2023/06/01(木) [n年前の日記]
#1 [cg_tools][python] ZoeDepthが気になる
1枚の静止画像からAIが奥行きを推測してデプスマップ画像を生成してくれる MiDaS というプログラムをローカルで動かして実験していたけれど。同様の処理をしてくれる ZoeDepth というアルゴリズム? プログラム? も気になり始めた。コレもローカル環境で動かせるのだろうか?
_GitHub - isl-org/ZoeDepth: Metric depth estimation from a single image
_ZoeDepthを使ってみた(Google Colabo)|Masayuki Abe
_ZoeDepthを用いて単一画像から深度推定するレシピ
github上の README.md に導入の仕方は書いてあると思うのだけど、自分、この手の知識はほとんどないから、何がなんだか…。
_GitHub - isl-org/ZoeDepth: Metric depth estimation from a single image
_ZoeDepthを使ってみた(Google Colabo)|Masayuki Abe
_ZoeDepthを用いて単一画像から深度推定するレシピ
github上の README.md に導入の仕方は書いてあると思うのだけど、自分、この手の知識はほとんどないから、何がなんだか…。
◎ デモページを少し触ってみた :
サーバに設置された ZoeDepth の動作をWebブラウザ上から試せるデモページがあるっぽい。
_ZoeDepth - a Hugging Face Space by shariqfarooq
お試しで触ってみた。ページが表示されるまで結構待たされる。
下のほうにサンプル画像があるので、どれかしらをクリックして、「送信」ボタンをクリックすれば処理してくれる。デプスマップ画像が生成されるまで1分近く待たされるけど…。
「Image to 3D」というタブが気になる…。試してみたら、生成したデプスマップ画像を元にして3D形状を作って表示してくれた。これも出てくるまで1分以上待たされるけど…。
_ZoeDepth - a Hugging Face Space by shariqfarooq
お試しで触ってみた。ページが表示されるまで結構待たされる。
下のほうにサンプル画像があるので、どれかしらをクリックして、「送信」ボタンをクリックすれば処理してくれる。デプスマップ画像が生成されるまで1分近く待たされるけど…。
「Image to 3D」というタブが気になる…。試してみたら、生成したデプスマップ画像を元にして3D形状を作って表示してくれた。これも出てくるまで1分以上待たされるけど…。
◎ condaってなんぞや :
ローカル環境でも動かしてみたいので、git clone でファイル一式を持ってきて、その中で Python + venv で仮想環境を作成して、environment.yml の記述を参考にして pip を使って Pythonモジュールをインストールしようとしたのだけど。
_ZoeDepth/environment.yml at main - isl-org/ZoeDepth - GitHub
「そんなモジュールは無い」と結構言われてしまう…。
調べてみたら、どうやら conda なるツールを使うとそれらのモジュールをインストールできるらしい。というか、そのプロジェクトに environment.yml が存在する場合、その環境は conda を使って構築されたものだよ、ということになっていたらしい…。
その conda なのだけど。ググってみたら、Anaconda だの、miniconda だの conda-forge だの、もう何がなんだか…。
_AnacondaとMinicondaの比較、どちらで環境構築するべきか | In-Silico NoteBook
_conda-forgeとは?主な使い方や活用のポイントをご紹介 | 株式会社キャパ CAPA,Inc. コーポレートサイト
_conda-forgeからのPythonパッケージインストール - われがわログ
_Anacondaの有償化に伴いminiconda+conda-forgeでの運用を考えてみた - Qiita
よく分からないけど、Anaconda なるものは有償化されたとの話なので、miniconda + conda-forge なるものを使ったほうがいいのだろう…。たぶん。知らんけど。
_ZoeDepth/environment.yml at main - isl-org/ZoeDepth - GitHub
「そんなモジュールは無い」と結構言われてしまう…。
調べてみたら、どうやら conda なるツールを使うとそれらのモジュールをインストールできるらしい。というか、そのプロジェクトに environment.yml が存在する場合、その環境は conda を使って構築されたものだよ、ということになっていたらしい…。
その conda なのだけど。ググってみたら、Anaconda だの、miniconda だの conda-forge だの、もう何がなんだか…。
_AnacondaとMinicondaの比較、どちらで環境構築するべきか | In-Silico NoteBook
_conda-forgeとは?主な使い方や活用のポイントをご紹介 | 株式会社キャパ CAPA,Inc. コーポレートサイト
_conda-forgeからのPythonパッケージインストール - われがわログ
_Anacondaの有償化に伴いminiconda+conda-forgeでの運用を考えてみた - Qiita
よく分からないけど、Anaconda なるものは有償化されたとの話なので、miniconda + conda-forge なるものを使ったほうがいいのだろう…。たぶん。知らんけど。
[ ツッコむ ]
2023/06/02(金) [n年前の日記]
#1 [cg_tools][python] ZoeDepthの環境をminicondaをインストールして用意してみた
静止画像の奥行き情報をAIで推測・生成できる ZoeDepth を動かすためには、どうも conda とやらが必要らしくて…。
_GitHub - isl-org/ZoeDepth: Metric depth estimation from a single image
とりあえず触ってみなければ何も分らんだろうから、miniconda をインストールして試してみることにした。
環境は以下。
_GitHub - isl-org/ZoeDepth: Metric depth estimation from a single image
とりあえず触ってみなければ何も分らんだろうから、miniconda をインストールして試してみることにした。
環境は以下。
- Windows10 x64 22H2
- CPU : AMD Ruzen 5 5600X
- GPU : NVIDIA GeForce GTX 1060 6GB
- RAM : 16GB
- Python 3.10.6 64bit
- Git 2.40.1
◎ ZoeDepthのファイル一式を取得 :
conda関係を触る前に、ZoeDepthのファイル一式を git clone で入手しておく。
ZoeDepthフォルダの中に入る。
git clone https://github.com/isl-org/ZoeDepth.git
ZoeDepthフォルダの中に入る。
cd ZoeDepth
◎ minicondaのインストール :
以下からインストーラを入手できる。
_Miniconda - conda documentation
Python 3.10用の、Miniconda3-py310_23.3.1-0-Windows-x86_64.exe を入手。実行してインストール。今回は、D:\Dev\miniconda3\ にインストールしてみた。
インストール時に、「環境変数PATHに追加」という項目があったけど、そこはチェックを入れなかった。「PATHに追加するのは推奨しない。他のアプリが動作しなくなるかも」と書いてあったし…。
その代わり、以下の解説ページを参考にして、conda を使いたい時は batファイルを実行して環境変数を設定してから使うことにする。
_【後で困らないための】Miniconda windows版の環境構築
以下のようなbatファイルを作成して実行。
miniconda.bat
condaのバージョンを確認。23.3.1 がインストールされた。
余談。conda の新しいバージョンがあるっぽい。
conda install conda=23.5.0 と打って更新。
_Miniconda - conda documentation
Python 3.10用の、Miniconda3-py310_23.3.1-0-Windows-x86_64.exe を入手。実行してインストール。今回は、D:\Dev\miniconda3\ にインストールしてみた。
インストール時に、「環境変数PATHに追加」という項目があったけど、そこはチェックを入れなかった。「PATHに追加するのは推奨しない。他のアプリが動作しなくなるかも」と書いてあったし…。
その代わり、以下の解説ページを参考にして、conda を使いたい時は batファイルを実行して環境変数を設定してから使うことにする。
_【後で困らないための】Miniconda windows版の環境構築
以下のようなbatファイルを作成して実行。
miniconda.bat
@echo off SET MINICONDA_ROOT=D:\Dev\miniconda3 SET ADDPATH=%MINICONDA_ROOT%;%MINICONDA_ROOT%\Library\mingw-w64\bin;%MINICONDA_ROOT%\Library\usr\bin;%MINICONDA_ROOT%\Library\bin;%MINICONDA_ROOT%\Scripts SET Path=%ADDPATH%;%Path% @rem %windir%\System32\cmd.exe "/K" %MINICONDA_ROOT%\Scripts\activate.bat %MINICONDA_ROOT% call %MINICONDA_ROOT%\Scripts\activate.bat %MINICONDA_ROOT% @echo MINICONDA_ROOT=%MINICONDA_ROOT% @echo add path %ADDPATH% @echo. @echo Exit : Input, conda deactivate
condaのバージョンを確認。23.3.1 がインストールされた。
> conda --version conda 23.3.1
余談。conda の新しいバージョンがあるっぽい。
==> WARNING: A newer version of conda exists. <==
current version: 23.3.1
latest version: 23.5.0
Please update conda by running
$ conda update -n base -c defaults conda
Or to minimize the number of packages updated during conda update use
conda install conda=23.5.0
conda install conda=23.5.0 と打って更新。
◎ 仮想環境を作ろうとしたのだけど :
conda create を使えば仮想環境を作成できるらしいので試してみたのだけど。
現在のカレントディレクトリ内に作られるのかと思ったら、minicondaインストールフォルダ\envs\ 内に色々なファイルが入ってしまった…。そこに入るんかい…。venv のように、入れる場所を指定できたほうが嬉しかったかも…。
仮想環境に切り替える。
conda create -n zoedepth python=3.9
現在のカレントディレクトリ内に作られるのかと思ったら、minicondaインストールフォルダ\envs\ 内に色々なファイルが入ってしまった…。そこに入るんかい…。venv のように、入れる場所を指定できたほうが嬉しかったかも…。
仮想環境に切り替える。
conda activate zoedepth
◎ 必要なパッケージをインストール :
パッケージと呼ぶのかモジュールと呼ぶのか分らんけど、ZoeDepth の動作に必要になるらしいパッケージを、conda を使ってインストールしていく。
_ZoeDepth/environment.yml at main - isl-org/ZoeDepth - GitHub
本来、environment.yml を conda に渡して、必要なパッケージが入った仮想環境を一発で用意できる。後で試したところ、たしかにこれでもインストールできたけど…。
自分は conda の使い方が全然分かってないので、勉強を兼ねて一つ一つ指定して試してみた。
conda にはチャンネルとやらが存在するらしい。ZoeDepth に関係するチャンネルを追加。
ZoeDepth を動かすために必要なパッケージを、一つ一つインストール。
めちゃくちゃ時間がかかった…。
ちなみに、仮想環境が入ったフォルダ(今回インストールしたモジュール群が入ってるフォルダ)の容量を確認してみたら、1つ1つ入れていった場合は 15.62GBで、一発でインストールした場合は8.21GBだった。1つ1つ入れていくと、使わないはずのバージョンやパッケージもインストールしてしまうのかなと…。
_ZoeDepth/environment.yml at main - isl-org/ZoeDepth - GitHub
本来、environment.yml を conda に渡して、必要なパッケージが入った仮想環境を一発で用意できる。後で試したところ、たしかにこれでもインストールできたけど…。
conda env create -n zoe --file environment.yml conda activate zoe
- conda env create で、仮想環境を新規作成。
- -n xxxx で、仮想環境名を指定。-n zoe なら、zoe という仮想環境名を指定してる。
- --file xxxx.yml で、.yml に記述されたパッケージをまとめてインストール。
自分は conda の使い方が全然分かってないので、勉強を兼ねて一つ一つ指定して試してみた。
conda にはチャンネルとやらが存在するらしい。ZoeDepth に関係するチャンネルを追加。
conda config --add channels conda-forge conda config --add channels pytorch conda config --add channels nvidia conda config --show-sources conda config --show channels
ZoeDepth を動かすために必要なパッケージを、一つ一つインストール。
conda install cuda==11.7.1 conda install h5py==3.7.0 conda install hdf5==1.12.2 conda install matplotlib==3.6.2 conda install matplotlib-base==3.6.2 conda install numpy==1.24.1 conda install opencv==4.6.0 conda install pytorch==1.13.1 conda install pytorch-cuda==11.7 conda install pytorch-mutex==1.0 conda install scipy==1.10.0 conda install torchaudio==0.13.1 conda install torchvision==0.14.1 pip install huggingface-hub==0.11.1 pip install tqdm==4.64.1 pip install wandb==0.13.9 pip install timm==0.6.12
めちゃくちゃ時間がかかった…。
ちなみに、仮想環境が入ったフォルダ(今回インストールしたモジュール群が入ってるフォルダ)の容量を確認してみたら、1つ1つ入れていった場合は 15.62GBで、一発でインストールした場合は8.21GBだった。1つ1つ入れていくと、使わないはずのバージョンやパッケージもインストールしてしまうのかなと…。
◎ 必要なものがインストールできてるかチェック :
sanity_hub.py を実行することで、ZoeDepth の動作に必要なファイルが全て用意されているのかチェックすることができるっぽい。
実行してみたところ、学習モデルデータファイル(.pt)が3ファイルほどダウンロードされた。1ファイルにつき1.3GB程度。
学習モデルデータは、C:\Users\(USERNAME)\.cache\torch\hub\checkpoints\ 以下に保存されてしまった…。本来はどこに置くべきなんだろう…。README.md には「models/ に置け」と書いてあるけど、そんなフォルダは無いのですが…。
ちなみに、学習モデルデータ自体は、Releasesページから入手できる。
_Releases - isl-org/ZoeDepth
とりあえず、sanity_hub.py は実行できたので、続いて sanity.py を実行する。これで動作確認できるらしい。
pred.png というPNG画像が保存された。元画像とデプスマップがくっついた状態で生成されている。どうやら ZoeDepth を動かせる状態にはなった模様。
python sanity_hub.py
実行してみたところ、学習モデルデータファイル(.pt)が3ファイルほどダウンロードされた。1ファイルにつき1.3GB程度。
学習モデルデータは、C:\Users\(USERNAME)\.cache\torch\hub\checkpoints\ 以下に保存されてしまった…。本来はどこに置くべきなんだろう…。README.md には「models/ に置け」と書いてあるけど、そんなフォルダは無いのですが…。
ちなみに、学習モデルデータ自体は、Releasesページから入手できる。
_Releases - isl-org/ZoeDepth
とりあえず、sanity_hub.py は実行できたので、続いて sanity.py を実行する。これで動作確認できるらしい。
python sanity.py
pred.png というPNG画像が保存された。元画像とデプスマップがくっついた状態で生成されている。どうやら ZoeDepth を動かせる状態にはなった模様。
◎ Webブラウザ経由で使う :
この ZoeDepth はWebブラウザ経由で使うこともできる。
ui/ui_requirements.txt に、Webブラウザ経由で動かす際に必要なPythonモジュールが列挙されているので、pipでインストールする。
インストールできたら以下を実行。
DOS窓上で、「Running on local URL: http://127.0.0.1:7860」と表示されるので、Webブラウザで http://127.0.0.1:7860 を開くと、Stable Diffusion web UI のようなページが表示される。
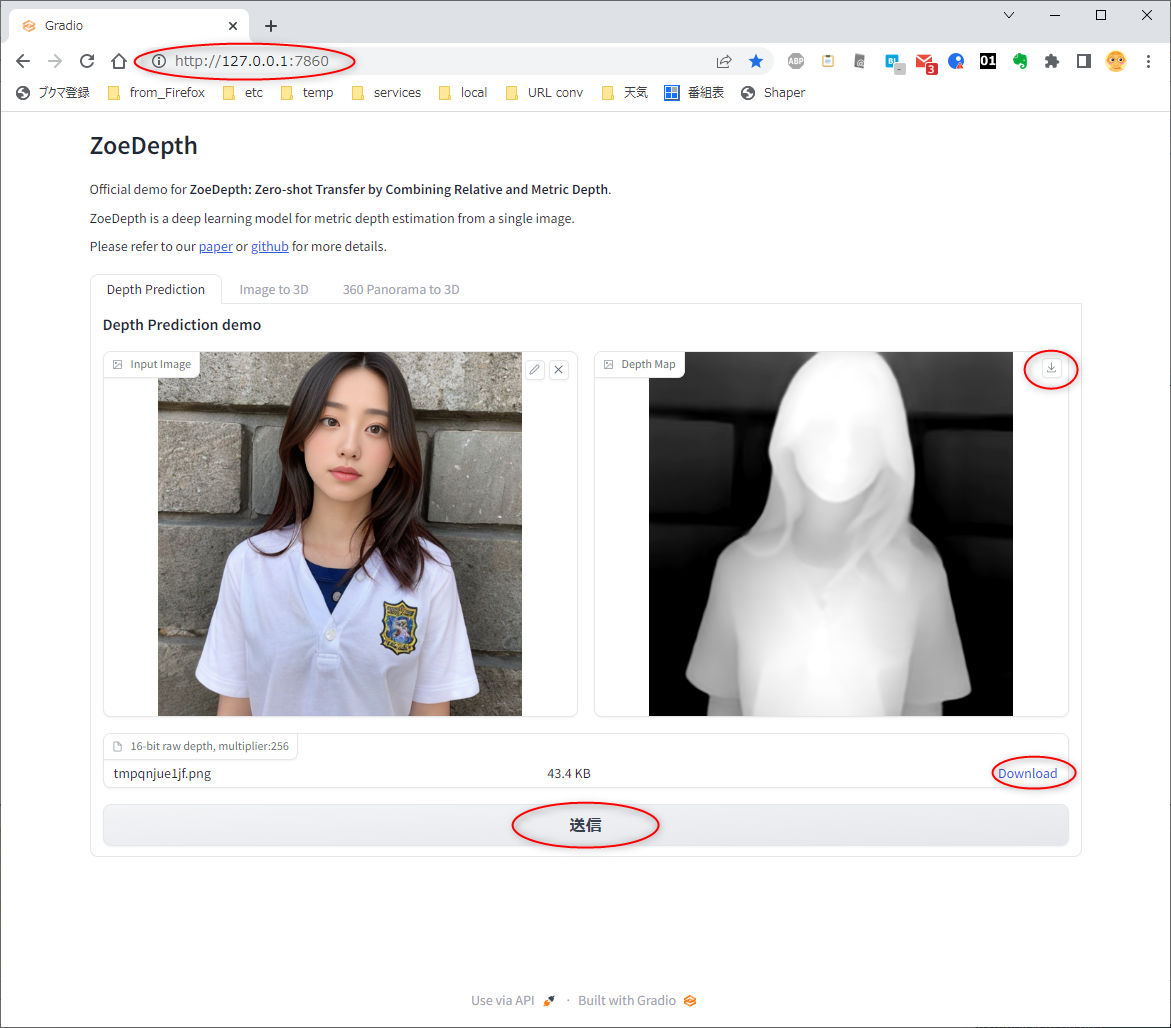
エクスプローラ等から画像をドラッグアンドドロップして、「送信」ボタンをクリックすると、ZoeDepthで生成されたデプスマップ画像が表示された。
余談。生成された16bitグレースケールのPNG画像を blender 3.3.7 x64 LTS のディスプレイスモディファイアに渡してみたけど、反映されなかった。blender の該当モディファイアは、8bitの画像か、OpenEXR のような 16bit浮動小数点の画像じゃないと反映されないようだなと…。
ui/ui_requirements.txt に、Webブラウザ経由で動かす際に必要なPythonモジュールが列挙されているので、pipでインストールする。
pip install -r ui/ui_requirements.txt
インストールできたら以下を実行。
python -m ui.app
DOS窓上で、「Running on local URL: http://127.0.0.1:7860」と表示されるので、Webブラウザで http://127.0.0.1:7860 を開くと、Stable Diffusion web UI のようなページが表示される。
エクスプローラ等から画像をドラッグアンドドロップして、「送信」ボタンをクリックすると、ZoeDepthで生成されたデプスマップ画像が表示された。
- 生成画像が表示されているウインドウの、右上のアイコンをクリックすれば、8bitグレースケールの画像をダウンロードできる。
- 下のほうに表示されているDownloadのリンクをクリックすれば16bitグレースケールのPNG画像をダウンロードできる。
余談。生成された16bitグレースケールのPNG画像を blender 3.3.7 x64 LTS のディスプレイスモディファイアに渡してみたけど、反映されなかった。blender の該当モディファイアは、8bitの画像か、OpenEXR のような 16bit浮動小数点の画像じゃないと反映されないようだなと…。
◎ 仮想環境から抜ける :
conda deactivate と打てば仮想環境から抜けられる。
仮想環境の一覧を見たい時は以下。
仮想環境を削除したい時は以下。
仮想環境の一覧を見たい時は以下。
conda info -e
仮想環境を削除したい時は以下。
conda remove -n zoedepth --all
◎ 課題 :
学習モデルデータ(.pt)をどこに置けばいいのだろう…? 現状、Cドライブ内の .cacheフォルダ(C:\Users\(USERNAME)\.cache\)内に入っちゃってるので、一応動くことは動くけど、貴重なCドライブの容量は使いたくない…。
とりあえず、.cache/ をDドライブに移動して、Cドライブ内にはシンボリックリンクを張って誤魔化しておこう…。
とりあえず、.cache/ をDドライブに移動して、Cドライブ内にはシンボリックリンクを張って誤魔化しておこう…。
◎ 参考ページ :
_windows10にPythonの開発環境minicondaをインストールする手順を解説 | うみうまブログ
_Miniconda3をWindows 10にインストール - Qiita
_【後で困らないための】Miniconda windows版の環境構築
_AnacondaとMinicondaの比較、どちらで環境構築するべきか | In-Silico NoteBook
_Conda コマンド: Python環境構築ガイド - python.jp
_[Python]Anacondaで仮想環境を作る - Qiita
_【Anacondaの使い方】よく使うcondaコマンド一覧【チートシート】 | 似非プログラマの備忘録
_Anacondaで仮想環境を構築する方法 | sakizo blog
_condaを使う際に利用するコマンド一覧 - Qiita
_Miniconda3をWindows 10にインストール - Qiita
_【後で困らないための】Miniconda windows版の環境構築
_AnacondaとMinicondaの比較、どちらで環境構築するべきか | In-Silico NoteBook
_Conda コマンド: Python環境構築ガイド - python.jp
_[Python]Anacondaで仮想環境を作る - Qiita
_【Anacondaの使い方】よく使うcondaコマンド一覧【チートシート】 | 似非プログラマの備忘録
_Anacondaで仮想環境を構築する方法 | sakizo blog
_condaを使う際に利用するコマンド一覧 - Qiita
[ ツッコむ ]
#2 [anime] 「リトル・マーメイド」を視聴
TVというか金曜ロードショーで放送されてたので視聴。おそらく初見。
自分、何故かこのアニメを「美女と野獣」の後の作品と思い込んでたのだけど、ググってみたら「美女と野獣」の数年前の作品だったのですな…。CGシーンが無いからおかしいと思った…。
昔のディズニーアニメ、しかも _ディズニー・ルネサンス の初期作品なので、眺めていてもこれといった学びは何も無かった…。さすがにまだこの時期では、大人の鑑賞に堪える内容ではなさそうだなと…。まあ、ハッピーエンドにアレンジしてあるあたりファミリー向けとしては良い改変なのかなと思ったりもしたけれど。原作通りのラストでは見てる子供が泣いちゃうよなあ…。
気になったのは、実写版で物議を醸している、ヒロインの肌の色。今回オリジナル版を最初に見た時、「アレ? こんなに黒いの? これじゃ黒人キャラじゃん」と驚いてしまった。ただ、それはあくまで海中シーンの話。水上や地上シーンになると、「なんだ。やっぱり白いじゃんよ」と…。
セルとフィルムでアニメを作っていた頃は、撮影段階で細かい色調補正なんてできなかったので、セルに塗る色を決めていく色指定の段階からして、地上用と海中用の色指定をバキッと変えて、ここは地上ですよ、ここは水中ですよと伝えていたはずで。例えば宮崎駿監督作品の「未来少年コナン」あたりを眺めるとそのあたりとても分かりやすいのだけど…。だから、このアニメでも、海中シーンと地上シーンでヒロインの肌の色が違っていてもそれは全然おかしくないわけだけど。
ちょっと不安になったのは、実写版のヒロインを選んだ人達って、オリジナル版でそういった工夫をしていたことすら分かってないのでは、という…。海中シーンだけを見て、「は? このヒロインは黒人だろ?」と思い込んでたらどうしよう…。
なわけないよな。ホントかどうか知らんけどヒロインの姉妹に色んな人種を起用してるという話も聞いたし、オリジナル版の肌の色なんてたぶん一切気にしてないよな…。全然違う理由でヒロインが黒人系になったのだろう…。
それはさておき。放送後に実写版の宣伝映像も少し流れてたけど、魚やカニ(ヤドカリ?)達が…。ディズニーアニメに登場する動物達を実写にするのは難問過ぎる…。フツーに3DCGアニメとしてリメイクしちゃダメだったのだろうか…。まさかとは思うけどアメリカ国内では、未だに「実写>アニメ」みたいな偏見があるとか…?
自分、何故かこのアニメを「美女と野獣」の後の作品と思い込んでたのだけど、ググってみたら「美女と野獣」の数年前の作品だったのですな…。CGシーンが無いからおかしいと思った…。
昔のディズニーアニメ、しかも _ディズニー・ルネサンス の初期作品なので、眺めていてもこれといった学びは何も無かった…。さすがにまだこの時期では、大人の鑑賞に堪える内容ではなさそうだなと…。まあ、ハッピーエンドにアレンジしてあるあたりファミリー向けとしては良い改変なのかなと思ったりもしたけれど。原作通りのラストでは見てる子供が泣いちゃうよなあ…。
気になったのは、実写版で物議を醸している、ヒロインの肌の色。今回オリジナル版を最初に見た時、「アレ? こんなに黒いの? これじゃ黒人キャラじゃん」と驚いてしまった。ただ、それはあくまで海中シーンの話。水上や地上シーンになると、「なんだ。やっぱり白いじゃんよ」と…。
セルとフィルムでアニメを作っていた頃は、撮影段階で細かい色調補正なんてできなかったので、セルに塗る色を決めていく色指定の段階からして、地上用と海中用の色指定をバキッと変えて、ここは地上ですよ、ここは水中ですよと伝えていたはずで。例えば宮崎駿監督作品の「未来少年コナン」あたりを眺めるとそのあたりとても分かりやすいのだけど…。だから、このアニメでも、海中シーンと地上シーンでヒロインの肌の色が違っていてもそれは全然おかしくないわけだけど。
ちょっと不安になったのは、実写版のヒロインを選んだ人達って、オリジナル版でそういった工夫をしていたことすら分かってないのでは、という…。海中シーンだけを見て、「は? このヒロインは黒人だろ?」と思い込んでたらどうしよう…。
なわけないよな。ホントかどうか知らんけどヒロインの姉妹に色んな人種を起用してるという話も聞いたし、オリジナル版の肌の色なんてたぶん一切気にしてないよな…。全然違う理由でヒロインが黒人系になったのだろう…。
それはさておき。放送後に実写版の宣伝映像も少し流れてたけど、魚やカニ(ヤドカリ?)達が…。ディズニーアニメに登場する動物達を実写にするのは難問過ぎる…。フツーに3DCGアニメとしてリメイクしちゃダメだったのだろうか…。まさかとは思うけどアメリカ国内では、未だに「実写>アニメ」みたいな偏見があるとか…?
[ ツッコむ ]
2023/06/03(土) [n年前の日記]
#1 [python][ubuntu][linux] Ubuntu 22.04 LTSでminicondaをインストール
Windows10 x64 22H2上で miniconda をインストールして触ってみたことだし、せっかくだから Ubuntu Linu 22.04 LTS (Core i3-6100T機)上でも同じことができるか試してみた。
_Miniconda - conda documentation
Ubuntu Linux 22.04 LTS には Python 3.10.6 がインストールされていたので、Python 3.10 用のインストーラ、Miniconda3-py310_23.3.1-0-Linux-x86_64.sh を入手して実行。
そのままだと、シェルが立ち上がるたびに仮想環境 base が自動で起動してしまう。以下を入力して自動起動を無効にする。
仮想環境を使いたい時は以下。
仮想環境から抜ける時は以下。
ちなみに、各仮想環境のファイルは以下に入る模様。
_Miniconda - conda documentation
Ubuntu Linux 22.04 LTS には Python 3.10.6 がインストールされていたので、Python 3.10 用のインストーラ、Miniconda3-py310_23.3.1-0-Linux-x86_64.sh を入手して実行。
cd Downloads wget https://repo.anaconda.com/miniconda/Miniconda3-py310_23.3.1-0-Linux-x86_64.sh bash Miniconda3-py310_23.3.1-0-Linux-x86_64.sh
- ライセンス関係が表示された後、ライセンスを受け入れるか聞いてくるので「yes」を入力。
- インストール場所を /home/(USERNAME)/miniconda3/ にしていいか尋ねてくるので、Enter。
- conda init を実行するか聞いてくるので、「yes」。
そのままだと、シェルが立ち上がるたびに仮想環境 base が自動で起動してしまう。以下を入力して自動起動を無効にする。
conda deactivate conda config --set auto_activate_base false
仮想環境を使いたい時は以下。
conda activate hoge
仮想環境から抜ける時は以下。
conda deactivate
ちなみに、各仮想環境のファイルは以下に入る模様。
/home/(USERNAME)/miniconda3/envs/
◎ 参考ページ :
[ ツッコむ ]
#2 [cg_tools][ubuntu][linux][python] Ubuntu 22.04 LTS上でZoeDepthをインストール
Ubuntu Linux 22.04 LTS 上で conda を使えるようになったので、ZoeDepth もインストールできるのか試してみる。環境は以下。
_GitHub - isl-org/ZoeDepth: Metric depth estimation from a single image
_Releases - isl-org/ZoeDepth
githubからファイル一式を git で取得。
conda を使って仮想環境 zoe を作成しつつ、必要なパッケージを一気にインストール。かなり時間がかかる。
conda を使って仮想環境 zoe に切替。Python 3.9 が入っているかバージョンを確認。
ZoeDepth を動作させるために必要になる、他のファイルをダウンロードして取得。
ZoeDepthが動作するか確認。
Webブラウザ経由で利用できるようにする。必要なモジュールをインストール。
Webブラウザでアクセスできるようにサービス(?)を実行。
Linuxのデスクトップで、以下のURLにアクセスしてみる。Stable Diffusion web UIのようなページが表示されたらOK。
LAN内の他のPCからアクセスできるようにしたい場合は、ui/app.py の最後のあたりを修正。.launch() に server_name='0.0.0.0' を与える。
- Ubuntu Linux 22.04 LTS
- CPU : Core i3-6100T
- GPU : 内蔵GPU
- RAM : 8GB
_GitHub - isl-org/ZoeDepth: Metric depth estimation from a single image
_Releases - isl-org/ZoeDepth
githubからファイル一式を git で取得。
cd
mkdir zoedepth cd zoedepth git clone https://github.com/isl-org/ZoeDepth.git cd ZoeDepth
conda を使って仮想環境 zoe を作成しつつ、必要なパッケージを一気にインストール。かなり時間がかかる。
conda env create -n zoe --file environment.yml
conda を使って仮想環境 zoe に切替。Python 3.9 が入っているかバージョンを確認。
conda activate zoe python -V
ZoeDepth を動作させるために必要になる、他のファイルをダウンロードして取得。
python sanity_hub.pyダウンロードされたファイルは、以下にキャッシュされる。
- /home/(USERNAME)/.cache/torch/hub/master.zip
- /home/(USERNAME)/.cache/torch/hub/checkpoints/ZoeD_M12_(K|N|NK).pt
ZoeDepthが動作するか確認。
python sanity.pypred.png が生成されていれば、動作している。
Webブラウザ経由で利用できるようにする。必要なモジュールをインストール。
pip install -r ui/ui_requirements.txt
Webブラウザでアクセスできるようにサービス(?)を実行。
python -m ui.app
Linuxのデスクトップで、以下のURLにアクセスしてみる。Stable Diffusion web UIのようなページが表示されたらOK。
http://127.0.0.1:7860停止は Ctrl+C。
LAN内の他のPCからアクセスできるようにしたい場合は、ui/app.py の最後のあたりを修正。.launch() に server_name='0.0.0.0' を与える。
demo.queue().launch() ↓ demo.queue().launch(server_name='0.0.0.0')これで、他のPCから http://192.168.x.x:7860、あるいは http://(ZoeDepthを動かしてるPC名):7860 にアクセスすれば使えるようになる。
[ ツッコむ ]
2023/06/04(日) [n年前の日記]
#1 [cg_tools] 画像生成AIが動かなくなっていて悩んだ
画像生成AI、Stable Diffusion web UIを使おうとしたら、JSONDecodeError なるエラーが出てきて、学習モデルデータのロードに失敗して動作しない状態になっていた。なんでや…。
仕方なく再インストールをしてみても、同じエラーが出てくる。どうしたらいいのか…。
ググってみたけれど、C:\Users\(USERNAME)\.cache\huggingface をリネームしてバックアップ、もしくは削除してから、Stable Diffusion web UIを再実行すると状況が変わるかもしれない。少なくとも自分の環境では、また動作するようになった。あるいは、config.json をリネームしてバックアップしてから、という手もあるらしい。
以下、参考ページ。
_[Bug]: JSONDecodeError | Failed to create model - Issue #8334 - AUTOMATIC1111/stable-diffusion-webui - GitHub
_[Bug][Linux]: Webui fails to load model on fresh installation - Issue #10877 - AUTOMATIC1111/stable-diffusion-webui - GitHub
_[Bug]: json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0) - Issue #8836 - AUTOMATIC1111/stable-diffusion-webui - GitHub
仕方なく再インストールをしてみても、同じエラーが出てくる。どうしたらいいのか…。
ググってみたけれど、C:\Users\(USERNAME)\.cache\huggingface をリネームしてバックアップ、もしくは削除してから、Stable Diffusion web UIを再実行すると状況が変わるかもしれない。少なくとも自分の環境では、また動作するようになった。あるいは、config.json をリネームしてバックアップしてから、という手もあるらしい。
以下、参考ページ。
_[Bug]: JSONDecodeError | Failed to create model - Issue #8334 - AUTOMATIC1111/stable-diffusion-webui - GitHub
_[Bug][Linux]: Webui fails to load model on fresh installation - Issue #10877 - AUTOMATIC1111/stable-diffusion-webui - GitHub
_[Bug]: json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0) - Issue #8836 - AUTOMATIC1111/stable-diffusion-webui - GitHub
[ ツッコむ ]
#2 [anime] 「銀河鉄道999 エターナル・ファンタジー/銀河鉄道999 永遠の旅人エメラルダス」を視聴
BS12で放送されていたので視聴。エターナル・ファンタジーのほうは、以前視聴していたような気がする。内容は覚えてないけど…。「エメラルダス」のほうは、TVアニメ版を再編集した作品らしい。
「エターナル」は1998年の作品らしいけど、作画面が原作寄りになっていて感心してしまった。当時、このくらいの作画を繰り出せるようになってたのだなと…。999も3DCGになっていたけど、煙の表現等で試行錯誤していたようで、カット毎に表現が違っていたあたりが興味深かった。
画面がガタガタしていたのでデジタル撮影ではなさそうに見えたけど、惑星の爆発等はCGらしいソレで、どういう作り方をしてたのかなと…。
この作品の人気が出れば続編もあっただろうし、宇宙戦艦ヤマトも登場したのだろうけど。まあ、仕方ないよな…。時間云々が絡んでくると、それはもはや別シリーズに思える。いや、そうでもないか。元々は時間城のような設定もあったわけだし、そこらへんを発展させていけばこういう展開も別におかしくはない気もしてきた。
そういえばヤマトのリメイクシリーズにも 時間断層という設定が出てきてたっけ。松本零士作品にちょこちょこ出てくるその手の設定を意識していくと、ヤマトのソレだってこれまた全然おかしくないのだな。
「エメラルダス」は、昭和アニメらしい作画で、なんというか…。今の日本のアニメって、映像面はとんでもないことになっているなと再認識。当時のアニメーターさん達に「鬼滅の刃」の映像を見せて「数十年後はTVアニメってこうなってますよ」と伝えたら一体どんなことになるのだろうと…。「やってられるか」と鉛筆を投げ出すのか、それとも「よーし、このレベルになるまで頑張るぞー」と気合いを入れるのか…。まあ、今のTVアニメって全部OVAみたいなものだから単純に比較するのはおかしい気もするけど。
「エターナル」は1998年の作品らしいけど、作画面が原作寄りになっていて感心してしまった。当時、このくらいの作画を繰り出せるようになってたのだなと…。999も3DCGになっていたけど、煙の表現等で試行錯誤していたようで、カット毎に表現が違っていたあたりが興味深かった。
画面がガタガタしていたのでデジタル撮影ではなさそうに見えたけど、惑星の爆発等はCGらしいソレで、どういう作り方をしてたのかなと…。
この作品の人気が出れば続編もあっただろうし、宇宙戦艦ヤマトも登場したのだろうけど。まあ、仕方ないよな…。時間云々が絡んでくると、それはもはや別シリーズに思える。いや、そうでもないか。元々は時間城のような設定もあったわけだし、そこらへんを発展させていけばこういう展開も別におかしくはない気もしてきた。
そういえばヤマトのリメイクシリーズにも 時間断層という設定が出てきてたっけ。松本零士作品にちょこちょこ出てくるその手の設定を意識していくと、ヤマトのソレだってこれまた全然おかしくないのだな。
「エメラルダス」は、昭和アニメらしい作画で、なんというか…。今の日本のアニメって、映像面はとんでもないことになっているなと再認識。当時のアニメーターさん達に「鬼滅の刃」の映像を見せて「数十年後はTVアニメってこうなってますよ」と伝えたら一体どんなことになるのだろうと…。「やってられるか」と鉛筆を投げ出すのか、それとも「よーし、このレベルになるまで頑張るぞー」と気合いを入れるのか…。まあ、今のTVアニメって全部OVAみたいなものだから単純に比較するのはおかしい気もするけど。
◎ FLASHで作られた999 :
関連情報をググっているうちに、2002年頃、FLASHで制作された「銀河鉄道999」のシリーズがWebで配信されていたと今頃知った。1話だけ無料公開されていたので眺めてみたけれど、再生環境がFLASHプラグインだったはずなのに、ここまでそれっぽく見せられるのかと感心してしまった。
その、FLASHによる999の映像を見ているうちに、ふとなんとなく考え込んでしまった。
今現在、YouTube等で公開されてる動画の数々も、何かしらを解説したりするだけなら、ここまでの帯域を必要としないのだよな…。FLASHのように、再生側でアニメーションをリアルタイム生成できる技術があれば、もっと少ない帯域で送信できていたはずで…。自分達は色んな面でとにかく無駄使いをしている…。
まあ、FLASHは殺されてしまったので、今更望んでもどうしようもないし、映像制作の過程を考えた場合、とにかく最後は動画にしちゃえばそれでOKというのは圧倒的に楽なので、当時のような技術が復活するはずもないのだけど。
厳しいスペックの中でどうやってリッチさを実現するのか悩む時代は過ぎ去って、画面がガクガクするならCPUやGPUを強化すればいい、電気バンバン食うなら大容量バッテリー乗せればいい、帯域が細いなら太くすればいい ―― まるでアメ車のような思考が席巻してるわけで…。
その、FLASHによる999の映像を見ているうちに、ふとなんとなく考え込んでしまった。
今現在、YouTube等で公開されてる動画の数々も、何かしらを解説したりするだけなら、ここまでの帯域を必要としないのだよな…。FLASHのように、再生側でアニメーションをリアルタイム生成できる技術があれば、もっと少ない帯域で送信できていたはずで…。自分達は色んな面でとにかく無駄使いをしている…。
まあ、FLASHは殺されてしまったので、今更望んでもどうしようもないし、映像制作の過程を考えた場合、とにかく最後は動画にしちゃえばそれでOKというのは圧倒的に楽なので、当時のような技術が復活するはずもないのだけど。
厳しいスペックの中でどうやってリッチさを実現するのか悩む時代は過ぎ去って、画面がガクガクするならCPUやGPUを強化すればいい、電気バンバン食うなら大容量バッテリー乗せればいい、帯域が細いなら太くすればいい ―― まるでアメ車のような思考が席巻してるわけで…。
[ ツッコむ ]
2023/06/05(月) [n年前の日記]
#1 [cg_tools] 画像生成AIを触ってる
画像生成AI Stable Diffusion web UI に対して、「xx years old」で人物の年齢を指定できるらしいと知って試していたのだけど。コレ、反映されてるのかどうかよく分らんなと…。乱数シードを固定して、1歳ずつ年齢を変えて生成してみたけれど、変化が無いような…。いやまあ、例えば「9 years old」と「15 years old」を比較したら変わってる感じはするのだけど、1歳程度の違いでは変わらんような…。
ちなみに、「9yo」「15yo」でも年齢指定ができるという話を見かけたけれど、そちらはまだ試してない。
そもそも、学習する元画像に対して、「これは何歳の人物」と指定しておかないと学習できないのではないかと思うのだけど…。その画像に映った人物の年齢なんてフツーは分かるわけないだろうし、このあたり一体どんな感じで学習させてるんだろうと…。それこそAIに何歳ぐらいか推測させながら学習させないと物量的にやってられないのでは…。
それとは別に。人種について今までは「asian」だけ指定して済ませていたけど、ひょっとして国籍まで指定したほうがいいのかなと試してるところ。とりあえず、「japanese」「korean」「chinese」「filipino」「thai」といったワードを指定して結果が違ってくるのか確認してみたけれど、一応変化はしている…のかな…。ちょっと自信が無い。ただ、たまたまそうなったのかもしれないけれど、「asian」と「thai」の生成結果が似た感じに見えなくもないなと…。
まあ、使ってる学習モデルデータによって、このあたりの指定が反映されたりされなかったりするのかもしれんし…。
ちなみに、「9yo」「15yo」でも年齢指定ができるという話を見かけたけれど、そちらはまだ試してない。
そもそも、学習する元画像に対して、「これは何歳の人物」と指定しておかないと学習できないのではないかと思うのだけど…。その画像に映った人物の年齢なんてフツーは分かるわけないだろうし、このあたり一体どんな感じで学習させてるんだろうと…。それこそAIに何歳ぐらいか推測させながら学習させないと物量的にやってられないのでは…。
それとは別に。人種について今までは「asian」だけ指定して済ませていたけど、ひょっとして国籍まで指定したほうがいいのかなと試してるところ。とりあえず、「japanese」「korean」「chinese」「filipino」「thai」といったワードを指定して結果が違ってくるのか確認してみたけれど、一応変化はしている…のかな…。ちょっと自信が無い。ただ、たまたまそうなったのかもしれないけれど、「asian」と「thai」の生成結果が似た感じに見えなくもないなと…。
まあ、使ってる学習モデルデータによって、このあたりの指定が反映されたりされなかったりするのかもしれんし…。
[ ツッコむ ]
2023/06/06(火) [n年前の日記]
#1 [linux] LinuxMintにポータブルHDDを接続してみた
Linux Mint で外付けHDDが認識されないという相談があったので、仮想PC上の Linux Mint 21.1、及び、ノートPC Gateway M-2408j にインストールしてある Linux Mint 21.1 で、USB接続のポータブルHDDが認識されるか動作確認した。
動作確認に使ったポータブルHDDは、Silicon Power SP640GBPHDA80S3B (中身は SAMSUNG HM641JI)。NTFSでフォーマットしてある。USB3.0接続対応。
USB3.0での接続を前提としたポータブルHDDなので、USB2.0ポートに接続したら電力不足で動かないのではないかと不安だったけど、メインPC(デスクトップ機)とノートPC、どちらのUSB2.0ポートに接続しても動いてくれた。
Linux Mint を動かしてる状態でポータブルHDDを接続すると、デスクトップ画面にHDD? USB接続機器? っぽいアイコンが一つ増えて、ファイラーのウインドウが開いて中に入ってるファイル一覧を見ることができた。先日 iPhone 5 をケーブル接続した時と同様に、Linux Mint はUSB接続された機器を自動認識してイイ感じに処理してくれるっぽい。
Windowsが使うフォーマットには、FAT32、NTFS、exFAT があるので…。FAT32、NTFS はともかく、exFATでフォーマットされた外付けHDDだったら面倒かも…? と思いきや、ググってみたところ昨今の Linux kernel は exFAT にも対応済みらしい。
_LinuxでexFATを利用する - ytooyamaのブログ
Ubuntu Linux 20.04 LTS の時点で対応済みらしいので…。Linux Mint 21.1 は、Ubuntu Linux 22.04 LTS をベースにして作られているから、おそらく対応済みではなかろうかと…。exfat と名前がついてるパッケージを検索したら、デフォルトで exfat-fuse が入ってたし…。実際試したわけではないからちょっと自信無いけど。
動作確認に使ったポータブルHDDは、Silicon Power SP640GBPHDA80S3B (中身は SAMSUNG HM641JI)。NTFSでフォーマットしてある。USB3.0接続対応。
USB3.0での接続を前提としたポータブルHDDなので、USB2.0ポートに接続したら電力不足で動かないのではないかと不安だったけど、メインPC(デスクトップ機)とノートPC、どちらのUSB2.0ポートに接続しても動いてくれた。
Linux Mint を動かしてる状態でポータブルHDDを接続すると、デスクトップ画面にHDD? USB接続機器? っぽいアイコンが一つ増えて、ファイラーのウインドウが開いて中に入ってるファイル一覧を見ることができた。先日 iPhone 5 をケーブル接続した時と同様に、Linux Mint はUSB接続された機器を自動認識してイイ感じに処理してくれるっぽい。
Windowsが使うフォーマットには、FAT32、NTFS、exFAT があるので…。FAT32、NTFS はともかく、exFATでフォーマットされた外付けHDDだったら面倒かも…? と思いきや、ググってみたところ昨今の Linux kernel は exFAT にも対応済みらしい。
_LinuxでexFATを利用する - ytooyamaのブログ
Ubuntu Linux 20.04 LTS の時点で対応済みらしいので…。Linux Mint 21.1 は、Ubuntu Linux 22.04 LTS をベースにして作られているから、おそらく対応済みではなかろうかと…。exfat と名前がついてるパッケージを検索したら、デフォルトで exfat-fuse が入ってたし…。実際試したわけではないからちょっと自信無いけど。
◎ 認識しない原因は何だろう :
そんなわけで、Linux Mint 自体は、USB接続外付けHDDを認識してくれることが分かった。となると、どうして認識しないという話になったのか…。
可能性としては、ポータブルHDDをバスパワーのUSBハブに繋いでしまって電力不足で動かない、とかではないのかなと…。あるいは、単に外付けHDDが壊れているか。そのHDDを、別PC、できればWindows機に接続して動くなら、壊れてないことが分かりそう。
PC側のUSBポートが壊れている可能性もあるか…。USBメモリやUSB接続マウスを差してみて、そのポートが生きてるかどうか確認してみるとか…。
可能性としては、ポータブルHDDをバスパワーのUSBハブに繋いでしまって電力不足で動かない、とかではないのかなと…。あるいは、単に外付けHDDが壊れているか。そのHDDを、別PC、できればWindows機に接続して動くなら、壊れてないことが分かりそう。
PC側のUSBポートが壊れている可能性もあるか…。USBメモリやUSB接続マウスを差してみて、そのポートが生きてるかどうか確認してみるとか…。
◎ 2023/06/16追記 :
「ノートPC本体側のUSBポートに外付けHDDを接続したらあっさり認識してくれた」と連絡があった。一安心。それにしても、Linux Mintって至れり尽くせりだな…。デスクトップPC用のOSとして全然使えるのでは…。
[ ツッコむ ]
2023/06/07(水) [n年前の日記]
#1 [python] tkinterのmessageboxでフォントサイズを変更したかったけど無理だった
Windows10 x64 22H2 + Python 3.10.10 で、tkinter を使ってメッセージボックス(messagebox)を表示したいと思った。
表示するだけなら、以下のような感じになる。
_01_showmessageboxtk.py
実行すると以下。Enterキーを叩いたらOKボタンが押されて、ダイアログは閉じてくれた。
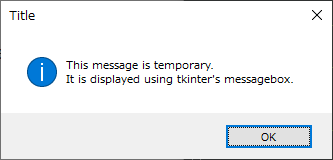
表示するだけなら、以下のような感じになる。
_01_showmessageboxtk.py
import tkinter as tk from tkinter import messagebox text = "This message is temporary.\nIt is displayed using tkinter's messagebox." title = "Title" root = tk.Tk() root.withdraw() messagebox.showinfo(title, text)
- root.withdraw() を呼ぶことで、tkinter のルートウインドウを表示しない状態にしている。
実行すると以下。Enterキーを叩いたらOKボタンが押されて、ダイアログは閉じてくれた。
◎ フォントサイズを変更したい :
これではフォントサイズが小さ過ぎる。フォントサイズを大きくして目立つようにしたい。
方法をググってみたのだけど、これがちょっと難しい。Mac や Linux なら、tkinter.messagebox のフォント種類やフォントサイズを変更することもできなくもないらしいのだけど…。
_How to set font of a messagebox with Python tkinter? - Stack Overflow
_python - Control Font in tkMessageBox - Stack Overflow
しかし、Windows上で動いてる tkinter は、Windowsのネイティブなメッセージボックスを使ってるからフォントサイズ等は変更できないそうで。ギャフン。
_python 3.x - how to change font size of messages inside messagebox.showinfo(message='Hello') in tkinter python3.7 - Stack Overflow
方法をググってみたのだけど、これがちょっと難しい。Mac や Linux なら、tkinter.messagebox のフォント種類やフォントサイズを変更することもできなくもないらしいのだけど…。
_How to set font of a messagebox with Python tkinter? - Stack Overflow
_python - Control Font in tkMessageBox - Stack Overflow
しかし、Windows上で動いてる tkinter は、Windowsのネイティブなメッセージボックスを使ってるからフォントサイズ等は変更できないそうで。ギャフン。
_python 3.x - how to change font size of messages inside messagebox.showinfo(message='Hello') in tkinter python3.7 - Stack Overflow
◎ messageboxを諦める :
幸い、「こういう処理をしたよ」と表示して、Enterキーを叩けばダイアログが閉じる ―― それだけで済むスクリプトを書いていたので、tkinter のルートウインドウにラベルとボタンを追加して済ませてしまうことにした。
_02_showmessageboxtk_root.py
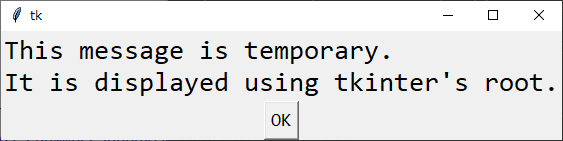
_02_showmessageboxtk_root.py
import tkinter as tk
text = "This message is temporary.\nIt is displayed using tkinter's root."
title = "Title"
root = tk.Tk()
lbl = tk.Label(root, text=text, font=("Consolas", 20), justify="left")
lbl.pack()
btn = tk.Button(root, text="OK", command=root.destroy, font=("Consolas", 14))
btn.pack()
root.mainloop()
- Label や Button に対しては、font=("フォント種類", フォントサイズ) が指定できる。
- Label 内で、改行を含む複数行を表示、かつ、左揃えにしたい場合、justify="left" を指定する。
- root.destroy() を呼べば、ルートウインドウを破棄できる。(.mainloop() から抜ける?)
◎ ショートカットキーを割り当て :
前述の表示結果で目的は果たせそうだけど、messagebox と違って、Enterキーを叩いただけでは閉じてくれない…。TABキーを叩いてボタンにフォーカスを移してSPACEキーを叩かないと、ボタンが押せない…。
ルートウインドウに、EnterキーやEscキーの割り当てをして、それらのキーが押されたら終了するようにしてみた。
_03_showmessageboxtk_root2.py
見た目は前述の結果と変わらないけど、Enterキー、もしくはEscキーを叩けば、ウインドウが閉じてくれるようになった。
ルートウインドウに、EnterキーやEscキーの割り当てをして、それらのキーが押されたら終了するようにしてみた。
_03_showmessageboxtk_root2.py
import tkinter as tk
def close_win(e):
root.destroy()
text = "This message is temporary.\nIt is displayed using tkinter's root."
title = "Title"
root = tk.Tk()
lbl = tk.Label(root, text=text, font=("Consolas", 20), justify="left")
lbl.pack()
btn = tk.Button(root, text="OK", command=root.destroy, font=("Consolas", 14))
btn.pack()
btn.focus()
root.bind("<Return>", lambda e: close_win(e))
root.bind("<Escape>", lambda e: close_win(e))
root.mainloop()
- .bind() で、キーの割り当てができる。
- .focus() で、そのウィジェットをあらかじめフォーカスしておくことができる。
見た目は前述の結果と変わらないけど、Enterキー、もしくはEscキーを叩けば、ウインドウが閉じてくれるようになった。
[ ツッコむ ]
2023/06/08(木) [n年前の日記]
#1 [cg_tools] 画像生成AIの使い方を勉強中
画像生成AI Stable Diffusion web UI の使い方について勉強中。手の形だけを修正したくて、Depth map library and poser という拡張機能をインストールしてみたのだけど、思ったように修正できない…。
◎ 制御不能なコンピュータ :
思考メモ。
画像生成AIを触ってると、今までのコンピュータ関連技術とは異質だなと思えてくる。コンピュータと言うのは、書いたプログラム通りに動いてくれるものだし、プログラムで書いてない機能は使えないもの、だったはずだけど。この手の生成AIは、指示した通りの結果を全然返してくれないし、こちらが指示してないものを平気でポンポン出してくる…。これはもう制御不能状態と言ってもおかしくないのではないか…。
でもまあ、疑似乱数を元にして結果を出してくるあたり、ゲームの類と近いものがあるのかもしれない…。ゲームの敵キャラだって、疑似乱数で動く場合は、どう動くのか分らんもんな…。
画像生成AIを触ってると、今までのコンピュータ関連技術とは異質だなと思えてくる。コンピュータと言うのは、書いたプログラム通りに動いてくれるものだし、プログラムで書いてない機能は使えないもの、だったはずだけど。この手の生成AIは、指示した通りの結果を全然返してくれないし、こちらが指示してないものを平気でポンポン出してくる…。これはもう制御不能状態と言ってもおかしくないのではないか…。
でもまあ、疑似乱数を元にして結果を出してくるあたり、ゲームの類と近いものがあるのかもしれない…。ゲームの敵キャラだって、疑似乱数で動く場合は、どう動くのか分らんもんな…。
[ ツッコむ ]
2023/06/09(金) [n年前の日記]
#1 [cg_tools] 画像生成AIの使い方を勉強中その2
画像生成AI Stable Diffusion web UI の Depth map library and poser の使い方について勉強中。
件の拡張機能で生成したデプスマップ画像を使って、手の部分だけを修正することができるのは間違いないらしい。実際手元の操作でも反映されることが確認できた。ただ、パラメータの与え方がよく分からない…。Control Weight と Starting Control Step を調整することで、反映されたり反映されなかったりするようだけど…。どのあたりが最適な値なのか…。また、img2img の場合は Denoising strength 値も影響するようで…。値が小さいと置き換えてくれない。
この拡張を使って修正すると、背景その他が結構変わってしまうような気もする。もっとも、img2img の Inpaint を利用して、最低限の範囲だけを変更すればいいのかもしれないか…。
件の拡張機能で生成したデプスマップ画像を使って、手の部分だけを修正することができるのは間違いないらしい。実際手元の操作でも反映されることが確認できた。ただ、パラメータの与え方がよく分からない…。Control Weight と Starting Control Step を調整することで、反映されたり反映されなかったりするようだけど…。どのあたりが最適な値なのか…。また、img2img の場合は Denoising strength 値も影響するようで…。値が小さいと置き換えてくれない。
この拡張を使って修正すると、背景その他が結構変わってしまうような気もする。もっとも、img2img の Inpaint を利用して、最低限の範囲だけを変更すればいいのかもしれないか…。
[ ツッコむ ]
#2 [movie] 「美女と野獣」実写版を途中まで視聴
TVで放送されてたので途中まで視聴。23:00からBS放送でアニメが始まったので、そこまでの視聴だけど…。
あの手のアニメに登場する、人間の姿をしていないキャラクター達をどうやって実写化するのか、そのあたりは難易度が高そうだなと思いながら眺めてた。正解が分からない…。あのキャラデザで合ってたのか、他の方向性もあったのかどうか…。
ダンスをするシーンは、アニメ版のほうが良かったなと…。当時の手描きアニメと言えば背景は基本的に動かないものという思い込みがあるわけで、そこを3DCGでぎゅーんと動かしてみせたからこそ「おおー」的感動が味わえたのだろうけど。実写ではカメラがぎゅんぎゅん動くのは当たり前なので、どこでも見かけるフツーの映像になっちゃった感じがするなと…。もっとも、3DCGアニメが当たり前になった現代の感覚からすると、カメラがぎゅーんと動くアニメ映像の何が珍しいの、という感じだろうし。オリジナル版の、あのシーンの驚きは、今ではもう味わえないのだよな…。
あの手のアニメに登場する、人間の姿をしていないキャラクター達をどうやって実写化するのか、そのあたりは難易度が高そうだなと思いながら眺めてた。正解が分からない…。あのキャラデザで合ってたのか、他の方向性もあったのかどうか…。
ダンスをするシーンは、アニメ版のほうが良かったなと…。当時の手描きアニメと言えば背景は基本的に動かないものという思い込みがあるわけで、そこを3DCGでぎゅーんと動かしてみせたからこそ「おおー」的感動が味わえたのだろうけど。実写ではカメラがぎゅんぎゅん動くのは当たり前なので、どこでも見かけるフツーの映像になっちゃった感じがするなと…。もっとも、3DCGアニメが当たり前になった現代の感覚からすると、カメラがぎゅーんと動くアニメ映像の何が珍しいの、という感じだろうし。オリジナル版の、あのシーンの驚きは、今ではもう味わえないのだよな…。
◎ 黒人キャラの扱いが気になった :
白人だけが住んでいる村なのだろうと思いながら眺めていたら、随分と身なりのいい黒人キャラがチラリと登場してゲンナリした…。村人達より高級そうな服を着てるのはダメだろ…。アイツ一体何者…?
また、「化け物をやっつけるぞー! おー!」と村人全員が盛り上がるシーンで、黒人キャラがたった一人、周りをキョロキョロしながら「おいおいお前達何言ってんの。ちょっと待てよ」的アクションをしていて心底ゲンナリした。なんでそういうの入れちゃうの…。そこは黒人キャラも一緒になって「やっつけるぞー! おー!」ってやらせないとダメだろ…。白人も黒人もこういう状況なら似たようなものだよ、肌の色なんて関係ない、人間なんだから皆同じだよ、って感じで見せないと…。黒人=善なる存在として見せつけたかったのかもしれんけど、これじゃある種の差別だろ…。黒人は白人と異なる存在なのだと、この期に及んでわざわざ強調してどうする…。
いやまあ、何かもっともらしいキャラ設定を作ってる可能性もありそうだけど。歴史を調べたら当時こういう扱いの黒人も居ましたので、こういう身なりのキャラがココに居てもおかしくないですよ、等の理論武装ぐらいはしてるんだろう…。そういう考証一切しないで考え無しに入れてたら只のアホだし…。
「やっつけるぞー!」のシーンも、彼の祖先はコレコレこういう扱いを受けてその結果彼はこうなってるので、彼の境遇を鑑みるとあの場で周囲に同調できるわけがないのです、てなバックボーンを持ってる可能性だってあるのかも…。
というか、野獣さんも見た目は真っ黒だから、黒人キャラは「おいおい、ちょっと待ってくれ。同じ黒々仲間としてこの流れは見過ごせん」になった可能性もあるのだろうか…。それならまあ…。いや、敵対する部族を白人に奴隷として売っていたという話を聞いた記憶もあるし、「黒いから」という理由だけで親近感を持つのもおかしいか…。
ああもう、めんどうくせえなあ。一体誰だよ、「黒人を入れろ」って言い出したヤツは…。混ぜるならせめて村人達の後ろのほうに配置して「実はこういうキャラも混ざってました」「よく見ると彼こういうことをしてるんですよ」ぐらいの扱いにしてくれよ…。わざわざ一番前に置くから目立ってしょうがない。晒し者にしてんじゃねえよ…。結局異物扱いしかできないなら最初から出すなよ…。
もっとも、白人の村人達の中にも「ちょ待てよ」派が何人か居た可能性もあるか…。白人の中の白人は目立たないけど、白人の中の黒人は目立つという、ただそれだけの話なのかも…。
また、「化け物をやっつけるぞー! おー!」と村人全員が盛り上がるシーンで、黒人キャラがたった一人、周りをキョロキョロしながら「おいおいお前達何言ってんの。ちょっと待てよ」的アクションをしていて心底ゲンナリした。なんでそういうの入れちゃうの…。そこは黒人キャラも一緒になって「やっつけるぞー! おー!」ってやらせないとダメだろ…。白人も黒人もこういう状況なら似たようなものだよ、肌の色なんて関係ない、人間なんだから皆同じだよ、って感じで見せないと…。黒人=善なる存在として見せつけたかったのかもしれんけど、これじゃある種の差別だろ…。黒人は白人と異なる存在なのだと、この期に及んでわざわざ強調してどうする…。
いやまあ、何かもっともらしいキャラ設定を作ってる可能性もありそうだけど。歴史を調べたら当時こういう扱いの黒人も居ましたので、こういう身なりのキャラがココに居てもおかしくないですよ、等の理論武装ぐらいはしてるんだろう…。そういう考証一切しないで考え無しに入れてたら只のアホだし…。
「やっつけるぞー!」のシーンも、彼の祖先はコレコレこういう扱いを受けてその結果彼はこうなってるので、彼の境遇を鑑みるとあの場で周囲に同調できるわけがないのです、てなバックボーンを持ってる可能性だってあるのかも…。
というか、野獣さんも見た目は真っ黒だから、黒人キャラは「おいおい、ちょっと待ってくれ。同じ黒々仲間としてこの流れは見過ごせん」になった可能性もあるのだろうか…。それならまあ…。いや、敵対する部族を白人に奴隷として売っていたという話を聞いた記憶もあるし、「黒いから」という理由だけで親近感を持つのもおかしいか…。
ああもう、めんどうくせえなあ。一体誰だよ、「黒人を入れろ」って言い出したヤツは…。混ぜるならせめて村人達の後ろのほうに配置して「実はこういうキャラも混ざってました」「よく見ると彼こういうことをしてるんですよ」ぐらいの扱いにしてくれよ…。わざわざ一番前に置くから目立ってしょうがない。晒し者にしてんじゃねえよ…。結局異物扱いしかできないなら最初から出すなよ…。
もっとも、白人の村人達の中にも「ちょ待てよ」派が何人か居た可能性もあるか…。白人の中の白人は目立たないけど、白人の中の黒人は目立つという、ただそれだけの話なのかも…。
[ ツッコむ ]
2023/06/10(土) [n年前の日記]
#1 [cg_tools] 画像生成AIで白黒漫画をどうにかできないか実験中
画像生成AI Stable Diffusion web UIを使って、白黒漫画の中の1コマを実写風画像に変換できないものかなと実験中。
これはちょっと失礼な話かもしれないけど、なんとなく思いついてしまったので…。かつて、写真をトレスして表紙イラストや漫画のコマを描いてることが判明して、ネット上で若干炎上してしまった漫画家さんが居たのだけど。そういった方々が描いた漫画のコマなら、写真を元にしてる可能性が高いだろうし、画像生成AIで実写風画像に変換しやすいのではなかろうかと閃いてしまった、という…。一般的には否定されがちなソレだろうけど、こういう実験をする時はとてもありがたい存在。何がプラスになるのか分らんもんだなと…。
そんなわけで、実際に変換しやすいのか試してたのだけど…。これが全然上手く行かない。仮説は完全に間違ってた。写真をトレスして描かれた(可能性の高い)線画だから、その分変換しやすい ―― そんなことはありえないのだなと分かった。
そもそも、実写風画像への変換どころか、イラスト風の着色処理すら上手く行かない。
考えてみれば、本来そこには色があったはずの光景を白黒で描いてしまった時点で、そこに何が描かれているのか推測する際に必要になるであろう膨大な画像情報が欠落してるのだよなと…。
例えば、コマの中で縦方向に線が数本描かれて空間が区切られていたとして、その各空間が一体何を示しているのか推測せよと言われても、AIどころか人間ですら推測は難しいわけで。作者から、ここは人間の足、ここは腕、ここは背景、ここは木の幹、ここは電柱、などと説明でも受けない限り分かるわけがない。人間ですらそうなのだから、ましてAIに正しく認識させることなんて無理だよな…。
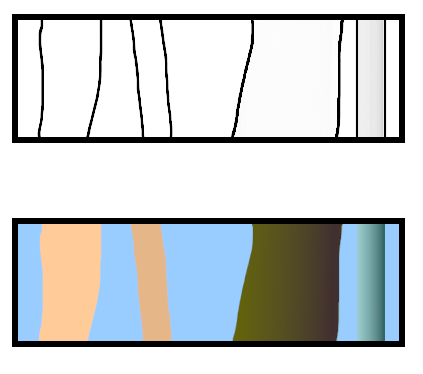
もっとも、漫画の場合、そこに描かれているものが何なのか、読者が推測できなかったら漫画として成立しないので、それが何なのか一目で分かるように、様々な工夫がされているわけだけど。
画像生成AIを触り始めてからというもの、漫画、特に日本で普及した白黒漫画は、よくまあここまで色んな技を駆使しているなと感心しまくりというか。それと同時に、AIがスゴイぞ、AIヤバイぞ、などと言ってるけれど全然まだまだだよなー、と…。人間のように漫画をスラスラと読める状態には程遠い。そもそも、1コマの中に一体何が描かれてるか、真っ当に認識することすらできてない…。
コンピュータやメカトロニクスで人間がやってることの一部を再現しようとすると人間の凄さが実感できる、という話があるけれど。それってホントだなと。人間ってスゴイ。
これはちょっと失礼な話かもしれないけど、なんとなく思いついてしまったので…。かつて、写真をトレスして表紙イラストや漫画のコマを描いてることが判明して、ネット上で若干炎上してしまった漫画家さんが居たのだけど。そういった方々が描いた漫画のコマなら、写真を元にしてる可能性が高いだろうし、画像生成AIで実写風画像に変換しやすいのではなかろうかと閃いてしまった、という…。一般的には否定されがちなソレだろうけど、こういう実験をする時はとてもありがたい存在。何がプラスになるのか分らんもんだなと…。
そんなわけで、実際に変換しやすいのか試してたのだけど…。これが全然上手く行かない。仮説は完全に間違ってた。写真をトレスして描かれた(可能性の高い)線画だから、その分変換しやすい ―― そんなことはありえないのだなと分かった。
そもそも、実写風画像への変換どころか、イラスト風の着色処理すら上手く行かない。
- 肌と服を取り違えた状態で認識されてしまって、無いはずの手足が描かれたり、あるはずの手足が消滅したり。
- 何も描いてない背景部分に何かがあると強固に推測されて、妙なモノが必ず描かれてしまったり。
考えてみれば、本来そこには色があったはずの光景を白黒で描いてしまった時点で、そこに何が描かれているのか推測する際に必要になるであろう膨大な画像情報が欠落してるのだよなと…。
例えば、コマの中で縦方向に線が数本描かれて空間が区切られていたとして、その各空間が一体何を示しているのか推測せよと言われても、AIどころか人間ですら推測は難しいわけで。作者から、ここは人間の足、ここは腕、ここは背景、ここは木の幹、ここは電柱、などと説明でも受けない限り分かるわけがない。人間ですらそうなのだから、ましてAIに正しく認識させることなんて無理だよな…。
もっとも、漫画の場合、そこに描かれているものが何なのか、読者が推測できなかったら漫画として成立しないので、それが何なのか一目で分かるように、様々な工夫がされているわけだけど。
- スクリーントーンを貼ったりハッチングを描き加えて影の形状を示して立体感を提示したり。
- 各線の先端に特徴的な形状を加えることで人体のどの部分なのか伝えていたり。
- 前後のコマで明確に描かれている物体から、そのコマに描かれているものを推測できるようにしていたり。
画像生成AIを触り始めてからというもの、漫画、特に日本で普及した白黒漫画は、よくまあここまで色んな技を駆使しているなと感心しまくりというか。それと同時に、AIがスゴイぞ、AIヤバイぞ、などと言ってるけれど全然まだまだだよなー、と…。人間のように漫画をスラスラと読める状態には程遠い。そもそも、1コマの中に一体何が描かれてるか、真っ当に認識することすらできてない…。
コンピュータやメカトロニクスで人間がやってることの一部を再現しようとすると人間の凄さが実感できる、という話があるけれど。それってホントだなと。人間ってスゴイ。
[ ツッコむ ]
2023/06/11(日) [n年前の日記]
#1 [cg_tools] 画像生成AIでポーズ指定ができなくてハマってる
画像生成AI Stable Diffusion web UI でポーズ指定が思ったようにできなくてちょっとハマってる。txt2img 上で単語を並べて指定する方法は上手くいかなくて、ControlNet の OpenPose を使ってみたりしたけれど…。
例えば、女性が一人立っています、特に変わったポーズではありません、みたいな画像であればフツーに生成できるのだけど。人物が二人以上居て、それぞれが横方向/平面的ではなく前後に配置されていて、しかもそれぞれの四肢が前後で交差しているポーズを取らせようとすると、たちまちクリーチャーというかホラー画像が生成されてしまう…。
要するに、人物画像を生成しようとしても、「奇麗なお人形さん絵」ぐらいしか得られない…。複数の人物が映ると破綻するし、奥行きを伴う配置も破綻する…。
AIが絵描きの仕事を奪うだのなんだの言われてるけど、少なくとも現状では、AIに描けない構図、AIに描けないポーズが山ほどあるので、人間の絵描きさんがAI相手に画力で圧勝することもまだ容易な気がする。とは言うものの、今まで奇麗なお人形絵しか描いてませんでした、みたいな絵描きさんだと絵柄・スタイルを学習されてたちまちアレなことになるのかもしれんけど…。
例えば、女性が一人立っています、特に変わったポーズではありません、みたいな画像であればフツーに生成できるのだけど。人物が二人以上居て、それぞれが横方向/平面的ではなく前後に配置されていて、しかもそれぞれの四肢が前後で交差しているポーズを取らせようとすると、たちまちクリーチャーというかホラー画像が生成されてしまう…。
要するに、人物画像を生成しようとしても、「奇麗なお人形さん絵」ぐらいしか得られない…。複数の人物が映ると破綻するし、奥行きを伴う配置も破綻する…。
AIが絵描きの仕事を奪うだのなんだの言われてるけど、少なくとも現状では、AIに描けない構図、AIに描けないポーズが山ほどあるので、人間の絵描きさんがAI相手に画力で圧勝することもまだ容易な気がする。とは言うものの、今まで奇麗なお人形絵しか描いてませんでした、みたいな絵描きさんだと絵柄・スタイルを学習されてたちまちアレなことになるのかもしれんけど…。
◎ 与える画像の品質が生成結果に関係しそう :
OpenPose でポーズを指定しようとしても上手く行かなくて、別のやり方を試し始めた。実在する人物を撮影したのであろう写真、かつ、望むポーズに近い画像をGoogle画像検索で探してみて、その画像を img2img に渡して生成してみるのはどうだろうと…。
しかし、その方法で試していたところ、顔の真ん中に紙を破いたような亀裂が入ったり、腕や足が途中で千切れるような生成結果が続出して、これはどういうことだろうと悩んでしまった。
少し試しただけなので自信が無いけれど、どうやらjpeg関係のノイズが盛大に載ってる画像を元画像にすると、そういうことが起きるようだなと…。ブロックノイズだかモスキートノイズだかの並びが、たまたま偶然何かの形状をAIに連想させてしまって、そこに無いはずの物体を召喚してしまうのだろう…。
そこからふと妄想。人間の目では「ちょっと画質が悪いかな?」程度にしか見えない画像だけど、その画像をAIに学習データや参照画像として与えた途端、AIの認識がグチャグチャになってしまう、そんな画像を作ることも不可能ではないのかもしれない…。実際、単にjpeg関連ノイズが乗ってるだけなのに、生成される人の顔がこうして真っ二つに切れてしまうわけだし…。
そういう技術、というか裏技が発見/発明されたら…。絵柄/スタイルをAIに盗まれたくない絵描きさんは、特定のパターンを表面にうっすら入れる画像処理ソフトを経由させてからネットで自作の画像を発表する ―― そんな流れが当たり前になるのかもしれない。
もっとも、今現在は誰も彼もが、「どうしたらより高品質な画像を生成できるか」という方向で実験してるはずだろうし…。AIが途端におかしくなっちゃう画像の法則を探そうとしてる人なんてほとんど居ないはずなので…。AIの学習状態を汚染してしまう特定パターンを見つけ出す人なんて居ないだろうし、となると、絵描きさんが「コイツを通せば俺の絵柄を盗まれずに済むぞ」とニンマリするソフトも出てこないだろう…。このあたり、なんだかブルーオーシャンの気配がする…。
しかし、その方法で試していたところ、顔の真ん中に紙を破いたような亀裂が入ったり、腕や足が途中で千切れるような生成結果が続出して、これはどういうことだろうと悩んでしまった。
少し試しただけなので自信が無いけれど、どうやらjpeg関係のノイズが盛大に載ってる画像を元画像にすると、そういうことが起きるようだなと…。ブロックノイズだかモスキートノイズだかの並びが、たまたま偶然何かの形状をAIに連想させてしまって、そこに無いはずの物体を召喚してしまうのだろう…。
そこからふと妄想。人間の目では「ちょっと画質が悪いかな?」程度にしか見えない画像だけど、その画像をAIに学習データや参照画像として与えた途端、AIの認識がグチャグチャになってしまう、そんな画像を作ることも不可能ではないのかもしれない…。実際、単にjpeg関連ノイズが乗ってるだけなのに、生成される人の顔がこうして真っ二つに切れてしまうわけだし…。
そういう技術、というか裏技が発見/発明されたら…。絵柄/スタイルをAIに盗まれたくない絵描きさんは、特定のパターンを表面にうっすら入れる画像処理ソフトを経由させてからネットで自作の画像を発表する ―― そんな流れが当たり前になるのかもしれない。
もっとも、今現在は誰も彼もが、「どうしたらより高品質な画像を生成できるか」という方向で実験してるはずだろうし…。AIが途端におかしくなっちゃう画像の法則を探そうとしてる人なんてほとんど居ないはずなので…。AIの学習状態を汚染してしまう特定パターンを見つけ出す人なんて居ないだろうし、となると、絵描きさんが「コイツを通せば俺の絵柄を盗まれずに済むぞ」とニンマリするソフトも出てこないだろう…。このあたり、なんだかブルーオーシャンの気配がする…。
◎ jpegノイズ除去ソフトを探した :
jpegノイズが盛大に乗ってる画像を元画像として使うと、画像生成AIが妙な結果ばかり出してくることに気づいたので、jpegノイズを除去/削除するソフトを少し探した。環境はWindows10 x64 22H2。
GIMP 2.10.34 Portable のフィルターの選択的ガウスぼかしや、ノイズ軽減を使ってみたけれど、どうも今一つと言うか…。たしかにノイズは消えるのだけど、ノイズ以外の部分、フィルタをかけてほしくないところまで、ぼかし処理がかかってしまう印象で…。
_3.8. 選択的ガウスぼかし...
_4.5. Noise Reduction
色々ググっているうちに、waifu2x-caffe にもノイズ除去機能があると知ったので試用してみた。
_waifu2x-caffe の使い方 - k本的に無料ソフト・フリーソフト
たしかに、全体的にそれっぽいノイズをうっすらと除去してくれた。まあ、等倍表示では違いが分からないけど、拡大表示すれば違いが分かる感じ。
Neat Image というソフトもノイズを除去できるらしいので試用してみたけれど。
_「Neat Image」ディテールを保ちつつデジカメ画像のノイズを低減 - 窓の杜
これは、ぼかしてほしくないところまで、ガンガンぼかすっぽいなと…。もはや何が映ってるのか分からない状態になった…。
そもそも Stable Diffusion web UI でノイズ除去をする機能はないのだろうか? ググってみたけど、それらしい情報には辿り着けず。Stable Diffusion ってノイズから元画像を推測して生成する仕組みだから、「ノイズ除去」でググってみても、画像生成AIの仕組みを解説してるページばかりリストアップされてしまう…。
GIMP 2.10.34 Portable のフィルターの選択的ガウスぼかしや、ノイズ軽減を使ってみたけれど、どうも今一つと言うか…。たしかにノイズは消えるのだけど、ノイズ以外の部分、フィルタをかけてほしくないところまで、ぼかし処理がかかってしまう印象で…。
_3.8. 選択的ガウスぼかし...
_4.5. Noise Reduction
色々ググっているうちに、waifu2x-caffe にもノイズ除去機能があると知ったので試用してみた。
_waifu2x-caffe の使い方 - k本的に無料ソフト・フリーソフト
たしかに、全体的にそれっぽいノイズをうっすらと除去してくれた。まあ、等倍表示では違いが分からないけど、拡大表示すれば違いが分かる感じ。
Neat Image というソフトもノイズを除去できるらしいので試用してみたけれど。
_「Neat Image」ディテールを保ちつつデジカメ画像のノイズを低減 - 窓の杜
これは、ぼかしてほしくないところまで、ガンガンぼかすっぽいなと…。もはや何が映ってるのか分からない状態になった…。
そもそも Stable Diffusion web UI でノイズ除去をする機能はないのだろうか? ググってみたけど、それらしい情報には辿り着けず。Stable Diffusion ってノイズから元画像を推測して生成する仕組みだから、「ノイズ除去」でググってみても、画像生成AIの仕組みを解説してるページばかりリストアップされてしまう…。
[ ツッコむ ]
2023/06/12(月) [n年前の日記]
#1 [cg_tools] OpenPoseについて調べてた
画像生成AI Stable Diffusion web UI は、ControlNet という拡張機能を追加すると人物画像のポーズなどを指定しやすくなる。その ControlNet の中に、OpenPose という棒人形っぽい画像を渡すことでポーズを指定する機能があるので、そのあたりを少し調べてた。
◎ 色は不要だった :
OpenPose は、右や左、肩や肘等の区別を色の違いで表現しているもの、と思っていたのだけど。Stable Diffusion web UI + ControlNet でOpenPoseを利用する場合、実は色情報は要らなくて、グレーの線が引いてあるだけでも十分らしい…。
_コンノヒロムさんはTwitterを...: 「ControlNetのOpenPose、体の左右を無視して常に... Twitter
手元の環境で試してみたけど、真っ黒(#000000) の背景の上に、灰色(#808080等)で線を引くだけで、たしかにポーズが指定できた…。
今まで、きっちり色違いで線を描きつつ、各頂点にもしっかり丸を描かなきゃいけないものと思い込んで苦労してた…。実は OpenPose Editor なんて要らなかったのだな…。いやまあ、OpenPose Editor は別の用途で使えそうだけど。
_コンノヒロムさんはTwitterを...: 「ControlNetのOpenPose、体の左右を無視して常に... Twitter
手元の環境で試してみたけど、真っ黒(#000000) の背景の上に、灰色(#808080等)で線を引くだけで、たしかにポーズが指定できた…。
今まで、きっちり色違いで線を描きつつ、各頂点にもしっかり丸を描かなきゃいけないものと思い込んで苦労してた…。実は OpenPose Editor なんて要らなかったのだな…。いやまあ、OpenPose Editor は別の用途で使えそうだけど。
◎ 色の一覧 :
グレーの線でも反映されると知る前に、OpenPose の色定義を探して眺めていたので、そのあたりも一応メモ。以下のやり取りで、色一覧が提示されてた。
_what is the OpenPose bone color scheme used for the controlnet model? - lllyasviel/ControlNet - Discussion #266 - GitHub
_Openpose-18-keypoints_coco_color_codes_v13-1.pdf
ただ、OpenPose 1.7.0 で抽出した OpenPose画像と照らし合わせると、色が違う気がする…。肩だの肘だのを示す頂点の色は合ってるように見えたけど、各頂点を結ぶ線の色が全然違うような…? 一覧では、線の色については少しだけ暗い色、60%の色として列挙されてるけれど、OpenPose 1.7.0 が出力した画像は頂点の色と線の色が同じに見える…。
_what is the OpenPose bone color scheme used for the controlnet model? - lllyasviel/ControlNet - Discussion #266 - GitHub
_Openpose-18-keypoints_coco_color_codes_v13-1.pdf
ただ、OpenPose 1.7.0 で抽出した OpenPose画像と照らし合わせると、色が違う気がする…。肩だの肘だのを示す頂点の色は合ってるように見えたけど、各頂点を結ぶ線の色が全然違うような…? 一覧では、線の色については少しだけ暗い色、60%の色として列挙されてるけれど、OpenPose 1.7.0 が出力した画像は頂点の色と線の色が同じに見える…。
[ ツッコむ ]
2023/06/13(火) [n年前の日記]
#1 [cg_tools][prog] cog.yamlって何だろう
低品質な画像を高画質化できるらしい、SwinIR という画像処理技術が気になった。AIを使って画像を拡大したり、ノイズを除去してくれるらしい。
_GitHub - JingyunLiang/SwinIR: SwinIR: Image Restoration Using Swin Transformer (official repository)
ローカル環境で動かせるなら動かしてみたい。ざっと見たところ、cog.yaml というファイルが目に入った。
_SwinIR/cog.yaml at main - JingyunLiang/SwinIR - GitHub
.yaml/.yml ファイルか…。中には動作に必要な Pythonモジュールが列挙されてる。これはもしかして、conda用のファイルだろうか。ちなみに condaというのはPythonの仮想環境を作れるツール。
conda に cog.yaml を渡してみた。
ググってみたら、この cog.yaml、どうやら Docker 用のファイルだったらしい。Dockerとな…。やたらと見かけるツール名だけど、何だっけソレ。
_GitHub - JingyunLiang/SwinIR: SwinIR: Image Restoration Using Swin Transformer (official repository)
ローカル環境で動かせるなら動かしてみたい。ざっと見たところ、cog.yaml というファイルが目に入った。
_SwinIR/cog.yaml at main - JingyunLiang/SwinIR - GitHub
.yaml/.yml ファイルか…。中には動作に必要な Pythonモジュールが列挙されてる。これはもしかして、conda用のファイルだろうか。ちなみに condaというのはPythonの仮想環境を作れるツール。
conda に cog.yaml を渡してみた。
conda env create -n swinir --file cog.yamlしかし、何一つパッケージがインストールされなかった。すると、このファイルは何用のファイルなんだろう?
ググってみたら、この cog.yaml、どうやら Docker 用のファイルだったらしい。Dockerとな…。やたらと見かけるツール名だけど、何だっけソレ。
◎ Dockerについて調べた :
「dockerとは」でググってみたら、仮想環境を作れるツールらしい。開発時に必要なライブラリやパッケージをひとまとめにしておけるので、開発が捗るのだとか。
しかし、Linuxのカーネルと密接に絡んだ仕組みになっているので、Windows上ではすんなり使えない模様。有償ソフトの Docker Desktop なるものを導入するか、あるいは、Windows上で仮想PCのWSL2を導入して、その上で Ubuntu Linux等を動かして、そのLinux上で Docker を使う、ということになるそうで。
しかし、Linuxのカーネルと密接に絡んだ仕組みになっているので、Windows上ではすんなり使えない模様。有償ソフトの Docker Desktop なるものを導入するか、あるいは、Windows上で仮想PCのWSL2を導入して、その上で Ubuntu Linux等を動かして、そのLinux上で Docker を使う、ということになるそうで。
◎ 仮想PCの選択で悩む :
Docker を使うためにはWSL2の導入が必要らしいと分かってきたけど…。WSL2か…。うーん。
以前試しに WSL2 を使った時は、他の仮想PC、VMware や VirtualBox の動作が目に見えて遅くなってしまって、WSL2 をアンインストールしてしまった記憶が…。だから、WSL2 はインストールしたくないのだよなあ…。
であれば、VMware や VirtualBox 上で動かしている Linux上で Docker を使うわけにはいかんのだろうか。
そう思って少し調べたけれど、これまた上手くはいかないようで。Docker そのものは仮想PC + Linux で動かせるのだろうけど。そもそも WSL2 上で Docker が使えているのだから、他の仮想PCでも同様だろう。しかし、今回やりたいのは、「GPU(GPGPU)を使って処理をする SwinIR を動かしたい」というお題なわけで…。
仮想PC + Linux から、ホストOS(Windows)が管理してるGPU/ビデオカードを制御できればいいのだけど、現状では難しいらしい。有償、かつ、サーバ用途として販売されてる VMware ならやれなくもないらしいけど、VMware Player や VirtualBox では無理だそうで。GPU(GPGPU)が使えないとなると、SwinIR も動かない…。
つまり、SwinIR が動く環境を Docker を使って構築したい場合は、OSは Linux、かつ、その Linux機にGPGPUが利用できるレベルのビデオカード/GPUを積む、という条件を満たさないといけない。Windows上で、Docker を使って、GPGPUを使うツールの環境を構築するというのは、ちょっと厳しいようだなと…。
もしかすると、WSL2 +Docker を使った場合も、GPGPUは利用できないという問題が発生するのでは…?
以前試しに WSL2 を使った時は、他の仮想PC、VMware や VirtualBox の動作が目に見えて遅くなってしまって、WSL2 をアンインストールしてしまった記憶が…。だから、WSL2 はインストールしたくないのだよなあ…。
であれば、VMware や VirtualBox 上で動かしている Linux上で Docker を使うわけにはいかんのだろうか。
そう思って少し調べたけれど、これまた上手くはいかないようで。Docker そのものは仮想PC + Linux で動かせるのだろうけど。そもそも WSL2 上で Docker が使えているのだから、他の仮想PCでも同様だろう。しかし、今回やりたいのは、「GPU(GPGPU)を使って処理をする SwinIR を動かしたい」というお題なわけで…。
仮想PC + Linux から、ホストOS(Windows)が管理してるGPU/ビデオカードを制御できればいいのだけど、現状では難しいらしい。有償、かつ、サーバ用途として販売されてる VMware ならやれなくもないらしいけど、VMware Player や VirtualBox では無理だそうで。GPU(GPGPU)が使えないとなると、SwinIR も動かない…。
つまり、SwinIR が動く環境を Docker を使って構築したい場合は、OSは Linux、かつ、その Linux機にGPGPUが利用できるレベルのビデオカード/GPUを積む、という条件を満たさないといけない。Windows上で、Docker を使って、GPGPUを使うツールの環境を構築するというのは、ちょっと厳しいようだなと…。
もしかすると、WSL2 +Docker を使った場合も、GPGPUは利用できないという問題が発生するのでは…?
[ ツッコむ ]
#2 [cg_tools] SwinIRをWindows10上で動かしてみた
AIを使って低品質な画像を高画質化するらしい SwinIR を、Windows10 x64 22H2上で動かしてみた。本来は cog.yaml を利用して、Docker で環境を構築するのだろうけど、Docker を使わずに環境構築をして動かしている事例を多々見かけたので、なんとかなりそうだなと…。
_GitHub - JingyunLiang/SwinIR: SwinIR: Image Restoration Using Swin Transformer (official repository)
環境は以下。
今回は、D:\aiwork\swinir\ にインストールしてみる。
_GitHub - JingyunLiang/SwinIR: SwinIR: Image Restoration Using Swin Transformer (official repository)
環境は以下。
- Windows10 x64 22H2
- AMd Ryzen 5 5600X
- NVIDIA GeForce GTX 1060 6GB
- RAM 16GB
- Python 3.8.10 x64, Python 3.10.10 x64
- CUDA 11.8, cuDNN 8.6 をインストール済み。
今回は、D:\aiwork\swinir\ にインストールしてみる。
◎ 環境構築 :
作業の流れとしては以下。
git clone でファイル一式を入手。
Python 3.8 の仮想環境を作成。仮想環境に切り替え。
pip が使えるか確認。ついでに pip をアップグレード。
pip で必要なモジュールをインストールしていく。cog.yaml を参考にして、requirements.txt を作成。
requirements.txt
requirements.txt を指定して一括インストール。
学習モデルデータをダウンロードして入手。
_Release Pretrained models, supplementary and visual results - JingyunLiang/SwinIR - GitHub
_Releases - JingyunLiang/SwinIR
今回は以下のファイルを入手してみた。それぞれ、100MB前後のファイル。
種類をざっくり説明しておくと…。
これらの学習モデルデータ(.pth)を、model_zoo\swinir\ というディレクトリを作成して、その中に入れる。
これで必要な環境は作れたはず。動作確認していく。
- git clone でファイル一式を入手。
- Python + venv で仮想環境を作成。
- 必要なPythonモジュールをpipでインストール。
- 学習モデルデータを入手。
- 動作確認。
git clone でファイル一式を入手。
cd /d D:\aiwork\swinir git clone https://github.com/JingyunLiang/SwinIR.git cd SwinIR
Python 3.8 の仮想環境を作成。仮想環境に切り替え。
py -3.8 -m venv venv venv\Scripts\activate python -V
pip が使えるか確認。ついでに pip をアップグレード。
pip list python -m pip install --upgrade pip
pip で必要なモジュールをインストールしていく。cog.yaml を参考にして、requirements.txt を作成。
requirements.txt
requests torchvision == 0.9.0 torch == 1.8.0 numpy == 1.19.4 opencv-python == 4.4.0.46 tqdm == 4.62.2 Pillow == 8.3.2 timm == 0.4.12 ipython == 7.19.0
requirements.txt を指定して一括インストール。
pip install -r requirements.txt
学習モデルデータをダウンロードして入手。
_Release Pretrained models, supplementary and visual results - JingyunLiang/SwinIR - GitHub
_Releases - JingyunLiang/SwinIR
今回は以下のファイルを入手してみた。それぞれ、100MB前後のファイル。
- 003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth
- 003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_PSNR.pth
- 005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth
- 005_colorDN_DFWB_s128w8_SwinIR-M_noise25.pth
- 005_colorDN_DFWB_s128w8_SwinIR-M_noise50.pth
- 006_CAR_DFWB_s126w7_SwinIR-M_jpeg10.pth
- 006_CAR_DFWB_s126w7_SwinIR-M_jpeg20.pth
- 006_CAR_DFWB_s126w7_SwinIR-M_jpeg30.pth
- 006_CAR_DFWB_s126w7_SwinIR-M_jpeg40.pth
- 006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg10.pth
- 006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg20.pth
- 006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg30.pth
- 006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg40.pth
種類をざっくり説明しておくと…。
- 003_* は、拡大処理用。
- 005_* は、ノイズ除去用。
- 006_* は、Jpegノイズ削減用。
これらの学習モデルデータ(.pth)を、model_zoo\swinir\ というディレクトリを作成して、その中に入れる。
これで必要な環境は作れたはず。動作確認していく。
◎ 動作確認 :
testsets\ の中にサンプル画像群がたくさん入ってるので、それらを使って動作確認ができる。
実行するには、main_test_swinir.py を利用する。
試してみたところ、AMD Ryzen 5 5600X + NVIDIA GeForce GTX 1060 6GB の環境で、1枚につき2分以上かけて処理された。また、サンプル画像フォルダ内には複数の画像が入っているので、全部処理するのに数十分かかった。
main_test_swinir.py --help でヘルプ表示。
--folder_lq と --folder_gt の違いが判らない…。lq = low-quality (低画質) はともかく、gt = ground-truth ってどういう意味…?
_Ground truth (グランドトゥルース) - MATLAB & Simulink
うむ。分からん。なんでもかんでも低画質扱いにしておけばいいのかなと思ったけれどそうでもないようで。--folder_lq ではエラーが出るけど、--folder_gt ならエラーが出ずに処理できた場合もあった。
とりあえず、以下のように使うらしい。
_公式のREADME.md にも記述があるけど使用例を列挙しておく。再度書いておくけど、1行分を実行する度に数十分待たされるので注意。
ちなみに、一番最後、Jpegノイズ軽減カラー版だけ、テスト用画像、testsets/LIVE1/ というフォルダが無かった。
一応、拡大、ノイズ除去、Jpegノイズ削減については動作することを確認できた。
実行するには、main_test_swinir.py を利用する。
試してみたところ、AMD Ryzen 5 5600X + NVIDIA GeForce GTX 1060 6GB の環境で、1枚につき2分以上かけて処理された。また、サンプル画像フォルダ内には複数の画像が入っているので、全部処理するのに数十分かかった。
main_test_swinir.py --help でヘルプ表示。
> python main_test_swinir.py --help
usage: main_test_swinir.py [-h] [--task TASK] [--scale SCALE] [--noise NOISE] [--jpeg JPEG]
[--training_patch_size TRAINING_PATCH_SIZE] [--large_model]
[--model_path MODEL_PATH] [--folder_lq FOLDER_LQ]
[--folder_gt FOLDER_GT] [--tile TILE] [--tile_overlap TILE_OVERLAP]
optional arguments:
-h, --help show this help message and exit
--task TASK classical_sr, lightweight_sr, real_sr, gray_dn, color_dn, jpeg_car, color_jpeg_car
--scale SCALE scale factor: 1, 2, 3, 4, 8
--noise NOISE noise level: 15, 25, 50
--jpeg JPEG scale factor: 10, 20, 30, 40
--training_patch_size TRAINING_PATCH_SIZE patch size used in training SwinIR.
Just used to differentiate two different settings in Table 2 of the paper.
Images are NOT tested patch by patch.
--large_model use large model, only provided for real image sr
--model_path MODEL_PATH
--folder_lq FOLDER_LQ input low-quality test image folder
--folder_gt FOLDER_GT input ground-truth test image folder
--tile TILE Tile size, None for no tile during testing (testing as a whole)
--tile_overlap TILE_OVERLAP Overlapping of different tiles
--folder_lq と --folder_gt の違いが判らない…。lq = low-quality (低画質) はともかく、gt = ground-truth ってどういう意味…?
_Ground truth (グランドトゥルース) - MATLAB & Simulink
Ground truth とは、AI モデルの出力の学習やテストに使用される実際のデータを表す用語です。 自動運転や音声認識など、多くの AI アプリケーションで Ground truth データが必要となります。
うむ。分からん。なんでもかんでも低画質扱いにしておけばいいのかなと思ったけれどそうでもないようで。--folder_lq ではエラーが出るけど、--folder_gt ならエラーが出ずに処理できた場合もあった。
とりあえず、以下のように使うらしい。
# 拡大処理 python main_test_swinir.py --task real_sr --scale 4 --large_model --model_path 学習モデルデータ(.pth)のパス --folder_lq 入力画像フォルダ # ノイズ除去(カラー画像) python main_test_swinir.py --task color_dn --noise 50 --model_path 学習モデルデータ(.pth)のパス --folder_gt 入力画像フォルダ # Jpegノイズ除去(カラー画像) python main_test_swinir.py --task color_jpeg_car --jpeg 40 --model_path 学習モデルデータ(.pth)のパス --folder_gt 入力画像フォルダ
- --task タスク種類 : classical_sr, lightweight_sr, real_sr, gray_dn, color_dn, jpeg_car, color_jpeg_car が指定できる。real_sr が拡大処理。color_dn がカラーノイズ除去。color_jpeg_car がJpegカラーノイズ除去。
- --scale 拡大率 : 1, 2, 3, 4, 8倍が指定できる。
- --large_model : 拡大処理の時のみ使用。大型モデルを使うことを伝えてる。
- --noise NOISE : ノイズ除去レベル。15, 25, 50 のどれかを指定。
- --jpeg JPEG : Jpegノイズ除去レベル。10, 20, 30, 40 のどれかを指定。
- --model_path MODEL_PATH : 学習モデルデータのパスを指定。処理内容によって、利用する学習モデルデータは違ってくる。
- --folder_lq FOLDER_LQ : 入力画像フォルダを指定。低画質画像用。
- --folder_gt FOLDER_GT : 入力画像フォルダを指定。
_公式のREADME.md にも記述があるけど使用例を列挙しておく。再度書いておくけど、1行分を実行する度に数十分待たされるので注意。
@rem @rem 拡大処理 @rem python main_test_swinir.py --task real_sr --scale 4 --large_model --model_path model_zoo/swinir/003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth --folder_lq testsets/RealSRSet+5images python main_test_swinir.py --task real_sr --scale 4 --large_model --model_path model_zoo/swinir/003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_PSNR.pth --folder_lq testsets/RealSRSet+5images @rem @rem ノイズ除去 @rem python main_test_swinir.py --task color_dn --noise 15 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth --folder_gt testsets/McMaster python main_test_swinir.py --task color_dn --noise 25 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise25.pth --folder_gt testsets/McMaster python main_test_swinir.py --task color_dn --noise 50 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise50.pth --folder_gt testsets/McMaster @rem @rem Jpegノイズ軽減、grayscale @rem python main_test_swinir.py --task jpeg_car --jpeg 10 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg10.pth --folder_gt testsets/classic5 python main_test_swinir.py --task jpeg_car --jpeg 20 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg20.pth --folder_gt testsets/classic5 python main_test_swinir.py --task jpeg_car --jpeg 30 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg30.pth --folder_gt testsets/classic5 python main_test_swinir.py --task jpeg_car --jpeg 40 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg40.pth --folder_gt testsets/classic5 @rem @rem Jpegノイズ軽減、color @rem python main_test_swinir.py --task color_jpeg_car --jpeg 10 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg10.pth --folder_gt testsets/LIVE1 python main_test_swinir.py --task color_jpeg_car --jpeg 20 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg20.pth --folder_gt testsets/LIVE1 python main_test_swinir.py --task color_jpeg_car --jpeg 30 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg30.pth --folder_gt testsets/LIVE1 python main_test_swinir.py --task color_jpeg_car --jpeg 40 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg40.pth --folder_gt testsets/LIVE1
ちなみに、一番最後、Jpegノイズ軽減カラー版だけ、テスト用画像、testsets/LIVE1/ というフォルダが無かった。
一応、拡大、ノイズ除去、Jpegノイズ削減については動作することを確認できた。
◎ 参考ページ :
[ ツッコむ ]
2023/06/14(水) [n年前の日記]
#1 [cg_tools] SwinIRを試用中
低品質画像を高画質化できる SwinIR をWindows10 x64 22H2上で動かせるようになったので、少し試用しているところ。
Jpegノイズを軽減する処理は、10,20,30,40 のどれかの値を選べるけれど、40 で処理してみたら目に見えてそれらしいノイズを除去することができた。これは比較的使えそうな気がする。
ノイズ除去処理は、15,25,50 から選べるけれど、50で処理してみたら画像がボケボケになった…。15でも、細部の描写が消えてしまった感じがする。添付のサンプル画像に対してかけた場合も、野菜の表面の水滴などがごっそり消えてしまっていた。たしかにノイズを除去してくれるけど、それ以外の画像情報も消してしまうようだなと…。
4倍に拡大してから、また1/4に縮小したら、元画像サイズそのままでクッキリした画像になるのでは、と想像して試してみたけど、期待していた結果は得られなかった。元画像と比べて、あまり違いが無いような気もする…。GIMP 2.10.34 Portable の「キュービック」(Bicubic?)で縮小してしまったけれど、違うアルゴリズムにすれば違ってきたりしないだろうか…。
Jpegノイズを軽減する処理は、10,20,30,40 のどれかの値を選べるけれど、40 で処理してみたら目に見えてそれらしいノイズを除去することができた。これは比較的使えそうな気がする。
ノイズ除去処理は、15,25,50 から選べるけれど、50で処理してみたら画像がボケボケになった…。15でも、細部の描写が消えてしまった感じがする。添付のサンプル画像に対してかけた場合も、野菜の表面の水滴などがごっそり消えてしまっていた。たしかにノイズを除去してくれるけど、それ以外の画像情報も消してしまうようだなと…。
4倍に拡大してから、また1/4に縮小したら、元画像サイズそのままでクッキリした画像になるのでは、と想像して試してみたけど、期待していた結果は得られなかった。元画像と比べて、あまり違いが無いような気もする…。GIMP 2.10.34 Portable の「キュービック」(Bicubic?)で縮小してしまったけれど、違うアルゴリズムにすれば違ってきたりしないだろうか…。
[ ツッコむ ]
2023/06/15(木) [n年前の日記]
#1 [cg_tools] SwinIRを試用中その2
低品質画像を高画質化できる SwinIR をWindows10 x64 22H2上で動かせるようになったので試用中。
今まで、ファイル名に「PSNR」と書かれてる学習モデルデータを使って拡大処理をしていたけれど。生成結果をよく観察したら、ファイル名に「GAN」と書かれている学習モデルデータで処理したほうが細かい部分もしっかり高画質化してくれるように見えた。
元画像が実写画像かアニメ絵かで違ってくるのかもしれんけど、とりあえず、GAN と書かれてるほうを使うのが良さそうだなと…。
また、拡大処理をすると、元画像に盛大に含まれていたJpeg関連ノイズがほとんど消えてくれることに気づいた。一旦Jpegノイズ除去処理をかけて、次に拡大処理を、などとやっていたけれど、いきなり拡大処理をかけてしまってOKっぽい。
今まで、ファイル名に「PSNR」と書かれてる学習モデルデータを使って拡大処理をしていたけれど。生成結果をよく観察したら、ファイル名に「GAN」と書かれている学習モデルデータで処理したほうが細かい部分もしっかり高画質化してくれるように見えた。
- 003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth ← こっちはバッチリOK
- 003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_PSNR.pth ← こっちはあちこちが結構ボケてしまう
元画像が実写画像かアニメ絵かで違ってくるのかもしれんけど、とりあえず、GAN と書かれてるほうを使うのが良さそうだなと…。
また、拡大処理をすると、元画像に盛大に含まれていたJpeg関連ノイズがほとんど消えてくれることに気づいた。一旦Jpegノイズ除去処理をかけて、次に拡大処理を、などとやっていたけれど、いきなり拡大処理をかけてしまってOKっぽい。
[ ツッコむ ]
#2 [anime] 「CAT'S EYE」は奇跡
思考メモ。
アニメのOP曲/ED曲に関してアレコレ語り合ってるやり取りを目にした。
_ジュディマリの『そばかす』はアニソンにおける米津やYOASOBIの先駆けと言える。ただ一つの問題点を除いては - Togetter
件の曲は、何の作品とタイアップするのかそれすら教えてもらえない状態で作ったと知り、バンドの方々に同情してしまったけれど、それはさておき。
この手のソレの理想形は「CAT'S EYE」だよなーと思えてきた。何せ、オシャレな歌謡曲にしか聞こえないのにサビの部分で作品タイトルをしっかりと歌い上げるという…。一般的な歌謡曲とアニソンの両方から求められるであろう要素を見事に満たしている。本編と分離しても全然聞けるし、本編と一緒に流してもまるでパズルのピースのようにパチッとハマる。全てが完璧。
アニメのOP曲/ED曲に関してアレコレ語り合ってるやり取りを目にした。
_ジュディマリの『そばかす』はアニソンにおける米津やYOASOBIの先駆けと言える。ただ一つの問題点を除いては - Togetter
件の曲は、何の作品とタイアップするのかそれすら教えてもらえない状態で作ったと知り、バンドの方々に同情してしまったけれど、それはさておき。
この手のソレの理想形は「CAT'S EYE」だよなーと思えてきた。何せ、オシャレな歌謡曲にしか聞こえないのにサビの部分で作品タイトルをしっかりと歌い上げるという…。一般的な歌謡曲とアニソンの両方から求められるであろう要素を見事に満たしている。本編と分離しても全然聞けるし、本編と一緒に流してもまるでパズルのピースのようにパチッとハマる。全てが完璧。
◎ 作品タイトルのコールは難しい :
考えてみたら、歌の中でアニメ作品のタイトルをコールするのは、実はとても難しい。いやまあ、やれなくはないのだろうけど、やった瞬間にジャンルが一気に狭まると言うか…。
例えば、「マジンガーZ」やガンダムシリーズでは、そういうことはできない。「ゼェーット!」や「ガンダムッ!」と叫んだら、「あっ。ハイ。コレって昭和のアニソンですよね?」という印象になってしまう…。
そもそも、漫画にしろ、アニメにしろ、作品タイトルと言うものは、膨大な作品群の中で埋没してしまわないよう、極めて独特なワードを含めた状態で決めることが多い。「異世界転生した俺がなんたらかんたらでどうのこうのでうんたらかんたら」とか「俺の○○が○○して○○した件について」とか、そういうアレも全部ソレ。いかにして独自性を出すか。他で使ってなさそうなタイトルを見つけるか。そういう思考で決まっていくはずで。
だから、耳にした瞬間に「ああ、アレか」と気づいてしまう、それらの作品タイトルを、OP/ED曲の歌詞に含めるのは難しい。無理矢理入れることはできる。できるけど、入れた瞬間にその曲は、その作品専用の曲に ―― 作品と分離して単独で楽しめる曲では無くなってしまう。まあ、昭和のアニソンのほとんどは、それを前提にして、どこか使い捨てに近い感覚で歌詞を書いてたと思うけど…。
「CAT'S EYE」も、なかなか危ない時期だった…。何せ、同じ作家さんが後に世に出した「CITY HUNTER」は、独自性を感じさせるタイトルになっていたし。「CITY HUNTER」のOP/ED曲の中で「スィティ〜ハンタァ〜」なんて歌わせることはできない…。それをやっちゃうと昭和のアニソンになってしまう…。その点「CAT'S EYE」はギリギリOKな作品タイトルだった。
そんなわけで、「CAT'S EYE」は奇跡だなと…。今後、あそこまで完璧なアニソンは世に出てこないのではなかろうか。米津玄師さんやYOASOBIさんに、「サビで(チェンソーマン!|ガンダム!)って叫ぶ曲をお願いします」なんて発注はできないもの。「昭和か!」とブチギレるよな…。
逆に考えると、一般的なワードの組み合わせになってる作品タイトルとタイアップする話が来たら、これはとんでもないチャンスなのではないか。あの「CAT'S EYE」と肩を並べる曲を世に出せる、極めて貴重な機会。後にも先にもこんなチャンスは二度と来ないのかもしれない。フツーのアニメだったら、歌詞の中に作品タイトルを入れたり、ましてサビでタイトルをコールするとか、まず無理なわけで…。やるなら今しかねえ…!
実はそんなビッグチャンスをあっさりスルーしてフツーの曲を書いちゃってる場面も多かったりしないかな。どうなんだろう。
例えば、「マジンガーZ」やガンダムシリーズでは、そういうことはできない。「ゼェーット!」や「ガンダムッ!」と叫んだら、「あっ。ハイ。コレって昭和のアニソンですよね?」という印象になってしまう…。
そもそも、漫画にしろ、アニメにしろ、作品タイトルと言うものは、膨大な作品群の中で埋没してしまわないよう、極めて独特なワードを含めた状態で決めることが多い。「異世界転生した俺がなんたらかんたらでどうのこうのでうんたらかんたら」とか「俺の○○が○○して○○した件について」とか、そういうアレも全部ソレ。いかにして独自性を出すか。他で使ってなさそうなタイトルを見つけるか。そういう思考で決まっていくはずで。
だから、耳にした瞬間に「ああ、アレか」と気づいてしまう、それらの作品タイトルを、OP/ED曲の歌詞に含めるのは難しい。無理矢理入れることはできる。できるけど、入れた瞬間にその曲は、その作品専用の曲に ―― 作品と分離して単独で楽しめる曲では無くなってしまう。まあ、昭和のアニソンのほとんどは、それを前提にして、どこか使い捨てに近い感覚で歌詞を書いてたと思うけど…。
「CAT'S EYE」も、なかなか危ない時期だった…。何せ、同じ作家さんが後に世に出した「CITY HUNTER」は、独自性を感じさせるタイトルになっていたし。「CITY HUNTER」のOP/ED曲の中で「スィティ〜ハンタァ〜」なんて歌わせることはできない…。それをやっちゃうと昭和のアニソンになってしまう…。その点「CAT'S EYE」はギリギリOKな作品タイトルだった。
そんなわけで、「CAT'S EYE」は奇跡だなと…。今後、あそこまで完璧なアニソンは世に出てこないのではなかろうか。米津玄師さんやYOASOBIさんに、「サビで(チェンソーマン!|ガンダム!)って叫ぶ曲をお願いします」なんて発注はできないもの。「昭和か!」とブチギレるよな…。
逆に考えると、一般的なワードの組み合わせになってる作品タイトルとタイアップする話が来たら、これはとんでもないチャンスなのではないか。あの「CAT'S EYE」と肩を並べる曲を世に出せる、極めて貴重な機会。後にも先にもこんなチャンスは二度と来ないのかもしれない。フツーのアニメだったら、歌詞の中に作品タイトルを入れたり、ましてサビでタイトルをコールするとか、まず無理なわけで…。やるなら今しかねえ…!
実はそんなビッグチャンスをあっさりスルーしてフツーの曲を書いちゃってる場面も多かったりしないかな。どうなんだろう。
◎ 言語を変更するもの手かもしれない :
もしかすると、歌詞の言語を変えてしまえば、作品タイトルを歌詞に含めることも可能なのかなと思えてきた。
例えば、劇場版アニメ「銀河鉄道999 The Galaxy Express 999」で、ゴダイゴが歌った「銀河鉄道999」。サビの部分にしっかりガッツリ作品タイトルが入っているのだけど、英語だから聞いている分には昭和のアニソンと印象が全然違う。
他に、「銀河漂流バイファム」のOP曲、「HELLO, VIFAM」もあるなと…。歌詞が全部英語。サビでしっかり「VIFAM〜」って歌ってるけど、これまた印象が全然違う。
言語変更とはちょっと違うけど、コーラスとして盛り込む手もありそうか…。「超時空世紀オーガス」のOP曲とか。おそらくボコーダーを通したのであろう「オーガス」というコーラスが入ってたっけ。そういえば、あのバンド、何かの歌番組に出演した際、「オーガス」の部分を全然違うシンセサイザー音で差し替えた状態で演奏していた記憶がある。アニソンを歌うのは恥ずかしいことと思われていた時代だったのだろうな…。
何にせよそのあたりを考えていくと、他にもやり方と言うか、抜け道と言うか、「なるほどその手があったか」と思えるアイデアがまだまだありそうな気もしてきた。
いやまあ、そうまでして作品タイトルを無理矢理コールしなくても、てなところもあるけれど。今時フツーのアニソンはそんなこと一切してないわけだし…。でも、「昭和のアニソンよろしくタイトルが歌詞に入ってるのに曲としてはめっちゃオシャレ」と思われたら…これは目立つんじゃないか…?
例えば、劇場版アニメ「銀河鉄道999 The Galaxy Express 999」で、ゴダイゴが歌った「銀河鉄道999」。サビの部分にしっかりガッツリ作品タイトルが入っているのだけど、英語だから聞いている分には昭和のアニソンと印象が全然違う。
他に、「銀河漂流バイファム」のOP曲、「HELLO, VIFAM」もあるなと…。歌詞が全部英語。サビでしっかり「VIFAM〜」って歌ってるけど、これまた印象が全然違う。
言語変更とはちょっと違うけど、コーラスとして盛り込む手もありそうか…。「超時空世紀オーガス」のOP曲とか。おそらくボコーダーを通したのであろう「オーガス」というコーラスが入ってたっけ。そういえば、あのバンド、何かの歌番組に出演した際、「オーガス」の部分を全然違うシンセサイザー音で差し替えた状態で演奏していた記憶がある。アニソンを歌うのは恥ずかしいことと思われていた時代だったのだろうな…。
何にせよそのあたりを考えていくと、他にもやり方と言うか、抜け道と言うか、「なるほどその手があったか」と思えるアイデアがまだまだありそうな気もしてきた。
いやまあ、そうまでして作品タイトルを無理矢理コールしなくても、てなところもあるけれど。今時フツーのアニソンはそんなこと一切してないわけだし…。でも、「昭和のアニソンよろしくタイトルが歌詞に入ってるのに曲としてはめっちゃオシャレ」と思われたら…これは目立つんじゃないか…?
[ ツッコむ ]
#3 [nitijyou] 日記をアップロード
2023/06/01を最後に日記をアップロードしてなかったのでアップロード。
[ ツッコむ ]
2023/06/16(金) [n年前の日記]
#1 [cg_tools] Swin2SRを試用してみた
低品質な画像を高画質化する SwinIR についてググっていたら、Swin2SR というプログラム? アルゴリズム? を見かけた。
_GitHub - mv-lab/swin2sr: Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration.
これも高画質化のツールなのだろうか…? 何ができるツールなのか分らないけど、動かしてみる。
環境は以下。
_GitHub - mv-lab/swin2sr: Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration.
これも高画質化のツールなのだろうか…? 何ができるツールなのか分らないけど、動かしてみる。
環境は以下。
- Windows10 x64 22H2
- CPU : AMD Ryzen 5 5600X
- GPU : NVIDIA GeForce GTX 1060 6GB
- RAM : 16GB
- Python 3.10.10 64bit を導入済み。
◎ CUDA、cuDNNのインストール :
CUDA 11.6 が必要になるっぽいので、NVIDIA のサイトから、CUDA 11.6.2 と cuDNN 8.4.1 を入手してインストールした。
_CUDA Toolkit - Free Tools and Training | NVIDIA Developer
_CUDA Deep Neural Network (cuDNN) | NVIDIA Developer
以下の2つのファイルを入手。
cuda_11.6.2_511.65_windows.exe を実行してインストール。今回は、D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\ にインストールした。
cudnn-windows-x86_64-8.4.1.50_cuda11.6-archive.zip を解凍して、中に入ってたファイル群を、CUDA 11.6 をインストールした場所にコピーした。
CUDAが使えるように環境変数を設定。今回は、D:\home\bin\cudaset.bat というBATファイルを作成して、cudaset.bat 116 と打てば設定できるようにしておいた、とメモ。実際に設定している内容は以下。
今後、CUDA 11.6 を使いたい時は、事前に BATファイルを実行して環境変数を設定してから使うようにしたい。
_CUDA Toolkit - Free Tools and Training | NVIDIA Developer
_CUDA Deep Neural Network (cuDNN) | NVIDIA Developer
以下の2つのファイルを入手。
- cuda_11.6.2_511.65_windows.exe
- cudnn-windows-x86_64-8.4.1.50_cuda11.6-archive.zip
cuda_11.6.2_511.65_windows.exe を実行してインストール。今回は、D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\ にインストールした。
cudnn-windows-x86_64-8.4.1.50_cuda11.6-archive.zip を解凍して、中に入ってたファイル群を、CUDA 11.6 をインストールした場所にコピーした。
CUDAが使えるように環境変数を設定。今回は、D:\home\bin\cudaset.bat というBATファイルを作成して、cudaset.bat 116 と打てば設定できるようにしておいた、とメモ。実際に設定している内容は以下。
set CUDA_PATH=%CUDA_PATH_V11_6% set CUDNN_PATH=%CUDA_PATH_V11_6% set ADDPATH=%CUDA_PATH%\bin;%CUDA_PATH%\libnvvp;%CUDA_PATH%\include;%CUDA_PATH%\extras\CUPTI\lib64;%CUDA_PATH%\cuda\bin set PATH=%ADDPATH%;%PATH%ちなみに、CUDA 11.6 をインストールすると、CUDA_PATH_V11_6 という環境変数が設定されて、その環境変数にインストール場所が入ってる状態になるので、%CUDA_PATH_V11_6% でインストール場所のパスを取得することができる。
今後、CUDA 11.6 を使いたい時は、事前に BATファイルを実行して環境変数を設定してから使うようにしたい。
◎ ファイル一式を入手 :
Swin2SR関係のファイル一式を git を使って入手。今回は、D:\aiwork\swin2sr\ にインストールした。
cd /d D:\aiwork\swin2sr git clone https://github.com/mv-lab/swin2sr.git cd swin2sr
◎ Pythonの仮想環境を作成 :
Python 3.10 が動く仮想環境を作成。
pip を更新しておく。
py -3.10 -m venv venv venv\Scripts\activate
> python -V Python 3.10.10
pip を更新しておく。
pip list python -m pip install --upgrade pip
◎ Pythonのモジュールをインストール :
cog.yaml の記述を参考にして、Pythonモジュールをpipでインストールしていく。
_swin2sr/cog.yaml at main - mv-lab/swin2sr - GitHub
torch 2.0.1 がインストールされてしまう…。torch 1.12.1 で固定したいのに…。後から torch 1.12.1 をインストールし直した。
torch 1.12.1 をインストールすると、torchvision 1.15.2 が衝突すると言ってくる…。torchvision-0.13.1+cu116 ならOKっぽい。torch のインストール時に torchvision も一緒に指定しておくことで、バージョンが合っている版をインストールしてくれた。
インストールされたPythonモジュールの種類とバージョンは以下の状態になった。
_swin2sr/cog.yaml at main - mv-lab/swin2sr - GitHub
pip install ipython==8.4.0 pip install opencv-python==4.6.0.66 pip install timm==0.6.11 pip install torch==1.12.1 torchvision --extra-index-url=https://download.pytorch.org/whl/cu116
torch 2.0.1 がインストールされてしまう…。torch 1.12.1 で固定したいのに…。後から torch 1.12.1 をインストールし直した。
torch 1.12.1 をインストールすると、torchvision 1.15.2 が衝突すると言ってくる…。torchvision-0.13.1+cu116 ならOKっぽい。torch のインストール時に torchvision も一緒に指定しておくことで、バージョンが合っている版をインストールしてくれた。
インストールされたPythonモジュールの種類とバージョンは以下の状態になった。
> pip list Package Version ------------------ ------------ asttokens 2.2.1 backcall 0.2.0 certifi 2023.5.7 charset-normalizer 3.1.0 colorama 0.4.6 decorator 5.1.1 executing 1.2.0 filelock 3.12.2 fsspec 2023.6.0 huggingface-hub 0.15.1 idna 3.4 ipython 8.4.0 jedi 0.18.2 Jinja2 3.1.2 MarkupSafe 2.1.3 matplotlib-inline 0.1.6 mpmath 1.3.0 networkx 3.1 numpy 1.24.3 opencv-python 4.6.0.66 packaging 23.1 parso 0.8.3 pickleshare 0.7.5 Pillow 9.5.0 pip 23.1.2 prompt-toolkit 3.0.38 pure-eval 0.2.2 Pygments 2.15.1 PyYAML 6.0 requests 2.31.0 setuptools 65.5.0 six 1.16.0 stack-data 0.6.2 sympy 1.12 timm 0.6.11 torch 1.12.1+cu116 torchvision 0.13.1+cu116 tqdm 4.65.0 traitlets 5.9.0 typing_extensions 4.6.3 urllib3 2.0.3 wcwidth 0.2.6
◎ 学習モデルデータを入手 :
model_zoo\swin2sr\ というフォルダを作成して、その中に学習モデルデータを置いておく。
_Release v0.0.1 - mv-lab/swin2sr - GitHub
拡張子が .pth のファイルが学習モデルデータ、らしい。ファイルサイズがそれぞれ数十MB程度なので、全部ダウンロードしてみた。
ちなみに、Pythonの仮想環境等も含めて、ファイルサイズは全部で5GBぐらいになった。
_Release v0.0.1 - mv-lab/swin2sr - GitHub
拡張子が .pth のファイルが学習モデルデータ、らしい。ファイルサイズがそれぞれ数十MB程度なので、全部ダウンロードしてみた。
ちなみに、Pythonの仮想環境等も含めて、ファイルサイズは全部で5GBぐらいになった。
◎ 動作テスト :
inputs というフォルダを作成して、その中に入力画像を入れておく。
main_test_swin2sr.py を実行することで動作確認ができる。--help をつけるとヘルプが表示されるけど、一部のオプションについて記述が抜けている気がする…。--task のところに compressed_sr が書いてないような…?
compressed_sr なる処理をしてみる。
なんだかエラーだか警告だかが出るな…。
生成画像は、自動で作成された resultsフォルダ内に保存される。
生成画像を眺めてみた。たしかに4倍に拡大されているけれど、随分と画質が荒い気がする…。Compressed SR って、一体どういう処理なのだろう?
RealSR とやらを試してみた。
こちらで生成した画像のほうが、画質は良さそうに見えた。
ただ、SwinIR の生成結果と比べると、ちょっと今一つというか…。アニメ絵などは細かい線が消えてしまっているし、実写画像も砂地や岩の模様が消えてしまっている。その代わり、SwinIRと比べて処理時間は圧倒的に短かった。
短い処理時間でそこそこの結果を得たい場合、Swin2SR は有用かもしれない。ただ、よりクッキリした画像が欲しい場合は、時間はかかるけれど SwinIR を使ったほうがいいのかもしれない。
もっとも、SwinIR の生成結果が元画像に近いかどうかは分らない。もしかすると Swin2SR のほうが元画像に近づけてくれている可能性もあるのだろうか。元画像でボケている部分も SwinIR はクッキリした感じにしてしまうけど、Swin2SR ならボケたままだった、そんな事例をどこかで目にした記憶が…。アレはどのページで見かけたのだったか…。ググっても見つからない…。別のアルゴリズムと見間違えたのかな…。
main_test_swin2sr.py を実行することで動作確認ができる。--help をつけるとヘルプが表示されるけど、一部のオプションについて記述が抜けている気がする…。--task のところに compressed_sr が書いてないような…?
> python main_test_swin2sr.py --help
usage: main_test_swin2sr.py [-h] [--task TASK] [--scale SCALE] [--noise NOISE] [--jpeg JPEG]
[--training_patch_size TRAINING_PATCH_SIZE] [--large_model]
[--model_path MODEL_PATH] [--folder_lq FOLDER_LQ] [--folder_gt FOLDER_GT]
[--tile TILE] [--tile_overlap TILE_OVERLAP] [--save_img_only]
options:
-h, --help show this help message and exit
--task TASK classical_sr, lightweight_sr, real_sr, gray_dn, color_dn, jpeg_car, color_jpeg_car
--scale SCALE scale factor: 1, 2, 3, 4, 8
--noise NOISE noise level: 15, 25, 50
--jpeg JPEG scale factor: 10, 20, 30, 40
--training_patch_size TRAINING_PATCH_SIZE
patch size used in training Swin2SR. Just used to differentiate two different
settings in Table 2 of the paper. Images are NOT tested patch by patch.
--large_model use large model, only provided for real image sr
--model_path MODEL_PATH
--folder_lq FOLDER_LQ
input low-quality test image folder
--folder_gt FOLDER_GT
input ground-truth test image folder
--tile TILE Tile size, None for no tile during testing (testing as a whole)
--tile_overlap TILE_OVERLAP
Overlapping of different tiles
--save_img_only save image and do not evaluate
compressed_sr なる処理をしてみる。
python main_test_swin2sr.py --task compressed_sr --scale 4 --training_patch_size 48 --model_path model_zoo/swin2sr/Swin2SR_CompressedSR_X4_48.pth --folder_lq ./inputs --save_img_only
なんだかエラーだか警告だかが出るな…。
D:\aiwork\swin2sr\swin2sr\venv\lib\site-packages\torch\functional.py:478: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ..\aten\src\ATen\native\TensorShape.cpp:2895.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]「将来的にはindexing引数が必要になるよ」と言われてるように見える。一応処理は出来てるようだけど…。
生成画像は、自動で作成された resultsフォルダ内に保存される。
生成画像を眺めてみた。たしかに4倍に拡大されているけれど、随分と画質が荒い気がする…。Compressed SR って、一体どういう処理なのだろう?
RealSR とやらを試してみた。
python main_test_swin2sr.py --task real_sr --scale 4 --model_path model_zoo/swin2sr/Swin2SR_RealworldSR_X4_64_BSRGAN_PSNR.pth --folder_lq ./inputs
こちらで生成した画像のほうが、画質は良さそうに見えた。
ただ、SwinIR の生成結果と比べると、ちょっと今一つというか…。アニメ絵などは細かい線が消えてしまっているし、実写画像も砂地や岩の模様が消えてしまっている。その代わり、SwinIRと比べて処理時間は圧倒的に短かった。
短い処理時間でそこそこの結果を得たい場合、Swin2SR は有用かもしれない。ただ、よりクッキリした画像が欲しい場合は、時間はかかるけれど SwinIR を使ったほうがいいのかもしれない。
もっとも、SwinIR の生成結果が元画像に近いかどうかは分らない。もしかすると Swin2SR のほうが元画像に近づけてくれている可能性もあるのだろうか。元画像でボケている部分も SwinIR はクッキリした感じにしてしまうけど、Swin2SR ならボケたままだった、そんな事例をどこかで目にした記憶が…。アレはどのページで見かけたのだったか…。ググっても見つからない…。別のアルゴリズムと見間違えたのかな…。
[ ツッコむ ]
#2 [python] tkinter用のGUIレイアウトツールを少し試用
Windows版のPythonには、標準でGUIアプリを作れるモジュール、tkinter が含まれている。Tcl/Tkという言語の、GUI部分を担当しているTkをPythonから利用できるようにしたのが tkinter。
その、tkinter用のGUIレイアウトが出来るツール(RADツール?)が気になったので、少し試用してみた。環境は Windows10 x64 22H2 + Python 3.10.10 64bit。
その、tkinter用のGUIレイアウトが出来るツール(RADツール?)が気になったので、少し試用してみた。環境は Windows10 x64 22H2 + Python 3.10.10 64bit。
◎ PAGEを試用 :
_PAGE - A Python GUI Generator
_PAGE - Browse /page/7.6 at SourceForge.net
現行版は 7.6 らしい。page-7.6.exe をダウンロードして実行するとインストーラが起動する。どこにインストールするかと尋ねてきたので、今回は D:\Python\page\ にインストールした。
デスクトップにアイコンが作成されたのでダブルクリックして起動しようとしたところ、「python3が無い」と言われて起動せず。page.bat を編集して python3 を python に書き換えたところ動くようになった。
少し触ってみたけれど、各部品を座標値で配置していくようだなと…。このレイアウト方法は、好きなように部品を配置できる点がメリットだけど、ウインドウサイズの変更時に部品の位置が追従して変わってくれないあたりはデメリットかも。
_PAGE - Browse /page/7.6 at SourceForge.net
現行版は 7.6 らしい。page-7.6.exe をダウンロードして実行するとインストーラが起動する。どこにインストールするかと尋ねてきたので、今回は D:\Python\page\ にインストールした。
デスクトップにアイコンが作成されたのでダブルクリックして起動しようとしたところ、「python3が無い」と言われて起動せず。page.bat を編集して python3 を python に書き換えたところ動くようになった。
@start /min python3 "%~dp0page.py" %1 %2 %3 ↓ @start /min python "%~dp0page.py" %1 %2 %3
少し触ってみたけれど、各部品を座標値で配置していくようだなと…。このレイアウト方法は、好きなように部品を配置できる点がメリットだけど、ウインドウサイズの変更時に部品の位置が追従して変わってくれないあたりはデメリットかも。
◎ GUI builderを試用 :
_SpecTcl Home Page
_SpecTcl - Browse /GUI Builder/2.5.20070129 at SourceForge.net
本来は Tcl/Tk 用のツールだけど、Perl/Tk、Ruby/Tk、Python/Tkinter もサポートしてる。座標値で部品を配置せず、グリッド内に部品を配置していくタイプ。
「here.」と書かれてるリンクをクリックすると、2.5.20070129 版の入手先ページが開く。guibuilder-win32-ix86-20070129.exe がWindows版。ダブルクリックすればウインドウが表示されて、そのまま利用できる。
Windows10 x64 22H2上でも起動はしたのだけど…。古いツールなので、Commands → Start Test を選んでも、Python 2.x 用のスクリプトを生成してしまって、Python 3.x がインストールされてる環境ではエラーが出てしまう。
環境変数 PATHの先頭に Python 2.7 を追加してから guibuilder-win32-ix86-20070129.exe を起動してみた。この状態なら Commands → Start Test でウインドウのプレビューが表示できた。ただ、一度表示すると GUI Builder が固まる…。File → Save をすれば .py も生成されて、Commands → Vide Code でPythonスクリプトのソースが見れるようなので、それでどうにか…。
_SpecTcl - Browse /GUI Builder/2.5.20070129 at SourceForge.net
本来は Tcl/Tk 用のツールだけど、Perl/Tk、Ruby/Tk、Python/Tkinter もサポートしてる。座標値で部品を配置せず、グリッド内に部品を配置していくタイプ。
「here.」と書かれてるリンクをクリックすると、2.5.20070129 版の入手先ページが開く。guibuilder-win32-ix86-20070129.exe がWindows版。ダブルクリックすればウインドウが表示されて、そのまま利用できる。
Windows10 x64 22H2上でも起動はしたのだけど…。古いツールなので、Commands → Start Test を選んでも、Python 2.x 用のスクリプトを生成してしまって、Python 3.x がインストールされてる環境ではエラーが出てしまう。
環境変数 PATHの先頭に Python 2.7 を追加してから guibuilder-win32-ix86-20070129.exe を起動してみた。この状態なら Commands → Start Test でウインドウのプレビューが表示できた。ただ、一度表示すると GUI Builder が固まる…。File → Save をすれば .py も生成されて、Commands → Vide Code でPythonスクリプトのソースが見れるようなので、それでどうにか…。
◎ SpecTclを試用 :
_SpecTcl Home Page
_SpecTcl - Browse /Windows binary/1.2.2a at SourceForge.net
前述の GUI Builder の元になったツール。だと思う。たぶん。1.2.2a が最終版だろうか。SpecTcl122a.exe をダウンロードして、ダブルクリックすれば起動する。1.2.2a なら Python/Tkinter もサポートしているらしい。他に、Java, Perl, HTML もサポートしてある模様。
これも古いツールなので、Python 2.x用のスクリプトを生成するのだけど…。Python 2.7 に切り替えて生成された .py を実行してもエラーが出てしまう。もしかすると tkinter に対応させようとしたけど途中で開発が止まってしまったのかも…。
_SpecTcl - Browse /Windows binary/1.2.2a at SourceForge.net
前述の GUI Builder の元になったツール。だと思う。たぶん。1.2.2a が最終版だろうか。SpecTcl122a.exe をダウンロードして、ダブルクリックすれば起動する。1.2.2a なら Python/Tkinter もサポートしているらしい。他に、Java, Perl, HTML もサポートしてある模様。
これも古いツールなので、Python 2.x用のスクリプトを生成するのだけど…。Python 2.7 に切り替えて生成された .py を実行してもエラーが出てしまう。もしかすると tkinter に対応させようとしたけど途中で開発が止まってしまったのかも…。
◎ pygubuを試用 :
_GitHub - alejandroautalan/pygubu: A simple GUI builder for the python tkinter module
_GitHub - alejandroautalan/pygubu-designer: A simple GUI designer for the python tkinter module
pipでインストールできる。
Pythonインストールフォルダ\Scripts\内に、pygubu-designer.exe があるので、実行するとレイアウトツールが起動する。
部品のレイアウト方法は、pack, grid, place が選べる。上下や左右に並べて配置することもできるし、グリッドで配置もできるし、座標値で配置することもできるのだろう。
pygubu-designer.exe は、拡張子が .ui の xmlファイルを出力することに特化したツールらしい。別途 .py を書いて、その中から .ui を呼び出して使う形になるっぽい。
しかし…。Python 3.10.10 + pygubu 0.31 では、import pygubu の行で「ModuleNotFoundError: No module named 'pygubu'」と表示されてしまう…。なんでや…。
py hoge.py ではエラーが出るけど、python hoge.py なら動くことに気づいた。何故…。
_GitHub - alejandroautalan/pygubu-designer: A simple GUI designer for the python tkinter module
pipでインストールできる。
pip install pygubu -U pip install pygubu-designer -U
> pip list | grep pygubu pygubu 0.31 pygubu-designer 0.36
Pythonインストールフォルダ\Scripts\内に、pygubu-designer.exe があるので、実行するとレイアウトツールが起動する。
部品のレイアウト方法は、pack, grid, place が選べる。上下や左右に並べて配置することもできるし、グリッドで配置もできるし、座標値で配置することもできるのだろう。
pygubu-designer.exe は、拡張子が .ui の xmlファイルを出力することに特化したツールらしい。別途 .py を書いて、その中から .ui を呼び出して使う形になるっぽい。
しかし…。Python 3.10.10 + pygubu 0.31 では、import pygubu の行で「ModuleNotFoundError: No module named 'pygubu'」と表示されてしまう…。なんでや…。
py hoge.py ではエラーが出るけど、python hoge.py なら動くことに気づいた。何故…。
◎ PySimpleGUIでもいいような気がしてきた :
_PySimpleGUI/readme.ja.md at master - PySimpleGUI/PySimpleGUI - GitHub
_Tkinterを使うのであればPySimpleGUIを使ってみたらという話 - Qiita
_[Python]PySimpleGUIでGUIプログラミング | 藤の手帳
_【PySimpleGUI】PythonでカンタンにGUIを作ろう! - Qiita
部品をグリッド内に配置していくだけなら、PySimpleGUI を使ってしまったほうが楽かもしれないと思えてきた。
あるいは、guizero とか…。
_Installation - guizero
_Tkinterを使うのであればPySimpleGUIを使ってみたらという話 - Qiita
_[Python]PySimpleGUIでGUIプログラミング | 藤の手帳
_【PySimpleGUI】PythonでカンタンにGUIを作ろう! - Qiita
部品をグリッド内に配置していくだけなら、PySimpleGUI を使ってしまったほうが楽かもしれないと思えてきた。
あるいは、guizero とか…。
_Installation - guizero
[ ツッコむ ]
2023/06/17(土) [n年前の日記]
#1 [tcltk] Windows用のTcl/Tkをいくつかインストール
Windows10 x64 22H2上で動きそうなTcl/Tkをいくつかインストールしてみた。ActiveTcl は有償化されたという話を見かけたので、代わりの何かを探さないといかんのだろうなと…。
以下参考ページ。
_Windows向けのTcl/Tk | 株式会社きじねこ
_WindowsのTcl/Tkの実行環境 - Qiita
_Tcl/Tk Software
以下参考ページ。
_Windows向けのTcl/Tk | 株式会社きじねこ
_WindowsのTcl/Tkの実行環境 - Qiita
_Tcl/Tk Software
◎ BAWTをインストール :
_Downloads | BAWT
Tcl 8.6.13 Batteries Included (64 bit) (SetupTcl-BI-8.6.13-x64_Bawt-2.3.1.exe) を入手。実行するとインストーラが起動する。今回は D:\TclTk\BAWT\ にインストールしてみた。
bin\ の中に wish.exe があるので実行すると、コマンド入力ウインドウとアプリ表示用ウインドウの2つが表示される。コマンド入力ウインドウでTcl/Tkのコマンドを打ち込むと、アプリ表示用ウインドウに反映される。
事前にスクリプトソース (.tcl) を書いて、wish hoge.tcl とすれば実行できる。
Tcl 8.6.13 Batteries Included (64 bit) (SetupTcl-BI-8.6.13-x64_Bawt-2.3.1.exe) を入手。実行するとインストーラが起動する。今回は D:\TclTk\BAWT\ にインストールしてみた。
bin\ の中に wish.exe があるので実行すると、コマンド入力ウインドウとアプリ表示用ウインドウの2つが表示される。コマンド入力ウインドウでTcl/Tkのコマンドを打ち込むと、アプリ表示用ウインドウに反映される。
事前にスクリプトソース (.tcl) を書いて、wish hoge.tcl とすれば実行できる。
◎ IronTclをインストール :
_IronTcl by Eyrie Solutions
「Tcl/Tk 8.6.7 (x86)」と書かれてるリンクをクリックすると、irontcl-win32-8.6.7.zip が入手できる。解凍して任意のフォルダに置く。今回は D:\TclTk\IronTcl\ に置いた。
bin\ 内に wish86t.exe があるので実行すれば、2つのウインドウが開いて動作確認ができる。
tclsh86t.exe、wish86t.exe は、tclsh.exe、wish.exe にリネームコピーして使ってしまっても構わないらしい。
「Tcl/Tk 8.6.7 (x86)」と書かれてるリンクをクリックすると、irontcl-win32-8.6.7.zip が入手できる。解凍して任意のフォルダに置く。今回は D:\TclTk\IronTcl\ に置いた。
bin\ 内に wish86t.exe があるので実行すれば、2つのウインドウが開いて動作確認ができる。
tclsh86t.exe、wish86t.exe は、tclsh.exe、wish.exe にリネームコピーして使ってしまっても構わないらしい。
◎ Tckkitをインストール :
_TclKits: Downloads
_Tcl3D - Applications - Tclkits
tclkit-8.6.3-win32-ix86.exe を入手。この exeファイル単体で動作する。今回は D:\TclTk\Tclkit-8.6.3\ に置いておいた。
tclkit.exe にリネームコピーして使ってもいい。
_Tcl3D - Applications - Tclkits
tclkit-8.6.3-win32-ix86.exe を入手。この exeファイル単体で動作する。今回は D:\TclTk\Tclkit-8.6.3\ に置いておいた。
tclkit.exe にリネームコピーして使ってもいい。
◎ Magicsplatをインストール :
_Magicsplat Tcl/Tk for Windows | Magicsplat
_magicsplat - Browse /magicsplat-tcl at SourceForge.net
tcl-8.6.13-installer-1.13.0-x64.msi を入手して実行するとインストーラが起動する。現在のユーザだけが利用できる状態にするか、全ユーザが利用できる状態にするかを尋ねてくるので、後者を選べば任意の場所にインストールすることができるっぽい。今回は D:\Tcl86\ にインストールしてみた。
bin\ 内に wish86t.exe 等があるので(以下略)
_magicsplat - Browse /magicsplat-tcl at SourceForge.net
tcl-8.6.13-installer-1.13.0-x64.msi を入手して実行するとインストーラが起動する。現在のユーザだけが利用できる状態にするか、全ユーザが利用できる状態にするかを尋ねてくるので、後者を選べば任意の場所にインストールすることができるっぽい。今回は D:\Tcl86\ にインストールしてみた。
bin\ 内に wish86t.exe 等があるので(以下略)
◎ 余談。Magicsplatのアンインストールと再インストールでBSOD :
Magicsplat のインストール場所を変えたくて、コントロールパネル経由でアンインストールしようとしたら、Windows10がブルースクリーン(BSOD)に…。
インストーラ、tcl-8.6.13-installer-1.13.0-x64.msi を起動して Remove を選んだらアンインストールはできたけど、今度は再インストールしようとしてもブルースクリーンになってしまう…。何度試してもブルースクリーン…。
自分の環境が何かおかしくなってる可能性が高いけれど、どうしたものか。何だか動作が怪しい気がするSSDではなく、HDDにインストールしようとしてるのに、それでもBSODになるとは…。
こういうこともあるから、zipを解凍して任意の場所に置けるインストール方法もあると嬉しいのだけど…。導入を簡単にするためにインストーラ形式にしているのだろうけど、その結果そもそもインストールできなくなるのでは…。いや、1度はインストールできたんだけど…。
まあ、BAWT か IronTcl を使えばいいか…。Magicsplat は諦めよう…。
インストーラ、tcl-8.6.13-installer-1.13.0-x64.msi を起動して Remove を選んだらアンインストールはできたけど、今度は再インストールしようとしてもブルースクリーンになってしまう…。何度試してもブルースクリーン…。
自分の環境が何かおかしくなってる可能性が高いけれど、どうしたものか。何だか動作が怪しい気がするSSDではなく、HDDにインストールしようとしてるのに、それでもBSODになるとは…。
こういうこともあるから、zipを解凍して任意の場所に置けるインストール方法もあると嬉しいのだけど…。導入を簡単にするためにインストーラ形式にしているのだろうけど、その結果そもそもインストールできなくなるのでは…。いや、1度はインストールできたんだけど…。
まあ、BAWT か IronTcl を使えばいいか…。Magicsplat は諦めよう…。
[ ツッコむ ]
#2 [pc] ページファイルの断片化が酷いことになってた
Windows10 x64 22H2 のページファイル、pagefile.sys の断片化数が 130207 と酷いことになっていた…。もしやこれが原因で Magicsplat のアンインストールや再インストールに失敗していたのでは…?
Auslogics Disk Defrag 8.0.24.0 でオフラインデフラグをかけて、断片化を解消。
しかし、Magicsplat の再インストールは相変わらずできなかった。何度試しても、やはりブルースクリーン(BSOD)になる…。
ちなみに、BSODの停止コードは PAGE_FAULT_IN_NONPAGED_AREA。失敗した内容は、Ntfs.sys。
SSD か HDDにアクセスしようとした時にBSODになるのだろうけど、何かしらのインストール処理やアンインストール処理をした時だけBSODになる感じがする…。何かのアプリを立ち上げて作業する分にはBSODになってないし…。
一応、ブルースクリーンになるたびに、chkdsk /f /offlinescanandfix C: や chkdsk /f /offlinescanandfix D: は走らせているけれど、何かが壊れているという表示は出ていない。
Auslogics Disk Defrag 8.0.24.0 でオフラインデフラグをかけて、断片化を解消。
しかし、Magicsplat の再インストールは相変わらずできなかった。何度試しても、やはりブルースクリーン(BSOD)になる…。
ちなみに、BSODの停止コードは PAGE_FAULT_IN_NONPAGED_AREA。失敗した内容は、Ntfs.sys。
SSD か HDDにアクセスしようとした時にBSODになるのだろうけど、何かしらのインストール処理やアンインストール処理をした時だけBSODになる感じがする…。何かのアプリを立ち上げて作業する分にはBSODになってないし…。
一応、ブルースクリーンになるたびに、chkdsk /f /offlinescanandfix C: や chkdsk /f /offlinescanandfix D: は走らせているけれど、何かが壊れているという表示は出ていない。
◎ 一時ファイル等も削除してみた :
CCleaner 6.11.10455 64bit を使って、一時ファイル等を削除してみた。その後エクスプローラを起動 → ドライブを右クリック → プロパティ → ツールを選んで、SSDを最適化、というか trim をかけてみた。
しかし、Magicsplat の再インストールを試みると相変わらずBSOD。うーん。
しかし、Magicsplat の再インストールを試みると相変わらずBSOD。うーん。
[ ツッコむ ]
2023/06/18(日) [n年前の日記]
#1 [tcltk] Windows用のTcl/Tkをいくつかインストールその2
Windows10 x64 22H2上で、Windows上で使える Tcl/Tk、Magicsplat (tcl-8.6.13-installer-1.13.0-x64.msi) をインストールしようとしてもブルースクリーンになってしまうのが気になって、その後もインストールできる方法が無いか試していた。
とりあえず、インストール時に Advanced や all user を選ばず、フツーに Install を選んで、C:\Users\(USERNAME)\AppData\Local\Apps\Tcl86\ 以下にインストールした場合はブルースクリーンにならずに済んだ。とメモ。
もっとも、この場合、そのユーザしか使えない状態でインストールされているわけだけど…。
とりあえず、インストール時に Advanced や all user を選ばず、フツーに Install を選んで、C:\Users\(USERNAME)\AppData\Local\Apps\Tcl86\ 以下にインストールした場合はブルースクリーンにならずに済んだ。とメモ。
もっとも、この場合、そのユーザしか使えない状態でインストールされているわけだけど…。
◎ exe化できるか試してみた :
Tcl/Tk用スクリプトを exeファイルにしてみたい。昔試した際のメモを参考にしつつ作業。
_mieki256's diary - Tcl/TkをWindows10にインストール
_mieki256's diary - Tcl/Tkのスクリプトをexe化
tclkit.exe、sdx.kit (sdx-20110317.kit) の入手先は以下。
_TclKits: Downloads
_Tcl3D - Applications - Tclkits
_Tclkit support files:
tclkit-8.6.*-win32-*.exe を入手できたので、tclkit.exe にリネームして、それらを使ってexe化できそうか試してみたのだけど、以前の手順では上手くいかなかった。別の手順なら exe化できた。
ググっていたら、以下のページにヒントらしきものが書いてあった。
_sdx: howto
「sdxを実行するための tclkit と、-runtime に指定する tclkit は同じではいけない。コピーを作って指定せよ」とのこと。
また、上記のページには以下のような指定方法も記述されていた。これは Linux上でのやり方だろうけど、Windows上でも使えそうな気がする…。
そんなわけで、以下を試みた。
以下を実行。
test001 というファイルが作成されたので、test001.exe にリネーム。
test001.exe を実行してみたところ、動いてくれた。
tclkit 8.6.0、8.6.3、8.6.9 で試してみたけれど、どの版の exe も同じように動いてくれた。
_mieki256's diary - Tcl/TkをWindows10にインストール
_mieki256's diary - Tcl/Tkのスクリプトをexe化
tclkit.exe、sdx.kit (sdx-20110317.kit) の入手先は以下。
_TclKits: Downloads
_Tcl3D - Applications - Tclkits
_Tclkit support files:
tclkit-8.6.*-win32-*.exe を入手できたので、tclkit.exe にリネームして、それらを使ってexe化できそうか試してみたのだけど、以前の手順では上手くいかなかった。別の手順なら exe化できた。
ググっていたら、以下のページにヒントらしきものが書いてあった。
_sdx: howto
For native kits, remember the tclkit that runs sdx cannot be the same tclkit that is used for -runtime .. so make a copy:sdx: howto より
「sdxを実行するための tclkit と、-runtime に指定する tclkit は同じではいけない。コピーを作って指定せよ」とのこと。
また、上記のページには以下のような指定方法も記述されていた。これは Linux上でのやり方だろうけど、Windows上でも使えそうな気がする…。
$ ./tclkit sdx.kit qwrap hello.tcl -runtime tclkit.exe $ mv hello hello.exe
そんなわけで、以下を試みた。
- sdx-20110317.kit と tclkit-8.6.3-win32-x86_64.exe を入手。
- sdx-20110317.kit を sdx.kit にリネーム。
- tclkit-8.6.3-win32-x86_64.exe を tclkit.exe にリネームしつつコピー。中身/バイナリとしては同じでもファイル名が異なる tclkit が2つある状態にしておく。
以下を実行。
tclkit.exe sdx.kit qwrap test001.tcl -runtime tclkit-8.6.3-win32-x86_64.exeウインドウが開いたままになるので、exit と打って抜ける。
test001 というファイルが作成されたので、test001.exe にリネーム。
ren test001 test001.exe
test001.exe を実行してみたところ、動いてくれた。
tclkit 8.6.0、8.6.3、8.6.9 で試してみたけれど、どの版の exe も同じように動いてくれた。
◎ 上手く行かなかった手順についてメモ :
sdx.bat qwrap hoge.tcl や sdx.bat unwrap hoge.kit をするたびに、ウインドウが表示されてそのまま残り続けるのだけど、exit と打ち込んでその都度ウインドウを閉じていった。そうしないとプロセスが残り続ける。
最後に sdx.bat wrap hoge.exe -runtime tclkit.exe と打ってexe化しようとしたけれど、ここでよく分からないエラーが出た。
tclkit 8.6.3、8.6.0、8.6.9、x86、x86_64等、各版を使って以前の手順を試してみたけど、どれも最後に似たようなエラーが出てダメだった。
ちなみに、sdx.kit を動かす tclkit.exe と、-runtime で指定する tclkit を別々のファイルにしたら、エラーは出なかったし、exe も生成できたし、出来上がった exe の実行もできた。
最後に sdx.bat wrap hoge.exe -runtime tclkit.exe と打ってexe化しようとしたけれど、ここでよく分からないエラーが出た。
file in use, cannot be prefix: D:/home/prg/tcl/tcl2exe/exetest02_863/tclkit.exe
SDX cannot continue (could not read link "D:/home/prg/tcl/tcl2exe/exetest02_863/sdx.kit": not a directory while executing "file readlink $mkflle")
tclkit 8.6.3、8.6.0、8.6.9、x86、x86_64等、各版を使って以前の手順を試してみたけど、どれも最後に似たようなエラーが出てダメだった。
ちなみに、sdx.kit を動かす tclkit.exe と、-runtime で指定する tclkit を別々のファイルにしたら、エラーは出なかったし、exe も生成できたし、出来上がった exe の実行もできた。
[ ツッコむ ]
2023/06/19(月) [n年前の日記]
#1 [python] PythonでFTP関係を処理したい
Python 3.10.10 で、FTP関係の処理をしたい。環境は Windows10 x64 22H2。
◎ Pythonで簡易FTPサーバを立てる :
Pythonを使って簡易FTPサーバを立てたい。pyftpdlib を使えばできるらしい。pip でインストール。
_1_ftpserver.py
python 1_ftpserver.py を実行すると、FTPサーバのIPアドレスは 127.0.0.1、ユーザ名は user、パスワードは password でFTP接続を受け付けるようになる。
pip install pyftpdlib
_1_ftpserver.py
import pyftpdlib.authorizers
import pyftpdlib.handlers
import pyftpdlib.servers
wwwdir = "D:\\home\\prg\\python\\_test_sample\\ftp\\www"
# 認証ユーザーを作る
authorizer = pyftpdlib.authorizers.DummyAuthorizer()
authorizer.add_user('user', 'password', wwwdir, perm='elradfmw')
# 個々の接続を管理するハンドラーを作る
handler = pyftpdlib.handlers.FTPHandler
handler.authorizer = authorizer
# FTPサーバーを立ち上げる
server = pyftpdlib.servers.FTPServer(("127.0.0.1", 21), handler)
server.serve_forever()
python 1_ftpserver.py を実行すると、FTPサーバのIPアドレスは 127.0.0.1、ユーザ名は user、パスワードは password でFTP接続を受け付けるようになる。
◎ PythonでFTPクライアント処理を行う :
Pythonを使って、FTPサーバに接続してファイルをアップロードしたい。ftplibを使えばできるらしい。このモジュールはおそらく標準で入ってる。たぶん。
_2_ftpclient.py
_b.png
_index.html.txt
python 2_ftpclient.py を実行すると、127.0.0.1 に、ユーザ名:user、パスワード:password でFTP接続して、ファイルを2つほどアップロードして終了する。
拡張子の種類によって、アスキーモードで転送するか、バイナリモードで転送するかの処理を分けている。
_2_ftpclient.py
import os
import ftplib
IP_ADDRESS = "127.0.0.1"
USER = "user"
PASSWORD = "password"
files = [
["D:\\home\\prg\\python\\_test_sample\\ftp\\src\\index.html", "/public_html/2_natsu"],
["D:\\home\\prg\\python\\_test_sample\\ftp\\src\\b.png", "/public_html/2_natsu"],
]
asciimode_ext = ["html", "htm", "css", "cgi", "pl", "py", "rb", "php", "js"]
try:
ftp = ftplib.FTP(IP_ADDRESS)
ftp.set_pasv('true')
ftp.login(USER, PASSWORD)
print("# FTP login (%s@%s)" % (USER, IP_ADDRESS))
print(ftp.getwelcome())
# get file list
print(ftp.nlst("."))
print(ftp.nlst("./public_html"))
for d in files:
src, dst = d
if not os.path.isfile(src):
print("Error : Not found %s" % src)
continue
ftp.cwd(dst)
fn = os.path.basename(src)
ext = os.path.splitext(src)[1][1:]
if ext in asciimode_ext:
print("Upload (Ascii) %s -> %s/%s" % (src, dst, fn))
# ftp.voidcmd('TYPE A')
with open(src, "rb") as f:
ftp.storlines("STOR %s" % fn, f)
else:
print("Upload (Binary) %s -> %s/%s" % (src, dst, fn))
# ftp.voidcmd('TYPE I')
with open(src, "rb") as f:
ftp.storbinary("STOR %s" % fn, f)
ftp.quit()
# ftp.close()
print("# FTP close.")
except ftplib.all_errors as e:
print('FTP Error :', e)
_b.png
{kind=link}
{kind=link}
_index.html.txt
python 2_ftpclient.py を実行すると、127.0.0.1 に、ユーザ名:user、パスワード:password でFTP接続して、ファイルを2つほどアップロードして終了する。
拡張子の種類によって、アスキーモードで転送するか、バイナリモードで転送するかの処理を分けている。
◎ 余談。WindowsのFTPツールを使って自動でアップロード :
Windows10 には標準で ftp.exe が入ってる。一般的には ftp.exe を実行して、コマンドを一つ一つ打ち込んで ―― という使い方が説明されてることが多いけれど、テキストファイルに一連のコマンドを列挙しておいて、そのテキストファイルを渡せば、一括で処理することができる。
以下は、前述の Pythonスクリプトでやっていたことを、ftpのコマンドで列挙した事例。
_ftp_cmd_list.txt
ftp -s:ファイル名、で実行。
以下は、前述の Pythonスクリプトでやっていたことを、ftpのコマンドで列挙した事例。
_ftp_cmd_list.txt
open 127.0.0.1 user password cd /public_html/2_natsu lcd src ascii put index.html binary put b.png quit
ftp -s:ファイル名、で実行。
ftp -s:ftp_cmd_list.txt
◎ 余談その2。アスキーモードについて :
ftp転送する際は、アスキーモードとバイナリモードの2つがあって、アスキーモードで転送すると改行コードが変化したりするのだけど…。今回、前述の Pythonスクリプトで動作確認してみたら、Windows10 + Pythonで立てた簡易FTPサーバに対してFTPでアップロードした場合、改行コードが変化しなくて悩んでしまった。Windows上で動かしてるから改行コードが変わらない状態が正解なのか、それとも簡易FTPサーバだからそこまで対応していないだけなのか…。
Ubuntu Linux 22.04 LTS がインストールされてるサブPCに、FTPサーバ vsftpd をインストールして動作確認してみたところ、前述の Pythonスクリプトでファイルをアップロードした場合でも、ちゃんと改行コードが変化してることが確認できた。とメモ。
Ubuntu Linux 22.04 LTS がインストールされてるサブPCに、FTPサーバ vsftpd をインストールして動作確認してみたところ、前述の Pythonスクリプトでファイルをアップロードした場合でも、ちゃんと改行コードが変化してることが確認できた。とメモ。
◎ 参考ページ :
_すぐ作ってすぐ壊せるFTPサーバーを立てる (Pythonで) - Qiita
_ftplibでFTPサーバをPythonで作る
_GitHub - giampaolo/pyftpdlib: Extremely fast and scalable Python FTP server library
_Tutorial - pyftpdlib 1.5.4 documentation
_ftplib --- FTPプロトコルクライアント - Python 3.11.4 ドキュメント
_PythonでFTPを使う方法 - Qiita
_[Python] PythonからFTPを実行する - YoheiM .NET
_Python ftplibでFTPサーバからダウンロード - fukuの犬小屋
_PythonでFTPクライアントを作成する
_python - FTP Upload--ASCII mode--a bytes-like object is required, not 'str' - Stack Overflow
_Windowsのftpコマンドをスクリプトで使う:Tech TIPS - @IT
_UbuntuでFTPサーバーを設定する
_UbuntuでFTPを使えるようにする | ばったんの技術系ブログ
_Ubuntu 20.04.4 LTS にFTPサーバを構築 - Qiita
_Ubuntu 22.04 LTS : Vsftpd : インストール : Server World
_【備忘録】vsftpdで”OOPS: vsftpd: refusing to run with writable root inside chroot()”が出た時の対処法 - 株式会社シーポイントラボ
_Linuxでテキストファイルの改行コードを調べる方法: 小粋空間
_ftplibでFTPサーバをPythonで作る
_GitHub - giampaolo/pyftpdlib: Extremely fast and scalable Python FTP server library
_Tutorial - pyftpdlib 1.5.4 documentation
_ftplib --- FTPプロトコルクライアント - Python 3.11.4 ドキュメント
_PythonでFTPを使う方法 - Qiita
_[Python] PythonからFTPを実行する - YoheiM .NET
_Python ftplibでFTPサーバからダウンロード - fukuの犬小屋
_PythonでFTPクライアントを作成する
_python - FTP Upload--ASCII mode--a bytes-like object is required, not 'str' - Stack Overflow
_Windowsのftpコマンドをスクリプトで使う:Tech TIPS - @IT
_UbuntuでFTPサーバーを設定する
_UbuntuでFTPを使えるようにする | ばったんの技術系ブログ
_Ubuntu 20.04.4 LTS にFTPサーバを構築 - Qiita
_Ubuntu 22.04 LTS : Vsftpd : インストール : Server World
_【備忘録】vsftpdで”OOPS: vsftpd: refusing to run with writable root inside chroot()”が出た時の対処法 - 株式会社シーポイントラボ
_Linuxでテキストファイルの改行コードを調べる方法: 小粋空間
[ ツッコむ ]
2023/06/20(火) [n年前の日記]
#1 [python] Pythonには__END__が無かった
Pythonで実験用のスクリプトを書いていた際に、スクリプトソースの最後のあたりにデータ行を書けないのかなと思えてきた。
◎ RubyやPerlならできる :
Ruby や Perl では、そういうことが ―― スクリプトソースの最後にデータを列挙することができる。
Ruby の場合、__END__ と書くと、そこから下はデータとして扱えて、DATA定数を使って取得することができる。
_Ruby の __END__ と DATA とは - Just do IT
_DATAと__END__でファイルオブジェクトを扱う | Ruby入門 - Worth Living
_[ Ruby ] DATA定数って何よ? [ 知ってる? ] - Qiita
Perl も似た感じで、__END__ 以降を <DATA> で取得することができる。
_ぺるりめも / DATAと__END__
_Perlでファイル内に書いた文字複数行を<DATA>で参照・ループする方法 - Qiita
_特殊ファイルハンドル DATA - ぱるも日記
Ruby の場合、__END__ と書くと、そこから下はデータとして扱えて、DATA定数を使って取得することができる。
_Ruby の __END__ と DATA とは - Just do IT
_DATAと__END__でファイルオブジェクトを扱う | Ruby入門 - Worth Living
_[ Ruby ] DATA定数って何よ? [ 知ってる? ] - Qiita
Perl も似た感じで、__END__ 以降を <DATA> で取得することができる。
_ぺるりめも / DATAと__END__
_Perlでファイル内に書いた文字複数行を<DATA>で参照・ループする方法 - Qiita
_特殊ファイルハンドル DATA - ぱるも日記
◎ Pythonはできない :
Ruby や Perl ではこういうことができるんだから、当然 Python にもあるんだろう。と思ってググってみたけど…。どうやら Python はそんな仕様を持ってないらしい…。
_Python, Ruby で簡単なテキスト処理 (1) - 特定の単語が含む行を抽出する | すぐに忘れる脳みそのためのメモ
_In Python what's the best way to emulate Perl's __END__? - Stack Overflow
「なんでそんなものが必要なんだ」とすら言われてるような…。Python の思想的に許せない何かがあるんだろうか。知らんけど。
考えてみれば、せっかくプログラム部分とデータ部分を分けた状態で作ってあっても、データ部分を変更したいだけなのにプログラムソースを書き換える羽目になるわけで、そこはデメリットかもしれないなと…。まあ、ちょっとしたスクリプトを配布する時に、プログラム部分とデータ部分の2つのファイルをわざわざ配布しなくて済む点はメリットなんだろうけど…。
さておき。Pythonも、自分で処理を書けば似たようなことができなくもないらしい。
_Pythonで__END__(もどき)を実現する - Qiita
_Python, Ruby で簡単なテキスト処理 (1) - 特定の単語が含む行を抽出する | すぐに忘れる脳みそのためのメモ
_In Python what's the best way to emulate Perl's __END__? - Stack Overflow
「なんでそんなものが必要なんだ」とすら言われてるような…。Python の思想的に許せない何かがあるんだろうか。知らんけど。
考えてみれば、せっかくプログラム部分とデータ部分を分けた状態で作ってあっても、データ部分を変更したいだけなのにプログラムソースを書き換える羽目になるわけで、そこはデメリットかもしれないなと…。まあ、ちょっとしたスクリプトを配布する時に、プログラム部分とデータ部分の2つのファイルをわざわざ配布しなくて済む点はメリットなんだろうけど…。
さておき。Pythonも、自分で処理を書けば似たようなことができなくもないらしい。
_Pythonで__END__(もどき)を実現する - Qiita
[ ツッコむ ]
2023/06/21(水) [n年前の日記]
#1 [pc] またブルースクリーン
メインPC、Windows10 x64 22H2機が、またブルースクリーン(BSOD)。普段はフツーに使えているのだけど…発生する条件が分からない…。
Ntfs.sys で問題が起きてると表示されてるから、SSDかHDDにアクセスしたタイミングでBSODになるのだろうけど…。どうも管理者権限が必要な何かをインストールするなり更新しようとする際に起きているのではないかという気も…。
BlueScreenView というツールを使ってBSODになった時に読み込まれいてた .sys を眺めてみたけど、何が何やら…。
Ntfs.sys で問題が起きてると表示されてるから、SSDかHDDにアクセスしたタイミングでBSODになるのだろうけど…。どうも管理者権限が必要な何かをインストールするなり更新しようとする際に起きているのではないかという気も…。
BlueScreenView というツールを使ってBSODになった時に読み込まれいてた .sys を眺めてみたけど、何が何やら…。
◎ メモリが足りてない気がする :
SSD内のファイルの断片化状態を見ると、pagefile.sys がいつのまにか断片化していたりする。これってメモリが足りてないのだろうか…。16GBじゃ足りないのか…。32GBぐらいにしないとダメかな。でも、ケースを開けて交換作業をするのも面倒臭い…。
[ ツッコむ ]
2023/06/22(木) [n年前の日記]
#1 [pc] Memtest86+ 6.20を入手
Memtest86+ 6.20 を入手して、USBメモリにインストールした、とメモ。
_Memtest86+ | The Open-Source Memory Testing Tool
Memtest86+ はメモリが壊れてないかチェックできるツール。今回は、1GBのUSBメモリにインストールした。
Windows機上で、USBメモリをUSBポートに差した状態で、セットアップファイル mt86plus_6.20_USB_Installer.exe を実行すると、どのドライブにインストールするか尋ねてくるので、USBメモリのドライブを指定すればインストールできる。
使う時は、USBメモリを差した状態でOSを再起動しつつ、OSが起動する前に Boot Menu を表示する何かしらのキーをポンポンポンと叩けば Boot Menu が表示されるので、そのメニューの中からUSBメモリを選択すればいい。
一応メインPCのメモリ(16GB)が壊れてないかチェックしてみた。1PASSは通ったから、明らかに壊れてるわけではなさそう。分かりやすく壊れてたら1PASSすら通らないし…。
1PASSすると、その旨がデカデカと表示される。「何かキーを押せばバナーが消えるよ」と英文で表示されていたのだけど、何かしらのキーを押しても消える気配が無く…。Ctrl + Alt + Delete で再起動はできたけど…。
_Memtest86+ | The Open-Source Memory Testing Tool
Memtest86+ はメモリが壊れてないかチェックできるツール。今回は、1GBのUSBメモリにインストールした。
Windows機上で、USBメモリをUSBポートに差した状態で、セットアップファイル mt86plus_6.20_USB_Installer.exe を実行すると、どのドライブにインストールするか尋ねてくるので、USBメモリのドライブを指定すればインストールできる。
使う時は、USBメモリを差した状態でOSを再起動しつつ、OSが起動する前に Boot Menu を表示する何かしらのキーをポンポンポンと叩けば Boot Menu が表示されるので、そのメニューの中からUSBメモリを選択すればいい。
一応メインPCのメモリ(16GB)が壊れてないかチェックしてみた。1PASSは通ったから、明らかに壊れてるわけではなさそう。分かりやすく壊れてたら1PASSすら通らないし…。
1PASSすると、その旨がデカデカと表示される。「何かキーを押せばバナーが消えるよ」と英文で表示されていたのだけど、何かしらのキーを押しても消える気配が無く…。Ctrl + Alt + Delete で再起動はできたけど…。
[ ツッコむ ]
2023/06/23(金) [n年前の日記]
#1 [nitijyou] HDD内を整理中
ふとなんとなく、某3Dゲームのシーンデータを整理しようと思い立ってしまった。おそらくはmodの入れすぎで壊れてしまったのであろう階段相当のマップオブジェクトをそれらしく見えるように修正しておこうかなと作業を始めたのだけど…。
繰り返し処理、あるいは、3Dモデルデータのリンク複製が欲しくなってきた。例えば、階段の一段分を基本図形の組み合わせで作成したら、それを位置をずらして並べて階段に見えるようにしたいわけで…。でも、件のゲームにそんな機能は無いから、コピペして位置をずらしていくしかない…。しかし、元になった部分を少し変更したいと思ったら、全部コピペし直さないといけない…。blenderの配列モディファイアやリンク複製の便利さを痛感…。
_[Blender] 配列モディファイアを応用してグリッドにしたり、円形やカーブに沿ってクローンする方法 | be CG Artist! (ビー・CGアーティスト!)- 3DCG制作、チュートリアルマガジンサイト
_【blender 2.8】オブジェクトを複製とリンク複製 | Tamago Design
いっそblenderでモデルを作ってインポートできたら楽なのだろうな…。ツール系ならそういう機能もアリだろうけど。いや、ツール系でも、追加モデルを商品として扱いたい場合その手のインポート機能は実装されないことが多いか…。そして、その手の制限を加えてしまったツール自体が不人気で売れなかったりする印象もあるなと。
繰り返し処理、あるいは、3Dモデルデータのリンク複製が欲しくなってきた。例えば、階段の一段分を基本図形の組み合わせで作成したら、それを位置をずらして並べて階段に見えるようにしたいわけで…。でも、件のゲームにそんな機能は無いから、コピペして位置をずらしていくしかない…。しかし、元になった部分を少し変更したいと思ったら、全部コピペし直さないといけない…。blenderの配列モディファイアやリンク複製の便利さを痛感…。
_[Blender] 配列モディファイアを応用してグリッドにしたり、円形やカーブに沿ってクローンする方法 | be CG Artist! (ビー・CGアーティスト!)- 3DCG制作、チュートリアルマガジンサイト
_【blender 2.8】オブジェクトを複製とリンク複製 | Tamago Design
いっそblenderでモデルを作ってインポートできたら楽なのだろうな…。ツール系ならそういう機能もアリだろうけど。いや、ツール系でも、追加モデルを商品として扱いたい場合その手のインポート機能は実装されないことが多いか…。そして、その手の制限を加えてしまったツール自体が不人気で売れなかったりする印象もあるなと。
[ ツッコむ ]
2023/06/24(土) [n年前の日記]
#1 [pc] テキストエディタ上で計算してみたかった
Windows10 x64 22H2上で動くテキストエディタ上で、123+456=、みたいな数式を書いて計算してみたくなった。履歴をざっと眺めて把握できそうだから便利になるのではないかと想像したのだけど…。
◎ xyzzyで試す :
xyzzy 0.2.2.253 上で、calc-mode (M-x calc) を使って少し作業してみたけど、これはどうもしっくりこない…。一応目的は果たせるのだけど、計算結果が次の行に表示されるあたりがどうも…。
ググっていたら、以下のページに遭遇。
_#xyzzy で その場で電卓計算してくれる - GitHub
calc-onthespot.l を導入することで、xyzzy上で書いてある数式の計算ができるらしい。が、xyzzy 0.2.2.253上で導入して試してみたら、「変数が定義されていません result-dsc」とエラーメッセージが表示されてしまった…。
ググっていたら、以下のページに遭遇。
_#xyzzy で その場で電卓計算してくれる - GitHub
calc-onthespot.l を導入することで、xyzzy上で書いてある数式の計算ができるらしい。が、xyzzy 0.2.2.253上で導入して試してみたら、「変数が定義されていません result-dsc」とエラーメッセージが表示されてしまった…。
◎ サクラエディタで試す :
サクラエディタ 2.4.2.6048上で、計算マクロ for サクラエディタ Ver.1.00 を試してみた。
_計算マクロ for サクラエディタの詳細情報 : Vector ソフトを探す!
sacal100.lzh を入手して解凍すると、中に calc.js と readme.txt が入っていた。
「123+456=」と打ってみて、「=」の後ろにカーソルがある状態で、Alt + K を叩いたら、計算結果が入力された。イイ感じ。
_計算マクロ for サクラエディタの詳細情報 : Vector ソフトを探す!
sacal100.lzh を入手して解凍すると、中に calc.js と readme.txt が入っていた。
- calc.js を、サクラエディタの macrosフォルダにコピー。
- サクラエディタの設定 → 共通設定 → マクロ。calc という名前で calc.js を登録。
- サクラエディタの設定 → 共通設定 → キー割り当て。種別を「外部マクロ」にして、calc を選んで、右側でキー割り当てをする。
「123+456=」と打ってみて、「=」の後ろにカーソルがある状態で、Alt + K を叩いたら、計算結果が入力された。イイ感じ。
◎ Notepad++で試す :
Notepad++ 8.5.4 32bit版でも、NppCalc というプラグインが導入されていれば、xyzzy の calc-mode のようなことができるっぽい。
_NppCalc / Wiki / Home
ツールバー上の電卓っぽいアイコンをクリックすれば Calcモード相当に切り替わるので、「123+456」と打って Enter を叩けば、次の行に計算結果が表示される。
ただ、「123+456=」といった感じに打ってみても計算結果は出てこない模様。
「x:=123+456」と打ち込むと、xという変数に値を代入できるようだなと…。「:=」が代入の記号らしい。
自分の環境では Ctrl + SHift + C でモードの切り替えができるのだけど、これはデフォルトのキー割り当てなのかどうか…。記憶が怪しい…。
膨大な数の関数をサポートしているっぽいなと…。度からラジアンに変換する DegToRad() や、三角関数の sin(), cos() もあった。
_NppCalc / Wiki / Home
ツールバー上の電卓っぽいアイコンをクリックすれば Calcモード相当に切り替わるので、「123+456」と打って Enter を叩けば、次の行に計算結果が表示される。
ただ、「123+456=」といった感じに打ってみても計算結果は出てこない模様。
「x:=123+456」と打ち込むと、xという変数に値を代入できるようだなと…。「:=」が代入の記号らしい。
自分の環境では Ctrl + SHift + C でモードの切り替えができるのだけど、これはデフォルトのキー割り当てなのかどうか…。記憶が怪しい…。
膨大な数の関数をサポートしているっぽいなと…。度からラジアンに変換する DegToRad() や、三角関数の sin(), cos() もあった。
◎ 余談。普段使ってる電卓アプリについて :
普段は Windows10 に標準で入ってる電卓(calc.exe) を使っているけれど、たまに SpeedCrunch 0.12 Portable を使ったりもしている。とメモ。
_SpeedCrunch
「a=123+456」といった感じで打ち込めば計算結果が変数に入って、次回の計算から「789+a」といった感じで利用できるので少し便利。
でも、考えてみたら、Ruby の irb や、Python の IDLE でも SpeedCrunch と似たようなことができそう…。
_SpeedCrunch
「a=123+456」といった感じで打ち込めば計算結果が変数に入って、次回の計算から「789+a」といった感じで利用できるので少し便利。
でも、考えてみたら、Ruby の irb や、Python の IDLE でも SpeedCrunch と似たようなことができそう…。
[ ツッコむ ]
2023/06/25(日) [n年前の日記]
#1 [anime] 「わが青春のアルカディア」を視聴
BS12で放送されていたので途中から視聴。キャプテンハーロックが主人公の劇場アニメ。以前BS12で放送されていた時にも視聴してるので、2回目の視聴。
1982年の作品らしいけど、なんだか気になってググってみたら、1980年前半は日本のSFアニメにとって激動の時代、だったような気がしてきた。
「宇宙戦艦ヤマト」から松本零士ブームが始まって、「銀河鉄道999」でピークになった感じ、なのかな? しかし、ちょうどその頃「ガンダム」が出現して…。ガンダムブームが盛り上がるその陰で、松本零士ブームは勢いが無くなって…。しかも、「わが青春の〜」と同じ年にマクロスのTV放映が始まってる。「ガンダム」「マクロス」を見てしまうと、もう松本零士先生のアレコレなんて「うわ古っ」って印象になるわな…。たった数年で、この変わり具合。早過ぎる…。
ひょっとすると、こういった流れにも、団塊Jrの人口数(?)が絡んでたりするのだろうか…? 団塊Jrの成長と歩調を合わせるように、ウケるSFアニメの内容も変化している…? 分らんけど。
1982年の作品らしいけど、なんだか気になってググってみたら、1980年前半は日本のSFアニメにとって激動の時代、だったような気がしてきた。
- 1977年08月: 「宇宙戦艦ヤマト (劇場版)」
- 1978年08月: 「さらば宇宙戦艦ヤマト 愛の戦士たち」
- 1979年04月: 「機動戦士ガンダム (TVアニメ版)」
- 1979年08月: 「銀河鉄道999 (The Galaxy Express 999)」
- 1981年03月: 「機動戦士ガンダム(劇場版第1作)」
- 1981年07月: 「機動戦士ガンダムII 哀・戦士編 (劇場版第2作)」
- 1981年08月: 「さよなら銀河鉄道999 アンドロメダ終着駅」
- 1981年03月: 「機動戦士ガンダムIII めぐりあい宇宙(そら)編 (劇場版第3作)」
- 1982年07月: 「わが青春のアルカディア」
- 1982年10月: 「超時空要塞マクロス (TVアニメ版)」
- 1984年07月: 「超時空要塞マクロス 愛・おぼえていますか (劇場版)」
「宇宙戦艦ヤマト」から松本零士ブームが始まって、「銀河鉄道999」でピークになった感じ、なのかな? しかし、ちょうどその頃「ガンダム」が出現して…。ガンダムブームが盛り上がるその陰で、松本零士ブームは勢いが無くなって…。しかも、「わが青春の〜」と同じ年にマクロスのTV放映が始まってる。「ガンダム」「マクロス」を見てしまうと、もう松本零士先生のアレコレなんて「うわ古っ」って印象になるわな…。たった数年で、この変わり具合。早過ぎる…。
ひょっとすると、こういった流れにも、団塊Jrの人口数(?)が絡んでたりするのだろうか…? 団塊Jrの成長と歩調を合わせるように、ウケるSFアニメの内容も変化している…? 分らんけど。
[ ツッコむ ]
2023/06/26(月) [n年前の日記]
#1 [anime] 勝間田具治監督関係の記事をググってた
昨日視聴した「わが青春のアルカディア」は、勝間田具治監督作品なのだけど。恥ずかしながらどういう監督さんなのか全然知らなかったので関連情報をググってた。
_勝間田具治 - Wikipedia
_勝間田 具治(アニメーション監督・演出家)【日本にフルCG アニメは根付くのか? 第4回/2012年6月号】|INTERVIEW インタビュー|EE.jp
_勝間田具治監督登場!『タイガーマスク』『マジンガーZ』・・ヒーローの誕生の影にこの男あり! | 東映[東映マイスター]
_映画黄金時代の京都太秦撮影所、そしてアニメの世界へ | 東映[東映マイスター]
_【異分子】との衝突(クラッシュ)がアニメーションを活性化する! | 東映[東映マイスター]
_“魂”は世代を超えて伝達する!〜『ヤマト』、そして『プリキュア』へ〜 | 東映[東映マイスター]
2012年頃のインタビュー記事が読めたのがありがたいなと…。「テンポより間が大事」「最近のアニメはテンポを優先し過ぎ」との発言に、なんだか納得。道理で、「わが青春の〜」を見ていて、失礼ながら「随分テンポが悪いな…眠くなる…」と感じてしまったわけで…。意図してそうしていたのだろうな…。
実写畑出身、かつ、自身は絵がほとんど描けないので、アニメーターの苦労が分からずに大変なコンテばかり描いてしまう、との発言にも納得。道理で、「わが青春の〜」でも、「やめて! アニメーターが死んじゃう!」と見てるこちらの顔が青ざめるカットが次々に出てきたわけで…。もっとも、その結果日本のアニメが紙芝居モドキから脱してダイナミックな見せ方も獲得できた、という面も絶対にあるよなと…。アニメーターにとって楽な見せ方ばかりしていたら、アニメの表現ってここまで何でもアリな状態にはなってないはず…。
宮崎駿監督のことを「宮ちゃん」と呼んでるらしいところも気になった。富野監督、高畑監督、大塚康生さん、押井監督等々、「宮さん」と呼んでる方々は見かけるけど、「宮ちゃん」と呼んでいた方も居たのね…。
_勝間田具治 - Wikipedia
_勝間田 具治(アニメーション監督・演出家)【日本にフルCG アニメは根付くのか? 第4回/2012年6月号】|INTERVIEW インタビュー|EE.jp
_勝間田具治監督登場!『タイガーマスク』『マジンガーZ』・・ヒーローの誕生の影にこの男あり! | 東映[東映マイスター]
_映画黄金時代の京都太秦撮影所、そしてアニメの世界へ | 東映[東映マイスター]
_【異分子】との衝突(クラッシュ)がアニメーションを活性化する! | 東映[東映マイスター]
_“魂”は世代を超えて伝達する!〜『ヤマト』、そして『プリキュア』へ〜 | 東映[東映マイスター]
- 元々は実写畑で助監督をされていた方。
- 東映動画のTVアニメ「狼少年ケン」(1964年)の頃からアニメ畑で演出として活躍。
- 「マジンガーZ」「グレートマジンガー」「グレンダイザー」等でも活躍。
- 宇宙戦艦ヤマトシリーズにもガッツリ参加。
- 「ハートキャッチプリキュア」にも参加してたらしい…。
2012年頃のインタビュー記事が読めたのがありがたいなと…。「テンポより間が大事」「最近のアニメはテンポを優先し過ぎ」との発言に、なんだか納得。道理で、「わが青春の〜」を見ていて、失礼ながら「随分テンポが悪いな…眠くなる…」と感じてしまったわけで…。意図してそうしていたのだろうな…。
実写畑出身、かつ、自身は絵がほとんど描けないので、アニメーターの苦労が分からずに大変なコンテばかり描いてしまう、との発言にも納得。道理で、「わが青春の〜」でも、「やめて! アニメーターが死んじゃう!」と見てるこちらの顔が青ざめるカットが次々に出てきたわけで…。もっとも、その結果日本のアニメが紙芝居モドキから脱してダイナミックな見せ方も獲得できた、という面も絶対にあるよなと…。アニメーターにとって楽な見せ方ばかりしていたら、アニメの表現ってここまで何でもアリな状態にはなってないはず…。
宮崎駿監督のことを「宮ちゃん」と呼んでるらしいところも気になった。富野監督、高畑監督、大塚康生さん、押井監督等々、「宮さん」と呼んでる方々は見かけるけど、「宮ちゃん」と呼んでいた方も居たのね…。
[ ツッコむ ]
2023/06/27(火) [n年前の日記]
#1 [anime] 「青春ブタ野郎はゆめみる少女の夢を見ない」を視聴
BS11で放送されていたので視聴。つい先日までBS11で再放送していた、小説を原作とするTVアニメ「青春ブタ野郎はバニーガール先輩の夢を見ない」の続きに相当する劇場版アニメ。ちなみに「青春ブタ野郎シリーズ」は、主人公の男子高校生の周辺で超常現象が次々に発生して、といった感じのお話で…。「化物語」から怪異の存在とバトルシーンを奇麗に抜いた感じ、とでも言えばいいのだろうか。あるいは藤子F先生のSF短編を今風に描写するとこうなる、みたいな感じというか…。
感想としては、実に面白かった。まさかここまで面白い作品だったとは…。TVアニメ版で描かれた各エピソードが伏線めいて絡んでくる流れに感心した。素晴らしい。
もっとも、映画単体で成立しない点は若干残念だった気もする。映画版だけを視聴しても何が何だか分らないはず。TVアニメ1クール分を見終わった直後、キャラ設定や各エピソードをまだちゃんと覚えている状態で、そのまま続けて見ないと面白く感じられない構成というか。シリーズのファン向け作品ではあるよなと…。
1クール+6話で構成してTVアニメとしてここまで流せば、アニメ版の評価が随分違ったかもしれないとも思えた。まあ、TVアニメがクール単位の制約を受けてる限り、そんな構成はできないのだろうけど…。将来、ネット配信が主流になって、TVと違って自由な話数でアニメを作れるようになったら、正当(?)な評価を受ける作品が増えるかもしれないなと…。
感想としては、実に面白かった。まさかここまで面白い作品だったとは…。TVアニメ版で描かれた各エピソードが伏線めいて絡んでくる流れに感心した。素晴らしい。
もっとも、映画単体で成立しない点は若干残念だった気もする。映画版だけを視聴しても何が何だか分らないはず。TVアニメ1クール分を見終わった直後、キャラ設定や各エピソードをまだちゃんと覚えている状態で、そのまま続けて見ないと面白く感じられない構成というか。シリーズのファン向け作品ではあるよなと…。
1クール+6話で構成してTVアニメとしてここまで流せば、アニメ版の評価が随分違ったかもしれないとも思えた。まあ、TVアニメがクール単位の制約を受けてる限り、そんな構成はできないのだろうけど…。将来、ネット配信が主流になって、TVと違って自由な話数でアニメを作れるようになったら、正当(?)な評価を受ける作品が増えるかもしれないなと…。
[ ツッコむ ]
2023/06/28(水) [n年前の日記]
#1 [nitijyou] 自宅サーバ止めてました
雷が鳴ったので、21:10-23:00の間、自宅サーバ止めてました。申し訳ないです。
[ ツッコむ ]
2023/06/29(木) [n年前の日記]
#1 [linux] Linuxのプリンタ印刷関係について調べてる
「Linux Mint 21.1機からプリンタ印刷できない」という相談が来たので、そのあたりを調べてるところ。対象のプリンタは EPSON EW-M660FT。無線LANで繋がってる複合機。
Linuxでプリンタ印刷ってどうやるんだっけ…。忘れた…。ということで、Linux Mint 21.1 がインストールされている手持ちのノートPC、Gateway M-2408j の電源を入れて、どのソフトでプリンタを管理するのか確認中。久々に電源を入れたものだから、インストールパッケージの更新だけで2時間ぐらい待たされた…。
Linux Mint の場合、システム設定(コントロールセンター) → プリンター、を選べば、プリンタ関係の管理ができるように見えた。もしくは、デスクトップ左下のスタートボタン相当をクリックして、検索欄で「printer」と打ち込んでも「プリンター」が表示される。
登録されているプリンタのアイコンを右クリックすれば、「プロパティ」や「印刷キューを表示」があるので、プリンタの基本設定や、印刷キューに何か溜まってないか確認することができる模様。印刷キューの一覧を表示したら、各ジョブを右クリックして、キャンセルしたり、削除したり、開放したりもできる。たぶん。
それとは別に、CUPS (Common Unix Printing System) の管理ページを開いてアレコレすることもできそうだなと…。Webブラウザで http://localhost:631/ を開けば、ここでも印刷ジョブの有無等を閲覧することができる。
それはともかく、相談を受けた Linux Mint機って、EPSON製プリンタのドライバをインストールしていたのだろうか…? 記憶が無い…。
Linuxでプリンタ印刷ってどうやるんだっけ…。忘れた…。ということで、Linux Mint 21.1 がインストールされている手持ちのノートPC、Gateway M-2408j の電源を入れて、どのソフトでプリンタを管理するのか確認中。久々に電源を入れたものだから、インストールパッケージの更新だけで2時間ぐらい待たされた…。
Linux Mint の場合、システム設定(コントロールセンター) → プリンター、を選べば、プリンタ関係の管理ができるように見えた。もしくは、デスクトップ左下のスタートボタン相当をクリックして、検索欄で「printer」と打ち込んでも「プリンター」が表示される。
登録されているプリンタのアイコンを右クリックすれば、「プロパティ」や「印刷キューを表示」があるので、プリンタの基本設定や、印刷キューに何か溜まってないか確認することができる模様。印刷キューの一覧を表示したら、各ジョブを右クリックして、キャンセルしたり、削除したり、開放したりもできる。たぶん。
それとは別に、CUPS (Common Unix Printing System) の管理ページを開いてアレコレすることもできそうだなと…。Webブラウザで http://localhost:631/ を開けば、ここでも印刷ジョブの有無等を閲覧することができる。
それはともかく、相談を受けた Linux Mint機って、EPSON製プリンタのドライバをインストールしていたのだろうか…? 記憶が無い…。
◎ EPSON製プリンタドライバのインストール :
ググってみた感じでは、Ubuntu や Linux Mint の場合、以下の手順で EPSON製プリンタ用ドライバのインストール作業が必要になるらしい。
_Ubuntuでも印刷したい - inamuu.com
_Ubuntu Mate 20.04.1 LTSで無線LANのプリンターを使おう | 与太郎のLinux道楽
_Linux Mintでプリンター設定のやり方(USB接続/ネットワーク接続) | 非IT企業に勤める中年サラリーマンのIT日記
_elementary OS に EPSON の複合機を設定してみた備忘録 | hyt adversaria
_第286回 UbuntuからEPSON複合機EP-805Aを使用する | gihyo.jp
EPSON製プリンタドライバは、以下から入手できるらしいのでメモ。
_EPSON Download Center
EPSON EW-M660FT の場合、Printer Driver として ESC/P-R Driver (generic driver)、Epson Printer Utility の2つと、Scanner Driver として All-in-one package というのがあるっぽいけど…。全部DLしてインストールしておけばいいのだろうか…。インストールの仕方は、sudo dpkg -i ./hoge.deb か、sudo apt install hoge.deb でイケそう。
必要なパッケージやドライバをインストールしておけば、Linux Mint のプリンター設定を開いて、プリンタの追加でネットワークプリンタに該当機種が表示されるらしいけど…。
ここまでメモして気づいたけど、同じLAN内にプリンタが無かったら、接続できないのではないか…? 例えば、1階と2階に別々のルータが置いてあって、それぞれ別のLANになってたら、2階のPCから1階のプリンタに印刷指示を出しても、そもそもプリンタが見つからないのでは…? それとも、昨今の複合機についているらしい、Wi-Fi Direct云々でどうにかなるものなんだろうか。ちょっとそのへん確認しておかないといけないな…。
- sudo apt install lsb
- EPSON製プリンタドライバ(.deb)をDLしてインストール。
- sudo apt install printer-driver-escpr
_Ubuntuでも印刷したい - inamuu.com
_Ubuntu Mate 20.04.1 LTSで無線LANのプリンターを使おう | 与太郎のLinux道楽
_Linux Mintでプリンター設定のやり方(USB接続/ネットワーク接続) | 非IT企業に勤める中年サラリーマンのIT日記
_elementary OS に EPSON の複合機を設定してみた備忘録 | hyt adversaria
_第286回 UbuntuからEPSON複合機EP-805Aを使用する | gihyo.jp
EPSON製プリンタドライバは、以下から入手できるらしいのでメモ。
_EPSON Download Center
EPSON EW-M660FT の場合、Printer Driver として ESC/P-R Driver (generic driver)、Epson Printer Utility の2つと、Scanner Driver として All-in-one package というのがあるっぽいけど…。全部DLしてインストールしておけばいいのだろうか…。インストールの仕方は、sudo dpkg -i ./hoge.deb か、sudo apt install hoge.deb でイケそう。
必要なパッケージやドライバをインストールしておけば、Linux Mint のプリンター設定を開いて、プリンタの追加でネットワークプリンタに該当機種が表示されるらしいけど…。
ここまでメモして気づいたけど、同じLAN内にプリンタが無かったら、接続できないのではないか…? 例えば、1階と2階に別々のルータが置いてあって、それぞれ別のLANになってたら、2階のPCから1階のプリンタに印刷指示を出しても、そもそもプリンタが見つからないのでは…? それとも、昨今の複合機についているらしい、Wi-Fi Direct云々でどうにかなるものなんだろうか。ちょっとそのへん確認しておかないといけないな…。
◎ 2023/06/30追記 :
「印刷できた」という連絡有り。「xxxx Series」と表示されてるプリンタではなく、別名のプリンタを選んだら印刷できたとのこと。ソレって、たしか自分も、Canon製複合機プリンタで試してた時に体験したなと…。「xxxx Series」と出てるほうを選んでも印刷できなかったはず。
それはともかく。先方のネットワーク構成は以前と変わってないそうで。それだとLANの島が2つあるからプリンタが見えないはずだけど、どうしてプリンタを検出/印刷できているのか…。もしかすると、複合機が持ってる Wi-Fi Direct が ―― 複合機が単体で印刷のみをサポートした簡易的な無線LANルータになる機能 ―― が絡んでるのだろうか。
それはともかく。先方のネットワーク構成は以前と変わってないそうで。それだとLANの島が2つあるからプリンタが見えないはずだけど、どうしてプリンタを検出/印刷できているのか…。もしかすると、複合機が持ってる Wi-Fi Direct が ―― 複合機が単体で印刷のみをサポートした簡易的な無線LANルータになる機能 ―― が絡んでるのだろうか。
◎ 2023/07/01追記 :
ググっていたら、最近の Ubuntu系 Linux はドライバレス印刷が可能になっていると知った。
_ドライバを入れずにプリンター利用「ドライバレス印刷」 - パソコン悪戦苦闘記録
_第472回 EPSON EP-879AWのドライバーレス印刷の不具合を報告する | gihyo.jp
おそらくこの機能が働いて印刷できたのではないかな…。これは便利そう…。
_ドライバを入れずにプリンター利用「ドライバレス印刷」 - パソコン悪戦苦闘記録
_第472回 EPSON EP-879AWのドライバーレス印刷の不具合を報告する | gihyo.jp
おそらくこの機能が働いて印刷できたのではないかな…。これは便利そう…。
[ ツッコむ ]
2023/06/30(金) [n年前の日記]
#1 [nitijyou] どうもふらふらする
昨日の夕方から、どうもふらふらする。いわゆるめまい、というヤツだろうか…。
昨日の夕方、犬の散歩をした時点では何も感じなかったけど。その後、買い物にでかけて、店の中で方向転換したときにふらつく感じがして、そこからずっとふらふらしてる状態。今朝、階下に降りようとして椅子から立ったらふらふらして、階段を1歩ずつゆっくり降りていく感じになった。また、夕方に犬の散歩をした時は、明らかに昨日の散歩の時とは違う感覚があった。
めまいの原因についてググったら、脳梗塞とか、くも膜下出血とか、怖い話が…。ただ、世界がぐるんぐるんと回ってるような状態ではないし、吐き気があるわけでもなく。歩けないほどふらふらしてるわけでもないし、家族と会話していてろれつが回らない状態というわけでもない。一体これは何だろう…。
昨日の夕方、犬の散歩をした時点では何も感じなかったけど。その後、買い物にでかけて、店の中で方向転換したときにふらつく感じがして、そこからずっとふらふらしてる状態。今朝、階下に降りようとして椅子から立ったらふらふらして、階段を1歩ずつゆっくり降りていく感じになった。また、夕方に犬の散歩をした時は、明らかに昨日の散歩の時とは違う感覚があった。
めまいの原因についてググったら、脳梗塞とか、くも膜下出血とか、怖い話が…。ただ、世界がぐるんぐるんと回ってるような状態ではないし、吐き気があるわけでもなく。歩けないほどふらふらしてるわけでもないし、家族と会話していてろれつが回らない状態というわけでもない。一体これは何だろう…。
[ ツッコむ ]
#2 [anime] 「機動戦士ガンダム 水星の魔女」23話を視聴
録画していたので視聴。スタッフロールを目にしてビックリ。原画の数がスゴイことになっていたけれど、有名なアニメーターさんがズラリと勢揃い。個人的には「このすば」のキャラデザ・総作監の方まで参加していたのが気になった。更にコンテが…。複数人でコンテを仕上げていたっぽいけど、麻宮騎亜さんまでコンテで参加していたとは…。いやまあ、麻宮騎亜さんは「境界戦機」にもコンテで参加してたからアレなんだけど。それにしても…総力戦って感じ…。
もちろん、有名アニメーターさんがごっそり参加してるだけあって、コレ本当にTVアニメですかと思う映像になっていて見応えがあったなと…。脚本というか展開的にも、 パスワード入力時のメッセージを後からコマ送りで確認してうるっときたし、 咄嗟の時にあのキャラがあのキャラをかばおうとするところでグッときたりで…。色んな面で面白い。素晴らしい。
もちろん、有名アニメーターさんがごっそり参加してるだけあって、コレ本当にTVアニメですかと思う映像になっていて見応えがあったなと…。脚本というか展開的にも、 パスワード入力時のメッセージを後からコマ送りで確認してうるっときたし、 咄嗟の時にあのキャラがあのキャラをかばおうとするところでグッときたりで…。色んな面で面白い。素晴らしい。
[ ツッコむ ]
以上、30 日分です。