2026/04/30(木) [n年前の日記]
#1 [gmic][gimp] G'MIC-Qt最新版をUbuntuに導入
Ubuntu Linux 24.04 LTS上で用意されている GIMP用G'MIC-Qt (gimp-gmic) はバージョンが 2.9.4。バージョンが古過ぎて、ネット経由で最新のフィルタファイルを入手することもできない。
2026/04/30時点での現行版、3.7.4 を導入できないものだろうか…。試してみた。
まず、Ubuntu の公式パッケージ (gimp-gmic) はアンインストールしておく。
ちなみに、この公式パッケージ版は /usr/lib/gimp/2.0/plug-ins/gmic_gimp に G'MIC-Qt の実行バイナリが置かれていたらしい。
_Ubuntu - noble の gimp-gmic パッケージに関する詳細
_Ubuntu - パッケージのファイル一覧: gimp-gmic/noble/amd64
G'MIC-Qt の現行版を入手。
_G'MIC - GREYC's Magic for Image Computing: A Full-Featured Open-Source Framework for Image Processing - Download
G'MIC-Qt plug-in for GIMP 2.10 の中に Ubuntu 24.04 Noble 版のリンクがある。gmic_3.7.4_gimp2.10_ubuntu24-04_noble_amd64.zip を入手。解凍すると、中に gmic_gimp_qt という実行ファイルがあるので、これを ~/.config/GIMP/2.10/plug-ins/ の中にコピーしてやればいい。
GIMP 2.10.36 を起動したら、G'MIC-Qt が 3.7.4 になっていた。
ここまでやっておきながらアレだけど…。各種動作確認をする際にはUbuntu公式パッケージ版を利用したほうがいいのではないかと思えてきた…。フツーは現行版/最新版をインストールしているわけではないだろうし…。
今回インストールした現行版は削除して、Ubuntu公式パッケージ版をインストールし直した。
2026/04/30時点での現行版、3.7.4 を導入できないものだろうか…。試してみた。
まず、Ubuntu の公式パッケージ (gimp-gmic) はアンインストールしておく。
sudo apt purge gimp-gmic
ちなみに、この公式パッケージ版は /usr/lib/gimp/2.0/plug-ins/gmic_gimp に G'MIC-Qt の実行バイナリが置かれていたらしい。
_Ubuntu - noble の gimp-gmic パッケージに関する詳細
_Ubuntu - パッケージのファイル一覧: gimp-gmic/noble/amd64
G'MIC-Qt の現行版を入手。
_G'MIC - GREYC's Magic for Image Computing: A Full-Featured Open-Source Framework for Image Processing - Download
G'MIC-Qt plug-in for GIMP 2.10 の中に Ubuntu 24.04 Noble 版のリンクがある。gmic_3.7.4_gimp2.10_ubuntu24-04_noble_amd64.zip を入手。解凍すると、中に gmic_gimp_qt という実行ファイルがあるので、これを ~/.config/GIMP/2.10/plug-ins/ の中にコピーしてやればいい。
GIMP 2.10.36 を起動したら、G'MIC-Qt が 3.7.4 になっていた。
ここまでやっておきながらアレだけど…。各種動作確認をする際にはUbuntu公式パッケージ版を利用したほうがいいのではないかと思えてきた…。フツーは現行版/最新版をインストールしているわけではないだろうし…。
今回インストールした現行版は削除して、Ubuntu公式パッケージ版をインストールし直した。
rm ~/.config/GIMP/2.10/plug-ins/gmic_gimp_qt sudo apt install gimp-gmic
[ ツッコむ ]
#2 [anime] 「劇場版 SHIROBAKO」を視聴
BS12で放送された版を録画していたので視聴。アニメ業界を舞台にしたTVアニメ「SHIROBAKO」の劇場版。
たしか以前何かで視聴したような記憶がある…。ネット配信で見たのかな? 覚えてない…。
それはともかく、やはりフツーに面白いなと…。TVアニメ版を見ていることが前提の作りだし、TVアニメ版の焼き直しっぽい展開ではあるけれど…。
たしか以前何かで視聴したような記憶がある…。ネット配信で見たのかな? 覚えてない…。
それはともかく、やはりフツーに面白いなと…。TVアニメ版を見ていることが前提の作りだし、TVアニメ版の焼き直しっぽい展開ではあるけれど…。
◎ 続編っぽい劇場版についてもやもやと考える :
思考メモです。
TVアニメの続編的な劇場版を作る際、どうしてメインキャラ達が酷い状態から話が始まってしまうのであろうか…。
まあ、右肩上がりの展開を見せていくためには一度落としておかないといかんのだ、みたいなことなのかな。ただ、TV版の最後のあたりで希望を持たせるような光景を見せておきながらコレは無いよー、という印象を受けてしまうのは否めない気もする…。 *1
押井守監督が劇場版パト2を作った際に、「シリーズを続けたいなら数年後のメインキャラを見せちゃダメ。俺はもうこの企画を終わらせたかったからこうしたけどフツーこんなことしたらシリーズの息の根は止まるんだよ」みたいな感じの発言をしていた記憶があるのだけど…。その論で行けば、「SHIROBAKO」劇場版も、「ゆるキャン」劇場版も、スタッフはもう、その企画にウンザリしていて、これで打ち止めのつもりでこういう設定にしたのかもしれない、と邪推することもできそう…。
「ちょっと待て。じゃあZガンダムやZZや逆シャアはどうなるんだよ。ずっと続いてるじゃねえか」 そうなんだよなあ…。例外は結構ある…。そもそも押井監督自身が実写版パトレイバーを作ってた気もする…。シリーズの息の根、全然止まってないじゃんよ。
押井監督のソレは、あくまで一般論としてはそうなのです、そういう設定にするならそのくらいの覚悟を持て、という話なのかも。ただし例外はあると…。
例外になるための条件がありそうな気もする…。例えばメインキャラが刷新された続編にするとか? ガンダムならF91とかVとかGとか? いや、そもそもZガンダムの主人公はアムロじゃなかったし、そこからして条件を満たしていたのだろうか。
プリキュアやライダーやウルトラマンもシリーズとしてずっと続いてるよな…。あのへんのシリーズはどうして続いているのだろう…。どういう条件を満たしているのだろう?
STAR WARSシリーズが続いているのは何故なのか。何の条件を満たしているのか。長期シリーズになってるアレコレに対して満たしている条件を探していくと何か見えてきそうな気も…。それが分かればヒットシリーズを作るのも夢ではない…?
思考メモです。オチは無いです。
TVアニメの続編的な劇場版を作る際、どうしてメインキャラ達が酷い状態から話が始まってしまうのであろうか…。
まあ、右肩上がりの展開を見せていくためには一度落としておかないといかんのだ、みたいなことなのかな。ただ、TV版の最後のあたりで希望を持たせるような光景を見せておきながらコレは無いよー、という印象を受けてしまうのは否めない気もする…。 *1
押井守監督が劇場版パト2を作った際に、「シリーズを続けたいなら数年後のメインキャラを見せちゃダメ。俺はもうこの企画を終わらせたかったからこうしたけどフツーこんなことしたらシリーズの息の根は止まるんだよ」みたいな感じの発言をしていた記憶があるのだけど…。その論で行けば、「SHIROBAKO」劇場版も、「ゆるキャン」劇場版も、スタッフはもう、その企画にウンザリしていて、これで打ち止めのつもりでこういう設定にしたのかもしれない、と邪推することもできそう…。
「ちょっと待て。じゃあZガンダムやZZや逆シャアはどうなるんだよ。ずっと続いてるじゃねえか」 そうなんだよなあ…。例外は結構ある…。そもそも押井監督自身が実写版パトレイバーを作ってた気もする…。シリーズの息の根、全然止まってないじゃんよ。
押井監督のソレは、あくまで一般論としてはそうなのです、そういう設定にするならそのくらいの覚悟を持て、という話なのかも。ただし例外はあると…。
例外になるための条件がありそうな気もする…。例えばメインキャラが刷新された続編にするとか? ガンダムならF91とかVとかGとか? いや、そもそもZガンダムの主人公はアムロじゃなかったし、そこからして条件を満たしていたのだろうか。
プリキュアやライダーやウルトラマンもシリーズとしてずっと続いてるよな…。あのへんのシリーズはどうして続いているのだろう…。どういう条件を満たしているのだろう?
STAR WARSシリーズが続いているのは何故なのか。何の条件を満たしているのか。長期シリーズになってるアレコレに対して満たしている条件を探していくと何か見えてきそうな気も…。それが分かればヒットシリーズを作るのも夢ではない…?
思考メモです。オチは無いです。
*1: もっともそのあたり、このアニメでは冒頭のあたりで人形を使ってセルフツッコミしていた気もする…。世の中そんなに上手く行くわけねえだろ大人の世界は色々あるんだよ、とかなんとか。
[ ツッコむ ]
2026/04/29(水) [n年前の日記]
#1 [ubuntu] VMware上のUbuntu 20.04 LTSを 24.04 LTSにアップグレードした
Windows11 x64 25H2 + VMware Workstation 17 Pro 17.6.4 build-24832109 上で動かしていた Ubuntu Linux 20.04 LTS を、24.04 LTS にアップグレードした。一旦 22.04 LTS にアップグレードしてから 24.04 LTS にアップグレード。
手順については以前メモしてあった。
_mieki256's diary - A8-3850機をUbuntu Linux 24.04 LTSにアップグレードした
fuse をインストールしてるとヤバイという話をどこかで見かけたので、sudo apt purge fuse と sudo apt autoremove をしてから作業した。とメモ。
途中でいくつかトラブルに遭遇。
手順については以前メモしてあった。
_mieki256's diary - A8-3850機をUbuntu Linux 24.04 LTSにアップグレードした
fuse をインストールしてるとヤバイという話をどこかで見かけたので、sudo apt purge fuse と sudo apt autoremove をしてから作業した。とメモ。
途中でいくつかトラブルに遭遇。
◎ ストレージの空き容量が足りなかった :
20.04 LTS から 22.04 LTS にアップグレードしようとしたら、仮想HDDイメージの容量が足りなくて、途中で処理が止まってしまった。「/」に、6〜7GBの空き容量が必要らしい…。今まで32GBだったけれど、48GBまで増やすことにした。
以下のページを参考にしながら作業。ありがたや。
_VM上のext4パーティションを拡張するメモ
_VMware上のUbuntu 22.04 ファイルシステム拡張 parted - Qiita
仮想PCをシャットダウンしてから、VMware の設定でストレージの容量を10GBほど拡張。仮想マシンの設定を編集する → ハードウェア → ハードディスク (SCSI) → ディスク容量を拡張します「展開」、をクリック。総容量を指定する。
Ubuntu を起動。
以下を打って、HDDのサイズ変更を認識させる。らしい。
parted を起動。
resize2fs でパーティションサイズを変更。
これで48GBまで増やせた。
ただ、後で過去の作業メモを見直してみたら、パーティションサイズを増やすだけなら GParted でも出来たらしい…。そっちを使ったほうが簡単だよな…。
_mieki256's diary - VMwareの仮想HDDのサイズを増やしてみた
以下のページを参考にしながら作業。ありがたや。
_VM上のext4パーティションを拡張するメモ
_VMware上のUbuntu 22.04 ファイルシステム拡張 parted - Qiita
仮想PCをシャットダウンしてから、VMware の設定でストレージの容量を10GBほど拡張。仮想マシンの設定を編集する → ハードウェア → ハードディスク (SCSI) → ディスク容量を拡張します「展開」、をクリック。総容量を指定する。
Ubuntu を起動。
以下を打って、HDDのサイズ変更を認識させる。らしい。
sudo sh -c "echo 1 > /sys/class/block/sda/device/rescan"
parted を起動。
sudo parted /dev/sda
- print free で状態を確認。
- resizepart 1 で特定のパーティションに空き容量を追加する。100% と打てば追加できる。
- q で終了。
print free resizepart 1 100% print free q
resize2fs でパーティションサイズを変更。
resize2fs /dev/sda2
これで48GBまで増やせた。
ただ、後で過去の作業メモを見直してみたら、パーティションサイズを増やすだけなら GParted でも出来たらしい…。そっちを使ったほうが簡単だよな…。
_mieki256's diary - VMwareの仮想HDDのサイズを増やしてみた
◎ /etc/profileでエラー :
Ubuntu Linux 24.04 LTS にアップグレードしたら、起動時に必ず以下のエラーダイアログが表示されて悩んでしまった。しかも、このエラーダイアログが表示されるまで、異様に時間がかかる…。デスクトップが表示されるまで待たされる…。
調べたら、/etc/profile.d/ 以下に mydisplay.sh というスクリプトがあって、その中で xrandr を呼び出していた。中身を削除してみたらエラーが表示されなくなった。また、デスクトップが表示されるまでの時間も短くなった。
どの段階でこのスクリプトを作ったのだろう…。自分で作ったのか、自動で作られたのか、覚えてない…。
Error found when loading /etc/profile: X Error of failed request: BadName (named color or font does not exist) Major opcode of failed request: 141 (RANDR) Minor opcode of failed request: 16 (RRCreateMode) Serial number of failed request: 55 Current serial number in output stream: 55 Asa result the session will not be configured correctly. You should fix the problem as soon as feasible.
調べたら、/etc/profile.d/ 以下に mydisplay.sh というスクリプトがあって、その中で xrandr を呼び出していた。中身を削除してみたらエラーが表示されなくなった。また、デスクトップが表示されるまでの時間も短くなった。
どの段階でこのスクリプトを作ったのだろう…。自分で作ったのか、自動で作られたのか、覚えてない…。
◎ vim起動時にエラー :
vim を起動しようとしたらエラーが出る。どうやら以前入れていたプラグインが動作しなくなっていた模様。
~/.vimrc 内の記述をごっそり削除したり、~/.vim/ 内をごっそり削除したらエラーは出なくなった…けれど、今までの設定はほとんど消滅した状態に…。まあいいか。エラーが出るよりはマシだよな…。
~/.vimrc 内の記述をごっそり削除したり、~/.vim/ 内をごっそり削除したらエラーは出なくなった…けれど、今までの設定はほとんど消滅した状態に…。まあいいか。エラーが出るよりはマシだよな…。
◎ sudo apt updateでエラー :
sudo apt update をすると Google Chrome 関係でエラーが表示された。
以下のページによると、/etc/apt/sources.list.d/google-chrome.sources 内で、amd64 を指定してないとこうなるらしい。
_萌え萌えmoebuntu Google Chromeのリポジトリで不要な「i386」関連のエラーに対処する方法!
以下の1行を、"Components: main" の次の行に追加。
N: リポジトリ 'https://dl.google.com/linux/chrome-stable/deb stable InRelease' がアーキテクチャ 'i386' をサポートしないため設定ファイル 'main/binary-i386/Packages' の取得をスキップ
以下のページによると、/etc/apt/sources.list.d/google-chrome.sources 内で、amd64 を指定してないとこうなるらしい。
_萌え萌えmoebuntu Google Chromeのリポジトリで不要な「i386」関連のエラーに対処する方法!
以下の1行を、"Components: main" の次の行に追加。
Architectures: amd64
◎ GIMPのバージョンについて :
元々、GIMPの動作確認をしたくてアップグレードしたのだけど、Ubuntu Linux 24.04 LTS に入ってたのは、GIMP 2.10.36 + G'MIC-Qt 2.9.4 だった。
これはちょっとビミョーな状況かも…。Debian Linux や Ubuntu Linux は Python 2.7 を切り捨てて Python 3.x に移行してしまったので、Python 2.7 を要求する GIMP 2.10.x では、Python-Fu / Gimp-Python は動作しない…。
GIMP 3.x は Python 3.x に移行したけれど、Python-Fu / Gimp-Python の書き方が大きく変わってしまったそうで、GIMP 2.10.x 時代の Python-Fu / Gimp-Python スクリプトはまず動作しない。
ただ、以下の AppImage を使えば Python-Fu / GIMP-Python が動作する GIMP 2.10.38 を利用できる。
_Release Continuous Hybrid (Experimental) - ivan-hc/GIMP-appimage
GNU-Image-Manipulation-Program_2.10.38-5-Hybrid-with-python2-from-Debian-Buster-archimage4.9-x86_64.AppImage を入手して、chmod +x *.AppImage で実行権限をつけて、./GNU-Image-Manipulation-Program... で実行したら Ubuntu Linux 24.04 LTS上でも動いてくれた。
これはちょっとビミョーな状況かも…。Debian Linux や Ubuntu Linux は Python 2.7 を切り捨てて Python 3.x に移行してしまったので、Python 2.7 を要求する GIMP 2.10.x では、Python-Fu / Gimp-Python は動作しない…。
GIMP 3.x は Python 3.x に移行したけれど、Python-Fu / Gimp-Python の書き方が大きく変わってしまったそうで、GIMP 2.10.x 時代の Python-Fu / Gimp-Python スクリプトはまず動作しない。
ただ、以下の AppImage を使えば Python-Fu / GIMP-Python が動作する GIMP 2.10.38 を利用できる。
_Release Continuous Hybrid (Experimental) - ivan-hc/GIMP-appimage
GNU-Image-Manipulation-Program_2.10.38-5-Hybrid-with-python2-from-Debian-Buster-archimage4.9-x86_64.AppImage を入手して、chmod +x *.AppImage で実行権限をつけて、./GNU-Image-Manipulation-Program... で実行したら Ubuntu Linux 24.04 LTS上でも動いてくれた。
[ ツッコむ ]
2026/04/28(火) [n年前の日記]
#1 [gimp][gmic] GIMP用のグラデーションファイルを作りたい
G'MICの関連情報を眺めていたら、画像内で指定した数点からグラデーションデータを作成するフィルタがあると知った。
_New G'MIC filter 'Rendering / Gradient [from line]' - GIMP Chat
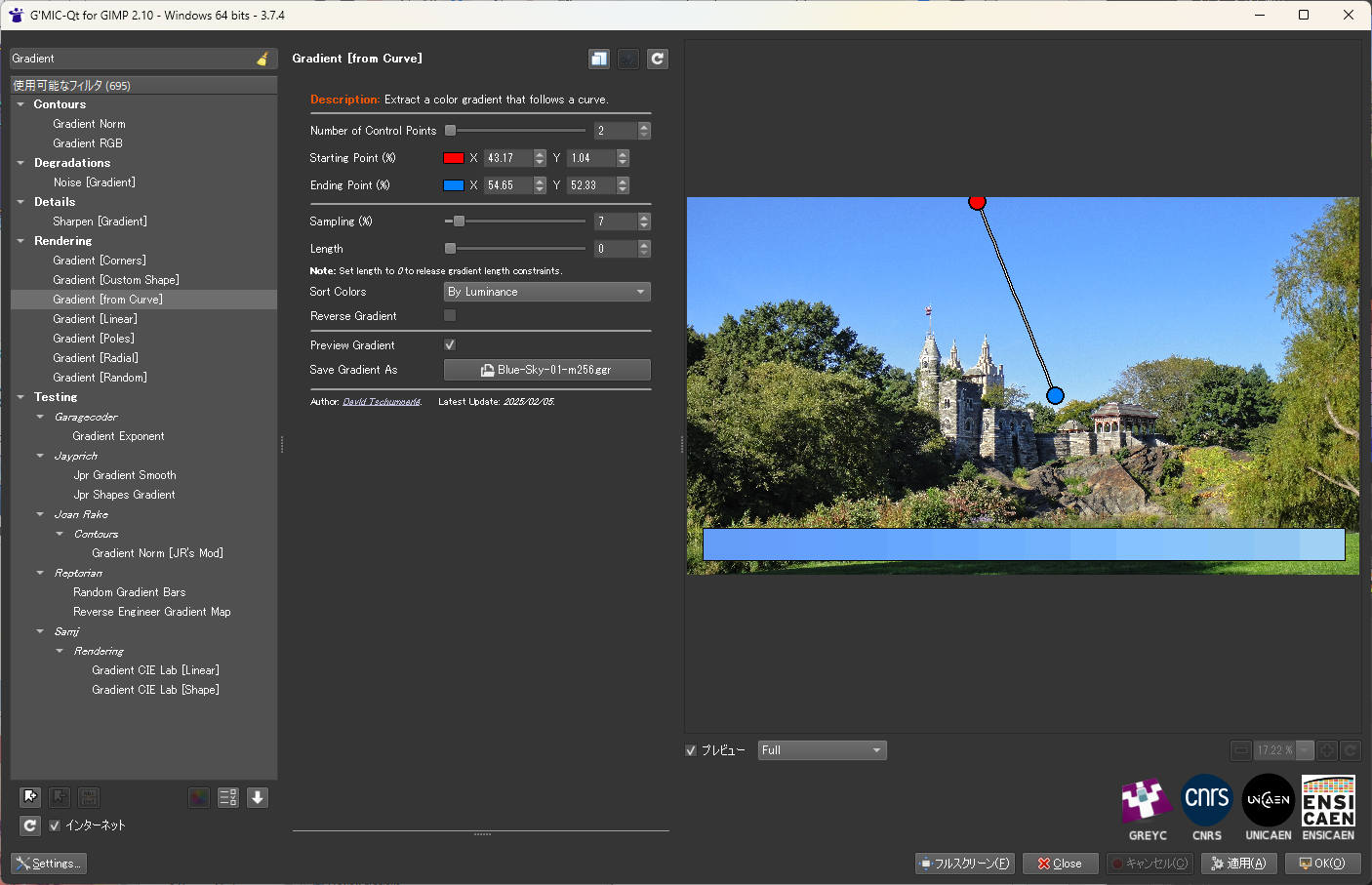
Rendering → Gradient [from Curve] で利用できる。プレビューウインドウ内で2点〜5点を指定して、直線/曲線上の色を取得してグラデーションを作成してくれるらしい。
しかし、ファイル保存する方法が分からない…。本来なら、Save Gradient As で、ファイル名(.ggr) や保存場所を指定すれば保存できるらしいのだけど…。
以下の2つの環境で試してみたけれど、どこかしらにファイルが保存されている気配が無い…。
ただ、OKボタンを押すと、元画像を横方向のグラデーション画像に変換してくれるようではある。この画像からグラデーションファイル(.ggr)を作れたらいいのに…。
_New G'MIC filter 'Rendering / Gradient [from line]' - GIMP Chat
Rendering → Gradient [from Curve] で利用できる。プレビューウインドウ内で2点〜5点を指定して、直線/曲線上の色を取得してグラデーションを作成してくれるらしい。
しかし、ファイル保存する方法が分からない…。本来なら、Save Gradient As で、ファイル名(.ggr) や保存場所を指定すれば保存できるらしいのだけど…。
以下の2つの環境で試してみたけれど、どこかしらにファイルが保存されている気配が無い…。
- Windows11 x64 25H2 + GIMP 3.2.4 Portable + G'MIC-Qt 3.7.4
- Windows11 x64 25H2 + GIMP 2.10.38 Portable + G'MIC-Qt 3.7.4
ただ、OKボタンを押すと、元画像を横方向のグラデーション画像に変換してくれるようではある。この画像からグラデーションファイル(.ggr)を作れたらいいのに…。
◎ 画像からグラデーションを作成するスクリプト :
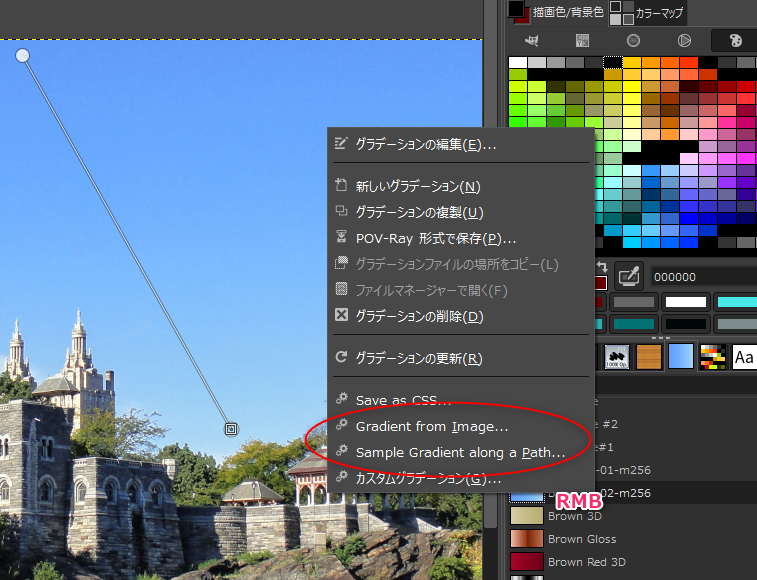
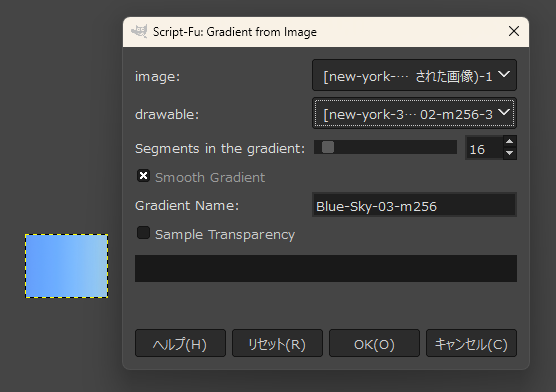
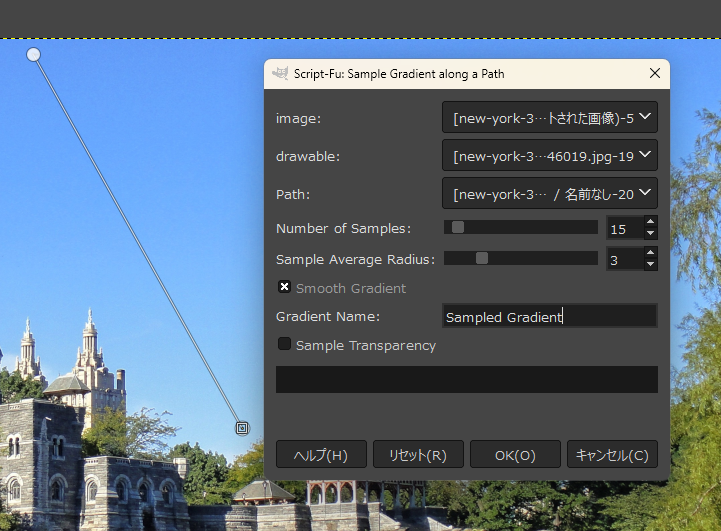
諦めきれずにググっていたら、画像からグラデーションファイル(.ggr)を作成できる Scrpit-Fu があると知った。
_Convert an IMG to a Gradient - GIMP Chat
_GGR from Image
以下の2つの Script-Fu が入手できた。おそらく GIMP 2.x にのみ対応。GIMP 3.x では動作しないのではないかな…。
G'MIC の Gradient [from Curve] だけで処理できれば嬉しかったのだけど、まあ、これでもどうにかなりそうではあるかな…。
ちなみに、G'MIC の Gradient [from Curve] は、サンプリングした色を明度でソートして並び替えたりもできるので、一旦 G'MIC で綺麗なグラデーション画像を作成してから、Script-Fu でグラデーションファイル化するのもアリかもしれない。
_Convert an IMG to a Gradient - GIMP Chat
_GGR from Image
以下の2つの Script-Fu が入手できた。おそらく GIMP 2.x にのみ対応。GIMP 3.x では動作しないのではないかな…。
- gradient-from-image.scm : 画像からグラデーションを作成する。
- sample-gradient-along-path.scm : パスを作成して、パス上の色を取得してグラデーションを作成する。
- インストール後、何かしらの画像を開いて、グラデーションウインドウ? パレット? 上で、何かしらのグラデーションを選んで右クリック。
- 「Gradient from Image...」「Sample gradient along a Path...」という項目が増えている。
- 選択するとダイアログが開くので、サンプリング個数、グラデーションファイル名等を入力してOKをクリック。
- GIMPがグラデーションファイルを読み込んでいるフォルダ内に、グラデショーンファイル(.ggr)が保存される。
G'MIC の Gradient [from Curve] だけで処理できれば嬉しかったのだけど、まあ、これでもどうにかなりそうではあるかな…。
ちなみに、G'MIC の Gradient [from Curve] は、サンプリングした色を明度でソートして並び替えたりもできるので、一旦 G'MIC で綺麗なグラデーション画像を作成してから、Script-Fu でグラデーションファイル化するのもアリかもしれない。
◎ 2026/04/29追記 :
どうやら G'MIC の Gradient [from Line] は、Linux環境じゃないとファイル保存できないっぽい。
Linux上でしか動作しないフィルタだったか…。そういうオチか。トホホ。
いや、もしかすると Windows上でも、GIMP Portable 版ではなくて通常のインストーラ版なら動作する可能性があるのかもしれない? Linux上で動かしたGIMPは通常インストール版に近いはずだから…。
ただ、そこまでして動作確認したくない…。GIMP 2.8 / 2.10時代の通常インストール版は旧バージョンのユーザフォルダを何の問い合わせもなく全削除しちゃって途方に暮れた記憶があって、それ以来触らないことにしている…。
それはさておき。Ubuntu Linux 22.04 LTS + GIMP 3.2.4 (flatpak版) + G'MIC-Qt 3.7.4 で試してみたら、/home/(USERNAME)/.config/GIMP/3.2/gradients/ ではなく、/home/(USERNAME)/.config/GIMP/2.10/gradients/ 以下に .ggr が保存された。保存先を 3.2/ にしてるはずなのに、どうして 2.10/ のほうに保存されるのだろう…?
- Windows11 x64 25H2 + GIMP 2.8.22 Portable + G'MIC-Qt 2.4.2 + Gradient [from Line] も試してみたけれど、グラデーションファイル(.ggr)は保存されなかった。
- G'MIC-Qt 3.7.4 Standalone版も試してみたけれど、保存されているようには見えない…。スタンドアロン版でもダメとは…。
- GIMP 2.6.12 Protable を起動してみたけど、これはそもそも G'MIC-Qt をインストールしてなかった…。
- Ubuntu Linux 22.04 LTS + GIMP 2.10.30 + G'MIC-Qt 2.9.4 で試してみたところ、/home/(USERNAME)/.config/GIMP/2.10/gradients/ に .ggr が保存された。
Linux上でしか動作しないフィルタだったか…。そういうオチか。トホホ。
いや、もしかすると Windows上でも、GIMP Portable 版ではなくて通常のインストーラ版なら動作する可能性があるのかもしれない? Linux上で動かしたGIMPは通常インストール版に近いはずだから…。
ただ、そこまでして動作確認したくない…。GIMP 2.8 / 2.10時代の通常インストール版は旧バージョンのユーザフォルダを何の問い合わせもなく全削除しちゃって途方に暮れた記憶があって、それ以来触らないことにしている…。
それはさておき。Ubuntu Linux 22.04 LTS + GIMP 3.2.4 (flatpak版) + G'MIC-Qt 3.7.4 で試してみたら、/home/(USERNAME)/.config/GIMP/3.2/gradients/ ではなく、/home/(USERNAME)/.config/GIMP/2.10/gradients/ 以下に .ggr が保存された。保存先を 3.2/ にしてるはずなのに、どうして 2.10/ のほうに保存されるのだろう…?
◎ 2026/05/01追記 :
G'MIC の Gradient [from Line] は、サンプリングした各色の間を補間(?)してくれない模様。ガタガタしたグラデーションになってしまう。
Script-Fuを使ってグラデーションファイル(.ggr)を作れば色と色の間をスムーズにできるのでそちらを使ったほうがいいかもしれない。
Script-Fuを使ってグラデーションファイル(.ggr)を作れば色と色の間をスムーズにできるのでそちらを使ったほうがいいかもしれない。
[ ツッコむ ]
以上、3 日分です。