をインストールしたい場合は、以下のように打つらしい。
今回は、Python 3.9 を使うことで、以下のバージョンでモジュールをインストールすることができた。absl-py と、apache-beam が、元々のバージョンとは違ってしまっている。
pyvenv39\Scripts\activate.bat pip list
git で clone してきた FILM のファイル群の中に、必要なPythonモジュールが列挙された requirements.txt というファイルがあるので、本来であれば、コレを指定するだけでインストールできるはずなのだけど…。
pip install -r requirements.txt
ところが、このファイル、各モジュールのバージョンが指定されていて…。
- Python 3.10 で利用すると、そもそも最初に記述されている TensorFlow 2.6.2 がインストールできなくて詰む。
- Python 3.9 で利用すれば多少はマシになるけれど、それでも一部でエラーが出る。
ちなみに、ググってたら、以下のような話も…。
_pipを使用してTensorFlowをインストールします
注意: TensorFlow 2.10ネイティブ Windows で GPU をサポートした最後のTensorFlow リリースです。
TensorFlow 2.11以降では、 WSL2 に TensorFlow をインストールするか、
tensorflowまたはtensorflow-cpuをインストールして、必要に応じてTensorFlow-DirectML-Pluginを試す必要があります。
つまり、TensorFlow を Python 3.10 + GPU で使いたいなら、TensorFlow 2.10以前で使えそうなバージョンを探さないといけない。最新版の TensorFlow 2.12.0 をインストールしたらGPUが使えなかったので、おかしいと思った…。ちなみに、2.10以前をインストールしたい場合は、以下のように打つらしい。
pip install "tensorflow<2.11"
今回は、Python 3.9 を使うことで、以下のバージョンでモジュールをインストールすることができた。absl-py と、apache-beam が、元々のバージョンとは違ってしまっている。
tensorflow==2.6.2 tensorflow-datasets==4.4.0 tensorflow-addons==0.15.0 absl-py==0.15.0 gin-config==0.5.0 parameterized==0.8.1 mediapy==1.0.3 scikit-image==0.19.1 apache-beam==2.47.0 google-cloud-bigquery-storage==1.1.0 natsort==8.1.0 gdown==4.5.4 tqdm==4.64.1
◎ 学習モデルデータを入手 :
FILM用の学習モデルデータを入手。
_pretrained_models - Google ドライブ
film_net と vgg というフォルダがあるので、2つともダウンロードする。
frame-interpolation\ 内に、pretrained_models という名前のフォルダを作成して、その中に入れる。フォルダ構成は以下のようになる。
_pretrained_models - Google ドライブ
film_net と vgg というフォルダがあるので、2つともダウンロードする。
frame-interpolation\ 内に、pretrained_models という名前のフォルダを作成して、その中に入れる。フォルダ構成は以下のようになる。
D:\AIWORK\FILM\FRAME-INTERPOLATION\PRETRAINED_MODELS
├─ film_net
│ ├─ L1
│ │ └─ saved_model
│ │ │ keras_metadata.pb
│ │ │ saved_model.pb
│ │ │
│ │ ├─ assets
│ │ └─ variables
│ │ variables.data-00000-of-00001
│ │ variables.index
│ │
│ ├─ Style
│ │ └─ saved_model
│ │ │ keras_metadata.pb
│ │ │ saved_model.pb
│ │ │
│ │ ├─ assets
│ │ └─ variables
│ │ variables.data-00000-of-00001
│ │ variables.index
│ │
│ └─ VGG
│ └─ saved_model
│ │ keras_metadata.pb
│ │ saved_model.pb
│ │
│ ├─ assets
│ └─ variables
│ variables.data-00000-of-00001
│ variables.index
│
└─ vgg
imagenet-vgg-verydeep-19.mat
◎ GPUが使えそうか調べる :
TensorFlow が GPUを使える状態になっているのか確認しておく。
まず、バージョンを確認。
TensorFlow 2.6.2 がインストールされていることが分かった。
GPUが使えそうか確認。
出力された結果の中に、GPU関連の情報が出てきたら、たぶん大丈夫。GPUが使えない状態の時は、CPUの情報しか出てこない…。Python 3.10.6 + TensorFlow 2.12.0 の時は、CPUの情報しか出てこなかった…。
まず、バージョンを確認。
python -c "import tensorflow as tf;print(tf.__version__)"
(pyvenv39) D:\aiwork\film\frame-interpolation>python -c "import tensorflow as tf;print(tf.__version__)" 2.6.2
TensorFlow 2.6.2 がインストールされていることが分かった。
GPUが使えそうか確認。
python -c "from tensorflow.python.client import device_lib;print(device_lib.list_local_devices())"
>python -c "from tensorflow.python.client import device_lib;print(device_lib.list_local_devices())"
2023-05-22 04:55:19.841520: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-05-22 04:55:20.188459: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /device:GPU:0 with 4622 MB memory: -> device: 0, name: NVIDIA GeForce GTX 1060 6GB, pci bus id: 0000:09:00.0, compute capability: 6.1
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 1099761069420990849
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 4846518272
locality {
bus_id: 1
links {
}
}
incarnation: 14526750838141541425
physical_device_desc: "device: 0, name: NVIDIA GeForce GTX 1060 6GB, pci bus id: 0000:09:00.0, compute capability: 6.1"
]
出力された結果の中に、GPU関連の情報が出てきたら、たぶん大丈夫。GPUが使えない状態の時は、CPUの情報しか出てこない…。Python 3.10.6 + TensorFlow 2.12.0 の時は、CPUの情報しか出てこなかった…。
◎ FILMを使ってみる :
これで環境設定はできたはず。長かった…。実際に FILM を使ってみる。
photosディレクトリの中に、one.png、two.png という2つの画像ファイルがあるので、この2つの画像の中間画像を生成させて、photos/output_middle.png として保存してみる。
妙なメッセージがたくさん出てきた。どうやら、「メモリ不足になった」と言われてる気がする…。VRAM 6GB では足りませんか…。ただ、「失敗してるわけではないよ」「メモリがもっとあればパフォーマンスが上がるんだけどなあ」と言われてるようにも見える。
とりあえず、こんな状態でも、output_middle.png は得られた。
次は動画を作ってみる。画像が入ってるフォルダ(photos)を指定して、動画で出力してみる。
これもまた、大量にエラーメッセージらしきものが出てきた…。メモリ不足はもちろんのこと、なんだかよく分からないアドレス値まで…。
それでも一応、photosディレクトリの中に、動画と連番画像が作成された。
ちなみに、Python 3.9 ではなく、Python 3.10 で動かした際には、動画生成終了時に謎のエラーメッセージが大量に出てきたのだけど、Python 3.9 で動かした場合は、そういったエラーメッセージは表示されなかった。
しかし、何かサンプル画像を出してみないと、どんな感じの成果物が得られるのか分らんよな…。Stable Diffusion web UI を使って、何かそれっぽい画像を生成して試してみよう…。
photosディレクトリの中に、one.png、two.png という2つの画像ファイルがあるので、この2つの画像の中間画像を生成させて、photos/output_middle.png として保存してみる。
python -m eval.interpolator_test --frame1 photos/one.png --frame2 photos/two.png --model_path pretrained_models/film_net/Style/saved_model --output_frame photos/output_middle.png
>python -m eval.interpolator_test --frame1 photos/one.png --frame2 photos/two.png --model_path pretrained_models/film_net/Style/saved_model --output_frame photos/output_middle.png 2023-05-22 04:57:51.982771: W tensorflow/core/common_runtime/bfc_allocator.cc:272] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.55GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2023-05-22 04:57:52.312263: W tensorflow/core/common_runtime/bfc_allocator.cc:272] Allocator (GPU_0_bfc) ran out of memory trying to allocate 3.40GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2023-05-22 04:57:52.471599: W tensorflow/core/common_runtime/bfc_allocator.cc:272] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.09GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2023-05-22 04:57:53.004908: W tensorflow/core/common_runtime/bfc_allocator.cc:272] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.74GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2023-05-22 04:57:53.177009: W tensorflow/core/common_runtime/bfc_allocator.cc:272] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.15GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2023-05-22 04:57:53.218532: W tensorflow/core/common_runtime/bfc_allocator.cc:272] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.02GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2023-05-22 04:57:53.279325: W tensorflow/core/common_runtime/bfc_allocator.cc:272] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.03GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2023-05-22 04:57:53.289617: W tensorflow/core/common_runtime/bfc_allocator.cc:272] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.03GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2023-05-22 04:57:53.425091: W tensorflow/core/common_runtime/bfc_allocator.cc:272] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.03GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2023-05-22 04:57:53.474574: W tensorflow/core/common_runtime/bfc_allocator.cc:272] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.03GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
妙なメッセージがたくさん出てきた。どうやら、「メモリ不足になった」と言われてる気がする…。VRAM 6GB では足りませんか…。ただ、「失敗してるわけではないよ」「メモリがもっとあればパフォーマンスが上がるんだけどなあ」と言われてるようにも見える。
とりあえず、こんな状態でも、output_middle.png は得られた。
次は動画を作ってみる。画像が入ってるフォルダ(photos)を指定して、動画で出力してみる。
python -m eval.interpolator_cli --pattern "photos" --model_path pretrained_models/film_net/Style/saved_model --times_to_interpolate 6 --output_video
これもまた、大量にエラーメッセージらしきものが出てきた…。メモリ不足はもちろんのこと、なんだかよく分からないアドレス値まで…。
それでも一応、photosディレクトリの中に、動画と連番画像が作成された。
ちなみに、Python 3.9 ではなく、Python 3.10 で動かした際には、動画生成終了時に謎のエラーメッセージが大量に出てきたのだけど、Python 3.9 で動かした場合は、そういったエラーメッセージは表示されなかった。
しかし、何かサンプル画像を出してみないと、どんな感じの成果物が得られるのか分らんよな…。Stable Diffusion web UI を使って、何かそれっぽい画像を生成して試してみよう…。
◎ 2023/05/23追記 :
画像生成AI Stable Diffusion web UIで生成した画像を元にして、FILMでフレーム補間して動画を作ってみた。
元画像は以下の2枚。


これをFILMに渡して、63枚の中間画像を作成。途中のフレームを何枚か削除して、動きがリニア(線形、直線的)ではない感じに調整。AviUtl + 拡張編集プラグインで、連番画像として読み込んで、ループ再生するように配置。512x512、24fpsのmp4として出力。
画像生成AIが出力した画像なので、背景が違ってしまっていて、見た目がちょっとアレだけど…。こういった紛い物の画像ではなく、実世界の本当の写真画像を元にして処理すれば、おそらく奇麗な生成結果が得られそうではあるなと…。
中間画像の生成時にt値を指定できたら、もうちょっと使い道がありそうな気もする。リニアな動きでしか出力できないのはちょっと…。まあ、出力された連番画像からテキトーに画像を削除することで対応できなくはないけれど、最初から イージング(?)が使えたらなあ…。
_イージング関数チートシート
待てよ? AviUtlでイージング使って再生速度を変化させればいいのかな…?
ところで、全然違う画像を渡して処理させたら、なかなか悲しい結果になった。



この結果からすると、手描きアニメの原画をいきなり渡して中割りしろ、なんて処理はまだまだ無理だよなあ、と…。
ただ、人間が中割りを描いて動画にして、その動画を中割り、というかフレーム補間して単純に枚数を増やす、といった感じなら使えなくもない…? でも、そういう処理なら After Effects でも可能だったりしそう。使ったことないから知らんけど。
元画像は以下の2枚。
これをFILMに渡して、63枚の中間画像を作成。途中のフレームを何枚か削除して、動きがリニア(線形、直線的)ではない感じに調整。AviUtl + 拡張編集プラグインで、連番画像として読み込んで、ループ再生するように配置。512x512、24fpsのmp4として出力。
画像生成AIが出力した画像なので、背景が違ってしまっていて、見た目がちょっとアレだけど…。こういった紛い物の画像ではなく、実世界の本当の写真画像を元にして処理すれば、おそらく奇麗な生成結果が得られそうではあるなと…。
中間画像の生成時にt値を指定できたら、もうちょっと使い道がありそうな気もする。リニアな動きでしか出力できないのはちょっと…。まあ、出力された連番画像からテキトーに画像を削除することで対応できなくはないけれど、最初から イージング(?)が使えたらなあ…。
_イージング関数チートシート
待てよ? AviUtlでイージング使って再生速度を変化させればいいのかな…?
ところで、全然違う画像を渡して処理させたら、なかなか悲しい結果になった。
この結果からすると、手描きアニメの原画をいきなり渡して中割りしろ、なんて処理はまだまだ無理だよなあ、と…。
ただ、人間が中割りを描いて動画にして、その動画を中割り、というかフレーム補間して単純に枚数を増やす、といった感じなら使えなくもない…? でも、そういう処理なら After Effects でも可能だったりしそう。使ったことないから知らんけど。
[ ツッコむ ]
#2 [cg_tools] Stable Diffusion web UIを再インストールした
画像生成AI Stable Diffusion web UI がエラーを出して動かなくなってしまったので再インストールした、とメモ。
ちなみに現行版は、処理に必要なファイル等を、実際に使う段階になってからダウンロードしてインストールするようになっていた模様。
ちなみに現行版は、処理に必要なファイル等を、実際に使う段階になってからダウンロードしてインストールするようになっていた模様。
◎ 壊してしまった経緯 :
Stable Diffusion web UI の中には、Python の仮想環境が入っている。venv というディレクトリがソレ。
せっかくだからと、色々なモジュールを pip install -U hoge でアップデートしていったのだけど…。そんなことをしていたら、Stable Diffusion web UIが動かなくなってしまった。webui-user.bat を実行すると、よく分からないエラーが出て、そこで止まってしまう。
ということで、面倒臭いから再インストールすることにした。
インストールの仕方は、「Stable Diffusion web UI インストール」でググれば解説ページがたくさん出てくるので…。
ところで、再インストール後に気づいたけれど、おそらく以下の2つのモジュールのバージョンが関係してたのではないかなと…。
そのまま pip でインストールすると、
何にせよ、Stable Diffusion web UI の、Python仮想環境内の各モジュールは、とにかく最新版にすればいいというものではないのだなと…。
- venv\Scripts\activate.bat を実行すると、仮想環境に切り替えることができる。
- その状態で pip list と打つと、インストールされているPythonモジュールの一覧が得られる。
- pip list -o と打てば、更新可能なモジュールの一覧が表示される。
せっかくだからと、色々なモジュールを pip install -U hoge でアップデートしていったのだけど…。そんなことをしていたら、Stable Diffusion web UIが動かなくなってしまった。webui-user.bat を実行すると、よく分からないエラーが出て、そこで止まってしまう。
ということで、面倒臭いから再インストールすることにした。
インストールの仕方は、「Stable Diffusion web UI インストール」でググれば解説ページがたくさん出てくるので…。
ところで、再インストール後に気づいたけれど、おそらく以下の2つのモジュールのバージョンが関係してたのではないかなと…。
torch 2.0.1+cu118 torchvision 0.15.2+cu118
そのまま pip でインストールすると、
- torch 2.0.2, 2.0.1, 2.0.0
- torchvision 0.15.2
何にせよ、Stable Diffusion web UI の、Python仮想環境内の各モジュールは、とにかく最新版にすればいいというものではないのだなと…。
[ ツッコむ ]
2023/05/23(火) [n年前の日記]
#1 [cg_tools] 画像生成AIで生成した画像をFILMとAviUtlで動かしてみる
画像生成AI Stable Diffusion web UI で生成した画像を動かしてみたい。
手順の流れとしては以下。
とりあえず、成果物を先に出しとく。
左肩や髪のあたりがおかしいとか、瞬きをしてないから怖いとか、人間の動きじゃないとか、色々問題はあるだろうけど…。それでもまあ、AIが生成した画像を、(この程度の動きでも良いのであれば)一応動画にできるようではあるなと。
作業手順をメモしておく。ちなみに環境は以下。
手順の流れとしては以下。
- Stable Diffusion web UIで、2枚の人物画像と背景画像を生成。
- フレーム補間ツール FILM で中間画像ファイル群を生成。
- 動画編集ソフト AviUtl で読み込んで再生速度にイージングをつけて動画にする。
とりあえず、成果物を先に出しとく。
左肩や髪のあたりがおかしいとか、瞬きをしてないから怖いとか、人間の動きじゃないとか、色々問題はあるだろうけど…。それでもまあ、AIが生成した画像を、(この程度の動きでも良いのであれば)一応動画にできるようではあるなと。
作業手順をメモしておく。ちなみに環境は以下。
- Windows10 x64 22H2
- CPU : AMD Ryzen 5 5600X
- GPU : NVIDIA GeForce GTX1060 6GB
- RAM : 16GB
- AviUtl 1.10
◎ 元になる素材画像を用意する :
画像生成AI Stable Diffusion web UI を使って、似た感じの人物画像を2枚、加えて、背景画像を1枚、生成した。ちなみに、LoRAを使えば、人物の顔をある程度統一できそうな気はする。



◎ 人物画像の背景を消去 :
画像生成AIが生成した人物画像は、人物部分はともかく、背景部分が全然違う。
このままだとフレーム補間で中間画像を作った際におかしなことになるので、人物の背景を消去して透過部分にしてしまって、別の背景画像を合成してしまうことにした。
Stable Diffusion web UI には、人物画像の背景部分を消去してくれる拡張機能がいくつか存在している。今回は、sd_katanuki という拡張機能を利用させてもらった。ありがたや。
_GitHub - aka7774/sd_katanuki: Anime Image Background Remover for AUTOMATIC1111
_【sd_katanuki】画像の背景を一括で透明化や白背景化してくれる拡張機能の紹介!【Stable Diffusion】 | 悠々ログ
人物の背景部分がある程度消去できた。


フリンジが残っていたり、髪の毛のあたりがちょっとアレなのが気になるし、処理時間は若干かかるというか、待たされている感じはあるのだけど、それでも、手作業での切り抜き作業と比べたら、圧倒的に早く目的を果たせる感じはする。
切り抜いた人物画像に対して、GIMP 2.10.34 Portable を使って、背景画像を合成。以下のような感じになった。


このぐらいの画像になってくれれば、フレーム補間ツールもそれなりに処理をしてくれるだろう…。
このままだとフレーム補間で中間画像を作った際におかしなことになるので、人物の背景を消去して透過部分にしてしまって、別の背景画像を合成してしまうことにした。
Stable Diffusion web UI には、人物画像の背景部分を消去してくれる拡張機能がいくつか存在している。今回は、sd_katanuki という拡張機能を利用させてもらった。ありがたや。
_GitHub - aka7774/sd_katanuki: Anime Image Background Remover for AUTOMATIC1111
_【sd_katanuki】画像の背景を一括で透明化や白背景化してくれる拡張機能の紹介!【Stable Diffusion】 | 悠々ログ
人物の背景部分がある程度消去できた。
フリンジが残っていたり、髪の毛のあたりがちょっとアレなのが気になるし、処理時間は若干かかるというか、待たされている感じはあるのだけど、それでも、手作業での切り抜き作業と比べたら、圧倒的に早く目的を果たせる感じはする。
切り抜いた人物画像に対して、GIMP 2.10.34 Portable を使って、背景画像を合成。以下のような感じになった。
このぐらいの画像になってくれれば、フレーム補間ツールもそれなりに処理をしてくれるだろう…。
◎ FILMで中間画像を生成 :
Googleが開発したフレーム補間ツール、FILM を使って、2枚の画像から中間画像を生成した。全部で65枚の画像が得られた。
0000.png - 0064.png にリネームして、連番画像にしておく。
FILMの導入の仕方、使い方については、 _昨日の日記メモ が参考になるかもしれない。
0000.png - 0064.png にリネームして、連番画像にしておく。
FILMの導入の仕方、使い方については、 _昨日の日記メモ が参考になるかもしれない。
◎ AviUtl+拡張編集プラグインで連番画像を読み込み :
出来上がった連番画像を、動画編集ソフト AviUtl + 拡張編集プラグインを使って動画にしていく。読み込んだ動画(連番画像)に対して、再生速度にイージングを適用していくことで、多少はそれっぽい動きになってくれることを期待する。
ここから先は、自分も作業手順を忘れそうなので、スクリーンショットを貼ってメモしていく…。3日後には忘れてそう…。
まずはプロジェクトを新規作成。拡張編集ウインドウの上で右クリック。「新規プロジェクトの作成」を選択。
元になる連番画像のサイズに合わせて、512x512、24fpsにしておく。
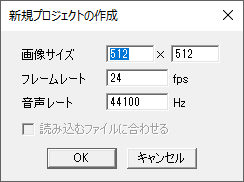
連番画像を動画として読み込む。右クリック → メディアオブジェクトの追加 → 動画ファイル。
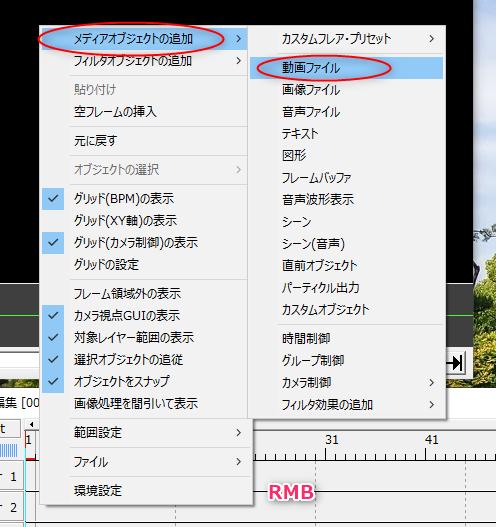
動画ファイルオブジェクトのプロパティウインドウが開くので、「参照ファイル」をクリック。
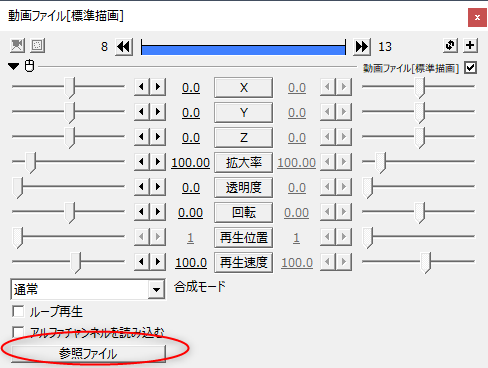
連番画像の一番最初のファイルを選択して「開く」。
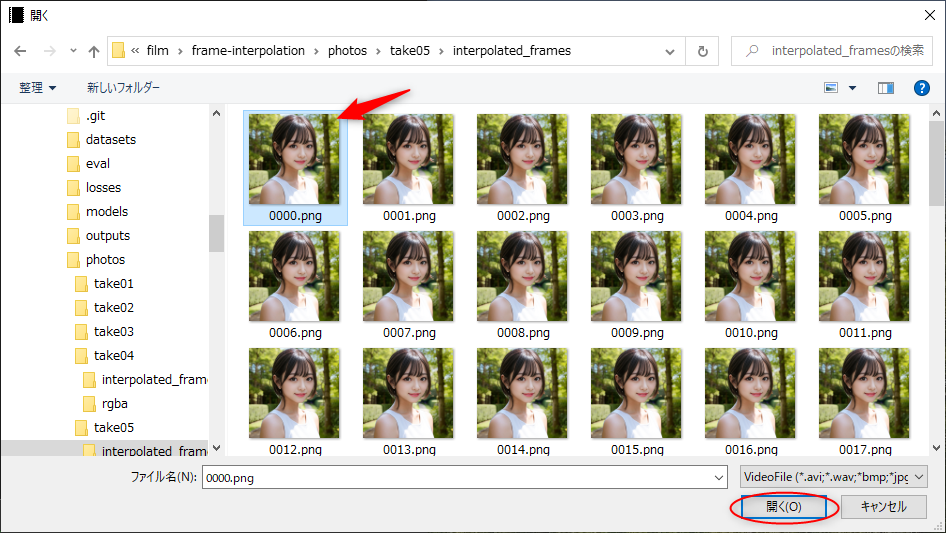
これで、連番画像を読み込んで、動画ファイルとして配置することができた。
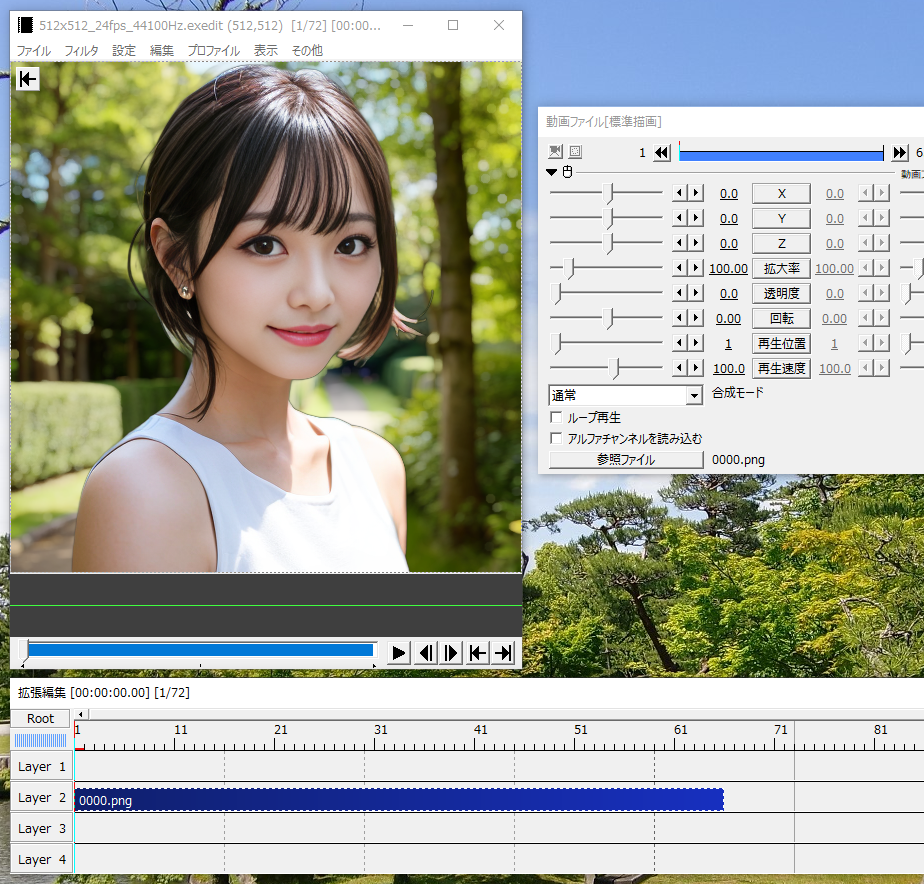
ここから先は、自分も作業手順を忘れそうなので、スクリーンショットを貼ってメモしていく…。3日後には忘れてそう…。
まずはプロジェクトを新規作成。拡張編集ウインドウの上で右クリック。「新規プロジェクトの作成」を選択。
元になる連番画像のサイズに合わせて、512x512、24fpsにしておく。
連番画像を動画として読み込む。右クリック → メディアオブジェクトの追加 → 動画ファイル。
動画ファイルオブジェクトのプロパティウインドウが開くので、「参照ファイル」をクリック。
連番画像の一番最初のファイルを選択して「開く」。
これで、連番画像を読み込んで、動画ファイルとして配置することができた。
◎ ループ動画にするために動画ファイルを複製 :
1 → 2 → 1 と再生されるようなループ動画を作ってみたいので、読み込んだ動画(連番画像)をコピペで増やして配置する。

◎ 動画を早送り、逆再生 :
前半の動画、1 → 2 に相当する部分は、若干早送りで再生して尺を短くしたい。動画ファイルのプロパティウインドウで、再生速度を、100 から 150 に変更。これで、元の動画の150%の速度で再生されて、尺はその分短くなる。
例えばこの値を200にすれば倍速再生になるし、50にすれば1/2の速度でスロー再生される、らしい。
後半部分は、2 → 1 と再生されるようにしたいので、逆再生を指定する。再生速度にマイナス値を設定すると逆再生になってくれる。
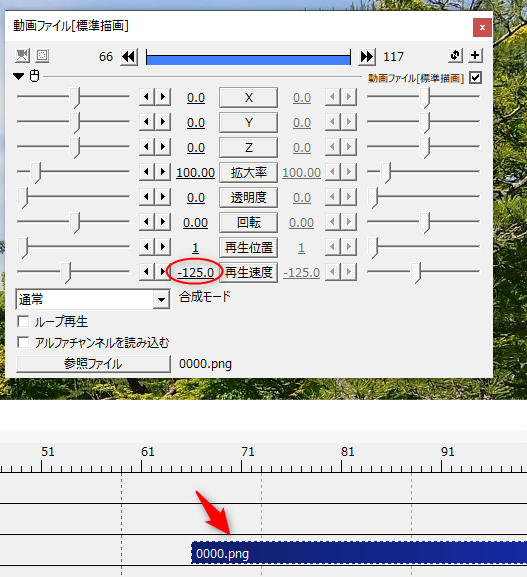
例えばこの値を200にすれば倍速再生になるし、50にすれば1/2の速度でスロー再生される、らしい。
後半部分は、2 → 1 と再生されるようにしたいので、逆再生を指定する。再生速度にマイナス値を設定すると逆再生になってくれる。
◎ 再生速度にイージングをかける :
このまま再生すると、フレーム補間で作った中間画像がリニア(線形)で再生されて、機械的な動きになってしまう。イージングと呼ばれる加速/減速をつけてやることで、多少は自然な動きになるようにしたい。
再生速度、というか再生位置を調整するオブジェクトとして、「時間制御」というオブジェクトがあるらしいので、ソレを追加する。右クリック → メディアオブジェクトの追加 → 時間制御。
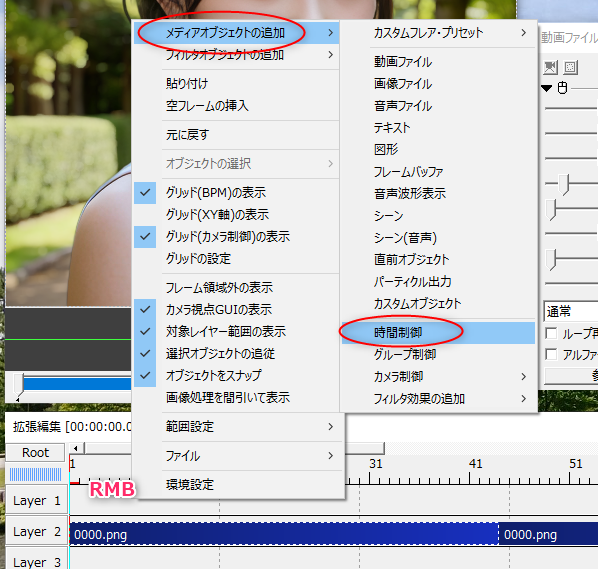
AviUtl でイージングを実現するスクリプトは色々あるようだけど、今回は、「イージングスクリプト トラックバー対応版」を利用させてもらうことにした。
_AviUtl イージングの悩みをあっさり解決。導入から使い方・2020年版まで初心者でもわかる。 - Aviutl簡単使い方入門|すんなりわかる動画編集
_AviUtlで必須のスクリプト、イージング(トラックバー版) - FLAPPER
もっと細かくタイミングを指定をしたい場合は、グラフを描画して調整していくタイプのプラグインやスクリプトを利用することになるのだと思う。
_AviUtl、イージングをウィンドウ上で編集するCurve Editor - FLAPPER
_GitHub - mimaraka/aviutl-plugin-curve_editor: Curve Editor - 様々なイージングをウィンドウ上で編集
_AviUtlのイージングをカスタマイズ、マルチベジェ軌道 - FLAPPER
時間制御オブジェクトのプロパティウインドウ上で、「位置」をクリックして、easing_normal@uf_easing を選択。
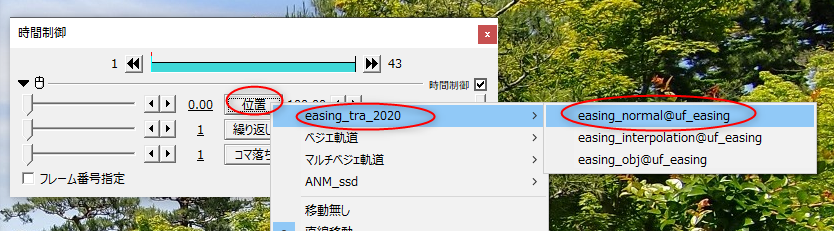
イージングの種類を指定しないといけない。「位置」をクリックして、「設定」を選ぶ。
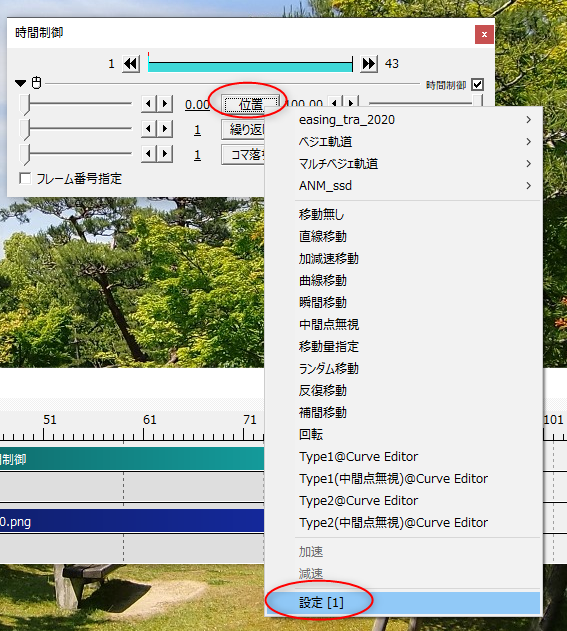
表示された「移動フレーム間隔」というウインドウ上で、イージングの種類番号を入力してEnter。
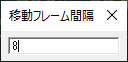
イージング種類は、イージングスクリプトに同梱されている画像を参考にする。一応引用しておきます。

再生速度、というか再生位置を調整するオブジェクトとして、「時間制御」というオブジェクトがあるらしいので、ソレを追加する。右クリック → メディアオブジェクトの追加 → 時間制御。
AviUtl でイージングを実現するスクリプトは色々あるようだけど、今回は、「イージングスクリプト トラックバー対応版」を利用させてもらうことにした。
_AviUtl イージングの悩みをあっさり解決。導入から使い方・2020年版まで初心者でもわかる。 - Aviutl簡単使い方入門|すんなりわかる動画編集
_AviUtlで必須のスクリプト、イージング(トラックバー版) - FLAPPER
もっと細かくタイミングを指定をしたい場合は、グラフを描画して調整していくタイプのプラグインやスクリプトを利用することになるのだと思う。
_AviUtl、イージングをウィンドウ上で編集するCurve Editor - FLAPPER
_GitHub - mimaraka/aviutl-plugin-curve_editor: Curve Editor - 様々なイージングをウィンドウ上で編集
_AviUtlのイージングをカスタマイズ、マルチベジェ軌道 - FLAPPER
時間制御オブジェクトのプロパティウインドウ上で、「位置」をクリックして、easing_normal@uf_easing を選択。
イージングの種類を指定しないといけない。「位置」をクリックして、「設定」を選ぶ。
表示された「移動フレーム間隔」というウインドウ上で、イージングの種類番号を入力してEnter。
イージング種類は、イージングスクリプトに同梱されている画像を参考にする。一応引用しておきます。
◎ 終了フレームを指定 :
動画の終了フレームを指定。最後のフレームを表示した状態にしてから、右クリック → 範囲設定 → 現在位置を最終フレーム。
これで、再生速度にイージングをつけた状態の動画を作成することができた。
後は、連番画像として保存してからffmpegでmp4動画にしてもいいし、いきなり mp4 で出力できるプラグインを導入してもいい。
_AviUtlの連番画像の読み込みと出力のやり方を初心者にもわかりやすく解説 - Aviutl簡単使い方入門|すんなりわかる動画編集
_AviUtl 物置 - JPN takeshima
_GitHub - rigaya/x264guiEx: 拡張 x264 出力(GUI) Ex
これで、再生速度にイージングをつけた状態の動画を作成することができた。
後は、連番画像として保存してからffmpegでmp4動画にしてもいいし、いきなり mp4 で出力できるプラグインを導入してもいい。
_AviUtlの連番画像の読み込みと出力のやり方を初心者にもわかりやすく解説 - Aviutl簡単使い方入門|すんなりわかる動画編集
_AviUtl 物置 - JPN takeshima
_GitHub - rigaya/x264guiEx: 拡張 x264 出力(GUI) Ex
◎ イージングの有無を比較 :
念のため、リニア(線形、直線的)な再生速度のまま出力した動画と、イージングをつけた動画を並べておく。
個人的にはイージングがついてるほうが良いと思うのだけど…どうだろうか…。
個人的にはイージングがついてるほうが良いと思うのだけど…どうだろうか…。
◎ 余談。コマを抜いたり増やしたりしたい :
もっと細かく、コマ(フレーム)を抜いたり増やしたりしてタイミング調整をしたいのだけど、そういう作業が向いている動画編集ソフトはないのだろうか…。それはもう、動画編集ではなく、アニメ制作ソフトのジャンルになってしまいそうな気もするけど…。
連番画像を読み込んで、このコマは使う、このコマは使わない、とチェックを入れて編集する、みたいな…。後から何度も、各コマの有効無効を切り替えて調整するだろうから、一般的な動画編集ソフトの、コマをズバッと削除して作業するソレとはちょっと違うソフトになりそうな気がする。ソフトには、そのコマが読み込まれているし、ずっと保持されているけど、プレビュー再生時は無効のコマをスキップして再生するだけ、みたいな…。まあ、需要が無いか…。
連番画像を読み込んで、このコマは使う、このコマは使わない、とチェックを入れて編集する、みたいな…。後から何度も、各コマの有効無効を切り替えて調整するだろうから、一般的な動画編集ソフトの、コマをズバッと削除して作業するソレとはちょっと違うソフトになりそうな気がする。ソフトには、そのコマが読み込まれているし、ずっと保持されているけど、プレビュー再生時は無効のコマをスキップして再生するだけ、みたいな…。まあ、需要が無いか…。
[ ツッコむ ]
#2 [anime] 「サイボーグ009 超銀河伝説」を視聴
BS12で放送されていたソレを録画していたので視聴。石ノ森章太郎先生の漫画作品「サイボーグ009」のアニメ映画。
「サイボーグ009」は、最初の頃は東映動画がアニメ化していて、カラーになったTVアニメ2作目はサンライズがアニメ化していたそうで。しかもサンライズ版は、後に「ダグラム」「ボトムズ」を世に出す高橋良輔監督が担当。
そしてこの映画は、サンライズ版の後に作られたらしいけど…。サンライズではなく東映動画が制作したようで…。1980年12月に公開。 *1 監督さんも、高橋監督ではなく、明比正行監督が担当。
感想としては…。なかなか厳しい。1979年公開の「劇場版銀河鉄道999」の次の年の作品だけど、「999の後に、これかあ…」という気分に…。
とりあえず、サイボーグ戦士の若干一名が大変なことになるのだけど、ラスト近辺で更に大変なことに…。見ていて、「オイオイ。それでいいの?」と思ってしまった。散々サイボーグ戦士の悲哀を台詞で語っておきながら、何故そうなる…。まあ、シリーズ物は基本設定を迂闊に変更できないから大変ですなあ、という気分だけが残りました。
音楽がすぎやまこういち先生の担当だったらしいけど、演歌調の曲が多く、コレ本当にすぎやま先生なんでしょうか、当時はこういう作風だったのでしょうか、という疑問が…。編曲にお弟子さん達の名前が並んでるけど、それらの方々の作風なのかなあ…。あるいは監督やPが演歌調ばかり要求してきたのだろうか…。
視聴後、気になって関連情報をググってたのだけど、気になる話がチラホラ…。元々はりんたろう監督が担当する予定だったけど脚本がなかなかできなかったので降りちゃったとか。なんだか納得。この脚本ではなあ…。
りんたろう監督が担当してたら、脚本面はともかくとして、映像的にはもうちょっと観れるものになってたんだろうなと…。というか、あの頃のりんたろう監督の作家性って、かなり貴重だった気がする。
例えば、「劇場版999」「さよ銀」で、メーテルが登場する時はどんな見せ方をしていたか。それを思い返しながら、この作品のゲスト美女の登場の仕方を眺めると…。素人ながら、「どうしてこんなコンテでOKと思えるんだ…」と…。特別感、皆無。いやまあ、りんたろう監督が凄かったということだろうけど。フツーの演出家さんが作るとこうなるんだろうな…。
「サイボーグ009」は、最初の頃は東映動画がアニメ化していて、カラーになったTVアニメ2作目はサンライズがアニメ化していたそうで。しかもサンライズ版は、後に「ダグラム」「ボトムズ」を世に出す高橋良輔監督が担当。
そしてこの映画は、サンライズ版の後に作られたらしいけど…。サンライズではなく東映動画が制作したようで…。1980年12月に公開。 *1 監督さんも、高橋監督ではなく、明比正行監督が担当。
感想としては…。なかなか厳しい。1979年公開の「劇場版銀河鉄道999」の次の年の作品だけど、「999の後に、これかあ…」という気分に…。
とりあえず、サイボーグ戦士の若干一名が大変なことになるのだけど、ラスト近辺で更に大変なことに…。見ていて、「オイオイ。それでいいの?」と思ってしまった。散々サイボーグ戦士の悲哀を台詞で語っておきながら、何故そうなる…。まあ、シリーズ物は基本設定を迂闊に変更できないから大変ですなあ、という気分だけが残りました。
音楽がすぎやまこういち先生の担当だったらしいけど、演歌調の曲が多く、コレ本当にすぎやま先生なんでしょうか、当時はこういう作風だったのでしょうか、という疑問が…。編曲にお弟子さん達の名前が並んでるけど、それらの方々の作風なのかなあ…。あるいは監督やPが演歌調ばかり要求してきたのだろうか…。
視聴後、気になって関連情報をググってたのだけど、気になる話がチラホラ…。元々はりんたろう監督が担当する予定だったけど脚本がなかなかできなかったので降りちゃったとか。なんだか納得。この脚本ではなあ…。
りんたろう監督が担当してたら、脚本面はともかくとして、映像的にはもうちょっと観れるものになってたんだろうなと…。というか、あの頃のりんたろう監督の作家性って、かなり貴重だった気がする。
例えば、「劇場版999」「さよ銀」で、メーテルが登場する時はどんな見せ方をしていたか。それを思い返しながら、この作品のゲスト美女の登場の仕方を眺めると…。素人ながら、「どうしてこんなコンテでOKと思えるんだ…」と…。特別感、皆無。いやまあ、りんたろう監督が凄かったということだろうけど。フツーの演出家さんが作るとこうなるんだろうな…。
◎ ジェフ・シーガルさんが謎過ぎる :
公開当時、「『STAR WARS』の脚本を担当したジェフ・シーガルが脚本作りに協力」と宣伝してたらしいのだけど。この、ジェフ・シーガルさん、「STAR WARS」のスタッフに名を連ねていないという…。何者なんだ。ジェフ・シーガル。
気になってググったけれど、実はコミック版の制作に関係してる人だったのに脚本家と間違えられてしまったという説があったりするようで…。記者会見でも、「ルーカスに二言三言アドバイスしただけ」と答えていて、ガッチリ関わったわけじゃないよと一応本人も弁明してるとか…。一体どこで「STAR WARS」の脚本家扱いになってしまったのやら…。
ただ、この手の映像制作に全く関わってない人物、というわけでもないようで。色々な作品に関わっていたのは間違いないっぽい。ますます謎。何者なんだ…。
気になってググったけれど、実はコミック版の制作に関係してる人だったのに脚本家と間違えられてしまったという説があったりするようで…。記者会見でも、「ルーカスに二言三言アドバイスしただけ」と答えていて、ガッチリ関わったわけじゃないよと一応本人も弁明してるとか…。一体どこで「STAR WARS」の脚本家扱いになってしまったのやら…。
ただ、この手の映像制作に全く関わってない人物、というわけでもないようで。色々な作品に関わっていたのは間違いないっぽい。ますます謎。何者なんだ…。
*1: 東映動画ではなくて東映アニメーションではないの? と思ったけど、東映アニメーションに名前が変わったのは、1998年だったらしい。
[ ツッコむ ]
2023/05/24(水) [n年前の日記]
#1 [gimp][cg_tools] GIMPでモーフィングができないか調べてる
フレーム補間ツール FILM を使っているうちに、コレってモーフィングでも似たような結果を得られそうだなと思えてきた。たしかGIMPでも、モーフィング処理ができたような気がするな ―― と調べ始めてしまった。
少なくとも、Windows版 GIMP 2.10.34 Portable + G'MIC 3.2.4 なら、Deformations/Morph (Interactive) というフィルタがあって、それを使えばモーフィングができる、と分かった。実際に少し試してみたけど、たしかにそれっぽいモノを生成できた。
ただ、朧げな記憶では、GIMP + GAP (GIMP Animation Package)でもモーフィングができたような…。そっちのやり方はどうだったっけ? と調べ直しているところ。
そもそも、Windows版 GIMP 2.10 で、GAP は使えただろうか? GIMP 2.6, 2.8 でしか動かなかった記憶もあるのだろうけど。
少なくとも、Windows版 GIMP 2.10.34 Portable + G'MIC 3.2.4 なら、Deformations/Morph (Interactive) というフィルタがあって、それを使えばモーフィングができる、と分かった。実際に少し試してみたけど、たしかにそれっぽいモノを生成できた。
ただ、朧げな記憶では、GIMP + GAP (GIMP Animation Package)でもモーフィングができたような…。そっちのやり方はどうだったっけ? と調べ直しているところ。
そもそも、Windows版 GIMP 2.10 で、GAP は使えただろうか? GIMP 2.6, 2.8 でしか動かなかった記憶もあるのだろうけど。
[ ツッコむ ]
2023/05/25(木) [n年前の日記]
#1 [gimp] GIMPでモーフィングをしてみる手順をメモ
無料で利用できる画像編集ソフト GIMP を使って、モーフィング処理ができそうかどうか試してみたので、作業手順をメモ。
モーフィングと言うのは、2枚の異なる画像から、その中間の画像を生成する処理、という説明でいいのだろうか…?
_モーフィング - Wikipedia
GIMPの標準機能だけではモーフィングはできないけれど、以下の組み合わせならモーフィングが使える。
とりあえず今回は、GIMP 2.10.34 Portable + G'MIC 3.2.4 でモーフィングができるか試してみた。
環境は、Windows10 x64 22H2 + GIMP 2.10.34 Portable。CPU は AMD Ryzen 5 5600X。
モーフィングと言うのは、2枚の異なる画像から、その中間の画像を生成する処理、という説明でいいのだろうか…?
_モーフィング - Wikipedia
GIMPの標準機能だけではモーフィングはできないけれど、以下の組み合わせならモーフィングが使える。
- GIMP + G'MIC
- GIMP + GAP (GIMP Animation Package)
とりあえず今回は、GIMP 2.10.34 Portable + G'MIC 3.2.4 でモーフィングができるか試してみた。
環境は、Windows10 x64 22H2 + GIMP 2.10.34 Portable。CPU は AMD Ryzen 5 5600X。
◎ 必要なソフト :
GIMP と G'MIC が必要。
_GIMP Portable (image editor) | PortableApps.com
_G'MIC - GREYC's Magic for Image Computing: A Full-Featured Open-Source Framework for Image Processing - Download
_GIMP Portable (image editor) | PortableApps.com
_G'MIC - GREYC's Magic for Image Computing: A Full-Featured Open-Source Framework for Image Processing - Download
◎ 作業手順 :
まず、元になる2枚の画像を、レイヤーとして読み込んでおく。
フィルター → G'MIC-Qt を選択。
Deformations の中の、Morph [Interactive] を選択する。
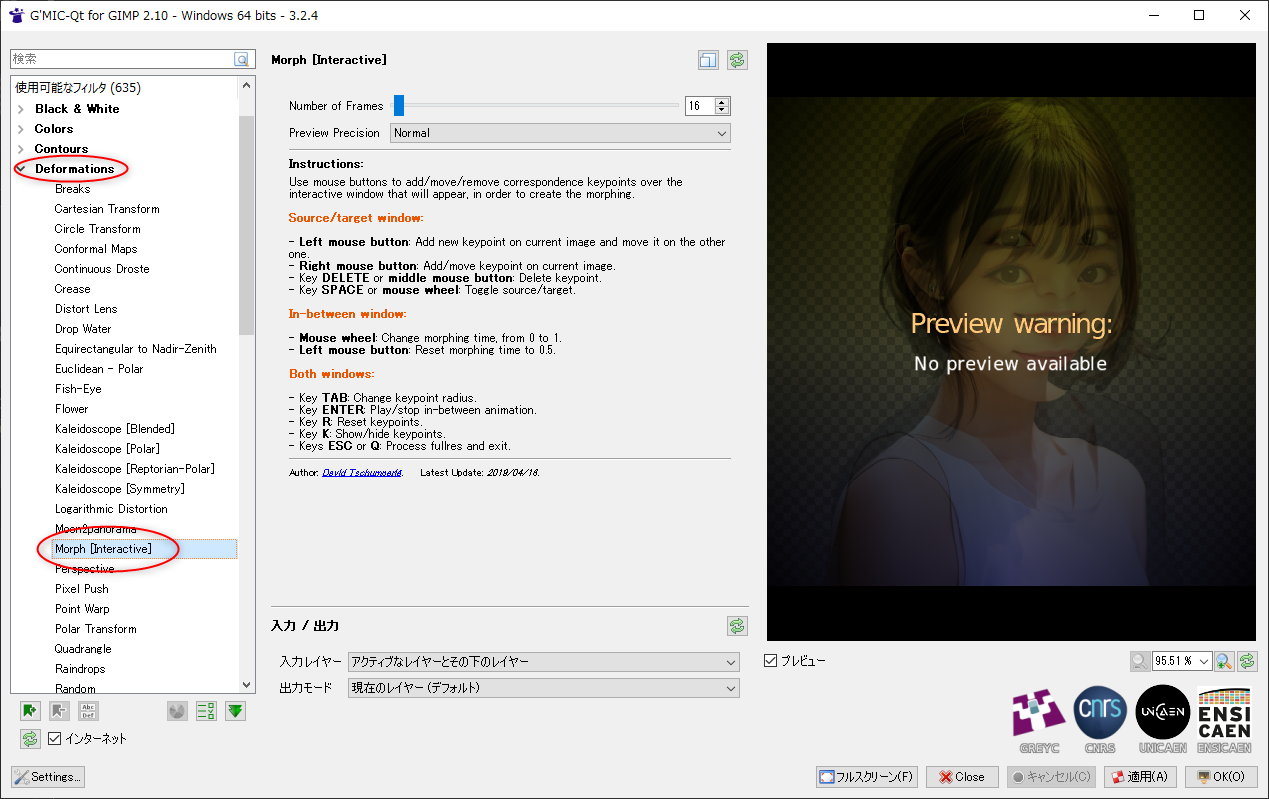
この画面で、中間画像を何枚作るか指定できる。Number of Frames で、必要な枚数を指定。
また、この画面ではショートカットキーが説明されてる。一応、以下に引用しておく。OCRで読み取った結果なので、綴りが間違ってるかもしれんけど…。
基本的にはマウス操作で、制御点(キーポイント)の追加/移動/削除をしていく模様。
念のため、ざっくりと日本語でもメモしておく。
さておき。「OK」ボタンをクリックすると、2つのウインドウが表示される。
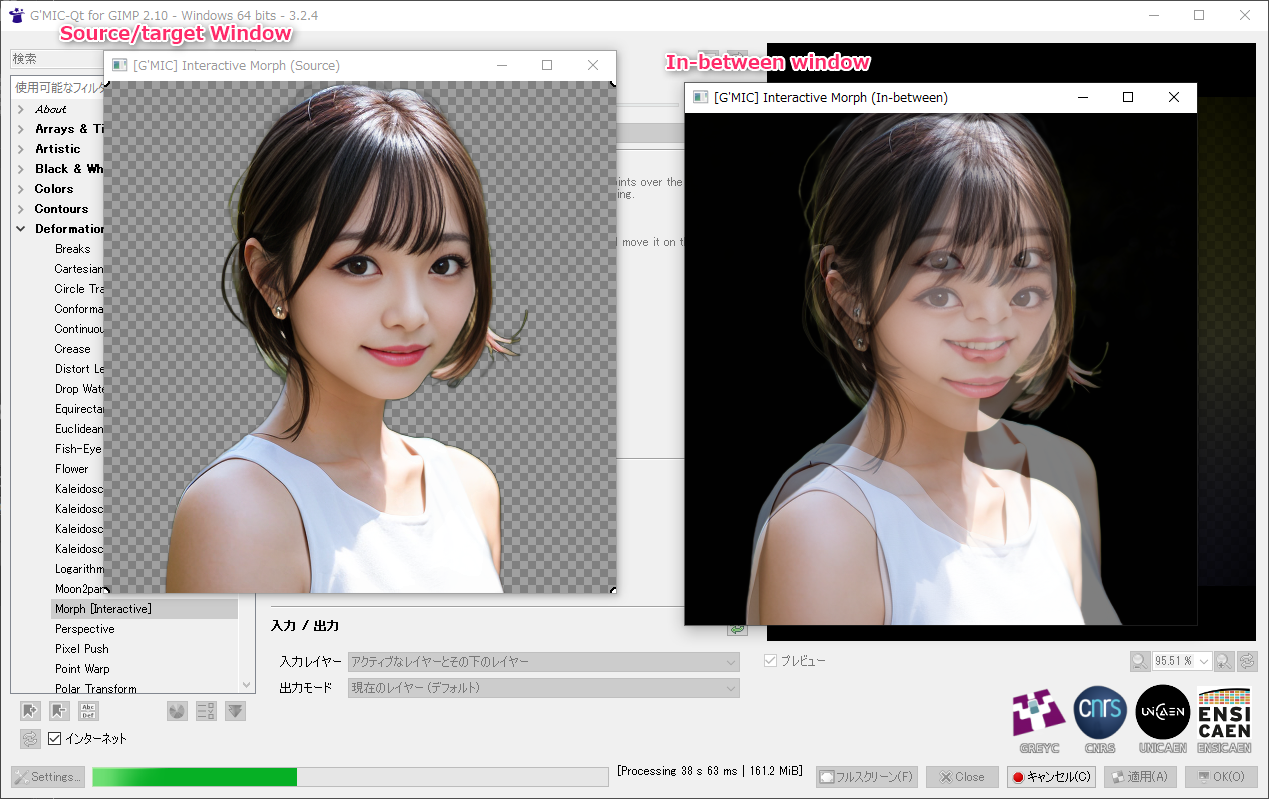
作業中は、G'MIC-Qtのウインドウの下のほうで、緑色の処理進行バーっぽいものがずっとアニメーションしてる。おそらく、「今現在 G'MIC が動いてますよ」と伝えてくれているのだと思う。
ソース/ターゲットウインドウは、ウインドウサイズを変更することもできるので、作業しやすい大きさに変更することを推奨。わざわざ小さいウインドウのままにしてチマチマと作業する必要はないです。

さて、ソース/ターゲットウインドウ上で、制御点(キーポイント)を追加していく。
この操作が、ちょっと説明しづらいのだけど…。
まあ、動画を見れば、なんとなくわかるだろうか…? 最初は戸惑うだろうけど、実際にやってみるとサクサク作業できるので、悪くない仕様だよなと…。
また、制御点を追加していくと、中間画像表示ウインドウ上の見た目がどんどん整っていくことが、上の動画でも分かるかと。
ちなみに、制御点を追加するたび、中間画像を全部生成し直しているようで…。制御点の数が増えてくると、目に見えて反応が遅くなってくる…。制御点を1つ追加するだけで数秒待たされる感じ…。
制御点を配置し終わったら、ソース/ターゲットウインドウの右上の閉じるボタンをクリックして、ウインドウを閉じる。すると、G'MICが中間画像を生成して、中間画像をGIMPのレイヤーとして追加してくれる。
この時、十数秒〜数十秒ほど待たされてしまうけど、ずっと計算処理をしている最中なので、フリーズしていると勘違いしないように。
GIMP上で、1フレーム=1レイヤーとして扱われている画像は、アニメーションを再生して様子を見ることができる。フィルター → アニメーション → 再生、を選択。
アニメーション再生ウインドウが開く。左上の再生ボタン(右向きの三角)をクリックすれば、再生される。
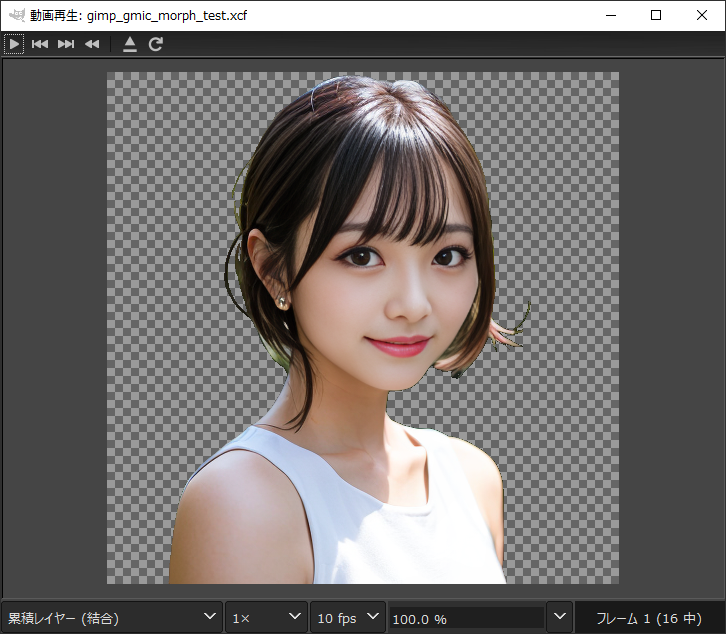
再生fpsを変更した場合は、上のほうの再読み込みボタンをクリックしないと反映されないので注意。
後は、アニメgifとして保存してもいいし、各レイヤーをエクスポートして連番画像にして動画編集ソフトに読み込んで使ってもいい。
ちなみに、各レイヤーをエクスポートできるプラグインは以下。何故か最初の一発目のpng保存でエラーが出て、再チャレンジすると正常にpng保存できるあたりが気になるけど…。
_Releases - kamilburda/gimp-export-layers
そんな感じで出来上がったアニメgifが以下になります。

頭のてっぺんのあたり、制御点の置き方を失敗している気がする…。そもそもこの元画像が、この手の処理のサンプル素材としては良くない気も…。でもまあ、これでモーフィングができることぐらいは分かるかなと。
フィルター → G'MIC-Qt を選択。
Deformations の中の、Morph [Interactive] を選択する。
この画面で、中間画像を何枚作るか指定できる。Number of Frames で、必要な枚数を指定。
また、この画面ではショートカットキーが説明されてる。一応、以下に引用しておく。OCRで読み取った結果なので、綴りが間違ってるかもしれんけど…。
Instructions: Use mouse buttons to add/move/remove correspondence keypoints over the interactive window that will appear, in order to create the morphing. Source/target window: - Left mouse button: Add new keypoint on current image and move it on the other one. - Right mouse button: Add/move keypoint on current image. - Key DELETE or middle mouse button: Delete keypoint. - Key SPACE or mouse wheel: Toggle source/target. In-between window: - Mouse wheel: Change morphing time, from 0 to 1. - Left mouse button: Reset morphing time to 0.5. Both windows: - Key TAB: Change keypoint radius. - Key ENTER Play/stop in-between animation. - Key R Reset keypoints. - Key K: Show/hide keypoints. - Keys ESC or Q: Process fullres and exit.
基本的にはマウス操作で、制御点(キーポイント)の追加/移動/削除をしていく模様。
念のため、ざっくりと日本語でもメモしておく。
ソース/ターゲットウインドウ : * 左ボタン : キーポイント追加、かつ、別画像に表示変更。 * 右ボタン : 現在画像上で、キーポイントの移動、もしくは追加。 * 中ボタン / Deleteキー : キーポイント削除。 * マウスホイール回転 / SPACEキー : ソースとターゲットの表示切替。 中間アニメーション表示ウインドウ : * マウスホイール : モーフィングタイム(現在表示中のフレーム)を、0から1の間で変更。 * 左ボタン : モーフィングタイムを0.5にリセット。 両方のウインドウ : * TABキー : キーポイントの半径(大きさ)を変更。 * Enterキー : 中間アニメーションの再生/停止。 * Rキー : キーポイントをリセット。全消去。 * Kキー : キーポイントの表示/非表示。 * Esc / Qキー : 処理をして終了。
さておき。「OK」ボタンをクリックすると、2つのウインドウが表示される。
- 1つが、ソース/ターゲットウインドウ。
- もう1つが、中間画像がどうなるかアニメーションで表示されるウインドウ。
作業中は、G'MIC-Qtのウインドウの下のほうで、緑色の処理進行バーっぽいものがずっとアニメーションしてる。おそらく、「今現在 G'MIC が動いてますよ」と伝えてくれているのだと思う。
ソース/ターゲットウインドウは、ウインドウサイズを変更することもできるので、作業しやすい大きさに変更することを推奨。わざわざ小さいウインドウのままにしてチマチマと作業する必要はないです。
さて、ソース/ターゲットウインドウ上で、制御点(キーポイント)を追加していく。
この操作が、ちょっと説明しづらいのだけど…。
- マウスの左ボタンを押した段階で、その位置に制御点が作られて、
- それと同時に、もう一つの画像に表示が切り替わるので、
- マウスの左ボタンを離さずにそのままドラッグして、
- 目標の位置に来たら、そこでようやく左ボタンを離す、
まあ、動画を見れば、なんとなくわかるだろうか…? 最初は戸惑うだろうけど、実際にやってみるとサクサク作業できるので、悪くない仕様だよなと…。
また、制御点を追加していくと、中間画像表示ウインドウ上の見た目がどんどん整っていくことが、上の動画でも分かるかと。
- マウスホイール回転、もしくは SPACEキーで、2枚の画像の表示を切り替えて様子を見たり。
- 右ボタンで、制御点の位置を変更したり。
- Enterキーを押して、中間画像をアニメーション表示して具合を見たり。
ちなみに、制御点を追加するたび、中間画像を全部生成し直しているようで…。制御点の数が増えてくると、目に見えて反応が遅くなってくる…。制御点を1つ追加するだけで数秒待たされる感じ…。
制御点を配置し終わったら、ソース/ターゲットウインドウの右上の閉じるボタンをクリックして、ウインドウを閉じる。すると、G'MICが中間画像を生成して、中間画像をGIMPのレイヤーとして追加してくれる。
この時、十数秒〜数十秒ほど待たされてしまうけど、ずっと計算処理をしている最中なので、フリーズしていると勘違いしないように。
GIMP上で、1フレーム=1レイヤーとして扱われている画像は、アニメーションを再生して様子を見ることができる。フィルター → アニメーション → 再生、を選択。
アニメーション再生ウインドウが開く。左上の再生ボタン(右向きの三角)をクリックすれば、再生される。
再生fpsを変更した場合は、上のほうの再読み込みボタンをクリックしないと反映されないので注意。
後は、アニメgifとして保存してもいいし、各レイヤーをエクスポートして連番画像にして動画編集ソフトに読み込んで使ってもいい。
ちなみに、各レイヤーをエクスポートできるプラグインは以下。何故か最初の一発目のpng保存でエラーが出て、再チャレンジすると正常にpng保存できるあたりが気になるけど…。
_Releases - kamilburda/gimp-export-layers
そんな感じで出来上がったアニメgifが以下になります。
頭のてっぺんのあたり、制御点の置き方を失敗している気がする…。そもそもこの元画像が、この手の処理のサンプル素材としては良くない気も…。でもまあ、これでモーフィングができることぐらいは分かるかなと。
◎ GIMPの減色処理を疑ってしまった :
GIMP 2.10.34 の減色処理というか、インデックスカラーへの変換処理が、なんだかおかしいような…? どうして一定間隔で白い点が入るの? ちなみに、GIMP 2.8.22 Portable でインデックスカラーに変換してみても同じ結果になったので、GIMP 2.10 でエンバグしてるわけではなさそう。まあ、元々 GIMP の減色処理は品質が非常に悪いというのが定評なのだけど…。
試しに、GIMP から各レイヤーをpngでエクスポートして、ffmpeg でアニメgifにしてみた。一旦パレット画像(palette.png)を抽出してから、そのパレット画像を元に減色してアニメgifにする方法を試している。

GIMPで生成した版と比べると、アルファチャンネルに対してディザをかけられなくて、しきい値で2値化されてしまうのがアレだけど、それ以外はGIMPの処理結果より全然マシに見える。
以下のページが参考になった。ありがたや。
_ffmpeg で 256色を最適化する palettegen, paletteuse | ニコラボ
_ffmpegでGIFアニメを作る - 脳内メモ++
と、ここまで書いて気が付いた。もしかして、GIMPのソレは透過部分にディザをかけているのがいかんのではないか。ffmpeg と同様に、アルファチャンネルをしきい値で2値化したら違う結果にならないか…? 試してみた。

一定間隔で点々が入ってない。つまり元画像のアルファチャンネルに微妙な値が入ってしまっていたのが原因だった模様。GIMPの減色処理の品質云々は、冤罪だった…。
試しに、GIMP から各レイヤーをpngでエクスポートして、ffmpeg でアニメgifにしてみた。一旦パレット画像(palette.png)を抽出してから、そのパレット画像を元に減色してアニメgifにする方法を試している。
ffmpeg -i export_layers\%04d.png -vf palettegen=max_colors=256:reserve_transparent=1:transparency_color=lime:stats_mode=full -update 1 -frames:v 1 palette.png -y ffmpeg -f image2 -framerate 12 -r 12 -i export_layers\%04d.png -i palette.png -filter_complex paletteuse=dither=bayer:bayer_scale=2 -r 12 gimp_gmic_morph_test_by_ffmpeg.gif -y
GIMPで生成した版と比べると、アルファチャンネルに対してディザをかけられなくて、しきい値で2値化されてしまうのがアレだけど、それ以外はGIMPの処理結果より全然マシに見える。
以下のページが参考になった。ありがたや。
_ffmpeg で 256色を最適化する palettegen, paletteuse | ニコラボ
_ffmpegでGIFアニメを作る - 脳内メモ++
と、ここまで書いて気が付いた。もしかして、GIMPのソレは透過部分にディザをかけているのがいかんのではないか。ffmpeg と同様に、アルファチャンネルをしきい値で2値化したら違う結果にならないか…? 試してみた。
一定間隔で点々が入ってない。つまり元画像のアルファチャンネルに微妙な値が入ってしまっていたのが原因だった模様。GIMPの減色処理の品質云々は、冤罪だった…。
◎ GAPのモーフィングについて :
GIMP + G'MIC だけではなく、GIMP + GAP でもモーフィングはできるのだけど…。
- 作業ウインドウ上で画像の拡大表示ができない。Windowsの拡大鏡等を併用しないとツライ。
- 左右に画像が表示されていて、その間をマウスカーソルが行き来することになる。
- 結果をプレビュー再生できない。
◎ フレーム補間とモーフィングについて :
先日利用したフレーム補間ツール FILM と、今回利用したモーフィングについて、違いは何だろうと考えてみたのだけど…。
フレーム補間は、制御点を人間様が指定しなくても済むのは便利だなと。自動でイイ感じにやってくれる。その代わり、2枚の画像の変化量が大きい時は対応できなくて、中間画像が崩れてしまったりする。
モーフィングは、人間様が制御点を一々指定しないといけないのがツラい。その代わり、2枚の画像の変化量が大きくても、人間様の指定次第で、中間画像の破綻を少なくすることができそう。
画像の変化が少ない時はフレーム補間で済むだろうし…。変化が大きかったり、あるいは、こちらの思った通りにちゃんと動かしたかったら、作業時間はかかるけどモーフィングで、という感じになるのだろうか…?
フレーム補間は、制御点を人間様が指定しなくても済むのは便利だなと。自動でイイ感じにやってくれる。その代わり、2枚の画像の変化量が大きい時は対応できなくて、中間画像が崩れてしまったりする。
モーフィングは、人間様が制御点を一々指定しないといけないのがツラい。その代わり、2枚の画像の変化量が大きくても、人間様の指定次第で、中間画像の破綻を少なくすることができそう。
画像の変化が少ない時はフレーム補間で済むだろうし…。変化が大きかったり、あるいは、こちらの思った通りにちゃんと動かしたかったら、作業時間はかかるけどモーフィングで、という感じになるのだろうか…?
[ ツッコむ ]
#2 [gimp] GIMP 2.10 64bit Windows版でGAPが使えると知った
無料で利用できる画像編集ソフト、GIMP には、かつて、GAP (GIMP Animation Package)と呼ばれる、動画編集を可能にするプラグイン集が存在していた。まあ、動画編集と言っても、連番の.xcfファイルを作成すると1ファイルを1フレームとして扱えますよ、みたいな感じなのだけど…。
Linux版のGIMPはもちろんのこと、Windows版のGIMPでも、GIMP 2.6、GIMP 2.8 の頃はGAPが使えたのだけど。GIMP 2.10 になったらGAPが使えない状態になってしまって…。どうしても GAP を使いたいなら GIMP 2.8 や GIMP 2.6 を使いましょう、GIMP Portable版を使えば異なるバージョンを共存することもできるし ―― そんな状況になっていた。
しかし、今回ググってみたら、Windows版 GIMP 2.10 用のGAPを公開してくれている方が居ると、今頃になって知った。
_GimpScripts: Gimp-GAP Win_64bit
2020年頃から公開されていたらしい…。GAP は古いGIMPじゃないと使えないものと思い込んで、全然チェックしてなかった…。
GIMP 2.10.34 Portable に導入して少し動作確認してみたけど、ある程度は動いてるように見えた。全部の機能を試してみたわけではないけれど、少なくとも以下の機能は動いてくれた。
もっとも、このGAP、1フレーム移動する度に、現在のファイルを保存してから別ファイルを開き直すわけで…。ストレージに何度も何度もアクセスすることになるので、サクサク作業できる状況には程遠い面もあるのだけど。
それでも、現行版のGIMPで連番画像の編集が可能になる点はありがたいなと…。
Linux版のGIMPはもちろんのこと、Windows版のGIMPでも、GIMP 2.6、GIMP 2.8 の頃はGAPが使えたのだけど。GIMP 2.10 になったらGAPが使えない状態になってしまって…。どうしても GAP を使いたいなら GIMP 2.8 や GIMP 2.6 を使いましょう、GIMP Portable版を使えば異なるバージョンを共存することもできるし ―― そんな状況になっていた。
しかし、今回ググってみたら、Windows版 GIMP 2.10 用のGAPを公開してくれている方が居ると、今頃になって知った。
_GimpScripts: Gimp-GAP Win_64bit
2020年頃から公開されていたらしい…。GAP は古いGIMPじゃないと使えないものと思い込んで、全然チェックしてなかった…。
GIMP 2.10.34 Portable に導入して少し動作確認してみたけど、ある程度は動いてるように見えた。全部の機能を試してみたわけではないけれど、少なくとも以下の機能は動いてくれた。
- Video → Duplcate Frames で、フレーム数(連番xcfのファイル数)を増やす。
- Video → Go to → Next Frame / Previous Frame で、次フレーム/前フレームに移動する。
- Video → VCR Navigator で、連番 xcf をサムネイル画像サイズでアニメーション再生。
- Video → Morphing → Morph で、モーフィング。
もっとも、このGAP、1フレーム移動する度に、現在のファイルを保存してから別ファイルを開き直すわけで…。ストレージに何度も何度もアクセスすることになるので、サクサク作業できる状況には程遠い面もあるのだけど。
それでも、現行版のGIMPで連番画像の編集が可能になる点はありがたいなと…。
◎ 導入の仕方 :
一応、導入の仕方もメモしておく。
Gimp_GAP Win_64bit.zip をDLして解凍すると、中には以下のディレクトリが入ってる。
正しい場所に各ファイルがコピーできていれば、GIMP起動時に各プラグインが読み込まれて、メニューに「Video」という項目が増える。以下のように、使える機能が大量に増える。
ただ、言語ファイルは反映されてない感じがする…。どこも日本語表示にはならなかった。
Gimp_GAP Win_64bit.zip をDLして解凍すると、中には以下のディレクトリが入ってる。
bin plug-ins scripts share
- bin/ の中に入ってる .dll ファイルは、GIMPインストールフォルダ内の bin/ にコピー。
- plug-ins/gap_*.exe は、ユーザープロファイルフォルダ内の plug-ins/ 以下にコピー。もしくは、任意のフォルダに入れておいて、GIMPの設定で、プラグインフォルダとして追加してもいい。そのほうが、ファイルがグチャグチャにならなくて管理が楽かもしれない。
- scripts/*.scm は、これもユーザープロファイルフォルダ内の scripts/ 以下にコピー。
- share/ 内には各言語への対応ファイルが入っている。GIMPインストールフォルダ/share/locale/ja/LC_MESSAGES/ 以下に、gimp20-gap.mo をコピーする。
正しい場所に各ファイルがコピーできていれば、GIMP起動時に各プラグインが読み込まれて、メニューに「Video」という項目が増える。以下のように、使える機能が大量に増える。
ただ、言語ファイルは反映されてない感じがする…。どこも日本語表示にはならなかった。
◎ 使い方 :
簡単な使い方をメモ。
まずは、何かしら画像を新規作成して、0000.xcf というファイル名で保存。これが0フレーム目。
Video → Duplcate Frames を選べば、現在の画像(レイヤー構成)で、フレーム数(連番の.xcf)を増やせる。N times に増やしたいフレーム数を指定してOKをクリックすれば、指定した数のフレーム = .xcf が自動で作成される。例えば N times に16を指定すれば、0001.xcf - 0016.xcf が新規作成される。
Video → Go to → Next Frame / Previous Frame で、次のフレーム/前のフレームに移動できる。何かしら編集して、Next Frame / Previous Frame をすれば、今まで開いてた画像ファイル(.xcf)が上書き保存されて、次/前の .xcf が開かれる。
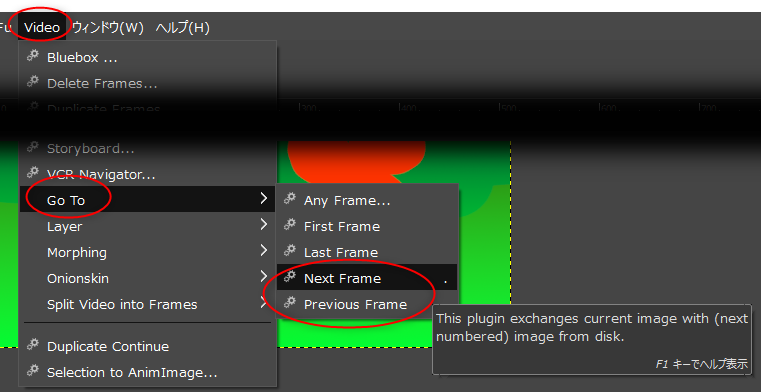
ちなみに、Next Frame に「.」を、Previous Frame に「,」を、ショートカットキーとして割り当てると、前後のフレームに移動するのが楽になる。
全フレームをアニメーションとして保存したい時は、Video → Frames to Image を選択。1レイヤーを1フレームとして扱う別画像を新規作成してくれる。

この状態になってしまえば、アニメgifとして保存することもできるし、各レイヤーをエクスポートして、別の動画編集ソフトで連番画像として読み込んで扱うこともできる。
そんな感じで作ったアニメが以下になります。

この程度のアニメでは何が便利なのか分らんだろうけど…。とりあえず、GIMP 2.10 でも GAP が使えた証明にはなるかなと…。
まずは、何かしら画像を新規作成して、0000.xcf というファイル名で保存。これが0フレーム目。
Video → Duplcate Frames を選べば、現在の画像(レイヤー構成)で、フレーム数(連番の.xcf)を増やせる。N times に増やしたいフレーム数を指定してOKをクリックすれば、指定した数のフレーム = .xcf が自動で作成される。例えば N times に16を指定すれば、0001.xcf - 0016.xcf が新規作成される。
Video → Go to → Next Frame / Previous Frame で、次のフレーム/前のフレームに移動できる。何かしら編集して、Next Frame / Previous Frame をすれば、今まで開いてた画像ファイル(.xcf)が上書き保存されて、次/前の .xcf が開かれる。
ちなみに、Next Frame に「.」を、Previous Frame に「,」を、ショートカットキーとして割り当てると、前後のフレームに移動するのが楽になる。
全フレームをアニメーションとして保存したい時は、Video → Frames to Image を選択。1レイヤーを1フレームとして扱う別画像を新規作成してくれる。
この状態になってしまえば、アニメgifとして保存することもできるし、各レイヤーをエクスポートして、別の動画編集ソフトで連番画像として読み込んで扱うこともできる。
そんな感じで作ったアニメが以下になります。
この程度のアニメでは何が便利なのか分らんだろうけど…。とりあえず、GIMP 2.10 でも GAP が使えた証明にはなるかなと…。
◎ 余談 :
ガシガシ描いてアニメーションを作りたいなら、Krita を使ったほうが良さそうな気もする。Krita なら、最初から標準機能としてアニメ作成機能を持っているので…。アニメを作る際には必須とも言えるオニオンスキン機能も使えるし。
[ ツッコむ ]
2023/05/26(金) [n年前の日記]
#1 [cg_tools] ControlNetのDepthについて調べてた
画像生成AI Stable Diffusion web UIには ControlNet という拡張機能があって、OpenPose画像やDepth画像を与えて人物のポーズを指定することができるのだけど。人物が映ってる画像を渡して、プリプロセッサに処理してもらうことで、画像からOpenPose画像を生成したり、Depth画像を生成したりすることもできる。
その、Depth画像(深度マップ、Z map)とやらを使う方法が分らなかったので少し調べてた。環境は、Windows10 x64 22H2。CPU : AMD Ryzen 5 5600X。GPU : NVIDIA GeForce GTX 1060 6GB。
以下のページが参考になった。ありがたや。現行バージョンとは違うところもあるけれど…。
_ControlNet 1.1のプリプロセッサまとめ!出力結果を比較してみた【Stable Diffusion】 | くろくまそふと
_「ControlNet」徹底攻略!導入方法と使い方解説 | IRoAI(イロアイブログ)
_ControlNetを使って構図をコントロールする|感想日記
その、Depth画像(深度マップ、Z map)とやらを使う方法が分らなかったので少し調べてた。環境は、Windows10 x64 22H2。CPU : AMD Ryzen 5 5600X。GPU : NVIDIA GeForce GTX 1060 6GB。
以下のページが参考になった。ありがたや。現行バージョンとは違うところもあるけれど…。
_ControlNet 1.1のプリプロセッサまとめ!出力結果を比較してみた【Stable Diffusion】 | くろくまそふと
_「ControlNet」徹底攻略!導入方法と使い方解説 | IRoAI(イロアイブログ)
_ControlNetを使って構図をコントロールする|感想日記
◎ プリプロセッサの種類 :
現行バージョンでは、プリプロセッサとして、以下が選べるように見えた。
少し試した感じでは、midas の結果が一番クッキリしていて、zoeの結果は少しボケ気味に見えた。ただ、生成画像にどういう影響が出るかは、また別の話のようで…。
ちなみに、それぞれの種類を選ぶと、(Stable Diffusion web UIインストールフォルダ)\extensions\sd-webui-controlnet\annotator\downloads\ 以下に、*.pt や *.pth がダウンロードされる模様。全部で2.59GBほどになっていた。
余談。プリプロセッサ種類を変更して試してたら、メモリ不足でエラー続出。VRAM 6GB では厳しいのかもしれない…? まあ、1種類だけ選んだ状態なら動いてくれるけど…。
- depth_leres
- depth_leres++
- depth_midas
- depth_zoe
少し試した感じでは、midas の結果が一番クッキリしていて、zoeの結果は少しボケ気味に見えた。ただ、生成画像にどういう影響が出るかは、また別の話のようで…。
ちなみに、それぞれの種類を選ぶと、(Stable Diffusion web UIインストールフォルダ)\extensions\sd-webui-controlnet\annotator\downloads\ 以下に、*.pt や *.pth がダウンロードされる模様。全部で2.59GBほどになっていた。
> tree /f downloads
D:\AIWORK\STABLE-DIFFUSION-WEBUI\EXTENSIONS\SD-WEBUI-CONTROLNET\ANNOTATOR\DOWNLOADS
├─leres
│ latest_net_G.pth
│ res101.pth
│
├─midas
│ dpt_hybrid-midas-501f0c75.pt
│
└─zoedepth
ZoeD_M12_N.pt
余談。プリプロセッサ種類を変更して試してたら、メモリ不足でエラー続出。VRAM 6GB では厳しいのかもしれない…? まあ、1種類だけ選んだ状態なら動いてくれるけど…。
◎ プリプロセッサの結果画像を取得したい :
プリプロセッサを通した直後のDepth画像だけを入手したい。どうすればいいのだろう。
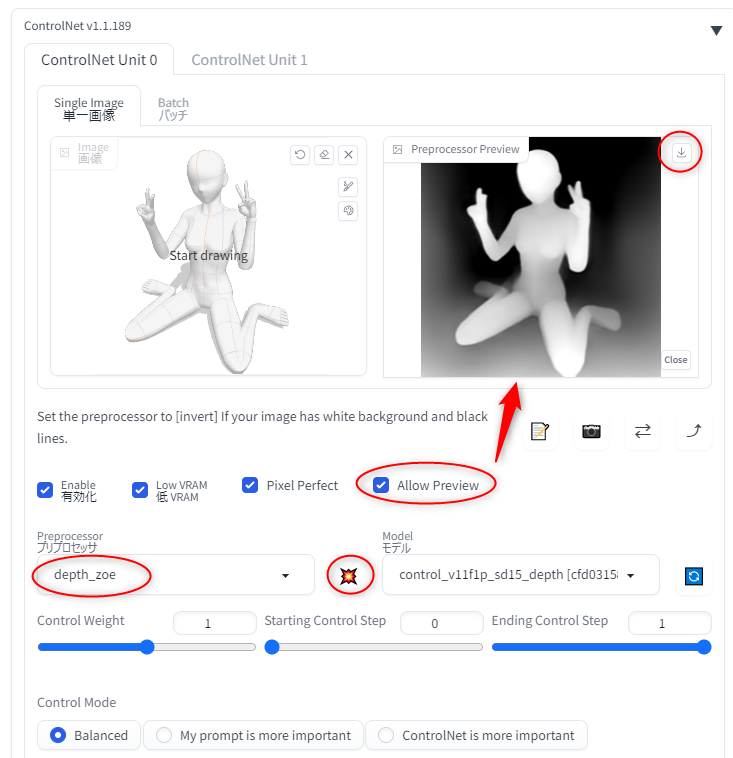
これで、Stable Diffusion web UI + ControlNet を使って、既存画像からデプス画像を生成して入手することができた。
- 「Allow Preview」にチェックを入れると、プリプロセッサの処理結果を表示する「Preprocessor Preview」ウインドウが増える。
- 更に、プリプロセッサ種類の横にあるアイコンをクリックすれば、プリプロセッサの処理だけを走らせて、結果が「Preprocessor Preview」ウインドウに表示される。
- プレビューが表示されたら、右上のアイコンをクリックすることで画像を保存できる。
これで、Stable Diffusion web UI + ControlNet を使って、既存画像からデプス画像を生成して入手することができた。
◎ 元画像を作成 :
Depthを使ってポーズを指定する際、CLIP STUDIO PAINT の3D機能が便利そうだなと…。久々に CLIP STUDIO PAINT を起動して体型人形を読み込んで…。
使い方が分からん…。これまた勉強しないと…。
とりあえず、つるっとした感じの人形が映ってる画像でも、ControlNetに渡せばポーズ指定には十分使えるようではあるなと。
使い方が分からん…。これまた勉強しないと…。
とりあえず、つるっとした感じの人形が映ってる画像でも、ControlNetに渡せばポーズ指定には十分使えるようではあるなと。
◎ 余談。Depth画像の利用法を妄想 :
どうしてDepth画像に興味が湧いたかと言うと…。Depth画像から簡易3Dモデルデータを作れたら、画像生成AIの生成画像を動かすことができるんじゃないかと妄想してしまったからで…。
さて、そんなことはできるんだろうか…? Depth画像から3Dモデルデータって作れるのかな…?
順番が逆であれば ―― Depth画像を先に作るのではなく、3Dモデルデータをblenderで先に作って、そこからDepth画像を作成、ControlNetに渡して生成した画像を3Dモデルに貼り付け、ということはできるっぽい。
_TDSさんはTwitterを...: 「Blenderで空間を... #aiart #b3d / Twitter
_AUTOMATIC1111+ControlNetのつかいかた3(デプスマップで建物を)|BTA(Kelorin Jo)
_【Stable Diffusion webUI】BlenderとControlNetを使って画像を作る - 7mm blog
- 画像生成AIで、画像を生成。
- 生成画像から、Depth画像を作成。
- Depth画像を元にして、blender で3Dモデルを生成。
- 3Dモデルに、画像生成AIの生成画像をテクスチャとして貼り付け。
- blender上で動かす。
さて、そんなことはできるんだろうか…? Depth画像から3Dモデルデータって作れるのかな…?
順番が逆であれば ―― Depth画像を先に作るのではなく、3Dモデルデータをblenderで先に作って、そこからDepth画像を作成、ControlNetに渡して生成した画像を3Dモデルに貼り付け、ということはできるっぽい。
_TDSさんはTwitterを...: 「Blenderで空間を... #aiart #b3d / Twitter
_AUTOMATIC1111+ControlNetのつかいかた3(デプスマップで建物を)|BTA(Kelorin Jo)
_【Stable Diffusion webUI】BlenderとControlNetを使って画像を作る - 7mm blog
[ ツッコむ ]
2023/05/27(土) [n年前の日記]
#1 [cg_tools][blender] 画像生成AIで生成した画像をデプスマップを利用してblenderで動かす
画像生成AI Stable Diffusion web UIで生成した画像を、blenderを使って動かしてみたい。
作業の流れとしては以下。
環境は、Windows10 x64 22H2。CPU : AMD Ryzen 5 5600X。GPU : NVIDIA GeForce GTX 1060 6GB。RAM : 16GB。
とりあえず、成果物の一つを先に提示しておきます。こんな感じでも良ければ一応動かせそうということで。
作業の流れとしては以下。
- Stable Diffusion web UIで画像を生成。
- 生成された画像を、ControlNet の depthプリプロセッサに渡して、デプスマップ(Depth画像、深度マップ、z map)を生成。
- blenderにデプスマップを渡して、メッシュを立体的に変形。元画像をテクスチャとして貼り付け。
- カメラを動かして動画を作成。
環境は、Windows10 x64 22H2。CPU : AMD Ryzen 5 5600X。GPU : NVIDIA GeForce GTX 1060 6GB。RAM : 16GB。
とりあえず、成果物の一つを先に提示しておきます。こんな感じでも良ければ一応動かせそうということで。
◎ 画像を生成 :
Stable Diffusion web UIを使って、背景っぽく見える画像を生成した。

512x512では小さいだろうと思えてきたので、Stable Diffusion web UI の Extrasタブで画像を拡大した。今回は、4倍、2048x2048にした。
_00011-2511203688.2048x2048.jpg
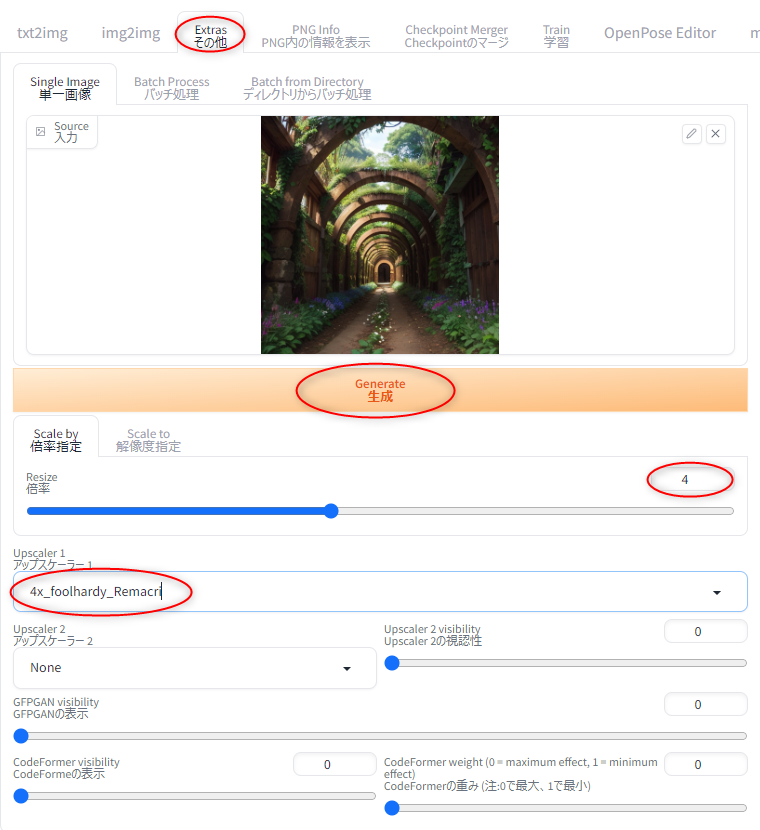
拡大処理に使うアップスケーラ(Upscaler)は、4x_foolhardy_Remacri。標準では入ってないので、使いたい時は追加インストールをする必要がある。
_RemacriをStable Diffusion web UIから利用
あるいは、画像拡大処理専用のツールを使ったほうが楽かもしれない。
_画像拡大ツールをもう少し試用してみた
_画像拡大ツールを試用
parameters plant tunnel, nature, masterpiece, best quality, Negative prompt: EasyNegative, painting, sketches, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, (monochrome), (grayscale), girl, man, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 2511203688, Size: 512x512, Model hash: 4d91c4c217, Model: lyriel_v15, Clip skip: 2, Version: v1.2.1
512x512では小さいだろうと思えてきたので、Stable Diffusion web UI の Extrasタブで画像を拡大した。今回は、4倍、2048x2048にした。
_00011-2511203688.2048x2048.jpg
{kind=link}
{kind=link}
拡大処理に使うアップスケーラ(Upscaler)は、4x_foolhardy_Remacri。標準では入ってないので、使いたい時は追加インストールをする必要がある。
_RemacriをStable Diffusion web UIから利用
あるいは、画像拡大処理専用のツールを使ったほうが楽かもしれない。
_画像拡大ツールをもう少し試用してみた
_画像拡大ツールを試用
◎ デプスマップを生成 :
Stable Diffusion web UI の ControlNet のプリプロセッサを利用して、デプスマップ(depth画像、深度マップ、z map)を生成する。
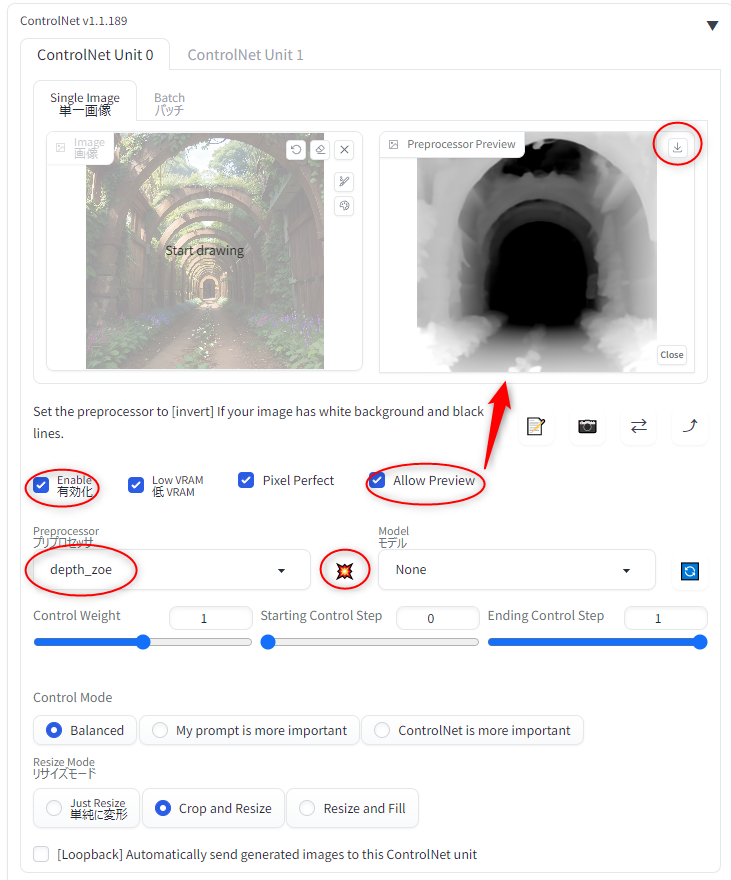
尚、出力される画像サイズは、Stable Diffusion web UI の画像生成時の width(横幅)とheight(縦幅)が使われる。標準では 512x512 だろうけど、768x768 や 1024x1024 を指定してやれば、少し大きめのデプスマップを得ることができる。

ただ、プリプロセッサも、特定の画像サイズを元にして学習してるだろうから…。768x768 や 1024x1024 より、512x512のほうが正確な深度を推測できている可能性はあるかもしれない。
以下に、プリプロセッサの種類、出力画像サイズを変えたものを並べてみる。見た目が結構違うことが分かるかと…。
_depth.leres.512x512.png
_depth.leres.768x768.png
_depth.leres.1024x1024.png
_depth.leres.2048x2048.png
_depth.midas.512x512.png
_depth.midas.768x768.png
_depth.midas.1024x1024.png
_depth.zoe.512x512.png
_depth.zoe.768x768.png
_depth.zoe.1024x1024.png
_depth.zoe.2048x2048.png
注目したいのは、leres の 1024x1024 と 2048x2048。後者のほうが細かく領域分けが出来ているけれど、その分(?)深度情報はめちゃくちゃになっていて、本来なら奥にあるはずのもの(黒くなるべき部分)が、かなり手前にあるもの(白い部分)として出力されちゃってる。画像サイズが大きければ大きいほど良い、というわけではなさそうだなと…。適切に処理できそうな出力サイズがあるっぽい。たぶん。
ちなみに、自分の手持ちのビデオカードはVRAMが6GBしかないけれど、depth_leres と depth_zoe は 2048x2048 で出力することができた。depth_midas は、2048x2048 はVRAMが足りないとエラーが出て、1024x1024 までしか出力できなかった。
- ControlNet の Allow Preview を有効にすると、プリプロセッサが処理した直後の画像をプレビュー表示するウインドウが増える。
- プリプロセッサの種類で、Depth系を選ぶ。現時点では、depth_leres, depth_leres++, depth_midas, depth_zoe が選べる。
- プリプロセッサ種類の横にある、爆発っぽいアイコンをクリックすると、プリプロセッサの処理だけを実行することができる。
- プレビューウインドウの右上の、下向き矢印っぽいアイコンをクリックすると、処理後の画像を保存できる。
尚、出力される画像サイズは、Stable Diffusion web UI の画像生成時の width(横幅)とheight(縦幅)が使われる。標準では 512x512 だろうけど、768x768 や 1024x1024 を指定してやれば、少し大きめのデプスマップを得ることができる。
ただ、プリプロセッサも、特定の画像サイズを元にして学習してるだろうから…。768x768 や 1024x1024 より、512x512のほうが正確な深度を推測できている可能性はあるかもしれない。
以下に、プリプロセッサの種類、出力画像サイズを変えたものを並べてみる。見た目が結構違うことが分かるかと…。
_depth.leres.512x512.png
{kind=link}
{kind=link}
_depth.leres.768x768.png
{kind=link}
{kind=link}
_depth.leres.1024x1024.png
{kind=link}
{kind=link}
_depth.leres.2048x2048.png
{kind=link}
{kind=link}
_depth.midas.512x512.png
{kind=link}
{kind=link}
_depth.midas.768x768.png
{kind=link}
{kind=link}
_depth.midas.1024x1024.png
{kind=link}
{kind=link}
_depth.zoe.512x512.png
{kind=link}
{kind=link}
_depth.zoe.768x768.png
{kind=link}
{kind=link}
_depth.zoe.1024x1024.png
{kind=link}
{kind=link}
_depth.zoe.2048x2048.png
{kind=link}
{kind=link}
注目したいのは、leres の 1024x1024 と 2048x2048。後者のほうが細かく領域分けが出来ているけれど、その分(?)深度情報はめちゃくちゃになっていて、本来なら奥にあるはずのもの(黒くなるべき部分)が、かなり手前にあるもの(白い部分)として出力されちゃってる。画像サイズが大きければ大きいほど良い、というわけではなさそうだなと…。適切に処理できそうな出力サイズがあるっぽい。たぶん。
ちなみに、自分の手持ちのビデオカードはVRAMが6GBしかないけれど、depth_leres と depth_zoe は 2048x2048 で出力することができた。depth_midas は、2048x2048 はVRAMが足りないとエラーが出て、1024x1024 までしか出力できなかった。
◎ blenderでデプスマップを読み込む :
blenderでデプスマップを読み込んで、立体的な状態にする。blender 3.3.7 x64 LTS を使用した。
平面(Plane)を作成。Shift + A → メッシュ → 平面。
編集モード(頂点編集モード)に切り替え。左上で「編集モード」を選んでもいいし、TABキーを押して編集モードに切り替えてもいい。
右クリックメニュー → 細分化。
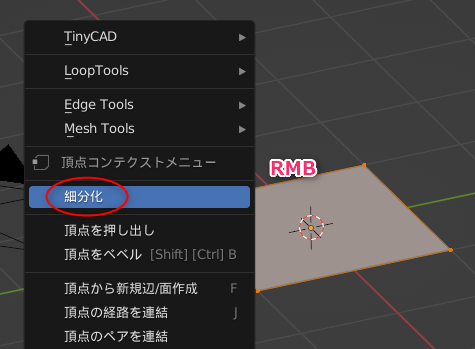
分割数を100にする。
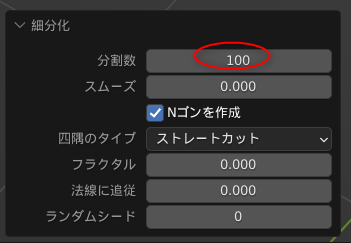
ちなみに、分割数として255等を打ち込んでみたりもしたのだけど、100と違いは無かった。どうやら分割数は最大100で決められてるっぽい。
ディスプレイス(Displace)モディファイアを追加する。このモディファイアで、画像情報を元にして頂点位置を変化させることができる。
テクスチャを指定する。新規をクリック。
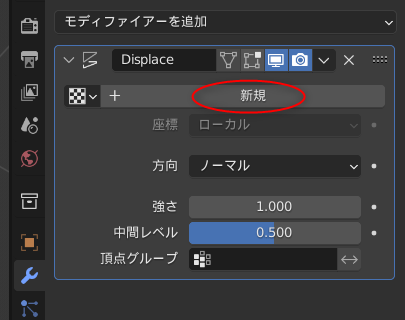
テクスチャプロパティで、デプスマップ画像を指定する。
平面が、デプスマップ画像のピクセル値に基づいて、変形してくれた。

平面(Plane)を作成。Shift + A → メッシュ → 平面。
編集モード(頂点編集モード)に切り替え。左上で「編集モード」を選んでもいいし、TABキーを押して編集モードに切り替えてもいい。
右クリックメニュー → 細分化。
分割数を100にする。
ちなみに、分割数として255等を打ち込んでみたりもしたのだけど、100と違いは無かった。どうやら分割数は最大100で決められてるっぽい。
ディスプレイス(Displace)モディファイアを追加する。このモディファイアで、画像情報を元にして頂点位置を変化させることができる。
テクスチャを指定する。新規をクリック。
テクスチャプロパティで、デプスマップ画像を指定する。
平面が、デプスマップ画像のピクセル値に基づいて、変形してくれた。
◎ 平面にテクスチャを割り当て :
テクスチャを割り当てる。マテリアルプロパティで、新規をクリック。
今回、テクスチャだけをレンダリングしたいので、サーフェイスの種類として放射を選ぶ。カラーは、画像テクスチャを選択。画像生成AIで生成・拡大した元画像(2048x2048)を指定してやる。
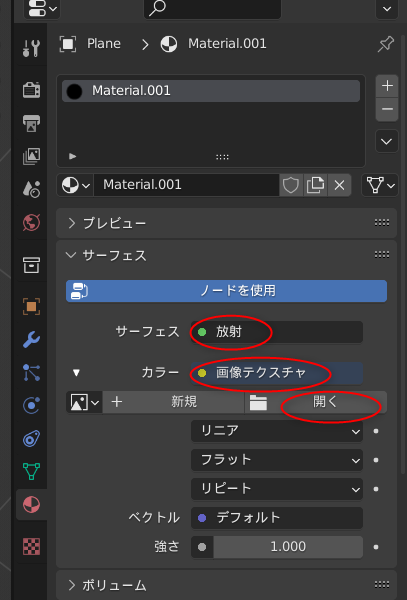
今回、テクスチャだけをレンダリングしたいので、サーフェイスの種類として放射を選ぶ。カラーは、画像テクスチャを選択。画像生成AIで生成・拡大した元画像(2048x2048)を指定してやる。
◎ 3Dビューのシェーディングを変更 :
3Dビューのシェーディング設定を変更して、テクスチャだけが表示される状態にする。右上のアイコンをクリックして、照明をフラットに、カラーをテクスチャに変更する。
テクスチャだけが表示される状態になった。

テクスチャだけが表示される状態になった。
◎ モデルの角度とスケールを変更 :
このままだと使い辛いので、x軸に沿って90度回転、y軸に沿って拡大する。

元画像によっては、サブディビジョンサーフェスモディファイアをかけて、平面を更に再分割したり、スムーズシェードをかけて滑らかにしてもいい。
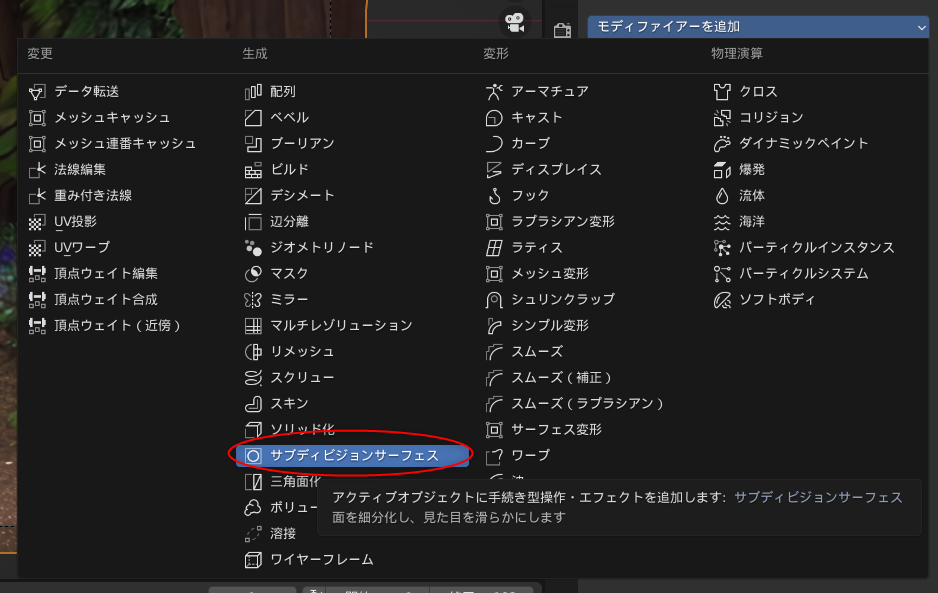
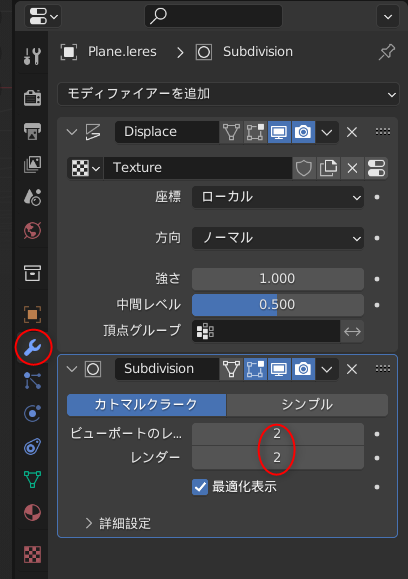
後はカメラを動かしてモーションをつけたりして好きなように。
元画像によっては、サブディビジョンサーフェスモディファイアをかけて、平面を更に再分割したり、スムーズシェードをかけて滑らかにしてもいい。
後はカメラを動かしてモーションをつけたりして好きなように。
◎ レンダリング :
モーションをつけたら、レンダリングして動画にする。
テクスチャだけが見える状態でレンダリングしたいので、レンダープロパティを変更する。
この状態でレンダリングすれば、テクスチャだけが表示された状態でレンダリングされる。
テクスチャだけが見える状態でレンダリングしたいので、レンダープロパティを変更する。
- レンダーエンジンはWorkbenchに。
- 照明はフラットに。
- カラーはテクスチャに。
- カラーマネージメントのビュー変換は標準に。
この状態でレンダリングすれば、テクスチャだけが表示された状態でレンダリングされる。
◎ 成果物 :
こんな感じで作った動画が以下になります。
depth_leres で生成したデプスマップを使った事例。
depth_midas で生成したデプスマップを使った事例。
depth_zoe で生成したデプスマップを使った事例。
depth_leres で生成したデプスマップを使った事例。
depth_midas で生成したデプスマップを使った事例。
depth_zoe で生成したデプスマップを使った事例。
◎ プリプロセッサ種類による違い :
プリプロセッサ種類によって、得られるデプスマップの性質は、かなり違ってくるように感じた。
以下に、各デプスマップで変形させた平面を、反対側というか、奥のほうから眺めたスクリーンショットを置いてみるけど…。

leres は、奥行きの距離間隔は比較的それらしく推測できてる。ただし、精度が荒いというか…。本来であれば木製のアーチがある部分(茶色の部分)は同じ奥行きであると推測してほしいわけだけど、見て分かる通り、奥行きがおかしくなって形として歪んでしまっている。前述の動画でも、各部分の形状がめちゃくちゃになってることが分かる。
midasは、精度に関してはそこそこちゃんとしてる。木製のアーチ部分もそれぞれ奥行きが一致してる。しかし、奥に進むにつれて、アーチの間隔がどんどん詰まっている…。奥のほうが距離が圧縮されているというか…。前述の動画を見ても、カメラの進む速度は一定なのに、奥に進むにつれて速度が上がってるように見える。奥のほうがモデルの奥行き/距離が圧縮されてるから、速度が上がってるように見えるという…。
zoeは、近距離に関しては比較的それらしく推測されてるように見える、しかし、一定の距離で、深度の推測が打ち切られてしまってる。クリッピングがかかってるとでもいうか…。
どれも一長一短だなと。
以下に、各デプスマップで変形させた平面を、反対側というか、奥のほうから眺めたスクリーンショットを置いてみるけど…。
leres は、奥行きの距離間隔は比較的それらしく推測できてる。ただし、精度が荒いというか…。本来であれば木製のアーチがある部分(茶色の部分)は同じ奥行きであると推測してほしいわけだけど、見て分かる通り、奥行きがおかしくなって形として歪んでしまっている。前述の動画でも、各部分の形状がめちゃくちゃになってることが分かる。
midasは、精度に関してはそこそこちゃんとしてる。木製のアーチ部分もそれぞれ奥行きが一致してる。しかし、奥に進むにつれて、アーチの間隔がどんどん詰まっている…。奥のほうが距離が圧縮されているというか…。前述の動画を見ても、カメラの進む速度は一定なのに、奥に進むにつれて速度が上がってるように見える。奥のほうがモデルの奥行き/距離が圧縮されてるから、速度が上がってるように見えるという…。
zoeは、近距離に関しては比較的それらしく推測されてるように見える、しかし、一定の距離で、深度の推測が打ち切られてしまってる。クリッピングがかかってるとでもいうか…。
どれも一長一短だなと。
◎ 雑感 :
昔、blenderでカメラマップ/カメラマッピングの実験をした際、「1クリックでやれるものではないですよ」「簡易的とは言え結局モデリング作業が入ってくるから、3DCGを作るのと変わりませんよ」みたいなことを書いたのだけど。
_mieki256's diary - blenderでカメラマッピングの実験
_mieki256's diary - blenderでカメラマッピングの実験その2
_mieki256's diary - blenderでカメラマッピングの実験その3 アニメ調
AIを使って推測させて、1枚の画像からデプスマップを自動生成して、そのデプスマップを使ってなんちゃってモデルデータを作ることはできるようになったから、そこだけ見れば1クリックで出来る状態に近づいたと言えそう。でも、そのデプスマップが正確かというとそうでもないので…。
やはり人間様が目視で確認しつつ、手間暇かけて作ったモデルデータ/映像には敵わないなと。雑な作りでもいいなら1クリックでやれますけど、本当にこんなクオリティでいいんですか? みたいな状態というか。
もっとも、元画像がシンプルならAIでも十分、とか、一瞬だけ出るカットなら歪んでいてもOK、みたいな場面もありそう。だけど、あらゆる場面で「どうせAIで一発でしょ?」と言われてしまうと、それはちょっと…。全ての場面で使えるほど精度が高いわけでもないので…。
宮崎駿監督が、「CGは魔法の小箱じゃないんだよ」とTV番組の中で呟いてたけど、AIも魔法の小箱じゃないよな…。できることは間違いなく増えてきているし、進化の速度もスゴイけど…。
_mieki256's diary - blenderでカメラマッピングの実験
_mieki256's diary - blenderでカメラマッピングの実験その2
_mieki256's diary - blenderでカメラマッピングの実験その3 アニメ調
AIを使って推測させて、1枚の画像からデプスマップを自動生成して、そのデプスマップを使ってなんちゃってモデルデータを作ることはできるようになったから、そこだけ見れば1クリックで出来る状態に近づいたと言えそう。でも、そのデプスマップが正確かというとそうでもないので…。
やはり人間様が目視で確認しつつ、手間暇かけて作ったモデルデータ/映像には敵わないなと。雑な作りでもいいなら1クリックでやれますけど、本当にこんなクオリティでいいんですか? みたいな状態というか。
もっとも、元画像がシンプルならAIでも十分、とか、一瞬だけ出るカットなら歪んでいてもOK、みたいな場面もありそう。だけど、あらゆる場面で「どうせAIで一発でしょ?」と言われてしまうと、それはちょっと…。全ての場面で使えるほど精度が高いわけでもないので…。
宮崎駿監督が、「CGは魔法の小箱じゃないんだよ」とTV番組の中で呟いてたけど、AIも魔法の小箱じゃないよな…。できることは間違いなく増えてきているし、進化の速度もスゴイけど…。
◎ 余談。自動でやってくれるアドオンがあるらしい :
ググっていて知ったけど、画像を渡すだけでこういったことをしてくれるblenderの有償アドオンがあるらしいのでメモ。
_I-Mesh for Blender - 2Dの深度イメージ(Depth)を元にメッシュを立体的にしてくれるBlenderアドオンが登場!
_I-Mesh for Blender ブレンダーで読み込んだ画像から深度マップが自動作成され奥行きのあるシーンが作成されるアドオン - 3DCG最新情報サイト MODELING HAPPY
_I-Mesh for Blender - 2Dの深度イメージ(Depth)を元にメッシュを立体的にしてくれるBlenderアドオンが登場!
_I-Mesh for Blender ブレンダーで読み込んだ画像から深度マップが自動作成され奥行きのあるシーンが作成されるアドオン - 3DCG最新情報サイト MODELING HAPPY
◎ 参考ページ :
_Blender:ライトの影響なしでレンダリング!/テクスチャの色100%でレンダリングをしよう! | マナベルCG
_Blender: 複数のカメラを切り替えて使用する方法 | reflectorange.net
_Blender Addon: Import Depth Map - YouTube
_Turn any image into 3d animation using AI generated depth map! - YouTube
_Create 3D animations of your AI-generated characters - YouTube
_Import Depth map v1.0.3 - YouTube
_TomLikesRobotsさんはTwitterを...: 「Simple Stable Diffusion to Blender: 1. Use Automatic1111's depth map extension ... / Twitter
_Serpens-Bledner-Addons/Serpens3 at main - Ladypoly/Serpens-Bledner-Addons - GitHub
_Stable Diffusion + ChatGPT + Blender - Pc-Trace
_This is amazing - Someone used ChatGPT to write an addon that imports the SD output image and the depthmap into Blender. Download link in comment
importdepthmap というアドオンもあるらしいのだけど、使い方がよく分からない…。
_Blender: 複数のカメラを切り替えて使用する方法 | reflectorange.net
_Blender Addon: Import Depth Map - YouTube
_Turn any image into 3d animation using AI generated depth map! - YouTube
_Create 3D animations of your AI-generated characters - YouTube
_Import Depth map v1.0.3 - YouTube
_TomLikesRobotsさんはTwitterを...: 「Simple Stable Diffusion to Blender: 1. Use Automatic1111's depth map extension ... / Twitter
_Serpens-Bledner-Addons/Serpens3 at main - Ladypoly/Serpens-Bledner-Addons - GitHub
_Stable Diffusion + ChatGPT + Blender - Pc-Trace
_This is amazing - Someone used ChatGPT to write an addon that imports the SD output image and the depthmap into Blender. Download link in comment
importdepthmap というアドオンもあるらしいのだけど、使い方がよく分からない…。
[ ツッコむ ]
2023/05/28(日) [n年前の日記]
#1 [blender] blenderのImportDepthMapアドオンの使い方が分かってきたのでメモ
blenderのアドオンとして、ImportDepthMapというものを見かけたのだけど、使い方が少し分かってきたのでメモ。環境は、Windows10 x64 22H2 + blender 3.3.7 x64 LTS。
どういうアドオンかと言うと、カラー画像とデプスマップ画像(深度マップ、z map)を読み込んで、2.5D的なモデルデータを作ってくれる。モデルデータと言っても、実体は一枚の平面(4角形ポリゴン)で、それをサブディビジョンサーフェイス、ディスプレイス等のモディファイアで立体物っぽく見せてる模様。
例えば、以下の2枚の静止画像から…。

_00027-2356436114_upscayl_4x_realesrgan-x4plus.jpg
_00027-2356436114.png

_00027-2356436114.depth.zoe.png
以下のような形状を作って…。

以下のような動画が作れたりする。
どういうアドオンかと言うと、カラー画像とデプスマップ画像(深度マップ、z map)を読み込んで、2.5D的なモデルデータを作ってくれる。モデルデータと言っても、実体は一枚の平面(4角形ポリゴン)で、それをサブディビジョンサーフェイス、ディスプレイス等のモディファイアで立体物っぽく見せてる模様。
例えば、以下の2枚の静止画像から…。
{kind=link}
{kind=link}
_00027-2356436114.png
{kind=link}
{kind=link}
以下のような形状を作って…。
以下のような動画が作れたりする。
◎ アドオンの入手先 :
以下から入手できる。
_Serpens-Bledner-Addons/Serpens3 at main - Ladypoly/Serpens-Bledner-Addons - GitHub
今回は importdepthmap_1.1.1.zip を入手。
_Serpens-Bledner-Addons/Serpens3 at main - Ladypoly/Serpens-Bledner-Addons - GitHub
今回は importdepthmap_1.1.1.zip を入手。
◎ インストール :
一般的なアドオンと同様の手順でインストールすればいい。一応メモしておくけど…。
編集 → プリファレンス、を選択。
アドオン → インストール、をクリック。
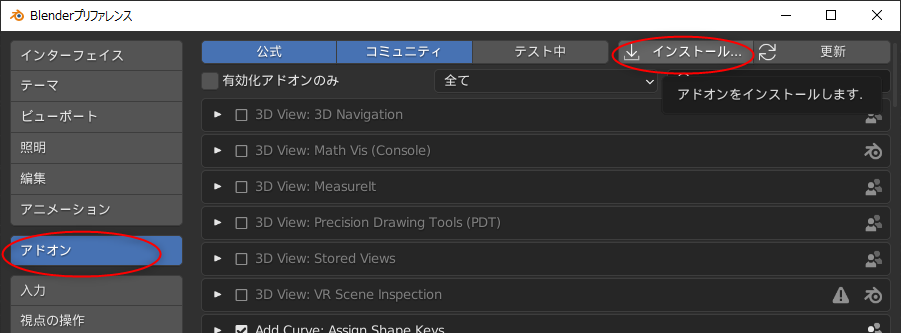
importdepthmap_1.1.1.zip を選択して、「アドオンをインストール」をクリック。
「Import-Export: ImportDepthMap」にチェックを入れて有効化。
編集 → プリファレンス、を選択。
アドオン → インストール、をクリック。
importdepthmap_1.1.1.zip を選択して、「アドオンをインストール」をクリック。
「Import-Export: ImportDepthMap」にチェックを入れて有効化。
◎ 使い方 :
ファイル → インポート → Import Depth Map、を選択。
続いて、カラー画像やデプスマップ画像を選択するのだけど、ここでちょっと注意。このアドオンは2つの方法で画像を読み込める。
今回は、Aの流れ、カラー画像とデプスマップ画像が別々になってるやり方で読み込む。
まずはカラー画像を選択して読み込む。その際、右上の、「Separate Depth Map」にチェックを入れて、カラー画像とデプスマップ画像を分けて読み込むように指定する。もし、該当項目が表示されてなかったら、右上の歯車っぽいアイコンをクリックすれば該当項目(オプション設定)が表示される。たぶん。
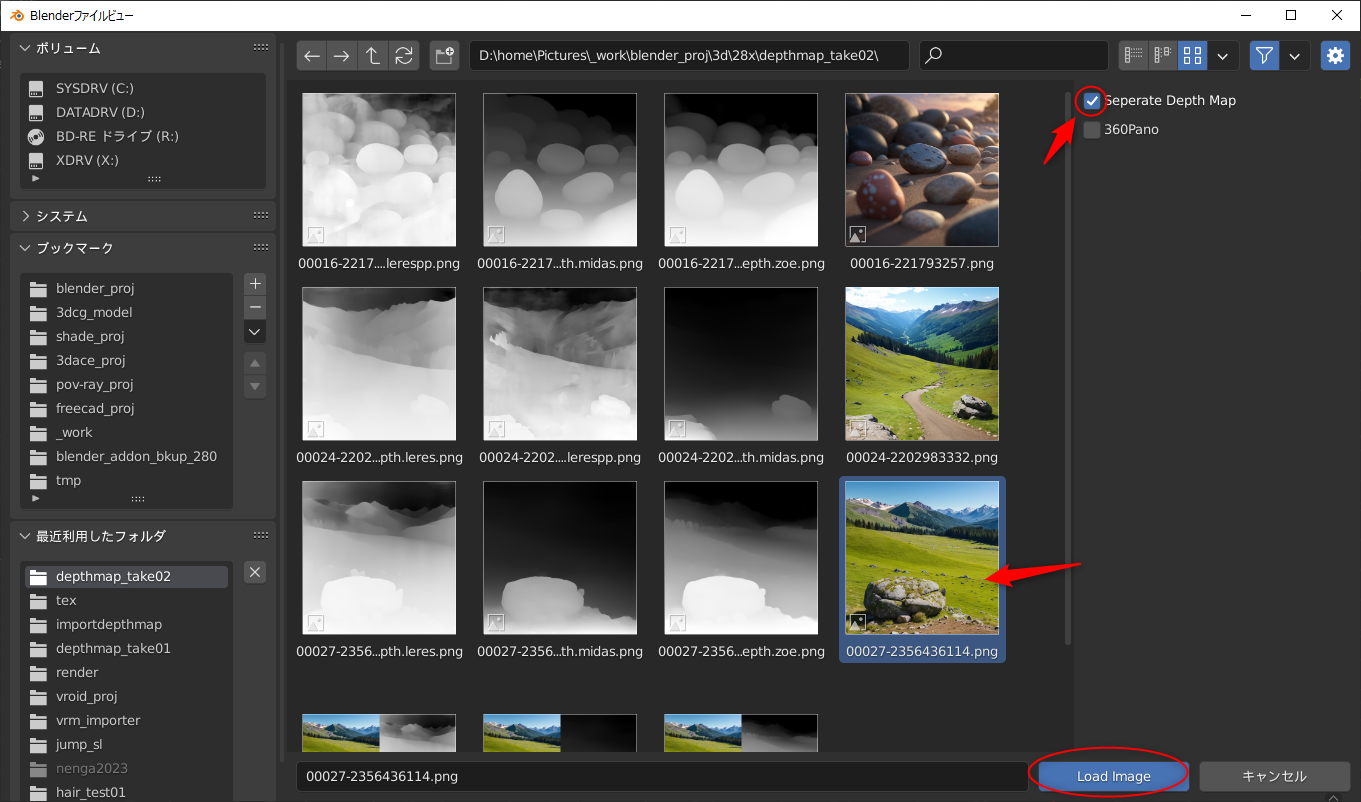
カラー画像を選択し終わると、次に、デプスマップ画像を選ぶためのファイル選択ダイアログが開く。デプスマップ画像を選んで、「Load Depth Image」をクリック。
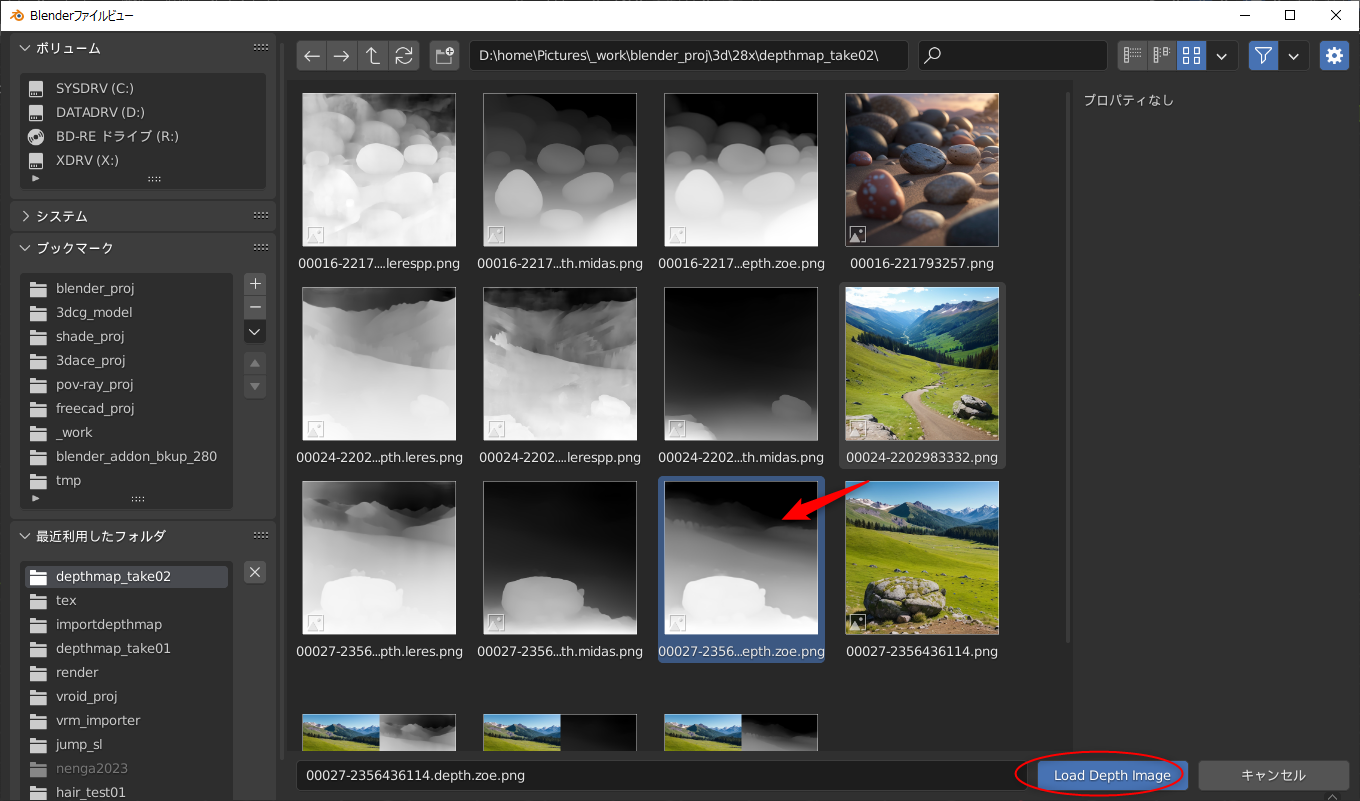
これで、デプスマップが反映された形状が出現する。
この状態だと分かりづらいので、右上のアイコンをクリックして、レンダープレビューに切り替える。これでテクスチャが反映された状態で表示される。
一応、1枚の画像を読み込んで済ませる場合についても説明。要は、以下のような見た目の画像を用意すればいいらしい。こういう状態の画像であれば、ファイル選択時に1回の指定で済む。

_00027-2356436114.src_and_zoe.png
ただし、この状態の画像を読み込んだ場合、3Dビューのシェーディングモードの設定によっては、カラー画像部分とデプスマップ画像部分の両方がモデルに割り当てられた状態で表示されてしまうこともある。
個人的には、カラー画像とデプスマップ画像は別々にしておいたほうが問題が起きにくい気もした。別々の画像にしておけば、デプスマップだけを差し替えて様子を見てみたり、カラー画像だけを高解像度の画像で差し替えて、より奇麗な見た目にすることもできるので…。
尚、このアドオンを利用して用意した形状は、レンダーエンジンが Eevee でもそれらしくレンダリングされる模様。レンダーエンジンを Workbench に変更しなくてもいい。
続いて、カラー画像やデプスマップ画像を選択するのだけど、ここでちょっと注意。このアドオンは2つの方法で画像を読み込める。
- A: カラー画像を1枚、デプスマップ画像を1枚用意して、別々に読み込む。
- B: カラー画像の右隣りにデプスマップ画像をくっつけた状態の1枚の画像を用意して、1回で読み込む。
今回は、Aの流れ、カラー画像とデプスマップ画像が別々になってるやり方で読み込む。
まずはカラー画像を選択して読み込む。その際、右上の、「Separate Depth Map」にチェックを入れて、カラー画像とデプスマップ画像を分けて読み込むように指定する。もし、該当項目が表示されてなかったら、右上の歯車っぽいアイコンをクリックすれば該当項目(オプション設定)が表示される。たぶん。
カラー画像を選択し終わると、次に、デプスマップ画像を選ぶためのファイル選択ダイアログが開く。デプスマップ画像を選んで、「Load Depth Image」をクリック。
これで、デプスマップが反映された形状が出現する。
この状態だと分かりづらいので、右上のアイコンをクリックして、レンダープレビューに切り替える。これでテクスチャが反映された状態で表示される。
一応、1枚の画像を読み込んで済ませる場合についても説明。要は、以下のような見た目の画像を用意すればいいらしい。こういう状態の画像であれば、ファイル選択時に1回の指定で済む。
{kind=link}
ただし、この状態の画像を読み込んだ場合、3Dビューのシェーディングモードの設定によっては、カラー画像部分とデプスマップ画像部分の両方がモデルに割り当てられた状態で表示されてしまうこともある。
個人的には、カラー画像とデプスマップ画像は別々にしておいたほうが問題が起きにくい気もした。別々の画像にしておけば、デプスマップだけを差し替えて様子を見てみたり、カラー画像だけを高解像度の画像で差し替えて、より奇麗な見た目にすることもできるので…。
尚、このアドオンを利用して用意した形状は、レンダーエンジンが Eevee でもそれらしくレンダリングされる模様。レンダーエンジンを Workbench に変更しなくてもいい。
◎ 仕組みを少し調べた :
どういうモディファイアが適用されているのか眺めてみた。
まず、元になってるオブジェクトは平面一枚で、細分化はされていなかった。4つの頂点で構成された1枚のポリゴンだけが存在している。
適用されているモディファイアは、以下の4種類。
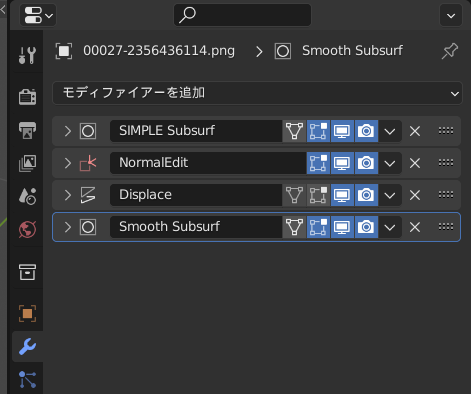
それぞれ、以下のような状態が指定されている。
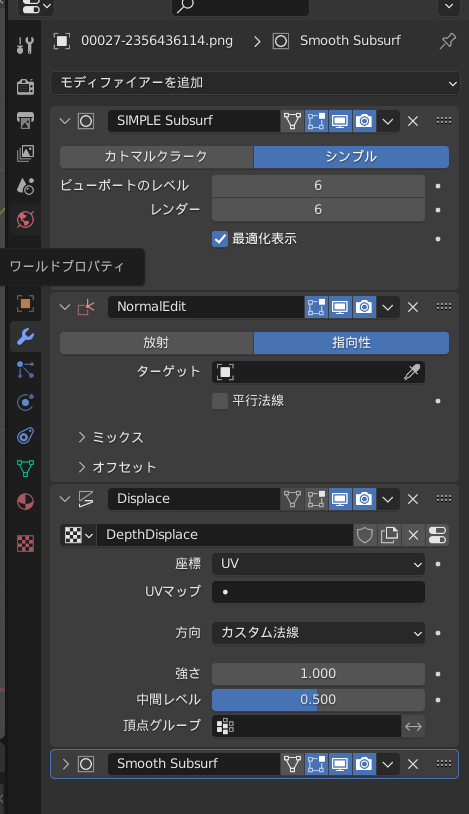
おそらくだけど…。
NormalEditとやらは何の効果をかけているのか分らなかった。表示の有効無効を切り替えても見た目の変化がなかったので…。これをかけておかないと何か問題が出てきてしまう状況があるのかもしれない。
ちなみに。
まず、元になってるオブジェクトは平面一枚で、細分化はされていなかった。4つの頂点で構成された1枚のポリゴンだけが存在している。
適用されているモディファイアは、以下の4種類。
それぞれ、以下のような状態が指定されている。
おそらくだけど…。
- サブディビジョンサーフェイスの「シンプル」を使って、平面を細分化したものと同様の状態にして、
- ディスプレイスでデプスマップ画像に基づいて頂点の位置を変更、
- 最後にサブディビジョンサーフェイスをかけて全体の形状を滑らかに、
NormalEditとやらは何の効果をかけているのか分らなかった。表示の有効無効を切り替えても見た目の変化がなかったので…。これをかけておかないと何か問題が出てきてしまう状況があるのかもしれない。
ちなみに。
- カラー画像を変更したい → マテリアルプロパティで、カラー、及び、放射で指定されているテクスチャ画像を差し替える。
- デプスマップを変更したい → テクスチャプロパティで指定されているテクスチャ画像を差し替える。
◎ カラー画像とデプスマップが1つになってる画像について :
カラー画像とデプスマップ画像が繋がってる画像がどうして使われてるのかと疑問だったけど、以下で紹介されてる Stable Diffusion web UI の拡張機能が関係してそうな気がしてきた。
_Stable Diffusion WebUIを使ってDepth画像を作成して立体視を楽しむ|Alone1M
カラー画像とデプスマップ画像を自動で繋げて出力してくれる拡張機能が存在しているらしい。blender の ImportDepthMapアドオンは、その拡張機能を利用することが前提で作られていたのかもしれない。
_Stable Diffusion WebUIを使ってDepth画像を作成して立体視を楽しむ|Alone1M
カラー画像とデプスマップ画像を自動で繋げて出力してくれる拡張機能が存在しているらしい。blender の ImportDepthMapアドオンは、その拡張機能を利用することが前提で作られていたのかもしれない。
◎ 本来作られるべき形状 :
作業をしていてふと疑問に思ったのだけど、こういった手順で作られるべき形状は、コレではないのではないか、と思えてきた。
今回、左側のような形状が作られたわけだけど…。本当なら、右側のような形状になるのが正しいのでは…?
もっとも、右側のような形状を作るためには、元画像がどのくらいの画角で撮影されてるのか分からないといけない気もする。でも、画角なんて推測しようもないか…。
一応、ラティス変形を使って、適当だけど若干ソレっぽい形にしてみた。
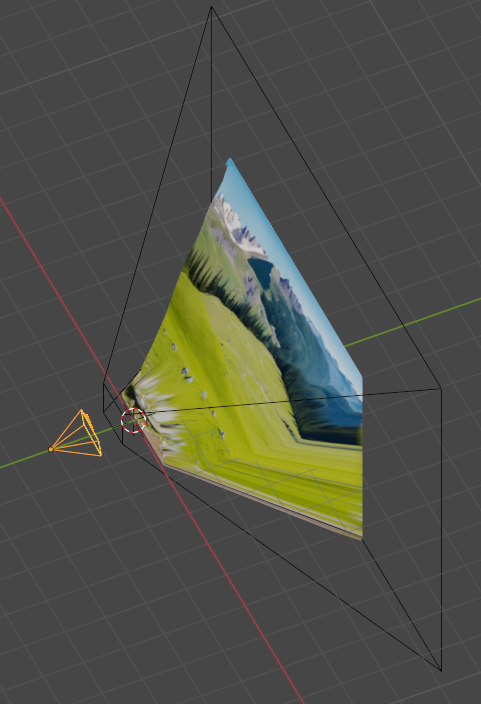
こっちのほうが、まだ多少はソレっぽく見えるような気もする…。どうなんだろう…。
今回、左側のような形状が作られたわけだけど…。本当なら、右側のような形状になるのが正しいのでは…?
もっとも、右側のような形状を作るためには、元画像がどのくらいの画角で撮影されてるのか分からないといけない気もする。でも、画角なんて推測しようもないか…。
一応、ラティス変形を使って、適当だけど若干ソレっぽい形にしてみた。
こっちのほうが、まだ多少はソレっぽく見えるような気もする…。どうなんだろう…。
[ ツッコむ ]
#2 [cg_tools] MiDaSを動かしてみたいのだけどやり方がわからない
1枚の静止画像から奥行き情報を推測してデプスマップを作ってくれる MiDaS というアルゴリズム? AI? があって、画像生成AI Stable Diffusion web UI の ControlNet でも使えるのだけど。本家版には更に強力な学習データが存在しているようで、それを使うとどのくらい結果が違ってくるのか気になった。ちょっと試してみたいのだけど…ローカルでどうやって動かせばいいのか、そこがさっぱり分らない…。
_MiDaS | PyTorch
_GitHub - isl-org/MiDaS: Code for robust monocular depth estimation described in "Ranftl et. al., Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer, TPAMI 2022"
PyTorch なるPythonモジュールが関係してるっぽいのだけど、他に何のモジュールをインストールすれば使えるようになるのか…。おそらくだけど、AI関係の研究をしてる人達にとって常識レベルの部分は、公式ドキュメント内でバッサリ説明が省かれている気がする…。そのへん分かんないヤツは手を出すな、みたいな感じなのかな…。
_単眼深度推定モデル MiDaS の解説と SageMaker へのデプロイ - Qiita
_画像から深度を推定するMiDaS - Qiita
_単眼カメラの撮影画像に、学習済みの深度推定器を使ってみた(MacOS CPU) - Qiita
_MiDaS Webcamを用いてリアルタイム単眼深度推定してみた - Qiita
動作環境に Windows10 の記述が見えるので、ローカルでも動くのは間違いないのだろうけど…。
_MiDaS | PyTorch
_GitHub - isl-org/MiDaS: Code for robust monocular depth estimation described in "Ranftl et. al., Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer, TPAMI 2022"
PyTorch なるPythonモジュールが関係してるっぽいのだけど、他に何のモジュールをインストールすれば使えるようになるのか…。おそらくだけど、AI関係の研究をしてる人達にとって常識レベルの部分は、公式ドキュメント内でバッサリ説明が省かれている気がする…。そのへん分かんないヤツは手を出すな、みたいな感じなのかな…。
_単眼深度推定モデル MiDaS の解説と SageMaker へのデプロイ - Qiita
_画像から深度を推定するMiDaS - Qiita
_単眼カメラの撮影画像に、学習済みの深度推定器を使ってみた(MacOS CPU) - Qiita
_MiDaS Webcamを用いてリアルタイム単眼深度推定してみた - Qiita
動作環境に Windows10 の記述が見えるので、ローカルでも動くのは間違いないのだろうけど…。
[ ツッコむ ]
2023/05/29(月) [n年前の日記]
#1 [cg_tools] MiDaSの動かし方が分かったのでメモ
1枚の静止画像から奥行きを推測してデプスマップ(深度マップ、z map)を作れる MiDaS というアルゴリズム? AI? が気になった。
_MiDaS | PyTorch
_GitHub - isl-org/MiDaS
ローカル環境で動かせるようにするための手順が分かったので一応メモ。
環境は以下。
AI関係のプログラムだから動かすためにはGPUが必要なのかなと思っていたけど、CPUだけでも処理できるっぽい。その分処理時間は増えてしまうのだろうけど、数秒で結果が得られてるようなので、その程度の処理時間で済むならCPUで処理しても問題無いかなと…。まあ、リアルタイムに処理したいとか、膨大な枚数を処理したい場合は、GPUが必要になるのかも。
導入手順をざっくりと列挙すると、以下のような感じ。
_MiDaS | PyTorch
_GitHub - isl-org/MiDaS
ローカル環境で動かせるようにするための手順が分かったので一応メモ。
環境は以下。
- Windows10 x64 22H2
- Python 3.10.6 64bit
- git 2.40.1
- CPU : AMD Ryzen 5 5600X, RAM : 16GB
AI関係のプログラムだから動かすためにはGPUが必要なのかなと思っていたけど、CPUだけでも処理できるっぽい。その分処理時間は増えてしまうのだろうけど、数秒で結果が得られてるようなので、その程度の処理時間で済むならCPUで処理しても問題無いかなと…。まあ、リアルタイムに処理したいとか、膨大な枚数を処理したい場合は、GPUが必要になるのかも。
導入手順をざっくりと列挙すると、以下のような感じ。
- github から MiDaS関連のファイル群を git clone で入手。
- Pythonの仮想環境を作成。
- MiDaSの動作に必要なPythonモジュールをインストール。
- 学習モデルデータを入手して weights フォルダに入れる。
- run.py を実行して動作確認。
◎ githubからクローン :
以下のページから、git を使ってプロジェクトファイル?一式をクローンする。
_GitHub - isl-org/MiDaS
今回は、D:\aiwork\midas\ というフォルダを作成して、その中で作業してみた。
MiDaS というフォルダが作られて、ファイル一式がダウンロードされた。
_GitHub - isl-org/MiDaS
今回は、D:\aiwork\midas\ というフォルダを作成して、その中で作業してみた。
git clone https://github.com/isl-org/MiDaS.git
MiDaS というフォルダが作られて、ファイル一式がダウンロードされた。
◎ Pythonの仮想環境を作成 :
MiDaS を動かすためには、Pyhonの色々なモジュールが必要になる。普段利用してるPython環境にそれらのモジュールをインストールしてしまうと、各モジュールのバージョン管理が面倒になるので、仮想環境を作成して、その中で作業することにしたい。
MiDaSフォルダの中に入って、venv を使って仮想環境を作成。
venv というフォルダが作成されて、その中にPythonの環境が入った。
仮想環境のPythonに切り替える。
インストールされているモジュールの一覧を表示する。
pip と setuptools、2つのモジュールしか入ってない奇麗な状態。
ところで、「pipの新しいバージョンがあるよ」「python.exe -m pip install --upgrade pip を実行して更新できるよ」と表示されてるので、一応更新しておく。
MiDaSフォルダの中に入って、venv を使って仮想環境を作成。
cd MiDaS python -m venv venv
- -m venv : venv というモジュールを使え、と指示してる。
- 最後の venv はフォルダ名(ディレクトリ名)。venv というフォルダの中に仮想環境を作れ、と指示してる。フォルダが無かったら自動でフォルダ作成してくれる。
venv というフォルダが作成されて、その中にPythonの環境が入った。
仮想環境のPythonに切り替える。
venv\Scripts\activate
インストールされているモジュールの一覧を表示する。
pip list
(venv) D:\aiwork\midas\MiDaS> pip list Package Version ---------- ------- pip 22.2.1 setuptools 63.2.0 [notice] A new release of pip available: 22.2.1 -> 23.1.2 [notice] To update, run: python.exe -m pip install --upgrade pip
pip と setuptools、2つのモジュールしか入ってない奇麗な状態。
ところで、「pipの新しいバージョンがあるよ」「python.exe -m pip install --upgrade pip を実行して更新できるよ」と表示されてるので、一応更新しておく。
python.exe -m pip install --upgrade pip
◎ 必要なモジュールをインストール :
githubから入手したファイル群の中に environment.yaml というファイルがある。この中に、使っているモジュールのバージョンが記録されていた。引用してみる。
environment.yaml
試したところ、これらのバージョンを使わないと、よく分からないエラーがバンバン出てしまったので…。バージョンを指定しつつモジュールをインストールしていく。
ちなみに、MiDaS を動かすにあたって重要なのは timm というモジュールっぽい。このモジュールをインストールすれば、MiDaS を動かすために必要なモジュールのほとんどがインストールできてしまう模様。ただ、依存してるモジュールのバージョンまで合わせてくれるわけではないらしい…。最新版のモジュールが入ってしまう…。
pip を使ってインストールしていく。
他に、opencv-contrib-python も必要っぽい。これを入れないとエラーが出てしまった。また、サンプルスクリプトを眺めると、matplotlib も必要になりそう。インストールしておく。
インストールされたモジュール一覧を確認。environment.yaml に記述されたバージョンと一致してるか確認しておく。
environment.yaml
name: midas-py310
channels:
- pytorch
- defaults
dependencies:
- nvidia::cudatoolkit=11.7
- python=3.10.8
- pytorch::pytorch=1.13.0
- torchvision=0.14.0
- pip=22.3.1
- numpy=1.23.4
- pip:
- opencv-python==4.6.0.66
- imutils==0.5.4
- timm==0.6.12
- einops==0.6.0
試したところ、これらのバージョンを使わないと、よく分からないエラーがバンバン出てしまったので…。バージョンを指定しつつモジュールをインストールしていく。
ちなみに、MiDaS を動かすにあたって重要なのは timm というモジュールっぽい。このモジュールをインストールすれば、MiDaS を動かすために必要なモジュールのほとんどがインストールできてしまう模様。ただ、依存してるモジュールのバージョンまで合わせてくれるわけではないらしい…。最新版のモジュールが入ってしまう…。
pip を使ってインストールしていく。
pip install timm==0.6.12 pip install torchvision==0.14.0 pip install torch==1.13.0 pip install numpy==1.23.4 pip install einops==0.6.0 pip install imutils==0.5.4 pip install opencv-python==4.6.0.66
他に、opencv-contrib-python も必要っぽい。これを入れないとエラーが出てしまった。また、サンプルスクリプトを眺めると、matplotlib も必要になりそう。インストールしておく。
pip install opencv-contrib-python==4.6.0.66 pip install matplotlib
インストールされたモジュール一覧を確認。environment.yaml に記述されたバージョンと一致してるか確認しておく。
> pip list Package Version --------------------- -------- certifi 2023.5.7 charset-normalizer 3.1.0 colorama 0.4.6 contourpy 1.0.7 cycler 0.11.0 einops 0.6.0 filelock 3.12.0 fonttools 4.39.4 fsspec 2023.5.0 huggingface-hub 0.14.1 idna 3.4 imutils 0.5.4 Jinja2 3.1.2 kiwisolver 1.4.4 MarkupSafe 2.1.2 matplotlib 3.7.1 mpmath 1.3.0 networkx 3.1 numpy 1.23.4 opencv-contrib-python 4.6.0.66 opencv-python 4.6.0.66 packaging 23.1 Pillow 9.5.0 pip 23.1.2 pyparsing 3.0.9 python-dateutil 2.8.2 PyYAML 6.0 requests 2.31.0 setuptools 63.2.0 six 1.16.0 sympy 1.12 timm 0.6.12 torch 1.13.0 torchvision 0.14.0 tqdm 4.65.0 typing_extensions 4.6.2 urllib3 2.0.2
◎ 学習モデルデータを入手 :
MiDaS を動かすためには学習モデルデータも必要。この学習モデルデータは、精度が高いけど容量が大きいもの、精度は低いけど容量が少なくて済むもの ―― 色々な種類がある。
_GitHub - isl-org/MiDaS
_Release MiDaS 3.1 - isl-org/MiDaS - GitHub
_Release MiDaS v3 (DPT) - isl-org/MiDaS - GitHub
上記ページから、dpt_beit_large_512, dpt_hybrid_384 等々の学習モデルデータを入手する。ファイルの拡張子は .pt。
今回は以下のファイルを入手してみた。
各 .pt を入手できたら、weights というフォルダの中にコピーする。
余談。各ファイル名についている 512, 384, 256, 224 という数字は、512x512, 384x384, 256x256, 224x224 で学習したよ、という意味らしい。
余談その2。画像生成AI Stable Diffusion web UI の ControlNet で使っているのは、dpt_hybrid_384.pt だった。
余談その3。学習モデルデータも含めて、全体のファイル群は、5.55GBになった。
_GitHub - isl-org/MiDaS
_Release MiDaS 3.1 - isl-org/MiDaS - GitHub
_Release MiDaS v3 (DPT) - isl-org/MiDaS - GitHub
上記ページから、dpt_beit_large_512, dpt_hybrid_384 等々の学習モデルデータを入手する。ファイルの拡張子は .pt。
今回は以下のファイルを入手してみた。
dpt_beit_large_512.pt (1.5GB) dpt_hybrid_384.pt (470MB) dpt_large_384.pt (1.3GB) dpt_levit_224.pt (196MB) dpt_swin2_large_384.pt (840MB) dpt_swin2_tiny_256.pt (165MB)
各 .pt を入手できたら、weights というフォルダの中にコピーする。
余談。各ファイル名についている 512, 384, 256, 224 という数字は、512x512, 384x384, 256x256, 224x224 で学習したよ、という意味らしい。
余談その2。画像生成AI Stable Diffusion web UI の ControlNet で使っているのは、dpt_hybrid_384.pt だった。
余談その3。学習モデルデータも含めて、全体のファイル群は、5.55GBになった。
◎ テスト画像を入手 :
テストする画像を入手して、inputフォルダの中に入れておく。おそらく、pngの他にjpgもイケそう。公式サイトのサンプルでは犬の写真画像を使ってたので、それに倣ってみる。以下から入手。
_hub/dog.jpg at master - pytorch/hub - GitHub
dog.jpg をダウンロードして、inputフォルダに入れた。
_hub/dog.jpg at master - pytorch/hub - GitHub
{kind=link}
{kind=link}
dog.jpg をダウンロードして、inputフォルダに入れた。
◎ サンプルスクリプトを実行 :
githubから入手したファイル群の中に、run.py というPythonスクリプトがある。このスクリプトを実行することで MiDaS の動作確認ができるらしい。
実行すると、こうなった。
outputフォルダ内に、以下の2つのファイルが生成された。
.png はPNG画像だろうけど、.pfm とは何ぞや。
_画像フォーマット
PFM = Portable Float Map、らしい。Float…? それはつまり、各ドットの情報を浮動小数点数で持ってるということだろうか。1チャンネル8bitしか情報を持ってないPNGと比べたら、めっちゃ豊かな情報を持ってそう。
さておき。.png はフツーに表示できる。

たしかにデプスマップを得られた。これで MiDaS をローカル環境で動かすことができた…。
ところで、run.py に渡す --model_type で学習モデルデータを指定できるのだけど、公式ページのドキュメントでは以下が指定できると書いてあった。もちろん、学習モデルデータ(.pt)を入手して weightsフォルダに入れてあればの話。
python run.py --model_type dpt_hybrid_384 --input_path input --output_path output
- --model_type dpt_hybrid_384 : 学習モデルデータとして dpt_hybrid_384 を指定。別の学習モデルデータを使いたい時は変更する。
- --input_path input : 画像が入ってるフォルダを指定。inputフォルダを指定してる。
- --output_path output : 結果画像の保存先フォルダを指定。outputフォルダを指定してる。
実行すると、こうなった。
(venv) D:\aiwork\midas\MiDaS> python run.py --model_type dpt_hybrid_384 --input_path input --output_path output
Initialize
Device: cpu
Model loaded, number of parameters = 123M
Start processing
Processing input\dog.jpg (1/1)
Input resized to 480x384 before entering the encoder
Finished
「Device: cpu」と表示されてるので、GPUではなくCPUで処理してるのだろう…。また、「入力された画像を 480x384 にリサイズしてから処理してるよ」とも表示されてる。outputフォルダ内に、以下の2つのファイルが生成された。
dog-dpt_hybrid_384.pfm dog-dpt_hybrid_384.png
.png はPNG画像だろうけど、.pfm とは何ぞや。
_画像フォーマット
PFM = Portable Float Map、らしい。Float…? それはつまり、各ドットの情報を浮動小数点数で持ってるということだろうか。1チャンネル8bitしか情報を持ってないPNGと比べたら、めっちゃ豊かな情報を持ってそう。
さておき。.png はフツーに表示できる。
たしかにデプスマップを得られた。これで MiDaS をローカル環境で動かすことができた…。
ところで、run.py に渡す --model_type で学習モデルデータを指定できるのだけど、公式ページのドキュメントでは以下が指定できると書いてあった。もちろん、学習モデルデータ(.pt)を入手して weightsフォルダに入れてあればの話。
dpt_beit_large_512 dpt_beit_large_384 dpt_beit_base_384 dpt_swin2_large_384 dpt_swin2_base_384 dpt_swin2_tiny_256 dpt_swin_large_384 dpt_next_vit_large_384 dpt_levit_224 dpt_large_384 dpt_hybrid_384 midas_v21_384 midas_v21_small_256 openvino_midas_v21_small_256
◎ 謎の警告が少し気になる :
学習モデルデータとして dpt_beit_large_512 を指定すると、何故かエラーが、というか警告が出る…。一応、結果画像は得られるのだけど…。
「今後のリリースではインデックス引数が必要になりますよ」と言ってるようだけど…。コレ、どうすればいいんだろう…?
MiDaS 3.0 の学習モデルデータを使うとこの警告は出てこないけど、MiDaS 3.1 の学習モデルデータを使うと出てくるようではあるなと…。
(venv) D:\aiwork\midas\MiDaS> python run.py --model_type dpt_beit_large_512 --input_path input --output_path output
Initialize
Device: cpu
D:\aiwork\midas\MiDaS\venv\lib\site-packages\torch\functional.py:504: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ..\aten\src\ATen\native\TensorShape.cpp:3191.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Model loaded, number of parameters = 345M
Start processing
Processing input\dog.jpg (1/1)
Input resized to 640x512 before entering the encoder
Finished
「今後のリリースではインデックス引数が必要になりますよ」と言ってるようだけど…。コレ、どうすればいいんだろう…?
MiDaS 3.0 の学習モデルデータを使うとこの警告は出てこないけど、MiDaS 3.1 の学習モデルデータを使うと出てくるようではあるなと…。
◎ グレイスケール画像で出力したい :
現状の run.py は、人間が目で見て分かりやすくするために、デプスマップを色付きの画像で出力しているけれど。他の何かに渡して処理したい場合、グレースケール画像で出力してくれたほうが嬉しいわけで…。
そんな時は、--grayscale をつければいいらしい。

たしかにグレースケールになった。
そんな時は、--grayscale をつければいいらしい。
python run.py --model_type dpt_large_384 --input_path input --output_path output --grayscale
たしかにグレースケールになった。
◎ その他のオプション :
run.py に --help をつければ、ヘルプが表示される。
-i input, -o output, -t dpt_hybrid_384 といった記述も指定できるっぽいな…。
run.py を眺めてみたけど、--model_type を指定しない場合、dpt_beit_large_512 がデフォルトで指定される模様。
> python run.py --help
usage: run.py [-h] [-i INPUT_PATH] [-o OUTPUT_PATH] [-m MODEL_WEIGHTS] [-t MODEL_TYPE] [-s]
[--optimize] [--height HEIGHT] [--square] [--grayscale]
options:
-h, --help show this help message and exit
-i INPUT_PATH, --input_path INPUT_PATH
Folder with input images (if no input path is specified, images are tried
to be grabbed from camera)
-o OUTPUT_PATH, --output_path OUTPUT_PATH
Folder for output images
-m MODEL_WEIGHTS, --model_weights MODEL_WEIGHTS
Path to the trained weights of model
-t MODEL_TYPE, --model_type MODEL_TYPE
Model type: dpt_beit_large_512, dpt_beit_large_384, dpt_beit_base_384,
dpt_swin2_large_384, dpt_swin2_base_384, dpt_swin2_tiny_256,
dpt_swin_large_384, dpt_next_vit_large_384, dpt_levit_224, dpt_large_384,
dpt_hybrid_384, midas_v21_384, midas_v21_small_256 or
openvino_midas_v21_small_256
-s, --side Output images contain RGB and depth images side by side
--optimize Use half-float optimization
--height HEIGHT Preferred height of images feed into the encoder during inference. Note
that the preferred height may differ from the actual height, because an
alignment to multiples of 32 takes place. Many models support only the
height chosen during training, which is used automatically if this
parameter is not set.
--square Option to resize images to a square resolution by changing their widths
when images are fed into the encoder during inference. If this parameter
is not set, the aspect ratio of images is tried to be preserved if
supported by the model.
--grayscale Use a grayscale colormap instead of the inferno one. Although the inferno
colormap, which is used by default, is better for visibility, it does not
allow storing 16-bit depth values in PNGs but only 8-bit ones due to the
precision limitation of this colormap.
-i input, -o output, -t dpt_hybrid_384 といった記述も指定できるっぽいな…。
run.py を眺めてみたけど、--model_type を指定しない場合、dpt_beit_large_512 がデフォルトで指定される模様。
◎ Webカメラからの入力 :
試しに python run.py だけで動かしたら、ウインドウが表示されて何かを表示し続けてるようではあった。
DOS窓には「No input path specified. Grabbing images from camera.」と表示されてたので、Webカメラの入力を処理しようとしてたっぽい。でも、自分のPC、Webカメラついてないんですけど…。ウインドウを閉じて強制終了した…。
せっかくだから、Webカメラからの入力も試してみた。USB接続Webカメラ BUFFALO BSWHD01 を部屋から発掘して接続。python run.py を実行。こんな感じになった。
たしかに、Webカメラからの入力に対して処理できてるようだなと…。
DOS窓上では「FPS: 0.47」と表示されていた。1フレームを数秒かけて処理して返してる状態なのだな…。もしかするとGPUで処理できたらもっと速く結果が得られるのだろうか。
ウインドウのタイトルに「ESCキーで抜けられるよ」と書いてあることに気づいた。ESCキーを数秒間ポンポンポンと連打していたら、ウインドウが閉じてくれた。
DOS窓には「No input path specified. Grabbing images from camera.」と表示されてたので、Webカメラの入力を処理しようとしてたっぽい。でも、自分のPC、Webカメラついてないんですけど…。ウインドウを閉じて強制終了した…。
せっかくだから、Webカメラからの入力も試してみた。USB接続Webカメラ BUFFALO BSWHD01 を部屋から発掘して接続。python run.py を実行。こんな感じになった。
たしかに、Webカメラからの入力に対して処理できてるようだなと…。
DOS窓上では「FPS: 0.47」と表示されていた。1フレームを数秒かけて処理して返してる状態なのだな…。もしかするとGPUで処理できたらもっと速く結果が得られるのだろうか。
ウインドウのタイトルに「ESCキーで抜けられるよ」と書いてあることに気づいた。ESCキーを数秒間ポンポンポンと連打していたら、ウインドウが閉じてくれた。
◎ 参考ページ :
_MiDaS | PyTorch
_GitHub - isl-org/MiDaS: Code for robust monocular depth estimation described in "Ranftl et. al., Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer, TPAMI 2022"
_MiDaS Webcamを用いてリアルタイム単眼深度推定してみた - Qiita
_【MiDaS】深度推定モデルをいろんな物で試してみる | FarmL
_単眼深度推定モデル MiDaS の解説と SageMaker へのデプロイ - Qiita
_画像から深度を推定するMiDaS - Qiita
_単眼カメラの撮影画像に、学習済みの深度推定器を使ってみた(MacOS CPU) - Qiita
_venv: Python 仮想環境管理 - Qiita
_GitHub - isl-org/MiDaS: Code for robust monocular depth estimation described in "Ranftl et. al., Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer, TPAMI 2022"
_MiDaS Webcamを用いてリアルタイム単眼深度推定してみた - Qiita
_【MiDaS】深度推定モデルをいろんな物で試してみる | FarmL
_単眼深度推定モデル MiDaS の解説と SageMaker へのデプロイ - Qiita
_画像から深度を推定するMiDaS - Qiita
_単眼カメラの撮影画像に、学習済みの深度推定器を使ってみた(MacOS CPU) - Qiita
_venv: Python 仮想環境管理 - Qiita
◎ 余談 :
MiDaS を触っていてふと思ったことをなんとなくメモ。思考メモ。
奥行き情報を取得しようとする場合、本来であれば2台のカメラで撮影して視差情報を利用して、とかやらないといかんのだろうと思うのだけど。1枚の静止画像から「たぶんこんな感じじゃねえかなあ」とAIが奥行き情報を作ってくれるなんて、スゴイことになってるなと…。仕組みを実現してしまった方々、凄過ぎる…。
もっとも、人間だって写真やTV映像を見て、「この人は手前に立っている」「この建物は奥にある」などと無意識に推測しながら認識してるわけで。
視差情報も無いのにどうしてそんなことができるかと言えば、それはやはり学習の賜物。自分の身の回りの風景を二つの目で捉えて距離感を測る訓練を延々してきたから、単眼で捉えた視覚情報に対しても前後関係を推測することができているのだろうなと。そう考えると、人間ってなかなかスゴイことしてるなと…。
そして、「人間が学習で能力を獲得しているのだから、コンピュータだって学習すれば似たようなことができらあ!」と ―― ある種乱暴だけど楽観的な思考が根底にあるから、こういった技術がここまで発達してきたような、そんな気もする。と言っても、何をどう学習させるか、そこが閃かなかったらどうにもならないのだろうけど。
奥行き情報を取得しようとする場合、本来であれば2台のカメラで撮影して視差情報を利用して、とかやらないといかんのだろうと思うのだけど。1枚の静止画像から「たぶんこんな感じじゃねえかなあ」とAIが奥行き情報を作ってくれるなんて、スゴイことになってるなと…。仕組みを実現してしまった方々、凄過ぎる…。
もっとも、人間だって写真やTV映像を見て、「この人は手前に立っている」「この建物は奥にある」などと無意識に推測しながら認識してるわけで。
視差情報も無いのにどうしてそんなことができるかと言えば、それはやはり学習の賜物。自分の身の回りの風景を二つの目で捉えて距離感を測る訓練を延々してきたから、単眼で捉えた視覚情報に対しても前後関係を推測することができているのだろうなと。そう考えると、人間ってなかなかスゴイことしてるなと…。
そして、「人間が学習で能力を獲得しているのだから、コンピュータだって学習すれば似たようなことができらあ!」と ―― ある種乱暴だけど楽観的な思考が根底にあるから、こういった技術がここまで発達してきたような、そんな気もする。と言っても、何をどう学習させるか、そこが閃かなかったらどうにもならないのだろうけど。
◎ 余談その2 :
妄想メモ。
1枚の静止画像から奥行き情報を推測できるなら…。別々の方向から撮影した数枚の画像があれば、色んな方向から見た深度情報を得られるよなと。その複数の深度情報を擦り合わせていったら、より正確な3D形状を得られたりしないだろうか。などと妄想。
でも、複数の方向から撮影できてる時点でそこには視差情報が含まれてるから、ソレを使って形状を構成するほうが妥当な気もしてきた。
まあ、そういう研究は既に誰かがやってるだろう…。というか、スマホで数枚撮影してそこから形状を作ってしまうサービスを結構前にどこかで見かけた気もするし…。
MiDaSのような技術は、「一枚の静止画しかないですけどコレ使ってとにかくどうにかしてください」というある種縛りプレイを強要される状況でこそ使える技術、だよな…。「もし必要なら色んな方向から撮影できますよ」と言ってもらえる恵まれた状況なら別の技術を使ったほうが…。
1枚の静止画像から奥行き情報を推測できるなら…。別々の方向から撮影した数枚の画像があれば、色んな方向から見た深度情報を得られるよなと。その複数の深度情報を擦り合わせていったら、より正確な3D形状を得られたりしないだろうか。などと妄想。
でも、複数の方向から撮影できてる時点でそこには視差情報が含まれてるから、ソレを使って形状を構成するほうが妥当な気もしてきた。
まあ、そういう研究は既に誰かがやってるだろう…。というか、スマホで数枚撮影してそこから形状を作ってしまうサービスを結構前にどこかで見かけた気もするし…。
MiDaSのような技術は、「一枚の静止画しかないですけどコレ使ってとにかくどうにかしてください」というある種縛りプレイを強要される状況でこそ使える技術、だよな…。「もし必要なら色んな方向から撮影できますよ」と言ってもらえる恵まれた状況なら別の技術を使ったほうが…。
[ ツッコむ ]
2023/05/30(火) [n年前の日記]
#1 [cg_tools][ubuntu][linux] MiDaSをLinux上で動かしてみた
_昨日、
Windows10 x64 22H2上で MiDaS を動かしてみたけれど。GPUを使わずにCPUだけで処理できるなら、内蔵GPUしか持ってないサブPC(Intel Core i3-6100T、Ubuntu Linux 22.04 LTS機)上でも動かせるのかなと疑問が湧いた。
そんなわけで、Ubuntu Linux 22.04 LTS上でも実際に動くのか試してみた。フツーに動いてくれた。とメモ。
導入の手順は、 _昨日の作業内容 と大体同じ。
ちょっとハマったのが、Pythonの仮想環境を用意して切り替えるあたり。Ubuntu Linux 22.04 LTS の場合、Python 3.x を動かすには、python3 と打つ。Python 2.x を動かしたい場合は python2 と打つ。単に python と打ったら「そんなものはねえ」と言われた…。なので、仮想環境を作る際は以下を打つ。
仮想環境への切り替え方も、Windowsとはちょっと違う。
以下が参考になった。ありがたや。
_【venv】Ubuntuでpython仮想環境をつくる - Qiita
また、今回Pythonモジュールは以下の順番でインストールした。一番最後に timm をインストールことで、一度インストールしたtimmの依存モジュール群を後から別バージョンでインストールし直す状態を避けてみたつもり。
そんなわけで、Ubuntu Linux 22.04 LTS上でも実際に動くのか試してみた。フツーに動いてくれた。とメモ。
導入の手順は、 _昨日の作業内容 と大体同じ。
ちょっとハマったのが、Pythonの仮想環境を用意して切り替えるあたり。Ubuntu Linux 22.04 LTS の場合、Python 3.x を動かすには、python3 と打つ。Python 2.x を動かしたい場合は python2 と打つ。単に python と打ったら「そんなものはねえ」と言われた…。なので、仮想環境を作る際は以下を打つ。
python3 -m venv venv
仮想環境への切り替え方も、Windowsとはちょっと違う。
- Windows10 x64 22H2の場合、venv\Scripts\activate を実行して仮想環境に切り替えて、venv\Scripts\deactivate.bat で仮想環境を抜ける。
- Linuxの場合、source venv/bin/activate で仮想環境に切り替えて、deactivate と打って仮想環境を抜ける。
以下が参考になった。ありがたや。
_【venv】Ubuntuでpython仮想環境をつくる - Qiita
また、今回Pythonモジュールは以下の順番でインストールした。一番最後に timm をインストールことで、一度インストールしたtimmの依存モジュール群を後から別バージョンでインストールし直す状態を避けてみたつもり。
pip install numpy==1.23.4 pip install einops==0.6.0 pip install imutils==0.5.4 pip install torch==1.13.0 pip install torchvision==0.14.0 pip install opencv-python==4.6.0.66 pip install opencv-contrib-python==4.6.0.66 pip install matplotlib pip install timm==0.6.12
◎ 余談。Python3 をpythonにしておいた :
せっかくだから、以下のページを参考にして、python と打ったら python3 が使われるようにしておいた。とメモ。
_Ubuntu Linux 22.04 LTSで、"python"コマンドがないと言われたら - CLOVER
他に、update-alternatives を使って切り替える方法もあるらしい。「update-alternatives python」でググれば解説ページに辿り着ける。
_Ubuntuでpythonのバージョンを切り換える - Qiita
_デフォルトで使うpythonのバージョンをめちゃ簡単に切り替える方法|かつお
_Ubuntu Linux 22.04 LTSで、"python"コマンドがないと言われたら - CLOVER
sudo apt install python-is-python3
$ python -V Python 3.10.6
他に、update-alternatives を使って切り替える方法もあるらしい。「update-alternatives python」でググれば解説ページに辿り着ける。
_Ubuntuでpythonのバージョンを切り換える - Qiita
_デフォルトで使うpythonのバージョンをめちゃ簡単に切り替える方法|かつお
[ ツッコむ ]
#2 [cg_tools] pfm画像の中身を目視したい
MiDaS の run.py は、処理結果を .png と .pfm (Portable Float Map) の2つで出力してくれる。.pfm にはどんな情報が含まれているのか確認してみたい。しかし、.pfm を開けそうなツールは存在するのだろうか。気になったので少し調べてみた。環境は Windows10 x64 22H2。
結論を先に書いておくと、.pfm を .exr に変換して使うのが妥当かなと…。
結論を先に書いておくと、.pfm を .exr に変換して使うのが妥当かなと…。
◎ GIMPで試した :
GIMP で開くことはできないのかな。ググってみたら、file-pnm で PFM を開けるように機能追加、という話を目にしたけど…。
_[gimp] plug-ins: add PFM reading support to file-pnm
GIMP 2.10.34 Portable で開いてみた。真っ白な画像しか出てこなかった。ただ、どれを開いてもそうなるわけでもなく…。一部の画像は隅っこのほうに黒いもやもやが入ってる。ただ、.png とは全く違う見た目なわけで…。どうも正常に開けているとは思えない。
_[gimp] plug-ins: add PFM reading support to file-pnm
GIMP 2.10.34 Portable で開いてみた。真っ白な画像しか出てこなかった。ただ、どれを開いてもそうなるわけでもなく…。一部の画像は隅っこのほうに黒いもやもやが入ってる。ただ、.png とは全く違う見た目なわけで…。どうも正常に開けているとは思えない。
◎ ImageMagickで試した :
ImageMagick 7.1.0-37 Q16-HDRI x64 で試してみた。とりあえず png に変換してみる。
GIMP と同様、真っ白な画像になった…。
_ImageMagick - Image Formats
上記ページによると、PFM は Read/Write対応済みと書いてあるように見えるのだけど…。うーん。
magick identify -verbose を使って画像の情報を眺めてみる。
別のフォーマットなのではと疑ったりもしたけど、PFM (Portable float format) と表示されてるから、画像ファイルであることは間違いなさそう。たぶん。
いきなり .pfm を開くのではなく、MiDaS が出力した .png を、ImageMagick を使って .pfm に変換して、各ツールで開けるのか試してみることにした。
.png から .pfm への変換は以下。
変換してできた .pfm を、ImageMagick に同梱されてるビューア、imdisplay で表示してみる。
つまり、ImageMagick (imdisplay) や GIMP で .pfm を開ける場合もある、ということだよな…。全ての .pfm が開けないわけではなさそう。ひょっとして、カラーの .pfm は開けるけど、グレースケールの .pfm は開けない、とか?
_Depth in float32 in meters units - Issue #36 - isl-org/MiDaS - GitHub
上記のやり取りによると、MiDaS が出力する .pfm には float32 が入ってる、と書いてある。最小値と最大値を調べて、各ドットの値を8bitに収めないと目視できる状態にならないと思うのだけど、各ツールはそういうことをしているのかどうか…。1000だの2000だのの値を取り出せても、0 - 255でクリッピングされていたら真っ白になっちゃいそうだけど…。
magick convert dog-dpt_beit_large_512.pfm out.png
GIMP と同様、真っ白な画像になった…。
_ImageMagick - Image Formats
上記ページによると、PFM は Read/Write対応済みと書いてあるように見えるのだけど…。うーん。
magick identify -verbose を使って画像の情報を眺めてみる。
> magick identify -verbose dog-dpt_beit_large_512.pfm
Image:
Filename: dog-dpt_beit_large_512.pfm
Format: PFM (Portable float format)
Class: DirectClass
Geometry: 1546x1213+0+0
Units: Undefined
Colorspace: Gray
Type: Grayscale
Endianness: LSB
Depth: 32/16-bit
Channel depth:
Gray: 16-bit
Channel statistics:
Pixels: 1875298
Gray:
min: -5.00881e+06 (-76.4295)
max: 6.35226e+08 (9692.93)
mean: 3.36157e+08 (5129.42)
median: 1.78825e+08 (2728.69)
standard deviation: 2.23969e+08 (3417.55)
kurtosis: -1.66082
skewness: -0.306461
entropy: 5.32168e-05
Rendering intent: Undefined
Gamma: 0.454545
Matte color: grey74
Background color: white
Border color: srgb(223,223,223)
Transparent color: none
Interlace: None
Intensity: Undefined
Compose: Over
Page geometry: 1546x1213+0+0
Dispose: Undefined
Iterations: 0
Compression: Undefined
Orientation: Undefined
Properties:
date:create: 2023-05-29T21:45:37+00:00
date:modify: 2023-05-29T00:41:42+00:00
signature: d65a7beee69bd2d2af7f3b85e73a82873cfe59fdf4777940af366f38d93ba316
Artifacts:
verbose: true
Tainted: False
Filesize: 7.15372MiB
Number pixels: 1.8753M
Pixel cache type: Memory
Pixels per second: 78.9084MP
User time: 0.063u
Elapsed time: 0:01.023
Version: ImageMagick 7.1.0-37 Q16-HDRI x64 1b8963a:20220605 https://imagemagick.org
別のフォーマットなのではと疑ったりもしたけど、PFM (Portable float format) と表示されてるから、画像ファイルであることは間違いなさそう。たぶん。
いきなり .pfm を開くのではなく、MiDaS が出力した .png を、ImageMagick を使って .pfm に変換して、各ツールで開けるのか試してみることにした。
.png から .pfm への変換は以下。
magick convert dog-dpt_beit_large_512.png out.pfm
変換してできた .pfm を、ImageMagick に同梱されてるビューア、imdisplay で表示してみる。
imdisplay out.pfmこれなら .png と似たような見た目になった。また、 GIMP 2.10.34 Portable でも開いてみたけど、そちらも .png と同じ見た目になった。
つまり、ImageMagick (imdisplay) や GIMP で .pfm を開ける場合もある、ということだよな…。全ての .pfm が開けないわけではなさそう。ひょっとして、カラーの .pfm は開けるけど、グレースケールの .pfm は開けない、とか?
_Depth in float32 in meters units - Issue #36 - isl-org/MiDaS - GitHub
上記のやり取りによると、MiDaS が出力する .pfm には float32 が入ってる、と書いてある。最小値と最大値を調べて、各ドットの値を8bitに収めないと目視できる状態にならないと思うのだけど、各ツールはそういうことをしているのかどうか…。1000だの2000だのの値を取り出せても、0 - 255でクリッピングされていたら真っ白になっちゃいそうだけど…。
◎ blenderで試した :
blenderで読み込めないものかなと、blender 3.3.7 x64 LTS で試してみたけど、.pfm という拡張子は画像として認識されなかった。
PFMに対応させるためのパッチが送られたこともあったらしいけど…。
_#28360 - Portable Floatmap format support - blender - Blender Projects
「マイナーなフォーマットをサポートしてたらキリが無いので」という理由で取り込まれることはなかった模様。
また、blender関係の掲示板を眺めてみたけど、「PFMを使いたい」という質問が出てくると「OpenEXRを使え」「PFM? そんなもん使ってるんじゃねえ」と言われることがほとんどのように見えた。OpenEXRは16bitの浮動小数点数で、PFMは32bitの浮動小数点数なんだけどな…。まあ、フツーは16bitで足りるやろという共通認識があるのだろう。
PFMに対応させるためのパッチが送られたこともあったらしいけど…。
_#28360 - Portable Floatmap format support - blender - Blender Projects
「マイナーなフォーマットをサポートしてたらキリが無いので」という理由で取り込まれることはなかった模様。
また、blender関係の掲示板を眺めてみたけど、「PFMを使いたい」という質問が出てくると「OpenEXRを使え」「PFM? そんなもん使ってるんじゃねえ」と言われることがほとんどのように見えた。OpenEXRは16bitの浮動小数点数で、PFMは32bitの浮動小数点数なんだけどな…。まあ、フツーは16bitで足りるやろという共通認識があるのだろう。
◎ exrに変換してみた :
以下のサービスを使って、.pfm を .exr に変換してみた。
_PFM EXR 変換。オンライン フリー - Convertio
得られた .exr を Luminance HDR 2.6.0 Build 50b31d で開いてみた。
_Luminance HDR
_Releases - LuminanceHDR/LuminanceHDR
それらしい形が目視できた。つまり、MiDaS が出力した .pfm には、ちゃんと情報が含まれているようだなと…。
得られた .exr を、blender 3.3.7 x64 LTS 上でディスプレイスモディファイアのソース画像として使ってみたところ、それらしい形状が得られた。ただ、かなり長い距離が得られるようで、縮小や移動をしてイイ感じのサイズにする作業が面倒…。奥行き方向の解像度が粗いとしても、グレースケールpng画像を利用したほうが使いやすそうだなと…。
余談。ImageMagick 7.1.0-37 Q16-HDRI x64 でも、.pfm から .exr に変換できた。
変換後の .exr を Luminance HDR 2.6.0 Build 50b31d で開いてみたけど、こちらもそれらしい形が目視できた。
_PFM EXR 変換。オンライン フリー - Convertio
得られた .exr を Luminance HDR 2.6.0 Build 50b31d で開いてみた。
_Luminance HDR
_Releases - LuminanceHDR/LuminanceHDR
それらしい形が目視できた。つまり、MiDaS が出力した .pfm には、ちゃんと情報が含まれているようだなと…。
得られた .exr を、blender 3.3.7 x64 LTS 上でディスプレイスモディファイアのソース画像として使ってみたところ、それらしい形状が得られた。ただ、かなり長い距離が得られるようで、縮小や移動をしてイイ感じのサイズにする作業が面倒…。奥行き方向の解像度が粗いとしても、グレースケールpng画像を利用したほうが使いやすそうだなと…。
余談。ImageMagick 7.1.0-37 Q16-HDRI x64 でも、.pfm から .exr に変換できた。
magick convert dog-dpt_beit_large_512.pfm out.exr
変換後の .exr を Luminance HDR 2.6.0 Build 50b31d で開いてみたけど、こちらもそれらしい形が目視できた。
◎ Darktableで試した :
Darktable 4.2.1 x64 で .pfm を開いてみた。
_darktable
最初に開いた時は真っ白だったけど、コントラスト、明るさ、その他を色々弄ってたらそれらしい形が見え始めた。ただ、どのあたりを変更すればどうなるのかがさっぱり分らない…。それでも一応、.pfm の中にそれらしい情報が入ってることぐらいは分かるけど…。
_darktable
最初に開いた時は真っ白だったけど、コントラスト、明るさ、その他を色々弄ってたらそれらしい形が見え始めた。ただ、どのあたりを変更すればどうなるのかがさっぱり分らない…。それでも一応、.pfm の中にそれらしい情報が入ってることぐらいは分かるけど…。
◎ 2023/05/31追記 :
ググっているうちに、 HDRViewというビューアと遭遇。「シンプルな研究指向の深度マップおよびハイダイナミックレンジ画像ビューア」とのこと。PFM、EXR、HDR をサポートしているらしい。
_GitHub - cdcseacave/HDRView
_Releases - cdcseacave/HDRView - GitHub
HDRView_Windows_x64.7z を解凍して、中に入っている HDRView.exe を実行してみた。ウインドウに .pfm をエクスプローラからドラッグアンドドロップしてみたら、それっぽい形が一発で表示された。素晴らしい…。これを使えば .pfm の中身がざっくり分かりそう。ありがたや。
_GitHub - cdcseacave/HDRView
_Releases - cdcseacave/HDRView - GitHub
HDRView_Windows_x64.7z を解凍して、中に入っている HDRView.exe を実行してみた。ウインドウに .pfm をエクスプローラからドラッグアンドドロップしてみたら、それっぽい形が一発で表示された。素晴らしい…。これを使えば .pfm の中身がざっくり分かりそう。ありがたや。
[ ツッコむ ]
2023/05/31(水) [n年前の日記]
#1 [cg_tools][blender] デプスマップで人物画像を動かしてみたい
ここ数日、画像生成AI Stable Diffusion web UIで生成した風景画像から、デプスマップを推測・生成して、blender で立体化して動画を作成する実験をしていたけれど。
これを人物画像でやったらどんな感じになるのか気になってきた。結構印象は変わってくるのだろうか。試してみたい。
環境は以下。
先に成果物を提示しておきます。こんな感じになりました。
これを人物画像でやったらどんな感じになるのか気になってきた。結構印象は変わってくるのだろうか。試してみたい。
環境は以下。
- Windows10 x64 22H2
- CPU : AMD Ryzen 5 5600X
- GPU : NVIDIA GeForce GTX 1060 6GB
- RAM : 16GB
先に成果物を提示しておきます。こんな感じになりました。
◎ 元画像を生成 :
Stable Diffusion web UIで以下のような画像を生成。画像サイズは512x512。

_00056-3036143978.i2i.03.png
このままだと画像が小さ過ぎる気がしたので、Upscayl 2.5.1を使って、2048x2048に拡大。アルゴリズムは Ultramix balanced を選択。
_GitHub - upscayl/upscayl
_Releases - upscayl/upscayl
_00056-3036143978.i2i.03_upscayl_4x_ultramix_balanced.jpg
{kind=link}
parameters 1 girl, solo, beautiful, japanese, idol, actress, photo realistic, masterpiece, best quality, school uniform, standing against the wall, Negative prompt: EasyNegative, painting, sketches, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, (monochrome), (grayscale), text, logo, watermark, message, bad anatomy, bad arms, bad legs, bad hans, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 2713881344, Face restoration: CodeFormer, Size: 512x512, Model hash: ac68270450, Model: braBeautifulRealistic_brav5, Denoising strength: 0.6, Clip skip: 2, Version: v1.2.1
このままだと画像が小さ過ぎる気がしたので、Upscayl 2.5.1を使って、2048x2048に拡大。アルゴリズムは Ultramix balanced を選択。
_GitHub - upscayl/upscayl
_Releases - upscayl/upscayl
_00056-3036143978.i2i.03_upscayl_4x_ultramix_balanced.jpg
{kind=link}
{kind=link}
◎ デプスマップを作成 :
Stable Diffusion web UI の拡張機能、ControlNet のプリプロセッサで、デプスマップを作成。種類は zoe を選んだ。

_00056-3036143978.i2i.03-depth_zoe.png
一応、leres や MiDaS も使ってデプスマップを作ってみたのだけど。御覧の通り、結果がマチマチで…。

_00056-3036143978.i2i.03-depth_leres.png

_00056-3036143978.i2i.03-dpt_beit_large_512.png

_00056-3036143978.i2i.03-dpt_hybrid_384.png
対象物が近距離に収まってる場合は zoe のデプスマップが一番それっぽい気がする。上記の例では、髪、鼻、襟元が違うというか…。
{kind=link}
一応、leres や MiDaS も使ってデプスマップを作ってみたのだけど。御覧の通り、結果がマチマチで…。
{kind=link}
{kind=link}
{kind=link}
対象物が近距離に収まってる場合は zoe のデプスマップが一番それっぽい気がする。上記の例では、髪、鼻、襟元が違うというか…。
◎ blenderで読み込み :
blender 3.3.7 x64 LTS + ImportDepthMapアドオンで、元画像とデプスマップをインポートして、2.5D的な立体形状を作成。
そのままでは、遠方が小さくなってしまうので、ラティス変形を使って形を歪ませた。以下のような状態になった。
ちなみに、MiDaSで作ったデプスマップを使って同じことをしてみたのだけど…。

まだ zoe のデプスマップを使ったほうがマシかなあ、と…。
カメラにモーションをつけてレンダリング。512x288、24fps、120フレームで連番pngを作成して、ffmpeg で mp4 に変換。
そのままでは、遠方が小さくなってしまうので、ラティス変形を使って形を歪ませた。以下のような状態になった。
ちなみに、MiDaSで作ったデプスマップを使って同じことをしてみたのだけど…。
まだ zoe のデプスマップを使ったほうがマシかなあ、と…。
カメラにモーションをつけてレンダリング。512x288、24fps、120フレームで連番pngを作成して、ffmpeg で mp4 に変換。
ffmpeg -framerate 24 -i render\%04d.png -vcodec libx264 -crf 18 -pix_fmt yuv420p -r 24 out.mp4 -y
◎ 成果物 :
そんな感じで作業をして、以下のような動画ができました。
◎ 雑感 :
2D画像を単にPANする動画よりは多少それっぽくなった気もするけど、所詮は2.5D的な見せ方と言うか…。ううーん。
デプスマップに顔のパーツの凸凹も含まれるかなと期待したのだけど、そのあたりの情報はほとんど含まれない状態で出力されてしまって…。鼻の高さが微妙に含まれているかな、どうかな、というレベルで…。結果、作った動画も、なんともビミョーな出来になってしまった。
以前、カメラマップ(カメラマッピング)の実験をした時も思ったけれど、こういった流れで動画を作るとしたら、モデルデータをどれだけ精巧に作れるかがポイントになるのかもしれない。少なくとも、静止画の人物画像からデプスマップを推測して云々というやり方では、人物部分の奥行き情報がざっくりとしたものになってしまうので、期待した結果から程遠いものになってしまうなあ、と…。
デプスマップに顔のパーツの凸凹も含まれるかなと期待したのだけど、そのあたりの情報はほとんど含まれない状態で出力されてしまって…。鼻の高さが微妙に含まれているかな、どうかな、というレベルで…。結果、作った動画も、なんともビミョーな出来になってしまった。
以前、カメラマップ(カメラマッピング)の実験をした時も思ったけれど、こういった流れで動画を作るとしたら、モデルデータをどれだけ精巧に作れるかがポイントになるのかもしれない。少なくとも、静止画の人物画像からデプスマップを推測して云々というやり方では、人物部分の奥行き情報がざっくりとしたものになってしまうので、期待した結果から程遠いものになってしまうなあ、と…。
◎ 余談 :
人物が映った動画を眺める際、見ている側は、おそらく顔周辺を最も注目して視聴しそうな気がするので…。そこだけでも精密なモデルデータを作れたら結構違うのかもしれない。
であれば…。あらかじめテンプレートになりそうな顔モデルデータを用意して、画像を顔認識させて、目・鼻・口・耳などの位置にアタリをつけて、それらの位置に沿うように顔モデルデータを変形させて、そこに元画像をテクスチャとして貼り込めば、などと妄想したりもして。
もっとも、たしかそういった方法で、動画内の顔部分を差し替えていた技術が既にあったような気がする。
ただ、動画内の顔を差し替えるソレは、元になる動画が存在しないと作業できないデメリットはありそうだなと。一枚の画像さえあれば少しは動かせますよ、というソレとは、ちょっと方向性が違ってくるような気もする。既に存在する動画を改変してしまう技術と、ほとんど何もない状態から動画を作るソレは、ジャンルが違うのでは…。まあ、どちらでも共通して使える技術もありそうだけど。
そういえば、一枚の人物写真を渡すだけで口パク動画を作れてしまうアニメーション作成ソフトがあったような…。CrazyTalk、だったっけ? ググってみたら、Character Creator + HeadShotプラグインに変わってた。
_画像から 3D 頭部モデルを生成 | Headshot | Character Creator
_Generate Faces from Photos in Minutes | Headshot Plug-in for Character Creator - YouTube
というわけで、顔だけでもそれっぽく、という技術やソフトなら既に色々ありますなと。
であれば…。あらかじめテンプレートになりそうな顔モデルデータを用意して、画像を顔認識させて、目・鼻・口・耳などの位置にアタリをつけて、それらの位置に沿うように顔モデルデータを変形させて、そこに元画像をテクスチャとして貼り込めば、などと妄想したりもして。
もっとも、たしかそういった方法で、動画内の顔部分を差し替えていた技術が既にあったような気がする。
ただ、動画内の顔を差し替えるソレは、元になる動画が存在しないと作業できないデメリットはありそうだなと。一枚の画像さえあれば少しは動かせますよ、というソレとは、ちょっと方向性が違ってくるような気もする。既に存在する動画を改変してしまう技術と、ほとんど何もない状態から動画を作るソレは、ジャンルが違うのでは…。まあ、どちらでも共通して使える技術もありそうだけど。
そういえば、一枚の人物写真を渡すだけで口パク動画を作れてしまうアニメーション作成ソフトがあったような…。CrazyTalk、だったっけ? ググってみたら、Character Creator + HeadShotプラグインに変わってた。
_画像から 3D 頭部モデルを生成 | Headshot | Character Creator
_Generate Faces from Photos in Minutes | Headshot Plug-in for Character Creator - YouTube
というわけで、顔だけでもそれっぽく、という技術やソフトなら既に色々ありますなと。
[ ツッコむ ]
以上、31 日分です。
>>COCOモデルを使えばいいらしい
最近、ブログ主さんと同様にアニメを試そうとしており、
調べ周っていたところこちらに行き着きました。
おかげさまでモデルの違いに気づくことができました。
ありがとうございます。
>>動画に基づいて各ポーズを指定したいだけなら、ControlNet のプリプロセッサで OpenPose を通せば良いのではないか。わざわざ別途、OpenPoseDemo.exe を動かす必要も無いのでは…。
一度、ポーズだけの動画を作ってしまえば都度の前処理が軽くなって
長期的には時間の節約になるのではないかと考えています。
なにかと試行錯誤が多くなりがちので......