2023/05/31(水) [n年前の日記]
#1 [cg_tools][blender] デプスマップで人物画像を動かしてみたい
ここ数日、画像生成AI Stable Diffusion web UIで生成した風景画像から、デプスマップを推測・生成して、blender で立体化して動画を作成する実験をしていたけれど。
これを人物画像でやったらどんな感じになるのか気になってきた。結構印象は変わってくるのだろうか。試してみたい。
環境は以下。
先に成果物を提示しておきます。こんな感じになりました。
これを人物画像でやったらどんな感じになるのか気になってきた。結構印象は変わってくるのだろうか。試してみたい。
環境は以下。
- Windows10 x64 22H2
- CPU : AMD Ryzen 5 5600X
- GPU : NVIDIA GeForce GTX 1060 6GB
- RAM : 16GB
先に成果物を提示しておきます。こんな感じになりました。
◎ 元画像を生成 :
Stable Diffusion web UIで以下のような画像を生成。画像サイズは512x512。

_00056-3036143978.i2i.03.png
このままだと画像が小さ過ぎる気がしたので、Upscayl 2.5.1を使って、2048x2048に拡大。アルゴリズムは Ultramix balanced を選択。
_GitHub - upscayl/upscayl
_Releases - upscayl/upscayl
_00056-3036143978.i2i.03_upscayl_4x_ultramix_balanced.jpg
{kind=link}
parameters 1 girl, solo, beautiful, japanese, idol, actress, photo realistic, masterpiece, best quality, school uniform, standing against the wall, Negative prompt: EasyNegative, painting, sketches, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, (monochrome), (grayscale), text, logo, watermark, message, bad anatomy, bad arms, bad legs, bad hans, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 2713881344, Face restoration: CodeFormer, Size: 512x512, Model hash: ac68270450, Model: braBeautifulRealistic_brav5, Denoising strength: 0.6, Clip skip: 2, Version: v1.2.1
このままだと画像が小さ過ぎる気がしたので、Upscayl 2.5.1を使って、2048x2048に拡大。アルゴリズムは Ultramix balanced を選択。
_GitHub - upscayl/upscayl
_Releases - upscayl/upscayl
_00056-3036143978.i2i.03_upscayl_4x_ultramix_balanced.jpg
{kind=link}
{kind=link}
◎ デプスマップを作成 :
Stable Diffusion web UI の拡張機能、ControlNet のプリプロセッサで、デプスマップを作成。種類は zoe を選んだ。

_00056-3036143978.i2i.03-depth_zoe.png
一応、leres や MiDaS も使ってデプスマップを作ってみたのだけど。御覧の通り、結果がマチマチで…。

_00056-3036143978.i2i.03-depth_leres.png

_00056-3036143978.i2i.03-dpt_beit_large_512.png

_00056-3036143978.i2i.03-dpt_hybrid_384.png
対象物が近距離に収まってる場合は zoe のデプスマップが一番それっぽい気がする。上記の例では、髪、鼻、襟元が違うというか…。
{kind=link}
一応、leres や MiDaS も使ってデプスマップを作ってみたのだけど。御覧の通り、結果がマチマチで…。
{kind=link}
{kind=link}
{kind=link}
対象物が近距離に収まってる場合は zoe のデプスマップが一番それっぽい気がする。上記の例では、髪、鼻、襟元が違うというか…。
◎ blenderで読み込み :
blender 3.3.7 x64 LTS + ImportDepthMapアドオンで、元画像とデプスマップをインポートして、2.5D的な立体形状を作成。
そのままでは、遠方が小さくなってしまうので、ラティス変形を使って形を歪ませた。以下のような状態になった。
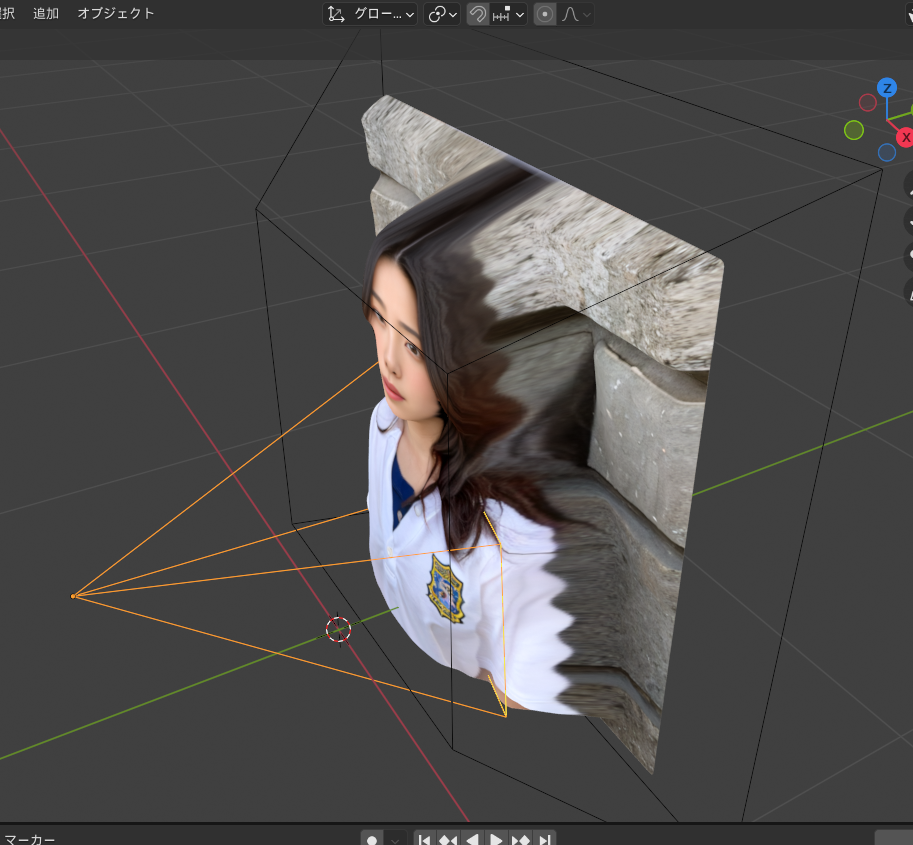
ちなみに、MiDaSで作ったデプスマップを使って同じことをしてみたのだけど…。

まだ zoe のデプスマップを使ったほうがマシかなあ、と…。
カメラにモーションをつけてレンダリング。512x288、24fps、120フレームで連番pngを作成して、ffmpeg で mp4 に変換。
そのままでは、遠方が小さくなってしまうので、ラティス変形を使って形を歪ませた。以下のような状態になった。
ちなみに、MiDaSで作ったデプスマップを使って同じことをしてみたのだけど…。
まだ zoe のデプスマップを使ったほうがマシかなあ、と…。
カメラにモーションをつけてレンダリング。512x288、24fps、120フレームで連番pngを作成して、ffmpeg で mp4 に変換。
ffmpeg -framerate 24 -i render\%04d.png -vcodec libx264 -crf 18 -pix_fmt yuv420p -r 24 out.mp4 -y
◎ 成果物 :
そんな感じで作業をして、以下のような動画ができました。
◎ 雑感 :
2D画像を単にPANする動画よりは多少それっぽくなった気もするけど、所詮は2.5D的な見せ方と言うか…。ううーん。
デプスマップに顔のパーツの凸凹も含まれるかなと期待したのだけど、そのあたりの情報はほとんど含まれない状態で出力されてしまって…。鼻の高さが微妙に含まれているかな、どうかな、というレベルで…。結果、作った動画も、なんともビミョーな出来になってしまった。
以前、カメラマップ(カメラマッピング)の実験をした時も思ったけれど、こういった流れで動画を作るとしたら、モデルデータをどれだけ精巧に作れるかがポイントになるのかもしれない。少なくとも、静止画の人物画像からデプスマップを推測して云々というやり方では、人物部分の奥行き情報がざっくりとしたものになってしまうので、期待した結果から程遠いものになってしまうなあ、と…。
デプスマップに顔のパーツの凸凹も含まれるかなと期待したのだけど、そのあたりの情報はほとんど含まれない状態で出力されてしまって…。鼻の高さが微妙に含まれているかな、どうかな、というレベルで…。結果、作った動画も、なんともビミョーな出来になってしまった。
以前、カメラマップ(カメラマッピング)の実験をした時も思ったけれど、こういった流れで動画を作るとしたら、モデルデータをどれだけ精巧に作れるかがポイントになるのかもしれない。少なくとも、静止画の人物画像からデプスマップを推測して云々というやり方では、人物部分の奥行き情報がざっくりとしたものになってしまうので、期待した結果から程遠いものになってしまうなあ、と…。
◎ 余談 :
人物が映った動画を眺める際、見ている側は、おそらく顔周辺を最も注目して視聴しそうな気がするので…。そこだけでも精密なモデルデータを作れたら結構違うのかもしれない。
であれば…。あらかじめテンプレートになりそうな顔モデルデータを用意して、画像を顔認識させて、目・鼻・口・耳などの位置にアタリをつけて、それらの位置に沿うように顔モデルデータを変形させて、そこに元画像をテクスチャとして貼り込めば、などと妄想したりもして。
もっとも、たしかそういった方法で、動画内の顔部分を差し替えていた技術が既にあったような気がする。
ただ、動画内の顔を差し替えるソレは、元になる動画が存在しないと作業できないデメリットはありそうだなと。一枚の画像さえあれば少しは動かせますよ、というソレとは、ちょっと方向性が違ってくるような気もする。既に存在する動画を改変してしまう技術と、ほとんど何もない状態から動画を作るソレは、ジャンルが違うのでは…。まあ、どちらでも共通して使える技術もありそうだけど。
そういえば、一枚の人物写真を渡すだけで口パク動画を作れてしまうアニメーション作成ソフトがあったような…。CrazyTalk、だったっけ? ググってみたら、Character Creator + HeadShotプラグインに変わってた。
_画像から 3D 頭部モデルを生成 | Headshot | Character Creator
_Generate Faces from Photos in Minutes | Headshot Plug-in for Character Creator - YouTube
というわけで、顔だけでもそれっぽく、という技術やソフトなら既に色々ありますなと。
であれば…。あらかじめテンプレートになりそうな顔モデルデータを用意して、画像を顔認識させて、目・鼻・口・耳などの位置にアタリをつけて、それらの位置に沿うように顔モデルデータを変形させて、そこに元画像をテクスチャとして貼り込めば、などと妄想したりもして。
もっとも、たしかそういった方法で、動画内の顔部分を差し替えていた技術が既にあったような気がする。
ただ、動画内の顔を差し替えるソレは、元になる動画が存在しないと作業できないデメリットはありそうだなと。一枚の画像さえあれば少しは動かせますよ、というソレとは、ちょっと方向性が違ってくるような気もする。既に存在する動画を改変してしまう技術と、ほとんど何もない状態から動画を作るソレは、ジャンルが違うのでは…。まあ、どちらでも共通して使える技術もありそうだけど。
そういえば、一枚の人物写真を渡すだけで口パク動画を作れてしまうアニメーション作成ソフトがあったような…。CrazyTalk、だったっけ? ググってみたら、Character Creator + HeadShotプラグインに変わってた。
_画像から 3D 頭部モデルを生成 | Headshot | Character Creator
_Generate Faces from Photos in Minutes | Headshot Plug-in for Character Creator - YouTube
というわけで、顔だけでもそれっぽく、という技術やソフトなら既に色々ありますなと。
[ ツッコむ ]
以上、1 日分です。