2023/04/01(Хк) [nЧЏСАЄЮЦќЕ]
#1 [nitijyou] ЫПНъЄЫЙдЄУЄЦЄЄП
ХХЦАМЋХОМжЄЧЫПНъЄоЄЧЁЃ09:00-13:00КЂЄоЄЧЕяЄПЄБЄЩЁЂКюЖШМЋТЮЄЯ11:00КЂЄЫЄЯНЊЄяЄУЄЦЄПЕЄЄЌЄЙЄыЁЃОмКйЄЯGRPЄЧЅсЅтЁЃ
ИХЄЄPCЦтЄЮЅеЅЁЅЄЅыЄђПЗЄЗЄЄPCЄЋЄщЛВОШЄЧЄЄыЄшЄІЄЫКюЖШЁЃ
ИХЄЄPCЦтЄЮЅеЅЁЅЄЅыЄђПЗЄЗЄЄPCЄЋЄщЛВОШЄЧЄЄыЄшЄІЄЫКюЖШЁЃ
[ ЅФЅУЅГЄр ]
#2 [nitijyou] МЋХОМжЭбЅиЅыЅсЅУЅШЄЌИЋЄФЄЋЄщЄЪЄЄ
ЫПНъЄЋЄщЄЮЕЂЄъЄЫЁЂЅРЅЄЅцЁМЅЈЅЄЅШПмВьРюРОХЙЄШЁЂЅРЅЄЅцЁМЅЈЅЄЅШПмВьРюХьХЙЄЫДѓЄУЄЦЁЂТчПЭИўЄБЄЮМЋХОМжЭбЅиЅыЅсЅУЅШЄђУЕЄЗЄЦЄпЄПЄБЄЩЁЂЄЩЄСЄщЄтХЙЦЌЄЧЄЯЧфЄъРкЄьОѕТжЄРЄУЄПЁЃЅЅУЅКЭбЄЪЄщЛФЄУЄЦЄыЄЮЄРЄБЄЩЁФЁЃЄГЄЮФДЛвЄРЄШЄЗЄаЄщЄЏЄЯЦўМъЄЧЄЄЪЄЄЄРЄэЄІЄЪЁФЁЃКпИЫЄЌЩќГшЄЙЄыЄЮЄЯВПЛўЄЫЄЪЄыЄГЄШЄфЄщЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/02(Цќ) [nЧЏСАЄЮЦќЕ]
#1 [nitijyou] ФДЛвЄЌАЄЄ
КђЦќЄСЄчЄУЄШЬЕЭ§ЄђЄЗЄПЄЛЄЄЄЋЁЂЄШЄЫЄЋЄЏЬВЄЄЁФЁЃРИГшЅЕЅЄЅЏЅыЄЌЪјЄьЄПОѕТжЄЧЁЂОЏЄЗБѓЄЏЄЮЅлЁМЅрЅЛЅѓЅПЁМЄоЄЧМЋХОМжЄђСіЄщЄЛЄПЄЮЄЌЮЩЄЏЄЪЄЋЄУЄПЄЮЄЋЄтЁЃЄЙЄАЄЫЕЂТ№ЄЗЄЦАьЬВЄъЄЙЄьЄаАуЄУЄЦЄПЄЋЄЪЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/03(Зю) [nЧЏСАЄЮЦќЕ]
#1 [windows] Windows10ЄЧВЛРМЧЇМБЄђЄЗЄЦЄпЄПЄЋЄУЄПЄБЄЩЅРЅсЄРЄУЄП
ЄГЄГКЧЖсЁЂAndoridЅЙЅоЁМЅШЅеЅЉЅѓОхЄЧWebИЁКїЄЙЄыКнЁЂВЛРМЦўЮЯЄђЛШЄУЄЦИЁКїЅЁМЅяЁМЅЩЄђЦўЮЯЄЙЄыЄГЄШЄЌТПЄЏЄЦЁЂВЛРМЦўЮЯЄУЄЦЪиЭјЄРЄЪЄШЁЃЦБЄИЄГЄШЄђWindows PCОхЄЧЄтЄЧЄЄЪЄЄЄтЄЮЄЋЄЪЄШЛзЄЈЄЦЄЄПЄЮЄЧМТИГЁЃДФЖЄЯ Windows10 x64 22H2ЁЃ
АьБўЁЂPCЄЧЛШЄЈЄыЅиЅУЅЩЅЛЅУЅШЄЯЛ§ЄУЄЦЄЄЄыЄЮЄРЄБЄЩЁЂЄЄЄСЄЄЄСЦЌЄЫЄФЄБЄыЄЮЄЌЬЬХнНЄЄЁЃЄЂЄщЄЋЄИЄсPCЄЮСАЄЫЁЂЅоЅЄЅЏЅЙЅПЅѓЅЩЄђРпУжЄЗЄЦЄЊЄБЄаВїХЌЄЫЄЪЄъЄНЄІЄРЄЪЄШЁЂPCЭбЅГЅѓЅЧЅѓЅЕЅоЅЄЅЏ SONY ECM-PC50 ЄђШЏЗЁЄЗЄЦЛШЄУЄЦЄпЄПЁЃ
АьБўЁЂPCЄЧЛШЄЈЄыЅиЅУЅЩЅЛЅУЅШЄЯЛ§ЄУЄЦЄЄЄыЄЮЄРЄБЄЩЁЂЄЄЄСЄЄЄСЦЌЄЫЄФЄБЄыЄЮЄЌЬЬХнНЄЄЁЃЄЂЄщЄЋЄИЄсPCЄЮСАЄЫЁЂЅоЅЄЅЏЅЙЅПЅѓЅЩЄђРпУжЄЗЄЦЄЊЄБЄаВїХЌЄЫЄЪЄъЄНЄІЄРЄЪЄШЁЂPCЭбЅГЅѓЅЧЅѓЅЕЅоЅЄЅЏ SONY ECM-PC50 ЄђШЏЗЁЄЗЄЦЛШЄУЄЦЄпЄПЁЃ
Ё§ WebИЁКїЄЫЄФЄЄЄЦ :
ЄоЄКЁЂGoogleИЁКїЄЫДиЄЗЄЦЄЯЁЂGoogle Chrome + GoogleИЁКїЄЧВЛРМЦўЮЯЄЌВФЧНЄщЄЗЄЄЁЃЦўЮЯЭѓЄЮБІУМЄЫЅоЅЄЅЏЄЮЅЂЅЄЅГЅѓЄЌЄЂЄыЄЋЄщЁЂЄНЄьЄђЅЏЅъЅУЅЏЄЙЄьЄаВЛРМЦўЮЯЅтЁМЅЩЄЫЄЪЄУЄЦЄЏЄьЄыЄЗЁЂЄлЄмИэЧЇМБЄтЄЕЄьЄКЄЫВЛРМЧЇМБЄђЄЗЄЦЄЏЄьЄПЁЃ
ЄСЄЪЄпЄЫЁЂFirefox + GoogleИЁКїЄЧЄЯЁЂЅоЅЄЅЏЄЮЅЂЅЄЅГЅѓЄЌЩНМЈЄЕЄьЄЪЄЏЄЦЛШЄЈЄЪЄЋЄУЄПЁЃ
Microsoft Edge + BingИЁКїЄтЁЂВЛРМЦўЮЯЄЌВФЧНЄщЄЗЄЄЁЃЄГЄьЄтЄНЄГЄНЄГЅЄЅЄДЖЄИЄЫВЛРМЧЇМБЄЗЄЦЄЏЄьЄПЁЃ
ЄСЄЪЄпЄЫЁЂFirefox + GoogleИЁКїЄЧЄЯЁЂЅоЅЄЅЏЄЮЅЂЅЄЅГЅѓЄЌЩНМЈЄЕЄьЄЪЄЏЄЦЛШЄЈЄЪЄЋЄУЄПЁЃ
Microsoft Edge + BingИЁКїЄтЁЂВЛРМЦўЮЯЄЌВФЧНЄщЄЗЄЄЁЃЄГЄьЄтЄНЄГЄНЄГЅЄЅЄДЖЄИЄЫВЛРМЧЇМБЄЗЄЦЄЏЄьЄПЁЃ
Ё§ Windows10ЄЮВЛРМЧЇМБЄЯЙѓЄЋЄУЄП :
ФДЛвЄЫОшЄУЄЦЁЂWindows10 x64 22H2 ЄЮВЛРМЧЇМБЕЁЧНЄђЭјЭбЄЗЄЦЄпЄшЄІЄШЛзЄУЄПЄЮЄРЄБЄЩЁЂЄГЄьЄЌЄоЄЂЁЂЄЪЄЋЄЪЄЋЄЮЙѓЄЕЄЧЁФЁЃ
ЅГЅѓЅШЅэЁМЅыЅбЅЭЅы ЂЊ ЅГЅѓЅдЅхЁМЅПЄЮДЪУБСрКю ЂЊ ВЛРМЧЇМБЁЂЄђСЊЄйЄаЁЂВЛРМЧЇМБДиЗИЄЮЅЂЅьЅГЅьЄђИЦЄгНаЄЛЄыЄшЄІЄЫЄЪЄыЁЃЁжЅоЅЄЅЏЄЮЅЛЅУЅШЅЂЅУЅзЁзЄђСЊЄѓЄЧЅоЅЄЅЏЄЮЦАКюОѕТжЄђГЮЧЇЄЗЄЦЄЋЄщЁЂЁжЅГЅѓЅдЅхЁМЅПЁМЄђЅШЅьЁМЅЫЅѓЅАЄЗЄЦЧЇМБРЉХйЄђОхЄВЄыЁзЄђСЊЄѓЄЧЁЂЩНМЈЄЕЄьЄыЪИОЯЄђЦЩЄпОхЄВЄЦЄпЄПЄЮЄРЄБЄЩЁЂСДСГЧЇМБЄЕЄьЄЪЄЄЁФЁЃ
ЛШЄУЄЦЄыЅоЅЄЅЏЄЌЁЂЁжЅЧЅЙЅЏЅШЅУЅзЅоЅЄЅЏ(ДљЄЮОхЄЫУжЄЏЅПЅЄЅзЄЮЅоЅЄЅЏ)ЁзЄРЄЋЄщЄЄЄЋЄѓЄЮЄЋЄЪЄШЁЂЅиЅУЅЩЅЛЅУЅШЄђАњЄУФЅЄъНаЄЗЄЦЄЄПЄБЄьЄЩОѕЖЗЄЯВўСБЄЛЄКЁЃЁжВЛРМЧЇМБЄЮГЋЛЯЁзЄђСЊЄѓЄЧЁЂЅЂЅьЅГЅьУ§ЄУЄЦЄпЄПЄБЄьЄЩЁЂЄоЄКЧЇМБЄЕЄьЄЪЄЄЄЗЁЂВПЄЋЄЌЧЇМБЄЕЄьЄЦЄтЦмФСДСЄЪШПБўЄђЄЙЄыЁЃИэЧЇМБЄЗЄоЄЏЄъЄЪЄѓЄРЄэЄІЄЪЁФЁЃ
ЅАЅАЄУЄЦЄпЄПЄщЁЂWindows10ЄЮВЛРМЧЇМБЄЯЄоЄШЄтЄЫЛШЄЈЄЪЄЄЅьЅйЅыЁЂЄШЄЄЄІЄЮЄЌАьШЬХЊЄЪЩОЄщЄЗЄЄЁЃЄПЄЗЄЋЄЫЁЂЄГЄьЄЧЄЯЄЪЄЂЁФЁЃ
ЄСЄЪЄпЄЫЁЂWindows10 ЄЧЄЯЄЪЄЏЁЂWindows11 ЄЯЁЂКђКЃЄЮAIБОЁЙЄЮРЎВЬЄђШПБЧЄЕЄЛЄЦЄЄЄыЄЮЄЋЁЂЗыЙНВўСБЄЕЄьЄЦЄЄЄыЄШЄЮЯУЄтИЋЄЋЄБЄПЁЃЄНЄІЄЄЄІЩєЪЌЄЧЄЯЮЩЄЏЄЪЄУЄЦЄЄЄыЄЮЄЋЁФЁЃ
ЅГЅѓЅШЅэЁМЅыЅбЅЭЅы ЂЊ ЅГЅѓЅдЅхЁМЅПЄЮДЪУБСрКю ЂЊ ВЛРМЧЇМБЁЂЄђСЊЄйЄаЁЂВЛРМЧЇМБДиЗИЄЮЅЂЅьЅГЅьЄђИЦЄгНаЄЛЄыЄшЄІЄЫЄЪЄыЁЃЁжЅоЅЄЅЏЄЮЅЛЅУЅШЅЂЅУЅзЁзЄђСЊЄѓЄЧЅоЅЄЅЏЄЮЦАКюОѕТжЄђГЮЧЇЄЗЄЦЄЋЄщЁЂЁжЅГЅѓЅдЅхЁМЅПЁМЄђЅШЅьЁМЅЫЅѓЅАЄЗЄЦЧЇМБРЉХйЄђОхЄВЄыЁзЄђСЊЄѓЄЧЁЂЩНМЈЄЕЄьЄыЪИОЯЄђЦЩЄпОхЄВЄЦЄпЄПЄЮЄРЄБЄЩЁЂСДСГЧЇМБЄЕЄьЄЪЄЄЁФЁЃ
ЛШЄУЄЦЄыЅоЅЄЅЏЄЌЁЂЁжЅЧЅЙЅЏЅШЅУЅзЅоЅЄЅЏ(ДљЄЮОхЄЫУжЄЏЅПЅЄЅзЄЮЅоЅЄЅЏ)ЁзЄРЄЋЄщЄЄЄЋЄѓЄЮЄЋЄЪЄШЁЂЅиЅУЅЩЅЛЅУЅШЄђАњЄУФЅЄъНаЄЗЄЦЄЄПЄБЄьЄЩОѕЖЗЄЯВўСБЄЛЄКЁЃЁжВЛРМЧЇМБЄЮГЋЛЯЁзЄђСЊЄѓЄЧЁЂЅЂЅьЅГЅьУ§ЄУЄЦЄпЄПЄБЄьЄЩЁЂЄоЄКЧЇМБЄЕЄьЄЪЄЄЄЗЁЂВПЄЋЄЌЧЇМБЄЕЄьЄЦЄтЦмФСДСЄЪШПБўЄђЄЙЄыЁЃИэЧЇМБЄЗЄоЄЏЄъЄЪЄѓЄРЄэЄІЄЪЁФЁЃ
ЅАЅАЄУЄЦЄпЄПЄщЁЂWindows10ЄЮВЛРМЧЇМБЄЯЄоЄШЄтЄЫЛШЄЈЄЪЄЄЅьЅйЅыЁЂЄШЄЄЄІЄЮЄЌАьШЬХЊЄЪЩОЄщЄЗЄЄЁЃЄПЄЗЄЋЄЫЁЂЄГЄьЄЧЄЯЄЪЄЂЁФЁЃ
ЄСЄЪЄпЄЫЁЂWindows10 ЄЧЄЯЄЪЄЏЁЂWindows11 ЄЯЁЂКђКЃЄЮAIБОЁЙЄЮРЎВЬЄђШПБЧЄЕЄЛЄЦЄЄЄыЄЮЄЋЁЂЗыЙНВўСБЄЕЄьЄЦЄЄЄыЄШЄЮЯУЄтИЋЄЋЄБЄПЁЃЄНЄІЄЄЄІЩєЪЌЄЧЄЯЮЩЄЏЄЪЄУЄЦЄЄЄыЄЮЄЋЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/04(Ва) [nЧЏСАЄЮЦќЕ]
#1 [linux] rangerЄЮВшСќЅзЅьЅгЅхЁМЩНМЈЄЫЄФЄЄЄЦЦАКюГЮЧЇ
Ubuntu Linux Єф Debian Linux ОхЄЧЁЂranger ЄШЄЄЄІЁЂCUIЄЧСрКюЄЧЄЄыЅеЅЁЅЄЅщЁМЄђЛШЄУЄЦЄЄЄыЁЃ
_CLI ЄЧ Linux ЅеЅЁЅЄЅыЅоЅЭЁМЅИЅу ranger ЄђЛШЄІЄГЄШЄЮЅсЅт | Jenemal Notes
_ЅПЁМЅпЅЪЅыЗПЅеЅЁЅЄЅыЅоЅЭЁМЅИЅуЁМranger [ЅЄЅѓЅеЅщЅЈЅѓЅИЅЫЅЂЄЮPCДФЖ]
_ranger - ArchWiki
_ЅПЁМЅпЅЪЅыЄЧЛШЄЈЄыЅеЅЁЅЄЅщrangerЄђЛШЄУЄЦЄпЄы - Qiita
ЄГЄЮ ranger ЄЯЁЂАЪВМЄЮКюЖШЄђЄЙЄьЄаВшСќЅзЅьЅгЅхЁМЩНМЈЄЌЄЧЄЄыЁЃ
ЦАКюГЮЧЇДФЖЄЯЁЂUbuntu Linux 20.04 LTS + xubuntu-desktopЁЃ
ЦАЄЋЄЪЄЄДФЖЄЌЁЂАеГАЄЫТПЄЋЄУЄПЁФЁЃ
ЦАЄЋЄЪЄЄЭ§ЭГЄЯЁЂАЪВМЄЮЄфЄъЄШЄъЄЧНёЄЋЄьЄЦЄЄЄПЁЃДФЖЪбПє WINDOWID ЄЌЭэЄѓЄЧЄЄЄЦЁЂw3m-img ЄЫТаБўЄЕЄЛЄыЄЮЄЯЦёЄЗЄЄЄщЄЗЄЄЁЃ
_Images in w3m on lilyterm. / Newbie Corner / Arch Linux Forums
_FrameBuffer images in w3m - Issue #61 - Tetralet/LilyTerm - GitHub
_Guake does not display images when w3m-img is installed - Issue #1806 - Guake/guake - GitHub
_CLI ЄЧ Linux ЅеЅЁЅЄЅыЅоЅЭЁМЅИЅу ranger ЄђЛШЄІЄГЄШЄЮЅсЅт | Jenemal Notes
_ЅПЁМЅпЅЪЅыЗПЅеЅЁЅЄЅыЅоЅЭЁМЅИЅуЁМranger [ЅЄЅѓЅеЅщЅЈЅѓЅИЅЫЅЂЄЮPCДФЖ]
_ranger - ArchWiki
_ЅПЁМЅпЅЪЅыЄЧЛШЄЈЄыЅеЅЁЅЄЅщrangerЄђЛШЄУЄЦЄпЄы - Qiita
ЄГЄЮ ranger ЄЯЁЂАЪВМЄЮКюЖШЄђЄЙЄьЄаВшСќЅзЅьЅгЅхЁМЩНМЈЄЌЄЧЄЄыЁЃ
- w3m-img ЄђЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЊЄЏЁЃ
- РпФъЅеЅЁЅЄЅы ~/.config/ranger/rc.conf ЦтЄЮЁжset preview_images falseЁзЄђЁжset preview_images trueЁзЄЫЪбЙЙЁЃ
ЦАКюГЮЧЇДФЖЄЯЁЂUbuntu Linux 20.04 LTS + xubuntu-desktopЁЃ
| termnal emurator | result | version |
|---|---|---|
| xfce4-terminal | work | 0.8.9.1-1 |
| rxvt-unicode (urxvt) | work | 9.22-6build3 |
| xterm | work | 353-1ubuntu1.20.04.2 |
| sakura | work | 3.7.0-1 |
| roxterm | work | 3.12.1-1ppa1focal1 |
| gnome-terminal | not work | 3.36.2-1ubuntu1~20.04 |
| lxterminal | not work | 0.3.2-1 |
| lilyterm | not work | 0.9.9.4+git20150208.f600c0-5 |
| terminator | not work | 1.91-4ubuntu1 |
| tilda | not work | 1.5.2-0ubuntu1 |
ЦАЄЋЄЪЄЄДФЖЄЌЁЂАеГАЄЫТПЄЋЄУЄПЁФЁЃ
ЦАЄЋЄЪЄЄЭ§ЭГЄЯЁЂАЪВМЄЮЄфЄъЄШЄъЄЧНёЄЋЄьЄЦЄЄЄПЁЃДФЖЪбПє WINDOWID ЄЌЭэЄѓЄЧЄЄЄЦЁЂw3m-img ЄЫТаБўЄЕЄЛЄыЄЮЄЯЦёЄЗЄЄЄщЄЗЄЄЁЃ
_Images in w3m on lilyterm. / Newbie Corner / Arch Linux Forums
_FrameBuffer images in w3m - Issue #61 - Tetralet/LilyTerm - GitHub
_Guake does not display images when w3m-img is installed - Issue #1806 - Guake/guake - GitHub
Ё§ ROXTermЄЫЄФЄЄЄЦ :
ROXTerm ЄЯЁЂDebian Linux Єф Ubuntu Linux ОхЄЧИјМАЅбЅУЅБЁМЅИЄЌЭбАеЄЕЄьЄЦЄЪЄЄЁЃ
_ROXTerm
_Has roxterm been removed from Debian 9 (stretch)? - Unix & Linux Stack Exchange
_Roxterm PPA : Tony Houghton
Ubuntu ЄЮОьЙчЁЂPPA ЄШЄфЄщЄђЭјЭбЄЙЄьЄаЅбЅУЅБЁМЅИЄЮЦўМъЄЌЄЧЄЄЪЄЏЄтЄЪЄЄЄщЄЗЄЄЁЃUbuntu Linux 20.04 LTS ЄЧЄЯЦАКюЄЗЄЦЄЏЄьЄПЁЃ
DebianОхЄЧЅЄЅѓЅЙЅШЁМЅыЄЙЄыЪ§ЫЁЄЯЩдЬРЁЃЅАЅАЄУЄЦЄтО№ЪѓЄЌНаЄЦЄГЄЪЄЋЄУЄПЁЃ
- Ubuntu 16.04 LTS ЄЮКЂЄЯЄЂЄУЄПЄБЄЩЁЂ18.04 LTS АЪЙпЄЧЄЯЅбЅУЅБЁМЅИЄЌЬЕЄЏЄЪЄУЄПЁЃ
- Debian Linux ЄтЁЂwheezy (Debian 7)ЁЂjessie (Debian 8) ЄЮКЂЄЯЄЂЄУЄПЄБЄЩЁЂstretch (Debian 9) ЄЮКЂЄЫЬЕЄЏЄЪЄУЄЦЄЗЄоЄУЄПЁЃ
_ROXTerm
_Has roxterm been removed from Debian 9 (stretch)? - Unix & Linux Stack Exchange
_Roxterm PPA : Tony Houghton
Ubuntu ЄЮОьЙчЁЂPPA ЄШЄфЄщЄђЭјЭбЄЙЄьЄаЅбЅУЅБЁМЅИЄЮЦўМъЄЌЄЧЄЄЪЄЏЄтЄЪЄЄЄщЄЗЄЄЁЃUbuntu Linux 20.04 LTS ЄЧЄЯЦАКюЄЗЄЦЄЏЄьЄПЁЃ
sudo add-apt-repository ppa:h-realh/roxterm sudo apt update sudo apt install roxterm roxterm
DebianОхЄЧЅЄЅѓЅЙЅШЁМЅыЄЙЄыЪ§ЫЁЄЯЩдЬРЁЃЅАЅАЄУЄЦЄтО№ЪѓЄЌНаЄЦЄГЄЪЄЋЄУЄПЁЃ
Ё§ ЭОУЬЁЃРпФъЅРЅЄЅЂЅэЅАЄЮНФЩ§ФЙВсЄЎЬфТъ :
МЋЪЌЄЮМъИЕЄЫЄЯБеОНВшЬЬЄЮВђСќХйЄЌ 1024x600 ЄЮЅЭЅУЅШЅжЅУЅЏЕЁЄЌЄЂЄыЄЮЄРЄБЄЩЁЂЄГЄЮВшЬЬВђСќХйЄЧЁЂЅПЁМЅпЅЪЅыЅЈЅпЅхЅьЁМЅПЄЮРпФъВшЬЬЄђГЋЄЏЄШЁЂЄЩЄьЄтЅРЅЄЅЂЅэЅАЄЮНФЩ§ЄЌЄЂЄъВсЄЎЄЦЁЂРпФъВшЬЬЄЮВМЄЮЄлЄІЄЌСрКюЄЧЄЄЪЄЏЄЦКЄЄУЄЦЄЗЄоЄІЁЃЄЩЄІЄЗЄЦЄЩЄьЄтЄГЄьЄтЄНЄѓЄЪЄЫНФЩ§ЄђФЙЄЏЄЗЄЦЄЗЄоЄІЄЮЄЋЁФЁЃВЃЪ§ИўЄЫПЄгЄЦЄЏЄьЄыЪЌЄЫЄЯЬфТъЬЕЄЄЄЮЄЫЁФЁЃ
[ ЅФЅУЅГЄр ]
#2 [linux][debian] xrandrЄЧВОСлХЊЄЪВшЬЬВђСќХйЄђЪбЙЙ
МъЛ§ЄСЄЮЅЭЅУЅШЅжЅУЅЏЕЁЁЂLenovo IdeaPad S10-2 ЄЧЁЂDebian Linux 11 bullseye i686 + LXDE ЄђЦАЄЋЄЗЄЦЄЄЄыЄБЄьЄЩЁЂБеОНВшЬЬЄЮВђСќХйЄЌ 1024x600 ЄЪЄЮЄЧЁЂЅЂЅзЅъЄЫЄшЄУЄЦЄЯВшЬЬЦтЄЫРпФъЅРЅЄЅЂЅэЅАХљЄЌМ§ЄоЄщЄЪЄЏЄЦЁЂЄСЄчЄУЄШКЄЄУЄЦЄЗЄоЄІЛўЄЌЄЂЄыЁЃ
ВПЄЋМъЄЯЬЕЄЄЄтЄЮЄЋЄШЅАЅАЄУЄЦЄЄЄПЄщЁЂxrandr ЄђЛШЄУЄЦВшЬЬЄЮГШТчНЬОЎЮЈЄђРпФъЄЧЄЄыЄШУЮЄУЄПЁЃЄГЄьЄђЛШЄЈЄаВђЗшЄЙЄыЄЮЄЧЄЯЁФЁЉ
_xrandr ЅЊЅзЅЗЅчЅѓЁЁ--scale - Monkey's hobby
_xrandr | ВКЄфЄЋЄЪЦќЁЙ
xrandr ЄШТЧЄУЄЦЁЂИНКпЄЮВшЬЬРпФъЄђГЮЧЇЁЃ
АЪВМЄЮЄшЄІЄЫТЧЄУЄПЄШЄГЄэЁЂВОСл(?)ЄЮВшЬЬВђСќХйЄђЁЂМТКнЄЮЅЧЅЃЅЙЅзЅьЅЄЄЫГШТчНЬОЎЄЗЄЦЩНМЈЄЗЄЦЄЏЄьЄПЁЃСЧРВЄщЄЗЄЄЁЃ
ИЕЄЫЬсЄЙЛўЄЯАЪВМЁЃ
ЩбШЫЄЫЛШЄІЄЋЄтЄЗЄьЄЪЄЄЄЮЄЧЁЂalias ЄЫХаЯПЄЗЄЦЄЊЄЄЄПЁЃscaling ЄтЄЗЄЏЄЯ resetscale ЄЧЁЂЄГЄЮЄЂЄПЄъЄђЪбЙЙЄЧЄЄыЄшЄІЄЫЄЪЄыЁЃ
ВПЄЋМъЄЯЬЕЄЄЄтЄЮЄЋЄШЅАЅАЄУЄЦЄЄЄПЄщЁЂxrandr ЄђЛШЄУЄЦВшЬЬЄЮГШТчНЬОЎЮЈЄђРпФъЄЧЄЄыЄШУЮЄУЄПЁЃЄГЄьЄђЛШЄЈЄаВђЗшЄЙЄыЄЮЄЧЄЯЁФЁЉ
_xrandr ЅЊЅзЅЗЅчЅѓЁЁ--scale - Monkey's hobby
_xrandr | ВКЄфЄЋЄЪЦќЁЙ
xrandr ЄШТЧЄУЄЦЁЂИНКпЄЮВшЬЬРпФъЄђГЮЧЇЁЃ
$ xrandr Screen 0: minimum 8 x 8, current 1024 x 600, maximum 32767 x 32767 LVDS1 connected primary 1024x600+0+0 (normal left inverted right x axis y axis) 220mm x 130mm 1024x600 59.97*+ 1024x576 59.90 59.82 960x540 59.63 59.82 800x600 60.32 56.25 864x486 59.92 59.57 640x480 59.94 720x405 59.51 58.99 640x360 59.84 59.32 512x300 60.00 VGA1 disconnected (normal left inverted right x axis y axis) VIRTUAL1 disconnected (normal left inverted right x axis y axis)ЄГЄЮДФЖЄЧЄЯЁЂxrandr ЄЮ output ЄЫ LVDS1 ЄШЄфЄщЄђЛиФъЄЙЄьЄаЄЄЄЄЄЮЄРЄэЄІЁЃ
АЪВМЄЮЄшЄІЄЫТЧЄУЄПЄШЄГЄэЁЂВОСл(?)ЄЮВшЬЬВђСќХйЄђЁЂМТКнЄЮЅЧЅЃЅЙЅзЅьЅЄЄЫГШТчНЬОЎЄЗЄЦЩНМЈЄЗЄЦЄЏЄьЄПЁЃСЧРВЄщЄЗЄЄЁЃ
xrandr --output LVDS1 --scale 1.28x1.28ВОСлЄЮВшЬЬВђСќХйЄЯЁЂ1311x768ЄЫЄЪЄУЄЦЄЄЄыЁЃЪИЛњЄтАьБўЄЪЄѓЄШЄЋЦЩЄсЄНЄІЄЪАѕОнЁЃ
ИЕЄЫЬсЄЙЛўЄЯАЪВМЁЃ
xrandr --output LVDS1 --scale 1x1
ЩбШЫЄЫЛШЄІЄЋЄтЄЗЄьЄЪЄЄЄЮЄЧЁЂalias ЄЫХаЯПЄЗЄЦЄЊЄЄЄПЁЃscaling ЄтЄЗЄЏЄЯ resetscale ЄЧЁЂЄГЄЮЄЂЄПЄъЄђЪбЙЙЄЧЄЄыЄшЄІЄЫЄЪЄыЁЃ
vi ~/.bash_aliases
alias scaling='xrandr --output LVDS1 --scale 1.28x1.28' alias resetscale='xrandr --output LVDS1 --scale 1x1'
Ё§ 1024x600ЄЮНФВЃШцЄЌЄшЄЏЄяЄЋЄщЄЪЄЄ :
1024x600ЄЮНФВЃШцЄУЄЦЁЂ16:9ЁЂ16:10ЁЂЄЩЄСЄщЄЫЖсЄЄЄЮЄРЄэЄІЁФЁЉ
1024x600 ЄРЄШЁЂ128:75 ЄЮЄшЄІЄРЄЪЁФЁЃ
128:75 = 16:9.375ЁЂЄРЄШЄЙЄыЄШЁЂ16:10 ЄшЄъ 16:9 ЄЫОЏЄЗЄРЄБЖсЄЄЄЮЄРЄэЄІЄЋЁЃ
1024x600 ЄРЄШЁЂ128:75 ЄЮЄшЄІЄРЄЪЁФЁЃ
- 1920/1080 = 1.77778
- 1024/600 = 1.70667
- 1920/1200 = 1.6
128:75 = 16:9.375ЁЂЄРЄШЄЙЄыЄШЁЂ16:10 ЄшЄъ 16:9 ЄЫОЏЄЗЄРЄБЖсЄЄЄЮЄРЄэЄІЄЋЁЃ
Ё§ Alt+КИЅЩЅщЅУЅАЄтЛШЄЈЄНЄІ :
1024x600ЄЮВшЬЬВђСќХйЄРЄШЁЂLXTerminal ЄЮРпФъВшЬЬ/РпФъЅРЅЄЅЂЅэЅАЄЙЄщВшЬЬЄЋЄщЄЯЄпНаЄЗЄЦЄЗЄоЄІЁЃ
РпФъЅРЅЄЅЂЅэЅАЄЮВМЄЮЄлЄІЄЧЁЂAlt+КИЅЩЅщЅУЅАЄђЄЗЄЦЁЂЅРЅЄЅЂЅэЅАСДТЮЄђОхЄЮЄлЄІЄЫАмЦАЄЗЄЦЄпЄПЄШЄГЄэЁЂВМЄЮЄлЄІЄђЩНМЈЄЙЄыЄГЄШЄЌЄЧЄЄПЁЃЄтЄСЄэЄѓОхЄЮЄлЄІЄЯБЃЄьЄЦЄЗЄоЄІЄБЄЩЁЂЄШЄъЄЂЄЈЄКЅГЅьЄЧЄЩЄІЄЫЄЋЄЙЄыЄЮЄтЅЂЅъЄРЄЪЄШЁФЁЃ
РпФъЅРЅЄЅЂЅэЅАЄЮВМЄЮЄлЄІЄЧЁЂAlt+КИЅЩЅщЅУЅАЄђЄЗЄЦЁЂЅРЅЄЅЂЅэЅАСДТЮЄђОхЄЮЄлЄІЄЫАмЦАЄЗЄЦЄпЄПЄШЄГЄэЁЂВМЄЮЄлЄІЄђЩНМЈЄЙЄыЄГЄШЄЌЄЧЄЄПЁЃЄтЄСЄэЄѓОхЄЮЄлЄІЄЯБЃЄьЄЦЄЗЄоЄІЄБЄЩЁЂЄШЄъЄЂЄЈЄКЅГЅьЄЧЄЩЄІЄЫЄЋЄЙЄыЄЮЄтЅЂЅъЄРЄЪЄШЁФЁЃ
[ ЅФЅУЅГЄр ]
#3 [linux][debian] sakuraЅПЁМЅпЅЪЅыЄђЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄП
ЅАЅАЄУЄЦЄПЄщЁЂsakura ЄШЄЄЄІЅПЁМЅпЅЪЅыЅЈЅпЅхЅьЁМЅПЄЌЗкЄЏЄЦЄЄЄЄЄщЄЗЄЄЄШУЮЄъЁЂЛюЭбЄЗЄЦЄпЄыЄГЄШЄЫЄЗЄПЁЃ
Lenovo IdeaPad S10-2 + Debian Linux 11 bullseye i686 ОхЄЧЅЄЅѓЅЙЅШЁМЅыЁЃ
ВшЬЬЄђБІЅЏЅъЅУЅЏЄЙЄыЄШРпФъЅсЅЫЅхЁМЄНЄЮТОЄЌГЋЄЏЁЃЄГЄьЄЪЄщРпФъЅРЅЄЅЂЅэЅАЄЌВшЬЬЄђЄЯЄпНаЄЗЄЦЄЗЄоЄУЄЦСрКюЄЧЄЄЪЄЄЄШЄЄЄІЄГЄШЄЯЄЪЄЕЄНЄІЁЃ
ЗкЄЄТхЄяЄъЄЫФуЕЁЧНЄШЄЮЄГЄШЄщЄЗЄЄЄБЄЩЁЂЅПЅжЕЁЧНЄЯЄФЄЄЄЦЄЄЄыЄЗЁЂЄГЄьЄЧННЪЌЄЪОьЬЬЄтТПЄНЄІЄРЄЪЄШЁФЁЃ
Lenovo IdeaPad S10-2 + Debian Linux 11 bullseye i686 ОхЄЧЅЄЅѓЅЙЅШЁМЅыЁЃ
sudo apt install sakura
ВшЬЬЄђБІЅЏЅъЅУЅЏЄЙЄыЄШРпФъЅсЅЫЅхЁМЄНЄЮТОЄЌГЋЄЏЁЃЄГЄьЄЪЄщРпФъЅРЅЄЅЂЅэЅАЄЌВшЬЬЄђЄЯЄпНаЄЗЄЦЄЗЄоЄУЄЦСрКюЄЧЄЄЪЄЄЄШЄЄЄІЄГЄШЄЯЄЪЄЕЄНЄІЁЃ
ЗкЄЄТхЄяЄъЄЫФуЕЁЧНЄШЄЮЄГЄШЄщЄЗЄЄЄБЄЩЁЂЅПЅжЕЁЧНЄЯЄФЄЄЄЦЄЄЄыЄЗЁЂЄГЄьЄЧННЪЌЄЪОьЬЬЄтТПЄНЄІЄРЄЪЄШЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/05(Пх) [nЧЏСАЄЮЦќЕ]
#1 [linux][ubuntu] kittyЅПЁМЅпЅЪЅыЅЈЅпЅхЅьЁМЅПЄђЛюЭб
ВОСлУМЫі/ЅПЁМЅпЅЪЅыЅЈЅпЅхЅьЁМЅПЄЫЄФЄЄЄЦЅАЅАЄУЄЦЄЄЄПЄщЁЂkitty ЄШЄЄЄІЅПЁМЅпЅЪЅыЅЈЅпЅхЅьЁМЅПЄЌЕЄЄЫЄЪЄУЄЦЄЄПЁЃ
_AlacrittyЄЋЄщkittyЄЫАмЙдЄЗЄЦЄЄЄы - ЄжЄЦЄЄЄЮЅэЅАЄЧЄжЅэЅА
_ЙтТЎЄЧЕЁЧНХЊЄЪGPUЅйЁМЅЙЄЮЅПЁМЅпЅЪЅыЅЈЅпЅхЅьЁМЅПЁМkittyЄђЛШЄУЄЦЄпЄы
_GPUЅйЁМЅЙЄЮЅПЁМЅпЅЪЅыЅНЅеЅШKittyЄЮЛШЄЄЪ§
GPUЄђРбЖЫХЊЄЫЛШЄУЄЦЩСВшЄЌЙтТЎЄЫЄЪЄУЄЦЄыЅНЅеЅШЄщЄЗЄЄЁЃЛюЭбЄЗЄЦЄпЄПЄЄЁЃ
ДФЖЄЯ Ubuntu Linux 20.04LTSЁЃapt ЄЧЅЄЅѓЅЙЅШЁМЅыЄЧЄЄыЁЃ
ЕЏЦАЄЗЄПФОИхЁЂЪИЛњЩНМЈЄЌЄЊЄЋЄЗЄЪИЋЄПЬмЄЫЄЪЄУЄЦЄЗЄоЄУЄЦКЄЄУЄПЁЃЄГЄЮЅНЅеЅШЁЂЭјЭбЄЧЄЄыЅеЅЉЅѓЅШМяЮрЄЌЁЂЄЋЄЪЄъИТЄщЄьЄыЄщЄЗЄЄЁФЁЃЩсУЪЛШЄУЄЦЄыIPAЅДЅЗЅУЅЏЄфHackGenЄЯЁЂВЃЪ§ИўЄЫДжБфЄгЄЗЄЦЄЗЄоЄУЄЦЅРЅсЄРЄУЄПЁЃUbuntu Mono ЄЪЄщЩНМЈЄЌЄоЄШЄтЄЫЄЪЄУЄПЁЃ
Ctrl + Shift + F2 ЄђУЁЄЏЄШЪЬЅІЅЄЅѓЅЩЅІЄЧРпФъЅеЅЁЅЄЅыЄЮПїЗСЄЌЩНМЈЄЕЄьЄыЄЮЄЧЁЂЄНЄГЄЋЄщРпФъЄђЅЋЅЙЅПЅоЅЄЅКЄЗЄЦЄЄЄЏЄШЄЄЄЄЄщЄЗЄЄЁЃ~/.config/kitty/kitty.conf ЄЌРпФъЅеЅЁЅЄЅыЁЃЄШЄъЄЂЄЈЄКЁЂЯЎЄУЄПЄШЄГЄэЄРЄБЅсЅтЁЃ
АьШЬХЊЄЪЅПЁМЅпЅЪЅыЅЈЅпЅхЅьЁМЅПЄЯЁЂShift + (PageUp|PageDown) ХљЄЧЅЙЅЏЅэЁМЅыЄЧЄЄПЕЄЄЌЄЙЄыЄБЄЩЁЂЄГЄЮ kitty ЄЧЄНЄІЄЄЄІЅЁМЄђУЁЄЏЄШЦцЄЮЪИЛњЄЌЩНМЈЄЕЄьЄЦЄЗЄоЄІЁЃCtrl + Shift + (Up|Down|PageUp|PageDown) ЄЪЄщЅЙЅЏЅэЁМЅыЄЙЄыЄЮЄЋЄЪЁФЁЃЄПЄжЄѓЁЃ
ranger + w3m-img ЄЧВшСќЅзЅьЅгЅхЁМЄЯЄЧЄЄПЄБЄЩЁЂВшСќЄЌЧиЗЪЄЮЦЉВсЮЈЄђАњЄЗбЄЄЄЧЄЗЄоЄІЄУЄнЄЄЁЃ
_AlacrittyЄЋЄщkittyЄЫАмЙдЄЗЄЦЄЄЄы - ЄжЄЦЄЄЄЮЅэЅАЄЧЄжЅэЅА
_ЙтТЎЄЧЕЁЧНХЊЄЪGPUЅйЁМЅЙЄЮЅПЁМЅпЅЪЅыЅЈЅпЅхЅьЁМЅПЁМkittyЄђЛШЄУЄЦЄпЄы
_GPUЅйЁМЅЙЄЮЅПЁМЅпЅЪЅыЅНЅеЅШKittyЄЮЛШЄЄЪ§
GPUЄђРбЖЫХЊЄЫЛШЄУЄЦЩСВшЄЌЙтТЎЄЫЄЪЄУЄЦЄыЅНЅеЅШЄщЄЗЄЄЁЃЛюЭбЄЗЄЦЄпЄПЄЄЁЃ
ДФЖЄЯ Ubuntu Linux 20.04LTSЁЃapt ЄЧЅЄЅѓЅЙЅШЁМЅыЄЧЄЄыЁЃ
sudo apt install kittykitty 0.15.0-1ubuntu0.2 ЄЌЅЄЅѓЅЙЅШЁМЅыЄЕЄьЄПЁЃ
ЕЏЦАЄЗЄПФОИхЁЂЪИЛњЩНМЈЄЌЄЊЄЋЄЗЄЪИЋЄПЬмЄЫЄЪЄУЄЦЄЗЄоЄУЄЦКЄЄУЄПЁЃЄГЄЮЅНЅеЅШЁЂЭјЭбЄЧЄЄыЅеЅЉЅѓЅШМяЮрЄЌЁЂЄЋЄЪЄъИТЄщЄьЄыЄщЄЗЄЄЁФЁЃЩсУЪЛШЄУЄЦЄыIPAЅДЅЗЅУЅЏЄфHackGenЄЯЁЂВЃЪ§ИўЄЫДжБфЄгЄЗЄЦЄЗЄоЄУЄЦЅРЅсЄРЄУЄПЁЃUbuntu Mono ЄЪЄщЩНМЈЄЌЄоЄШЄтЄЫЄЪЄУЄПЁЃ
Ctrl + Shift + F2 ЄђУЁЄЏЄШЪЬЅІЅЄЅѓЅЩЅІЄЧРпФъЅеЅЁЅЄЅыЄЮПїЗСЄЌЩНМЈЄЕЄьЄыЄЮЄЧЁЂЄНЄГЄЋЄщРпФъЄђЅЋЅЙЅПЅоЅЄЅКЄЗЄЦЄЄЄЏЄШЄЄЄЄЄщЄЗЄЄЁЃ~/.config/kitty/kitty.conf ЄЌРпФъЅеЅЁЅЄЅыЁЃЄШЄъЄЂЄЈЄКЁЂЯЎЄУЄПЄШЄГЄэЄРЄБЅсЅтЁЃ
font_family ubuntu mono bold_font auto italic_font auto bold_italic_font auto font_size 16.0 scrollback_lines 65536 copy_on_select yes remember_window_size yes background_opacity 0.8 dynamic_background_opacity yes
АьШЬХЊЄЪЅПЁМЅпЅЪЅыЅЈЅпЅхЅьЁМЅПЄЯЁЂShift + (PageUp|PageDown) ХљЄЧЅЙЅЏЅэЁМЅыЄЧЄЄПЕЄЄЌЄЙЄыЄБЄЩЁЂЄГЄЮ kitty ЄЧЄНЄІЄЄЄІЅЁМЄђУЁЄЏЄШЦцЄЮЪИЛњЄЌЩНМЈЄЕЄьЄЦЄЗЄоЄІЁЃCtrl + Shift + (Up|Down|PageUp|PageDown) ЄЪЄщЅЙЅЏЅэЁМЅыЄЙЄыЄЮЄЋЄЪЁФЁЃЄПЄжЄѓЁЃ
ranger + w3m-img ЄЧВшСќЅзЅьЅгЅхЁМЄЯЄЧЄЄПЄБЄЩЁЂВшСќЄЌЧиЗЪЄЮЦЉВсЮЈЄђАњЄЗбЄЄЄЧЄЗЄоЄІЄУЄнЄЄЁЃ
[ ЅФЅУЅГЄр ]
#2 [anime] ЁжЅЩЅЅхЅсЅѓЅШЁжЅЗЅѓЁІВОЬЬЅщЅЄЅРЁМЁзЅвЁМЅэЁМЅЂЅЏЅЗЅчЅѓФЉРяЄЮЩёТцЮЂЁзЄђЛыФА
NHK BSЅзЅьЅпЅЂЅрЄЧЪќСїЄЕЄьЄЦЄПЅНЅьЄђЯПВшЄЗЄЦЄЄЄПЄЮЄЧЛыФАЁЃЁжЅЗЅѓЁІВОЬЬЅщЅЄЅРЁМЁзЄЮЛЃБЦИНОьЄЯЄГЄѓЄЪДЖЄИЄЧЄЗЄПЄШОвВ№ЄЗЄЦЄЏЄьЄыШжСШЁЂЄШЄЄЄІРтЬРЄЧЄЄЄЄЄЮЄРЄэЄІЄЋЁЃ
ЬЬЧђЄЋЄУЄПЁЃЄЄЄфЁЂЅГЅьЄђЬЬЧђЄЋЄУЄПЄШИРЄУЄЦЄЗЄоЄУЄЦЄЄЄЄЄЮЄЋЄЩЄІЄЋЄСЄчЄУЄШЧКЄрЄБЄЩЁФЁЃЄЕЄЙЄЌАУЬюДЦЦФЄРЄМЁЂИНОьЄЮЖѕЕЄЄЌЄпЄыЄпЄыХУЄѓЄЧЄЄЄЏЄМЁЂДќТдЄђЮЂРкЄщЄЪЄЄДЦЦФЄЕЄѓЄРЄЪЄЂЁЂЄпЄПЄЄЄЪЁЃ
ЛІПиЄЌЛІЄЗЙчЄЄЄЫИЋЄЈЄЪЄЄЄШЄЄЄІЄЂЄПЄъЄЯЁЂЄЪЄыЄлЄЩЄПЄЗЄЋЄЫЄШЛзЄУЄЦЄЗЄоЄУЄПЄъЄтЄЗЄЦЁЃЅЭЅУЅШЄЧУЏЄЋЄЌИРЄУЄЦЄПЄБЄЩЁЂКЧЖсЄЮЅНЅьЄЯЛІПиЄШИРЄІЄшЄъЅРЅѓЅЙЄЫИЋЄЈЄыЁЂЄпЄПЄЄЄЪЄШЄГЄэЄЯЄЂЄыЄшЄЪЁФЁЃЄФЄоЄъЄЯЁЂЅЂЅЏЅЗЅчЅѓЄЋЄщЛІЕЄЄЌДЖЄИЄщЄьЄЪЄЄЄШЄЄЄІЄГЄШЄЪЄЮЄРЄэЄІЄЋЁЃСЧПЭЙЭЄЈЄЧЛзЄУЄПЄБЄьЄЩЁЂЅЂЅЏЅЗЅчЅѓЛЃБЦУцЄЫЁжЅщЅЄЅРЁМЁЂЛрЄЭЄфЄЂЁЊЁзЁжЛІЄЙЛІЄЙЛІЄЙЁЂЄжЄУЛІЅЉЅЙЁЊЁзЁжЄІЄУЄЛЄЈЁЊ ЅАЅСЅуЅАЅСЅуЄЫЄЗЄЦЄфЄыЁЊЁзЁжЭшЄЄЄшЅЊЅщЅЁЁЊ ЄЋЄЋЄУЄЦЄГЄЄЄфЄЂЁЊЁзЄШГЦПЭЙЅЄЄЪЄшЄІЄЫХмЬФЄщЄЛЄЪЄЌЄщЅЂЅЏЅЗЅчЅѓЄЕЄЛЄЦЄпЄПЄщЄСЄчЄУЄШЄЯЪбЄяЄУЄПЄъЄЗЄЪЄЄЄЋЄЪЄШЁФЁЃЅЂЅЏЅЗЅчЅѓЅЗЁМЅѓЄЮВЛРМЄЯИхЄЋЄщЅЂЅеЅьЅГЄЧЦўЄьФОЄЙЄЮЄРЄэЄІЄЋЄщВПЄђЖЋЄѓЄЧЄтЬфТъЬЕЄЄЄРЄэЄІЄЗЁЃЄЧЄтЄПЄжЄѓЁЂЄНЄьЄЧЄтЅтЅЫЅПЗаЭГЄЧБЧСќИЋЄПЄщЁжАуЄІЄѓЄРЄшЄЪЄЂЁФЁзЄШЄЪЄъЄНЄІЄЪЭНДЖЁЃРИЄЧЬмЄЫЄЙЄыЅНЅьЄШЁЂЅтЅЫЅПВшЬЬЄЫБЧЄЗНаЄЕЄьЄПЅНЅьЄЯЁЂХСЄяЄУЄЦЄЏЄыЄтЄЮЄЌЄЪЄѓЄЋАуЄІЄЗЁФЁЃЄШЄЄЄІЄЋАУЬюДЦЦФЄЮЄГЄШЄРЄЋЄщЁЂЁжЅЗЅчЅУЅЋЁМРяЦЎАїЄЯЁиЅЄЁМЅУЁйЄЗЄЋИРЄЄЄоЄЛЄѓЁЃЁиЛрЄЭЁйЄРЄЮЁиЛІЄЙЁйЄРЄЮИРЄЄНаЄЙЄЮЄЯЫмЪЊЄИЄуЄЪЄЄЄЧЄЙЁзЄШЄЋИРЄяЄьЄСЄуЄІЄЋЄЪЁФЁЃ
ЄНЄьЄЯЄШЄтЄЋЄЏЁЃЅЙЅПЅУЅеЄЋЄщЅЂЅЄЅЧЅЂЄђНаЄЕЄЛЄЦЁЂЄНЄьЄђЪвЄУУМЄЋЄщШнФъЄЗЄЦЫзЄЫЄЗЄЦЄЄЄЏЄфЄъЪ§ЄРЄШЁЂЅЙЅПЅУЅеЄЮЅтЅСЅйЄЯОхЄЌЄщЄЪЄЄЄРЄэЄІЄЪЄШЁФЁЃЄШЄЯИРЄЈДЦЦФЄЕЄѓЄЮУцЄЧЄЯЁжАуЄІЁЃЅГЅьЅИЅуЅЪЅЄЁзЄШЄЪЄУЄСЄуЄУЄЦЄыЄЋЄщФЬЄЙЄяЄБЄЫЄтЄЄЄЋЄЪЄЄЄЗЁЃЅЙЅПЅУЅеЄЮЅтЅСЅйЄђАнЛ§ЄЗЄФЄФЁЂДЦЦФЄЫЄШЄУЄЦЄЮРЕВђЄЫЖсЄХЄБЄЦЄЄЄЏОхМъЄЄЪ§ЫЁЄЯЄЪЄЄЄтЄЮЄРЄэЄІЄЋЁЃЄЂЄыЄяЄБЄЪЄЄЄЋЁЃ
togetterЄЧШжСШЄЮДЖСлЄђФЏЄсЄЦЄпЄПЄщЁЂЄГЄЮШжСШЄЧОвВ№ЄЗЄЦЄПЄлЄШЄѓЄЩЄЮЅЋЅУЅШЄЌЫмЪдЄЧЄЯЫзЄРЄУЄПЄНЄІЄЧЁФЁЃЄЂЄѓЄЪЄЫЖьЯЋЄЗЄЦЛЃБЦЄЗЄПЄЮЄЫЅЋЅУЅШЄЕЄьЄСЄуЄІЄШЄЋЁЂЅФЅщЄЄЁФЁЃ
МчЬђЄЮЪ§ЄЌЁжЅйЅЙЅШЄЯЄЩЄьЄЪЄѓЄРЁФЁзЄШвьЄЄЄЦЄПЄБЄЩЁЂЄФЄЏЄХЄЏЁЂИфГкКюЩЪЄЮРЉКюЄУЄЦТчЪбЄРЄЪЄШЁФЁЃ
ЬЬЧђЄЋЄУЄПЁЃЄЄЄфЁЂЅГЅьЄђЬЬЧђЄЋЄУЄПЄШИРЄУЄЦЄЗЄоЄУЄЦЄЄЄЄЄЮЄЋЄЩЄІЄЋЄСЄчЄУЄШЧКЄрЄБЄЩЁФЁЃЄЕЄЙЄЌАУЬюДЦЦФЄРЄМЁЂИНОьЄЮЖѕЕЄЄЌЄпЄыЄпЄыХУЄѓЄЧЄЄЄЏЄМЁЂДќТдЄђЮЂРкЄщЄЪЄЄДЦЦФЄЕЄѓЄРЄЪЄЂЁЂЄпЄПЄЄЄЪЁЃ
ЛІПиЄЌЛІЄЗЙчЄЄЄЫИЋЄЈЄЪЄЄЄШЄЄЄІЄЂЄПЄъЄЯЁЂЄЪЄыЄлЄЩЄПЄЗЄЋЄЫЄШЛзЄУЄЦЄЗЄоЄУЄПЄъЄтЄЗЄЦЁЃЅЭЅУЅШЄЧУЏЄЋЄЌИРЄУЄЦЄПЄБЄЩЁЂКЧЖсЄЮЅНЅьЄЯЛІПиЄШИРЄІЄшЄъЅРЅѓЅЙЄЫИЋЄЈЄыЁЂЄпЄПЄЄЄЪЄШЄГЄэЄЯЄЂЄыЄшЄЪЁФЁЃЄФЄоЄъЄЯЁЂЅЂЅЏЅЗЅчЅѓЄЋЄщЛІЕЄЄЌДЖЄИЄщЄьЄЪЄЄЄШЄЄЄІЄГЄШЄЪЄЮЄРЄэЄІЄЋЁЃСЧПЭЙЭЄЈЄЧЛзЄУЄПЄБЄьЄЩЁЂЅЂЅЏЅЗЅчЅѓЛЃБЦУцЄЫЁжЅщЅЄЅРЁМЁЂЛрЄЭЄфЄЂЁЊЁзЁжЛІЄЙЛІЄЙЛІЄЙЁЂЄжЄУЛІЅЉЅЙЁЊЁзЁжЄІЄУЄЛЄЈЁЊ ЅАЅСЅуЅАЅСЅуЄЫЄЗЄЦЄфЄыЁЊЁзЁжЭшЄЄЄшЅЊЅщЅЁЁЊ ЄЋЄЋЄУЄЦЄГЄЄЄфЄЂЁЊЁзЄШГЦПЭЙЅЄЄЪЄшЄІЄЫХмЬФЄщЄЛЄЪЄЌЄщЅЂЅЏЅЗЅчЅѓЄЕЄЛЄЦЄпЄПЄщЄСЄчЄУЄШЄЯЪбЄяЄУЄПЄъЄЗЄЪЄЄЄЋЄЪЄШЁФЁЃЅЂЅЏЅЗЅчЅѓЅЗЁМЅѓЄЮВЛРМЄЯИхЄЋЄщЅЂЅеЅьЅГЄЧЦўЄьФОЄЙЄЮЄРЄэЄІЄЋЄщВПЄђЖЋЄѓЄЧЄтЬфТъЬЕЄЄЄРЄэЄІЄЗЁЃЄЧЄтЄПЄжЄѓЁЂЄНЄьЄЧЄтЅтЅЫЅПЗаЭГЄЧБЧСќИЋЄПЄщЁжАуЄІЄѓЄРЄшЄЪЄЂЁФЁзЄШЄЪЄъЄНЄІЄЪЭНДЖЁЃРИЄЧЬмЄЫЄЙЄыЅНЅьЄШЁЂЅтЅЫЅПВшЬЬЄЫБЧЄЗНаЄЕЄьЄПЅНЅьЄЯЁЂХСЄяЄУЄЦЄЏЄыЄтЄЮЄЌЄЪЄѓЄЋАуЄІЄЗЁФЁЃЄШЄЄЄІЄЋАУЬюДЦЦФЄЮЄГЄШЄРЄЋЄщЁЂЁжЅЗЅчЅУЅЋЁМРяЦЎАїЄЯЁиЅЄЁМЅУЁйЄЗЄЋИРЄЄЄоЄЛЄѓЁЃЁиЛрЄЭЁйЄРЄЮЁиЛІЄЙЁйЄРЄЮИРЄЄНаЄЙЄЮЄЯЫмЪЊЄИЄуЄЪЄЄЄЧЄЙЁзЄШЄЋИРЄяЄьЄСЄуЄІЄЋЄЪЁФЁЃ
ЄНЄьЄЯЄШЄтЄЋЄЏЁЃЅЙЅПЅУЅеЄЋЄщЅЂЅЄЅЧЅЂЄђНаЄЕЄЛЄЦЁЂЄНЄьЄђЪвЄУУМЄЋЄщШнФъЄЗЄЦЫзЄЫЄЗЄЦЄЄЄЏЄфЄъЪ§ЄРЄШЁЂЅЙЅПЅУЅеЄЮЅтЅСЅйЄЯОхЄЌЄщЄЪЄЄЄРЄэЄІЄЪЄШЁФЁЃЄШЄЯИРЄЈДЦЦФЄЕЄѓЄЮУцЄЧЄЯЁжАуЄІЁЃЅГЅьЅИЅуЅЪЅЄЁзЄШЄЪЄУЄСЄуЄУЄЦЄыЄЋЄщФЬЄЙЄяЄБЄЫЄтЄЄЄЋЄЪЄЄЄЗЁЃЅЙЅПЅУЅеЄЮЅтЅСЅйЄђАнЛ§ЄЗЄФЄФЁЂДЦЦФЄЫЄШЄУЄЦЄЮРЕВђЄЫЖсЄХЄБЄЦЄЄЄЏОхМъЄЄЪ§ЫЁЄЯЄЪЄЄЄтЄЮЄРЄэЄІЄЋЁЃЄЂЄыЄяЄБЄЪЄЄЄЋЁЃ
togetterЄЧШжСШЄЮДЖСлЄђФЏЄсЄЦЄпЄПЄщЁЂЄГЄЮШжСШЄЧОвВ№ЄЗЄЦЄПЄлЄШЄѓЄЩЄЮЅЋЅУЅШЄЌЫмЪдЄЧЄЯЫзЄРЄУЄПЄНЄІЄЧЁФЁЃЄЂЄѓЄЪЄЫЖьЯЋЄЗЄЦЛЃБЦЄЗЄПЄЮЄЫЅЋЅУЅШЄЕЄьЄСЄуЄІЄШЄЋЁЂЅФЅщЄЄЁФЁЃ
МчЬђЄЮЪ§ЄЌЁжЅйЅЙЅШЄЯЄЩЄьЄЪЄѓЄРЁФЁзЄШвьЄЄЄЦЄПЄБЄЩЁЂЄФЄЏЄХЄЏЁЂИфГкКюЩЪЄЮРЉКюЄУЄЦТчЪбЄРЄЪЄШЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/06(Ьк) [nЧЏСАЄЮЦќЕ]
#1 [pc] ЅпЅЫPCЄЫЄФЄЄЄЦФДЄйЄЦЄП
ЄПЄоЄПЄоWebОхЄЧЁЂМъЄЮЄвЄщЅЕЅЄЅКЄЮЅпЅЫPCЄЮЙЙ№ЄђЬмЄЫЄЗЄЦЄЗЄоЄУЄЦЁЂЁжЄГЄЮЄЏЄщЄЄЄЮЅЕЅЄЅКЄЮPCЄЫЁЂLinuxЄђЦўЄьЄЦЦАЄЋЄЛЄПЄщЁФЁзЄЪЄЩЄШЬбСлЄЗЄЦЄЗЄоЄУЄЦЁЂЄФЄЄЄФЄЄДиЯЂО№ЪѓЄђЅАЅАЄъЛЯЄсЄЦЄЗЄоЄУЄПЁЃ
Celeron J4125 Єф Celeron N5105 ХљЄЌКмЄУЄЦЄыЅпЅЫPCЄЌЮЩЄЕЄНЄІЄЧЄЯЄЂЄыЄЪЄШЁФЁЃAtomЗЯЄЮCPUЄщЄЗЄЄЄБЄЩЁЂТчРЮЄЮЅЮЁМЅШPCЄЫКмЄУЄЦЄП ОЪХХЮЯЅПЅЄЅзЄЮ Core i3 Єф i5 ЄШЦБХљЄЮНшЭ§ЧНЮЯЄЯЄЂЄыЄщЄЗЄЄЄЗЁЃКЃЄЮЅпЅЫPCЄЯSSDЄђРбЄѓЄЧЄыЄЋЄщЁЂЄНЄГЄНЄГВїХЌЄЫЛШЄЈЄНЄІЄЧЄтЄЂЄыЁЃВПЄшЄъЁЂОУШёХХЮЯЄЌАЕХнХЊЄЫОЏЄЪЄЄЄЗЁЂЄЊУЭУЪЄтАТЄЄЁЃОЎЄЕЄЄЄЋЄщЁЂОьЙчЄЫЄшЄУЄЦЄЯЛ§ЄСЪтЄЏЄГЄШЄтЄЧЄЄНЄІЁЃЄЄЄфЄоЄЂЁЂЛ§ЄСЪтЄЄЄЦЄЩЄІЄЙЄыЄѓЄРЄШЄЄЄІЕЄЄтЄЗЄЦЄЏЄыЄБЄЩЁЃВПЄЫЄЛЄшЁЂУцИХPCЄђЙиЦўЄЗЄЦЦАЄЋЄЙЄшЄъЁЂКЃЛўЄЮЅпЅЫPCЄђЙиЦўЄЗЄЦЛШЄУЄПЄлЄІЄЌЅсЅъЅУЅШЄЯЄЂЄъЄНЄІЄРЄЪЄШЁЃ
LinuxЄЌЦАЄЋЄЛЄыЄЋЄЩЄІЄЋЄђЅАЅАЄУЄЦЄпЄПЄБЄЩЁЂUbuntu Linux ЄЂЄПЄъЄЯЦАКюЄЙЄыЄУЄнЄЄЁЃЄПЄРЁЂFreeBSD ЄЯЁЂЄНЄьЄщЅпЅЫPCЄЌЛШЭбЄЗЄЦЄыЅЧЅаЅЄЅЙЄЌПЗЄЗВсЄЎЄЦЦАЄЋЄЪЄЋЄУЄПЁЂЄШЄЄЄІЯУЄтИЋЄЋЄБЄПЁЃЬЕРўLANЄЌЛШЄЈЄЪЄЄЄЪЄщЄоЄРЄЗЄтЁЂЭРўLANЄЙЄщЛШЄЈЄЪЄЋЄУЄПЄШЄЄЄІЯУЄтЄЂЄУЄЦЁЂЄНЄьЄЯЄЕЄЙЄЌЄЫЄСЄчЄУЄШИЗЄЗЄЄЁЃЄЄЄфЄоЄЂЁЂWindows11 ЄЌЄЗЄУЄЋЄъЦАЄЏЄѓЄРЄЋЄщЅНЅьЛШЄУЄЦЄьЄаЄЈЄЈЄфЄѓЁЂЄШЄЄЄІЕЄЄтЄЙЄыЄБЄЩЁЃ
ЄНЄѓЄЪЄяЄБЄЧЄСЄчЄУЄШЪЊЭпЄЌЭЏЄЄЄЦЄЗЄоЄУЄПЄБЄьЄЩЁЂЩєВАЄЮУцЄЧЛыРўЄђВЃЄЫЅСЅщЅъЄШЄКЄщЄЗЄЦЄпЄьЄаЁЂЩсУЪЬЧТПЄЫХХИЛЄђЦўЄьЄЪЄЄPCЄЌ5ЁС6ТцЪТЄѓЄЧЄыИїЗЪЄЌЬмЄЫЦўЄыЄяЄБЄЧЁФЁЃЅГЅЄЅФЅщЄђЭИњГшЭбЄЧЄЄЦЄЪЄЄЄЮЄЫЁЂЄГЄьАЪОхPCЧуЄУЄЦЄЩЄІЄЙЄыЄЮЁЂЭюЄСУхЄБМЋЪЌЁФЁЃ
Celeron J4125 Єф Celeron N5105 ХљЄЌКмЄУЄЦЄыЅпЅЫPCЄЌЮЩЄЕЄНЄІЄЧЄЯЄЂЄыЄЪЄШЁФЁЃAtomЗЯЄЮCPUЄщЄЗЄЄЄБЄЩЁЂТчРЮЄЮЅЮЁМЅШPCЄЫКмЄУЄЦЄП ОЪХХЮЯЅПЅЄЅзЄЮ Core i3 Єф i5 ЄШЦБХљЄЮНшЭ§ЧНЮЯЄЯЄЂЄыЄщЄЗЄЄЄЗЁЃКЃЄЮЅпЅЫPCЄЯSSDЄђРбЄѓЄЧЄыЄЋЄщЁЂЄНЄГЄНЄГВїХЌЄЫЛШЄЈЄНЄІЄЧЄтЄЂЄыЁЃВПЄшЄъЁЂОУШёХХЮЯЄЌАЕХнХЊЄЫОЏЄЪЄЄЄЗЁЂЄЊУЭУЪЄтАТЄЄЁЃОЎЄЕЄЄЄЋЄщЁЂОьЙчЄЫЄшЄУЄЦЄЯЛ§ЄСЪтЄЏЄГЄШЄтЄЧЄЄНЄІЁЃЄЄЄфЄоЄЂЁЂЛ§ЄСЪтЄЄЄЦЄЩЄІЄЙЄыЄѓЄРЄШЄЄЄІЕЄЄтЄЗЄЦЄЏЄыЄБЄЩЁЃВПЄЫЄЛЄшЁЂУцИХPCЄђЙиЦўЄЗЄЦЦАЄЋЄЙЄшЄъЁЂКЃЛўЄЮЅпЅЫPCЄђЙиЦўЄЗЄЦЛШЄУЄПЄлЄІЄЌЅсЅъЅУЅШЄЯЄЂЄъЄНЄІЄРЄЪЄШЁЃ
LinuxЄЌЦАЄЋЄЛЄыЄЋЄЩЄІЄЋЄђЅАЅАЄУЄЦЄпЄПЄБЄЩЁЂUbuntu Linux ЄЂЄПЄъЄЯЦАКюЄЙЄыЄУЄнЄЄЁЃЄПЄРЁЂFreeBSD ЄЯЁЂЄНЄьЄщЅпЅЫPCЄЌЛШЭбЄЗЄЦЄыЅЧЅаЅЄЅЙЄЌПЗЄЗВсЄЎЄЦЦАЄЋЄЪЄЋЄУЄПЁЂЄШЄЄЄІЯУЄтИЋЄЋЄБЄПЁЃЬЕРўLANЄЌЛШЄЈЄЪЄЄЄЪЄщЄоЄРЄЗЄтЁЂЭРўLANЄЙЄщЛШЄЈЄЪЄЋЄУЄПЄШЄЄЄІЯУЄтЄЂЄУЄЦЁЂЄНЄьЄЯЄЕЄЙЄЌЄЫЄСЄчЄУЄШИЗЄЗЄЄЁЃЄЄЄфЄоЄЂЁЂWindows11 ЄЌЄЗЄУЄЋЄъЦАЄЏЄѓЄРЄЋЄщЅНЅьЛШЄУЄЦЄьЄаЄЈЄЈЄфЄѓЁЂЄШЄЄЄІЕЄЄтЄЙЄыЄБЄЩЁЃ
ЄНЄѓЄЪЄяЄБЄЧЄСЄчЄУЄШЪЊЭпЄЌЭЏЄЄЄЦЄЗЄоЄУЄПЄБЄьЄЩЁЂЩєВАЄЮУцЄЧЛыРўЄђВЃЄЫЅСЅщЅъЄШЄКЄщЄЗЄЦЄпЄьЄаЁЂЩсУЪЬЧТПЄЫХХИЛЄђЦўЄьЄЪЄЄPCЄЌ5ЁС6ТцЪТЄѓЄЧЄыИїЗЪЄЌЬмЄЫЦўЄыЄяЄБЄЧЁФЁЃЅГЅЄЅФЅщЄђЭИњГшЭбЄЧЄЄЦЄЪЄЄЄЮЄЫЁЂЄГЄьАЪОхPCЧуЄУЄЦЄЩЄІЄЙЄыЄЮЁЂЭюЄСУхЄБМЋЪЌЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/07(Жт) [nЧЏСАЄЮЦќЕ]
#1 [linux] rangerЄЧВшСќЅзЅьЅгЅхЁМЄЌЄЧЄЄЪЄЄ
Raspberry Pi Zero W + Raspberry Pi OS buster ОхЄЧ ranger ЄђЛШЄЊЄІЄШЄЗЄПЄЮЄРЄБЄЩЁЂВшСќЅзЅьЅгЅхЁМЄЌЄЧЄЄЪЄЄЄГЄШЄЫЕЄЄХЄЄЄПЁЃw3m, w3m-img ЄЯЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЂЄыЄЯЄКЄЪЄЮЄРЄБЄЩЁФЁЃ
ranger ЄЧ .png ЅеЅЁЅЄЅыЄЫЅЋЁМЅНЅыЄђЙчЄяЄЛЄыЄШЁЂАЪВМЄЮЅсЅУЅЛЁМЅИЄЌЩНМЈЄЕЄьЄЦЄЗЄоЄІЁЃ
Raspberry Pi OS buster ЄЮОьЙчЁЂw3mimgdisplay ЄЯ /usr/lib/w3m/ ЄЮУцЄЫЄЂЄыЄЮЄЧЁЂ~/.bashrc ЄЧАЪВМЄЮЛиФъЄтФЩВУЄЗЄПЄЮЄРЄБЄЩЁЂИњВЬЄЯЬЕЄЄЬЯЭЭЁФЁЃ
which w3mimgdisplay ЄШТЧЄФЄШЁЂАЪВМЄЌЩНМЈЄЕЄьЄыЁЃЅбЅЙЄЯФЬЄУЄЦЄЄЄыЄшЄІЄРЄЌЁФЁЃ
w3mimgdisplay УБТЮЄЧЦАКюЄЙЄыЄЮЄЋГЮЧЇЄЗЄПЄЄЄШЛзЄУЄПЄтЄЮЄЮЁЂw3mimgdisplay hoge.png ЄШЄЄЄУЄПДЖЄИЄЧТЧЄУЄЦЄтВПЄЮШПБўЄтЪжЄУЄЦЄГЄЪЄЄЁЃЄЩЄІЄфЄщЅеЅФЁМЄЮЅФЁМЅыЄЮЄшЄІЄЪЛиФъЄђЄЗЄЦЦАЄЋЄЙЅзЅэЅАЅщЅрЄЧЄЯЬЕЄЕЄНЄІЄРЄЪЄШЁФЁЃ
ВђЗшКіЄЯКЃЄЮЄШЄГЄэЩдЬРЁЃЄШЄъЄЂЄЈЄКЁЂRaspberry Pi + ranger ЄЧВшСќЅзЅьЅгЅхЁМЄЯФќЄсЄшЄІЁФЁЃТОЄЮДФЖЄЪЄщЬфТъЬЕЄЏЦАЄЄЄЦЄыЄЗЁФЁЃ
ranger ЄЧ .png ЅеЅЁЅЄЅыЄЫЅЋЁМЅНЅыЄђЙчЄяЄЛЄыЄШЁЂАЪВМЄЮЅсЅУЅЛЁМЅИЄЌЩНМЈЄЕЄьЄЦЄЗЄоЄІЁЃ
('Failed to execute w3mimgdisplay',[])
Raspberry Pi OS buster ЄЮОьЙчЁЂw3mimgdisplay ЄЯ /usr/lib/w3m/ ЄЮУцЄЫЄЂЄыЄЮЄЧЁЂ~/.bashrc ЄЧАЪВМЄЮЛиФъЄтФЩВУЄЗЄПЄЮЄРЄБЄЩЁЂИњВЬЄЯЬЕЄЄЬЯЭЭЁФЁЃ
export PATH=$PATH:/usr/lib/w3m export W3MIMGDISPLAY_PATH=/usr/lib/w3m/w3mimgdisplay
which w3mimgdisplay ЄШТЧЄФЄШЁЂАЪВМЄЌЩНМЈЄЕЄьЄыЁЃЅбЅЙЄЯФЬЄУЄЦЄЄЄыЄшЄІЄРЄЌЁФЁЃ
$ which w3mimgdisplay /usr/lib/w3m/w3mimgdisplay
w3mimgdisplay УБТЮЄЧЦАКюЄЙЄыЄЮЄЋГЮЧЇЄЗЄПЄЄЄШЛзЄУЄПЄтЄЮЄЮЁЂw3mimgdisplay hoge.png ЄШЄЄЄУЄПДЖЄИЄЧТЧЄУЄЦЄтВПЄЮШПБўЄтЪжЄУЄЦЄГЄЪЄЄЁЃЄЩЄІЄфЄщЅеЅФЁМЄЮЅФЁМЅыЄЮЄшЄІЄЪЛиФъЄђЄЗЄЦЦАЄЋЄЙЅзЅэЅАЅщЅрЄЧЄЯЬЕЄЕЄНЄІЄРЄЪЄШЁФЁЃ
ВђЗшКіЄЯКЃЄЮЄШЄГЄэЩдЬРЁЃЄШЄъЄЂЄЈЄКЁЂRaspberry Pi + ranger ЄЧВшСќЅзЅьЅгЅхЁМЄЯФќЄсЄшЄІЁФЁЃТОЄЮДФЖЄЪЄщЬфТъЬЕЄЏЦАЄЄЄЦЄыЄЗЁФЁЃ
[ ЅФЅУЅГЄр ]
#2 [tv][comic] ЁжБКТєФОМљЄЮЬЁЪйneo (18)ХчЫмЯТЩЇЁзЄђЛыФА
NHKЄЧЪќСїЄЕЄьЄЦЄЄЄыЁжЬЁЪйЁзЄЮХчЫмЯТЩЇРшРИЄЮВѓЄђЯПВшЄЗЄЦЄЄЄПЄЮЄЧЛыФАЁЃЁжЬЁЪйЁзЄЯЁЂЬЁВшВШЄЕЄѓЄЮЛХЛіОьЄЫЅЋЅсЅщЄђРпУжЄЗЄЦЁЂКюЖШЄЮЭЭЛвЄђОвВ№ЄЗЄЦЄЄЄЏШжСШЁЃ
ЬЬЧђЄЋЄУЄПЁФЁЃВПЄшЄъЁЂХчЫмЯТЩЇРшРИЄЌЬЬЧђЄЄЁФЁЃЛХЛіОьЄЫХўУхСсЁЙЁЂЁжNHKЁЊ ЄЩЄІЄРЁЊЁЉ НрШїЄЯЄЧЄЄЦЄЄЄыЄЋЁЊЁЉЁзЄШЅЋЅсЅщЄђЛиКЙЄЗЄЪЄЌЄщЖЋЄжЬЁВшВШЄЕЄѓЄЯЅЗЅъЁМЅКНщЄЪЄЮЄЧЄЯЄЪЄЋЄэЄІЄЋЁЃ
ЕМВЛХљЄЯЦќЫмЛњЅкЅѓЁЂЅЅуЅщЄЯGЅкЅѓЄЮЛШЄЄЪЌЄБЄЌЖНЬЃПМЄЋЄУЄПЁЃБКТєРшРИЄтЦќЫмЛњЅкЅѓЄђЛШЄУЄЦЄыЄШШЏИРЄЗЄЦЄЄЄПЄБЄЩЁЂЗыЙНЦќЫмЛњЅкЅѓЄђЛШЄІЬЁВшВШЄЕЄѓЄЯТПЄЄЄЮЄРЄЪЁФЁЃЄЄЄфЄоЄЂЁЂКЃЄЮМуЄЄЬЁВшВШЄЕЄѓЄЯЅЧЅИЅПЅыЄЧЩСЄЏЄЋЄщЅЂЅьЄРЄэЄІЄБЄЩЁЃЄтЄУЄШЄтЁЂЅЧЅИЅПЅыЄЮОьЙчЄтЁЂЅбЅщЅсЁМЅПЄђФДРАЄЗЄЦЩСЄЬЃЄђМЋЪЌЙЅЄпЄЫФДРАЄЗЄЦЄЄЄЏЄяЄБЄЧЁЂЅЋЅЙЅПЅоЅЄЅКВФЧНЄЪЩєЪЌЄЮТПЄЕЄШИРЄІХРЄЧЄЯЅЧЅИЅПЅыЄЮЄлЄІЄЌКнИТЄЌЬЕЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃ
ЬЬЧђЄЋЄУЄПЁФЁЃВПЄшЄъЁЂХчЫмЯТЩЇРшРИЄЌЬЬЧђЄЄЁФЁЃЛХЛіОьЄЫХўУхСсЁЙЁЂЁжNHKЁЊ ЄЩЄІЄРЁЊЁЉ НрШїЄЯЄЧЄЄЦЄЄЄыЄЋЁЊЁЉЁзЄШЅЋЅсЅщЄђЛиКЙЄЗЄЪЄЌЄщЖЋЄжЬЁВшВШЄЕЄѓЄЯЅЗЅъЁМЅКНщЄЪЄЮЄЧЄЯЄЪЄЋЄэЄІЄЋЁЃ
ЕМВЛХљЄЯЦќЫмЛњЅкЅѓЁЂЅЅуЅщЄЯGЅкЅѓЄЮЛШЄЄЪЌЄБЄЌЖНЬЃПМЄЋЄУЄПЁЃБКТєРшРИЄтЦќЫмЛњЅкЅѓЄђЛШЄУЄЦЄыЄШШЏИРЄЗЄЦЄЄЄПЄБЄЩЁЂЗыЙНЦќЫмЛњЅкЅѓЄђЛШЄІЬЁВшВШЄЕЄѓЄЯТПЄЄЄЮЄРЄЪЁФЁЃЄЄЄфЄоЄЂЁЂКЃЄЮМуЄЄЬЁВшВШЄЕЄѓЄЯЅЧЅИЅПЅыЄЧЩСЄЏЄЋЄщЅЂЅьЄРЄэЄІЄБЄЩЁЃЄтЄУЄШЄтЁЂЅЧЅИЅПЅыЄЮОьЙчЄтЁЂЅбЅщЅсЁМЅПЄђФДРАЄЗЄЦЩСЄЬЃЄђМЋЪЌЙЅЄпЄЫФДРАЄЗЄЦЄЄЄЏЄяЄБЄЧЁЂЅЋЅЙЅПЅоЅЄЅКВФЧНЄЪЩєЪЌЄЮТПЄЕЄШИРЄІХРЄЧЄЯЅЧЅИЅПЅыЄЮЄлЄІЄЌКнИТЄЌЬЕЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃ
[ ЅФЅУЅГЄр ]
#3 [anime] ЁжЗрОьШЧЁиSHIROBAKOЁйЁзЄђЛыФА
ДќДжИТФъЄЧЁЂЁжЗрОьШЧЁиSHIROBAKOЁйЁзЄЌYouTubeОхЄЧЬЕЮСЧлПЎЄЕЄьЄЦЄыЄШУЮЄУЄПЄЮЄЧЛыФАЁЃЅЂЅЫЅсРЉКюЅЙЅПЅИЅЊЄђЩёТцЄЫЄЗЄПTVЅЂЅЫЅсЁжSHIROBAKOЁзЄЮЗрОьШЧЁЂЄШЄЄЄІЄГЄШЄщЄЗЄЄЁЃ
ЅЭЅУЅШОхЄЧЄЯЄЂЄоЄъЩОШНЄЌЮЩЄЏЄЪЄЋЄУЄПЄщЄЗЄЄЄЮЄЧОЏЄЗЩдАТЄРЄУЄПЄБЄЩЁЂИЋЄЦЄпЄПЄщЅеЅФЁМЄЫЬЬЧђЄЋЄУЄПЁЃЄтЄУЄШЄтЁЂTVЅЂЅЫЅсШЧЄђЬЄЛыФАЄЮПЭЄЌЄЄЄЄЪЄъЄГЄьЄРЄБИЋЄЦЄтЁЂХаОьПЭЪЊЄЌЄЩЄѓЄЪЅЅуЅщЄЪЄЮЄЋЄЕЄУЄбЄъЪЌЄщЄЪЄЄЄРЄэЄІЄЗЁЂЄНЄІЙЭЄЈЄыЄШДАСДЄЫЅеЅЁЅѓИўЄБЄЮКюЄъЄРЄУЄПЕЄЄтЄЙЄыЁЃЄШЄЯИРЄЈЁЂЅеЅЁЅѓИўЄБЄРЄШЄЗЄПЄщЅГЅьЄЯЄЩЄІЄЪЄЮЄШЛзЄУЄЦЄЗЄоЄІЩєЪЌЄтЄПЄЗЄЋЄЫЄЂЄУЄЦЁФЁЃ
ЯУЄђРЙЄъОхЄВЄыЄПЄсЄЫЁЂ ААеЄђЛ§ЄУЄППЭДжЄђХаОьЄЕЄЛЄПЄЂЄПЄъЄЯЁЂЄтЄІЄСЄчЄУЄШЄЩЄІЄЫЄЋЄЧЄЄЪЄЋЄУЄПЄЋЄЪЄЂЁЂЄШЄЄЄІЕЄЄтЄЙЄыЁЃГЇЄЌЄСЄуЄѓЄШДшФЅЄУЄЦЄыЄБЄЩЄНЄьЄЧЄтЅШЅщЅжЅыЄЌЕЏЄЄыЛўЄЯЄфЄУЄбЄъЕЏЄЄСЄуЄІЄтЄѓЄЧЁЂЄпЄПЄЄЄЪХИГЋЄЪЄщАѕОнЄЌАуЄУЄПЄЮЄРЄэЄІЄБЄЩЁФЁЃЄтЄУЄШЄтЁЂЄРЄУЄПЄщВПЄЋЅЂЅЄЅЧЅЂНаЄЗЄЦЄпЄЦЄшЄШИРЄяЄьЄПЄщЦЌЄђЪњЄЈЄЦЄЗЄоЄЄЄНЄІЁЃЅЅуЅщЄђЦАЄЋЄЗЄЦЬфТъЄђЕЏЄГЄЙЄЮЄЌАьШжГЮМТЄЧЄЯЄЂЄыЄѓЄРЄэЄІЄЪЁФЁЃ
TVЅЂЅЫЅсШЧИхШОЄЧЄтЁжЪбЄЪЯУЁзЄЮЅЅуЅщЄЌХаОьЄЗЄПЄЂЄПЄъЄЧЩдЩОЄЫЄЪЄУЄПАѕОнЄЌЄЂЄыЄЮЄРЄБЄЩЁЂ РяШШЄЌРЉКлЄђСДЄЏМѕЄБЄЪЄЄЄЂЄПЄъЄтЅЙЅУЅЅъЄЗЄЪЄЄЄшЄЪЄШЁФЁЃЄЄЄфЄоЄЂЁЂЄНЄьЄЌИНМТЄРЄэЄІЁЂЅъЅЂЅыЄРЄэЄІЄШИРЄяЄьЄПЄщЁЂЄНЄьЄЯЄоЄЂЄНЄІЄЋЄтЄЗЄьЄоЄЛЄѓЄЌЁЂЄШЪжЄЙЄЗЄЋЄЪЄЄЄБЄьЄЩЁЃЄФЄоЄыЄШЄГЄэЁЂРЉКюЄЗЄП P.A.WORKS ЄЮЅзЅэЅЧЅхЁМЅЕЁМЄЌЄЩЄГЄЋЄЧШЏИРЄЗЄЦЄЄЄПЄшЄІЄЫЁЂЅъЅЂЅыЄШЅеЅЁЅѓЅПЅИЁМЄЮШцЮЈЄђЄЩЄЮФјХйЄЫЄЙЄыЄЋЁЂЄпЄПЄЄЄЪЯУЄЫЗвЄЌЄУЄЦЄЄЄЏЄЮЄРЄэЄІЄЋЁЃ
ЄНЄІЄЄЄУЄПЁЂЄСЄчЄУЄШЕЄЄЫЄЪЄыЩєЪЌЄЯЄЂЄъЄФЄФЄтЁЂСДСГЅеЅФЁМЄЫГкЄЗЄсЄыЅЂЅЫЅсЅЗЅъЁМЅКЄЫЄЪЄУЄЦЄыЄЮЄРЄЋЄщЁЂЄПЄЄЄЗЄПЄтЄѓЄРЄЪЄШЁЃЮуЄЈЄаЅГЅьЄЌЄтЄЗЁЂВЁАцМщДЦЦФЄЂЄПЄъЄЌЅЂЅЫЅсЖШГІЄђЩёТцЄЫЄЗЄПВПЄЋЄђКюЄУЄПЄШЄЗЄПЄщЁЂЛІПЭЛіЗяЄЌЕЏЄЄПЄъЁЂДЦЦФЄЌЦЈЫДЄЗЄПЄъЄШЁЂЁжЄНЄѓЄЪЄЮЕвЄЫИЋЄЛЄЦЄЩЄІЄЙЄѓЄЮЁФЁзЄШЅВЅѓЅЪЅъЄЙЄыЅтЅЮЄЌЪПЕЄЄЧНаЄЦЄЏЄыЄяЄБЄЧЁЃЅЂЅЫЅсЖШГІПЭЄЌЅЂЅЫЅсЖШГІЄђЩёТцЄЫЄЙЄыЄШЩЌЄКЅРЁМЅЏЄЪЄтЄЮЄЌНаЄЦЄЏЄыЁФЁЃЄНЄІЄЄЄУЄПЅЂЅьЅГЅьЄШШцЄйЄПЄщЁЂЄГЄЮЅЗЅъЁМЅКЄЯЅаЅщЅѓЅЙДЖГаЄЌЄЂЄыЄлЄІЄРЄшЄЪЄШЁФЁЃ
ЅЭЅУЅШОхЄЧЄЯЄЂЄоЄъЩОШНЄЌЮЩЄЏЄЪЄЋЄУЄПЄщЄЗЄЄЄЮЄЧОЏЄЗЩдАТЄРЄУЄПЄБЄЩЁЂИЋЄЦЄпЄПЄщЅеЅФЁМЄЫЬЬЧђЄЋЄУЄПЁЃЄтЄУЄШЄтЁЂTVЅЂЅЫЅсШЧЄђЬЄЛыФАЄЮПЭЄЌЄЄЄЄЪЄъЄГЄьЄРЄБИЋЄЦЄтЁЂХаОьПЭЪЊЄЌЄЩЄѓЄЪЅЅуЅщЄЪЄЮЄЋЄЕЄУЄбЄъЪЌЄщЄЪЄЄЄРЄэЄІЄЗЁЂЄНЄІЙЭЄЈЄыЄШДАСДЄЫЅеЅЁЅѓИўЄБЄЮКюЄъЄРЄУЄПЕЄЄтЄЙЄыЁЃЄШЄЯИРЄЈЁЂЅеЅЁЅѓИўЄБЄРЄШЄЗЄПЄщЅГЅьЄЯЄЩЄІЄЪЄЮЄШЛзЄУЄЦЄЗЄоЄІЩєЪЌЄтЄПЄЗЄЋЄЫЄЂЄУЄЦЁФЁЃ
ЯУЄђРЙЄъОхЄВЄыЄПЄсЄЫЁЂ ААеЄђЛ§ЄУЄППЭДжЄђХаОьЄЕЄЛЄПЄЂЄПЄъЄЯЁЂЄтЄІЄСЄчЄУЄШЄЩЄІЄЫЄЋЄЧЄЄЪЄЋЄУЄПЄЋЄЪЄЂЁЂЄШЄЄЄІЕЄЄтЄЙЄыЁЃГЇЄЌЄСЄуЄѓЄШДшФЅЄУЄЦЄыЄБЄЩЄНЄьЄЧЄтЅШЅщЅжЅыЄЌЕЏЄЄыЛўЄЯЄфЄУЄбЄъЕЏЄЄСЄуЄІЄтЄѓЄЧЁЂЄпЄПЄЄЄЪХИГЋЄЪЄщАѕОнЄЌАуЄУЄПЄЮЄРЄэЄІЄБЄЩЁФЁЃЄтЄУЄШЄтЁЂЄРЄУЄПЄщВПЄЋЅЂЅЄЅЧЅЂНаЄЗЄЦЄпЄЦЄшЄШИРЄяЄьЄПЄщЦЌЄђЪњЄЈЄЦЄЗЄоЄЄЄНЄІЁЃЅЅуЅщЄђЦАЄЋЄЗЄЦЬфТъЄђЕЏЄГЄЙЄЮЄЌАьШжГЮМТЄЧЄЯЄЂЄыЄѓЄРЄэЄІЄЪЁФЁЃ
TVЅЂЅЫЅсШЧИхШОЄЧЄтЁжЪбЄЪЯУЁзЄЮЅЅуЅщЄЌХаОьЄЗЄПЄЂЄПЄъЄЧЩдЩОЄЫЄЪЄУЄПАѕОнЄЌЄЂЄыЄЮЄРЄБЄЩЁЂ РяШШЄЌРЉКлЄђСДЄЏМѕЄБЄЪЄЄЄЂЄПЄъЄтЅЙЅУЅЅъЄЗЄЪЄЄЄшЄЪЄШЁФЁЃЄЄЄфЄоЄЂЁЂЄНЄьЄЌИНМТЄРЄэЄІЁЂЅъЅЂЅыЄРЄэЄІЄШИРЄяЄьЄПЄщЁЂЄНЄьЄЯЄоЄЂЄНЄІЄЋЄтЄЗЄьЄоЄЛЄѓЄЌЁЂЄШЪжЄЙЄЗЄЋЄЪЄЄЄБЄьЄЩЁЃЄФЄоЄыЄШЄГЄэЁЂРЉКюЄЗЄП P.A.WORKS ЄЮЅзЅэЅЧЅхЁМЅЕЁМЄЌЄЩЄГЄЋЄЧШЏИРЄЗЄЦЄЄЄПЄшЄІЄЫЁЂЅъЅЂЅыЄШЅеЅЁЅѓЅПЅИЁМЄЮШцЮЈЄђЄЩЄЮФјХйЄЫЄЙЄыЄЋЁЂЄпЄПЄЄЄЪЯУЄЫЗвЄЌЄУЄЦЄЄЄЏЄЮЄРЄэЄІЄЋЁЃ
ЄНЄІЄЄЄУЄПЁЂЄСЄчЄУЄШЕЄЄЫЄЪЄыЩєЪЌЄЯЄЂЄъЄФЄФЄтЁЂСДСГЅеЅФЁМЄЫГкЄЗЄсЄыЅЂЅЫЅсЅЗЅъЁМЅКЄЫЄЪЄУЄЦЄыЄЮЄРЄЋЄщЁЂЄПЄЄЄЗЄПЄтЄѓЄРЄЪЄШЁЃЮуЄЈЄаЅГЅьЄЌЄтЄЗЁЂВЁАцМщДЦЦФЄЂЄПЄъЄЌЅЂЅЫЅсЖШГІЄђЩёТцЄЫЄЗЄПВПЄЋЄђКюЄУЄПЄШЄЗЄПЄщЁЂЛІПЭЛіЗяЄЌЕЏЄЄПЄъЁЂДЦЦФЄЌЦЈЫДЄЗЄПЄъЄШЁЂЁжЄНЄѓЄЪЄЮЕвЄЫИЋЄЛЄЦЄЩЄІЄЙЄѓЄЮЁФЁзЄШЅВЅѓЅЪЅъЄЙЄыЅтЅЮЄЌЪПЕЄЄЧНаЄЦЄЏЄыЄяЄБЄЧЁЃЅЂЅЫЅсЖШГІПЭЄЌЅЂЅЫЅсЖШГІЄђЩёТцЄЫЄЙЄыЄШЩЌЄКЅРЁМЅЏЄЪЄтЄЮЄЌНаЄЦЄЏЄыЁФЁЃЄНЄІЄЄЄУЄПЅЂЅьЅГЅьЄШШцЄйЄПЄщЁЂЄГЄЮЅЗЅъЁМЅКЄЯЅаЅщЅѓЅЙДЖГаЄЌЄЂЄыЄлЄІЄРЄшЄЪЄШЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/08(Хк) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] ВшСќРИРЎAIЄђЦАЄЋЄЛЄЪЄЄЄЋЛюЄЗЄЦЄЄЄыЄШЄГЄэ
ЅсЅЄЅѓPC(Windows10 x64 22H2)ОхЄЧВшСќРИРЎAIЁЂStable Diffusion web UI ЄђЦАЄЋЄЛЄЪЄЄЄЋЛюЄЗЄЦЄЄЄыЄШЄГЄэЁЃ
ЄШЄъЄЂЄЈЄКЦАЄЋЄЛЄыОѕТжЄЫЄЪЄУЄПЁЃИхЄЧМъНчЄђЅсЅтЄЙЄыЄФЄтЄъЁЃ
ЄШЄъЄЂЄЈЄКЦАЄЋЄЛЄыОѕТжЄЫЄЪЄУЄПЁЃИхЄЧМъНчЄђЅсЅтЄЙЄыЄФЄтЄъЁЃ
[ ЅФЅУЅГЄр ]
2023/04/09(Цќ) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] ВшСќРИРЎAI Stable Diffusion web UIЄђЛюЭб
ВшСќРИРЎAIЁЂStable Diffusion web UI ЄђЛюЄЗЄЦЄпЄПЄЄЁЃЄЧЄЄьЄаЁЂЅэЁМЅЋЅыДФЖЁЂМъИЕЄЮWindows10 x64 22H2ОхЄЧЦАЄЋЄЗЄПЄЄЁЃ
ДФЖЄЯАЪВМЁЃ
ЙЋЄЮВђРтЕЛіЄђФЏЄсЄыЄШЁЂЁжЅгЅЧЅЊЅЋЁМЅЩЄЮVRAMЄЯ 12GBАЪОхЄђПфОЉЁзЄШНёЄЋЄьЄЦЄыЄБЄЩЁЂМЋЪЌЄЮДФЖЁЂVRAM 6GB ЄЧЁЂЄЯЄПЄЗЄЦЦАЄЏЄЮЄЋЄЩЄІЄЋЁФЁЉ ЗыВЬЄђРшЄЫНёЄЄЄЦЄЊЄЏЄБЄЩЁЂИНЙдШЧЄЮ Stable Diffusion web UI ЄЪЄщ VRAM 6GB ЄЧЄтЦАЄЄЄЦЄЏЄьЄоЄЗЄПЁЃ
АьБўЄЖЄУЄЏЄъЄШЅЄЅѓЅЙЅШЁМЅыМъНчЄђЅсЅтЁЃЄСЄЪЄпЄЫЁЂЁжStable Diffusion web UI ЅЄЅѓЅЙЅШЁМЅыЁзЄЧЅАЅАЄьЄаВђРтЕЛіЄЌЄПЄЏЄЕЄѓНаЄЦЄЏЄыЁЃЄЂЄъЄЌЄПЄфЁЃ
ДФЖЄЯАЪВМЁЃ
- OS : Windows10 x64 22H2
- CPU : AMD Ryzen 5 5600X
- GPU : NVIDIA GeForce GTX 1060 6GB
- RAM : 16GB
ЙЋЄЮВђРтЕЛіЄђФЏЄсЄыЄШЁЂЁжЅгЅЧЅЊЅЋЁМЅЩЄЮVRAMЄЯ 12GBАЪОхЄђПфОЉЁзЄШНёЄЋЄьЄЦЄыЄБЄЩЁЂМЋЪЌЄЮДФЖЁЂVRAM 6GB ЄЧЁЂЄЯЄПЄЗЄЦЦАЄЏЄЮЄЋЄЩЄІЄЋЁФЁЉ ЗыВЬЄђРшЄЫНёЄЄЄЦЄЊЄЏЄБЄЩЁЂИНЙдШЧЄЮ Stable Diffusion web UI ЄЪЄщ VRAM 6GB ЄЧЄтЦАЄЄЄЦЄЏЄьЄоЄЗЄПЁЃ
АьБўЄЖЄУЄЏЄъЄШЅЄЅѓЅЙЅШЁМЅыМъНчЄђЅсЅтЁЃЄСЄЪЄпЄЫЁЂЁжStable Diffusion web UI ЅЄЅѓЅЙЅШЁМЅыЁзЄЧЅАЅАЄьЄаВђРтЕЛіЄЌЄПЄЏЄЕЄѓНаЄЦЄЏЄыЁЃЄЂЄъЄЌЄПЄфЁЃ
Ё§ Python ЄШ git ЄЌЩЌЭз :
Stable Diffusion web UI ЄЮЅЄЅѓЅЙЅШЁМЅыЄЫЄЯЁЂКЧФуИТЁЂPython ЄШ git ЄЌЩЌЭзЄщЄЗЄЄЁЃPython 3.10.6 ЄШ git ЄЯДћЄЫЅЄЅѓЅЙЅШЁМЅыКбЄпЁЃ
_Download Python | Python.org
Python 3.10.6 ЄЯЁЂpython-3.10.6-amd64.exe ЄђЦўМъЄЗЄЦМТЙдЄЙЄьЄаЅЄЅѓЅЙЅШЁМЅыЄЧЄЄыЁЃ
КЃИНКпЄЮ Python ЄЮКЧПЗШЧЄЯ 3.11.x ЄРЄБЄЩЁЂPython 3.10.6 ЄЧГЦМяЅзЅэЅАЅщЅрЄЮЦАКюГЮЧЇЄЌЙдЄяЄьЄЦЄЄЄыЄщЄЗЄЄЄЮЄЧЁЂАьБўЅНЅьЄЫЙчЄяЄЛЄЦЄЊЄЄЄПЁЃ
_Git for Windows
Git for Windows ЄЯЁЂGit-2.40.0-64-bit.exe ЄђЦўМъЄЗЄЦМТЙдЄЗЄЦЅЄЅѓЅЙЅШЁМЅыЁЃ
_Download Python | Python.org
Python 3.10.6 ЄЯЁЂpython-3.10.6-amd64.exe ЄђЦўМъЄЗЄЦМТЙдЄЙЄьЄаЅЄЅѓЅЙЅШЁМЅыЄЧЄЄыЁЃ
КЃИНКпЄЮ Python ЄЮКЧПЗШЧЄЯ 3.11.x ЄРЄБЄЩЁЂPython 3.10.6 ЄЧГЦМяЅзЅэЅАЅщЅрЄЮЦАКюГЮЧЇЄЌЙдЄяЄьЄЦЄЄЄыЄщЄЗЄЄЄЮЄЧЁЂАьБўЅНЅьЄЫЙчЄяЄЛЄЦЄЊЄЄЄПЁЃ
_Git for Windows
Git for Windows ЄЯЁЂGit-2.40.0-64-bit.exe ЄђЦўМъЄЗЄЦМТЙдЄЗЄЦЅЄЅѓЅЙЅШЁМЅыЁЃ
Ё§ CUDAЄђЅЄЅѓЅЙЅШЁМЅы :
NVIDIA CUDA toolkit 11.8 ЄтАьБўЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄыЁЃКЃИНКпЄЮ Stable Diffusion web UI ЄЪЄщЁЂКЧНщЄЫbatЅеЅЁЅЄЅыЄђМТЙдЄЗЄПКнЄЫМЋЦАЄЧЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЏЄьЄыЄШЄЄЄІЯУЄтИЋЄЋЄБЄПЄБЄьЄЩЁЂCUDAДиЯЂЄЮЅеЅЁЅЄЅыЅЕЅЄЅКЄЌТчЄЄЄЄЮЄЧЁЂМЋЪЌЄЧОѕЖЗЄђЧФАЎЄЗЄФЄФЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄыЄГЄШЄЫЄЗЄПЁЃ
АЪВМЄЮЅкЁМЅИЄђЛВЙЭЄЫЄЗЄФЄФКюЖШЄђПЪЄсЄПЁЃЄЂЄъЄЌЄПЄфЁЃ
_WindowsЄиЄЮNVIDIA CUDAЄЮGPUДФЖЙНУл | ТыЄЮЬмНЕЫіЅзЅэЅАЅщЅоЁМ
_CUDA Toolkit 11.8 Downloads | NVIDIA Developer
_CUDA Toolkit Archive | NVIDIA Developer
cuda_11.8.0_522.06_windows.exe (3.0GB) ЄђDLЄЗЄЦМТЙдЁЃЅЕЅЄЅКЄЌТчЄЄЄЄЮЄЧЁЂDЅЩЅщЅЄЅжЄЮHDDЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄПЁЃЅЄЅѓЅЙЅШЁМЅыОьНъЄЯАЪВМЁЃ
ДФЖЪбПє PATH ЄЫАЪВМЄђФЩВУЁЃ
CuDNNЄтЅЄЅѓЅЙЅШЁМЅыЁЃЦўМъЄЫЄЯ NVIDIAЅЂЅЋЅІЅѓЅШЄЌЩЌЭзЄщЄЗЄЄЁЃЄГЄЮЄЂЄПЄъЁЂStable Diffusion web UI ЄЮbatЅеЅЁЅЄЅыЄЧМЋЦАЅЄЅѓЅЙЅШЁМЅыЄЙЄыЛўЄЯЄЩЄІЄЪЄыЄЮЄРЄэЄІЁФЁЉ
_CUDA Deep Neural Network (cuDNN) | NVIDIA Developer
cudnn-windows-x86_64-8.8.1.3_cuda11-archive.zip (667MB) ЄђЦўМъЄЗЄЦВђХрЁЃУцЄЫЄЯЁЂbin, include, lib ЄЮ3ЄФЄЮЅеЅЉЅыЅРЄЌЦўЄУЄЦЄыЁЃCUDA ЄЮЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅРЄЫЅГЅдЁМЄЙЄыЁЃ
ДФЖЪбПєЄђФЩВУЁЃ
DOSСы(ЅГЅоЅѓЅЩЅзЅэЅѓЅзЅШ, cmd.exe)ЄђГЋЄЄЄЦЁЂnvcc ЄШЄфЄщЄЌЦАЄЄНЄІЄЋЄЩЄІЄЋЄђГЮЧЇЁЃ
АЪВМЄЮЅкЁМЅИЄђЛВЙЭЄЫЄЗЄФЄФКюЖШЄђПЪЄсЄПЁЃЄЂЄъЄЌЄПЄфЁЃ
_WindowsЄиЄЮNVIDIA CUDAЄЮGPUДФЖЙНУл | ТыЄЮЬмНЕЫіЅзЅэЅАЅщЅоЁМ
_CUDA Toolkit 11.8 Downloads | NVIDIA Developer
_CUDA Toolkit Archive | NVIDIA Developer
cuda_11.8.0_522.06_windows.exe (3.0GB) ЄђDLЄЗЄЦМТЙдЁЃЅЕЅЄЅКЄЌТчЄЄЄЄЮЄЧЁЂDЅЩЅщЅЄЅжЄЮHDDЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄПЁЃЅЄЅѓЅЙЅШЁМЅыОьНъЄЯАЪВМЁЃ
D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\
ДФЖЪбПє PATH ЄЫАЪВМЄђФЩВУЁЃ
D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\libnvvp
CuDNNЄтЅЄЅѓЅЙЅШЁМЅыЁЃЦўМъЄЫЄЯ NVIDIAЅЂЅЋЅІЅѓЅШЄЌЩЌЭзЄщЄЗЄЄЁЃЄГЄЮЄЂЄПЄъЁЂStable Diffusion web UI ЄЮbatЅеЅЁЅЄЅыЄЧМЋЦАЅЄЅѓЅЙЅШЁМЅыЄЙЄыЛўЄЯЄЩЄІЄЪЄыЄЮЄРЄэЄІЁФЁЉ
_CUDA Deep Neural Network (cuDNN) | NVIDIA Developer
cudnn-windows-x86_64-8.8.1.3_cuda11-archive.zip (667MB) ЄђЦўМъЄЗЄЦВђХрЁЃУцЄЫЄЯЁЂbin, include, lib ЄЮ3ЄФЄЮЅеЅЉЅыЅРЄЌЦўЄУЄЦЄыЁЃCUDA ЄЮЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅРЄЫЅГЅдЁМЄЙЄыЁЃ
ДФЖЪбПєЄђФЩВУЁЃ
CUDA_PATH = D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8 CUDA_PATH_V11_8 = D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8 CUDNN_PATH = D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8
DOSСы(ЅГЅоЅѓЅЩЅзЅэЅѓЅзЅШ, cmd.exe)ЄђГЋЄЄЄЦЁЂnvcc ЄШЄфЄщЄЌЦАЄЄНЄІЄЋЄЩЄІЄЋЄђГЮЧЇЁЃ
> nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2022 NVIDIA Corporation Built on Wed_Sep_21_10:41:10_Pacific_Daylight_Time_2022 Cuda compilation tools, release 11.8, V11.8.89 Build cuda_11.8.r11.8/compiler.31833905_0
Ё§ Stable Diffusion web UI ЄђgitЄЧЅЏЅэЁМЅѓ :
Stable Diffusion web UI ЄђЦГЦўЁЃАЪВМЄЮЕЛіЄђЛВЙЭЄЫЄЕЄЛЄЦЄтЄщЄУЄЦЅЄЅѓЅЙЅШЁМЅыЄЗЄПЁЃ
_Stable Diffusion webui(AUTOMATIC1111ШЧ)ЄЮЦГЦўВђРтЁУДЖСлЦќЕ
_GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
КЃВѓЄЯЁЂD:\aiwork\ ЄШЄЄЄІЅЧЅЃЅьЅЏЅШЅъЄђКюРЎЄЗЄЦЁЂЄНЄЮУцЄЫЦўЄьЄыЄГЄШЄЫЄЗЄПЁЃЅЈЅЏЅЙЅзЅэЁМЅщОхЄЧ D:\aiwork\ ЄђБІЅЏЅъЅУЅЏ ЂЊ Git BashЁЃBash ЄЮЅІЅЄЅѓЅЩЅІЄЌГЋЄЏЄЮЄЧАЪВМЄђТЧЄСЙўЄрЁЃ
github ЄЋЄщЁЂStable Diffusion web UI ЄЌЅЏЅэЁМЅѓЄЕЄьЄЦЁЂD:\aiwork\stable-diffusion-webui\ ЄЫАьМАЄЌЦўЄУЄПЁЃ
_Stable Diffusion webui(AUTOMATIC1111ШЧ)ЄЮЦГЦўВђРтЁУДЖСлЦќЕ
_GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
КЃВѓЄЯЁЂD:\aiwork\ ЄШЄЄЄІЅЧЅЃЅьЅЏЅШЅъЄђКюРЎЄЗЄЦЁЂЄНЄЮУцЄЫЦўЄьЄыЄГЄШЄЫЄЗЄПЁЃЅЈЅЏЅЙЅзЅэЁМЅщОхЄЧ D:\aiwork\ ЄђБІЅЏЅъЅУЅЏ ЂЊ Git BashЁЃBash ЄЮЅІЅЄЅѓЅЩЅІЄЌГЋЄЏЄЮЄЧАЪВМЄђТЧЄСЙўЄрЁЃ
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
github ЄЋЄщЁЂStable Diffusion web UI ЄЌЅЏЅэЁМЅѓЄЕЄьЄЦЁЂD:\aiwork\stable-diffusion-webui\ ЄЫАьМАЄЌЦўЄУЄПЁЃ
Ё§ ЅтЅЧЅыЄђЦўМъ :
ГиНЌЅтЅЧЅыЅЧЁМЅПЄђЦўМъЁЃЅГЅьЄЌЬЕЄЄЄШВшСќЄђРИРЎЄЧЄЄЪЄЄЁЃ
ПЇЄѓЄЪМяЮрЄЮГиНЌЅтЅЧЅыЅЧЁМЅПЄЌЄЂЄСЄГЄСЄЧЧлЩлЄЕЄьЄЦЄЄЄыЄБЄьЄЩЁФЁЃStable Diffusion web UI ЄЮЁЂЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР\models\Stable-diffusion\ АЪВМЄЫЁЂ.safetensors ЄтЄЗЄЏЄЯ .ckpt ЅеЅЁЅЄЅыЄђУжЄБЄаЄЄЄЄЄщЄЗЄЄЁЃ
.safetensors ЄЮЄлЄІЄЌЁЂПЗЄЗЄЏЄЦЁЂЙтТЎЄЫНшЭ§ЄЧЄЄЦЁЂДэИБРЄЌОЏЄЪЄЄЅеЅЉЁМЅоЅУЅШЁЂЄщЄЗЄЄЁЃ.ckpt ЄЯЁЂУцЄЫЅЙЅЏЅъЅзЅШЄЌЦўЄУЄЦЄЄЄЦМТЙдЄЧЄЄПЄъЄЙЄыЄНЄІЄЧЁЂПШИЕЩдЬРЄЮЅЧЁМЅПЄЯВПЄђЄЙЄыЄЮЄЋЪЌЄЋЄщЄЪЄЏЄЦДэИБЄРЄЋЄщУэАеЄЙЄыЄйЄЗЁЂЄШРтЬРЄЕЄьЄЦЄПЁЃ
ЄСЄЪЄпЄЫЁЂ1ЅеЅЁЅЄЅыЄЫЩеЄЁЂ2ЁС7GBЄЮЅеЅЁЅЄЅыЅЕЅЄЅКЁЃЄЂЄУЄШЄЄЄІДжЄЫHDDЄЮЖѕЄЭЦЮЬЄЌИКЄУЄЦЄЄЄЏЁФЁЃ
КЃВѓЄЯЁЂv2-1_768-ema-pruned.ckpt ЄШЁЂchilloutmix_.safetensors ЄђЦўМъЄЕЄЛЄЦЄтЄщЄУЄПЁЃИхМдЄЯЁЂCivitai ЄШЄЄЄІЅЕЁМЅгЅЙЄЫЅЂЅЋЅІЅѓЅШЄђКюЄщЄЪЄЄЄШЦўМъЄЧЄЄЪЄЄЁЃ
_stabilityai/stable-diffusion-2-1 at main
_ChilloutMix | Stable Diffusion Checkpoint | Civitai
ЙЋЄЮВђРтЕЛіЄЫЄшЄыЄШЁЂЄлЄШЄѓЄЩЄЮОьЙчЁЂHugging FaceЁЂЄтЄЗЄЏЄЯ Civitai ЄЧЅтЅЧЅыЅЧЁМЅПЄЮЦўМъЄЯЄЧЄЄыЄШЄЮЄГЄШЁЃ
_Hugging Face - The AI community building the future.
_Civitai | Stable Diffusion models, embeddings, hypernetworks and more
ЄЩЄѓЄЪЅтЅЧЅыЄЌТИКпЄЗЄЦЄЄЄыЄЮЄЋЁЂЄНЄЮЄЂЄПЄъЄЯАЪВМЄЮЄоЄШЄсЕЛіЄЌЛВЙЭЄЫЄЪЄУЄПЁЃЄЂЄъЄЌЄПЄфЁЃ
_ЅъЅЂЅыЗЯЅтЅЧЅыШцГгЁІЛЈДЖ - NovelAI 5ch Wiki
_ЅтЅЧЅыЄЫЄФЄЄЄЦ - ЄШЄЗЄЂЄdiffusion Wiki*
ПЇЄѓЄЪМяЮрЄЮГиНЌЅтЅЧЅыЅЧЁМЅПЄЌЄЂЄСЄГЄСЄЧЧлЩлЄЕЄьЄЦЄЄЄыЄБЄьЄЩЁФЁЃStable Diffusion web UI ЄЮЁЂЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР\models\Stable-diffusion\ АЪВМЄЫЁЂ.safetensors ЄтЄЗЄЏЄЯ .ckpt ЅеЅЁЅЄЅыЄђУжЄБЄаЄЄЄЄЄщЄЗЄЄЁЃ
.safetensors ЄЮЄлЄІЄЌЁЂПЗЄЗЄЏЄЦЁЂЙтТЎЄЫНшЭ§ЄЧЄЄЦЁЂДэИБРЄЌОЏЄЪЄЄЅеЅЉЁМЅоЅУЅШЁЂЄщЄЗЄЄЁЃ.ckpt ЄЯЁЂУцЄЫЅЙЅЏЅъЅзЅШЄЌЦўЄУЄЦЄЄЄЦМТЙдЄЧЄЄПЄъЄЙЄыЄНЄІЄЧЁЂПШИЕЩдЬРЄЮЅЧЁМЅПЄЯВПЄђЄЙЄыЄЮЄЋЪЌЄЋЄщЄЪЄЏЄЦДэИБЄРЄЋЄщУэАеЄЙЄыЄйЄЗЁЂЄШРтЬРЄЕЄьЄЦЄПЁЃ
ЄСЄЪЄпЄЫЁЂ1ЅеЅЁЅЄЅыЄЫЩеЄЁЂ2ЁС7GBЄЮЅеЅЁЅЄЅыЅЕЅЄЅКЁЃЄЂЄУЄШЄЄЄІДжЄЫHDDЄЮЖѕЄЭЦЮЬЄЌИКЄУЄЦЄЄЄЏЁФЁЃ
КЃВѓЄЯЁЂv2-1_768-ema-pruned.ckpt ЄШЁЂchilloutmix_.safetensors ЄђЦўМъЄЕЄЛЄЦЄтЄщЄУЄПЁЃИхМдЄЯЁЂCivitai ЄШЄЄЄІЅЕЁМЅгЅЙЄЫЅЂЅЋЅІЅѓЅШЄђКюЄщЄЪЄЄЄШЦўМъЄЧЄЄЪЄЄЁЃ
_stabilityai/stable-diffusion-2-1 at main
_ChilloutMix | Stable Diffusion Checkpoint | Civitai
ЙЋЄЮВђРтЕЛіЄЫЄшЄыЄШЁЂЄлЄШЄѓЄЩЄЮОьЙчЁЂHugging FaceЁЂЄтЄЗЄЏЄЯ Civitai ЄЧЅтЅЧЅыЅЧЁМЅПЄЮЦўМъЄЯЄЧЄЄыЄШЄЮЄГЄШЁЃ
_Hugging Face - The AI community building the future.
_Civitai | Stable Diffusion models, embeddings, hypernetworks and more
ЄЩЄѓЄЪЅтЅЧЅыЄЌТИКпЄЗЄЦЄЄЄыЄЮЄЋЁЂЄНЄЮЄЂЄПЄъЄЯАЪВМЄЮЄоЄШЄсЕЛіЄЌЛВЙЭЄЫЄЪЄУЄПЁЃЄЂЄъЄЌЄПЄфЁЃ
_ЅъЅЂЅыЗЯЅтЅЧЅыШцГгЁІЛЈДЖ - NovelAI 5ch Wiki
_ЅтЅЧЅыЄЫЄФЄЄЄЦ - ЄШЄЗЄЂЄdiffusion Wiki*
Ё§ Stable Diffusion ЄђЅЄЅѓЅЙЅШЁМЅы :
УцЄЫЦўЄУЄЦЄыЁЂwebui-user.bat ЄђЪдНИЄЗЄЦЁЂЅгЅЧЅЊЅЋЁМЅЩЄЮVRAMЄЌОЏЄЪЄЄДФЖЄЧЄтОЏЄЗЄЯЙтТЎЄЫНшЭ§ЄЌЄЧЄЄыЄшЄІЄЫЄЪЄыЄШЄЄЄІЁЂxformers ЄЪЄыЄтЄЮЄђЅЄЅѓЅЙЅШЁМЅыЄЙЄыЄшЄІЄЫЛиФъЁЃ
xformers ЄђЦГЦўЄЙЄыЄШНшЭ§ЛўДжЄЌУЛЄЏЄЪЄыЄБЄьЄЩЁЂЄНЄЮТхЄяЄъЁЂНшЭ§ЄЮКЦИНРЄЌЕОРЗЄЫЄЪЄыЄщЄЗЄЄЁЃЦБЄИМіЪИ(ЅзЅэЅѓЅзЅШЁЂЄШИЦЄаЄьЄЦЄЄЄыЄщЄЗЄЄ)ЄђТЧЄСЙўЄѓЄЧЄтОЏЄЗАуЄІВшСќЄЌРИРЎЄЕЄьЄыЄшЄІЄЫЄЪЄыЄЮЄРЄШЄЋЁЃ
webui-user.bat ЄђЅРЅжЅыЅЏЅъЅУЅЏЄЗЄЦМТЙдЁЃDOSСыЄЌГЋЄЄЄЦЁЂМЋЦАЄЧЅЄЅѓЅЙЅШЁМЅыНшЭ§ЄЌПЪЄрЁЃPython ЄЧAIДиЗИЄЮВПЄЋЄђНшЭ§ЄЧЄЄыЁЂPyTorch (torch) ЄШЄЄЄІЅщЅЄЅжЅщЅъЄНЄЮТОЄЌЅЄЅѓЅЙЅШЁМЅыЄЕЄьЄыЁЃ
ЄСЄЪЄпЄЫЁЂPyTorch ЄЯ2GBАЪОхЄЮЅеЅЁЅЄЅыЄРЄУЄПЄЮЄЧЁЂНшЭ§ЄЌНЊЄяЄыЄоЄЧЄНЄГЄНЄГТдЄПЄЕЄьЄыЁЃ
set COMMANDLINE_ARGS= --xformers
xformers ЄђЦГЦўЄЙЄыЄШНшЭ§ЛўДжЄЌУЛЄЏЄЪЄыЄБЄьЄЩЁЂЄНЄЮТхЄяЄъЁЂНшЭ§ЄЮКЦИНРЄЌЕОРЗЄЫЄЪЄыЄщЄЗЄЄЁЃЦБЄИМіЪИ(ЅзЅэЅѓЅзЅШЁЂЄШИЦЄаЄьЄЦЄЄЄыЄщЄЗЄЄ)ЄђТЧЄСЙўЄѓЄЧЄтОЏЄЗАуЄІВшСќЄЌРИРЎЄЕЄьЄыЄшЄІЄЫЄЪЄыЄЮЄРЄШЄЋЁЃ
webui-user.bat ЄђЅРЅжЅыЅЏЅъЅУЅЏЄЗЄЦМТЙдЁЃDOSСыЄЌГЋЄЄЄЦЁЂМЋЦАЄЧЅЄЅѓЅЙЅШЁМЅыНшЭ§ЄЌПЪЄрЁЃPython ЄЧAIДиЗИЄЮВПЄЋЄђНшЭ§ЄЧЄЄыЁЂPyTorch (torch) ЄШЄЄЄІЅщЅЄЅжЅщЅъЄНЄЮТОЄЌЅЄЅѓЅЙЅШЁМЅыЄЕЄьЄыЁЃ
ЄСЄЪЄпЄЫЁЂPyTorch ЄЯ2GBАЪОхЄЮЅеЅЁЅЄЅыЄРЄУЄПЄЮЄЧЁЂНшЭ§ЄЌНЊЄяЄыЄоЄЧЄНЄГЄНЄГТдЄПЄЕЄьЄыЁЃ
Ё§ ЛШЄУЄЦЄпЄы :
ЅЄЅѓЅЙЅШЁМЅыНшЭ§ЄЌНЊЄяЄыЄШЁЂDOSСыОхЄЫЁЂАЪВМЄЮЪИЛњЮѓЄЌЩНМЈЄЕЄьЄыЁЃ
Google Chrome ЄЧОхЕURLЄђГЋЄЏЁЃЄСЄЪЄпЄЫЁЂFirefox ЄЧЛюЄНЄІЄШЄЗЄПЄщЁЂЄЪЄѓЄРЄЋЄСЄчЄУЄШШПБўЄЌЬЏЄЪДЖЄИЄЧЁФЁЃЄЊЄНЄщЄЏЄГЄІЄЄЄІЅЂЅьЅГЅьЄЯЁЂGoogle Chrome ЄђЛШЄІЄГЄШЄђСАФѓЄЫЄЗЄЦКюЄщЄьЄЦЄЄЄыЄЮЄРЄэЄІЄЪЄШЁЃ
txt2img ЄШЄЄЄІЁЂМіЪИЄђТЧЄСЙўЄрЄШВшСќЄЌРИРЎЄЕЄьЄыЅФЁМЅыЄЧЦАКюГЮЧЇЄЗЄЦЄпЄПЁЃЄШЄъЄЂЄЈЄКЁЂЁжPromptЁзЄШЩНМЈЄЕЄьЄЦЄыЦўЮЯЭѓЄЫЁЂЁж1girl, cuteЁзЄШТЧЄСЙўЄсЄаЁЂНїЄЮЛвЄЮГЈЄЌРИРЎЄЕЄьЄыЄщЄЗЄЄЁЃ
МъИЕЄЮДФЖЄЯЁЂGeforce GTX 1060 6GB ЁНЁН VRAMЄЌ6GBЄЗЄЋЄЪЄЄЄЋЄщЅЈЅщЁМЄЌНаЄыЄЮЄЋЄЪЄШЛзЄУЄПЄБЄЩЁЂЄСЄуЄѓЄШВшСќЄђРИРЎЄЗЄЦЄЏЄьЄПЁЃ512 x 512 ЄЮВшСќАьЫчЄђЁЂ30ЩУАЪОхЄЋЄБЄЦРИРЎЄЗЄЦЄЏЄьЄЦЄЄЄыЁЃ
ЄСЄЪЄпЄЫЁЂGeForce RTX 3060 12GB ЄЂЄПЄъЄђЛШЄЈЄаЁЂ1Ыч6ЩУЄАЄщЄЄЄЧРИРЎЄЗЄЦЄЏЄьЄыЄщЄЗЄЄЁФЁЃЄоЄЂЁЂЄЊУЭУЪЄЌ5ЫќБпСАИхЄщЄЗЄЄЄБЄЩЁФЁЃ
КИОхЄЮЅъЅЙЅШЅмЅУЅЏЅЙЁЉЄЧЁЂЅтЅЧЅыЅЧЁМЅПЄђРкЄъТиЄЈЄыЄГЄШЄЌЄЧЄЄыЁЃМЋЪЌЄЮДФЖЄЧЄЯЁЂРкЄъТиЄЈЄыКнЄЫПєЪЌЄАЄщЄЄТдЄПЄЕЄьЄыЁЃ
http://127.0.0.1:7860/ЅэЁМЅЋЅыДФЖЄЧWebЅЕЁМЅаЄЌЮЉЄСОхЄЌЄУЄЦЁЂОхЕЄЮURLЄЫЅЂЅЏЅЛЅЙЄЙЄьЄаЛШЄЈЄыЄшЁЂЄШХСЄЈЄЦЄЏЄьЄЦЄЄЄыЁЃ
Google Chrome ЄЧОхЕURLЄђГЋЄЏЁЃЄСЄЪЄпЄЫЁЂFirefox ЄЧЛюЄНЄІЄШЄЗЄПЄщЁЂЄЪЄѓЄРЄЋЄСЄчЄУЄШШПБўЄЌЬЏЄЪДЖЄИЄЧЁФЁЃЄЊЄНЄщЄЏЄГЄІЄЄЄІЅЂЅьЅГЅьЄЯЁЂGoogle Chrome ЄђЛШЄІЄГЄШЄђСАФѓЄЫЄЗЄЦКюЄщЄьЄЦЄЄЄыЄЮЄРЄэЄІЄЪЄШЁЃ
txt2img ЄШЄЄЄІЁЂМіЪИЄђТЧЄСЙўЄрЄШВшСќЄЌРИРЎЄЕЄьЄыЅФЁМЅыЄЧЦАКюГЮЧЇЄЗЄЦЄпЄПЁЃЄШЄъЄЂЄЈЄКЁЂЁжPromptЁзЄШЩНМЈЄЕЄьЄЦЄыЦўЮЯЭѓЄЫЁЂЁж1girl, cuteЁзЄШТЧЄСЙўЄсЄаЁЂНїЄЮЛвЄЮГЈЄЌРИРЎЄЕЄьЄыЄщЄЗЄЄЁЃ
МъИЕЄЮДФЖЄЯЁЂGeforce GTX 1060 6GB ЁНЁН VRAMЄЌ6GBЄЗЄЋЄЪЄЄЄЋЄщЅЈЅщЁМЄЌНаЄыЄЮЄЋЄЪЄШЛзЄУЄПЄБЄЩЁЂЄСЄуЄѓЄШВшСќЄђРИРЎЄЗЄЦЄЏЄьЄПЁЃ512 x 512 ЄЮВшСќАьЫчЄђЁЂ30ЩУАЪОхЄЋЄБЄЦРИРЎЄЗЄЦЄЏЄьЄЦЄЄЄыЁЃ
ЄСЄЪЄпЄЫЁЂGeForce RTX 3060 12GB ЄЂЄПЄъЄђЛШЄЈЄаЁЂ1Ыч6ЩУЄАЄщЄЄЄЧРИРЎЄЗЄЦЄЏЄьЄыЄщЄЗЄЄЁФЁЃЄоЄЂЁЂЄЊУЭУЪЄЌ5ЫќБпСАИхЄщЄЗЄЄЄБЄЩЁФЁЃ
КИОхЄЮЅъЅЙЅШЅмЅУЅЏЅЙЁЉЄЧЁЂЅтЅЧЅыЅЧЁМЅПЄђРкЄъТиЄЈЄыЄГЄШЄЌЄЧЄЄыЁЃМЋЪЌЄЮДФЖЄЧЄЯЁЂРкЄъТиЄЈЄыКнЄЫПєЪЌЄАЄщЄЄТдЄПЄЕЄьЄыЁЃ
Ё§ ГШФЅЕЁЧНЄђЅЄЅѓЅЙЅШЁМЅы :
ГШФЅЕЁЧН(Extensions)ЄђЄЄЄЏЄФЄЋЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЁЃUIЄђЦќЫмИьВНЄЗЄПЄъЁЂЅЁМЅяЁМЅЩЄЮЪфДАЄЌЄЧЄЄыЄшЄІЄЫЄЪЄыЄщЄЗЄЄЁЃ
_GitHub - journey-ad/sd-webui-bilingual-localization
_GitHub - Katsuyuki-Karasawa/stable-diffusion-webui-localization-ja_JP
_GitHub - DominikDoom/a1111-sd-webui-tagcomplete
Extensions ЂЊ Install from URLЁЂЄђСЊТђЄЗЄЦЁЂURL for extension's git repository ЄЮЭѓЄЫ github ЄЮ URL ЄђЅГЅдЅкЄЗЄЦЁЂInstallЅмЅПЅѓЄђЅЏЅъЅУЅЏЁЃInstalled ЅПЅжЄђСЊТђЄЗЄЦЁЂЅЄЅѓЅЙЅШЁМЅыЄЗЄПГШФЅЄЫЅСЅЇЅУЅЏЄђЦўЄьЄЦЭИњВНЁЃ
_GitHub - journey-ad/sd-webui-bilingual-localization
_GitHub - Katsuyuki-Karasawa/stable-diffusion-webui-localization-ja_JP
_GitHub - DominikDoom/a1111-sd-webui-tagcomplete
Extensions ЂЊ Install from URLЁЂЄђСЊТђЄЗЄЦЁЂURL for extension's git repository ЄЮЭѓЄЫ github ЄЮ URL ЄђЅГЅдЅкЄЗЄЦЁЂInstallЅмЅПЅѓЄђЅЏЅъЅУЅЏЁЃInstalled ЅПЅжЄђСЊТђЄЗЄЦЁЂЅЄЅѓЅЙЅШЁМЅыЄЗЄПГШФЅЄЫЅСЅЇЅУЅЏЄђЦўЄьЄЦЭИњВНЁЃ
[ ЅФЅУЅГЄр ]
2023/04/10(Зю) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] ВшСќРИРЎAI Stable Diffusion web UIЄђЛюЭбУц
ВшСќРИРЎAIЁЂStable Diffusion web UI ЄђЅэЁМЅЋЅыДФЖЄЫЅЄЅѓЅЙЅШЁМЅыЄЧЄЄПЄЮЄЧЁЂБбУБИьЄфБбЪИЄђТЧЄСЙўЄрЄШВшСќЄђРИРЎЄЗЄЦЄЏЄьЄы txt2img ЄЫПЇЁЙЄЪУБИьЄђТЧЄСЙўЄѓЄЧЛюЄЗЄЦЄЄЄПЄЮЄРЄБЄЩЁЃСРЄУЄПДЖЄИЄЮВшСќЄђРИРЎЄЙЄыЄЮЄЌЦёЄЗЄЄЄЪЄШЛзЄЈЄЦЄЄПЄЮЄЧЁЂВшСќЄЋЄщЪЬВшСќЄђРИРЎЄЧЄЄыЄщЄЗЄЄ img2img ЄЫЄФЄЄЄЦФДЄйЛЯЄсЄЦЄЄЄыЄШЄГЄэЁЃЅГЅьЄђЛШЄЈЄаРИРЎВшСќЄЮНЄРЕЄЌЄЧЄЄыЄщЄЗЄЄЄЮЄРЄБЄЩЁФЁЃ
ЄШЄъЄЂЄЈЄКЁЂКЃИНКпЄЮЛЈДЖЄђЅсЅтЁЃ
ЄШЄъЄЂЄЈЄКЁЂКЃИНКпЄЮЛЈДЖЄђЅсЅтЁЃ
Ё§ 8bit PCЛўТхЄЮЅЂЅЩЅйЅѓЅСЅуЁМЅВЁМЅрЄУЄнЄЄ :
txt2img ЄђЛюЭбЄЗЄЦЄЄЄыЄІЄСЄЫЁЂ8bit PCЛўТхЄЮЅЂЅЩЅйЅѓЅСЅуЁМЅВЁМЅрЄђЛзЄЄНаЄЗЄЦЄЗЄоЄУЄПЁЃ
ХіЛўЄЮЅЂЅЩЅйЅѓЅСЅуЁМЅВЁМЅрЄЯЁЂЦАЛьЄфЬОЛьЄђЅЁМЅмЁМЅЩЄЋЄщТЧЄСЙўЄѓЄЧЭЗЄжЅЙЅПЅЄЅыЄРЄУЄПЄЮЄРЄБЄЩЁФЁЃТчТЮАЪВМЄЮЄшЄІЄЪДЖЄИЄЮЅзЅьЅЄЅЙЅПЅЄЅыЄЧЁФЁЃ
ЄНЄЮЅВЁМЅрЄЮУцЄЫЁЂЄЩЄѓЄЪУБИьЄЌХаЯПЄЕЄьЄЦЄЄЄыЄЋЪЌЄЋЄщЄЪЄЄЄЋЄщЁЂЄШЄъЄЂЄЈЄКЛзЄЄЄФЄЄЄПУБИьЄђМъХіЄПЄъМЁТшЄЫТЧЄСЙўЄѓЄЧЄпЄЦЁЂХіЄПЄъЄЌНаЄПЄщРшЄЫПЪЄсЄыЁЂЄЦЄЪДЖЄИЄЧЁФЁЃЁжЅЧЅМЅЫЅщЅѓЅЩЁзЄШЄЄЄІЅВЁМЅрЄЧЁЂattach ЄШЄЄЄІУБИьЄЌЛзЄЄЄФЄЋЄЪЄЏЄЦЁЂЄНЄГЄЋЄщРшЄЫПЪЄоЄЪЄЋЄУЄПЄъЄЗЄПЄУЄБЁЃ
ВшСќРИРЎAIЄЮЅзЅэЅѓЅзЅШЄтЁЂГиНЌЅтЅЧЅыЅЧЁМЅПЄЫЄЩЄѓЄЪУБИьЄЌХаЯПЄЕЄьЄЦЄЄЄыЄЮЄЋЁЂЄЩЄЮУБИьЄЌЄЩЄѓЄЪИњВЬЄђШЏДјЄЙЄыЄЮЄЋЁЂЄНЄЮЄЂЄПЄъЄЌКЃАьЄФЪЌЄЋЄщЄЪЄЄЄтЄЮЄРЄЋЄщЁЂЛзЄЄЄФЄЄЄПБбУБИьЄђТЧЄСЙўЄѓЄЧЭЭЛвЄђИЋЄЦЁЂЄоЄПЪЬЄЮУБИьЄђТЧЄСЙўЄѓЄЧЁЂЄШЄЄЄІДЖЄИЄЫЄЪЄУЄСЄуЄІЄЪЄШЁЃ
21РЄЕЊЄЫСЩЄУЄПattachТВЄРЄшЄЪЄШЁФЁЃЦАЄЋЄЗЄЦЄЄЄыЅЯЁМЅЩЅІЅЇЅЂЄЮЅЙЅкЅУЅЏЄтЁЂAIЄЌЙдЄУЄЦЄЄЄыНшЭ§ЄтЁЂХіЛўЄШЄЯШцГгЄЫЄЪЄщЄЪЄЄЅДЅЄЅЙЄЪЅьЅйЅыЄЪЄЮЄЫЁЂЅГЅѓЅдЅхЁМЅПЄЮСАЄЫКТЄУЄЦЄыПЭДжЄЯЁЂХіЛўЄШЪбЄяЄщЄКЁЂattachТВЁФЁЃ
ЄСЄЪЄпЄЫЁЂЅЂЅЩЅйЅѓЅСЅуЁМЅВЁМЅрЄЯЁЂЦАЛьЄфЬОЛьЄђАьЁЙТЧЄСЙўЄрЅЙЅПЅЄЅыЄЋЄщЁЂИхЄЫЁЂЅсЅЫЅхЁМЄЋЄщЦАЛьЄфЬОЛьЄђСЊЄѓЄРЄъЁЂВшЬЬОхЄЫЩСВшЄЕЄьЄПГЈЄЮЄЩЄГЄЋЄЗЄщЄђЅЏЅъЅУЅЏЄЙЄыЄШОѕЖЗЄЌЪбЄяЄыЁЂЄШЄЄЄІЅЙЅПЅЄЅыЄЫЪбВНЄЗЄЦЄЄЄУЄПЄЮЄРЄБЄЩЁЃЄНЄьЄђЙЭЄЈЄыЄШЁЂЄГЄІЄЄЄУЄПВшСќРИРЎAIЄтЁЂЅсЅЫЅхЁМЄЋЄщУБИьЄђСЊЄѓЄРЄъЁЂРИРЎВшСќЄЫТаЄЗЄЦЅоЅІЅЙСрКюЄђЄЙЄыЄШЗыВЬЄЌЪбЄяЄыЁЂЄШЄЄЄУЄПЅЙЅПЅЄЅыЄЫЪбВНЄЗЄЦЄЄЄЏЄЮЄРЄэЄІЄЪЄШЁЃЄЄЄфЄоЄЂЁЂЅнЁМЅКЄђЛиФъЄЧЄЄы ControlNet ЄфЁЂВшСќЄЋЄщЪЬВшСќЄђРИРЎЄЧЄЄы img2img ЄЌЄНЄЮЄЂЄПЄъЄЫСъХіЄЙЄыЄЮЄЋЄтЄЗЄьЄЪЄЄЄБЄьЄЩЁЃ
ХіЛўЄЮЅЂЅЩЅйЅѓЅСЅуЁМЅВЁМЅрЄЯЁЂЦАЛьЄфЬОЛьЄђЅЁМЅмЁМЅЩЄЋЄщТЧЄСЙўЄѓЄЧЭЗЄжЅЙЅПЅЄЅыЄРЄУЄПЄЮЄРЄБЄЩЁФЁЃТчТЮАЪВМЄЮЄшЄІЄЪДЖЄИЄЮЅзЅьЅЄЅЙЅПЅЄЅыЄЧЁФЁЃ
> ЅЩЅІЅЙЅыЁЉ look > ЅЪЅЫЅђЁЉ door > ЅЋЅЎЅЌЅЋЅЋЅУЅЦЅЄЅыЁЃ > ЅЩЅІЅЙЅыЁЉ
ЄНЄЮЅВЁМЅрЄЮУцЄЫЁЂЄЩЄѓЄЪУБИьЄЌХаЯПЄЕЄьЄЦЄЄЄыЄЋЪЌЄЋЄщЄЪЄЄЄЋЄщЁЂЄШЄъЄЂЄЈЄКЛзЄЄЄФЄЄЄПУБИьЄђМъХіЄПЄъМЁТшЄЫТЧЄСЙўЄѓЄЧЄпЄЦЁЂХіЄПЄъЄЌНаЄПЄщРшЄЫПЪЄсЄыЁЂЄЦЄЪДЖЄИЄЧЁФЁЃЁжЅЧЅМЅЫЅщЅѓЅЩЁзЄШЄЄЄІЅВЁМЅрЄЧЁЂattach ЄШЄЄЄІУБИьЄЌЛзЄЄЄФЄЋЄЪЄЏЄЦЁЂЄНЄГЄЋЄщРшЄЫПЪЄоЄЪЄЋЄУЄПЄъЄЗЄПЄУЄБЁЃ
ВшСќРИРЎAIЄЮЅзЅэЅѓЅзЅШЄтЁЂГиНЌЅтЅЧЅыЅЧЁМЅПЄЫЄЩЄѓЄЪУБИьЄЌХаЯПЄЕЄьЄЦЄЄЄыЄЮЄЋЁЂЄЩЄЮУБИьЄЌЄЩЄѓЄЪИњВЬЄђШЏДјЄЙЄыЄЮЄЋЁЂЄНЄЮЄЂЄПЄъЄЌКЃАьЄФЪЌЄЋЄщЄЪЄЄЄтЄЮЄРЄЋЄщЁЂЛзЄЄЄФЄЄЄПБбУБИьЄђТЧЄСЙўЄѓЄЧЭЭЛвЄђИЋЄЦЁЂЄоЄПЪЬЄЮУБИьЄђТЧЄСЙўЄѓЄЧЁЂЄШЄЄЄІДЖЄИЄЫЄЪЄУЄСЄуЄІЄЪЄШЁЃ
21РЄЕЊЄЫСЩЄУЄПattachТВЄРЄшЄЪЄШЁФЁЃЦАЄЋЄЗЄЦЄЄЄыЅЯЁМЅЩЅІЅЇЅЂЄЮЅЙЅкЅУЅЏЄтЁЂAIЄЌЙдЄУЄЦЄЄЄыНшЭ§ЄтЁЂХіЛўЄШЄЯШцГгЄЫЄЪЄщЄЪЄЄЅДЅЄЅЙЄЪЅьЅйЅыЄЪЄЮЄЫЁЂЅГЅѓЅдЅхЁМЅПЄЮСАЄЫКТЄУЄЦЄыПЭДжЄЯЁЂХіЛўЄШЪбЄяЄщЄКЁЂattachТВЁФЁЃ
ЄСЄЪЄпЄЫЁЂЅЂЅЩЅйЅѓЅСЅуЁМЅВЁМЅрЄЯЁЂЦАЛьЄфЬОЛьЄђАьЁЙТЧЄСЙўЄрЅЙЅПЅЄЅыЄЋЄщЁЂИхЄЫЁЂЅсЅЫЅхЁМЄЋЄщЦАЛьЄфЬОЛьЄђСЊЄѓЄРЄъЁЂВшЬЬОхЄЫЩСВшЄЕЄьЄПГЈЄЮЄЩЄГЄЋЄЗЄщЄђЅЏЅъЅУЅЏЄЙЄыЄШОѕЖЗЄЌЪбЄяЄыЁЂЄШЄЄЄІЅЙЅПЅЄЅыЄЫЪбВНЄЗЄЦЄЄЄУЄПЄЮЄРЄБЄЩЁЃЄНЄьЄђЙЭЄЈЄыЄШЁЂЄГЄІЄЄЄУЄПВшСќРИРЎAIЄтЁЂЅсЅЫЅхЁМЄЋЄщУБИьЄђСЊЄѓЄРЄъЁЂРИРЎВшСќЄЫТаЄЗЄЦЅоЅІЅЙСрКюЄђЄЙЄыЄШЗыВЬЄЌЪбЄяЄыЁЂЄШЄЄЄУЄПЅЙЅПЅЄЅыЄЫЪбВНЄЗЄЦЄЄЄЏЄЮЄРЄэЄІЄЪЄШЁЃЄЄЄфЄоЄЂЁЂЅнЁМЅКЄђЛиФъЄЧЄЄы ControlNet ЄфЁЂВшСќЄЋЄщЪЬВшСќЄђРИРЎЄЧЄЄы img2img ЄЌЄНЄЮЄЂЄПЄъЄЫСъХіЄЙЄыЄЮЄЋЄтЄЗЄьЄЪЄЄЄБЄьЄЩЁЃ
Ё§ ГиНЌЄЗЄЦЄЪЄЄЅтЅЮЄЯНаЄЦЄГЄЪЄЄ :
ХіЄПЄъСАЄРЄБЄЩЁЂГиНЌЄЗЄЦЄЄЄЪЄЄВшСќЄЫДиЄЗЄЦЄЯРИРЎЗыВЬЄЫНаЄЦЄГЄЪЄЄЄЮЄЧЁЂЄЪЄѓЄРЄЋЛФЧАЄРЄЪЄШДЖЄИЄыНжДжЄЌЄЂЄыЄЪЄШЁФЁЃЮуЄЈЄаЁЂЁжЅЌЅѓЅРЅрЁзЄфЁжЅЩЅщЄЈЄтЄѓЁзЄШТЧЄСЙўЄѓЄЧЄпЄПЄщЁЂЁжЅЌЅѓЅЌЅыЁзЄфЁжЄІЄоЄЈЄтЄѓЁзЄЫЄЙЄщЖсЄХЄБЄЦЄЄЄЪЄЄФСЬЏВшСќЄЌНаЄЦЄЄЦЄЗЄоЄУЄЦЁЂЄЪЄѓЄШЄЄЄІЄЋЁФЁЃ
ЄЧЄтЄоЄЂЁЂПЭДжЄРЄУЄЦЁЂЁжЅЌЅѓЅРЅрЄђЩСЄБЁзЁжЅЩЅщЄЈЄтЄѓЄђЩСЄБЁзЄШИРЄяЄьЄПЄщЁЂЅеЅФЁМЄЮПЭЄЯФСЬЏЄЪЦцЅЅуЅщЅЏЅПЁМЄђЩСЄЄЄСЄуЄІЄяЄБЄРЄЋЄщЁЂЄНЄІЙЭЄЈЄыЄШЁЂAIЄтПЭДжЄШЦБЄИЁЂЄЪЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃЄЗЄУЄЋЄъГиНЌЄЗЄЦЄЪЄЄЄтЄЮЄЯЁЂAIЄтЁЂПЭДжЄтЁЂНаЮЯЄЧЄЄЪЄЄЄшЄЪЁЃ
ЄЧЄтЄоЄЂЁЂПЭДжЄРЄУЄЦЁЂЁжЅЌЅѓЅРЅрЄђЩСЄБЁзЁжЅЩЅщЄЈЄтЄѓЄђЩСЄБЁзЄШИРЄяЄьЄПЄщЁЂЅеЅФЁМЄЮПЭЄЯФСЬЏЄЪЦцЅЅуЅщЅЏЅПЁМЄђЩСЄЄЄСЄуЄІЄяЄБЄРЄЋЄщЁЂЄНЄІЙЭЄЈЄыЄШЁЂAIЄтПЭДжЄШЦБЄИЁЂЄЪЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃЄЗЄУЄЋЄъГиНЌЄЗЄЦЄЪЄЄЄтЄЮЄЯЁЂAIЄтЁЂПЭДжЄтЁЂНаЮЯЄЧЄЄЪЄЄЄшЄЪЁЃ
[ ЅФЅУЅГЄр ]
2023/04/11(Ва) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] img2imgЄЫЄФЄЄЄЦЪйЖЏУц
ВшСќРИРЎAIЁЂStable Diffusion web UI ЄЫДоЄоЄьЄЦЄЄЄыЁЂimg2img ЄШЄЄЄІЅФЁМЅыЄЮЛШЄЄЪ§ЄЫЄФЄЄЄЦЪйЖЏУцЁЃ
Stable Diffusion web UI ЄЯЁЂТчЪЬЄЗЄЦЁЂ2МяЮрЄЮВшСќРИРЎЅФЁМЅыЄђЛ§ЄУЄЦЄЄЄыЁЂЄшЄІЄЫИЋЄЈЄыЁЃ
txt2img ЄЧЭпЄЗЄЄВшСќЄЌЦРЄщЄьЄЪЄЋЄУЄПКнЄЫЁЂЄНЄЮРИРЎВшСќЄђ img2img ЄЫХЯЄЗЄЦЁЂВПЄЋЄЗЄщЄЮНЄРЕЄђВУЄЈЄЦЄЋЄщРИРЎНшЭ§ЄђЄЙЄыЄГЄШЄЧЁЂЬмХЊЄЮВшСќЄЫЖсЄХЄБЄЦЄЄЄЏЄГЄШЄЌЄЧЄЄЪЄЏЄтЄЪЄЄЁЂЄщЄЗЄЄЁЃ
ЄШЄъЄЂЄЈЄКЁЂWebЅжЅщЅІЅЖОхЄЧЩНМЈЄЕЄьЄЦЄЄЄы Stable Diffusion web UI ЄЮЅкЁМЅИЄЧЁЂimg2imgЅПЅжЄђЅЏЅъЅУЅЏЄЗЄЦЁЂЅЅуЅѓЅаЅЙЄЫВшСќЄђЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзИхЁЂDenoising strength ЄђРпФъЄЗЄЦЄЋЄщ Generate ЄђЅЏЅъЅУЅЏЄЙЄьЄаЁЂИЕВшСќЄЋЄщЮрПфЄЧЄЄыЪЬЄЮВшСќЄђРИРЎЄЗЄЦЄЏЄьЄыЁЂЄШЄГЄэЄоЄЧЄЯЪЌЄЋЄУЄПЁЃDenoising strength ЄЌОЎЄЕЄБЄьЄаИЕВшСќЄЫЖсЄЏЁЂТчЄЄБЄьЄаИЕВшСќЄЋЄщЮЅЄьЄыЁЂЄщЄЗЄЄЁЃЄПЄжЄѓЁЃ
ЄоЄПЁЂSketch ЄШ inpaint ЄтЁЂЄЪЄѓЄШЄЪЄЏЪЌЄЋЄУЄЦЄЄПЁЃ
ЄНЄьЄЯЄШЄтЄЋЄЏЁЂinpaint sketch ЄЮЛШЄЄЪ§ЄЌЪЌЄЋЄщЄЪЄЄЁФЁЃinpaint + sketch ЄЮЕЁЧНЄђЛ§ЄУЄЦЄыЄШЄЄЄІЄГЄШЄРЄэЄІЄЋЁФЁЉ
ЄНЄЮЄЂЄПЄъЄЮЛШЄЄЪ§ЄЌЪЌЄЋЄщЄЪЄЄЄЮЄЧЁЂАЪВМЄЮЄшЄІЄЪЮЎЄьЄЧКюЖШЄЗЄЦЄЗЄоЄУЄЦЄЄЄыЁЃ
ЭОУЬЁЃimg2img ЄЮВшСќЄђЩНМЈЄЙЄыЅЅуЅѓЅаЅЙЄЌОЎЄЕВсЄЎЄЦЁЂКйЄЋЄЄЛиФъЄЌЄЧЄЄЪЄЄЄЂЄПЄъЄЌЅФЅщЅЄЁЃЄтЄЗЄЋЄЙЄыЄШ GIMPХљЄЧВшСќЄђГЋЄЄЄЦНЄРЕЄЗЄЦЄЋЄщХЯЄЗЄЦЄЗЄоЄУЄПЄлЄІЄЌГкЄЪЄЮЄЧЄЯЁФЁЃЄЄЄфЄоЄЂЁЂКйЄЋЄЏЩСЄЙўЄѓЄЧЄпЄЦЄтСДСГАуЄІВшСќЄЌНаЄЦЄЏЄыЄЮЄРЄЋЄщЁЂЄЖЄУЄЏЄъЛиФъЄЌЄЧЄЄьЄаНМЪЌЄфЄэЄШЄЄЄІЕЄЄтЄЙЄыЄБЄьЄЩЁЃ
Stable Diffusion web UI ЄЯЁЂТчЪЬЄЗЄЦЁЂ2МяЮрЄЮВшСќРИРЎЅФЁМЅыЄђЛ§ЄУЄЦЄЄЄыЁЂЄшЄІЄЫИЋЄЈЄыЁЃ
- txt2img : БбЪИЄфБбУБИьЄђТЧЄСЙўЄрЄШЁЂЄНЄЮЦтЭЦЄЫБшЄУЄПВшСќЄђРИРЎЄЗЄЦЄЏЄьЄыЁЃ
- img2img : ВшСќЄђЭПЄЈЄыЄШЁЂЄНЄЮВшСќЄЋЄщЮрПфЄЧЄЄыВшСќЄђРИРЎЄЗЄЦЄЏЄьЄыЁЃ
txt2img ЄЧЭпЄЗЄЄВшСќЄЌЦРЄщЄьЄЪЄЋЄУЄПКнЄЫЁЂЄНЄЮРИРЎВшСќЄђ img2img ЄЫХЯЄЗЄЦЁЂВПЄЋЄЗЄщЄЮНЄРЕЄђВУЄЈЄЦЄЋЄщРИРЎНшЭ§ЄђЄЙЄыЄГЄШЄЧЁЂЬмХЊЄЮВшСќЄЫЖсЄХЄБЄЦЄЄЄЏЄГЄШЄЌЄЧЄЄЪЄЏЄтЄЪЄЄЁЂЄщЄЗЄЄЁЃ
ЄШЄъЄЂЄЈЄКЁЂWebЅжЅщЅІЅЖОхЄЧЩНМЈЄЕЄьЄЦЄЄЄы Stable Diffusion web UI ЄЮЅкЁМЅИЄЧЁЂimg2imgЅПЅжЄђЅЏЅъЅУЅЏЄЗЄЦЁЂЅЅуЅѓЅаЅЙЄЫВшСќЄђЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзИхЁЂDenoising strength ЄђРпФъЄЗЄЦЄЋЄщ Generate ЄђЅЏЅъЅУЅЏЄЙЄьЄаЁЂИЕВшСќЄЋЄщЮрПфЄЧЄЄыЪЬЄЮВшСќЄђРИРЎЄЗЄЦЄЏЄьЄыЁЂЄШЄГЄэЄоЄЧЄЯЪЌЄЋЄУЄПЁЃDenoising strength ЄЌОЎЄЕЄБЄьЄаИЕВшСќЄЫЖсЄЏЁЂТчЄЄБЄьЄаИЕВшСќЄЋЄщЮЅЄьЄыЁЂЄщЄЗЄЄЁЃЄПЄжЄѓЁЃ
ЄоЄПЁЂSketch ЄШ inpaint ЄтЁЂЄЪЄѓЄШЄЪЄЏЪЌЄЋЄУЄЦЄЄПЁЃ
- Sketch : ЄЊГЈЩСЄЅтЁМЅЩЁЃЄЖЄУЄЏЄъЄШЄЗЄПВшСќЄђЄНЄЮОьЄЧКюРЎЄЧЄЄыЁЃИЕВшСќЄђ Sketch ЄЫХОСїИхЁЂОУЕюЄЗЄПЄЄЩєЪЌЄђЅжЅщЅЗЄЧОхНёЄЄЗЄЦЄЋЄщРИРЎНшЭ§ЁЂЄШЄЄЄУЄПЄГЄШЄтЄЧЄЄыЁЃ
- inpaint : ЅоЅЙЅЏЛиФъЅтЁМЅЩЁЃЅоЅЙЅЏЄЮУцЁЂЄтЄЗЄЏЄЯГАЄРЄБЄђЁЂРИРЎЄЗЄЦЩСВшЄЙЄыЄГЄШЄЌЄЧЄЄыЁЃ
ЄНЄьЄЯЄШЄтЄЋЄЏЁЂinpaint sketch ЄЮЛШЄЄЪ§ЄЌЪЌЄЋЄщЄЪЄЄЁФЁЃinpaint + sketch ЄЮЕЁЧНЄђЛ§ЄУЄЦЄыЄШЄЄЄІЄГЄШЄРЄэЄІЄЋЁФЁЉ
ЄНЄЮЄЂЄПЄъЄЮЛШЄЄЪ§ЄЌЪЌЄЋЄщЄЪЄЄЄЮЄЧЁЂАЪВМЄЮЄшЄІЄЪЮЎЄьЄЧКюЖШЄЗЄЦЄЗЄоЄУЄЦЄЄЄыЁЃ
- ИЕВшСќЄђЦЩЄпЙўЄпЁЃ
- Sketch ЄЫХОСїЁЃ
- ЩдЭзЄЪЩєЪЌЄђПЇЄЧХЩЄъФйЄЗЁЃ
- inpaint ЄЫХОСїЁЃ
- ХЩЄъФйЄЗЄПЩєЪЌЄЫЅоЅЙЅЏЄђКюРЎЁЃ
- ЅоЅЙЅЏЄЮУцЄРЄБВшСќРИРЎЁЃ
ЭОУЬЁЃimg2img ЄЮВшСќЄђЩНМЈЄЙЄыЅЅуЅѓЅаЅЙЄЌОЎЄЕВсЄЎЄЦЁЂКйЄЋЄЄЛиФъЄЌЄЧЄЄЪЄЄЄЂЄПЄъЄЌЅФЅщЅЄЁЃЄтЄЗЄЋЄЙЄыЄШ GIMPХљЄЧВшСќЄђГЋЄЄЄЦНЄРЕЄЗЄЦЄЋЄщХЯЄЗЄЦЄЗЄоЄУЄПЄлЄІЄЌГкЄЪЄЮЄЧЄЯЁФЁЃЄЄЄфЄоЄЂЁЂКйЄЋЄЏЩСЄЙўЄѓЄЧЄпЄЦЄтСДСГАуЄІВшСќЄЌНаЄЦЄЏЄыЄЮЄРЄЋЄщЁЂЄЖЄУЄЏЄъЛиФъЄЌЄЧЄЄьЄаНМЪЌЄфЄэЄШЄЄЄІЕЄЄтЄЙЄыЄБЄьЄЩЁЃ
[ ЅФЅУЅГЄр ]
2023/04/12(Пх) [nЧЏСАЄЮЦќЕ]
#1 [windows][pc] ЅсЅЄЅѓPCЄЌBSOD
ЅсЅЄЅѓPCЁЂWindows10 x64 22H2ЕЁЄЌЁЂЕзЁЙЄЫЅжЅыЁМЅЙЅЏЅъЁМЅѓ(BSOD)ЄЫЄЪЄУЄПЁЃВшЬЬЄЫЄЯЁЂЁжФфЛпЅГЁМЅЩ : SYSTEM_THREAD_EXCEPTION_NOT_HANDLEDЁзЁжМКЧдЄЗЄПЦтЭЦ : Ntfs.sysЁзЄШЩНМЈЄЕЄьЄЦЄыЁЃ
РшЦќЁЂDЅЩЅщЅЄЅжЄЮHDDЄђИђДЙЄЗЄЦАЪЭшЁЂBSODЄЯЄКЄУЄШШЏРИЄЗЄЦЄЪЄЋЄУЄПЄЮЄЧЁЂЄЕЄЦЄЯАЪСАЛШЄУЄЦЄПHDDЄЌВѕЄьЄЋЄБЄЦЄЄЄЦЁЂЄНЄьЄЌИЖАјЄЧBSODЄЫЄЪЄУЄЦЄЄЄПЄЮЄЋЄЪЄШЭНСлЄЗЄЦЄЄЄПЄЮЄРЄБЄЩЁЂЄЩЄІЄфЄщЄНЄЮЭНСлЄЯГАЄьЄЦЄЄЄПЄщЄЗЄЄЁЃHDDЄЯДиЗИЬЕЄЕЄНЄІЄРЄЪЁФЁЃЄШЄЪЄыЄШЁЂSSDЄЌВјЄЗЄЄЄШЄЗЄЋЛзЄЈЄЪЄЄЁФЁЃ
ЄГЄьЄЯЄЂЄЏЄоЄЧСлСќЄРЄБЄЩЁЂSSDОхЄЫGBУБАЬЄЮЕ№ТчЄЪЅеЅЁЅЄЅыЄЌКюЄщЄьЄЦЁЂЄЋЄФЁЂВПЄЋЄЮЅЕЁМЅгЅЙЄЌЁЂЄНЄЮЕ№ТчЄЪЅеЅЁЅЄЅыЄђЅЕЁМЅСЄЗЛЯЄсЄыЄШЁЂSSDЄЮШПБўЄШЄЄЄІЄЋХОСїТЎХйЄЌЁЂЄЂЄыОђЗяВМЄЧЖЫУМЄЫУйЄЏЄЪЄУЄЦЁЂЁжSSDЄЌЪжЛіЄђЄЗЄЦЄЏЄьЄЪЄЄЁЃЄГЄьЄЯЄЊЄЋЄЗЄЄЄОЁзЄШBSODЄЫЄЪЄыЄЮЄЧЄЯЄЪЄЄЄЋЁЂЄШЄЄЄІЕЄЄЌЄЗЄЦЄЄЄыЁЃWindows Defender ЄШЄЋЁЂMicrosoft Compatibility Telemetry ЄШЄЋЁЂЄНЄЮЄЂЄПЄъЄЌЬЏЄЪЅЂЅЏЅЛЅЙЄђЄЗЄЦЄЄЄыЄЮЄЧЄЯЄЪЄЄЄЋЄШЕПЄУЄЦЄЄЄыЄЮЄРЄБЄЩЁФЁЃBSOD ЄЫЄЪЄыФОСАЄЫЄЩЄѓЄЪЅЕЁМЅгЅЙЄЌГЋЛЯЄЕЄьЄЦЄЄЄыЄЮЄЋЁЂГЮЧЇЄЙЄыЪ§ЫЁЄЌЛзЄЄЄФЄЋЄЪЄЏЄЦЁФЁЃ
ЄНЄтЄНЄтЁЂЅЕЁМЅгЅЙЄЩЄІЄГЄІАЪСАЄЫЁЂЛШЄУЄЦЄЄЄыSSDЁЂcrucial MX500 CT500MX500SSD1/JP ЄЌЅРЅсЄЪЄЮЄЧЄЯЄЪЄЄЄЋЁФЁЃНщДќЩдЮЩЩЪЄЋЁЂЅеЅЁЁМЅрЅІЅЇЅЂЄЌЅаЅАЄУЄЦЄыЄѓЄИЄуЄЪЄЄЄЮЄЋЁФЁЃЄЧЄтЁЂЄЋЄЪЄъПєЄЌНаЄЦЄыРНЩЪЄРЄЋЄщЁЂВОЄЫЅеЅЁЁМЅрЅІЅЇЅЂЄЮЅаЅАЄЪЄщЁЂЦБМяЄЮЛіЮуЄЌЩбШЫЄЫЬмЄЫЦўЄУЄЦЄтЄЊЄЋЄЗЄЏЄЪЄЄЄшЄІЄЪЕЄЄтЄЙЄыЄЗЁФЁЃЄШЄЪЄыЄШНщДќЩдЮЩЩЪЄЪЄѓЄРЄэЄІЄЋЁФЁЃЄЧЄтЁЂЩсУЪЄЯЅеЅФЁМЄЫЛШЄЈЄЦЄЄЄыЄЗЁЃВПЄЋЄЮОђЗяЄЌТЗЄУЄПЛўЄРЄБЩдЖёЙчЄђЕЏЄГЄЙЕЄЧлЄЌЄЙЄыЄяЄБЄЧЁЃ
РшЦќЁЂDЅЩЅщЅЄЅжЄЮHDDЄђИђДЙЄЗЄЦАЪЭшЁЂBSODЄЯЄКЄУЄШШЏРИЄЗЄЦЄЪЄЋЄУЄПЄЮЄЧЁЂЄЕЄЦЄЯАЪСАЛШЄУЄЦЄПHDDЄЌВѕЄьЄЋЄБЄЦЄЄЄЦЁЂЄНЄьЄЌИЖАјЄЧBSODЄЫЄЪЄУЄЦЄЄЄПЄЮЄЋЄЪЄШЭНСлЄЗЄЦЄЄЄПЄЮЄРЄБЄЩЁЂЄЩЄІЄфЄщЄНЄЮЭНСлЄЯГАЄьЄЦЄЄЄПЄщЄЗЄЄЁЃHDDЄЯДиЗИЬЕЄЕЄНЄІЄРЄЪЁФЁЃЄШЄЪЄыЄШЁЂSSDЄЌВјЄЗЄЄЄШЄЗЄЋЛзЄЈЄЪЄЄЁФЁЃ
ЄГЄьЄЯЄЂЄЏЄоЄЧСлСќЄРЄБЄЩЁЂSSDОхЄЫGBУБАЬЄЮЕ№ТчЄЪЅеЅЁЅЄЅыЄЌКюЄщЄьЄЦЁЂЄЋЄФЁЂВПЄЋЄЮЅЕЁМЅгЅЙЄЌЁЂЄНЄЮЕ№ТчЄЪЅеЅЁЅЄЅыЄђЅЕЁМЅСЄЗЛЯЄсЄыЄШЁЂSSDЄЮШПБўЄШЄЄЄІЄЋХОСїТЎХйЄЌЁЂЄЂЄыОђЗяВМЄЧЖЫУМЄЫУйЄЏЄЪЄУЄЦЁЂЁжSSDЄЌЪжЛіЄђЄЗЄЦЄЏЄьЄЪЄЄЁЃЄГЄьЄЯЄЊЄЋЄЗЄЄЄОЁзЄШBSODЄЫЄЪЄыЄЮЄЧЄЯЄЪЄЄЄЋЁЂЄШЄЄЄІЕЄЄЌЄЗЄЦЄЄЄыЁЃWindows Defender ЄШЄЋЁЂMicrosoft Compatibility Telemetry ЄШЄЋЁЂЄНЄЮЄЂЄПЄъЄЌЬЏЄЪЅЂЅЏЅЛЅЙЄђЄЗЄЦЄЄЄыЄЮЄЧЄЯЄЪЄЄЄЋЄШЕПЄУЄЦЄЄЄыЄЮЄРЄБЄЩЁФЁЃBSOD ЄЫЄЪЄыФОСАЄЫЄЩЄѓЄЪЅЕЁМЅгЅЙЄЌГЋЛЯЄЕЄьЄЦЄЄЄыЄЮЄЋЁЂГЮЧЇЄЙЄыЪ§ЫЁЄЌЛзЄЄЄФЄЋЄЪЄЏЄЦЁФЁЃ
ЄНЄтЄНЄтЁЂЅЕЁМЅгЅЙЄЩЄІЄГЄІАЪСАЄЫЁЂЛШЄУЄЦЄЄЄыSSDЁЂcrucial MX500 CT500MX500SSD1/JP ЄЌЅРЅсЄЪЄЮЄЧЄЯЄЪЄЄЄЋЁФЁЃНщДќЩдЮЩЩЪЄЋЁЂЅеЅЁЁМЅрЅІЅЇЅЂЄЌЅаЅАЄУЄЦЄыЄѓЄИЄуЄЪЄЄЄЮЄЋЁФЁЃЄЧЄтЁЂЄЋЄЪЄъПєЄЌНаЄЦЄыРНЩЪЄРЄЋЄщЁЂВОЄЫЅеЅЁЁМЅрЅІЅЇЅЂЄЮЅаЅАЄЪЄщЁЂЦБМяЄЮЛіЮуЄЌЩбШЫЄЫЬмЄЫЦўЄУЄЦЄтЄЊЄЋЄЗЄЏЄЪЄЄЄшЄІЄЪЕЄЄтЄЙЄыЄЗЁФЁЃЄШЄЪЄыЄШНщДќЩдЮЩЩЪЄЪЄѓЄРЄэЄІЄЋЁФЁЃЄЧЄтЁЂЩсУЪЄЯЅеЅФЁМЄЫЛШЄЈЄЦЄЄЄыЄЗЁЃВПЄЋЄЮОђЗяЄЌТЗЄУЄПЛўЄРЄБЩдЖёЙчЄђЕЏЄГЄЙЕЄЧлЄЌЄЙЄыЄяЄБЄЧЁЃ
[ ЅФЅУЅГЄр ]
2023/04/13(Ьк) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] img2imgЄђЛюЭбУц
ВшСќРИРЎAIЁЂStable Diffusion web UI ЄЮЁЂimg2img ЄђЛШЄУЄЦЁЂВшСќЄЋЄщЪЬВшСќЄђРИРЎЄЙЄыКюЖШЄЮЮЎЄьЄђГЮЧЇУцЁЃ
img2img ЄЯЁЂИЕВшСќЄђХЯЄЙЄШЁЂЄНЄГЄЋЄщЮрПфЄЕЄьЄыЪЬВшСќЄђРИРЎЄЗЄЦЄЏЄьЄыЅФЁМЅыЁЃЅзЅэЅѓЅзЅШЄШИЦЄаЄьЄыМіЪИЄтЭПЄЈЄыЄГЄШЄЧЁЂРИРЎЄЙЄыВшСќЄЮЗЙИўЄђЪбВНЄЕЄЛЄыЄГЄШЄтЄЧЄЄыЁЃ
ЄЛЄУЄЋЄЏЄРЄЋЄщМТИГЗыВЬЄтЅсЅтЄЗЄЦЄЊЄГЄІЁФЁЃЄЄЄфЄоЄЂЁЂРшПЭУЃЄЌЄтЄУЄШЬђЄЫЮЉЄФО№ЪѓЄђПяЪЌСАЄЋЄщТПЁЙИјГЋЄЗЄЦЄЏЄьЄЦЄыЄЮЄЧЁЂКЃЙЙЄГЄѓЄЪО№ЪѓЄђЅЂЅУЅзЄЗЄЦЄтАеЬЃЄЯЬЕЄЕЄНЄІЄРЄБЄЩЁЃ
img2img ЄЯЁЂИЕВшСќЄђХЯЄЙЄШЁЂЄНЄГЄЋЄщЮрПфЄЕЄьЄыЪЬВшСќЄђРИРЎЄЗЄЦЄЏЄьЄыЅФЁМЅыЁЃЅзЅэЅѓЅзЅШЄШИЦЄаЄьЄыМіЪИЄтЭПЄЈЄыЄГЄШЄЧЁЂРИРЎЄЙЄыВшСќЄЮЗЙИўЄђЪбВНЄЕЄЛЄыЄГЄШЄтЄЧЄЄыЁЃ
ЄЛЄУЄЋЄЏЄРЄЋЄщМТИГЗыВЬЄтЅсЅтЄЗЄЦЄЊЄГЄІЁФЁЃЄЄЄфЄоЄЂЁЂРшПЭУЃЄЌЄтЄУЄШЬђЄЫЮЉЄФО№ЪѓЄђПяЪЌСАЄЋЄщТПЁЙИјГЋЄЗЄЦЄЏЄьЄЦЄыЄЮЄЧЁЂКЃЙЙЄГЄѓЄЪО№ЪѓЄђЅЂЅУЅзЄЗЄЦЄтАеЬЃЄЯЬЕЄЕЄНЄІЄРЄБЄЩЁЃ
Ё§ МТИГЄНЄЮ1 :
ЄШЄъЄЂЄЈЄКЁЂPoser Pro 11 ЄђЛШЄУЄЦЁЂ512 x 512 ЄЮЁЂНїЄЮЛвЄЮВшСќЄђЅьЅѓЅРЅъЅѓЅАЄЗЄЦЁЂЄНЄьЄђИЕВшСќЄЫЄЗЄЦМТИГЁЃИЕВшСќЄЯАЪВМЁЃ

МТЄЫЅЅтЄЄЄЧЄЙЄЭЁФЁЃ
ГиНЌЅтЅЧЅыЅЧЁМЅПЄЯЁЂv2-1_768-ema-pruned.ckpt ЄђЛШЄУЄЦЄпЄПЁЃ
img2img ЄЫИЕВшСќЄђЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзЄЧХЯЄЗЄЦЁЂЅзЅэЅѓЅзЅШЄЫЄЯЁж1girlЁзЄШЦўЮЯЁЃАЪВМЄЮВшСќЄЌРИРЎЄЕЄьЄПЁЃ



ЄПЄЗЄЋЄЫВшСќЄЌРИРЎЄЕЄьЄПЁЃРИРЎЄЕЄьЄПЄБЄЩЁЂЄГЄьЄЮЄЩЄГЄщЄиЄѓЄЌЁжgirlЁзЄфЄЭЄѓЁЉ AIЗЏЄЫЄЯЁжgirlЁзЄУЄЦЄГЄІИЋЄЈЄЦЄыЄЮЁЉ
МТЄЫЅЅтЄЄЄЧЄЙЄЭЁФЁЃ
ГиНЌЅтЅЧЅыЅЧЁМЅПЄЯЁЂv2-1_768-ema-pruned.ckpt ЄђЛШЄУЄЦЄпЄПЁЃ
img2img ЄЫИЕВшСќЄђЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзЄЧХЯЄЗЄЦЁЂЅзЅэЅѓЅзЅШЄЫЄЯЁж1girlЁзЄШЦўЮЯЁЃАЪВМЄЮВшСќЄЌРИРЎЄЕЄьЄПЁЃ
parameters 1girl, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1972562182, Size: 512x512, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.75
ЄПЄЗЄЋЄЫВшСќЄЌРИРЎЄЕЄьЄПЁЃРИРЎЄЕЄьЄПЄБЄЩЁЂЄГЄьЄЮЄЩЄГЄщЄиЄѓЄЌЁжgirlЁзЄфЄЭЄѓЁЉ AIЗЏЄЫЄЯЁжgirlЁзЄУЄЦЄГЄІИЋЄЈЄЦЄыЄЮЁЉ
Ё§ МТИГЄНЄЮ2 :
Denoising strength ЄЮУЭЄЌЅЧЅеЅЉЅыЅШЄЮ 0.75 ЄЧНшЭ§ЄЕЄЛЄыЄШОхЕЄЮЄшЄІЄЪЗыВЬЄЌНаЄЦЄЏЄыЄБЄьЄЩЁЂПєУЭЄђВМЄВЄьЄаИЕВшСќЄЫБшЄУЄПРИРЎНшЭ§ЄЫЄЪЄУЄЦЄЏЄьЄыЄщЄЗЄЄЁЃ0.5 ЄоЄЧВМЄВЄЦЄпЄыЄШЁЂРИРЎЄЕЄьЄыВшСќЄЌЪбЄяЄУЄЦЄЄПЁЃ








КЃХйЄЯОЏЄЗЄРЄБЁжgirlЁзЄщЄЗЄЄРИРЎВшСќЄЫЄЪЄУЄЦЄЄПЁЃЄтЄУЄШЄтЁЂЅИЅчЅИЅчЄЮЅЙЅПЅѓЅЩЄЮНаЭшТЛЄЪЄЄЄпЄПЄЄЄЪИЋЄПЬмЄРЄЪЄШЁФЁЃЄШЄЄЄІЄЋЅГЅьЁЂЅаЅШЅыЄЧЧдЫЬЄЗЄЦЄЄЄЏЄШЄЄЮЅЙЅПЅѓЅЩЄИЄуЄЪЄЄЄЋЄЪЁЃ
parameters 1girl, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1147899033, Size: 512x512, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.5
КЃХйЄЯОЏЄЗЄРЄБЁжgirlЁзЄщЄЗЄЄРИРЎВшСќЄЫЄЪЄУЄЦЄЄПЁЃЄтЄУЄШЄтЁЂЅИЅчЅИЅчЄЮЅЙЅПЅѓЅЩЄЮНаЭшТЛЄЪЄЄЄпЄПЄЄЄЪИЋЄПЬмЄРЄЪЄШЁФЁЃЄШЄЄЄІЄЋЅГЅьЁЂЅаЅШЅыЄЧЧдЫЬЄЗЄЦЄЄЄЏЄШЄЄЮЅЙЅПЅѓЅЩЄИЄуЄЪЄЄЄЋЄЪЁЃ
Ё§ МТИГЄНЄЮ3 :
ЙтВшМСВНЄђСРЄЈЄыЄщЄЗЄЄЅзЅэЅѓЅзЅШЄђТЧЄСЙўЄѓЄЧЄпЄыЁЃ
ЄЖЄУЄЏЄъРтЬРЄЙЄыЄШЁФЁЃ
ВУЄЈЄЦЁЂDenoising strength Єђ 0.4 ЄЫМхЄсЄЦЄпЄПЁЃ
ЄоЄПЁЂCFG scale ЄђЁЂ7 ЄЋЄщ 5 ЄЫИКЄщЄЗЄЦЄпЄПЁЃCFG scale ЄЯЁЂПєУЭЄЌТчЄЄЄЄШЅзЅэЅѓЅзЅШЄЮЦтЭЦЄЫНОЄЊЄІЄШЄЙЄыЄБЄьЄЩЁЂЄНЄЮЪЌЬЕЭ§ЄЪДЖЄИЄЮЙчРЎЄђЄЙЄыЄЮЄЧВшСќЄЮЧЫУОЄЌС§ЄЈЛЯЄсЄЦЁЂПєУЭЄЌОЎЄЕЄЄЄШЅзЅэЅѓЅзЅШЄЮЦтЭЦЄЋЄщЮЅЄьЄЦAIЄЌМЋЪЌОЁМъЄЫЙчРЎЄЙЄыЄБЄЩЁЂЄНЄЮЪЌЧЫУОЄЗЄЫЄЏЄЄВшСќЄЌРИРЎЄЕЄьЄфЄЙЄЏЄЪЄыЁЂЄщЄЗЄЄЁЃ
ЁжЄщЄЗЄЄЁзЁжЄПЄжЄѓЁзЄаЄЋЄъНёЄЄЄЦЄЂЄыЄБЄЩЁЂЄЩЄьЄтЫмХіЄЫИњВЬЄЌНаЄЦЄыЄЮЄЋЁЂЄНЄІЄЄЄІВђМсЄЧЄЄЄЄЄЮЄЋЁЂЄСЄчЄУЄШМЋПЎЄЌЬЕЄЄЁФЁЃ




ЄЋЄЪЄъВўСБЄЕЄьЄЦЄЄПЄБЄЩЁФЁЃЬДЄЮУцЄЫНаЄЦЄЄПЄщЁЂЄІЄЪЄЕЄьЄНЄІЄЧЄЙЁФЁЃ
- Postivie prompt : masterpiece, best quality, photo realistic, realistic,
- Negative prompt : painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality, ((monochrome)), ((grayscale)),
ЄЖЄУЄЏЄъРтЬРЄЙЄыЄШЁФЁЃ
- Positive Prompt ЄЫЄЯЁЂЁжЄГЄІЄЄЄІВшСќЄђНаЄЗЄЦЄЏЄьЁзХЊЄЪЅЁМЅяЁМЅЩЄђЮѓЕѓЄЙЄыЁЃ
- Negative Prompt ЄЫЄЯЁЂЁжЄГЄІЄЄЄІВшСќЄЯШђЄБЄЦЄЏЄьЁзХЊЄЪЅЁМЅяЁМЅЩЄђЮѓЕѓЄЙЄыЁЃ
- Postitive prompt ЄЫ "masterpiece, best quality, " ЄђЛиФъЄЙЄыЄШЁЂЙтВшМСВНЄЌСРЄЈЄыЁЃЄщЄЗЄЄЁЃЄПЄжЄѓЁЃ
- "photo realistic, realistic, " ЄђЛиФъЄЙЄыЄШЁЂМЬМТХЊЄЪИЋЄПЬмЄЫДѓЄЛЄЦЄЏЄьЄыЁЃЄщЄЗЄЄЁЃЄПЄжЄѓЁЃ
- Negative prompt ЄЫ "painting, sketches, " ЄђЛиФъЄЙЄыЄШЁЂЄЊЄНЄщЄЏМъЩСЄЩїЄђШђЄБЄЦЄЏЄьЄыЄЮЄЋЄЪЁЃЄПЄжЄѓЁЃ
- "(worst quality:2), (low quality:2), (normal quality:2), lowers, " ЄђЛиФъЄЙЄыЄШЁЂКЧФуВшМСЁЂФуВшМСЁЂФЬОяВшМСЁЂФуВђСќХйЄђШђЄБЄЦЄЏЄьЄыЄУЄнЄЄЁЃЄПЄжЄѓЁЃ
- "((monochrome)), ((grayscale)), " ЄђЛиФъЄЙЄыЄШЁЂЧђЙѕВшСќЁЂЅАЅьЁМЅЙЅБЁМЅыВшСќЄђШђЄБЄЦЄЏЄьЄыЄЮЄРЄэЄІЁЃЄПЄжЄѓЁЃ
- (hoge:1.4) ЄШЄЋ (hoge:2) ЄШЄЋ (hoge:0.5) ЄШЄЄЄУЄПЕНвЄђЄЙЄыЄШЁЂЄЩЄЮФјХйИњВЬЄђЭјЄЋЄЛЄыЄЮЄЋПєУЭЄЧЛиФъЄЧЄЄыЁЃЄщЄЗЄЄЁЃТчЄЄЏЄЦЄт 1.4 - 2.0 ЄАЄщЄЄЄЫЄЗЄПЄлЄІЄЌЄЄЄЄЁЂЄШЄЄЄІЯУЄтИЋЄЋЄБЄПЁЃ
- hoge ЄЧ1.0ЧмЁЂ(hoge) ЄЧ1.1ЧмЁЂ((hoge)) ЄЧЬѓ1.2ЧмЄЮИњВЬЄЫЄЗЄЦЄЏЄьЄыЁЂЄщЄЗЄЄЁЃ
- ЭОУЬЁЃStable Diffusion web UI ЄЮЅзЅэЅѓЅзЅШ(ЦўЮЯЭѓ)ЄЧЁЂ(hoge:1.0) ЄШНёЄЋЄьЄПЄШЄГЄэЄЫЅЋЁМЅНЅыЄђЙчЄяЄЛЄЦЁЂCtrl + Up(ЂЌ)ЁЂCtrl+ Down(Ђ) ЄђУЁЄЏЄШЁЂПєУЭЄђ0.1УБАЬЄЧЪбВНЄЕЄЛЄщЄьЄыЁЃ
ВУЄЈЄЦЁЂDenoising strength Єђ 0.4 ЄЫМхЄсЄЦЄпЄПЁЃ
ЄоЄПЁЂCFG scale ЄђЁЂ7 ЄЋЄщ 5 ЄЫИКЄщЄЗЄЦЄпЄПЁЃCFG scale ЄЯЁЂПєУЭЄЌТчЄЄЄЄШЅзЅэЅѓЅзЅШЄЮЦтЭЦЄЫНОЄЊЄІЄШЄЙЄыЄБЄьЄЩЁЂЄНЄЮЪЌЬЕЭ§ЄЪДЖЄИЄЮЙчРЎЄђЄЙЄыЄЮЄЧВшСќЄЮЧЫУОЄЌС§ЄЈЛЯЄсЄЦЁЂПєУЭЄЌОЎЄЕЄЄЄШЅзЅэЅѓЅзЅШЄЮЦтЭЦЄЋЄщЮЅЄьЄЦAIЄЌМЋЪЌОЁМъЄЫЙчРЎЄЙЄыЄБЄЩЁЂЄНЄЮЪЌЧЫУОЄЗЄЫЄЏЄЄВшСќЄЌРИРЎЄЕЄьЄфЄЙЄЏЄЪЄыЁЂЄщЄЗЄЄЁЃ
ЁжЄщЄЗЄЄЁзЁжЄПЄжЄѓЁзЄаЄЋЄъНёЄЄЄЦЄЂЄыЄБЄЩЁЂЄЩЄьЄтЫмХіЄЫИњВЬЄЌНаЄЦЄыЄЮЄЋЁЂЄНЄІЄЄЄІВђМсЄЧЄЄЄЄЄЮЄЋЁЂЄСЄчЄУЄШМЋПЎЄЌЬЕЄЄЁФЁЃ
parameters girl, masterpiece, best quality, photo realistic, realistic, Negative prompt: painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality, ((monochrome)), ((grayscale)), Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 4219038187, Size: 512x512, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.4
ЄЋЄЪЄъВўСБЄЕЄьЄЦЄЄПЄБЄЩЁФЁЃЬДЄЮУцЄЫНаЄЦЄЄПЄщЁЂЄІЄЪЄЕЄьЄНЄІЄЧЄЙЁФЁЃ
Ё§ МТИГЄНЄЮ4 :
ГиНЌЅтЅЧЅыЅЧЁМЅПЁЂv2-1_768-ema-pruned.ckpt ЄЫЄЯИТГІЄЌЄЂЄыЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃГиНЌЅтЅЧЅыЅЧЁМЅПЄђЁЂЯУТъЄЮЁЂchilloutmix_.safetensors ЄЫЪбЙЙЄЗЄЦЄпЄыЁЃ








ЄЊЄЊЁФЁЃЄГЄьЄЪЄщЄПЄЗЄЋЄЫЁжgirlЁзЄЮВшСќЄРЁФЁЃPoser ЄЮЁЂЄЂЄЮЅЅтВшСќЄЋЄщЁЂЄГЄѓЄЪВшСќЄЫЄЗЄЦЄЏЄьЄыЄШЄЯЁФЁЃ
ЄНЄѓЄЪЄяЄБЄЧЁЂЄЩЄѓЄЪГиНЌЅтЅЧЅыЅЧЁМЅПЄђЛШЄІЄЋЄЧЁЂСДЄЏАуЄІВшСќЄЌРИРЎЄЕЄьЄыЄЮЄРЄЪЄШЁЃЄГЄГЄоЄЧАуЄУЄЦЄЏЄыЄШЄЯЁЃ
ЄСЄЪЄпЄЫЁЂЁжrussian childЁзЁжasian childЁзЄШЄЄЄУЄПЅЁМЅяЁМЅЩЄтШПБўЄЗЄЦЄЏЄьЄыЬЯЭЭЁЃ



ЄЪЄыЄлЄЩЁЂЄПЄЗЄЋЄЫЁЂЅэЅЗЅЂЄШЅЂЅИЅЂЄЪДЖЄИЄЫЪЌЄЋЄьЄПЁЃ
parameters girl, masterpiece, best quality, photo realistic, realistic, Negative prompt: painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality, ((monochrome)), ((grayscale)), Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 1534430406, Size: 512x512, Model hash: a757fe8b3d, Model: chilloutmix_, Denoising strength: 0.4
ЄЊЄЊЁФЁЃЄГЄьЄЪЄщЄПЄЗЄЋЄЫЁжgirlЁзЄЮВшСќЄРЁФЁЃPoser ЄЮЁЂЄЂЄЮЅЅтВшСќЄЋЄщЁЂЄГЄѓЄЪВшСќЄЫЄЗЄЦЄЏЄьЄыЄШЄЯЁФЁЃ
ЄНЄѓЄЪЄяЄБЄЧЁЂЄЩЄѓЄЪГиНЌЅтЅЧЅыЅЧЁМЅПЄђЛШЄІЄЋЄЧЁЂСДЄЏАуЄІВшСќЄЌРИРЎЄЕЄьЄыЄЮЄРЄЪЄШЁЃЄГЄГЄоЄЧАуЄУЄЦЄЏЄыЄШЄЯЁЃ
ЄСЄЪЄпЄЫЁЂЁжrussian childЁзЁжasian childЁзЄШЄЄЄУЄПЅЁМЅяЁМЅЩЄтШПБўЄЗЄЦЄЏЄьЄыЬЯЭЭЁЃ
parameters russian child, girl, masterpiece, best quality, photo realistic, realistic, Negative prompt: painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality, ((monochrome)), ((grayscale)), nsfw, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 209150273, Size: 512x512, Model hash: a757fe8b3d, Model: chilloutmix_, Denoising strength: 0.6
parameters asian child, girl, masterpiece, best quality, photo realistic, realistic, Negative prompt: painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality, ((monochrome)), ((grayscale)), nsfw, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 509918546, Size: 512x512, Model hash: a757fe8b3d, Model: chilloutmix_, Denoising strength: 0.6
ЄЪЄыЄлЄЩЁЂЄПЄЗЄЋЄЫЁЂЅэЅЗЅЂЄШЅЂЅИЅЂЄЪДЖЄИЄЫЪЌЄЋЄьЄПЁЃ
[ ЅФЅУЅГЄр ]
2023/04/14(Жт) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] img2imgЄђЄоЄРЛюЭбУц
ВшСќРИРЎAIЁЂStable Diffusion web UI ЄЮ img2img ЄђЛюЭбУцЁЃ
МТКнЄЫПЈЄУЄЦЄпЄЦЄЪЄѓЄШЄЪЄЏЪЌЄЋЄУЄЦЄЄПЅЂЅьЅГЅьЄШИРЄІЄЋЁЂЛЈДЖЄђЅсЅтЁЃ
МТКнЄЫПЈЄУЄЦЄпЄЦЄЪЄѓЄШЄЪЄЏЪЌЄЋЄУЄЦЄЄПЅЂЅьЅГЅьЄШИРЄІЄЋЁЂЛЈДЖЄђЅсЅтЁЃ
Ё§ CGВшСќЄђИЕВшСќЄЫЄЙЄыЄШЄшЄэЄЗЄЏЄЪЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄ :
ЄШЄЂЄы3DCGЅВЁМЅрЄЮЅЅуЅзЅСЅуВшСќЄђИЕВшСќЄЫЄЗЄЦМТИГЄЗЄЦЄЄЄПЄБЄьЄЩЁЂРИРЎВшСќЦтЄЮПЭДжЄЮДщЄЮМяЮрЄЌСДЄЏЪбВНЄЗЄЪЄЏЄЦЁЂЄГЄьЄЯЬЏЄРЄЪЄШЁЃ
ЄеЄШЕЄЩеЄЄЄПЁЃCGВшСќЦтЄЮПЭТЮЅтЅЧЅыЄЮДщЅбЁМЅФЄЮЅаЅщЅѓЅЙЄЌИНМТЄЮПЭДжЄЋЄщЮЅЄьЄЦЄЗЄоЄУЄЦЄЄЄЦЁЂПЭДжЄЮДщЄШЄЗЄЦЧЇМБЄЕЄьЄЦЄЄЄЪЄЄЄЮЄЧЄЯЁЉ
ЛюЄЗЄЫИЕВшСќЄђЅьЅПЅУЅСЄЗЄЦЁЂЦЌЄЮФЙЄЕЄђОЏЄЗУЛЄсЄЫЄЗЄЦЄпЄПЄщЁЂРИРЎЄЕЄьЄыДщЄФЄЄЫЅаЅъЅЈЁМЅЗЅчЅѓЄЌНаЄЦЄЄПЁЃЄЪЄыЄлЄЩЁЂЄНЄІЄЄЄІцЋЄтЄЂЄыЄЮЄЋЁФЁЃИНМТЄЮПЭДжЄђБЧЄЗЄПМЬППЄШЁЂЅтЅЧЅщЁМЄЕЄѓЄЮЙЅЄпЄЮЗСОѕЄЫЅЧЅЖЅЄЅѓЄЕЄьЄПCGПЭДжЄЮВшСќЄЧЄЯЁЂВшСќРИРЎAIЄЮЧЇМБЖёЙчЄЌАуЄУЄЦЄЏЄыЄГЄШЄтЄЂЄыЄЮЄРЄЪЄШЁЃ
ЄтЄУЄШЄтЁЂИНМТЄЮПЭДжЄРЄУЄЦПЇЄѓЄЪДщЄЌЄЂЄыЄяЄБЄЧЁЂЄНЄІЄЪЄыЄШЁЂAIЄЫЧЇМБЄЕЄьЄфЄЙЄЄПЭЁЂЄЕЄьЄЫЄЏЄЄПЭЄЮЮОЪ§ЄЌМТКпЄЗЄЦЄНЄІЄЪЕЄЄтЄЗЄЦЄЏЄыЁЃЄЊЄНЄщЄЏЁЂЅбЁМЅФЄЮЧлУжЄЌЪПЖбУЭЄЫЖсЄЄДщЄЯЧЇМБЄЕЄьЄфЄЙЄЏЄЦЁЂЄНЄГЄЋЄщЮЅЄьЄПДщЄЯЁЂAIЄЌЁЂЁжЅГЅьЁЂПЭДжЄЮДщЄИЄуЄЪЄЄЄЧЄЗЄчЁЉ ЄЈЁЉ ПЭДжЄЪЄЮЁЉ БГЄРЄэЁЃВЖЄЮГиНЌЅЧЁМЅПЄЋЄщЄЙЄыЄШЄНЄѓЄЪЄяЄБЄЪЄЄЄѓЄРЄБЄЩЁзЄШМКЮщЄЪЅИЅуЅУЅИЄђЁФЁЃ
ЄеЄШЕЄЩеЄЄЄПЁЃCGВшСќЦтЄЮПЭТЮЅтЅЧЅыЄЮДщЅбЁМЅФЄЮЅаЅщЅѓЅЙЄЌИНМТЄЮПЭДжЄЋЄщЮЅЄьЄЦЄЗЄоЄУЄЦЄЄЄЦЁЂПЭДжЄЮДщЄШЄЗЄЦЧЇМБЄЕЄьЄЦЄЄЄЪЄЄЄЮЄЧЄЯЁЉ
ЛюЄЗЄЫИЕВшСќЄђЅьЅПЅУЅСЄЗЄЦЁЂЦЌЄЮФЙЄЕЄђОЏЄЗУЛЄсЄЫЄЗЄЦЄпЄПЄщЁЂРИРЎЄЕЄьЄыДщЄФЄЄЫЅаЅъЅЈЁМЅЗЅчЅѓЄЌНаЄЦЄЄПЁЃЄЪЄыЄлЄЩЁЂЄНЄІЄЄЄІцЋЄтЄЂЄыЄЮЄЋЁФЁЃИНМТЄЮПЭДжЄђБЧЄЗЄПМЬППЄШЁЂЅтЅЧЅщЁМЄЕЄѓЄЮЙЅЄпЄЮЗСОѕЄЫЅЧЅЖЅЄЅѓЄЕЄьЄПCGПЭДжЄЮВшСќЄЧЄЯЁЂВшСќРИРЎAIЄЮЧЇМБЖёЙчЄЌАуЄУЄЦЄЏЄыЄГЄШЄтЄЂЄыЄЮЄРЄЪЄШЁЃ
ЄтЄУЄШЄтЁЂИНМТЄЮПЭДжЄРЄУЄЦПЇЄѓЄЪДщЄЌЄЂЄыЄяЄБЄЧЁЂЄНЄІЄЪЄыЄШЁЂAIЄЫЧЇМБЄЕЄьЄфЄЙЄЄПЭЁЂЄЕЄьЄЫЄЏЄЄПЭЄЮЮОЪ§ЄЌМТКпЄЗЄЦЄНЄІЄЪЕЄЄтЄЗЄЦЄЏЄыЁЃЄЊЄНЄщЄЏЁЂЅбЁМЅФЄЮЧлУжЄЌЪПЖбУЭЄЫЖсЄЄДщЄЯЧЇМБЄЕЄьЄфЄЙЄЏЄЦЁЂЄНЄГЄЋЄщЮЅЄьЄПДщЄЯЁЂAIЄЌЁЂЁжЅГЅьЁЂПЭДжЄЮДщЄИЄуЄЪЄЄЄЧЄЗЄчЁЉ ЄЈЁЉ ПЭДжЄЪЄЮЁЉ БГЄРЄэЁЃВЖЄЮГиНЌЅЧЁМЅПЄЋЄщЄЙЄыЄШЄНЄѓЄЪЄяЄБЄЪЄЄЄѓЄРЄБЄЩЁзЄШМКЮщЄЪЅИЅуЅУЅИЄђЁФЁЃ
Ё§ ВшСќЄђВѓХОЄЕЄЛЄыЄШЮЩЄЄЗыВЬЄЌЦРЄщЄьЄыОьЙчЄтЄЂЄъЄНЄІ :
ПЭЄЌЄЮЄБЄОЄУЄПДЖЄИЄЮИЕВшСќЄђХЯЄЗЄЦНшЭ§ЄЕЄЛЄПЄщЁЂРИРЎВшСќЦтЄЮДщЄЌЄШЄѓЄЧЄтЄЪЄЄЄГЄШЄЫЄЪЄУЄПЁЃЄГЄьЄтЄоЄПЁЂДщЄШЄЗЄЦЧЇМБЄЕЄьЄЦЄЪЄЄЕЄЄЌЄЙЄыЁФЁЃ
ЛюЄЗЄЫЁЂИЕВшСќЄђЁЂКИЄфБІЄЫ90ХйВѓХОЄЕЄЛЄЦХЯЄЗЄЦЄпЄПЄщЁЂЄНЄьЄУЄнЄЄДщЄђРИРЎЄЗЄЦЄЏЄьЄПЁЃЄНЄЮТхЄяЄъЁЂТЮЄЮЄлЄІЄЯЄАЄСЄуЄАЄСЄуЄЫЄЪЄУЄПЄБЄЩЁЃ
ЙЭЄЈЄЦЄпЄПЄщЁЂМЋЪЌУЃЄЌПЭДжЄЮМЬППЄђЛЃЄыКнЁЂТчТЮЄЯЬмЄЌОхЄЫЄЂЄУЄЦИ§ЄЌВМЄЫЄЂЄыОѕТжЄЮМЬППЄђЛЃЄыЄяЄБЄЧЁЃХіСГЁЂГиНЌЅтЅЧЅыЅЧЁМЅПЄтЁЂЄНЄІЄЄЄІМЬППЄЧГиНЌЄЗЄЦЄЄЄыЄяЄЪЁФЁЃ
ЄЧЄЂЄьЄаЁЂimg2imgЄЫЁЂИЕВшСќЄђ90/180/270ХйВѓХОЄЕЄЛЄЦЄЋЄщНшЭ§ЄђЄЗЄЦЁЂРИРЎВшСќЄЯИЕЄЮГбХйЄЫЬсЄЙЁЂЄШЄЄЄУЄПЕЁЧНЄЌЄЂЄыЄШПяЪЌАуЄУЄПЗыВЬЄђНаЄЗЄЦЄЏЄьЄыЄшЄІЄЫЄЪЄыЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃМТЄЯЄНЄІЄЄЄІЕЁЧНЄЌЄЂЄУЄПЄъЄЗЄЪЄЄЄЮЄРЄэЄІЄЋЁЃ
ЛюЄЗЄЫЁЂИЕВшСќЄђЁЂКИЄфБІЄЫ90ХйВѓХОЄЕЄЛЄЦХЯЄЗЄЦЄпЄПЄщЁЂЄНЄьЄУЄнЄЄДщЄђРИРЎЄЗЄЦЄЏЄьЄПЁЃЄНЄЮТхЄяЄъЁЂТЮЄЮЄлЄІЄЯЄАЄСЄуЄАЄСЄуЄЫЄЪЄУЄПЄБЄЩЁЃ
ЙЭЄЈЄЦЄпЄПЄщЁЂМЋЪЌУЃЄЌПЭДжЄЮМЬППЄђЛЃЄыКнЁЂТчТЮЄЯЬмЄЌОхЄЫЄЂЄУЄЦИ§ЄЌВМЄЫЄЂЄыОѕТжЄЮМЬППЄђЛЃЄыЄяЄБЄЧЁЃХіСГЁЂГиНЌЅтЅЧЅыЅЧЁМЅПЄтЁЂЄНЄІЄЄЄІМЬППЄЧГиНЌЄЗЄЦЄЄЄыЄяЄЪЁФЁЃ
ЄЧЄЂЄьЄаЁЂimg2imgЄЫЁЂИЕВшСќЄђ90/180/270ХйВѓХОЄЕЄЛЄЦЄЋЄщНшЭ§ЄђЄЗЄЦЁЂРИРЎВшСќЄЯИЕЄЮГбХйЄЫЬсЄЙЁЂЄШЄЄЄУЄПЕЁЧНЄЌЄЂЄыЄШПяЪЌАуЄУЄПЗыВЬЄђНаЄЗЄЦЄЏЄьЄыЄшЄІЄЫЄЪЄыЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃМТЄЯЄНЄІЄЄЄІЕЁЧНЄЌЄЂЄУЄПЄъЄЗЄЪЄЄЄЮЄРЄэЄІЄЋЁЃ
Ё§ img2imgЄШЛЈЅГЅщПІПЭЅЙЅЅы :
ЄГЄГЄЋЄщЄЯЛЈДЖЁЃЛзЙЭЅсЅтЁЃ
img2img ЄђЛШЄУЄЦЄыЄШЁЂРИРЎВшСќЄЫТаЄЗЄЦЁЂЄтЄІЄСЄчЄУЄШЄЩЄІЄЫЄЋЄЪЄщЄЪЄЄЄЋЄШЛзЄЈЄЦЄЏЄыОьЬЬЄЌЗыЙНЄЂЄУЄЦЁЃЄГЄУЄСЄЮВшСќЄЮЄГЄЮЩєЪЌЄШЁЂЄНЄУЄСЄЮВшСќЄЮЄГЄЮЩєЪЌЄЌАьНяЄЫЦўЄУЄЦЄПЄщЭ§СлЄЮВшСќЄЫЄЪЄыЄЮЄРЄБЄЩЄЪЄЂЁЂЄЩЄІЄЫЄЋЄЪЄщЄѓЄЋЄЪЄЂЁЂЄпЄПЄЄЄЪЁЃ
ЄНЄГЄЧЁЂimg2img ЄРЄБЄЧСДЄЦЄђВђЗшЄЗЄшЄІЄШЄЙЄыЄЮЄЯЬЬХнНЄЄЄЋЄщ GIMP ЄЧЙчРЎЄЗЄЦЄЗЄоЄЊЄІЄЋЄШЛзЄЄЄФЄЄЄЦЄЗЄоЄУЄПЁЃ
ЄЗЄЋЄЗЁЂGIMP ЄђЮЉЄСОхЄВЄЦЁЂВшСќЄђЦЩЄпЙўЄѓЄЧЁЂЅьЅЄЅфЁМЄђНХЄЭЄЦЁЂЄСЄчЄГЄСЄчЄГЄШНЄРЕЄЗЄЦЄЄЄыЄІЄСЄЫЁЂНЄРЕ/ЅьЅПЅУЅСКюЖШЄЧБфЁЙЛўДжЄђШёЄфЄЗЄЦЄЗЄоЄУЄЦЁЂЅЂЅьЅЂЅьЁЉ МЋЪЌЄЯАьТЮВПЄђЄфЄУЄЦЄЄЄыЄЮЄРЄэЄІЁЉ ЄШЄЄЄІЕЄЪЌЄЫЁФЁЃ
ВшСќРИРЎAIЄђПЈЄыЄШЁЂКЧНЊХЊЄЫЄЯЁЂЛЈЅГЅщПІПЭЅЙЅЅыЄђЫсЄЄПЄЏЄЪЄУЄЦЄЏЄыЄЪЄШЁФЁЃЄЄЄфЄоЄЂЁЂЭ§СлЄЮВшСќЄЌЭпЄЗЄЄЄЪЄщЁЂЩдЫўЄђЛ§ЄУЄПЩєЪЌЄђЁЂМЋЪЌЄЮМъЄђЦАЄЋЄЗЄЦНЄРЕЄЗЄСЄуЄІЄЮЄЌСсЄЄЄЮЄЧЁЂЄЊЄЋЄЗЄЄЄГЄШЄЧЄЯЄЪЄЄЄЮЄРЄэЄІЄБЄЩЁЃ
КЧНЊХЊЄЪЪдНИЄЯДћТИЄЮВшСќЪдНИЅНЅеЅШЄЧЙдЄІЄШЄЗЄЦЁЂВшСќРИРЎAIЄЯСЧКрВшСќЄђТчЮЬРИРЎЄЙЄыЄЮЄЫИўЄЄЄЦЄЄЄыЅФЁМЅыЄЪЄЮЄРЄШТЊЄЈЄЦЄЗЄоЄЈЄаГкЄЋЄтЄЗЄьЄЪЄЄЄЪЄШЁЃЄЊСАЄЫТПЄЏЄЯЫОЄоЄЪЄЄЁЃСЧКрЄЕЄЈКюЄУЄЦЄЏЄьЄьЄаИхЄЯЄГЄУЄСЄЧЄЩЄІЄЫЄЋЄЗЄЦЄфЄѓЄшЁЃЄпЄПЄЄЄЪЁЃ
img2img ЄђЛШЄУЄЦЄыЄШЁЂРИРЎВшСќЄЫТаЄЗЄЦЁЂЄтЄІЄСЄчЄУЄШЄЩЄІЄЫЄЋЄЪЄщЄЪЄЄЄЋЄШЛзЄЈЄЦЄЏЄыОьЬЬЄЌЗыЙНЄЂЄУЄЦЁЃЄГЄУЄСЄЮВшСќЄЮЄГЄЮЩєЪЌЄШЁЂЄНЄУЄСЄЮВшСќЄЮЄГЄЮЩєЪЌЄЌАьНяЄЫЦўЄУЄЦЄПЄщЭ§СлЄЮВшСќЄЫЄЪЄыЄЮЄРЄБЄЩЄЪЄЂЁЂЄЩЄІЄЫЄЋЄЪЄщЄѓЄЋЄЪЄЂЁЂЄпЄПЄЄЄЪЁЃ
ЄНЄГЄЧЁЂimg2img ЄРЄБЄЧСДЄЦЄђВђЗшЄЗЄшЄІЄШЄЙЄыЄЮЄЯЬЬХнНЄЄЄЋЄщ GIMP ЄЧЙчРЎЄЗЄЦЄЗЄоЄЊЄІЄЋЄШЛзЄЄЄФЄЄЄЦЄЗЄоЄУЄПЁЃ
ЄЗЄЋЄЗЁЂGIMP ЄђЮЉЄСОхЄВЄЦЁЂВшСќЄђЦЩЄпЙўЄѓЄЧЁЂЅьЅЄЅфЁМЄђНХЄЭЄЦЁЂЄСЄчЄГЄСЄчЄГЄШНЄРЕЄЗЄЦЄЄЄыЄІЄСЄЫЁЂНЄРЕ/ЅьЅПЅУЅСКюЖШЄЧБфЁЙЛўДжЄђШёЄфЄЗЄЦЄЗЄоЄУЄЦЁЂЅЂЅьЅЂЅьЁЉ МЋЪЌЄЯАьТЮВПЄђЄфЄУЄЦЄЄЄыЄЮЄРЄэЄІЁЉ ЄШЄЄЄІЕЄЪЌЄЫЁФЁЃ
ВшСќРИРЎAIЄђПЈЄыЄШЁЂКЧНЊХЊЄЫЄЯЁЂЛЈЅГЅщПІПЭЅЙЅЅыЄђЫсЄЄПЄЏЄЪЄУЄЦЄЏЄыЄЪЄШЁФЁЃЄЄЄфЄоЄЂЁЂЭ§СлЄЮВшСќЄЌЭпЄЗЄЄЄЪЄщЁЂЩдЫўЄђЛ§ЄУЄПЩєЪЌЄђЁЂМЋЪЌЄЮМъЄђЦАЄЋЄЗЄЦНЄРЕЄЗЄСЄуЄІЄЮЄЌСсЄЄЄЮЄЧЁЂЄЊЄЋЄЗЄЄЄГЄШЄЧЄЯЄЪЄЄЄЮЄРЄэЄІЄБЄЩЁЃ
КЧНЊХЊЄЪЪдНИЄЯДћТИЄЮВшСќЪдНИЅНЅеЅШЄЧЙдЄІЄШЄЗЄЦЁЂВшСќРИРЎAIЄЯСЧКрВшСќЄђТчЮЬРИРЎЄЙЄыЄЮЄЫИўЄЄЄЦЄЄЄыЅФЁМЅыЄЪЄЮЄРЄШТЊЄЈЄЦЄЗЄоЄЈЄаГкЄЋЄтЄЗЄьЄЪЄЄЄЪЄШЁЃЄЊСАЄЫТПЄЏЄЯЫОЄоЄЪЄЄЁЃСЧКрЄЕЄЈКюЄУЄЦЄЏЄьЄьЄаИхЄЯЄГЄУЄСЄЧЄЩЄІЄЫЄЋЄЗЄЦЄфЄѓЄшЁЃЄпЄПЄЄЄЪЁЃ
Ё§ ЫЁЮЇЄЌЅжЅьЁМЅЄђЄЋЄБЄЦЄЄНЄІ :
ВшСќРИРЎAIЄђЁЂСЧКрВшСќРИРЎЅФЁМЅыЄШЄЗЄЦТЊЄЈЄПОьЙчЁЂИЂЭјДиЗИЄђЅЏЅъЅЂЄЫЄЙЄыЄЮЄЌТчЪбЄНЄІЁФЁЃКЃИхЁЂЅщЅЄЅЛЅѓЅЙЬЬЄЧДАСДЄЫЬфТъЬЕЄЄЄГЄШЄЌЪнОкЄЕЄьЄПГиНЌЅЧЁМЅПЄЫВСУЭЄЌНаЄЦЄЄНЄІЄЪЕЄЄтЄЙЄыЁЃЄЧЄтЁЂЄЩЄГЄЋЄЧВПЄЋЄЌЄвЄУЄНЄъКЎЄЖЄУЄЦЄЗЄоЄЄЄНЄІЄЧЄтЄЂЄыЄЪЁФЁЃ
РЮЄЯЬфТъЬЕЄЋЄУЄПГиНЌЅЧЁМЅПЄЌЁЂЫЁЮЇВўЪбЄЧЬфТъЄЮЄЂЄыЅЧЁМЅПЄЫЪбЄяЄУЄЦЄЗЄоЄІЄГЄШЄтЄЂЄъЦРЄыЄРЄэЄІЄЪЄШЁЃЮуЄЈЄаЁЂЄЋЄФЄЦЄЯПЭЄЮДщЄЫИЂЭјЄЪЄѓЄЦЧЇЄсЄщЄьЄЪЄЋЄУЄПЄБЄЩЁЂКЃЄЯОгСќИЂБОЁЙЄЌИРЄяЄьЄЦЄЗЄоЄІЄяЄБЄЧЁЃЬЄРЎЧЏЄЮЭчТЮЄтЦБЭЭЄЋЁЃРЮЄЯЬфТъЛыЄЕЄьЄЦЄЪЄЋЄУЄПЄЗЁЃ
ЫЁЮЇЄЧЅжЅьЁМЅЄђЄЋЄБЄыЙёЄшЄъЁЂЅжЅьЁМЅЄђЄЋЄБЄЪЄЄЙёЄЮЄлЄІЄЌЕЛНбЄЌШЏУЃЄЗЄЦЁЂСАМдЄЯРЄГІЄЋЄщМшЄъЛФЄЕЄьЄЦЄЄЄЏЄѓЄРЄэЄІЄЪЄЂЁФЁЃ
ЮуЄЈЄаРЮЄЮЦќЫмЄЧЄЯЁЂЫЁХЊЄЫЁЂЅГЅѓЅдЅхЁМЅПЦБЛЮЄђХХЯУВѓРўЄЧРмТГЄЙЄыЄГЄШЄЌХХХХИјМвАЪГАЕіЄЕЄьЄЦЄЪЄЏЄЦЁЂЄНЄьЄЧЅЄЅѓЅПЁМЅЭЅУЅШДиЯЂЕЛНбЄЮШЏХИЄЌВЄЪЦЄшЄъУйЄьЄПЄШЄЄЄІЯУЄтЁФЁЃЅтЅЧЅрЄђЛШЄУЄЦРмТГЄЙЄыЄРЄБЄЧИІЕцМдЄЌШШКсМдАЗЄЄЄЫЄЪЄыЙёЄЧЄЯЁЂЄНЄъЄуИхЄьЄђМшЄъЄоЄЙЄяЁЃЄоЄЂЁЂЄЕЄЙЄЌЄЫКЃЄЯЫЁВўРЕЄЕЄьЄПЄБЄЩЁЃЄНЄтЄНЄтХХХХИјМвЬЕЄЏЄЪЄУЄПЄЗЁЃ
ЄПЄРЁЂЄНЄѓЄЪДЖЄИЄЧЁЂЅжЅьЁМЅЄђЄЋЄБЄЦЄыЫЁЮЇЄЌЄоЄРЄоЄРЄЂЄъЄНЄІЄРЄЪЄШЁЃЄНЄІЄЄЄЈЄаУјКюИЂДиЗИЄтЄНЄІЄЋЁЃЪнИюДќДжЄЌФЙАњЄЄЄПЄГЄШЄЧИІЕцЭбЅЧЁМЅПЄЮЦўМъЄШГшЭбЄЌЙЙЄЫЦёЄЗЄЏЄЪЄУЄПЬЬЄтЄЂЄыЄЮЄРЄэЄІЄЪЁФЁЃ
РЮЄЯЬфТъЬЕЄЋЄУЄПГиНЌЅЧЁМЅПЄЌЁЂЫЁЮЇВўЪбЄЧЬфТъЄЮЄЂЄыЅЧЁМЅПЄЫЪбЄяЄУЄЦЄЗЄоЄІЄГЄШЄтЄЂЄъЦРЄыЄРЄэЄІЄЪЄШЁЃЮуЄЈЄаЁЂЄЋЄФЄЦЄЯПЭЄЮДщЄЫИЂЭјЄЪЄѓЄЦЧЇЄсЄщЄьЄЪЄЋЄУЄПЄБЄЩЁЂКЃЄЯОгСќИЂБОЁЙЄЌИРЄяЄьЄЦЄЗЄоЄІЄяЄБЄЧЁЃЬЄРЎЧЏЄЮЭчТЮЄтЦБЭЭЄЋЁЃРЮЄЯЬфТъЛыЄЕЄьЄЦЄЪЄЋЄУЄПЄЗЁЃ
ЫЁЮЇЄЧЅжЅьЁМЅЄђЄЋЄБЄыЙёЄшЄъЁЂЅжЅьЁМЅЄђЄЋЄБЄЪЄЄЙёЄЮЄлЄІЄЌЕЛНбЄЌШЏУЃЄЗЄЦЁЂСАМдЄЯРЄГІЄЋЄщМшЄъЛФЄЕЄьЄЦЄЄЄЏЄѓЄРЄэЄІЄЪЄЂЁФЁЃ
ЮуЄЈЄаРЮЄЮЦќЫмЄЧЄЯЁЂЫЁХЊЄЫЁЂЅГЅѓЅдЅхЁМЅПЦБЛЮЄђХХЯУВѓРўЄЧРмТГЄЙЄыЄГЄШЄЌХХХХИјМвАЪГАЕіЄЕЄьЄЦЄЪЄЏЄЦЁЂЄНЄьЄЧЅЄЅѓЅПЁМЅЭЅУЅШДиЯЂЕЛНбЄЮШЏХИЄЌВЄЪЦЄшЄъУйЄьЄПЄШЄЄЄІЯУЄтЁФЁЃЅтЅЧЅрЄђЛШЄУЄЦРмТГЄЙЄыЄРЄБЄЧИІЕцМдЄЌШШКсМдАЗЄЄЄЫЄЪЄыЙёЄЧЄЯЁЂЄНЄъЄуИхЄьЄђМшЄъЄоЄЙЄяЁЃЄоЄЂЁЂЄЕЄЙЄЌЄЫКЃЄЯЫЁВўРЕЄЕЄьЄПЄБЄЩЁЃЄНЄтЄНЄтХХХХИјМвЬЕЄЏЄЪЄУЄПЄЗЁЃ
ЄПЄРЁЂЄНЄѓЄЪДЖЄИЄЧЁЂЅжЅьЁМЅЄђЄЋЄБЄЦЄыЫЁЮЇЄЌЄоЄРЄоЄРЄЂЄъЄНЄІЄРЄЪЄШЁЃЄНЄІЄЄЄЈЄаУјКюИЂДиЗИЄтЄНЄІЄЋЁЃЪнИюДќДжЄЌФЙАњЄЄЄПЄГЄШЄЧИІЕцЭбЅЧЁМЅПЄЮЦўМъЄШГшЭбЄЌЙЙЄЫЦёЄЗЄЏЄЪЄУЄПЬЬЄтЄЂЄыЄЮЄРЄэЄІЄЪЁФЁЃ
Ё§ ВшСќРИРЎAIЄЯМЬППЄЫЛїЄЦЄЄЄы :
АЪСАЁЂЅЭЅУЅШОхЄЮЄЩЄГЄЋЄЧЁЂЁжВшСќРИРЎAIЄЯМЬППЄЮШЏЬРЄЫЛїЄЦЄЄЄыЁзЄШЄЄЄУЄПДЖСлЄђНвЄйЄЦЄыЕЛіЄђИЋЄЋЄБЄЦЁЂЁжЄНЄьЄЯСДСГАуЄІЄРЄэЁзХЊДЖСлЄЌЛГЄлЄЩЄФЄЄЄЦЄПЁЂЄНЄѓЄЪОьЬЬЄђЬмЄЫЄЗЄПЕВБЄЌЄЂЄыЄЮЄРЄБЄЩЁЃ
МТКнЄЫПЈЄУЄЦЄпЄыЄШЁЂЄПЄЗЄЋЄЫМЬППЄШЛїЄЦЄЄЄыЩєЪЌЄЌЄЂЄыЄЪЄШМЋЪЌЄтДЖЄИЄЦЄЗЄоЄУЄПЁЃ
РЮЁЂВПЄЋЄЮTVШжСШЄЧЬмЄЫЄЗЄПЄБЄьЄЩЁЃЮуЄЈЄаЛЈЛяЄЮЩНЛцЄЫЄЪЄыЄшЄІЄЪЁЂНїЭЅЄЕЄѓЄфНїРЅЂЅЄЅЩЅыЄЮМЬППЄђЛЃБЦЄЙЄыЛўЄЯЁФЁЃАьДуЅьЅеЅЧЅИЅЋЅсЄђЯЂМЭЅтЁМЅЩЄЫЄЗЄЦЁЂНїЭЅЄЕЄѓЄЌШБЄђЄЋЄОхЄВЄыЄлЄѓЄЮАьНжЄђЅоЅЗЅѓЅЌЅѓЄЮЄшЄІЄЫЛЃБЦЄЗЄЦЁЂЄЙЄАЄЕЄоМЬППЗВЄђPCЄЫЅяЅЄЅфЅьЅЙЄЧХОСїЄЗЄЦЁЂPCЄЮЅЧЅЃЅЙЅзЅьЅЄЄЫБЧЄУЄПВПННЫчЁСВПЩДЫчЄЮМЬППЄЮУцЄЋЄщЁЂЄПЄУЄПАьЫчЄђСЊЄжЁЂЄШЄЄЄІЄГЄШЄђЄЗЄЦЄЄЄПЄяЄБЄЧЁЃ
ВшСќРИРЎAIЄтЁЂПЈЄУЄЦЄЄЄыЄІЄСЄЫЁЂТчТЮЛїЄПДЖЄИЄЫЄЪЄУЄЦЄЏЄыЄЪЄШЁЃЄШЄъЄЂЄЈЄКЄЊЛюЄЗЄЧЁЂВПННЫчЁСВПЩДЫчЄтВшСќЄђРИРЎЄЕЄЛЄЦЄпЄЦЁЂЄНЄЮУцЄЋЄщЮЩЄЕЄНЄІЄЪПєЫчЄђСЊЄжЄЮЄЌХіЄПЄъСАЁЃЄНЄѓЄЪДЖГаЄЫЪбЄяЄУЄЦЄЏЄыЁЃ
ЄГЄьЄЌЄтЄЗЁЂМЋЪЌЄЮМъЄђЦАЄЋЄЗЄЦГЈЄђЩСЄЏЅНЅьЄРЄУЄПЄщЁЂЁжЄШЄъЄЂЄЈЄКЁзЄЧВПННЫчЄтЩСЄЄЄЦЄпЄЦЁЂЄНЄЮУцЄЋЄщАьЫчЄђСЊЄжЁЂЄЪЄѓЄЦЄГЄШЄЯЁЂЄлЄмЬЕЭ§ЁЃАьЫчЩСЄЏЄЮЄЫПєЛўДжЁСПєЦќЄЋЄЋЄыЄЋЄщЁФЁЃ *1 ЄЄЄфЄоЄЂЁЂЅщЅеГЈЄЧЄЄЄЄЄЪЄщВПЫчЄЧЄтЩСЄБЄыЄБЄЩЁЃЄЂЄыЄЄЄЯГЈЩСЄЄЕЄѓЄђВППЭЄтИЦЄѓЄЧЄЏЄьЄаЪТЮѓЄЧРИЛК(?)ЄЧЄЄыЄБЄЩЁЃ
АьЫчЄЮВшЄђРИРЎЄЙЄыЄЮЄЫЄЋЄЋЄыЛўДжЄЌУЛЄЏЄЪЄыЄШЁЂАЗЄЄЄШЄЄЄІЄЋЁЂРмЄЙЄыЛўЄЮДЖГаЄЌЁЂМЬППЄЫЖсЄХЄЄЄЦЄЄЄЏЄЪЄШЁФЁЃ
ЄтЄУЄШЄтЁЂМЬППЄЫЄтЁЂЅеЅЃЅыЅрЅЋЅсЅщ/ЖфБіЅЋЅсЅщЄШЅЧЅИЅЋЅсЄЮАуЄЄЄЌЄЂЄыЄяЄБЄРЄБЄЩЁЃЅеЅЃЅыЅрЄЯИНСќЄЗЄЪЄЄЄШВПЄЌЛЃЄьЄЦЄЄЄыЄЮЄЋЪЌЄщЄЪЄЄЄЗЁЂЅеЅЃЅыЅрТхЄтЄЋЄЋЄыЄЮЄЧЁЂЛЃЄУЄПВшЄЌЭ§СлЄШЮЅЄьЄЦЄЄЄЦЄтФќЄсЄыЄЗЄЋЄЪЄЄЄБЄьЄЩЁЃЅгЅЧЅЊЅЋЅсЅщЄфЅЧЅИЅЋЅсЄЮХаОьЄЧЁЂЛЃЄУЄПЄНЄЮОьЄЧВПЄЌБЧЄУЄЦЄыЄЮЄЋГЮЧЇЄЧЄЄыЄшЄІЄЫЄЪЄУЄЦЁЂВшЄЮМшМЮСЊТђЄЌЄЗЄфЄЙЄЏЄЪЄУЄПЄШЄГЄэЄЯЄЂЄыЄЪЄШЁЃ
ЄНЄьЄЯЄШЄтЄЋЄЏЁЃЦБЄИЅЋЅсЅщЄђЛШЄУЄЦЄтЁЂСЧПЭЄЮЛЃЄУЄПМЬППЄШЁЂЅзЅэЅЋЅсЅщЅоЅѓЄЮЛЃЄУЄПМЬППЄЧСДСГАуЄІЄяЄБЄРЄБЄЩЁЂЄНЄЮЄЂЄПЄъЄтИНОѕЄЮВшСќРИРЎAIЄЯЛїЄЦЄЄЄыЕЄЄЌЄЙЄыЁЃЅзЅэЅѓЅзЅШЅЈЅѓЅИЅЫЅЂЅъЅѓЅАЄЫРКФЬЄЗЄЦЄЄЄыПЭЄЪЄщЅЄЅЄДЖЄИЄЮВшСќЄђОЄДЄШЄЄЄІЄЋЯЃРЎЄЧЄЄыЄБЄЩЁЂВПЄтУЮЄщЄЪЄЄПЭЄЌЛШЄІЄШЙѓЄЄВшСќЄЗЄЋНаЄЦЄГЄЪЄЄЁЃЦЛЖёЄЌЦБЄИЄЧЄтЁЂЛШЄІПЭЄЮУЮМБЮЬЄЫЄшЄУЄЦЦРЄщЄьЄыЗыВЬЄЌАуЄУЄЦЄЏЄыЁЃ
ЄЧЄтЄоЄЂЁЂЄНЄьЄЯЁЂМъЩСЄЄЮГЈЄтЦБЄИЄЋЁФЁЃPhotoshopЄђЛШЄУЄПЄщУЏЄЧЄтДёЮяЄЪЅЄЅщЅЙЅШЄЌЩСЄБЄыЄяЄБЄЧЄтЄЪЄЄЄЗЁФЁЃ
ЄПЄРЁЂМЬППЄЮОьЙчЁЂСЧПЭЄтЖіСГЅЄЅЄДЖЄИЄЮМЬППЄЌЛЃЄьЄЦЄЗЄоЄІЛўЄЌЄЂЄУЄЦЁЂВшСќРИРЎAIЄтЄНЄЮЄЂЄПЄъЄЯЛїЄЦЄЄЄыЄЮЄЋЄтЁЃЄПЄоЄПЄоЁЂЕПЛїЭ№ПєЄШЄЄЄІЁЂЅЕЅЄЅГЅэЄЮНаЄЗЄПЬмЄЫЄшЄУЄЦЁЂЅЄЅЄДЖЄИЄЮВшСќЄЌНаЄЦЄЏЄыЛўЄтЄЂЄыЄяЄБЄЧЁЃЄГЄьЄЌМъЩСЄЄЮГЈЄРЄШЁЂЄНЄІЄЯЄЪЄщЄЪЄЄЁЃСЧПЭЄтЖіСГЅДЅЄЅЙЄЪГЈЄЌЩСЄБЄСЄуЄЄЄоЄЗЄПЁЂЄЪЄѓЄЦЄГЄШЄЯЄлЄм100ЁѓЄЂЄъЄЈЄЪЄЄЁЃЄНЄІЙЭЄЈЄыЄШЁЂЄфЄЯЄъВшСќРИРЎAIЄЯЁЂМЬППЄШЛїЄЦЄЄЄыЄШЄГЄэЄЌЄЂЄъЄНЄІЄРЄЪЄШЁЃ
МТКнЄЫПЈЄУЄЦЄпЄыЄШЁЂЄПЄЗЄЋЄЫМЬППЄШЛїЄЦЄЄЄыЩєЪЌЄЌЄЂЄыЄЪЄШМЋЪЌЄтДЖЄИЄЦЄЗЄоЄУЄПЁЃ
РЮЁЂВПЄЋЄЮTVШжСШЄЧЬмЄЫЄЗЄПЄБЄьЄЩЁЃЮуЄЈЄаЛЈЛяЄЮЩНЛцЄЫЄЪЄыЄшЄІЄЪЁЂНїЭЅЄЕЄѓЄфНїРЅЂЅЄЅЩЅыЄЮМЬППЄђЛЃБЦЄЙЄыЛўЄЯЁФЁЃАьДуЅьЅеЅЧЅИЅЋЅсЄђЯЂМЭЅтЁМЅЩЄЫЄЗЄЦЁЂНїЭЅЄЕЄѓЄЌШБЄђЄЋЄОхЄВЄыЄлЄѓЄЮАьНжЄђЅоЅЗЅѓЅЌЅѓЄЮЄшЄІЄЫЛЃБЦЄЗЄЦЁЂЄЙЄАЄЕЄоМЬППЗВЄђPCЄЫЅяЅЄЅфЅьЅЙЄЧХОСїЄЗЄЦЁЂPCЄЮЅЧЅЃЅЙЅзЅьЅЄЄЫБЧЄУЄПВПННЫчЁСВПЩДЫчЄЮМЬППЄЮУцЄЋЄщЁЂЄПЄУЄПАьЫчЄђСЊЄжЁЂЄШЄЄЄІЄГЄШЄђЄЗЄЦЄЄЄПЄяЄБЄЧЁЃ
ВшСќРИРЎAIЄтЁЂПЈЄУЄЦЄЄЄыЄІЄСЄЫЁЂТчТЮЛїЄПДЖЄИЄЫЄЪЄУЄЦЄЏЄыЄЪЄШЁЃЄШЄъЄЂЄЈЄКЄЊЛюЄЗЄЧЁЂВПННЫчЁСВПЩДЫчЄтВшСќЄђРИРЎЄЕЄЛЄЦЄпЄЦЁЂЄНЄЮУцЄЋЄщЮЩЄЕЄНЄІЄЪПєЫчЄђСЊЄжЄЮЄЌХіЄПЄъСАЁЃЄНЄѓЄЪДЖГаЄЫЪбЄяЄУЄЦЄЏЄыЁЃ
ЄГЄьЄЌЄтЄЗЁЂМЋЪЌЄЮМъЄђЦАЄЋЄЗЄЦГЈЄђЩСЄЏЅНЅьЄРЄУЄПЄщЁЂЁжЄШЄъЄЂЄЈЄКЁзЄЧВПННЫчЄтЩСЄЄЄЦЄпЄЦЁЂЄНЄЮУцЄЋЄщАьЫчЄђСЊЄжЁЂЄЪЄѓЄЦЄГЄШЄЯЁЂЄлЄмЬЕЭ§ЁЃАьЫчЩСЄЏЄЮЄЫПєЛўДжЁСПєЦќЄЋЄЋЄыЄЋЄщЁФЁЃ *1 ЄЄЄфЄоЄЂЁЂЅщЅеГЈЄЧЄЄЄЄЄЪЄщВПЫчЄЧЄтЩСЄБЄыЄБЄЩЁЃЄЂЄыЄЄЄЯГЈЩСЄЄЕЄѓЄђВППЭЄтИЦЄѓЄЧЄЏЄьЄаЪТЮѓЄЧРИЛК(?)ЄЧЄЄыЄБЄЩЁЃ
АьЫчЄЮВшЄђРИРЎЄЙЄыЄЮЄЫЄЋЄЋЄыЛўДжЄЌУЛЄЏЄЪЄыЄШЁЂАЗЄЄЄШЄЄЄІЄЋЁЂРмЄЙЄыЛўЄЮДЖГаЄЌЁЂМЬППЄЫЖсЄХЄЄЄЦЄЄЄЏЄЪЄШЁФЁЃ
ЄтЄУЄШЄтЁЂМЬППЄЫЄтЁЂЅеЅЃЅыЅрЅЋЅсЅщ/ЖфБіЅЋЅсЅщЄШЅЧЅИЅЋЅсЄЮАуЄЄЄЌЄЂЄыЄяЄБЄРЄБЄЩЁЃЅеЅЃЅыЅрЄЯИНСќЄЗЄЪЄЄЄШВПЄЌЛЃЄьЄЦЄЄЄыЄЮЄЋЪЌЄщЄЪЄЄЄЗЁЂЅеЅЃЅыЅрТхЄтЄЋЄЋЄыЄЮЄЧЁЂЛЃЄУЄПВшЄЌЭ§СлЄШЮЅЄьЄЦЄЄЄЦЄтФќЄсЄыЄЗЄЋЄЪЄЄЄБЄьЄЩЁЃЅгЅЧЅЊЅЋЅсЅщЄфЅЧЅИЅЋЅсЄЮХаОьЄЧЁЂЛЃЄУЄПЄНЄЮОьЄЧВПЄЌБЧЄУЄЦЄыЄЮЄЋГЮЧЇЄЧЄЄыЄшЄІЄЫЄЪЄУЄЦЁЂВшЄЮМшМЮСЊТђЄЌЄЗЄфЄЙЄЏЄЪЄУЄПЄШЄГЄэЄЯЄЂЄыЄЪЄШЁЃ
ЄНЄьЄЯЄШЄтЄЋЄЏЁЃЦБЄИЅЋЅсЅщЄђЛШЄУЄЦЄтЁЂСЧПЭЄЮЛЃЄУЄПМЬППЄШЁЂЅзЅэЅЋЅсЅщЅоЅѓЄЮЛЃЄУЄПМЬППЄЧСДСГАуЄІЄяЄБЄРЄБЄЩЁЂЄНЄЮЄЂЄПЄъЄтИНОѕЄЮВшСќРИРЎAIЄЯЛїЄЦЄЄЄыЕЄЄЌЄЙЄыЁЃЅзЅэЅѓЅзЅШЅЈЅѓЅИЅЫЅЂЅъЅѓЅАЄЫРКФЬЄЗЄЦЄЄЄыПЭЄЪЄщЅЄЅЄДЖЄИЄЮВшСќЄђОЄДЄШЄЄЄІЄЋЯЃРЎЄЧЄЄыЄБЄЩЁЂВПЄтУЮЄщЄЪЄЄПЭЄЌЛШЄІЄШЙѓЄЄВшСќЄЗЄЋНаЄЦЄГЄЪЄЄЁЃЦЛЖёЄЌЦБЄИЄЧЄтЁЂЛШЄІПЭЄЮУЮМБЮЬЄЫЄшЄУЄЦЦРЄщЄьЄыЗыВЬЄЌАуЄУЄЦЄЏЄыЁЃ
ЄЧЄтЄоЄЂЁЂЄНЄьЄЯЁЂМъЩСЄЄЮГЈЄтЦБЄИЄЋЁФЁЃPhotoshopЄђЛШЄУЄПЄщУЏЄЧЄтДёЮяЄЪЅЄЅщЅЙЅШЄЌЩСЄБЄыЄяЄБЄЧЄтЄЪЄЄЄЗЁФЁЃ
ЄПЄРЁЂМЬППЄЮОьЙчЁЂСЧПЭЄтЖіСГЅЄЅЄДЖЄИЄЮМЬППЄЌЛЃЄьЄЦЄЗЄоЄІЛўЄЌЄЂЄУЄЦЁЂВшСќРИРЎAIЄтЄНЄЮЄЂЄПЄъЄЯЛїЄЦЄЄЄыЄЮЄЋЄтЁЃЄПЄоЄПЄоЁЂЕПЛїЭ№ПєЄШЄЄЄІЁЂЅЕЅЄЅГЅэЄЮНаЄЗЄПЬмЄЫЄшЄУЄЦЁЂЅЄЅЄДЖЄИЄЮВшСќЄЌНаЄЦЄЏЄыЛўЄтЄЂЄыЄяЄБЄЧЁЃЄГЄьЄЌМъЩСЄЄЮГЈЄРЄШЁЂЄНЄІЄЯЄЪЄщЄЪЄЄЁЃСЧПЭЄтЖіСГЅДЅЄЅЙЄЪГЈЄЌЩСЄБЄСЄуЄЄЄоЄЗЄПЁЂЄЪЄѓЄЦЄГЄШЄЯЄлЄм100ЁѓЄЂЄъЄЈЄЪЄЄЁЃЄНЄІЙЭЄЈЄыЄШЁЂЄфЄЯЄъВшСќРИРЎAIЄЯЁЂМЬППЄШЛїЄЦЄЄЄыЄШЄГЄэЄЌЄЂЄъЄНЄІЄРЄЪЄШЁЃ
Ё§ ЄЊЖтЄђЄЋЄБЄКЄЫЅЌЅСЅуЄђГкЄЗЄсЄы :
ВшСќРИРЎAIЄђПЈЄУЄЦЄЄЄЦЛзЄІЄЮЄЯЁЂЄГЄьЄЯЅЌЅСЅуЄРЄЪЄЂЁЂЄШЁЃ
ЅЯЁМЅЩЅІЅЇЅЂЅЙЅкЅУЅЏЄЕЄЈЫўЄПЄЗЄЦЄЄЄьЄаЁЂЅьЅЂЅЋЁМЅЩЄЪЄщЄЬЅьЅЂВшСќЄЌНаЄЦЄЏЄыЄоЄЧЁЂЄЄЄФЄоЄЧЄтБфЁЙЄШЅЌЅСЅуЄђВѓЄЗТГЄБЄыЄГЄШЄЌЄЧЄЄЦЄЗЄоЄІЁЃЄЗЄЋЄтЁЂВнЖтЬЕЄЗЁЃ
ЄЪЄыЄлЄЩЁЂЄГЄьЄЯГЇЄЕЄѓЅЯЅоЄыЄяЄБЄРЄЪЄШЁЃЅВЁМЅрЄЧВнЖтЄЗЄЦЅЌЅСЅуЄђВѓЄЙЄшЄъЁЂЄГЄУЄСЄђВѓЄЗЄПЄлЄІЄЌГкЄЗЄЄЁЃЄЊЖтЄтЄЋЄЋЄщЄѓЄЗЁФЁЃЄЄЄфЄоЄЂЁЂЅЯЁМЅЩЅІЅЇЅЂЙиЦўЄЮНщДќХъЛёЄШЁЂХХЕЄТхЄЯЄЋЄЋЄУЄЦЄЄЄыЄБЄЩЁЃЄЧЄтЁЂЅНЅьЄЯЅВЁМЅрЄтЦБЄИЄЋЁЃ
ЄоЄЂЁЂЅВЅУЅШЄЗЄПЅьЅЂВшСќЄђИјГЋЄЧЄЄЪЄЄЄЮЄЯЅЂЅьЄРЄБЄЩЁЃГиНЌЅЧЁМЅПЄЮИЂЭјДиЗИЄЧПЇЁЙЄЂЄъЄНЄІЄРЄЗЁЃЄтЄУЄШЄтЁЂЅВЅУЅШЄЗЄПЅНЅьЄђИјГЋЄЧЄЄЪЄЄХРЄЯЁЂЅВЁМЅрЄЮЮрЄтЦБЄИЄРЄэЄІЄЋЁЃ
ЅЯЁМЅЩЅІЅЇЅЂЅЙЅкЅУЅЏЄЕЄЈЫўЄПЄЗЄЦЄЄЄьЄаЁЂЅьЅЂЅЋЁМЅЩЄЪЄщЄЬЅьЅЂВшСќЄЌНаЄЦЄЏЄыЄоЄЧЁЂЄЄЄФЄоЄЧЄтБфЁЙЄШЅЌЅСЅуЄђВѓЄЗТГЄБЄыЄГЄШЄЌЄЧЄЄЦЄЗЄоЄІЁЃЄЗЄЋЄтЁЂВнЖтЬЕЄЗЁЃ
ЄЪЄыЄлЄЩЁЂЄГЄьЄЯГЇЄЕЄѓЅЯЅоЄыЄяЄБЄРЄЪЄШЁЃЅВЁМЅрЄЧВнЖтЄЗЄЦЅЌЅСЅуЄђВѓЄЙЄшЄъЁЂЄГЄУЄСЄђВѓЄЗЄПЄлЄІЄЌГкЄЗЄЄЁЃЄЊЖтЄтЄЋЄЋЄщЄѓЄЗЁФЁЃЄЄЄфЄоЄЂЁЂЅЯЁМЅЩЅІЅЇЅЂЙиЦўЄЮНщДќХъЛёЄШЁЂХХЕЄТхЄЯЄЋЄЋЄУЄЦЄЄЄыЄБЄЩЁЃЄЧЄтЁЂЅНЅьЄЯЅВЁМЅрЄтЦБЄИЄЋЁЃ
ЄоЄЂЁЂЅВЅУЅШЄЗЄПЅьЅЂВшСќЄђИјГЋЄЧЄЄЪЄЄЄЮЄЯЅЂЅьЄРЄБЄЩЁЃГиНЌЅЧЁМЅПЄЮИЂЭјДиЗИЄЧПЇЁЙЄЂЄъЄНЄІЄРЄЗЁЃЄтЄУЄШЄтЁЂЅВЅУЅШЄЗЄПЅНЅьЄђИјГЋЄЧЄЄЪЄЄХРЄЯЁЂЅВЁМЅрЄЮЮрЄтЦБЄИЄРЄэЄІЄЋЁЃ
*1: ЄтЄУЄШЄтЁЂЩСЄЄЄЦЄыКЧУцЁЂCtrl+ZЄЯВПХйЄтВЁЄЙЄЗЁЂЅьЅЄЅфЁМЄЮЦЉЬРХйЄРЄЮПЇФДРАЄРЄЮЄЮГЦМяПєУЭЄЯЅСЅгЅСЅгФДРАЄЗЄоЄЏЄыЄЮЄЧЁЂМъЩСЄЄЧВшСќЄђКюРЎЄЙЄыВсФјЄЫЄЯЁЂЭ§СлЄЮВшЄЫЖсЄХЄБЄыЄПЄсЄЮФДРАКюЖШЄЌЄоЄыЄУЄШДоЄоЄьЄЦЄЄЄыЄяЄБЄЧЁЃИЮЄЫЁЂЄЋЄЋЄыЛўДжЄРЄБЄђИЋЄЦУБНуЄЫШцГгЄЙЄыЄЮЄЯЭ№ЫНЄЪЕЄЄтЄЙЄыЁЃ
[ ЅФЅУЅГЄр ]
2023/04/15(Хк) [nЧЏСАЄЮЦќЕ]
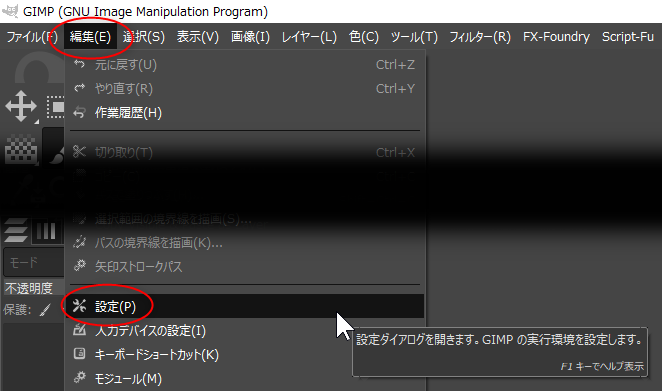
#1 [cg_tools][gimp] GIMPЄЋЄщ Stable Diffusion web UIЄђИЦЄгНаЄЗЄЦЄпЄы
ЄеЄШЄЪЄѓЄШЄЪЄЏЁЂGIMP ЄЋЄщ Stable Diffusion web UI ЄђИЦЄгНаЄЗЄЦЭјЭбЄЧЄЄЪЄЄЄтЄЮЄЋЄЪЄШЛзЄЄЄФЄЄЄПЁЃ
ДФЖЄЯАЪВМЁЃ
ЅАЅАЄУЄПДЖЄИЄЧЄЯЁЂ2ЄФЄЮЅзЅщЅАЅЄЅѓЄЫСјЖјЄЗЄПЁЃ
_GitHub - thndrbrrr/gimp-stable-boy: GIMP plugin for AUTOMATIC1111's Stable Diffusion WebUI
_GitHub - blueturtleai/gimp-stable-diffusion
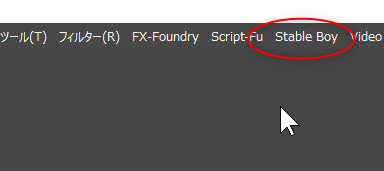
КЃВѓЄЯЁЂStable Boy (gimp-stable-boy) ЄЮЄлЄІЄђЛШЄУЄЦЄпЄыЁЃ
GIMPЄђКЦЕЏЦАЄЙЄыЄШЁЂОхЩєЄЮЅсЅЫЅхЁМЄЮУцЄЫЁЂStable Boy ЄШЄЄЄІЙрЬмЄЌС§ЄЈЄЦЄЄЄыЁЃ
ДФЖЄЯАЪВМЁЃ
- Windows10 x64 22H2
- GIMP 2.10.32 x64 Portable samjШЧ
- CPU : AMD Ryzen 5 5600X
- RAM : 16GB
- GPU : GeForce GTX 1060 6GB
ЅАЅАЄУЄПДЖЄИЄЧЄЯЁЂ2ЄФЄЮЅзЅщЅАЅЄЅѓЄЫСјЖјЄЗЄПЁЃ
_GitHub - thndrbrrr/gimp-stable-boy: GIMP plugin for AUTOMATIC1111's Stable Diffusion WebUI
_GitHub - blueturtleai/gimp-stable-diffusion
КЃВѓЄЯЁЂStable Boy (gimp-stable-boy) ЄЮЄлЄІЄђЛШЄУЄЦЄпЄыЁЃ
Ё§ ЦГЦў :
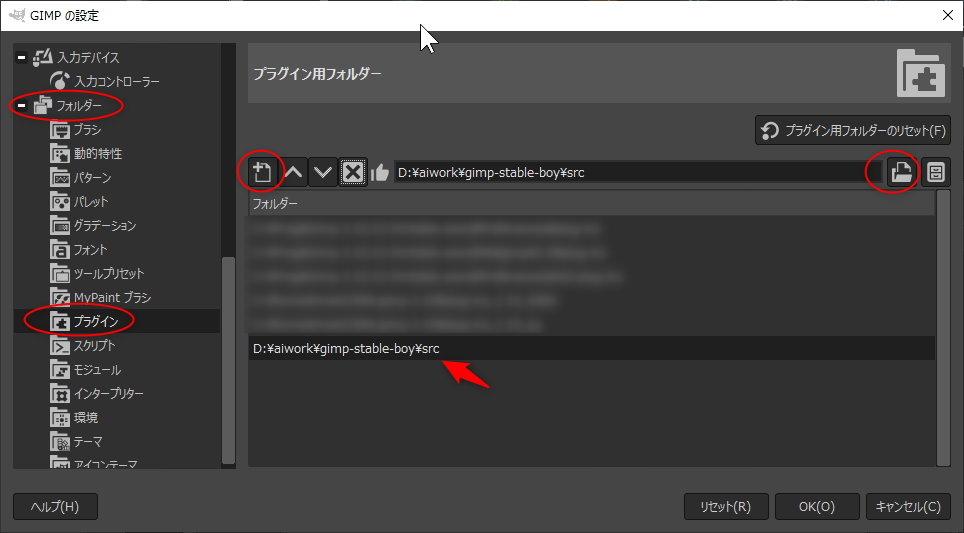
ЦГЦўЄЯАЪВМЁЃЧЄАеЄЮЅеЅЉЅыЅРЄЧЁЂgit ЄђЛШЄУЄЦЅЏЅэЁМЅѓЁЃ
КЃВѓЄЯЁЂD:\aiwork\ АЪВМЄЧКюЖШЄЗЄЦЄпЄПЁЃ
git clone https://github.com/thndrbrrr/gimp-stable-boy.git
КЃВѓЄЯЁЂD:\aiwork\ АЪВМЄЧКюЖШЄЗЄЦЄпЄПЁЃ
cd /D D:\aiwork git clone https://github.com/thndrbrrr/gimp-stable-boy.gitD:\aiwork\gimp-stable-boy\ ЄШЄЄЄІЅеЅЉЅыЅРЄЌНаЭшЄЦЁЂУцЄЫЅеЅЁЅЄЅыАьМАЄЌЅГЅдЁМЄЕЄьЄЦЄЄЄыЁЃ
Ё§ GIMPЄЮЅзЅщЅАЅЄЅѓЄШЄЗЄЦЛиФъЄЙЄы :
- GIMP 2.10 ЄђЕЏЦАЁЃ
- ЅзЅщЅАЅЄЅѓЅеЅЉЅыЅРЄЮРпФъВшЬЬЄђЩНМЈЁЃЪдНИ ЂЊ РпФъ ЂЊ ЅеЅЉЅыЅРЁМ ЂЊ ЅзЅщЅАЅЄЅѓЁЃ
- РшЄлЄЩЅЏЅэЁМЅѓЄЗЄПЅзЅщЅАЅЄЅѓЄЮОьНъ + src ЄђЛиФъЁЃ
D:\aiwork\gimp-stable-boy\src
GIMPЄђКЦЕЏЦАЄЙЄыЄШЁЂОхЩєЄЮЅсЅЫЅхЁМЄЮУцЄЫЁЂStable Boy ЄШЄЄЄІЙрЬмЄЌС§ЄЈЄЦЄЄЄыЁЃ
Ё§ Stable Diffusion web UIЄђЕЏЦАЄЗЄЦЄЊЄЏ :
Stable Diffusion web UIЄђЕЏЦАЄЗЄЦЄЊЄЄЄЦЁЂТОЄЮЅЂЅзЅъЄЋЄщЛШЄЈЄыОѕТжЄЫЄЗЄЦЄЊЄЏЁЃ
Stable Boy ЄЮРтЬРЅкЁМЅИ(README.md)ЄЫЄЯЁЂ--api ЄђЛиФъЄЗЄЦЕЏЦАЄЙЄыЁЂЄШНёЄЄЄЦЄЂЄыЁЃDOSСы(cmd.exe)ЄђГЋЄЄЄЦЁЂStable Diffusion web UI ЄЮЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅРЄђЅЋЅьЅѓЅШЅЧЅЃЅьЅЏЅШЅъЄЫЄЗЄЦЁЂАЪВМЄђМТЙдЁЃ
_API - AUTOMATIC1111/stable-diffusion-webui Wiki - GitHub
DOSСыЦтЄЫЄКЄщЄКЄщЄШЅсЅУЅЛЁМЅИЄЌЩНМЈЄЕЄьЄыЁЃФЬОяЄЪЄщЁЂАЪВМЄЮURL(URI)ЄЫЅЂЅЏЅЛЅЙЄЙЄьЄаЭјЭбЄЧЄЄыЄшЄІЄЫЄЪЄУЄЦЄЄЄыЄЯЄКЁФЁЃ
Stable Boy ЄЮРтЬРЅкЁМЅИ(README.md)ЄЫЄЯЁЂ--api ЄђЛиФъЄЗЄЦЕЏЦАЄЙЄыЁЂЄШНёЄЄЄЦЄЂЄыЁЃDOSСы(cmd.exe)ЄђГЋЄЄЄЦЁЂStable Diffusion web UI ЄЮЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅРЄђЅЋЅьЅѓЅШЅЧЅЃЅьЅЏЅШЅъЄЫЄЗЄЦЁЂАЪВМЄђМТЙдЁЃ
webui.bat --api
_API - AUTOMATIC1111/stable-diffusion-webui Wiki - GitHub
DOSСыЦтЄЫЄКЄщЄКЄщЄШЅсЅУЅЛЁМЅИЄЌЩНМЈЄЕЄьЄыЁЃФЬОяЄЪЄщЁЂАЪВМЄЮURL(URI)ЄЫЅЂЅЏЅЛЅЙЄЙЄьЄаЭјЭбЄЧЄЄыЄшЄІЄЫЄЪЄУЄЦЄЄЄыЄЯЄКЁФЁЃ
http://127.0.0.1:7860
Ё§ GIMPТІЄЧЅзЅщЅАЅЄЅѓЄЮНщДќРпФъ :
GIMPТІЄЧЁЂ512x512ЄЮВшСќЄђПЗЕЌКюРЎЄЗЄЦЄЊЄЄЄЦЄЋЄщЁЂStable Boy ЂЊ РпФъЁЂЄђСЊЄѓЄЧЁЂЅЂЅЏЅЛЅЙЄЙЄйЄURL(URI)ЄђЛиФъЄЙЄыЁЃ
ВПЄЋЄЗЄщЄЮВшСќЅІЅЄЅѓЅЩЅІЄЌЬЕЄЄЄШЅсЅЫЅхЁМСЊТђЄЌЄЧЄЄЪЄЄЄЮЄЧУэАеЁЃ
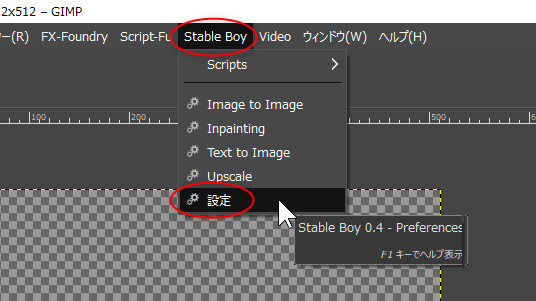
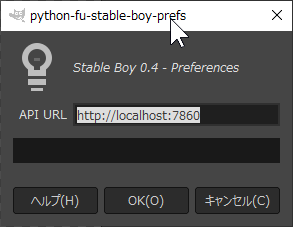
ЅЧЅеЅЉЅыЅШЄЧЄЯЁЂhttp://localhost:7860 ЄЫЄЪЄУЄЦЄЄЄыЄЌЁЂЄГЄЮРпФъЄРЄШЬЕШПБўЄРЄУЄПЄЮЄЧЁЂhttp://127.0.0.1:7860 ЄЫЪбЙЙЄЙЄыЁЃ
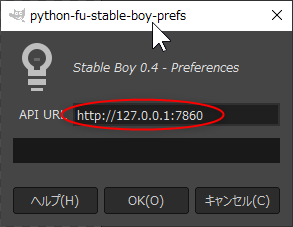
ЄСЄЪЄпЄЫЁЂРпФъЄЗЄПURLЄЯЪнТИЄЕЄьЄЪЄЄЄЮЄЧЁЂGIMP ЄђЕЏЦАЄЙЄыЄПЄгЄЫЁЂЫшВѓРпФъЄЗЄЪЄЄЄШЄЄЄБЄЪЄЄЁФЁЃЬЬХнНЄЄЁЃ
gimp-stable-boy\src\gimp_stable_boy\constants.py ЄЮУцЄЧЁЂ"http://localhost:7860" ЄЌФъЕСЄЕЄьЄЦЄЄЄыЄЮЄЧЁЂЄНЄГЄђНЄРЕЄЗЄЦЄЗЄоЄІЄЮЄтМъЄЋЄтЄЗЄьЄЪЄЄЁЃ
ВПЄЋЄЗЄщЄЮВшСќЅІЅЄЅѓЅЩЅІЄЌЬЕЄЄЄШЅсЅЫЅхЁМСЊТђЄЌЄЧЄЄЪЄЄЄЮЄЧУэАеЁЃ
ЅЧЅеЅЉЅыЅШЄЧЄЯЁЂhttp://localhost:7860 ЄЫЄЪЄУЄЦЄЄЄыЄЌЁЂЄГЄЮРпФъЄРЄШЬЕШПБўЄРЄУЄПЄЮЄЧЁЂhttp://127.0.0.1:7860 ЄЫЪбЙЙЄЙЄыЁЃ
http://127.0.0.1:7860
ЄСЄЪЄпЄЫЁЂРпФъЄЗЄПURLЄЯЪнТИЄЕЄьЄЪЄЄЄЮЄЧЁЂGIMP ЄђЕЏЦАЄЙЄыЄПЄгЄЫЁЂЫшВѓРпФъЄЗЄЪЄЄЄШЄЄЄБЄЪЄЄЁФЁЃЬЬХнНЄЄЁЃ
gimp-stable-boy\src\gimp_stable_boy\constants.py ЄЮУцЄЧЁЂ"http://localhost:7860" ЄЌФъЕСЄЕЄьЄЦЄЄЄыЄЮЄЧЁЂЄНЄГЄђНЄРЕЄЗЄЦЄЗЄоЄІЄЮЄтМъЄЋЄтЄЗЄьЄЪЄЄЁЃ
Ё§ МТКнЄЫЭјЭбЄЗЄЦЄпЄыЁЃ :
Stable Boy ЂЊ Text to Image ЄђСЊЄжЁЃЄЊЄНЄщЄЏ txt2img ЄђИЦЄгНаЄЗЄЦЁЂБбЪИЄфБбУБИьЄђТЧЄСЙўЄсЄаЁЂВшСќРИРЎЄЗЄЦЄЏЄьЄыЄЮЄРЄэЄІЁЃ
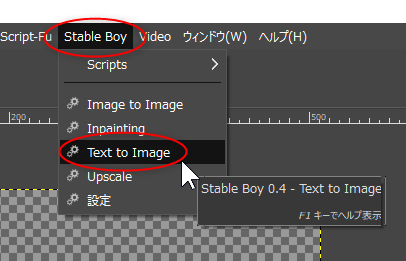
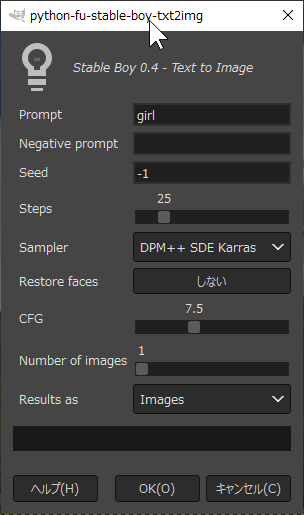
Prompt ЄЫЁжgirlЁзЄШЄЧЄтТЧЄСЙўЄѓЄЧЦАКюГЮЧЇЁЃЄоЄПЁЂResults as ЄЧЁЂLayer (ПЗЕЌЅьЅЄЅфЁМКюРЎ) ЄЋ Image (ПЗЕЌВшСќКюРЎ) ЄђСЊЄйЄыЁЃ
Stable Diffusion web UIТІЄЮНшЭ§ЄЌНЊЄяЄыЄШЁЂGIMPЄЮЅІЅЄЅѓЅЩЅІЦтЄЫРИРЎВшСќЄЌЪжЄУЄЦЄЏЄыЁЃ
Inpaint ЄтЛШЄЈЄыЄщЄЗЄЄЁЃ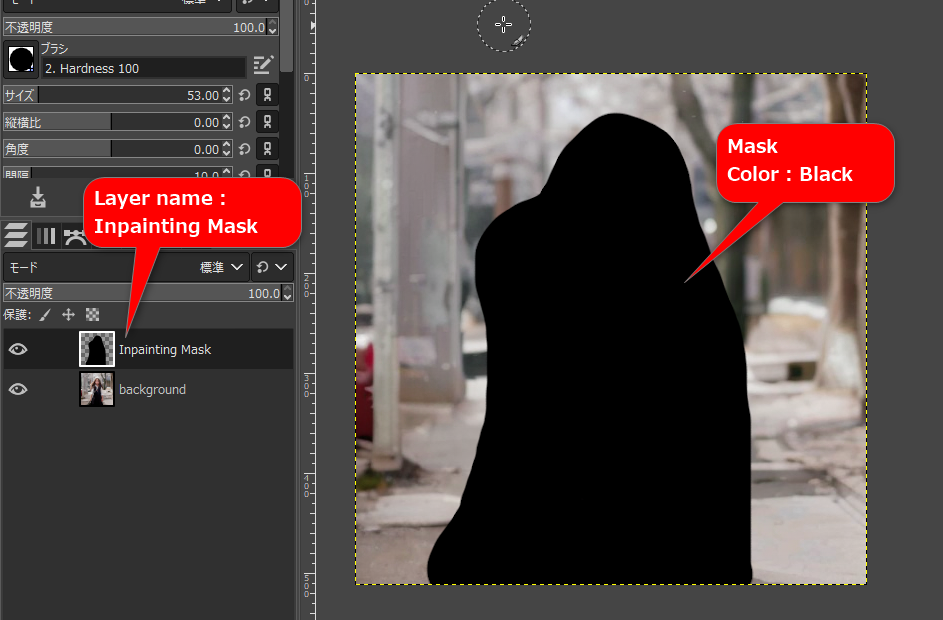
ЄГЄьЄЧЁЂЙѕПЇЄЫХЩЄУЄПЩєЪЌЄЌПЗЄЗЄЏКюРЎЄЕЄьЄыЁЃ
Prompt ЄЫЁжgirlЁзЄШЄЧЄтТЧЄСЙўЄѓЄЧЦАКюГЮЧЇЁЃЄоЄПЁЂResults as ЄЧЁЂLayer (ПЗЕЌЅьЅЄЅфЁМКюРЎ) ЄЋ Image (ПЗЕЌВшСќКюРЎ) ЄђСЊЄйЄыЁЃ
Stable Diffusion web UIТІЄЮНшЭ§ЄЌНЊЄяЄыЄШЁЂGIMPЄЮЅІЅЄЅѓЅЩЅІЦтЄЫРИРЎВшСќЄЌЪжЄУЄЦЄЏЄыЁЃ
Inpaint ЄтЛШЄЈЄыЄщЄЗЄЄЁЃ
- Inpainting Mask ЄШЄЄЄІЬОСАЄЮЅьЅЄЅфЁМЄђПЗЕЌКюРЎЄЗЄЦЁЂАьШжОхЄЮГЌСиЄЫЛ§ЄУЄЦЄЏЄыЁЃ
- ЙѕПЇЄЧЅоЅЙЅЏЄЗЄПЄЄЩєЪЌЄђХЩЄъФйЄЙЁЃ
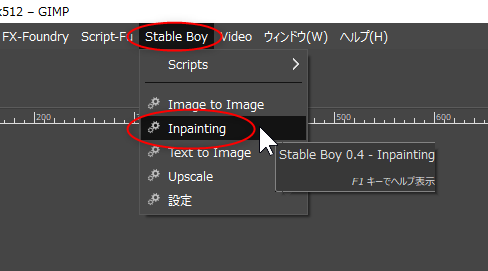
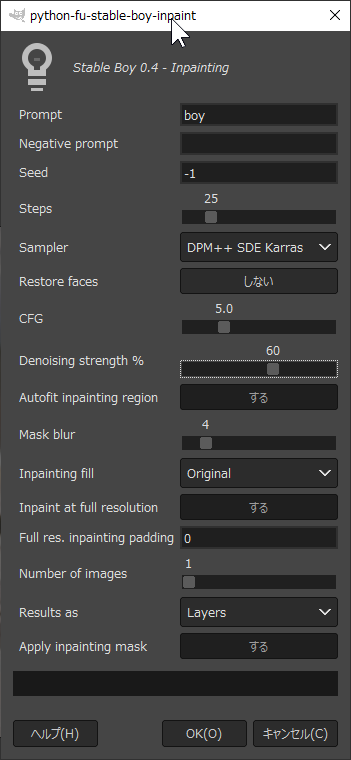
- ЄНЄЮОѕТжЄЧЁЂStable Boy ЂЊ Inpainting ЄђСЊТђЁЃ
ЄГЄьЄЧЁЂЙѕПЇЄЫХЩЄУЄПЩєЪЌЄЌПЗЄЗЄЏКюРЎЄЕЄьЄыЁЃ
Ё§ НЊЮЛЄЮЛХЪ§ :
GIMPЄђНЊЮЛЄЗЄПЄщЁЂStable Diffusion web UI ЄђМТЙдЄЗЄЦЄыDOSСыЄтЪФЄИЄЦЄЗЄоЄУЄЦЄЄЄЄЁЃ
Ё§ ЬфТъХР :
АьБўЁЂЄГЄьЄЧЁЂGIMPЄЋЄщ Stable Diffusion web UI ЄђЭјЭбЄЙЄыЄГЄШЄЌЄЧЄЄыЄшЄІЄЫЄЪЄУЄПЄБЄЩЁЃЄПЄРЁЂЄГЄЮЅзЅщЅАЅЄЅѓЁЂЛўЁЙЦАКюЄЌВјЄЗЄЄЁФЁЃ
ЅзЅщЅАЅЄЅѓЄЮЅРЅЄЅЂЅэЅАЄЧЁжOKЁзЄђЅЏЅъЅУЅЏЄЗЄЦЁЂЄЙЄАЄЫЅРЅЄЅЂЅэЅАЄЌЪФЄИЄщЄьЄыЛўЄЯЁЂВПЄщЄЋЄЮНшЭ§ЄЫМКЧдЄЗЄЦЄЄЄыЁЃНшЭ§ЄЫМКЧдЄЗЄЦЄыЄБЄЩЁЂStable Diffusion web UIТІЄЯЁЂНшЭ§ЄђТГЙдЄЗЄЦЄЄЄыЁФЁЃ
ЫмХіЄЪЄщЁЂStable Diffusion web UI ЄЌРИРЎНшЭ§ЄђНЊЄЈЄыЄоЄЧЁЂЅРЅЄЅЂЅэЅАЄЌГЋЄЄУЄбЄЪЄЗЄЮЄоЄоЄЫЄЪЄыЄЗЁЂЅРЅЄЅЂЅэЅАЄЮЅІЅЄЅѓЅЩЅІЅПЅЄЅШЅыЄЫЁж(БўХњЄЪЄЗ)ЁзЄтЩНМЈЄЕЄьЄыЁЃStable Diffusion web UIТІЄЮНшЭ§ЄЌНЊЄяЄьЄаЁЂЅРЅЄЅЂЅэЅАОхЄЮЁжProcessingЁзЄЮЩНМЈЄЌ100%ЄЫЄЪЄУЄЦЁЂРИРЎВшСќЄЌЪжЄУЄЦЄЏЄыЄЯЄКЁЃ
ЄШЄЄЄІЄГЄШЄЧЁЂЅРЅЄЅЂЅэЅАЄЌЄЙЄАЄЫЪФЄИЄПЄщЁЂНшЭ§ЄЫМКЧдЄЗЄЦЄыЄШШНУЧЄЗЄЦЁЂStable Diffusion web UIТІЄЮНшЭ§ЄЌНЊЄяЄУЄПКЂЄђИЋЗзЄщЄУЄЦЄЋЄщЁЂКЦХйЅзЅщЅАЅЄЅѓЄђМТЙдЄЗЄЦЄпЄыЄйЄЗЁЃ
ЄтЄІАьХРЁЃИјМАЅЩЅЅхЅсЅѓЅШЄЫЄтНёЄЄЄЦЄЂЄыЄБЄЩЁЂГиНЌЅтЅЧЅыЅЧЁМЅПЄЮСЊТђЄЯЁЂЄГЄЮЅзЅщЅАЅЄЅѓТІЄЋЄщЄЧЄЄЪЄЄЄЮЄЧЁЂStable Diffusion web UI ТІЄЧЛіСАЄЫСЊТђЄЗЄЦЄЊЄЏЄГЄШЁЃ
ЅзЅщЅАЅЄЅѓЄЮЅРЅЄЅЂЅэЅАЄЧЁжOKЁзЄђЅЏЅъЅУЅЏЄЗЄЦЁЂЄЙЄАЄЫЅРЅЄЅЂЅэЅАЄЌЪФЄИЄщЄьЄыЛўЄЯЁЂВПЄщЄЋЄЮНшЭ§ЄЫМКЧдЄЗЄЦЄЄЄыЁЃНшЭ§ЄЫМКЧдЄЗЄЦЄыЄБЄЩЁЂStable Diffusion web UIТІЄЯЁЂНшЭ§ЄђТГЙдЄЗЄЦЄЄЄыЁФЁЃ
ЫмХіЄЪЄщЁЂStable Diffusion web UI ЄЌРИРЎНшЭ§ЄђНЊЄЈЄыЄоЄЧЁЂЅРЅЄЅЂЅэЅАЄЌГЋЄЄУЄбЄЪЄЗЄЮЄоЄоЄЫЄЪЄыЄЗЁЂЅРЅЄЅЂЅэЅАЄЮЅІЅЄЅѓЅЩЅІЅПЅЄЅШЅыЄЫЁж(БўХњЄЪЄЗ)ЁзЄтЩНМЈЄЕЄьЄыЁЃStable Diffusion web UIТІЄЮНшЭ§ЄЌНЊЄяЄьЄаЁЂЅРЅЄЅЂЅэЅАОхЄЮЁжProcessingЁзЄЮЩНМЈЄЌ100%ЄЫЄЪЄУЄЦЁЂРИРЎВшСќЄЌЪжЄУЄЦЄЏЄыЄЯЄКЁЃ
ЄШЄЄЄІЄГЄШЄЧЁЂЅРЅЄЅЂЅэЅАЄЌЄЙЄАЄЫЪФЄИЄПЄщЁЂНшЭ§ЄЫМКЧдЄЗЄЦЄыЄШШНУЧЄЗЄЦЁЂStable Diffusion web UIТІЄЮНшЭ§ЄЌНЊЄяЄУЄПКЂЄђИЋЗзЄщЄУЄЦЄЋЄщЁЂКЦХйЅзЅщЅАЅЄЅѓЄђМТЙдЄЗЄЦЄпЄыЄйЄЗЁЃ
ЄтЄІАьХРЁЃИјМАЅЩЅЅхЅсЅѓЅШЄЫЄтНёЄЄЄЦЄЂЄыЄБЄЩЁЂГиНЌЅтЅЧЅыЅЧЁМЅПЄЮСЊТђЄЯЁЂЄГЄЮЅзЅщЅАЅЄЅѓТІЄЋЄщЄЧЄЄЪЄЄЄЮЄЧЁЂStable Diffusion web UI ТІЄЧЛіСАЄЫСЊТђЄЗЄЦЄЊЄЏЄГЄШЁЃ
Ё§ ЛЈДЖ :
ЙЭЄЈЄЦЄпЄПЄщЁЂWebЅжЅщЅІЅЖЗаЭГЄЧ Stable Diffusion web UI ЄђЛШЄУЄЦЄтЁЂРфЄЈЄКpngВшСќЄЌЪнТИЄЕЄьЄыЄЮЄРЄЋЄщЁФЁЃЅЈЅЏЅЙЅзЅэЁМЅщХљЄЋЄщ GIMP ЄЫВшСќЄђЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзЄЗЄЦЅЂЅьЅГЅьЄЙЄьЄаКбЄпЄНЄІЄЪЕЄЄтЄЙЄыЁФЁЃЄЄЄфЁЂЄНЄЮОьЙчЁЂЅоЅЙЅЏВшСќЄђКюРЎЄЗЄЦХЯЄЙЄЮЄЌЬЬХнНЄЄЄЋЄЪЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/16(Цќ) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] RembgЄЧЅЈЅщЁМЄЌНаЄЦОЏЄЗЅЯЅоЄУЄП
ВшСќРИРЎAIЁЂStabel Diffusion web UI ЄЫЁЂЧиЗЪЄђОУЕюЄЗЄЦЄЏЄьЄыЄщЄЗЄЄГШФЅЕЁЧНЁЂRembg ЄђЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЛШЄУЄЦЄпЄшЄІЄШЄЗЄПЄЮЄРЄБЄЩЁЃ
_GitHub - AUTOMATIC1111/stable-diffusion-webui-rembg: Removes backgrounds from pictures. Extension for webui.
_ДЪУБЄЫЧиЗЪЄђНќЕюЄЗЄЦЦЉВсЄЧЄЄыЁЊRembgЄЮЛШЄЄЪ§ЁЪWebUI AUTOMATIC1111 ГШФЅЕЁЧНЁЫ | note_lilish
_ВшСќЄЮЧиЗЪЄђКяНќЄЙЄыГШФЅЕЁЧНЁжRembgЁзЄЮЛШЄЄЪ§ЁкStable Diffusion web UIЁл | ЄЏЄэЄЏЄоЄНЄеЄШ
ЬЏЄЪЅЈЅщЁМЄЌНаЄЦОЏЄЗЅЯЅоЄУЄЦЄЗЄоЄУЄПЄЮЄЧЁЂВђЗшЄЙЄйЄЏЅИЅПЅаЅПЄЗЄПЮЎЄьЄђЅсЅтЁЃ
АьБўЗыЯРЄђРшЄЫНёЄЏЄШЁЂPython ЄЮ rembg ЄШ onnxruntime-gpu ЄђЅЂЅѓЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЋЄщКЦЅЄЅѓЅЙЅШЁМЅыЄЙЄыЄШВўСБЄЙЄыЛўЄтЄЂЄыЄУЄнЄЄЁЃ
ДФЖЄЯЁЂДФЖЄЯЁЂWindows10 x64 22H2 + Pyhton 3.10.6ЁЃAMD Ryzen 5 5600X + GeForce GTX 1060 6GBЁЃ
Stable Diffusion web UI (АЪВМЁЂSDwebUIЄШЕНв) ЄЯЁЂD:\aiwork\stable-diffusion-webui\ ЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЂЄыЁЃ
Rembg ЄЮЅЄЅѓЅЙЅШЁМЅыКюЖШМЋТЮЄЯСАНвЄЮВђРтЅкЁМЅИЄђЛВЙЭЄЫЄЗЄЦКюЖШЁЃSDwebUI ЄЮЅкЁМЅИЁЂhttp://127.0.0.1:7860/ ЄђWebЅжЅщЅІЅЖЄЧГЋЄЄЄЦЁЂГШФЅЕЁЧН Extensions ЅПЅжЄђГЋЄБЄаЁЂЄНЄГЄЋЄщЅЄЅѓЅЙЅШЁМЅыЄЌЄЧЄЄыЁЃ
Extras ЅПЅжЄђГЋЄЄЄЦЁЂВМЄЮЄлЄІЄЫЧиЗЪКяНќДиЯЂЄЮЙрЬмЄЌС§ЄЈЄЦЄЄЄыЄЋЄщЁЂЄНЄЮЄЂЄПЄъЄђЛиФъЄЗЄЦЄЄЄБЄаНшЭ§ЄЧЄЄыЄЯЄКЄЪЄЮЄРЄБЄЩЁЂАЪВМЄЮЅЈЅщЁМЄЌНаЄЦЄЗЄоЄУЄПЁЃ
ЄЩЄІЄтЄшЄЏЪЌЄЋЄщЄѓЄЌЁЂonnxruntime_providers_tensorrt.dll ЄШЄфЄщЄЧЅЈЅщЁМЄЌНаЄЦЄыЄѓЄРЄэЄІЄЋЁЉ
ЅеЅЁЅЄЅыМЋТЮЄЯЁЂD:\aiwork\stable-diffusion-webui\venv\Lib\site-packages\onnxruntime\capi\ ЄЮУцЄЫЁЂonnxruntime_providers_tensorrt.dll ЄЌЄСЄуЄѓЄШЄЂЄУЄПЁЃ
ЅЈЅщЁМЅсЅУЅЛЁМЅИЦтЭЦЄЧЅАЅАЄУЄПЄщЁЂАЪВМЄЮЄфЄъМшЄъЄЫСјЖјЁЃ
_[BUG] ...RuntimeError: ...\onnxruntime\capi\onnxruntime_providers_tensorrt.dll" - Issue #312 - danielgatis/rembg - GitHub
rembg ЄШ onnxruntime ЄђЅЂЅѓЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЋЄщКЦЅЄЅѓЅЙЅШЁМЅыЄЗЄПЄщВђЗшЄЗЄПЁЂЄШЄЄЄІЪѓЙ№ЄЌЄЂЄыЄЪЁФЁЃЄСЄЪЄпЄЫЁЂSDwebUIЄЮЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅРЄЫЁЂPython ДФЖЄЌЦўЄУЄЦЄыЄЯЄКЄЪЄЮЄЧЁЂ(SDwebUIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\venv\Scripts\ ЄђЅЋЅьЅѓЅШЅЧЅЃЅьЅЏЅШЅъЄЫЄЗЄЦЄЋЄщ pip ЄђЛШЄУЄЦКюЖШЄЙЄыЩЌЭзЄЌЄЂЄыЁЃ
pip ЄЧЁЂГЦЅтЅИЅхЁМЅыЄЮЅЂЅѓЅЄЅѓЅЙЅШЁМЅыЄШКЦЅЄЅѓЅЙЅШЁМЅыЁЃ
ЄЗЄЋЄЗЁЂpip ЄЌАЪВМЄЮЄшЄІЄЪЅЈЅщЁМЅсЅУЅЛЁМЅИЄђНаЄЗЄЦЄЄПЁЃ
open-clip-torch 2.7.0 ЄЌ protobuf 3.20.0 ЄђЭзЕсЄЗЄЦЄыЄБЄЩЁЂprotobuf 3.20.3 ЄЌЅЄЅѓЅЙЅШЁМЅыЄЕЄьЄСЄуЄУЄЦЄыЄОЁЂЄШЄЄЄІЄГЄШЄЋЄЪЁЃ
ЄЪЄщЁЂprotobuf 3.20.0 ЄђЅЄЅѓЅЙЅШЁМЅыЄЙЄьЄаЄЄЄЄЄЮЄРЄэЄІЄЋЁЃ
onnx 1.13.1 ЄЌ protobuf 3.20.2 АЪОхЄђЭзЕсЄЗЄЦЄыЄБЄЩЁЂprotobuf 3.20.0 ЄЌЅЄЅѓЅЙЅШЁМЅыЄЕЄьЄСЄуЄУЄЦЄыЄОЁЂЄШХмЄщЄьЄПЁЃЄЩЄІЄЗЄэЄШЁЃ
onnx 1.13.0 ЄђЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЄщЄЩЄІЄЪЄыЄРЄэЄІЁЃ
ЄШЄъЄЂЄЈЄКЅРЅсИЕЄЧЁЂЬмЄЫЦўЄУЄПЅтЅИЅхЁМЅыЬОЄЫЄФЄЄЄЦЁЂpip ЄЫ -U ЄђЄФЄБЄЦКЦЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЁЃ-U ЄЯЁЂЄНЄЮЅтЅИЅхЁМЅыЄЮПЗШЧЄЌWebОхЄЫТИКпЄЙЄыЄЪЄщЅЂЅУЅзЅЧЁМЅШЄЙЄыЄшЄІЄЫЛиМЈЄЙЄыЅЊЅзЅЗЅчЅѓЁЃ
ЄГЄѓЄЪДЖЄИЄЧЅЂЅьЅГЅьЄђКЦЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЄЄПЄщЁЂКЧНщЄЫЅсЅтЄЗЄПЅЈЅщЁМЄЌНаЄЪЄЄОѕТжЄЫЄЪЄУЄЦЁЂRembg ЄЌЄшЄІЄфЄЏЦАЄЄЄЦЄЏЄьЄПЁЃНѕЄЋЄУЄПЁЃ
ЄСЄЪЄпЄЫЁЂИНЛўХРЄЧЄЯЁЂГЦЅтЅИЅхЁМЅыЄЮЅаЁМЅИЅчЅѓЄЯАЪВМЄЮЄшЄІЄЫЄЪЄУЄЦЄыЁЃ
_GitHub - AUTOMATIC1111/stable-diffusion-webui-rembg: Removes backgrounds from pictures. Extension for webui.
_ДЪУБЄЫЧиЗЪЄђНќЕюЄЗЄЦЦЉВсЄЧЄЄыЁЊRembgЄЮЛШЄЄЪ§ЁЪWebUI AUTOMATIC1111 ГШФЅЕЁЧНЁЫ | note_lilish
_ВшСќЄЮЧиЗЪЄђКяНќЄЙЄыГШФЅЕЁЧНЁжRembgЁзЄЮЛШЄЄЪ§ЁкStable Diffusion web UIЁл | ЄЏЄэЄЏЄоЄНЄеЄШ
ЬЏЄЪЅЈЅщЁМЄЌНаЄЦОЏЄЗЅЯЅоЄУЄЦЄЗЄоЄУЄПЄЮЄЧЁЂВђЗшЄЙЄйЄЏЅИЅПЅаЅПЄЗЄПЮЎЄьЄђЅсЅтЁЃ
АьБўЗыЯРЄђРшЄЫНёЄЏЄШЁЂPython ЄЮ rembg ЄШ onnxruntime-gpu ЄђЅЂЅѓЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЋЄщКЦЅЄЅѓЅЙЅШЁМЅыЄЙЄыЄШВўСБЄЙЄыЛўЄтЄЂЄыЄУЄнЄЄЁЃ
ДФЖЄЯЁЂДФЖЄЯЁЂWindows10 x64 22H2 + Pyhton 3.10.6ЁЃAMD Ryzen 5 5600X + GeForce GTX 1060 6GBЁЃ
Stable Diffusion web UI (АЪВМЁЂSDwebUIЄШЕНв) ЄЯЁЂD:\aiwork\stable-diffusion-webui\ ЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЂЄыЁЃ
Rembg ЄЮЅЄЅѓЅЙЅШЁМЅыКюЖШМЋТЮЄЯСАНвЄЮВђРтЅкЁМЅИЄђЛВЙЭЄЫЄЗЄЦКюЖШЁЃSDwebUI ЄЮЅкЁМЅИЁЂhttp://127.0.0.1:7860/ ЄђWebЅжЅщЅІЅЖЄЧГЋЄЄЄЦЁЂГШФЅЕЁЧН Extensions ЅПЅжЄђГЋЄБЄаЁЂЄНЄГЄЋЄщЅЄЅѓЅЙЅШЁМЅыЄЌЄЧЄЄыЁЃ
Extras ЅПЅжЄђГЋЄЄЄЦЁЂВМЄЮЄлЄІЄЫЧиЗЪКяНќДиЯЂЄЮЙрЬмЄЌС§ЄЈЄЦЄЄЄыЄЋЄщЁЂЄНЄЮЄЂЄПЄъЄђЛиФъЄЗЄЦЄЄЄБЄаНшЭ§ЄЧЄЄыЄЯЄКЄЪЄЮЄРЄБЄЩЁЂАЪВМЄЮЅЈЅщЁМЄЌНаЄЦЄЗЄоЄУЄПЁЃ
Error completing request
Arguments: (0, <PIL.Image.Image image mode=RGB size=192x128 at 0x1C2B77937F0>, None, '', '', True, 0, 4, 512, 512, True, 'None', 'None', 0, 0, 0, 0, False, False, 4, 'u2net', False, True, 240, 10, 10) {}
Traceback (most recent call last):
File "D:\aiwork\stable-diffusion-webui\modules\call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "D:\aiwork\stable-diffusion-webui\modules\call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "D:\aiwork\stable-diffusion-webui\modules\postprocessing.py", line 56, in run_postprocessing
scripts.scripts_postproc.run(pp, args)
File "D:\aiwork\stable-diffusion-webui\modules\scripts_postprocessing.py", line 130, in run
script.process(pp, **process_args)
File "D:\aiwork\stable-diffusion-webui\extensions\stable-diffusion-webui-rembg\scripts\postprocessing_rembg.py", line 53, in process
session=rembg.new_session(model),
File "D:\aiwork\stable-diffusion-webui\venv\lib\site-packages\rembg\session_factory.py", line 71, in new_session
ort.InferenceSession(
File "D:\aiwork\stable-diffusion-webui\venv\lib\site-packages\onnxruntime\capi\onnxruntime_inference_collection.py", line 360, in __init__
self._create_inference_session(providers, provider_options, disabled_optimizers)
File "D:\aiwork\stable-diffusion-webui\venv\lib\site-packages\onnxruntime\capi\onnxruntime_inference_collection.py", line 408, in _create_inference_session
sess.initialize_session(providers, provider_options, disabled_optimizers)
RuntimeError: D:\a\_work\1\s\onnxruntime\core\session\provider_bridge_ort.cc:1106 onnxruntime::ProviderLibrary::Get [ONNXRuntimeError] : 1 : FAIL : LoadLibrary failed with error 126 "" when trying to load "D:\aiwork\stable-diffusion-webui\venv\lib\site-packages\onnxruntime\capi\onnxruntime_providers_tensorrt.dll"
ЄЩЄІЄтЄшЄЏЪЌЄЋЄщЄѓЄЌЁЂonnxruntime_providers_tensorrt.dll ЄШЄфЄщЄЧЅЈЅщЁМЄЌНаЄЦЄыЄѓЄРЄэЄІЄЋЁЉ
ЅеЅЁЅЄЅыМЋТЮЄЯЁЂD:\aiwork\stable-diffusion-webui\venv\Lib\site-packages\onnxruntime\capi\ ЄЮУцЄЫЁЂonnxruntime_providers_tensorrt.dll ЄЌЄСЄуЄѓЄШЄЂЄУЄПЁЃ
ЅЈЅщЁМЅсЅУЅЛЁМЅИЦтЭЦЄЧЅАЅАЄУЄПЄщЁЂАЪВМЄЮЄфЄъМшЄъЄЫСјЖјЁЃ
_[BUG] ...RuntimeError: ...\onnxruntime\capi\onnxruntime_providers_tensorrt.dll" - Issue #312 - danielgatis/rembg - GitHub
rembg ЄШ onnxruntime ЄђЅЂЅѓЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЋЄщКЦЅЄЅѓЅЙЅШЁМЅыЄЗЄПЄщВђЗшЄЗЄПЁЂЄШЄЄЄІЪѓЙ№ЄЌЄЂЄыЄЪЁФЁЃЄСЄЪЄпЄЫЁЂSDwebUIЄЮЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅРЄЫЁЂPython ДФЖЄЌЦўЄУЄЦЄыЄЯЄКЄЪЄЮЄЧЁЂ(SDwebUIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\venv\Scripts\ ЄђЅЋЅьЅѓЅШЅЧЅЃЅьЅЏЅШЅъЄЫЄЗЄЦЄЋЄщ pip ЄђЛШЄУЄЦКюЖШЄЙЄыЩЌЭзЄЌЄЂЄыЁЃ
cd /d D:\aiwork\stable-diffusion-webui\venv\Scripts pip list
pip ЄЧЁЂГЦЅтЅИЅхЁМЅыЄЮЅЂЅѓЅЄЅѓЅЙЅШЁМЅыЄШКЦЅЄЅѓЅЙЅШЁМЅыЁЃ
pip uninstall rembg pip uninstall onnxruntime pip install rembg[gpu] onnxruntime-gpu
ЄЗЄЋЄЗЁЂpip ЄЌАЪВМЄЮЄшЄІЄЪЅЈЅщЁМЅсЅУЅЛЁМЅИЄђНаЄЗЄЦЄЄПЁЃ
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. open-clip-torch 2.7.0 requires protobuf==3.20.0, but you have protobuf 3.20.3 which is incompatible.
open-clip-torch 2.7.0 ЄЌ protobuf 3.20.0 ЄђЭзЕсЄЗЄЦЄыЄБЄЩЁЂprotobuf 3.20.3 ЄЌЅЄЅѓЅЙЅШЁМЅыЄЕЄьЄСЄуЄУЄЦЄыЄОЁЂЄШЄЄЄІЄГЄШЄЋЄЪЁЃ
ЄЪЄщЁЂprotobuf 3.20.0 ЄђЅЄЅѓЅЙЅШЁМЅыЄЙЄьЄаЄЄЄЄЄЮЄРЄэЄІЄЋЁЃ
pip install protobuf==3.20.0
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. onnx 1.13.1 requires protobuf<4,>=3.20.2, but you have protobuf 3.20.0 which is incompatible.
onnx 1.13.1 ЄЌ protobuf 3.20.2 АЪОхЄђЭзЕсЄЗЄЦЄыЄБЄЩЁЂprotobuf 3.20.0 ЄЌЅЄЅѓЅЙЅШЁМЅыЄЕЄьЄСЄуЄУЄЦЄыЄОЁЂЄШХмЄщЄьЄПЁЃЄЩЄІЄЗЄэЄШЁЃ
onnx 1.13.0 ЄђЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЄщЄЩЄІЄЪЄыЄРЄэЄІЁЃ
pip install onnx==1.13.0ЄфЄЯЄъХмЄщЄьЄыЄЪЁФЁЃ
ЄШЄъЄЂЄЈЄКЅРЅсИЕЄЧЁЂЬмЄЫЦўЄУЄПЅтЅИЅхЁМЅыЬОЄЫЄФЄЄЄЦЁЂpip ЄЫ -U ЄђЄФЄБЄЦКЦЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЁЃ-U ЄЯЁЂЄНЄЮЅтЅИЅхЁМЅыЄЮПЗШЧЄЌWebОхЄЫТИКпЄЙЄыЄЪЄщЅЂЅУЅзЅЧЁМЅШЄЙЄыЄшЄІЄЫЛиМЈЄЙЄыЅЊЅзЅЗЅчЅѓЁЃ
pip install rembg[gpu] onnxruntime-gpu -U
ЄГЄѓЄЪДЖЄИЄЧЅЂЅьЅГЅьЄђКЦЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЄЄПЄщЁЂКЧНщЄЫЅсЅтЄЗЄПЅЈЅщЁМЄЌНаЄЪЄЄОѕТжЄЫЄЪЄУЄЦЁЂRembg ЄЌЄшЄІЄфЄЏЦАЄЄЄЦЄЏЄьЄПЁЃНѕЄЋЄУЄПЁЃ
ЄСЄЪЄпЄЫЁЂИНЛўХРЄЧЄЯЁЂГЦЅтЅИЅхЁМЅыЄЮЅаЁМЅИЅчЅѓЄЯАЪВМЄЮЄшЄІЄЫЄЪЄУЄЦЄыЁЃ
> pip list | grep -E "rembg|onnx|proto|open-clip-torch" onnx 1.13.0 onnxruntime 1.14.1 onnxruntime-gpu 1.14.1 open-clip-torch 2.16.0 protobuf 3.20.3 rembg 2.0.32
Ё§ pipЄЌЗйЙ№ЄђНаЄЙ :
ЭОУЬЁЃpip list ЄђТЧЄУЄПЄщЁЂЄЪЄѓЄРЄЋЄфЄПЄщЄШЗйЙ№ЄЌНаЄЦЄЄПЁЃ
АЪВМЄЮЛіЮуЄщЄЗЄЄЁЃ
_pip listЄЮWARNINGЄђОУЄЙ - Qiita
D:\aiwork\stable-diffusion-webui\venv\Lib\site-packages\ ЦтЄЫЁЂКЧНщЄЮЪИЛњЄЌ Ёж~ЁзЄЫЄЪЄУЄЦЄыЅЧЅЃЅьЅЏЅШЅъЄЌЄЄЄЏЄФЄЋЄЂЄУЄПЁЃЄНЄьЄщЄЮЅЧЅЃЅьЅЏЅШЅъЄђЪЬЄЮОьНъЄЫАмЦАЄЗЄЦЄпЄПЄШЄГЄэЁЂpip list ЄђТЧЄУЄЦЄтЗйЙ№ЄЌНаЄЦЄГЄЪЄЏЄЪЄУЄПЁЃ
АЪВМЄЮЛіЮуЄщЄЗЄЄЁЃ
_pip listЄЮWARNINGЄђОУЄЙ - Qiita
D:\aiwork\stable-diffusion-webui\venv\Lib\site-packages\ ЦтЄЫЁЂКЧНщЄЮЪИЛњЄЌ Ёж~ЁзЄЫЄЪЄУЄЦЄыЅЧЅЃЅьЅЏЅШЅъЄЌЄЄЄЏЄФЄЋЄЂЄУЄПЁЃЄНЄьЄщЄЮЅЧЅЃЅьЅЏЅШЅъЄђЪЬЄЮОьНъЄЫАмЦАЄЗЄЦЄпЄПЄШЄГЄэЁЂpip list ЄђТЧЄУЄЦЄтЗйЙ№ЄЌНаЄЦЄГЄЪЄЏЄЪЄУЄПЁЃ
[ ЅФЅУЅГЄр ]
2023/04/17(Зю) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] img2imgЄЯЦёЄЗЄЄ
Stable Diffusion web UI ЄЮ img2img ЄЧЁЂinpaint + sketchЕЁЧНЄђЛШЄУЄЦЁЂЄШЄЂЄыЪЊТЮЄђОЄДЄЗЄшЄІЄШЄЗЄПЄЮЄРЄБЄЩЁЂЄГЄьЄЌЄЪЄЋЄЪЄЋЛзЄУЄПФЬЄъЄЫЄЄЄЋЄЪЄЄЁЃЄЖЄУЄЏЄъЄШЄЗЄПЗСЄђЩСЄЄЄЦЁЂЅоЅЙЅЏЄђЛиФъЄЗЄЦЁЂЅзЅэЅѓЅзЅШЄЫЄНЄЮЪЊТЮЄЮЬООЮЄђМЈЄЙУБИьЄђТЧЄСЙўЄѓЄЧЄпЄПЄтЄЮЄЮЁЂПЭДжЄЮМъТЄЌНаЄЦЄЄПЄъЁЂДиЗИЄЪЄЄЖтТАЅбЅЄЅзЄЌНаЄЦЄЄПЄъЄЧЁФЁЃ
ДћЄЫПЇЁЙЩСЄЋЄьЄЦЄЗЄоЄУЄЦЄЄЄыВшСќЄЮОхЄЫОЄДЄЗЄшЄІЄШЄЙЄыЄЋЄщИэЧЇМБЄЕЄьЄыЄЮЄЋЄЪЁЂЄЧЄЂЄьЄаУБТЮЄЧЪЊТЮЄђОЄДЄЙЄьЄаЄЩЄІЄЫЄЋЄЪЄщЄѓЄЋЁЃКюРяЄђЪбЄЈЄЦЁЂsketchЕЁЧНЄЮЄпЄђЛШЄУЄЦКЦЅСЅуЅьЅѓЅИЁЃСДЬЬЄђППЄУРФЄЫХЩЄъФйЄЗЄЦЄЋЄщЁЂЬмХЊЄЮЪЊТЮЄУЄнЄЄЄтЄЮЄђЩСЄЄЄЦНшЭ§ЄЕЄЛЄЦЄпЄПЄтЄЮЄЮЁЂЗСЄЌСДСГАуЄІЄЗЁЂИўЄЄтАуЄІЁЃЄГЄьЄтОхМъЄЏЙдЄЋЄЪЄЄЄЋЁФЁЃ
ЗыЖЩЁЂЬмХЊЄЮЪЊТЮЄЌЄНЄьЄщЄЗЄЄИўЄЄЧБЧЄУЄЦЄЄЄыВшСќЄђУЕЄЗЄЦЭјЭбЄЗЄЦЄпЄыЄГЄШЄЫЄЗЄПЁЃGoogleВшСќИЁКїЄЧCC0ЄЮВшСќЄђУЕЄЗЄЦЁЂВшСќЄђЅГЅдЁМЄЗЄЦЁЂGIMPЄЧЧиЗЪЄђОУЄЗЄЦЁЂВѓХОГШТчНЬОЎЄЗЄЦЁЂДћЄЫЄЂЄыВшСќЄЮЁЂЬмЩИАЬУжЄЫХНЄъЩеЄБЁЃЄГЄЮОѕТжЄЧ img2img ЄђЛШЄУЄПЄщЁЂЄЕЄЙЄЌЄЫВПЄЮЪЊТЮЄђЭзЕсЄЗЄЦЄЄЄыЄЮЄЋЪЌЄЋЄУЄЦЁФЄЏЄьЄЪЄЄЁЃЄоЄПМъТЄШЄЗЄЦЧЇМБЄЕЄьЄЦЄЗЄоЄІЁЃЅзЅэЅѓЅзЅШЄЧЁЂЁж((2 ЪЊТЮ))ЁзЄпЄПЄЄЄЪДЖЄИЄЧИњВЬЄђЖЏФДЄЗЄЦЁЂЄшЄІЄфЄЏЬмХЊЄЌВЬЄПЄЛЄПЁЃ
ЛШЄЄЄГЄЪЄЙЄЮЄЯЁЂЄЪЄЋЄЪЄЋЦёЄЗЄЄЄтЄЮЄРЄЪЄШЁФЁЃ
ДћЄЫПЇЁЙЩСЄЋЄьЄЦЄЗЄоЄУЄЦЄЄЄыВшСќЄЮОхЄЫОЄДЄЗЄшЄІЄШЄЙЄыЄЋЄщИэЧЇМБЄЕЄьЄыЄЮЄЋЄЪЁЂЄЧЄЂЄьЄаУБТЮЄЧЪЊТЮЄђОЄДЄЙЄьЄаЄЩЄІЄЫЄЋЄЪЄщЄѓЄЋЁЃКюРяЄђЪбЄЈЄЦЁЂsketchЕЁЧНЄЮЄпЄђЛШЄУЄЦКЦЅСЅуЅьЅѓЅИЁЃСДЬЬЄђППЄУРФЄЫХЩЄъФйЄЗЄЦЄЋЄщЁЂЬмХЊЄЮЪЊТЮЄУЄнЄЄЄтЄЮЄђЩСЄЄЄЦНшЭ§ЄЕЄЛЄЦЄпЄПЄтЄЮЄЮЁЂЗСЄЌСДСГАуЄІЄЗЁЂИўЄЄтАуЄІЁЃЄГЄьЄтОхМъЄЏЙдЄЋЄЪЄЄЄЋЁФЁЃ
ЗыЖЩЁЂЬмХЊЄЮЪЊТЮЄЌЄНЄьЄщЄЗЄЄИўЄЄЧБЧЄУЄЦЄЄЄыВшСќЄђУЕЄЗЄЦЭјЭбЄЗЄЦЄпЄыЄГЄШЄЫЄЗЄПЁЃGoogleВшСќИЁКїЄЧCC0ЄЮВшСќЄђУЕЄЗЄЦЁЂВшСќЄђЅГЅдЁМЄЗЄЦЁЂGIMPЄЧЧиЗЪЄђОУЄЗЄЦЁЂВѓХОГШТчНЬОЎЄЗЄЦЁЂДћЄЫЄЂЄыВшСќЄЮЁЂЬмЩИАЬУжЄЫХНЄъЩеЄБЁЃЄГЄЮОѕТжЄЧ img2img ЄђЛШЄУЄПЄщЁЂЄЕЄЙЄЌЄЫВПЄЮЪЊТЮЄђЭзЕсЄЗЄЦЄЄЄыЄЮЄЋЪЌЄЋЄУЄЦЁФЄЏЄьЄЪЄЄЁЃЄоЄПМъТЄШЄЗЄЦЧЇМБЄЕЄьЄЦЄЗЄоЄІЁЃЅзЅэЅѓЅзЅШЄЧЁЂЁж((2 ЪЊТЮ))ЁзЄпЄПЄЄЄЪДЖЄИЄЧИњВЬЄђЖЏФДЄЗЄЦЁЂЄшЄІЄфЄЏЬмХЊЄЌВЬЄПЄЛЄПЁЃ
ЛШЄЄЄГЄЪЄЙЄЮЄЯЁЂЄЪЄЋЄЪЄЋЦёЄЗЄЄЄтЄЮЄРЄЪЄШЁФЁЃ
[ ЅФЅУЅГЄр ]
#2 [nitijyou] ЩєВАЄЫВуЄЌЕяЄы
ЄеЄШЁЂТЄЮЛиРшЄЌЬЏЄЪДЖЄИЄРЄЪЄШИЋЄЦЄпЄПЄщЁЂВуЄЌЛпЄоЄУЄЦЄЄЄЦЁЂЅСЅхЁМЅУЄШЄфЄщЄьЄЦЄПЁЃЄЗЄЋЄтФйЄЗТЛЄЭЄПЁЃЦЈЄВЄщЄьЄПЁЃ
ЛХЪ§ЄЪЄЏВуМшЄъРўЙсЄђЄФЄБЄПЄБЄЩЁЂВуМшЄъРўЙсЄЯМЋЪЌЄтЅРЅсЁМЅИЄђМѕЄБЄыЄЮЄРЄшЄЪЁФЁЃВуЄШМЋЪЌЄЮТЮЮЯОЁЩщЁФЁЃ
ВуМшЄъРўЙсЄУЄЦЫмХіЄЫИњВЬЄЌЄЂЄыЄЮЄРЄэЄІЄЋЁЃМТЄЯКЃЛўЄЮВуЄЫЄЯИњЄЋЄЪЄЏЄЦЁЂМЋЪЌЄРЄБЄЌЅРЅсЁМЅИЄђМѕЄБЄЦЄыОѕТжЄРЄУЄПЄъЄЗЄЪЄЄЄЋЁФЁЃ
ЛХЪ§ЄЪЄЏВуМшЄъРўЙсЄђЄФЄБЄПЄБЄЩЁЂВуМшЄъРўЙсЄЯМЋЪЌЄтЅРЅсЁМЅИЄђМѕЄБЄыЄЮЄРЄшЄЪЁФЁЃВуЄШМЋЪЌЄЮТЮЮЯОЁЩщЁФЁЃ
ВуМшЄъРўЙсЄУЄЦЫмХіЄЫИњВЬЄЌЄЂЄыЄЮЄРЄэЄІЄЋЁЃМТЄЯКЃЛўЄЮВуЄЫЄЯИњЄЋЄЪЄЏЄЦЁЂМЋЪЌЄРЄБЄЌЅРЅсЁМЅИЄђМѕЄБЄЦЄыОѕТжЄРЄУЄПЄъЄЗЄЪЄЄЄЋЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/18(Ва) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] ВшСќЅгЅхЁМЅЂ XnView ЄЫЄФЄЄЄЦФДЄйЄЦЄП
XnView (Classic) ЄШЄЄЄІВшСќЅгЅхЁМЅяЄЯЁЂГЦВшСќЄЫТаЄЗЄЦЁЂ5УЪГЌЄЮУцЄЋЄщЅьЁМЅЦЅЃЅѓЅАЄђЄФЄБЄЦЁЂЅьЁМЅЦЅЃЅѓЅАНчЄЧЅЕЅрЅЭЅЄЅыАьЭїЄђЩНМЈЄЗЄПЄъЄЙЄыЄГЄШЄЌЄЧЄЄыЁЃ
_The Best Windows Photo Viewer, Image Resizer and Batch Converter - XnView
_ЁжXnViewЁзЅЈЅЏЅЙЅзЅэЁМЅщЁМЗПВшСќЅгЅхЁМЅяЁМ - СыЄЮХЮ
_XnView ЄЮЅРЅІЅѓЅэЁМЅЩ - ЃыЫмХЊЄЫЬЕЮСЅНЅеЅШЁІЅеЅъЁМЅНЅеЅШ
ЄПЄРЁЂЄГЄЮЅьЁМЅЦЅЃЅѓЅАО№ЪѓЄЯЁЂАьТЮЄЩЄГЄЫЕЯПЄЕЄьЄыЄЮЄЋЁЂЄНЄЮЄЂЄПЄъЄЌЕЄЄЫЄЪЄУЄПЁЃЄтЄЗЁЂВшСќЅеЅЁЅЄЅыЄЮУцЄЫЫфЄсЙўЄрЗСЄЧМТИНЄЗЄЦЄЄЄыЄЪЄщЁЂStable Diffusion web UI ЄЧРИРЎЄЗЄПpngВшСќЄЮУцПШЄђШљЬЏЄЫЧЫВѕЄЗЄЦЄЗЄоЄУЄЦЁЂИхЄЋЄщЅзЅэЅѓЅзЅШО№ЪѓЄђМшЄъНаЄЛЄЪЄЏЄЪЄыЄЋЄтЄЗЄьЄЪЄЄЄЪЄШЁФЁЃ
ЄНЄЮЄЂЄПЄъЄЮЛХСШЄпЄЫЄФЄЄЄЦЅАЅАЄУЄЦЄПЄщЁЂАЪВМЄЮЕЛіЄЫСјЖјЁЃ
_ЦќОяЄЮЅсЅт XnViewMPЄЮЅЧЁМЅПЅйЁМЅЙЄђЄЄЄИЄы
XnView ЄЧЄЯЄЪЄЏЄЦЁЂXnViewMP ЄЮЯУЄЧЄЯЄЂЄыЄБЄЩЁЂВшСќЄЧЄЯЄЪЄЏЁЂSQLiteЭбЄЮЅЧЁМЅПЅйЁМЅЙЅеЅЁЅЄЅыЄЫЕЯПЄЕЄьЄыЄшЄІЄРЄЪЄШЁФЁЃЄЧЄЂЄьЄаЁЂАТПДЄЗЄЦЛШЄЈЄНЄІЄЋЄЪЁФЁЃГЮЧЇЄЗЄЦЄЪЄЄЄБЄьЄЩЁЂЄЊЄНЄщЄЏ XnView (Classic) ЄтЦБЭЭЄЪЄЮЄЧЄЯЄЂЄыЄоЄЄЄЋЁЃЪЌЄщЄѓЄБЄЩЁЃ
_The Best Windows Photo Viewer, Image Resizer and Batch Converter - XnView
_ЁжXnViewЁзЅЈЅЏЅЙЅзЅэЁМЅщЁМЗПВшСќЅгЅхЁМЅяЁМ - СыЄЮХЮ
_XnView ЄЮЅРЅІЅѓЅэЁМЅЩ - ЃыЫмХЊЄЫЬЕЮСЅНЅеЅШЁІЅеЅъЁМЅНЅеЅШ
ЄПЄРЁЂЄГЄЮЅьЁМЅЦЅЃЅѓЅАО№ЪѓЄЯЁЂАьТЮЄЩЄГЄЫЕЯПЄЕЄьЄыЄЮЄЋЁЂЄНЄЮЄЂЄПЄъЄЌЕЄЄЫЄЪЄУЄПЁЃЄтЄЗЁЂВшСќЅеЅЁЅЄЅыЄЮУцЄЫЫфЄсЙўЄрЗСЄЧМТИНЄЗЄЦЄЄЄыЄЪЄщЁЂStable Diffusion web UI ЄЧРИРЎЄЗЄПpngВшСќЄЮУцПШЄђШљЬЏЄЫЧЫВѕЄЗЄЦЄЗЄоЄУЄЦЁЂИхЄЋЄщЅзЅэЅѓЅзЅШО№ЪѓЄђМшЄъНаЄЛЄЪЄЏЄЪЄыЄЋЄтЄЗЄьЄЪЄЄЄЪЄШЁФЁЃ
ЄНЄЮЄЂЄПЄъЄЮЛХСШЄпЄЫЄФЄЄЄЦЅАЅАЄУЄЦЄПЄщЁЂАЪВМЄЮЕЛіЄЫСјЖјЁЃ
_ЦќОяЄЮЅсЅт XnViewMPЄЮЅЧЁМЅПЅйЁМЅЙЄђЄЄЄИЄы
ЅЋЅЦЅДЅъЄфЅьЁМЅЦЅЃЅѓЅАЄЪЄЩЄЮЅЧЁМЅПЄЯ XnView.db ЄЫЕЯПЄЕЄьЄыЁЃ
SQLite ЄЧДЩЭ§ЄЕЄьЄЦЄЄЄыЄЮЄЧУцЄђФДЄйЄЦЄпЄПЁЃ
XnView ЄЧЄЯЄЪЄЏЄЦЁЂXnViewMP ЄЮЯУЄЧЄЯЄЂЄыЄБЄЩЁЂВшСќЄЧЄЯЄЪЄЏЁЂSQLiteЭбЄЮЅЧЁМЅПЅйЁМЅЙЅеЅЁЅЄЅыЄЫЕЯПЄЕЄьЄыЄшЄІЄРЄЪЄШЁФЁЃЄЧЄЂЄьЄаЁЂАТПДЄЗЄЦЛШЄЈЄНЄІЄЋЄЪЁФЁЃГЮЧЇЄЗЄЦЄЪЄЄЄБЄьЄЩЁЂЄЊЄНЄщЄЏ XnView (Classic) ЄтЦБЭЭЄЪЄЮЄЧЄЯЄЂЄыЄоЄЄЄЋЁЃЪЌЄщЄѓЄБЄЩЁЃ
Ё§ ЩНМЈВшМСЄЌЄшЄэЄЗЄЏЄЪЄЄ :
XnView (Classic) 2.51.2 ЄђЛШЄУЄЦЁЂ512x512 ЄЮВшСќЄђГШТчЄЗЄФЄФСДВшЬЬЩНМЈЄЙЄыЄШЁЂЩНМЈВшМСЄЌЙгЄьЄыЄШЄЄЄІЄЋЁЂЅмЅБЄыЄШЄЄЄІЄЋЁЂЄШЄЫЄЋЄЏИЋЄПЬмЄЌЄЂЄоЄъЄшЄэЄЗЄЏЄЪЄЄЄГЄШЄЫЕЄЄХЄЄЄПЁЃ
РпФъЄђФЏЄсЄЦЄпЄПЄБЄЩЁЂГШТчЩНМЈЄЙЄыКнЄЮЅЂЅыЅДЅъЅКЅрЄђСЊЄѓЄРЄъЄЯЄЧЄЄЪЄЄЄшЄІЄРЄЪЄШЁФЁЃ
АьБўЁЂРпФъЅРЅЄЅЂЅэЅА ЂЊ ЩНМЈ ЂЊ ЁжЩНМЈЁзЅПЅжЄЮУцЄЫЁЂЁжЙтВшМСЅКЁМЅр(ФуТЎ)ЁзЄШЄЄЄІЙрЬмЄЌЄЂЄУЄЦЁЂЁжНЬОЎЁзЁжГШТчЁзЁжЅЂЅЫЅсЁМЅЗЅчЅѓGIFЄЫХЌЭбЁзЄЮЄНЄьЄОЄьЄЫЅСЅЇЅУЅЏЄђЦўЄьЄщЄьЄыЄшЄІЄЧЄЯЄЂЄУЄПЁЃЄГЄЮЁжГШТчЁзЄЫЅСЅЇЅУЅЏЄђЦўЄьЄыЄШЁЂГШТчЩНМЈЄђЄЙЄыКнЄтТПОЏЄЯЅоЅЗЄЪИЋЄПЬмЄЫЄЪЄыЬЯЭЭЁЃЄПЄРЁЂЄНЄьЄЧЄтЅЄЅоЅЄЅСЁФЁЃ
ЛХЪ§ЄЪЄЄЄЮЄЧЁЂЦБЄИРпФъВшЬЬЄЮУцЄЮЁЂЁжЅЗЅуЁМЅзВНЄђЛШЭбЁзЄЫЅСЅЇЅУЅЏЄђЦўЄьЄЦЭИњВНЄЗЄЦЄпЄПЁЃУЭЄЯ35ЁЃ
ЄШЄГЄэЄЧЁЂXnView ЄЯГШТчНЬОЎЩНМЈЛўЄЮЅЂЅыЅДЅъЅКЅрЄђСЊЄйЄЪЄЄЄБЄьЄЩЁЂXnViewMP 1.4.3 ЄЪЄщПЇЁЙЄЪЅЂЅыЅДЅъЅКЅрЄђСЊЄйЄыЄшЄІЄЫИЋЄЈЄПЁЃРпФъЅРЅЄЅЂЅэЅА ЂЊ ЩНМЈ ЂЊ ЁжЩНМЈЁзЅПЅжЄЮУцЄЫЁЂЁжЙтЅКЁМЅрВшМСЁзЄШЄЄЄІЙрЬмЄЌЄЂЄУЄЦЁЂЁжSpline36ЁзЁжLanczos 3ЁзЁжLanczos 4ЁзХљЁЙЄЌСЊЄйЄыЁЃ
_LanczosЁЪЅщЅѓЅСЅчЅЙЫЁЁЫЁкЄФЄЄЄЧЄЫSpline36Ёл | Rain or Shine
_ЅъЅЕЅЄЅКРпФъ - Nilposoft
_AviUtlЛШЭбЅеЅЃЅыЅПОвВ№ЁЪЅъЅЕЅЄЅКЗЯЁЫ ЄСЄъЄШЄоЄШЅСЅуЅѓЅЭЅы
XnViewMP ЄЮЄлЄІЄЌЁЂИЋЄПДЖЄИЄЧЄЯЮЩЄЕЄНЄІЄЪЩНМЈЄђЄЗЄЦЄЏЄьЄыЄшЄІЄЪЕЄЄЌЄЙЄыЁФЁЃКЃЄоЄЧ XnView ЄђЄСЄчЄЏЄСЄчЄЏЛШЄУЄЦЄПЄБЄЩЁЂXnViewMP ЄиЄЮАмЙдЄђАеМБЄЗЄПЄлЄІЄЌЄЄЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃ
ЄоЄЂЁЂЮОЪ§ЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЊЄЄЄЦЁЂXnViewMP ЄЧЄЯЕЁЧНЄЌТЄъЄЪЄЄЄЪЄШЛзЄУЄПЛўЄРЄБЁЂXnView ЄђЛШЄЈЄаКбЄрЄЋЄЪЁФЁЃ
РпФъЄђФЏЄсЄЦЄпЄПЄБЄЩЁЂГШТчЩНМЈЄЙЄыКнЄЮЅЂЅыЅДЅъЅКЅрЄђСЊЄѓЄРЄъЄЯЄЧЄЄЪЄЄЄшЄІЄРЄЪЄШЁФЁЃ
АьБўЁЂРпФъЅРЅЄЅЂЅэЅА ЂЊ ЩНМЈ ЂЊ ЁжЩНМЈЁзЅПЅжЄЮУцЄЫЁЂЁжЙтВшМСЅКЁМЅр(ФуТЎ)ЁзЄШЄЄЄІЙрЬмЄЌЄЂЄУЄЦЁЂЁжНЬОЎЁзЁжГШТчЁзЁжЅЂЅЫЅсЁМЅЗЅчЅѓGIFЄЫХЌЭбЁзЄЮЄНЄьЄОЄьЄЫЅСЅЇЅУЅЏЄђЦўЄьЄщЄьЄыЄшЄІЄЧЄЯЄЂЄУЄПЁЃЄГЄЮЁжГШТчЁзЄЫЅСЅЇЅУЅЏЄђЦўЄьЄыЄШЁЂГШТчЩНМЈЄђЄЙЄыКнЄтТПОЏЄЯЅоЅЗЄЪИЋЄПЬмЄЫЄЪЄыЬЯЭЭЁЃЄПЄРЁЂЄНЄьЄЧЄтЅЄЅоЅЄЅСЁФЁЃ
ЛХЪ§ЄЪЄЄЄЮЄЧЁЂЦБЄИРпФъВшЬЬЄЮУцЄЮЁЂЁжЅЗЅуЁМЅзВНЄђЛШЭбЁзЄЫЅСЅЇЅУЅЏЄђЦўЄьЄЦЭИњВНЄЗЄЦЄпЄПЁЃУЭЄЯ35ЁЃ
ЄШЄГЄэЄЧЁЂXnView ЄЯГШТчНЬОЎЩНМЈЛўЄЮЅЂЅыЅДЅъЅКЅрЄђСЊЄйЄЪЄЄЄБЄьЄЩЁЂXnViewMP 1.4.3 ЄЪЄщПЇЁЙЄЪЅЂЅыЅДЅъЅКЅрЄђСЊЄйЄыЄшЄІЄЫИЋЄЈЄПЁЃРпФъЅРЅЄЅЂЅэЅА ЂЊ ЩНМЈ ЂЊ ЁжЩНМЈЁзЅПЅжЄЮУцЄЫЁЂЁжЙтЅКЁМЅрВшМСЁзЄШЄЄЄІЙрЬмЄЌЄЂЄУЄЦЁЂЁжSpline36ЁзЁжLanczos 3ЁзЁжLanczos 4ЁзХљЁЙЄЌСЊЄйЄыЁЃ
_LanczosЁЪЅщЅѓЅСЅчЅЙЫЁЁЫЁкЄФЄЄЄЧЄЫSpline36Ёл | Rain or Shine
_ЅъЅЕЅЄЅКРпФъ - Nilposoft
_AviUtlЛШЭбЅеЅЃЅыЅПОвВ№ЁЪЅъЅЕЅЄЅКЗЯЁЫ ЄСЄъЄШЄоЄШЅСЅуЅѓЅЭЅы
XnViewMP ЄЮЄлЄІЄЌЁЂИЋЄПДЖЄИЄЧЄЯЮЩЄЕЄНЄІЄЪЩНМЈЄђЄЗЄЦЄЏЄьЄыЄшЄІЄЪЕЄЄЌЄЙЄыЁФЁЃКЃЄоЄЧ XnView ЄђЄСЄчЄЏЄСЄчЄЏЛШЄУЄЦЄПЄБЄЩЁЂXnViewMP ЄиЄЮАмЙдЄђАеМБЄЗЄПЄлЄІЄЌЄЄЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃ
ЄоЄЂЁЂЮОЪ§ЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЊЄЄЄЦЁЂXnViewMP ЄЧЄЯЕЁЧНЄЌТЄъЄЪЄЄЄЪЄШЛзЄУЄПЛўЄРЄБЁЂXnView ЄђЛШЄЈЄаКбЄрЄЋЄЪЁФЁЃ
[ ЅФЅУЅГЄр ]
#2 [prog] PandocЄЫХЯЄЙgithubЩїcssЄЫЄФЄЄЄЦ
PandocЄШЄЄЄІЅФЁМЅыЄђЛШЄІЄШЁЂMarkdownЅеЅЁЅЄЅыЄђhtmlЄЫЪбДЙЄЧЄЄыЁЃЄНЄЮКнЁЂgithubЩїЄЮИЋЄПЬмЄЫЄЪЄыcssЄђЛиФъЄЙЄыЄГЄШЄЧЁЂНаЮЯЄЕЄьЄыhtmlЄђgithubЩїЄЫЄЙЄыЄГЄШЄЌЄЧЄЄыЄЮЄРЄБЄЩЁЃ
РЮЄЮВђРтЕЛіЄЧОвВ№ЄЕЄьЄЦЄЄЄПЗяЄЮcssЄЯЁЂАьЩєЄЧВшСќЄђЛШЄУЄЦЄЄЄЦЁЂЄЗЄЋЄЗЁЂЄНЄЮВшСќЄЮЦўМъРшURLЄЌКЃЄЧЄЯАуЄУЄЦЄЗЄоЄУЄПЄшЄІЄЧЁЂВшСќЄђЦўМъЄЧЄЄЪЄЏЄЦЄСЄчЄУЄШКЄЄУЄЦЄЗЄоЄУЄПЁЃ
ФќЄсЄЄьЄКЄЫЅАЅАЄУЄЦЄПЄщЁЂgithubОхЄЫУжЄЄЄЦЄЏЄьЄЦЄЄЄПЪ§ЄЌЕяЄПЄшЄІЄЧЁЃЄЂЄъЄЌЄПЄфЁЃНѕЄЋЄУЄПЁЃЄШЄЄЄІЄГЄШЄЧЅсЅтЁЃ
_pandoc-md2github1html/css at master - tukiyo/pandoc-md2github1html - GitHub
ОхЕЄЮЅкЁМЅИЄЋЄщЁЂАЪВМЄЮ3ЄФЄЮЅеЅЁЅЄЅыЄђЦўМъЄЧЄЄыЁЃ
ЄСЄЪЄпЄЫЁЂPandoc ЄђЛШЄУЄПЁЂgfm (githubОхЄЧЕЌФъЄЕЄьЄЦЄыMarkdownЩїЕЫЁ)ЄЋЄщhtml5ЄиЄЮЪбДЙЄЯАЪВМЁЃ
РЮЄЮВђРтЕЛіЄЧОвВ№ЄЕЄьЄЦЄЄЄПЗяЄЮcssЄЯЁЂАьЩєЄЧВшСќЄђЛШЄУЄЦЄЄЄЦЁЂЄЗЄЋЄЗЁЂЄНЄЮВшСќЄЮЦўМъРшURLЄЌКЃЄЧЄЯАуЄУЄЦЄЗЄоЄУЄПЄшЄІЄЧЁЂВшСќЄђЦўМъЄЧЄЄЪЄЏЄЦЄСЄчЄУЄШКЄЄУЄЦЄЗЄоЄУЄПЁЃ
ФќЄсЄЄьЄКЄЫЅАЅАЄУЄЦЄПЄщЁЂgithubОхЄЫУжЄЄЄЦЄЏЄьЄЦЄЄЄПЪ§ЄЌЕяЄПЄшЄІЄЧЁЃЄЂЄъЄЌЄПЄфЁЃНѕЄЋЄУЄПЁЃЄШЄЄЄІЄГЄШЄЧЅсЅтЁЃ
_pandoc-md2github1html/css at master - tukiyo/pandoc-md2github1html - GitHub
ОхЕЄЮЅкЁМЅИЄЋЄщЁЂАЪВМЄЮ3ЄФЄЮЅеЅЁЅЄЅыЄђЦўМъЄЧЄЄыЁЃ
- dirty-shade.png
- github.css
- para.png
ЄСЄЪЄпЄЫЁЂPandoc ЄђЛШЄУЄПЁЂgfm (githubОхЄЧЕЌФъЄЕЄьЄЦЄыMarkdownЩїЕЫЁ)ЄЋЄщhtml5ЄиЄЮЪбДЙЄЯАЪВМЁЃ
pandoc hoge.md -f gfm -t html5 -s --self-contained -c github.css -o hoge.html
- hoge.md : ЦўЮЯЅеЅЁЅЄЅыЬОЁЃ
- -f gfm : ЦўЮЯЅеЅЁЅЄЅыЄЌgfmЗСМАЄЧЄЂЄыЄШЛиФъЁЃ
- -t html5 : НаЮЯЅеЅЁЅЄЅыЄЌhtml5ЄЧЄЂЄыЄШЛиФъЁЃ
- -s : StandaloneЄЮsЁЃhtmlЪИНёЄШЄЗЄЦДАЗыЄЗЄЦЄыОѕТжЄЧНаЮЯЁЃЄГЄьЄђЄФЄБЄЪЄЄЄШЁЂhtmlЅПЅАЄфbodyЅПЅАЄЌЬЕЄЄОѕТжЄЧНаЮЯЄЕЄьЄЦЄЗЄоЄІЁЃ
- --self-contained : css ЄфВшСќЅеЅЁЅЄЅыЄђЦтЪёЄЗЄПhtmlЅеЅЁЅЄЅыЄШЄЗЄЦНаЮЯЁЃ
- -c github.css : cssЄђЛиФъЁЃЄГЄЮОьЙчЁЂgithub.css ЄђЛШЄЈЄШЛиФъЄЗЄЦЄЄЄыЁЃ
- -o hoge.html : НаЮЯЅеЅЁЅЄЅыЬОЄЮЛиФъЁЃ
Ё§ cssЦтЄЫВшСќЄђДоЄсЄПЄЄ :
ЅГЅьЄУЄЦЁЂВшСќЄЌЪЬЅеЅЁЅЄЅыЄШЄЗЄЦЩЌЭзЄЫЄЪЄУЄЦЄЄЄыЄБЄьЄЩЁЂcssЦтЄЫВшСќЄђДоЄсЄЦЄЊЄЏЄГЄШЄЯЄЧЄЄЪЄЄЄЮЄРЄэЄІЄЋЁЃ
ЅАЅАЄУЄЦЄпЄПЄщЁЂData URI scheme ЄШЄЄЄІЕЛЄЌЄЂЄыЄщЄЗЄЄЁЃВшСќЄђbase64ЄЫЪбДЙЄЗЄЦЁЂ"data:image/png;base64,..." ЄШЕНвЄЙЄыЄГЄШЄЧЦтЪёЄЧЄЄыЄЮЄРЄШЄЋЁЃ
_ЩНМЈТЎХйВўСБЁЁData URIЅЙЅЁМЅр | САЪд ЛХСШЄпЄШЅсЅъЅУЅШ
_Data URLЅЙЅЁМЅрЄШЄЯВПЄЪЄЮЄЋЁЉЪиЭјЄЪЭ§ЭГЄШАЗЄІЄШЄЄЮУэАеХР | PisukeCode - WebГЋШЏЄоЄШЄс
_CSSЄЮbackgroundЄЫВшСќЄђФОРмЫфЄсЙўЄрЪ§ЫЁ | HTMLЁІCSSЁІJavaScriptЄЮЅЦЅЏЅЫЅУЅЏНИ | WebЅЕЅЄЅШРЉКюЛйБч | ShanaBrian Website
_Data URI scheme - Wikipedia
ВшСќЄђbase64ЄЫЪбДЙЄЙЄыКюЖШЄЯЁЂАЪВМЄЮЅкЁМЅИЄђЛШЄяЄЛЄЦЄтЄщЄУЄПЁЃЄЂЄъЄЌЄПЄфЁЃ
_ВшСќЄђData URI schemeЄЧЅЦЅЅЙЅШЄЫЪбДЙЄЙЄыЅФЁМЅы - PEKO STEP
ЄФЄоЄъЁЂСАНвЄЮ github.css ЄЮУцЄЧЁЂАЪВМЄЮЄшЄІЄЫЕНвЄЙЄьЄаВшСќЅеЅЁЅЄЅыЄђЪЬХгЭбАеЄЗЄЪЄЏЄЦКбЄрЁЂЄШЄЄЄІЄГЄШЄЫЄЪЄыЄЮЄРЄэЄІЄЋЁЃ
ЛюЄЗЄЦЄпЄПЄШЄГЄэЁЂhrЅПЅАЄЮИЋЄПЬмЄЯЄПЄЗЄЋЄЫЪбЄяЄУЄПЄБЄьЄЩЁФЁЃh1 Єф h2 ЅПЅАЄЮМўЪеЄЯЁЂЄЩЄІЕНвЄЙЄьЄаЄЄЄЄЄЮЄЋЁФЁЃ
ЅАЅАЄУЄЦЄпЄПЄщЁЂData URI scheme ЄШЄЄЄІЕЛЄЌЄЂЄыЄщЄЗЄЄЁЃВшСќЄђbase64ЄЫЪбДЙЄЗЄЦЁЂ"data:image/png;base64,..." ЄШЕНвЄЙЄыЄГЄШЄЧЦтЪёЄЧЄЄыЄЮЄРЄШЄЋЁЃ
_ЩНМЈТЎХйВўСБЁЁData URIЅЙЅЁМЅр | САЪд ЛХСШЄпЄШЅсЅъЅУЅШ
_Data URLЅЙЅЁМЅрЄШЄЯВПЄЪЄЮЄЋЁЉЪиЭјЄЪЭ§ЭГЄШАЗЄІЄШЄЄЮУэАеХР | PisukeCode - WebГЋШЏЄоЄШЄс
_CSSЄЮbackgroundЄЫВшСќЄђФОРмЫфЄсЙўЄрЪ§ЫЁ | HTMLЁІCSSЁІJavaScriptЄЮЅЦЅЏЅЫЅУЅЏНИ | WebЅЕЅЄЅШРЉКюЛйБч | ShanaBrian Website
_Data URI scheme - Wikipedia
ВшСќЄђbase64ЄЫЪбДЙЄЙЄыКюЖШЄЯЁЂАЪВМЄЮЅкЁМЅИЄђЛШЄяЄЛЄЦЄтЄщЄУЄПЁЃЄЂЄъЄЌЄПЄфЁЃ
_ВшСќЄђData URI schemeЄЧЅЦЅЅЙЅШЄЫЪбДЙЄЙЄыЅФЁМЅы - PEKO STEP
ЄФЄоЄъЁЂСАНвЄЮ github.css ЄЮУцЄЧЁЂАЪВМЄЮЄшЄІЄЫЕНвЄЙЄьЄаВшСќЅеЅЁЅЄЅыЄђЪЬХгЭбАеЄЗЄЪЄЏЄЦКбЄрЁЂЄШЄЄЄІЄГЄШЄЫЄЪЄыЄЮЄРЄэЄІЄЋЁЃ
h1:hover a.anchor,
h2:hover a.anchor,
h3:hover a.anchor,
h4:hover a.anchor,
h5:hover a.anchor,
h6:hover a.anchor {
/* background: url("para.png") no-repeat 10px center; */
background: url("data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAZ0lEQVQ4T2NkoBAwUqifAZsBgkBDZwJxKBbDK4Bincji2AzYDVTggqQIpAYkdg+I09ENRTdACajgLpoi+hoAspwiL4AMAHljFRAbQ71CkheQvZ8GjY1RAxjAqZXohETVQCQqn1GcGwEpnyMREv2DmQAAAABJRU5ErkJggg==") no-repeat 10px center;
text-decoration: none;
}
hr {
/* background: transparent url("dirty-shade.png") repeat-x 0 0; */
background: transparent url("data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAYAAAAECAYAAACtBE5DAAAAIklEQVQIW2NkQAXGMC4jkjhcECh2FiaBIghSDJLAEARJAABzRgM4pXO10AAAAABJRU5ErkJggg==") repeat-x 0 0;
border: 0 none;
color: #cccccc;
height: 4px;
padding: 0;
}
ЛюЄЗЄЦЄпЄПЄШЄГЄэЁЂhrЅПЅАЄЮИЋЄПЬмЄЯЄПЄЗЄЋЄЫЪбЄяЄУЄПЄБЄьЄЩЁФЁЃh1 Єф h2 ЅПЅАЄЮМўЪеЄЯЁЂЄЩЄІЕНвЄЙЄьЄаЄЄЄЄЄЮЄЋЁФЁЃ
[ ЅФЅУЅГЄр ]
#3 [cg_tools] ВшСќГШТчЅФЁМЅыЄђЛюЭб
Stable Diffusion web UIЄЧВшСќЄђРИРЎЄЙЄыКнЁЂ512x512ЄЧНаЮЯЄЗЄЦЄЄЄыЄЮЄРЄБЄЩЁЂЄСЄчЄУЄШВшСќЅЕЅЄЅКЄЌОЎЄЕЄЄЕЄЄЌЄЗЄЦЄЄПЁЃStable Diffusion web UIЄЯ512x512ЄЫКЧХЌВНЄЗЄЦКюЄщЄьЄЦЄЄЄыЄШЄЄЄІЯУЄђЄЩЄГЄЋЄЧИЋЄЋЄБЄПЄЮЄЧЁЂЄНЄІЄЄЄІЄГЄШЄЪЄщЙчЄяЄЛЄЦЄЊЄЄЄПЄлЄІЄЌЄЄЄЄЄЋЄЪЄШЁЂЄНЄЮЅЕЅЄЅКЄЫЄЗЄЦЄЄЄыЄЮЄРЄБЄЩЁФЁЃ
ЄНЄѓЄЪЄяЄБЄЧЁЂВшСќГШТчЅФЁМЅыЄђЛюЄЗЄЫЛШЄУЄЦЄпЄшЄІЄЋЄЪЄШЁЃ
Stable Diffusion web UI ЄЫЄтВшСќГШТчЅФЁМЅыЄЯЦўЄУЄЦЄыЁЃExtrasЅПЅжЄђСЊТђЄЙЄьЄаЁЂПЇЁЙЄЪЅЂЅыЅДЅъЅКЅрЄђСЊЄѓЄЧВшСќГШТчЄЌЄЧЄЄыЄЗЁЂtxt2img ЄђЛШЄІОьЙчЄт Hires.fix ЄШЄЄЄІЕЁЧНЄЌЛШЄЈЄыЁЃ
ЄПЄРЁЂЄНЄьЄШЄЯЪЬЄЫЁЂВшСќГШТчНшЭ§ЄђРьЬчЄЫЄЗЄЦЄЄЄыЅФЁМЅыЄЮЄлЄІЄЌИЕВшСќЄЫЖсЄЄЗыВЬЄђЦРЄщЄьЄыЄЋЄтЄЗЄьЄЪЄЄЄШЛзЄЈЄЦЄЄПЄЮЄЧЁЂЄНЄЮЄЂЄПЄъЄтЛШЄУЄЦЄпЄыЄГЄШЄЫЄЗЄПЁЃ
ДФЖЄЯЁЂAMD Ryzen 5 5600X + GeForce GTX 1060 6GBЁЃRAM 16GBЁЃWindows10 x64 22H2ЁЃ
ЄНЄѓЄЪЄяЄБЄЧЁЂВшСќГШТчЅФЁМЅыЄђЛюЄЗЄЫЛШЄУЄЦЄпЄшЄІЄЋЄЪЄШЁЃ
Stable Diffusion web UI ЄЫЄтВшСќГШТчЅФЁМЅыЄЯЦўЄУЄЦЄыЁЃExtrasЅПЅжЄђСЊТђЄЙЄьЄаЁЂПЇЁЙЄЪЅЂЅыЅДЅъЅКЅрЄђСЊЄѓЄЧВшСќГШТчЄЌЄЧЄЄыЄЗЁЂtxt2img ЄђЛШЄІОьЙчЄт Hires.fix ЄШЄЄЄІЕЁЧНЄЌЛШЄЈЄыЁЃ
ЄПЄРЁЂЄНЄьЄШЄЯЪЬЄЫЁЂВшСќГШТчНшЭ§ЄђРьЬчЄЫЄЗЄЦЄЄЄыЅФЁМЅыЄЮЄлЄІЄЌИЕВшСќЄЫЖсЄЄЗыВЬЄђЦРЄщЄьЄыЄЋЄтЄЗЄьЄЪЄЄЄШЛзЄЈЄЦЄЄПЄЮЄЧЁЂЄНЄЮЄЂЄПЄъЄтЛШЄУЄЦЄпЄыЄГЄШЄЫЄЗЄПЁЃ
ДФЖЄЯЁЂAMD Ryzen 5 5600X + GeForce GTX 1060 6GBЁЃRAM 16GBЁЃWindows10 x64 22H2ЁЃ
Ё§ NiceScalerЄђЛюЭб :
NiceScaler ЄШЄЄЄІЅФЁМЅыЄЌЄЂЄыЄщЄЗЄЄЁЃAIЄЧГиНЌЄЗЄПЗыВЬЄЫД№ЄХЄЄЄЦГШТчНшЭ§ЄђЄЗЄЦЄЏЄьЄыЬЯЭЭЁЃ
_GitHub - Djdefrag/NiceScaler: NiceScaler - image/video deeplearning upscaler (OpenCV)
_NiceScaler ЄЮЅРЅІЅѓЅэЁМЅЩЄШЛШЄЄЪ§ - ЃыЫмХЊЄЫЬЕЮСЅНЅеЅШЁІЅеЅъЁМЅНЅеЅШ
_AIЄЧМЬППЄђАьШжЄЄьЄЄЄЫГШТчЄЙЄыЄЮЄЯЄЩЄьЁЉЁжNiceScalerЁзЁжReal-ESRGANЁзЁжUpscaylЁз - ЅбЅНЅГЅѓФЛЄЮЅжЅэЅА
_ВшСќЄфЦАВшЄђAIЄЌЙтВшМСЄЫЄЗЄЦЄЏЄьЄыЅНЅеЅШ ЁиNiceScalerЁй | PCЄЂЄьЄГЄьУЕКї
_ВшМСЄђЭюЄШЄЕЄКЄЫЁЂГШТчЁЊAIВшСќВУЙЉЅНЅеЅШЁжNiceScalerЁз |
2ЧмЄЫГШТчЄЗЄПЗыВЬЄЯЁЂЄЋЄЪЄъЅЄЅЄДЖЄИЄЫИЋЄЈЄПЁЃМЬППВшСќЄЮГШТчЄЫЄЯИўЄЄЄЦЄЄЄыЄШЄЄЄІЯУЄђИЋЄЋЄБЄПЄБЄьЄЩЁЂЄПЄЗЄЋЄЫЅшЅЕЅВЁЃЄСЄЪЄпЄЫЁЂ512x512 ЄђЁЂ2ЧмЄЮ 1024x1024 ЄЫЄЗЄПОьЙчЁЂАЪВМЄЮНшЭ§ЛўДжЄЫЄЪЄУЄПЁЃ
ЅЂЅыЅДЅъЅКЅрЄЯПЇЁЙСЊЄйЄыЄБЄьЄЩЁЂГЦЅЂЅыЅДЅъЅКЅрЄЌЄЩЄІЄЄЄІЄтЄЮЄЪЄЮЄЋЄЯЁЂАЪВМЄЮЅкЁМЅИЄЌЛВЙЭЄЫЄЪЄУЄПЁЃ
_ЁкIntern CV ReportЁлФЖВђСќЄЮЮђЛЫУЕЫЌ -2016ЧЏЪд- - Sansan Tech Blog
_ЅГЅѓЅдЅхЁМЅПЅгЅИЅчЅѓЄЮКЧПЗЯРЪИФДКК Single Image Super-Resolution САЪд | BLOG - DeNA Engineering
ОхЕЄЮЕЛіЄЫЄшЄыЄШЁФЁЃ
_GitHub - Djdefrag/NiceScaler: NiceScaler - image/video deeplearning upscaler (OpenCV)
_NiceScaler ЄЮЅРЅІЅѓЅэЁМЅЩЄШЛШЄЄЪ§ - ЃыЫмХЊЄЫЬЕЮСЅНЅеЅШЁІЅеЅъЁМЅНЅеЅШ
_AIЄЧМЬППЄђАьШжЄЄьЄЄЄЫГШТчЄЙЄыЄЮЄЯЄЩЄьЁЉЁжNiceScalerЁзЁжReal-ESRGANЁзЁжUpscaylЁз - ЅбЅНЅГЅѓФЛЄЮЅжЅэЅА
_ВшСќЄфЦАВшЄђAIЄЌЙтВшМСЄЫЄЗЄЦЄЏЄьЄыЅНЅеЅШ ЁиNiceScalerЁй | PCЄЂЄьЄГЄьУЕКї
_ВшМСЄђЭюЄШЄЕЄКЄЫЁЂГШТчЁЊAIВшСќВУЙЉЅНЅеЅШЁжNiceScalerЁз |
2ЧмЄЫГШТчЄЗЄПЗыВЬЄЯЁЂЄЋЄЪЄъЅЄЅЄДЖЄИЄЫИЋЄЈЄПЁЃМЬППВшСќЄЮГШТчЄЫЄЯИўЄЄЄЦЄЄЄыЄШЄЄЄІЯУЄђИЋЄЋЄБЄПЄБЄьЄЩЁЂЄПЄЗЄЋЄЫЅшЅЕЅВЁЃЄСЄЪЄпЄЫЁЂ512x512 ЄђЁЂ2ЧмЄЮ 1024x1024 ЄЫЄЗЄПОьЙчЁЂАЪВМЄЮНшЭ§ЛўДжЄЫЄЪЄУЄПЁЃ
- ESPCN ЄШ FSRCNN ЄЯ2ЩУЄлЄЩЄЧНшЭ§ЄЌНЊЄяЄУЄПЁЃ
- LapSRN ЄЯ3ЩУЁЃ
- EDSRЄЯЄсЄУЄСЄуЛўДжЄЌЄЋЄЋЄУЄЦЁЂ127ЩУЁЃ
ЅЂЅыЅДЅъЅКЅрЄЯПЇЁЙСЊЄйЄыЄБЄьЄЩЁЂГЦЅЂЅыЅДЅъЅКЅрЄЌЄЩЄІЄЄЄІЄтЄЮЄЪЄЮЄЋЄЯЁЂАЪВМЄЮЅкЁМЅИЄЌЛВЙЭЄЫЄЪЄУЄПЁЃ
_ЁкIntern CV ReportЁлФЖВђСќЄЮЮђЛЫУЕЫЌ -2016ЧЏЪд- - Sansan Tech Blog
_ЅГЅѓЅдЅхЁМЅПЅгЅИЅчЅѓЄЮКЧПЗЯРЪИФДКК Single Image Super-Resolution САЪд | BLOG - DeNA Engineering
ОхЕЄЮЕЛіЄЫЄшЄыЄШЁФЁЃ
- ESPCN ЄШ FSRCNN ЄЯЁЂSRCNN ЄШЄЄЄІЅЂЅыЅДЅъЅКЅрЄђЄНЄьЄОЄьЪЬЄЮЄфЄъЪ§ЄЧЙтТЎВНЄЗЄПЅЂЅыЅДЅъЅКЅрЁЃ
- EDSR ЄЯЁЂESPCN Єф FSRCNN ЄЧЦРЄщЄьЄПУЮИЋЄЋЄщ SRResNet ЄЌКюЄщЄьЄЦЁЂЄНЄЮ SRResNet ЄшЄъЄтЙтРККйЄЕЄђФЩЕсЄЗЄПЅЂЅыЅДЅъЅКЅрЁЃ
Ё§ UpscaylЄђЛюЭб :
Upscayl ЄШЄЄЄІЅФЁМЅыЄтЄЂЄыЄщЄЗЄЄЁЃЄГЄьЄтЁЂAIЄЧГиНЌЄЗЄПЗыВЬЄЫД№ЄХЄЄЄЦГШТчНшЭ§ЄђЄЗЄЦЄЏЄьЄыЁЃ
_GitHub - upscayl/upscayl: Upscayl - Free and Open Source AI Image Upscaler for Linux, MacOS and Windows built with Linux-First philosophy.
_Upscayl ЄЮЅРЅІЅѓЅэЁМЅЩЄШЛШЄЄЪ§ - ЃыЫмХЊЄЫЬЕЮСЅНЅеЅШЁІЅеЅъЁМЅНЅеЅШ
_ЬЕЮСЄЧДЪУБЄЫAIЄЧФуВшМСЄЪВшСќЄђЙтВшМСЄЫ4ЧмЅЂЅУЅзЅГЅѓЅаЁМЅШЄЧЄЄыЁжUpscaylЁзЄђЛШЄУЄЦЄпЄП - GIGAZINE
_AIЄЧЅЧЅЃЅЦЁМЅыЄђЪнЄУЄПЄоЄоВшСќЄђГШТчЄЙЄыЬЕНўЅФЁМЅыЁжUpscaylЁзЄЌv2.0.0ЄЫ - СыЄЮХЮ
_AIЁФЄШЄъЄЂЄЈЄКЙтВшМСВНЅФЁМЅыЄђЦўЄьЄЦЄпЄПЁЂЄШЄЄЄІЯУ - FURYU Tech Blog - ЅеЅъЅхЁМГєМАВёМв
ЄГЄСЄщЄЯЁЂ4ЧмЄЫГШТчЄЙЄыЄГЄШЄЗЄЋЄЧЄЄЪЄЄЄщЄЗЄЄЁЃЛюЄЗЄЦЄпЄПЄШЄГЄэЁЂЄГЄСЄщЄтПєЩУЄЧЗыВЬЄђРИРЎЄЗЄЦЄЏЄьЄПЁЃ
Real-ESRGAN ЄЯЅЂЅЫЅсЄУЄнЄЏЄЮЄУЄкЄъЄЗЄПЗыВЬЄЫЄЪЄУЄПЁЃПЭЪЊЄЮШЉЄЪЄЩЄЯЄФЄыЄѓЄШЄЗЄЦЄЄЄЦЁЂДёЮяЄЪИЋЄПЬмЄЧЄЯЄЂЄыЄЮЄРЄБЄЩЁФЁЃRemacri ЄЯЅЗЅуЁМЅзЄЕЄЌС§ЄЗЄПЄБЄьЄЩЁЂВшСќЄЮЬРЄыЄЕЁЉ ПЇЁЉ ЄЌТчЄЄЏЪбВНЄЗЄПЁЃ
_GitHub - upscayl/upscayl: Upscayl - Free and Open Source AI Image Upscaler for Linux, MacOS and Windows built with Linux-First philosophy.
_Upscayl ЄЮЅРЅІЅѓЅэЁМЅЩЄШЛШЄЄЪ§ - ЃыЫмХЊЄЫЬЕЮСЅНЅеЅШЁІЅеЅъЁМЅНЅеЅШ
_ЬЕЮСЄЧДЪУБЄЫAIЄЧФуВшМСЄЪВшСќЄђЙтВшМСЄЫ4ЧмЅЂЅУЅзЅГЅѓЅаЁМЅШЄЧЄЄыЁжUpscaylЁзЄђЛШЄУЄЦЄпЄП - GIGAZINE
_AIЄЧЅЧЅЃЅЦЁМЅыЄђЪнЄУЄПЄоЄоВшСќЄђГШТчЄЙЄыЬЕНўЅФЁМЅыЁжUpscaylЁзЄЌv2.0.0ЄЫ - СыЄЮХЮ
_AIЁФЄШЄъЄЂЄЈЄКЙтВшМСВНЅФЁМЅыЄђЦўЄьЄЦЄпЄПЁЂЄШЄЄЄІЯУ - FURYU Tech Blog - ЅеЅъЅхЁМГєМАВёМв
ЄГЄСЄщЄЯЁЂ4ЧмЄЫГШТчЄЙЄыЄГЄШЄЗЄЋЄЧЄЄЪЄЄЄщЄЗЄЄЁЃЛюЄЗЄЦЄпЄПЄШЄГЄэЁЂЄГЄСЄщЄтПєЩУЄЧЗыВЬЄђРИРЎЄЗЄЦЄЏЄьЄПЁЃ
Real-ESRGAN ЄЯЅЂЅЫЅсЄУЄнЄЏЄЮЄУЄкЄъЄЗЄПЗыВЬЄЫЄЪЄУЄПЁЃПЭЪЊЄЮШЉЄЪЄЩЄЯЄФЄыЄѓЄШЄЗЄЦЄЄЄЦЁЂДёЮяЄЪИЋЄПЬмЄЧЄЯЄЂЄыЄЮЄРЄБЄЩЁФЁЃRemacri ЄЯЅЗЅуЁМЅзЄЕЄЌС§ЄЗЄПЄБЄьЄЩЁЂВшСќЄЮЬРЄыЄЕЁЉ ПЇЁЉ ЄЌТчЄЄЏЪбВНЄЗЄПЁЃ
Ё§ Stable Diffusion web UIЄЮExtrasЄђЛюЭб :
Stable Diffusion web UIЄЮExtrasЄЧЄтГШТчНшЭ§ЄЌЄЧЄЄыЄЮЄЧЛюЭбЄЗЄЦЄпЄПЁЃ
Upscaler 1 ЄШ Upscaler 2 ЄЮ2ЄФЄђНХЄЭГнЄБЄЙЄыЄГЄШЄЌЄЧЄЄыЄщЄЗЄЄЁЃЅбЅщЅсЁМЅПЄЯАЪВМЁЃ
ЅЂЅыЅДЅъЅКЅрЄЯАЪВМЄЌСЊЄйЄыЁЃ
ЄШЄъЄЂЄЈЄК SwinIR_4x ЄђЛШЄУЄЦЄпЄПЁЃЅбЅщЅсЁМЅПЄЯСДЩє0ЁЃ2ЧмГШТчЄЧЄтРККйЄЕЄЯ NiceScaler ЄЮНшЭ§ЗыВЬЄшЄъЙтЄЄЄшЄІЄЫДЖЄИЄПЁЃЄПЄРЁЂШЉЄЯЅЂЅЫЅсЄУЄнЄЏЄЮЄУЄкЄъЄЗЄЦЄЗЄоЄІЁФЁЃЄЄЄфЄоЄЂЁЂШўШЉБОЁЙЄђЕсЄсЄЦЄыЄЪЄщЄГЄьЄЧЄЄЄЄЄЮЄРЄэЄІЄБЄЩЁФЁЃ
ЅЂЅыЅДЅъЅКЅрЄЫЄшЄыЗыВЬЄЮАуЄЄЄЯЁЂАЪВМЄЌЛВЙЭЄЫЄЪЄъЄНЄІЁЃ
_Stable DiffusionЄЮUpscalerЄЮГЦЅсЅНЅУЅЩШцГгЁУNobuЁУnote
Upscaler 1 ЄШ Upscaler 2 ЄЮ2ЄФЄђНХЄЭГнЄБЄЙЄыЄГЄШЄЌЄЧЄЄыЄщЄЗЄЄЁЃЅбЅщЅсЁМЅПЄЯАЪВМЁЃ
- Upscaler 2 visibility
- GFPGAN visibility
- CodeFormer visibility
- CodeFormer weight : 0ЄЪЄщКЧТчИњВЬЁЂ1ЄЪЄщКЧОЎИњВЬЁЃ
ЅЂЅыЅДЅъЅКЅрЄЯАЪВМЄЌСЊЄйЄыЁЃ
- Lanczos
- Nearest
- ESRFAN_4x
- LDSR
- R-ESRGAN 4x+
- R-ESRGAN 4x+Anime6B
- ScuNET GAN
- ScuNET PSNR
- SwinIR_4x
ЄШЄъЄЂЄЈЄК SwinIR_4x ЄђЛШЄУЄЦЄпЄПЁЃЅбЅщЅсЁМЅПЄЯСДЩє0ЁЃ2ЧмГШТчЄЧЄтРККйЄЕЄЯ NiceScaler ЄЮНшЭ§ЗыВЬЄшЄъЙтЄЄЄшЄІЄЫДЖЄИЄПЁЃЄПЄРЁЂШЉЄЯЅЂЅЫЅсЄУЄнЄЏЄЮЄУЄкЄъЄЗЄЦЄЗЄоЄІЁФЁЃЄЄЄфЄоЄЂЁЂШўШЉБОЁЙЄђЕсЄсЄЦЄыЄЪЄщЄГЄьЄЧЄЄЄЄЄЮЄРЄэЄІЄБЄЩЁФЁЃ
ЅЂЅыЅДЅъЅКЅрЄЫЄшЄыЗыВЬЄЮАуЄЄЄЯЁЂАЪВМЄЌЛВЙЭЄЫЄЪЄъЄНЄІЁЃ
_Stable DiffusionЄЮUpscalerЄЮГЦЅсЅНЅУЅЩШцГгЁУNobuЁУnote
Ё§ ДЖСл :
РККйЄЪВшСќЄЌЭпЄЗЄЄЄЪЄщЁЂStable Diffusion web UI ЄЮ SwinIR ЄђЛШЄУЄПЄлЄІЄЌЄЄЄЄЄЋЄЪЁФЁЃЄПЄРЁЂИЕВшСќЄЫЖсЄЄЄЮЄЯЁЂNiceScaler ЄЮЄшЄІЄЪЕЄЄтЄЙЄыЁФЁЃSwinIR ЄЯЅЂЅЫЅсФДЄШЄЄЄІЄЋЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/19(Пх) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] ВшСќГШТчЅФЁМЅыЄђЄтЄІОЏЄЗЛюЭбЄЗЄЦЄпЄП
_КђЦќЁЂ
ГЦМяВшСќГШТчЅФЁМЅыЄђЛюЭбЄЗЄЦЄпЄПЄБЄьЄЩЁЂЄЛЄУЄЋЄЏЄРЄЋЄщМТИГЗыВЬЄЮВшСќЗВЄђЅЂЅУЅзЅэЁМЅЩЄЗЄЦЄпЄыЁЃЄфЄЯЄъВшСќЄђИЋЄЦЄпЄЪЄЄЄШШНУЧЄЌЄФЄЋЄЪЄЄЄРЄэЄІЄЗЁФЁЃ
ДФЖЄЯЁЂWindows10 x64 22H2ЁЃCPU : AMD Ryzen 5 5600XЁЃRAM : 16GBЁЃGPU : NVIDIA GeForce GXT 1060 6GBЁЃ
ЛШЭбЅФЁМЅыЄЯАЪВМЁЃ
_GitHub - Djdefrag/NiceScaler: NiceScaler - image/video deeplearning upscaler (OpenCV)
_GitHub - upscayl/upscayl: Upscayl - Free and Open Source AI Image Upscaler for Linux, MacOS and Windows built with Linux-First philosophy.
_GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
_samj Creations: GIMP 2.10.32 Portable 32 bits et 64 bits Win
_IrfanView - Official Homepage - One of the Most Popular Viewers Worldwide
ДФЖЄЯЁЂWindows10 x64 22H2ЁЃCPU : AMD Ryzen 5 5600XЁЃRAM : 16GBЁЃGPU : NVIDIA GeForce GXT 1060 6GBЁЃ
ЛШЭбЅФЁМЅыЄЯАЪВМЁЃ
- NiceScaler 1.13
- Upscayl 2.0.1
- Stable Diffusion web UI
- GIMP 2.10.32 x64 Portable samjШЧ
- IrfanView 4.62 32bit
_GitHub - Djdefrag/NiceScaler: NiceScaler - image/video deeplearning upscaler (OpenCV)
_GitHub - upscayl/upscayl: Upscayl - Free and Open Source AI Image Upscaler for Linux, MacOS and Windows built with Linux-First philosophy.
_GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
_samj Creations: GIMP 2.10.32 Portable 32 bits et 64 bits Win
_IrfanView - Official Homepage - One of the Most Popular Viewers Worldwide
Ё§ ИЕВшСќЄЫЄФЄЄЄЦ :
ЄоЄКЄЯИЕВшСќЁЃStable Diffusion web UI ЄШЁЂmuseV1_v1.safetensors ЄШЄЄЄІГиНЌЅтЅЧЅыЅЧЁМЅПЄђЛШЄУЄЦРИРЎЄЗЄЦЄпЄПЁЃ512x512ЄЮВшСќЁЃ

_00_img_orig.png
ЄГЄьЄђЁЂGIMP 2.10.32 ЄђЛШЄУЄЦЁЂЅЅхЁМЅгЅУЅЏ(BicubicЁЉ)ЄЧ4/1ЄЫНЬОЎЁЃ128x128ЄЮВшСќЄЫЄЗЄПЁЃ

ЄГЄЮ128x128ЄЮВшСќЄђЁЂНФВЃ4ЧмЁЂ512x512ЄЮВшСќЄЫГШТчЄЗЄЦЄпЄыЁЃЄЕЄЦЁЂЄЩЄІЄЪЄыЄЋЁЃ
{kind=link}
{kind=link}
parameters 1 asian girl, masterpiece, best quality, photo realistic, realistic, ultra high res, 8k, RAW photo, High detail RAW color photo, professional photograph, smile, looking at viewer, beautiful face, cute eyes, cowboy shot, school uniform, dynamic lighting, dynamic pose, Negative prompt: painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, ((monochrome)), ((grayscale)), bad hands, bad arms, missing fingers, missing arms, missing hands, bad anatomy, bas legs, nsfw, Steps: 40, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 2968748192, Face restoration: CodeFormer, Size: 512x512, Model hash: 84a23b651d, Model: museV1_v1
ЄГЄьЄђЁЂGIMP 2.10.32 ЄђЛШЄУЄЦЁЂЅЅхЁМЅгЅУЅЏ(BicubicЁЉ)ЄЧ4/1ЄЫНЬОЎЁЃ128x128ЄЮВшСќЄЫЄЗЄПЁЃ
ЄГЄЮ128x128ЄЮВшСќЄђЁЂНФВЃ4ЧмЁЂ512x512ЄЮВшСќЄЫГШТчЄЗЄЦЄпЄыЁЃЄЕЄЦЁЂЄЩЄІЄЪЄыЄЋЁЃ
Ё§ ЗыВЬВшСќАьЭї :
GIMP 2.10.32 + Nearest neighbor ЄЧГШТчЁЃ

1x1ЅЩЅУЅШЄЌ4x4ЅЩЅУЅШЄЫУБНуЄЫАњЄБфЄаЄЕЄьЄЦЄыЁЃНшЭ§ЄЮТЎЄЕЄРЄБЄЌМшЄъЪСЄРЄЪЄШЁФЁЃ
GIMP 2.10.32 + Bilinear ЄЧГШТчЁЃ
GIMP 2.10.32 + Bicubic ЄЧГШТчЁЃ
BilinearЄШBicubicЄЯЁЂЄЂЄоЄъЪбЄяЄщЄЪЄЄЕЄЄЌЄЙЄыЁФЁЃЫмХіЄЫ GIMP ЄЯЄНЄЮЅЂЅыЅДЅъЅКЅрЄђЛШЄУЄЦЄЄЄыЄЮЄРЄэЄІЄЋЁЃ *1 ЪЬЄЮЅФЁМЅыЄђЛШЄУЄПЄлЄІЄЌЮЩЄЋЄУЄПЄЮЄЋЄЪЁФЁЉ
ВПЄЫЄЛЄшЁЂAIЄђЛШЄяЄЪЄЄЁЂДћТИЄЮГШТчЅЂЅыЅДЅъЅКЅрЄЧЄЯЁЂТчТЮЄГЄѓЄЪДЖЄИЄЮЄмЄфЄБЄПЗыВЬЄЗЄЋЦРЄщЄьЄЪЄЄЁЃ
NiceScaler 1.13 + ESPCN x4 ЄЧГШТчЁЃ
NiceScaler 1.13 + FSRCNN x4 ЄЧГШТчЁЃ
NiceScaler 1.13 + LapSRN x4 ЄЧГШТчЁЃ
NiceScaler 1.13 + EDSR x4 ЄЧГШТчЁЃ
EDSR ЄЯЁЂТОЄЮЅЂЅыЅДЅъЅКЅрЄШШцЄйЄЦЁЂ10ЁС20ЧмЄлЄЩНшЭ§ЛўДжЄЌЄЋЄЋЄУЄПЁЃЄНЄЮЄЛЄЄЄЋЁЂМуДГРККйЄЪЗыВЬЄђНаЄЛЄЦЄЄЄыЕЄЄЌЄЙЄыЁЃ
Upscayl 2.0.1 + RealESRGAN-x4+ ЄЧГШТчЁЃ
Upscayl 2.0.1 + Remacri x4 ЄЧГШТчЁЃ
Remacri ЄЌЖЫЄсЄЦЭЅНЈЄЪЄЮЄЧЄЯЄЪЄЋЄэЄІЄЋЁФЁЃ
Stable Diffusion web UI + Extras + ESRGAN ЄЧГШТчЁЃ
ЧиЗЪЩєЪЌЄЯЄЩЄЮЅЂЅыЅДЅъЅКЅрЄшЄъЄтРККйЄЕЄЌЄЂЄыЄБЄьЄЩЁЂПЭЪЊЄЮЮиГдЩєЪЌЄфВшСќУМЄЫЦцЄЮЦѓНХРўЄЌНаЛЯЄсЄЦЄЄЄыЁЃМЋСГЪЊЄђСъМъЄЫЄЙЄыЛўЄЯЛШЄЈЄыЄЮЄЋЄтЄЗЄьЄЪЄЄЁФЁЉ
Stable Diffusion web UI + Extras + R-ESRGAN-4x+ ЄЧГШТчЁЃ
Stable Diffusion web UI + Extras + SwinIR_4x ЄЧГШТчЁЃ
Stable Diffusion web UI + Extras + LDSR ЄЧГШТчЁЃ
LDSR ЄЯЁЂТОЄЮЅЂЅыЅДЅъЅКЅрЄШШцЄйЄыЄШЁЂЄШЄѓЄЧЄтЄЪЄЏЛўДжЄЌЄЋЄЋЄУЄПЁЃЄНЄЮТхЄяЄъЁЂЄЋЄЪЄъРККйЄЪЗыВЬЄђЄРЄЗЄЦЄЄПЄшЄІЄЫИЋЄЈЄыЁЃ
Stable Diffusion web UI + Extras + R-ESRGAN-4x+ + SwinIR_x4 ЄЧГШТчЁЃ
Stable Diffusion web UIЄЯЁЂUpscaler Єђ2МяЮрЛиФъЄЙЄыЄГЄШЄЌЄЧЄЄыЄЮЄЧЛюЄЗЄЦЄпЄПЁЃЄЗЄЋЄЗЁЂЗрХЊЄЪИњВЬЄЯЦРЄщЄьЄЪЄЋЄУЄПЁЃЄПЄРЁЂСЊЄжЅЂЅыЅДЅъЅКЅрЄЮСШЄпЙчЄяЄЛЄЫЄшЄУЄЦЄЯТчВНЄБЄЗЄНЄІЄЪЕЄЄтЄЙЄыЁФЁЃ
Stable Diffusion web UI + Extras + R-ESRGAN-4x+ + SwinIR_x4 + GFPGAN 1.0 + CodeFormer 1.0 ЄЧГШТчЁЃ
Stable Diffusion web UIЄЯЁЂДщЩєЪЌЄђНЄЩќЄЧЄЄыЁЂGFPGANЁЂCodeFormer ЄђЛШЄІЄГЄШЄтЄЧЄЄыЁЃДщЄЮЩєЪЌЄРЄБЄЫУэЬмЄЙЄыЄШЁЂЅАЅѓЄШРККйЄЕЄЌС§ЄЗЄЦЄЄЄыЁЃЄПЄРЄЗЁЂДщАЪГАЄЯКЃЄоЄЧЄШЄлЄШЄѓЄЩАуЄЄЄЯЬЕЄЄЁЃ
ЭОУЬЁЃUpscayl + Remacri ЄЮЗыВЬЄЌЭЅНЈЄРЄУЄПЄЮЄЧЁЂЛюЄЗЄЫЁЂЄНЄЮЗыВЬВшСќЄЫТаЄЗЄЦКЦХй Remacri ЄђЄЋЄБЄЦЄпЄЦ(ИЕВшСќЄЋЄщ16ЧмЁЂ2048x2048ЄЮВшСќЄЫЄЗЄЦ)ЁЂЄНЄГЄЋЄщ IrfanView + Lanczos ЄЧ 4/1 ЄЫ(512x512ЄЮВшСќЄЫ)НЬОЎЄЗЄЦЄпЄПЁЃ
1x1ЅЩЅУЅШЄЌ4x4ЅЩЅУЅШЄЫУБНуЄЫАњЄБфЄаЄЕЄьЄЦЄыЁЃНшЭ§ЄЮТЎЄЕЄРЄБЄЌМшЄъЪСЄРЄЪЄШЁФЁЃ
GIMP 2.10.32 + Bilinear ЄЧГШТчЁЃ
GIMP 2.10.32 + Bicubic ЄЧГШТчЁЃ
BilinearЄШBicubicЄЯЁЂЄЂЄоЄъЪбЄяЄщЄЪЄЄЕЄЄЌЄЙЄыЁФЁЃЫмХіЄЫ GIMP ЄЯЄНЄЮЅЂЅыЅДЅъЅКЅрЄђЛШЄУЄЦЄЄЄыЄЮЄРЄэЄІЄЋЁЃ *1 ЪЬЄЮЅФЁМЅыЄђЛШЄУЄПЄлЄІЄЌЮЩЄЋЄУЄПЄЮЄЋЄЪЁФЁЉ
ВПЄЫЄЛЄшЁЂAIЄђЛШЄяЄЪЄЄЁЂДћТИЄЮГШТчЅЂЅыЅДЅъЅКЅрЄЧЄЯЁЂТчТЮЄГЄѓЄЪДЖЄИЄЮЄмЄфЄБЄПЗыВЬЄЗЄЋЦРЄщЄьЄЪЄЄЁЃ
NiceScaler 1.13 + ESPCN x4 ЄЧГШТчЁЃ
NiceScaler 1.13 + FSRCNN x4 ЄЧГШТчЁЃ
NiceScaler 1.13 + LapSRN x4 ЄЧГШТчЁЃ
NiceScaler 1.13 + EDSR x4 ЄЧГШТчЁЃ
EDSR ЄЯЁЂТОЄЮЅЂЅыЅДЅъЅКЅрЄШШцЄйЄЦЁЂ10ЁС20ЧмЄлЄЩНшЭ§ЛўДжЄЌЄЋЄЋЄУЄПЁЃЄНЄЮЄЛЄЄЄЋЁЂМуДГРККйЄЪЗыВЬЄђНаЄЛЄЦЄЄЄыЕЄЄЌЄЙЄыЁЃ
Upscayl 2.0.1 + RealESRGAN-x4+ ЄЧГШТчЁЃ
Upscayl 2.0.1 + Remacri x4 ЄЧГШТчЁЃ
Remacri ЄЌЖЫЄсЄЦЭЅНЈЄЪЄЮЄЧЄЯЄЪЄЋЄэЄІЄЋЁФЁЃ
Stable Diffusion web UI + Extras + ESRGAN ЄЧГШТчЁЃ
ЧиЗЪЩєЪЌЄЯЄЩЄЮЅЂЅыЅДЅъЅКЅрЄшЄъЄтРККйЄЕЄЌЄЂЄыЄБЄьЄЩЁЂПЭЪЊЄЮЮиГдЩєЪЌЄфВшСќУМЄЫЦцЄЮЦѓНХРўЄЌНаЛЯЄсЄЦЄЄЄыЁЃМЋСГЪЊЄђСъМъЄЫЄЙЄыЛўЄЯЛШЄЈЄыЄЮЄЋЄтЄЗЄьЄЪЄЄЁФЁЉ
Stable Diffusion web UI + Extras + R-ESRGAN-4x+ ЄЧГШТчЁЃ
Stable Diffusion web UI + Extras + SwinIR_4x ЄЧГШТчЁЃ
Stable Diffusion web UI + Extras + LDSR ЄЧГШТчЁЃ
LDSR ЄЯЁЂТОЄЮЅЂЅыЅДЅъЅКЅрЄШШцЄйЄыЄШЁЂЄШЄѓЄЧЄтЄЪЄЏЛўДжЄЌЄЋЄЋЄУЄПЁЃЄНЄЮТхЄяЄъЁЂЄЋЄЪЄъРККйЄЪЗыВЬЄђЄРЄЗЄЦЄЄПЄшЄІЄЫИЋЄЈЄыЁЃ
Stable Diffusion web UI + Extras + R-ESRGAN-4x+ + SwinIR_x4 ЄЧГШТчЁЃ
Stable Diffusion web UIЄЯЁЂUpscaler Єђ2МяЮрЛиФъЄЙЄыЄГЄШЄЌЄЧЄЄыЄЮЄЧЛюЄЗЄЦЄпЄПЁЃЄЗЄЋЄЗЁЂЗрХЊЄЪИњВЬЄЯЦРЄщЄьЄЪЄЋЄУЄПЁЃЄПЄРЁЂСЊЄжЅЂЅыЅДЅъЅКЅрЄЮСШЄпЙчЄяЄЛЄЫЄшЄУЄЦЄЯТчВНЄБЄЗЄНЄІЄЪЕЄЄтЄЙЄыЁФЁЃ
Stable Diffusion web UI + Extras + R-ESRGAN-4x+ + SwinIR_x4 + GFPGAN 1.0 + CodeFormer 1.0 ЄЧГШТчЁЃ
Stable Diffusion web UIЄЯЁЂДщЩєЪЌЄђНЄЩќЄЧЄЄыЁЂGFPGANЁЂCodeFormer ЄђЛШЄІЄГЄШЄтЄЧЄЄыЁЃДщЄЮЩєЪЌЄРЄБЄЫУэЬмЄЙЄыЄШЁЂЅАЅѓЄШРККйЄЕЄЌС§ЄЗЄЦЄЄЄыЁЃЄПЄРЄЗЁЂДщАЪГАЄЯКЃЄоЄЧЄШЄлЄШЄѓЄЩАуЄЄЄЯЬЕЄЄЁЃ
ЭОУЬЁЃUpscayl + Remacri ЄЮЗыВЬЄЌЭЅНЈЄРЄУЄПЄЮЄЧЁЂЛюЄЗЄЫЁЂЄНЄЮЗыВЬВшСќЄЫТаЄЗЄЦКЦХй Remacri ЄђЄЋЄБЄЦЄпЄЦ(ИЕВшСќЄЋЄщ16ЧмЁЂ2048x2048ЄЮВшСќЄЫЄЗЄЦ)ЁЂЄНЄГЄЋЄщ IrfanView + Lanczos ЄЧ 4/1 ЄЫ(512x512ЄЮВшСќЄЫ)НЬОЎЄЗЄЦЄпЄПЁЃ
Ё§ ЛЈДЖ :
ДћТИЄЮЅЂЅыЅДЅъЅКЅрЁЂNearest neighborЁЂBilinearЁЂBicubic ЄЯЄШЄтЄЋЄЏЄШЄЗЄЦЁЂЄНЄьАЪГАЁЂAIЄђЛШЄУЄЦГШТчЄЙЄыЅФЁМЅыЄЮЅЂЅыЅДЅъЅКЅрЄЯЁЂЄЩЄьЄтШцГгХЊЮЩЄЄЗыВЬЄђНаЄЗЄЦЄЄЄыЄшЄІЄЪЕЄЄЌЄЙЄыЁЃ
ВПЄЛЁЂИЕВшСќЄЌ128x128ЁЃЁжЄНЄьЁЂТўЄЮЅЕЅрЅЭЅЄЅыВшСќЄИЄуЄѓЁзОѕТжЁЃЄЪЄЮЄЫЁЂЄНЄьЄщЄЗЄЄВшСќЄђНаЮЯЄЧЄЄЦЄЄЄыЄяЄБЄЧЁФЁЃ
ЄЖЄУЄШФЏЄсЄПДЖЄИЄЧЄЯЁЂUpscayl + Remacri ЄЮЗыВЬЄЌЁЂЗВЄђШДЄЄЄЦЄНЄьЄУЄнЄЏЄЪЄУЄЦЄЄЄыЄшЄІЄЫЛзЄЈЄПЁЃ
АЪВМЄЫЁЂЅЊЅъЅИЅЪЅыВшСќЄШ Remacri ЄЮЗыВЬВшСќЄђКЦЗЧЄЗЄЦЄпЄыЄБЄьЄЩЁЂЅЕЅрЅЭЅЄЅыВшСќЅтЅЩЅЄЋЄщЄГЄГЄоЄЧЩќИЕЄЧЄЄПЄЮЄРЄЋЄщЅЙЅДЅЄЕЄЄЌЄЙЄыЁФЁЃ
ГШТчНшЭ§САЄЮВшСќЄЌЁЂЅГЅьЄЧЄЙЄЋЄщЄЭЁФЁЃ
ЄтЄУЄШЄтЁЂRemacri ЄЮЗыВЬВшСќЄђГШТчЄЗЄЦФЏЄсЄыЄШЁЂЄтЄЯЄфМЬППЄЧЄЯЄЪЄЏЁЂДАСДЄЫГЈЄЫЄЪЄУЄЦЄЄЄыАѕОнЄтМѕЄБЄПЁЃЮуЄЈЄаЁЂАЪВМЄЯ Remacri Єђ2ВѓЄЋЄБЄП 2048x2048ЄЮВшСќЄРЄБЄЩЁЂЄлЄШЄѓЄЩЄЮЩєЪЌЄЌЄЬЄыЄУЄШЄЗЄПИЋЄПЬмЄЫЄЪЄУЄЦЄЄЄыЁЃЄГЄьЄЯЄтЄІГЈЄРЄЪЄШЁФЁЃ
_22_img_remacri_x4x4_upscayl.jpg
ВПЄЛЁЂИЕВшСќЄЌ128x128ЁЃЁжЄНЄьЁЂТўЄЮЅЕЅрЅЭЅЄЅыВшСќЄИЄуЄѓЁзОѕТжЁЃЄЪЄЮЄЫЁЂЄНЄьЄщЄЗЄЄВшСќЄђНаЮЯЄЧЄЄЦЄЄЄыЄяЄБЄЧЁФЁЃ
ЄЖЄУЄШФЏЄсЄПДЖЄИЄЧЄЯЁЂUpscayl + Remacri ЄЮЗыВЬЄЌЁЂЗВЄђШДЄЄЄЦЄНЄьЄУЄнЄЏЄЪЄУЄЦЄЄЄыЄшЄІЄЫЛзЄЈЄПЁЃ
АЪВМЄЫЁЂЅЊЅъЅИЅЪЅыВшСќЄШ Remacri ЄЮЗыВЬВшСќЄђКЦЗЧЄЗЄЦЄпЄыЄБЄьЄЩЁЂЅЕЅрЅЭЅЄЅыВшСќЅтЅЩЅЄЋЄщЄГЄГЄоЄЧЩќИЕЄЧЄЄПЄЮЄРЄЋЄщЅЙЅДЅЄЕЄЄЌЄЙЄыЁФЁЃ
ГШТчНшЭ§САЄЮВшСќЄЌЁЂЅГЅьЄЧЄЙЄЋЄщЄЭЁФЁЃ
ЄтЄУЄШЄтЁЂRemacri ЄЮЗыВЬВшСќЄђГШТчЄЗЄЦФЏЄсЄыЄШЁЂЄтЄЯЄфМЬППЄЧЄЯЄЪЄЏЁЂДАСДЄЫГЈЄЫЄЪЄУЄЦЄЄЄыАѕОнЄтМѕЄБЄПЁЃЮуЄЈЄаЁЂАЪВМЄЯ Remacri Єђ2ВѓЄЋЄБЄП 2048x2048ЄЮВшСќЄРЄБЄЩЁЂЄлЄШЄѓЄЩЄЮЩєЪЌЄЌЄЬЄыЄУЄШЄЗЄПИЋЄПЬмЄЫЄЪЄУЄЦЄЄЄыЁЃЄГЄьЄЯЄтЄІГЈЄРЄЪЄШЁФЁЃ
_22_img_remacri_x4x4_upscayl.jpg
{kind=link}
{kind=link}
Ё§ ВшСќЄиЄЮЅъЅѓЅЏ :
АьБўЁЂГЦВшСќЄиЄЮЅъЅѓЅЏЄтХНЄУЄЦЄЊЄЄоЄЙЁЃ
_00_img_orig.png
_01_img_orig.png
_02_img_quarter_gimp210.png
_03_img_nearest_neighbor_x4_gimp210.png
_04_img_bilinear_x4_gimp210.png
_05_img_bicubic_x4_gimp210.png
_06_img_espcn_x4_nicescaler.png
_07_img_fsrcnn_x4_nicescaler.png
_08_img_lapsrn_x4_nicescaler.png
_09_img_edsr_x4_nicescaler.png
_10_img_realesrgan-x4plus_x4_upscayl.png
_11_img_remacri_x4_upscayl.png
_12_img_esrgan_x4_sdwebui.png
_13_img_r-esrgan-4xplus_x4_sdwebui.png
_14_img_swinir_x4_sdwebui.png
_15_img_ldsr_x4_sdwebui.png
_15_img_r-esrgan-4xplus_swinir_x4_sdwebui.png
_16_img_r-esrgan-4xplus_swinir_gfpgan_x4_sdwebui.png
_22_img_remacri_x4x4_upscayl.jpg
_23_img_remacri_x4x4_upscayl_x025lanczos_irfan.png
_00_img_orig.png
_01_img_orig.png
{kind=link}
_02_img_quarter_gimp210.png
{kind=link}
_03_img_nearest_neighbor_x4_gimp210.png
{kind=link}
_04_img_bilinear_x4_gimp210.png
{kind=link}
_05_img_bicubic_x4_gimp210.png
{kind=link}
_06_img_espcn_x4_nicescaler.png
{kind=link}
_07_img_fsrcnn_x4_nicescaler.png
{kind=link}
_08_img_lapsrn_x4_nicescaler.png
{kind=link}
_09_img_edsr_x4_nicescaler.png
{kind=link}
_10_img_realesrgan-x4plus_x4_upscayl.png
{kind=link}
_11_img_remacri_x4_upscayl.png
{kind=link}
_12_img_esrgan_x4_sdwebui.png
{kind=link}
_13_img_r-esrgan-4xplus_x4_sdwebui.png
{kind=link}
_14_img_swinir_x4_sdwebui.png
{kind=link}
_15_img_ldsr_x4_sdwebui.png
{kind=link}
_15_img_r-esrgan-4xplus_swinir_x4_sdwebui.png
{kind=link}
_16_img_r-esrgan-4xplus_swinir_gfpgan_x4_sdwebui.png
{kind=link}
_22_img_remacri_x4x4_upscayl.jpg
_23_img_remacri_x4x4_upscayl_x025lanczos_irfan.png
{kind=link}
*1: РЮЄЮGIMPЄЫЄЯЁЂЩНЕЄЕЄьЄЦЄыЅЂЅыЅДЅъЅКЅрЬОЄШАуЄІЅЂЅыЅДЅъЅКЅрЄђМТКнЄЫЄЯЛШЄУЄЦЄЄЄПЄШЄЄЄІЅаЅАЄЌЄЂЄУЄПЕЄЄЌЄЙЄыЁЃ
[ ЅФЅУЅГЄр ]
#2 [zatta] ЦќЕЄђЅЂЅУЅзЅэЁМЅЩ
2023/03/22ЄЋЄщЦќЕЄђЅЂЅУЅзЅэЁМЅЩЄЗЄЦЄЪЄЋЄУЄПЄЮЄЧЅЂЅУЅзЅэЁМЅЩЁЃ
[ ЅФЅУЅГЄр ]
2023/04/20(Ьк) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] ControlNetЄђЛюЭб
ВшСќРИРЎAIЁЂStable Diffusion web UI ЄЯЁЂПЭЪЊЄЮЅнЁМЅКЄЪЄЩЄђЛиФъЄЙЄыЄЮЄЌЬЬХнНЄЄЁЃЄЩЄІЄЄЄІУБИьЄђТЧЄСЙўЄсЄаЄНЄьЄщЄЗЄЄЅнЁМЅКЄђЄШЄУЄЦЄЏЄьЄыЄЮЄЋЪЌЄЋЄщЄЪЄЄЄЮЄЧЁЂЛзЄЄЄФЄЏЄоЄоВПЄЋЄЗЄщЄЮУБИьЄђТЧЄУЄЦЁЂЄГЄьЄЧЄтЄЪЄЄЁЂЄГЄьЄЧЄтЄЪЄЄЄШЧКЄрЄГЄШЄЫЄЪЄыЁЃ
ЄЗЄЋЄЗЁЂControlNet ЄЪЄыЄтЄЮЄђЛШЄЈЄаЅнЁМЅКХљЄђЛиФъЄЗЄфЄЙЄЏЄЪЄыЄщЄЗЄЄЁЃЄЛЄУЄЋЄЏЄРЄЋЄщЛюЭбЄЗЄЦЄпЄыЄГЄШЄЫЄЗЄПЁЃ
ДФЖЄЯАЪВМЁЃ
МЋЪЌЄЮДФЖЄЧЄЯЁЂStable Diffusion web UI ЄђЁЂD:\aiwork\stable-diffusion-webui\ ЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЂЄыЁЃ
ControlNet ЄЮЦГЦўЪ§ЫЁЄЯЁЂАЪВМЄЮВђРтЕЛіЄђЛВЙЭЄЫЄЕЄЛЄЦЄтЄщЄУЄПЁЃЄЂЄъЄЌЄПЄфЁЃ
_ЅнЁМЅКЄђЛиФъЄЗЄЦВшСќЄђРИРЎЄЧЄЄыЁжControlNetЁзЄЮЛШЄЄЪ§ЁкStable Diffusion web UIЁл | ЄЏЄэЄЏЄоЄНЄеЄШ
ЄЖЄУЄЏЄъНёЄЏЄШЁЂАЪВМЄђЅЄЅѓЅЙЅШЁМЅыЄЙЄыЄГЄШЄЫЄЪЄыЄщЄЗЄЄЁЃ
ЄЗЄЋЄЗЁЂControlNet ЄЪЄыЄтЄЮЄђЛШЄЈЄаЅнЁМЅКХљЄђЛиФъЄЗЄфЄЙЄЏЄЪЄыЄщЄЗЄЄЁЃЄЛЄУЄЋЄЏЄРЄЋЄщЛюЭбЄЗЄЦЄпЄыЄГЄШЄЫЄЗЄПЁЃ
ДФЖЄЯАЪВМЁЃ
- Windows10 x64 22H2
- Python 3.10.6 x64
- CPU : AMD Ryzen 5 5600X
- RAM : 16GB
- GPU : NVIDIA GeForce GTX 1060 6GB
МЋЪЌЄЮДФЖЄЧЄЯЁЂStable Diffusion web UI ЄђЁЂD:\aiwork\stable-diffusion-webui\ ЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЂЄыЁЃ
ControlNet ЄЮЦГЦўЪ§ЫЁЄЯЁЂАЪВМЄЮВђРтЕЛіЄђЛВЙЭЄЫЄЕЄЛЄЦЄтЄщЄУЄПЁЃЄЂЄъЄЌЄПЄфЁЃ
_ЅнЁМЅКЄђЛиФъЄЗЄЦВшСќЄђРИРЎЄЧЄЄыЁжControlNetЁзЄЮЛШЄЄЪ§ЁкStable Diffusion web UIЁл | ЄЏЄэЄЏЄоЄНЄеЄШ
ЄЖЄУЄЏЄъНёЄЏЄШЁЂАЪВМЄђЅЄЅѓЅЙЅШЁМЅыЄЙЄыЄГЄШЄЫЄЪЄыЄщЄЗЄЄЁЃ
- Stable Diffusion web UI ЄЧ ControlNet ЄђЭјЭбЄЙЄыЄПЄсЄЮГШФЅЕЁЧНЄђЅЄЅѓЅЙЅШЁМЅыЁЃ
- ControlNetЭбЄЮЅтЅЧЅыЅЧЁМЅПЄђЅЄЅѓЅЙЅШЁМЅыЁЃ
Ё§ ГШФЅЕЁЧНЄЮЅЄЅѓЅЙЅШЁМЅы :
ЙЋЄЮВђРтЕЛіЄђФЏЄсЄыЄШЁЂТчТЮЄЯЁЂgithub ЄЮURLЄђЅГЅдЅкЄЗЄЦЅЄЅѓЅЙЅШЁМЅыЄЙЄыЪ§ЫЁЄЌОвВ№ЄЕЄьЄЦЄЄЄыЄЮЄРЄБЄЩЁЃКЃВѓЄЯСАНвЄЮВђРтЕЛіЄЫНОЄУЄЦЁЂStable Diffusion web UI ЄЮГШФЅЕЁЧНЅПЅж ЂЊ ГШФЅЕЁЧНЅъЅЙЅШЄЧГШФЅЕЁЧНЄЮАьЭїЄђЩНМЈЄЗЄЦЁЂЅЄЅѓЅЙЅШЁМЅыЄЙЄыЪ§ЫЁЄђСЊЄѓЄЧЄпЄПЁЃ
ГШФЅЕЁЧНЄЮАьЭїЄЋЄщЁЂsd-webui-controlnet ЄђУЕЄЗЄЦЁЂБІТІЄЫЄЂЄыЅЄЅѓЅЙЅШЁМЅыЅмЅПЅѓЄђЅЏЅъЅУЅЏЄЙЄьЄаЅЄЅѓЅЙЅШЁМЅыЄЧЄЄыЁЃ
ЄЗЄЋЄЗЁЂsd-webui-controlnet ЄЮЅЄЅѓЅЙЅШЁМЅыЛўЁЂDOSСыОхЄЫЅЈЅщЁМЄЌНаЄПЁЃЄшЄЏЪЌЄЋЄщЄЪЄЄЄЮЄЧЁЂСДЩєХНЄъЩеЄБЄЦЄпЄыЁЃ
ЄЊЄНЄщЄЏЄРЄБЄЩЁФЁЃsd-webui-controlnet ЄШЄЄЄІГШФЅЕЁЧНЄђЦАЄЋЄЙЄПЄсЄЫЄЯЁЂopencv-contrib-python ЄШ mediapipe ЄШЄЄЄІ PythonЄЮЅтЅИЅхЁМЅыЄЌЩЌЭзЄЫЄЪЄыЄУЄнЄЄЁЃЄЗЄЋЄЗЁЂЄНЄЮЅтЅИЅхЁМЅыЄЮЅЄЅѓЅЙЅШЁМЅыЛўЄЫЅЈЅщЁМЄЌНаЄЦЄЗЄоЄУЄПЄшЄІЄЫИЋЄЈЄыЁЃЄПЄжЄѓЁЃМЋПЎЬЕЄЄЄБЄЩЁЃ
ЛюЄЗЄЫЁЂЄНЄьЄщЄЮЅтЅИЅхЁМЅыЄђЁЂМъКюЖШЄЧЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄыЄГЄШЄЫЄЗЄПЁЃ
Stable Diffusion web UIЄђНЊЮЛЄЕЄЛЄЦ(DOSСыЄђЪФЄИЄЦ)ЁЂЪЬХгЁЂDOSСы(cmd.exe) ЄђЕЏЦАЄЗЄЦЄЋЄщЁЂpip ЄђЛШЄУЄЦЅЄЅѓЅЙЅШЁМЅыЁЃЄПЄРЄЗЁЂ(Stable Diffusion web UIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\venv\Scripts\ ЄђЅЋЅьЅѓЅШЅЧЅЃЅьЅЏЅШЅъЄЫЄЗЄЦКюЖШЄЗЄЪЄЄЄШЄЄЄБЄЪЄЄЁЃ
МъКюЖШЄЧЅЄЅѓЅЙЅШЁМЅыЄЙЄыЪЌЄЫЄЯЁЂЅЈЅщЁМЄЌНаЄЪЄЄОѕТжЄЧЅЄЅѓЅЙЅШЁМЅыЄЧЄЄПЁЂЄшЄІЄЪЕЄЄЌЄЙЄыЁЃ
ГШФЅЕЁЧНЄЮАьЭїЄЋЄщЁЂsd-webui-controlnet ЄђУЕЄЗЄЦЁЂБІТІЄЫЄЂЄыЅЄЅѓЅЙЅШЁМЅыЅмЅПЅѓЄђЅЏЅъЅУЅЏЄЙЄьЄаЅЄЅѓЅЙЅШЁМЅыЄЧЄЄыЁЃ
ЄЗЄЋЄЗЁЂsd-webui-controlnet ЄЮЅЄЅѓЅЙЅШЁМЅыЛўЁЂDOSСыОхЄЫЅЈЅщЁМЄЌНаЄПЁЃЄшЄЏЪЌЄЋЄщЄЪЄЄЄЮЄЧЁЂСДЩєХНЄъЩеЄБЄЦЄпЄыЁЃ
Error running install.py for extension D:\aiwork\stable-diffusion-webui\extensions\sd-webui-controlnet.
Command: "D:\aiwork\stable-diffusion-webui\venv\Scripts\python.exe" "D:\aiwork\stable-diffusion-webui\extensions\sd-webui-controlnet\install.py"
Error code: 1
stdout: Installing sd-webui-controlnet requirement: mediapipe==0.9.1.0
stderr: Traceback (most recent call last):
File "D:\aiwork\stable-diffusion-webui\extensions\sd-webui-controlnet\install.py", line 11, in <module>
launch.run_pip(f"install {lib}", f"sd-webui-controlnet requirement: {lib}")
File "D:\aiwork\stable-diffusion-webui\launch.py", line 129, in run_pip
return run(f'"{python}" -m pip {args} --prefer-binary{index_url_line}', desc=f"Installing {desc}", errdesc=f"Couldn't install {desc}")
File "D:\aiwork\stable-diffusion-webui\launch.py", line 97, in run
raise RuntimeError(message)
RuntimeError: Couldn't install sd-webui-controlnet requirement: mediapipe==0.9.1.0.
Command: "D:\aiwork\stable-diffusion-webui\venv\Scripts\python.exe" -m pip install mediapipe==0.9.1.0 --prefer-binary
Error code: 1
stdout: Collecting mediapipe==0.9.1.0
Downloading mediapipe-0.9.1.0-cp310-cp310-win_amd64.whl (49.8 MB)
---------------------------------------- 49.8/49.8 MB 9.2 MB/s eta 0:00:00
Requirement already satisfied: protobuf<4,>=3.11 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from mediapipe==0.9.1.0) (3.20.3)
Requirement already satisfied: flatbuffers>=2.0 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from mediapipe==0.9.1.0) (23.3.3)
Requirement already satisfied: attrs>=19.1.0 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from mediapipe==0.9.1.0) (22.2.0)
Requirement already satisfied: matplotlib in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from mediapipe==0.9.1.0) (3.7.1)
Requirement already satisfied: numpy in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from mediapipe==0.9.1.0) (1.23.3)
Requirement already satisfied: absl-py in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from mediapipe==0.9.1.0) (1.4.0)
Collecting opencv-contrib-python
Downloading opencv_contrib_python-4.7.0.72-cp37-abi3-win_amd64.whl (44.9 MB)
---------------------------------------- 44.9/44.9 MB 9.5 MB/s eta 0:00:00
Requirement already satisfied: kiwisolver>=1.0.1 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from matplotlib->mediapipe==0.9.1.0) (1.4.4)
Requirement already satisfied: contourpy>=1.0.1 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from matplotlib->mediapipe==0.9.1.0) (1.0.7)
Requirement already satisfied: python-dateutil>=2.7 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from matplotlib->mediapipe==0.9.1.0) (2.8.2)
Requirement already satisfied: cycler>=0.10 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from matplotlib->mediapipe==0.9.1.0) (0.11.0)
Requirement already satisfied: pyparsing>=2.3.1 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from matplotlib->mediapipe==0.9.1.0) (3.0.9)
Requirement already satisfied: fonttools>=4.22.0 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from matplotlib->mediapipe==0.9.1.0) (4.39.3)
Requirement already satisfied: packaging>=20.0 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from matplotlib->mediapipe==0.9.1.0) (23.0)
Requirement already satisfied: pillow>=6.2.0 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from matplotlib->mediapipe==0.9.1.0) (9.4.0)
Requirement already satisfied: six>=1.5 in d:\aiwork\stable-diffusion-webui\venv\lib\site-packages (from python-dateutil>=2.7->matplotlib->mediapipe==0.9.1.0) (1.16.0)
Installing collected packages: opencv-contrib-python, mediapipe
stderr: ERROR: Could not install packages due to an OSError: [WinError 5] ANZX\u06c2\u0702B: 'D:\\aiwork\\stable-diffusion-webui\\venv\\Lib\\site-packages\\cv2\\cv2.pyd'
Check the permissions.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\aiwork\stable-diffusion-webui\extensions\sd-webui-controlnet\install.py", line 13, in <module>
print(e)
UnicodeEncodeError: 'cp932' codec can't encode character '\u06c2' in position 2984: illegal multibyte sequence
ЄЊЄНЄщЄЏЄРЄБЄЩЁФЁЃsd-webui-controlnet ЄШЄЄЄІГШФЅЕЁЧНЄђЦАЄЋЄЙЄПЄсЄЫЄЯЁЂopencv-contrib-python ЄШ mediapipe ЄШЄЄЄІ PythonЄЮЅтЅИЅхЁМЅыЄЌЩЌЭзЄЫЄЪЄыЄУЄнЄЄЁЃЄЗЄЋЄЗЁЂЄНЄЮЅтЅИЅхЁМЅыЄЮЅЄЅѓЅЙЅШЁМЅыЛўЄЫЅЈЅщЁМЄЌНаЄЦЄЗЄоЄУЄПЄшЄІЄЫИЋЄЈЄыЁЃЄПЄжЄѓЁЃМЋПЎЬЕЄЄЄБЄЩЁЃ
ЛюЄЗЄЫЁЂЄНЄьЄщЄЮЅтЅИЅхЁМЅыЄђЁЂМъКюЖШЄЧЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄыЄГЄШЄЫЄЗЄПЁЃ
Stable Diffusion web UIЄђНЊЮЛЄЕЄЛЄЦ(DOSСыЄђЪФЄИЄЦ)ЁЂЪЬХгЁЂDOSСы(cmd.exe) ЄђЕЏЦАЄЗЄЦЄЋЄщЁЂpip ЄђЛШЄУЄЦЅЄЅѓЅЙЅШЁМЅыЁЃЄПЄРЄЗЁЂ(Stable Diffusion web UIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\venv\Scripts\ ЄђЅЋЅьЅѓЅШЅЧЅЃЅьЅЏЅШЅъЄЫЄЗЄЦКюЖШЄЗЄЪЄЄЄШЄЄЄБЄЪЄЄЁЃ
cd /d D:\aiwork\stable-diffusion-webui\venv\Scripts pip install opencv-contrib-python pip install mediapipe
МъКюЖШЄЧЅЄЅѓЅЙЅШЁМЅыЄЙЄыЪЌЄЫЄЯЁЂЅЈЅщЁМЄЌНаЄЪЄЄОѕТжЄЧЅЄЅѓЅЙЅШЁМЅыЄЧЄЄПЁЂЄшЄІЄЪЕЄЄЌЄЙЄыЁЃ
Ё§ ControlNetЭбЅтЅЧЅыЅЧЁМЅПЄЮЦўМъ :
ControlNetЄђЛШЄІЄПЄсЄЫЄЯЁЂЪЬХгЁЂЅтЅЧЅыЅЧЁМЅПЄЌЩЌЭзЁЃАЪВМЄЋЄщDLЄЙЄыЁЃ
_lllyasviel/ControlNet-v1-1 at main
1.45GBЄАЄщЄЄЄЮГЦЅеЅЁЅЄЅы(ГШФЅЛвЄЯ .pth ЄРЄУЄП)ЄђDLЁЃСДЩєЄЧ14ЅеЅЁЅЄЅыЄЂЄыЄБЄьЄЩЁЂМЋЪЌЄЌЛШЄЄЄНЄІЄЪЅтЅЮЄРЄБDLЄЙЄьЄаЄЄЄЄЄщЄЗЄЄЁЃЄЗЄЋЄЗЁЂЄЩЄьЄЌВПЄЪЄЮЄЋЁЂКЃЄЮЛўХРЄЧЄЯЪЌЄщЄЪЄЄЄЮЄЧЁЂЄШЄъЄЂЄЈЄК14ЅеЅЁЅЄЅыСДЩєЄђDLЄЗЄЦЄЊЄЄЄПЁЃ
ЄГЄьЄђЁЂАЪВМЄЫЅГЅдЁМЄЙЄыЁЃ
ЄСЄЪЄпЄЫЁЂАЪВМЄЮЅкЁМЅИЄЧЄтЁЂЅеЅЁЅЄЅыЅЕЅЄЅКЄЌОЎЄЕЄЏЄЪЄУЄЦЄыЅтЅЧЅыЅЧЁМЅПЄЌЄЂЄыЄЮЄРЄБЄЩЁЃ
_webui/ControlNet-modules-safetensors at main
ЅеЅЁЅЄЅыЄЮЦќЩеЄЌ2ЅіЗюСАЄРЄУЄПЄЮЄЧЁЂЄГЄСЄщЄЯСЊЄаЄКЁЂСАНвЄЮЅкЁМЅИЄЋЄщЦўМъЄЧЄЄыЁЂ1.45GB ЄЮЅеЅЁЅЄЅыЗВЄђСЊЄѓЄРЁЃЄНЄСЄщЄЮЅеЅЁЅЄЅыЗВЄЯЁЂ7ЦќСАЄЫЙЙПЗЄЕЄьЄЦЄыЄУЄнЄЄЄЮЄЧЁФЁЃПЗЄЗЄЄЄлЄІЄЌЄЄЄЄЄЮЄРЄэЄІЄШЁФЁЃ
_lllyasviel/ControlNet-v1-1 at main
1.45GBЄАЄщЄЄЄЮГЦЅеЅЁЅЄЅы(ГШФЅЛвЄЯ .pth ЄРЄУЄП)ЄђDLЁЃСДЩєЄЧ14ЅеЅЁЅЄЅыЄЂЄыЄБЄьЄЩЁЂМЋЪЌЄЌЛШЄЄЄНЄІЄЪЅтЅЮЄРЄБDLЄЙЄьЄаЄЄЄЄЄщЄЗЄЄЁЃЄЗЄЋЄЗЁЂЄЩЄьЄЌВПЄЪЄЮЄЋЁЂКЃЄЮЛўХРЄЧЄЯЪЌЄщЄЪЄЄЄЮЄЧЁЂЄШЄъЄЂЄЈЄК14ЅеЅЁЅЄЅыСДЩєЄђDLЄЗЄЦЄЊЄЄЄПЁЃ
ЄГЄьЄђЁЂАЪВМЄЫЅГЅдЁМЄЙЄыЁЃ
(Stable Diffusion web UIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\extensions\sd-webui-controlnet\models\
ЄСЄЪЄпЄЫЁЂАЪВМЄЮЅкЁМЅИЄЧЄтЁЂЅеЅЁЅЄЅыЅЕЅЄЅКЄЌОЎЄЕЄЏЄЪЄУЄЦЄыЅтЅЧЅыЅЧЁМЅПЄЌЄЂЄыЄЮЄРЄБЄЩЁЃ
_webui/ControlNet-modules-safetensors at main
ЅеЅЁЅЄЅыЄЮЦќЩеЄЌ2ЅіЗюСАЄРЄУЄПЄЮЄЧЁЂЄГЄСЄщЄЯСЊЄаЄКЁЂСАНвЄЮЅкЁМЅИЄЋЄщЦўМъЄЧЄЄыЁЂ1.45GB ЄЮЅеЅЁЅЄЅыЗВЄђСЊЄѓЄРЁЃЄНЄСЄщЄЮЅеЅЁЅЄЅыЗВЄЯЁЂ7ЦќСАЄЫЙЙПЗЄЕЄьЄЦЄыЄУЄнЄЄЄЮЄЧЁФЁЃПЗЄЗЄЄЄлЄІЄЌЄЄЄЄЄЮЄРЄэЄІЄШЁФЁЃ
Ё§ ЛШЄУЄЦЄпЄП :
ЅЄЅѓЅЙЅШЁМЅыЄЫРЎИљЄЙЄыЄШЁЂStable Diffusion web UI ЄЮЁЂtxt2img Єф img2img ЄЮЅкЁМЅИЄЫЁЂControlNet ЄШЄЄЄІРпФъЙрЬмЄЌС§ЄЈЄЦЄЄЄыЁЃОЎЄЕЄЄЛАГбЄђЅЏЅъЅУЅЏЄЙЄыЄШЁЂБЃЄьЄЦЄЄЄПРпФъЙрЬмЄЌЩНМЈЄЕЄьЄыЁЃ
АЪВМЄЮЅкЁМЅИЄЧЁЂ3МяЮрЄЮЦАКюЅЦЅЙЅШЪ§ЫЁЄЌОвВ№ЄЕЄьЄЦЄЄЄПЁЃ
_ControlNet - ЄШЄЗЄЂЄdiffusion Wiki*
3ШжЬмЄЮЁЂimg2img ЅПЅжОхЄЧЄЮ Inpaint upload ЄЯЁЂЄСЄчЄУЄШЅЯЅоЄУЄПЁЃInpaint upload ЄЫЄЯЁЂОхЄЫИЕВшСќЁЂВМЄЫЅоЅЙЅЏВшСќЁЂЄФЄоЄъ2ЄФЄЮВшСќЄђХЯЄЗЄЦЄфЄщЄЪЄЄЄШЄЄЄЋЄѓЄЮЄРЄЪЁФЁЃЅоЅЙЅЏВшСќЄРЄБЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзЄЗЄЦЁЂЛзЄУЄПФЬЄъЄЫЦАЄЋЄЪЄЄЄЪЄШЧКЄѓЄЧЄЗЄоЄУЄПЁЃ
- ControlNet ЄЮРпФъЙрЬмЩєЪЌЄЫЁЂИЕЅнЁМЅКЄШЄЪЄыВшСќЄђЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзЁЃ
- ControlNet ЄђЭИњЄЫЁЃ
- ЅзЅъЅзЅэЅЛЅУЅЕМяЮрЄЧЁЂcanny(ЅЅуЅЫЁМ)БОЁЙЄђСЊТђЁЃ
- ЅзЅъЅзЅэЅЛЅУЅЕЄЮЅтЅЧЅыЄЧЁЂcannyБОЁЙЄђСЊТђЁЃ
АЪВМЄЮЅкЁМЅИЄЧЁЂ3МяЮрЄЮЦАКюЅЦЅЙЅШЪ§ЫЁЄЌОвВ№ЄЕЄьЄЦЄЄЄПЁЃ
_ControlNet - ЄШЄЗЄЂЄdiffusion Wiki*
3ШжЬмЄЮЁЂimg2img ЅПЅжОхЄЧЄЮ Inpaint upload ЄЯЁЂЄСЄчЄУЄШЅЯЅоЄУЄПЁЃInpaint upload ЄЫЄЯЁЂОхЄЫИЕВшСќЁЂВМЄЫЅоЅЙЅЏВшСќЁЂЄФЄоЄъ2ЄФЄЮВшСќЄђХЯЄЗЄЦЄфЄщЄЪЄЄЄШЄЄЄЋЄѓЄЮЄРЄЪЁФЁЃЅоЅЙЅЏВшСќЄРЄБЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзЄЗЄЦЁЂЛзЄУЄПФЬЄъЄЫЦАЄЋЄЪЄЄЄЪЄШЧКЄѓЄЧЄЗЄоЄУЄПЁЃ
Ё§ Openpose Editor ЄтЅЄЅѓЅЙЅШЁМЅы :
ЫшВѓЁЂИЕЅнЁМЅКЄШЄЪЄыВшСќЄђЄЩЄГЄЋЄЋЄщУЕЄЗЄЦЄЄЦЁЂControlNet ЄЫХЯЄЙЄЮЄЯЁЂЄСЄчЄУЄШЬЬХнНЄЄЁЃЧЄАеЄЮЅнЁМЅКЄђЛиФъЄЧЄЄыЄшЄІЄЫЄЪЄщЄЪЄЄЄтЄЮЄЋЁЃ
ЄНЄѓЄЪЛўЄЯЁЂOpenPose ЄШЄЄЄІЄтЄЮЄЌЛШЄЈЄыЄщЄЗЄЄЁЃOpenPoseЭбЄЮВшСќЄђФЏЄсЄыЄШЁЂЫРПЭДжЄУЄнЄЄЄтЄЮЄЌЩСЄЋЄьЄЦЄЄЄыЄБЄьЄЩЁЂПЇЄРЄЮЄЪЄѓЄРЄЮЄђЛШЄУЄЦЁЂЁжЄГЄГЄЌБІТЁзЁжЄГЄГЄЌКИЬмЁзЁжЄГЄГЄЌКИМЊЁзЄШИРЄУЄПДЖЄИЄЧПЭТЮЄЮЅнЁМЅКЄЌЛиФъЄЕЄьЄЦЄЄЄыЄЮЄРЄШЄЋЁЃ
ЄЪЄѓЄЧЄтЁЂControlNet + Openpose ЄЌСАНшЭ§ЄШЄЗЄЦЄфЄУЄЦЄЄЄыЄЮЄтЁЂИЕВшСќЄЋЄщЅнЁМЅКЄђУъНаЄЗЄЦ OpenPose ЄЫЄЙЄыНшЭ§ЄРЄНЄІЄЧЁФЁЃЄФЄоЄъЁЂЄНЄЮСАНшЭ§ЄђЁЂПЭДжЭЭЄЌЄфЄУЄЦЄЗЄоЄУЄПЄлЄІЄЌЯУЄЌСсЄЄЁЃЫшХйЫшХйЁЂИЕЅнЁМЅКВшСќЄђУЕЄЗЄЦЄЏЄыМъДжЄђОЪЄБЄыЁЃ
ЄНЄЮЁЂOpenPoseВшСќЄђКюЄыЄПЄсЄЮ Stable Diffusion web UIЭбГШФЅЕЁЧНЄЌЁЂOpenpose Editor ЄЪЄЮЄРЄШЄЋЁЃ
_GitHub - fkunn1326/openpose-editor: Openpose Editor for AUTOMATIC1111's stable-diffusion-webui
ЄШЄЄЄІЄГЄШЄЧЁЂЄГЄьЄтЅЄЅѓЅЙЅШЁМЅыЁЃЄГЄЮГШФЅЕЁЧНЄЫЄФЄЄЄЦЄЯЁЂgithub ЄЮURL ЄђЁЂStable Diffusion web UI ЄЮГШФЅЕЁЧНЅПЅжЄЧХНЄъЩеЄБЄЦЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЁЃ
ЄСЄЪЄпЄЫЁЂЅЄЅѓЅЙЅШЁМЅыЛўЄЫЅЈЅщЁМЄЯЩНМЈЄЕЄьЄЪЄЋЄУЄПЁЃ
ОЏЄЗЛШЄУЄЦЄпЄПЄБЄьЄЩЁЂЄПЄЗЄЋЄЫ OpenPose ЄЧЛиФъЄЗЄПЅнЁМЅКЄЌРИРЎВшСќЄЫЄтШПБЧЄЕЄьЄПЁЃ
ЄНЄѓЄЪЛўЄЯЁЂOpenPose ЄШЄЄЄІЄтЄЮЄЌЛШЄЈЄыЄщЄЗЄЄЁЃOpenPoseЭбЄЮВшСќЄђФЏЄсЄыЄШЁЂЫРПЭДжЄУЄнЄЄЄтЄЮЄЌЩСЄЋЄьЄЦЄЄЄыЄБЄьЄЩЁЂПЇЄРЄЮЄЪЄѓЄРЄЮЄђЛШЄУЄЦЁЂЁжЄГЄГЄЌБІТЁзЁжЄГЄГЄЌКИЬмЁзЁжЄГЄГЄЌКИМЊЁзЄШИРЄУЄПДЖЄИЄЧПЭТЮЄЮЅнЁМЅКЄЌЛиФъЄЕЄьЄЦЄЄЄыЄЮЄРЄШЄЋЁЃ
ЄЪЄѓЄЧЄтЁЂControlNet + Openpose ЄЌСАНшЭ§ЄШЄЗЄЦЄфЄУЄЦЄЄЄыЄЮЄтЁЂИЕВшСќЄЋЄщЅнЁМЅКЄђУъНаЄЗЄЦ OpenPose ЄЫЄЙЄыНшЭ§ЄРЄНЄІЄЧЁФЁЃЄФЄоЄъЁЂЄНЄЮСАНшЭ§ЄђЁЂПЭДжЭЭЄЌЄфЄУЄЦЄЗЄоЄУЄПЄлЄІЄЌЯУЄЌСсЄЄЁЃЫшХйЫшХйЁЂИЕЅнЁМЅКВшСќЄђУЕЄЗЄЦЄЏЄыМъДжЄђОЪЄБЄыЁЃ
ЄНЄЮЁЂOpenPoseВшСќЄђКюЄыЄПЄсЄЮ Stable Diffusion web UIЭбГШФЅЕЁЧНЄЌЁЂOpenpose Editor ЄЪЄЮЄРЄШЄЋЁЃ
_GitHub - fkunn1326/openpose-editor: Openpose Editor for AUTOMATIC1111's stable-diffusion-webui
ЄШЄЄЄІЄГЄШЄЧЁЂЄГЄьЄтЅЄЅѓЅЙЅШЁМЅыЁЃЄГЄЮГШФЅЕЁЧНЄЫЄФЄЄЄЦЄЯЁЂgithub ЄЮURL ЄђЁЂStable Diffusion web UI ЄЮГШФЅЕЁЧНЅПЅжЄЧХНЄъЩеЄБЄЦЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЁЃ
https://github.com/fkunn1326/openpose-editor.git
ЄСЄЪЄпЄЫЁЂЅЄЅѓЅЙЅШЁМЅыЛўЄЫЅЈЅщЁМЄЯЩНМЈЄЕЄьЄЪЄЋЄУЄПЁЃ
- ЅЄЅѓЅЙЅШЁМЅыЄЫРЎИљЄЙЄыЄШЁЂOpenpose Editor ЄШЄЄЄІЅПЅжЄЌС§ЄЈЄЦЄЄЄыЁЃ
- ЄНЄГЄЧЫРПЭДжЄЮГЦДиРсЄЮАЬУжЄђФДРАЄЗЄЦЁЂControlNet ЄЫВшСќЄђСїЄыЄГЄШЄЌЄЧЄЄыЁЃ
- ControlNet ТІЄЧЄЯЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЮМяЮрЄђЁжNone(ЄЪЄЗ)ЁзЄЫЁЃЅзЅъЅзЅэЅЛЅУЅЕЄЮЅтЅЧЅыЄђЁЂЁжopenposeЁзБОЁЙЄЫЄЙЄыЁЃ
ОЏЄЗЛШЄУЄЦЄпЄПЄБЄьЄЩЁЂЄПЄЗЄЋЄЫ OpenPose ЄЧЛиФъЄЗЄПЅнЁМЅКЄЌРИРЎВшСќЄЫЄтШПБЧЄЕЄьЄПЁЃ
Ё§ ЅжЅщЅІЅЖОхЄЧOpenposeВшСќЄђКюЄьЄыЅЕЁМЅгЅЙ :
Stable Diffusion web UI ЄЫГШФЅЕЁЧНЄђЅЄЅѓЅЙЅШЁМЅыЄЗЄЪЄЏЄЦЄтЁЂWebЅжЅщЅІЅЖОхЄЧ OpenPose ЄђКюЄьЄыЅЕЁМЅгЅЙЄЌЄЂЄыЄШУЮЄУЄПЄЮЄЧЅсЅтЁЃ
_3D Openpose Editor
_GitHub - ZhUyU1997/open-pose-editor: online 3d openpose editor for stable diffusion and controlnet
_GitHub - nonnonstop/sd-webui-3d-open-pose-editor: 3d openpose editor for stable diffusion and controlnet
_sd-webui-3d-open-pose-editor/README-ja.md at main - nonnonstop/sd-webui-3d-open-pose-editor - GitHub
_3D Openpose Editor
_GitHub - ZhUyU1997/open-pose-editor: online 3d openpose editor for stable diffusion and controlnet
_GitHub - nonnonstop/sd-webui-3d-open-pose-editor: 3d openpose editor for stable diffusion and controlnet
_sd-webui-3d-open-pose-editor/README-ja.md at main - nonnonstop/sd-webui-3d-open-pose-editor - GitHub
- ИЊЁЂЩЊЁЂЙјЁЂЩЈЁЂХљЁЙЄђЅЏЅъЅУЅЏЄЙЄыЄШЁЂx,y,zЄЮВѓХОМДЄђМЈЄЙБпЄЌЩНМЈЄЕЄьЄыЁЃ
- ЄНЄЮБпЄђЅЩЅщЅУЅАЄЗЄЦЄфЄыЄШЁЂГЦДиРсЄЮГбХйЄђЪбЙЙЄЧЄЄыЁЃ
- ЅнЁМЅКЄђКюЄУЄЦЁжРИРЎЄЙЄыЁзЄђЅЏЅъЅУЅЏЄЙЄыЄШЁЂВМЄЮЄлЄІЄЫВшСќЄЮЅЕЅрЅЭЅЄЅыЄЌЄЧЄЄыЁЃ
- ГЦЅЕЅрЅЭЅЄЅыЄђЅЏЅъЅУЅЏЄЙЄыЄШЁЂOpenPoseВшСќЄђЅРЅІЅѓЅэЁМЅЩЄЧЄЄыЁЃ
Ё§ ЭОУЬЁЃVRAMЄЌТЄъЄЪЄЏЄЪЄУЄЦЄЄП :
ControlNetЄђЅЄЅѓЅЙЅШЁМЅыЄЗЄПЄЛЄЄЄЪЄЮЄЋЁЂЄНЄьЄШЄтИЕЄЋЄщТЄъЄЪЄЋЄУЄПЄЮЄЋЪЌЄЋЄщЄЪЄЄЄБЄЩЁЂStable Diffusion web UI ЄЧВшСќЄђРИРЎЄЗЄшЄІЄШЄЙЄыЄШЁЂCUDA ЄЌ Out of memory ЄШИРЄУЄЦЄЏЄыЄГЄШЄЌТПЄЏЄЪЄУЄЦЄЄПЁЃЭзЄЙЄыЄЫЁЂЁжVRAMЄЌТЄъЄЪЄЄЄЋЄщЄГЄьАЪОхНшЭ§ЄЧЄЄЪЄЄЄшЁзЄШЁФЁЃЁжControlNetЄђЛШЄЊЄІЄШЄЙЄыЄШVRAMЄЌЙЙЄЫЩЌЭзЄЫЄЪЄыЁзЄШЄЄЄІЯУЄђЄЩЄГЄЋЄЧИЋЄЋЄБЄПЄБЄьЄЩЁЂЄфЄЯЄъ VRAM 6GB ЄЧЄЯИЗЄЗЄЄОьЬЬЄЌЄЂЄыЄщЄЗЄЄЁФЁЃ
ЦУЄЫЁЂHires.fix ЄђЛШЄІЄШЁЂЅсЅтЅъЄЌТЄъЄЪЄЄЄШИРЄяЄьЄЦЄЗЄоЄІЁЃЄЪЄЋЄЪЄЋИЗЄЗЄЄЁЃ
ЄСЄЪЄпЄЫЁЂVRAM ЄРЄБЄЧЄЯЄЪЄЏЁЂЅсЅЄЅѓЅсЅтЅъЄт16GBЄЧЄЯТЄъЄЪЄЄДЖЄИЄЌЄЗЄЦЄЄЄыЁЃЕЄЩеЄЄЄПЄщЁЂCЅЩЅщЅЄЅжЄЫЁЂpagefile.sys ЄЌ8.5GBЄлЄЩКюЄщЄьЄЦЄЄЄПЁЃЄФЄоЄъЁЂStable Diffusion web UI ЄђЛШЄУЄЦЄЄЄыЄІЄСЄЫЁЂ16GB + 8.5GB ЄлЄЩЄЮЅсЅтЅъЄЌЩЌЭзЄЫЄЪЄУЄПНжДжЄЌЄЂЄУЄПЁЂЄШЄЄЄІЄГЄШЄРЄэЄІЄЪЄШЁФЁЃ32GB ЄђКмЄЛЄЪЄЄЄШЅРЅсЄЋЄЪЁФЁЃ
ЦУЄЫЁЂHires.fix ЄђЛШЄІЄШЁЂЅсЅтЅъЄЌТЄъЄЪЄЄЄШИРЄяЄьЄЦЄЗЄоЄІЁЃЄЪЄЋЄЪЄЋИЗЄЗЄЄЁЃ
ЄСЄЪЄпЄЫЁЂVRAM ЄРЄБЄЧЄЯЄЪЄЏЁЂЅсЅЄЅѓЅсЅтЅъЄт16GBЄЧЄЯТЄъЄЪЄЄДЖЄИЄЌЄЗЄЦЄЄЄыЁЃЕЄЩеЄЄЄПЄщЁЂCЅЩЅщЅЄЅжЄЫЁЂpagefile.sys ЄЌ8.5GBЄлЄЩКюЄщЄьЄЦЄЄЄПЁЃЄФЄоЄъЁЂStable Diffusion web UI ЄђЛШЄУЄЦЄЄЄыЄІЄСЄЫЁЂ16GB + 8.5GB ЄлЄЩЄЮЅсЅтЅъЄЌЩЌЭзЄЫЄЪЄУЄПНжДжЄЌЄЂЄУЄПЁЂЄШЄЄЄІЄГЄШЄРЄэЄІЄЪЄШЁФЁЃ32GB ЄђКмЄЛЄЪЄЄЄШЅРЅсЄЋЄЪЁФЁЃ
[ ЅФЅУЅГЄр ]
#2 [zatta] МЋХОМжЭбЅиЅыЅсЅУЅШЄЌЄоЄРЧфЄУЄЦЄЪЄЄ
ЅлЁМЅрЅЛЅѓЅПЁМЅЕЅѓЅЧЁМЄЫДѓЄУЄЦЁЂТчПЭИўЄБЄЮМЋХОМжЭбЅиЅыЅсЅУЅШЄЌЧфЄУЄЦЄЪЄЄЄЋГЮЧЇЄЗЄЦЄЄПЄЮЄРЄБЄЩЁЂХЙЦЌЄЧЄЯАьЄФЄтЧфЄУЄЦЄЪЄЋЄУЄПЁЃ
АьБўЁЂУЊЄЫЄЯЁжТчПЭЭбЁзЄШЛЅЄтХНЄУЄЦЄЂЄУЄПЄЗЁЂЄяЄЖЄяЄЖЦўЄъИ§ЄЮЄЂЄПЄъЄЫЅиЅыЅсЅУЅШЧфЄъОьЄђАмЦАЄЗЄЦЄЄЄПЄЮЄЧЁЂ2023/04ЄЋЄщУхЭбЄЌХиЮЯЕСЬГЄЫЄЪЄУЄЦЄЄЄыЄГЄШЄђХЙТІЄтЧФАЎЄЗЄЦЄыЄУЄнЄЄЄЮЄРЄБЄЩЁФЁЃОІЩЪЄЌЬЕЄЄЄЮЄЧЄЯЄЪЄЂЁФЁЃ
ЄЩЄЮЄЏЄщЄЄЗаЄЦЄаЁЂКпИЫЄЌЩќГшЄЙЄыЄѓЄРЄэЄІЄЋЁЃ
АьБўЁЂУЊЄЫЄЯЁжТчПЭЭбЁзЄШЛЅЄтХНЄУЄЦЄЂЄУЄПЄЗЁЂЄяЄЖЄяЄЖЦўЄъИ§ЄЮЄЂЄПЄъЄЫЅиЅыЅсЅУЅШЧфЄъОьЄђАмЦАЄЗЄЦЄЄЄПЄЮЄЧЁЂ2023/04ЄЋЄщУхЭбЄЌХиЮЯЕСЬГЄЫЄЪЄУЄЦЄЄЄыЄГЄШЄђХЙТІЄтЧФАЎЄЗЄЦЄыЄУЄнЄЄЄЮЄРЄБЄЩЁФЁЃОІЩЪЄЌЬЕЄЄЄЮЄЧЄЯЄЪЄЂЁФЁЃ
ЄЩЄЮЄЏЄщЄЄЗаЄЦЄаЁЂКпИЫЄЌЩќГшЄЙЄыЄѓЄРЄэЄІЄЋЁЃ
[ ЅФЅУЅГЄр ]
2023/04/21(Жт) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] RemacriЄђStable Diffusion web UIЄЋЄщЭјЭб
AIЄђЭбЄЄЄПВшСќГШТчЅЂЅыЅДЅъЅКЅрЄЮУцЄЧЁЂRemacri ЄЌШцГгХЊЭЅНЈЄРЄЪЄШДЖЄИЄПЄЮЄРЄБЄЩЁЂЅАЅАЄУЄЦЄЄЄПЄщ Stable Diffusion web UI ЄЋЄщ Remacri ЄђЛШЄІЄГЄШЄтЄЧЄЄыЄШУЮЄУЄПЄЮЄЧЦГЦўЄЗЄЦЄпЄПЁЃ
_РЅЬОЄЗЄЈЄщ(sierra)@AIcomics. ... ЁжЃВМЁИЕГЈЄЊЄЙЄЙЄсЄЮЅЂЅУЅзЅЙЅБЁМЅщЁМЄЯlollypopЄЋRemacri... / Twitter
_Model Database - Upscale Wiki
ОхЕЄЮЅкЁМЅИЄЧЁЂЁжRemacriЁзЄЧИЁКїЄЙЄыЄШЁЂЁжRemacri Remacri Backup MirrorЁзЄШЄЄЄІЅъЅѓЅЏЄЌЄЂЄыЄЮЄЧЁЂЄЩЄСЄщЄЋЄЋЄщЅеЅЁЅЄЅыЄђЦўМъЁЃЩЌЭзЄЪЄЮЄЯЁЂАЪВМЄЮ2ЄФЁЃ
ЄФЄЄЄЧЄЫЁЂlollypop ЄШЄфЄщЄтЛюЄЗЄЦЄпЄПЄЋЄУЄПЄЮЄЧЁЂlollypop.pth ЄтЦўМъЁЃ
ЄНЄьЄщ .pth ЄђЁЂ(Stable Diffusion web UIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\models\ESRGAN\ АЪВМЄЫЅГЅдЁМЁЃ
ЄГЄьЄЧЁЂStable Diffusion web UI ЄЮЅкЁМЅИЄђWebЅжЅщЅІЅЖЄЋЄщГЋЄЄЄПКнЄЫЁЂExtras ХљЄЧ Upscaler ЄЮМяЮрЄШЄЗЄЦАЪВМЄђСЊЄйЄыЄшЄІЄЫЄЪЄУЄПЁЃ
ЄСЄЪЄпЄЫЁЂАЪВМЄЮЄфЄъМшЄъЄЮУцЄЧЁЂRemacri ЄЮНшЭ§ЗыВЬЄфЁЂТОЄЮЅЂЅыЅДЅъЅКЅрЄЫЄФЄЄЄЦОвВ№ЄЕЄьЄЦЄПЁЃПЇЁЙЄЪМяЮрЄЌЄЂЄыЄЮЄРЄЪЁФЁЃ
_Extensive Research of upscalers: Remacri has best results across the board, tested on 8 AI generated Images, details and ratings in comments : StableDiffusion
_РЅЬОЄЗЄЈЄщ(sierra)@AIcomics. ... ЁжЃВМЁИЕГЈЄЊЄЙЄЙЄсЄЮЅЂЅУЅзЅЙЅБЁМЅщЁМЄЯlollypopЄЋRemacri... / Twitter
_Model Database - Upscale Wiki
ОхЕЄЮЅкЁМЅИЄЧЁЂЁжRemacriЁзЄЧИЁКїЄЙЄыЄШЁЂЁжRemacri Remacri Backup MirrorЁзЄШЄЄЄІЅъЅѓЅЏЄЌЄЂЄыЄЮЄЧЁЂЄЩЄСЄщЄЋЄЋЄщЅеЅЁЅЄЅыЄђЦўМъЁЃЩЌЭзЄЪЄЮЄЯЁЂАЪВМЄЮ2ЄФЁЃ
- 4x_foolhardy_Remacri.pth
- 4x_foolhardy_Remacri_ExtraSmoother.pth
ЄФЄЄЄЧЄЫЁЂlollypop ЄШЄфЄщЄтЛюЄЗЄЦЄпЄПЄЋЄУЄПЄЮЄЧЁЂlollypop.pth ЄтЦўМъЁЃ
ЄНЄьЄщ .pth ЄђЁЂ(Stable Diffusion web UIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\models\ESRGAN\ АЪВМЄЫЅГЅдЁМЁЃ
ЄГЄьЄЧЁЂStable Diffusion web UI ЄЮЅкЁМЅИЄђWebЅжЅщЅІЅЖЄЋЄщГЋЄЄЄПКнЄЫЁЂExtras ХљЄЧ Upscaler ЄЮМяЮрЄШЄЗЄЦАЪВМЄђСЊЄйЄыЄшЄІЄЫЄЪЄУЄПЁЃ
- 4x_foolhardy_Remacri
- 4x_foolhardy_Remacri_ExtraSmoother
- lollypop
ЄСЄЪЄпЄЫЁЂАЪВМЄЮЄфЄъМшЄъЄЮУцЄЧЁЂRemacri ЄЮНшЭ§ЗыВЬЄфЁЂТОЄЮЅЂЅыЅДЅъЅКЅрЄЫЄФЄЄЄЦОвВ№ЄЕЄьЄЦЄПЁЃПЇЁЙЄЪМяЮрЄЌЄЂЄыЄЮЄРЄЪЁФЁЃ
_Extensive Research of upscalers: Remacri has best results across the board, tested on 8 AI generated Images, details and ratings in comments : StableDiffusion
[ ЅФЅУЅГЄр ]
2023/04/22(Хк) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] canvas-zoomЄђЛюЭб
ВшСќРИРЎAIЁЂStable Diffusion web UI ОхЄЧЁЂimg2img ЄЮ inpaintХљЄђЛШЄІКнЁЂЅоЅЙЅЏЩєЪЌЄђХЩЄУЄЦЄЄЄЏЄЮЄЌЅЗЅѓЅЩЅЄЁЃВшСќЄЌХљЧмЩНМЈЄЫЄЪЄУЄЦЄЄЄыЄЮЄЧЁЂКйЄЋЄЄЄШЄГЄэЄђХЩЄъЪЌЄБЄыЄЮЄЌЄСЄчЄУЄШЦёЄЗЄЏЄЦЁЃ
КЃЄоЄЧЄЯЁЂWindows10ЄЮГШТчЖРЄђЭјЭбЄЗЄЦЁЂОЏЄЗЄЯВўСБЄЧЄЄЪЄЄЄЋЄШЛюЄЗЄЦЄЄЄПЄЮЄРЄБЄЩЁФЁЃStable Diffusion web UIЄЮГШФЅЕЁЧНЄШЄЗЄЦЁЂcanvas-zoom ЄШЄЄЄІЄтЄЮЄЌЄЂЄыЄШУЮЄУЄПЄЮЄЧЦГЦўЄЗЄЦЄпЄПЁЃ
_canvas-zoom - work4ai
_GitHub - richrobber2/canvas-zoom: zoom and pan functionality
ЅЄЅѓЅЙЅШЁМЅыЄЯЁЂStable Diffusion web UIЄЮГШФЅЕЁЧНАьЭїЄЋЄщСЊТђЁЃ
КЧФуИТЄЮЛШЄЄЪ§ЄЯАЪВМЁЃ
ЄГЄьЄРЄБЄЧЄтПяЪЌЄШКюЖШЄЌГкЄЫЄЪЄУЄПЁЃ
КЃЄоЄЧЄЯЁЂWindows10ЄЮГШТчЖРЄђЭјЭбЄЗЄЦЁЂОЏЄЗЄЯВўСБЄЧЄЄЪЄЄЄЋЄШЛюЄЗЄЦЄЄЄПЄЮЄРЄБЄЩЁФЁЃStable Diffusion web UIЄЮГШФЅЕЁЧНЄШЄЗЄЦЁЂcanvas-zoom ЄШЄЄЄІЄтЄЮЄЌЄЂЄыЄШУЮЄУЄПЄЮЄЧЦГЦўЄЗЄЦЄпЄПЁЃ
_canvas-zoom - work4ai
_GitHub - richrobber2/canvas-zoom: zoom and pan functionality
ЅЄЅѓЅЙЅШЁМЅыЄЯЁЂStable Diffusion web UIЄЮГШФЅЕЁЧНАьЭїЄЋЄщСЊТђЁЃ
КЧФуИТЄЮЛШЄЄЪ§ЄЯАЪВМЁЃ
- Shift + ЅлЅЄЁМЅыВѓХО : ЅЅуЅѓЅаЅЙЄЮЅКЁМЅрЅЄЅѓ/ЅКЁМЅрЅЂЅІЅШЁЃ
- SHift + УцЅЩЅщЅУЅА (ЅлЅЄЁМЅыЅмЅПЅѓЄЧЅЩЅщЅУЅА) : ЅЅуЅѓЅаЅЙЄЮЩНМЈАЬУжЄђАмЦАЁЃ
- R : ЅКЁМЅрЮЈЄђЅъЅЛЅУЅШЁЃ
ЄГЄьЄРЄБЄЧЄтПяЪЌЄШКюЖШЄЌГкЄЫЄЪЄУЄПЁЃ
Ё§ 2023/04/24ФЩЕЁЃ :
ЅЗЅчЁМЅШЅЋЅУЅШЅЁМЄЫЄФЄЄЄЦЁЂЄтЄІОЏЄЗЅсЅтЄђФЩВУЁЃ
- Shift + ЅЦЅѓЅЁМЄЮЁж+Ёз/Ёж-Ёз : ЅКЁМЅрЅЄЅѓ/ЅКЁМЅрЅЂЅІЅШЁЃ
- Ctrl + ЅлЅЄЁМЅыВѓХО : ЅжЅщЅЗЅЕЅЄЅКЪбЙЙЁЃ
- A : ЅЋЅщЁМЅдЅУЅЋЁМ(ПЇМшЦРЅФЁМЅы)ЄиЄЮРкЄъТиЄЈЁЃЅоЅІЅЙЅЋЁМЅНЅыЄЌННЛњЄЫЄЪЄыЄЮЄЧЁЂПЇЄђМшЦРЄЗЄПЄЄЩєЪЌЄђЅЏЅъЅУЅЏЄЙЄыЁЃ
[ ЅФЅУЅГЄр ]
2023/04/23(Цќ) [nЧЏСАЄЮЦќЕ]
#1 [pc] SSDЄЮЁж5184ЛўДжЬфТъЁз
Windows10 x64 22H2ЄђЦАЄЋЄЗЄЦЄЄЄыЅсЅЄЅѓPCЄЌЁЂЄоЄПЅжЅыЁМЅЙЅЏЅъЁМЅѓ(BSOD)ЄЫЄЪЄУЄЦЁЂЄГЄьЄЯЄфЄЯЄъSSDЄЌЄЊЄЋЄЗЄЄЄЮЄРЄэЄІЄЋЄШДиЯЂО№ЪѓЄђЅАЅАЄУЄЦЄЄЄПЄШЄГЄэЁЂЁж5184ЛўДжЬфТъЁзЄШЄЄЄІЄтЄЮЄЌЄЂЄыЄШКЃКЂЄЫЄЪЄУЄЦУЮЄУЄПЄЮЄЧЅсЅтЁЃ
_5184ЛўДжЬфТъЁЪCrucial M4 SSDЁЫЁЇUTAN1985BLOG
_ЁкНХЭзЁлCrucial m4ЄЫЩдЖёЙч 5184ЛўДж ЬфТъ : ЄщЄЄЄУЄСЄЮPCЪГЦЎЕ
_BSODЄЮИЕЖЇЄЯ5184ЛўДж ЬфТъ(Crucial m4 SSD/FirmwareЄЮЩдЖёЙч): Automatic
CrucialРНSSDЄЫЄЊЄЄЄЦЄЯЁЂЛШЭбЛўДжЄЌ5184ЛўДжЄђВсЄЎЄыЄШЁЂ1ЛўДжЫшЄЫБўХњЄЌФфЛпЄЙЄыЁЂЄШЄЄЄІЩдЖёЙчЄЌЄЂЄыЄНЄІЄЧЁЃ
ЕЄЄЫЄЪЄУЄЦЁЂМЋЪЌЄЌЛШЄУЄЦЄЄЄы crucial MX500 CT500MX500SSD1/JP (ЅеЅЁЁМЅрЅІЅЇЅЂ M3CR023) ЄЮЛШЭбЛўДжЄђЁЂCrystalDiskInfo 8.17.14 x64 ЄЧФДЄйЄЦЄпЄПЄщЁЂ5700ЛўДжЄђФЖЄЈЄЦЄПЁЃЄоЄЕЄЋЁЂЄГЄьЄЋЁЃЄГЄьЄЪЄЮЄЋЁЃЄГЄьЄЌЅжЅыЁМЅЙЅЏЅъЁМЅѓЄЮИЖАјЄЪЄЮЄЧЄЯЁЃ
ЄПЄРЁЂЗяЄЮЬфТъЄЯЁЂCrusial M4 Єф Micron C400 ЄШЄЄЄУЄПРНЩЪЄЮЁЂЦУФъЄЮЅеЅЁЁМЅрЅІЅЇЅЂЅаЁМЅИЅчЅѓЄЧШЏРИЄЙЄыЬфТъЄЮЄшЄІЄЧЁФЁЃMX500 ЄЯЁЂЄЊЄНЄщЄЏГКХіЄЗЄЪЄЄРНЩЪЄРЄшЄЪЁФЁЃЅеЅЁЁМЅрЅІЅЇЅЂЅаЁМЅИЅчЅѓЄтСДСГАуЄІЩНЕЄРЄЗЁФЁЃЄНЄьЄЫЁЂ2014ЧЏЄШЄЋ2015ЧЏКЂЄЫЕЏЄЄЦЄПЬфТъЄЮЄшЄІЄЧЄтЄЂЄыЄЗЁФЁЃ
ЄтЄУЄШЄтЁЂSSDЄШЄЄЄІЄЮЄЯЁЂРНТЄЛўДќЄЫЄшЄУЄЦУцПШЄЌСДЄЏАуЄУЄЦЄЄЄПЄъЄЙЄыЄНЄІЄРЄЋЄщЁЂРЮЄЯТчОцЩзЄЪРНЩЪЄРЄУЄПЄБЄЩЁЂЖсЧЏЄЯЬфТъЄђЪњЄЈЄЦЄЄЄыРНЩЪЄЫЄГЄУЄНЄъЪбЄяЄУЄЦЄЄЄЦЄтЄЊЄЋЄЗЄЏЄЪЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄЄЋЁФЁЃ
ЄНЄьЄЫЄЗЄЦЄтЁЂЄГЄЮМъЄЮЬфТъЄЌШЏГаЄЙЄыЄоЄЧЁЂ5000ЛўДжЄлЄЩЄЋЄЋЄыЄЮЄЯИЗЄЗЄЄЯУЄРЄЪЄШЁЃВОЄЫ24ЛўДжЦАЄЋЄЗТГЄБЄПЄШЄЗЄЦЄт216ЦќЁЂ1Цќ10ЛўДжЄлЄЩЦАЄЋЄЙЄШЄЗЄЦЄт1ЧЏШОФјХйЄЯВПЄЮЬфТъЄтЬЕЄЏЦАЄЄЄЦЄЗЄоЄІЄЮЄЧЄЂЄэЄІЄЗЁЃМТЄЯЩдЖёЙчЄЌЄЂЄыРНЩЪЄЪЄЮЄРЄШЪЌЄЋЄыЄоЄЧЗыЙНЛўДжЄЌЄЋЄЋЄУЄЦЄЗЄоЄІЁЃЬЬХнЄРЄЪЄШЁФЁЃ
_5184ЛўДжЬфТъЁЪCrucial M4 SSDЁЫЁЇUTAN1985BLOG
_ЁкНХЭзЁлCrucial m4ЄЫЩдЖёЙч 5184ЛўДж ЬфТъ : ЄщЄЄЄУЄСЄЮPCЪГЦЎЕ
_BSODЄЮИЕЖЇЄЯ5184ЛўДж ЬфТъ(Crucial m4 SSD/FirmwareЄЮЩдЖёЙч): Automatic
CrucialРНSSDЄЫЄЊЄЄЄЦЄЯЁЂЛШЭбЛўДжЄЌ5184ЛўДжЄђВсЄЎЄыЄШЁЂ1ЛўДжЫшЄЫБўХњЄЌФфЛпЄЙЄыЁЂЄШЄЄЄІЩдЖёЙчЄЌЄЂЄыЄНЄІЄЧЁЃ
ЕЄЄЫЄЪЄУЄЦЁЂМЋЪЌЄЌЛШЄУЄЦЄЄЄы crucial MX500 CT500MX500SSD1/JP (ЅеЅЁЁМЅрЅІЅЇЅЂ M3CR023) ЄЮЛШЭбЛўДжЄђЁЂCrystalDiskInfo 8.17.14 x64 ЄЧФДЄйЄЦЄпЄПЄщЁЂ5700ЛўДжЄђФЖЄЈЄЦЄПЁЃЄоЄЕЄЋЁЂЄГЄьЄЋЁЃЄГЄьЄЪЄЮЄЋЁЃЄГЄьЄЌЅжЅыЁМЅЙЅЏЅъЁМЅѓЄЮИЖАјЄЪЄЮЄЧЄЯЁЃ
ЄПЄРЁЂЗяЄЮЬфТъЄЯЁЂCrusial M4 Єф Micron C400 ЄШЄЄЄУЄПРНЩЪЄЮЁЂЦУФъЄЮЅеЅЁЁМЅрЅІЅЇЅЂЅаЁМЅИЅчЅѓЄЧШЏРИЄЙЄыЬфТъЄЮЄшЄІЄЧЁФЁЃMX500 ЄЯЁЂЄЊЄНЄщЄЏГКХіЄЗЄЪЄЄРНЩЪЄРЄшЄЪЁФЁЃЅеЅЁЁМЅрЅІЅЇЅЂЅаЁМЅИЅчЅѓЄтСДСГАуЄІЩНЕЄРЄЗЁФЁЃЄНЄьЄЫЁЂ2014ЧЏЄШЄЋ2015ЧЏКЂЄЫЕЏЄЄЦЄПЬфТъЄЮЄшЄІЄЧЄтЄЂЄыЄЗЁФЁЃ
ЄтЄУЄШЄтЁЂSSDЄШЄЄЄІЄЮЄЯЁЂРНТЄЛўДќЄЫЄшЄУЄЦУцПШЄЌСДЄЏАуЄУЄЦЄЄЄПЄъЄЙЄыЄНЄІЄРЄЋЄщЁЂРЮЄЯТчОцЩзЄЪРНЩЪЄРЄУЄПЄБЄЩЁЂЖсЧЏЄЯЬфТъЄђЪњЄЈЄЦЄЄЄыРНЩЪЄЫЄГЄУЄНЄъЪбЄяЄУЄЦЄЄЄЦЄтЄЊЄЋЄЗЄЏЄЪЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄЄЋЁФЁЃ
ЄНЄьЄЫЄЗЄЦЄтЁЂЄГЄЮМъЄЮЬфТъЄЌШЏГаЄЙЄыЄоЄЧЁЂ5000ЛўДжЄлЄЩЄЋЄЋЄыЄЮЄЯИЗЄЗЄЄЯУЄРЄЪЄШЁЃВОЄЫ24ЛўДжЦАЄЋЄЗТГЄБЄПЄШЄЗЄЦЄт216ЦќЁЂ1Цќ10ЛўДжЄлЄЩЦАЄЋЄЙЄШЄЗЄЦЄт1ЧЏШОФјХйЄЯВПЄЮЬфТъЄтЬЕЄЏЦАЄЄЄЦЄЗЄоЄІЄЮЄЧЄЂЄэЄІЄЗЁЃМТЄЯЩдЖёЙчЄЌЄЂЄыРНЩЪЄЪЄЮЄРЄШЪЌЄЋЄыЄоЄЧЗыЙНЛўДжЄЌЄЋЄЋЄУЄЦЄЗЄоЄІЁЃЬЬХнЄРЄЪЄШЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/24(Зю) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] ВшСќРИРЎAIЄЧУхПЇНшЭ§ЄђЄЗЄПЄЄ
ВшСќРИРЎAIЁЂStable Diffusion web UIЄђЛШЄУЄЦЁЂРўВшЄЫУхПЇНшЭ§ЄђЄЗЄЦЄпЄПЄЄЁЃ
ДФЖЄЯАЪВМЁЃ
УхПЇНшЭ§ЄђЄЙЄыЄЫЄЯЁЂControlNet Єђ Stable Diffusion web UI ЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЊЄЏЩЌЭзЄЌЄЂЄыЄщЄЗЄЄЁЃ
ControlNetЭбЄЮЁЂcanny ЄЋ Anime Lineart ЄЮФЩВУЅЧЁМЅПЄЌЩЌЭзЄщЄЗЄЄЄЮЄЧЁЂЄНЄьЄтЦўМъЄЗЄЦЁЂ(Stable Diffusion web UIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\extensions\sd-webui-controlnet\models\ АЪВМЄЫЅГЅдЁМЄЗЄЦЄЊЄЏЁЃ
ДФЖЄЯАЪВМЁЃ
- OS : Windows10 x64 22H2
- CPU : AMD Ryzen 5 5600X
- RAM : 16GB
- GPU : NVIDIA GeForce GTX 1060 6GB
УхПЇНшЭ§ЄђЄЙЄыЄЫЄЯЁЂControlNet Єђ Stable Diffusion web UI ЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЊЄЏЩЌЭзЄЌЄЂЄыЄщЄЗЄЄЁЃ
ControlNetЭбЄЮЁЂcanny ЄЋ Anime Lineart ЄЮФЩВУЅЧЁМЅПЄЌЩЌЭзЄщЄЗЄЄЄЮЄЧЁЂЄНЄьЄтЦўМъЄЗЄЦЁЂ(Stable Diffusion web UIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\extensions\sd-webui-controlnet\models\ АЪВМЄЫЅГЅдЁМЄЗЄЦЄЊЄЏЁЃ
Ё§ РўВшЄђРИРЎЄЗЄЦЄпЄы :
УхПЇНшЭ§ЄђЄЙЄыЄПЄсЄЫЄЯРўВшЄЌЩЌЭзЄРЄБЄЩЁЂРўВшЄт Stable Diffusion web UI ЄЧРИРЎЄЧЄЄЦЄЗЄоЄІЄщЄЗЄЄЁЃ
_ЁкВшСќРИРЎAIЁлРўВшЩСВшLoRAЄђЛШЄЊЄІЁЊЁЪAnime Lineart Style LoRAЁЫЁУЅЙЅЦЅЙЅэЅЙЁУnote
_ЁкStable DiffusionЁлРўВшЄђРИРЎЄЧЄЄыLoRA | ЅИЅГЅэЅА
_Anime Lineart / Manga-like (...) Style - v3.0 manga-like | Stable Diffusion LoRA | Civitai
_andite/anything-v4.0 - Hugging Face
Anime Lineart / Manga-like Style ЄШЄЄЄІLORAЅЧЁМЅП(ФЩВУГиНЌЅтЅЧЅыЅЧЁМЅП)ЄЌЄЂЄьЄаЁЂРўВшЄЮРИРЎЄЌЄЧЄЄыЬЯЭЭЁЃ
ЄГЄЮLORAЄЯЁЂГиНЌЅтЅЧЅыЅЧЁМЅПЁЂAnything V4.5 ЄЫКЧХЌВНЄЗЄЦЄЄЄыЄШЄЮЄГЄШЄЪЄЮЄЧЁЂЄНЄСЄщЄЮЅтЅЧЅыЅЧЁМЅПЄтЦўМъЄЙЄыЁЃЄФЄоЄъЁЂАЪВМЄЮЅеЅЁЅЄЅыЄђDLЄЙЄыЄГЄШЄЫЄЪЄыЁЃ
Stable Diffusion web UI ЄђЕЏЦАЄЗЄЦЁЂАЪВМЄЮЅтЅЧЅыЅЧЁМЅПЁЂVAEЄЫЄЗЄЦЄЊЄЏЁЃ
ЄШЄъЄЂЄЈЄКЁЂtxt2imgОхЄЧЁЂРИРЎЄЧЄЄыЄЋЅЦЅЙЅШЁЃ

ЅеЅФЁМЄЫПЇЄЌЄФЄЄЄЦЄыОѕТжЄЧРИРЎЄЕЄьЄПЁЃ
Anime Lineart Style ЄђЭИњЄЫЄЗЄЦРўВшЄЌРИРЎЄЕЄьЄыЄЋГЮЧЇЄЗЄЦЄпЄыЁЃЅзЅэЅѓЅзЅШЄЫ <lora:animeLineartMangaLike_v30MangaLike:1> ЄђЦўЄьЄЦЭИњВНЁЃЄЋЄФЁЂЅШЅъЅЌЁМЅяЁМЅЩЄЮ lineart ЄђЦўЄьЄЦЄпЄПЁЃ

ЄЕЄЙЄЌЄЫЙНПоХљЄЯЪбЄяЄУЄЦЄЗЄоЄУЄПЄБЄЩЁЂЄсЄУЄСЄуРўВшЄУЄнЄЏЄЪЄУЄПЁЃ
ВПХйЄЋРИРЎЄЗЄЦЄпЄПЄБЄЩЁЂЄЩЄьЄтЅЄЅЄДЖЄИЁЃЄШЄъЄЂЄЈЄКЁЂКЃВѓЄЯАЪВМЄЮРИРЎВшСќЄђЛШЄУЄЦУхПЇНшЭ§ЄђЄЗЄЦЄпЄПЄЄЁЃ

_ЁкВшСќРИРЎAIЁлРўВшЩСВшLoRAЄђЛШЄЊЄІЁЊЁЪAnime Lineart Style LoRAЁЫЁУЅЙЅЦЅЙЅэЅЙЁУnote
_ЁкStable DiffusionЁлРўВшЄђРИРЎЄЧЄЄыLoRA | ЅИЅГЅэЅА
_Anime Lineart / Manga-like (...) Style - v3.0 manga-like | Stable Diffusion LoRA | Civitai
_andite/anything-v4.0 - Hugging Face
Anime Lineart / Manga-like Style ЄШЄЄЄІLORAЅЧЁМЅП(ФЩВУГиНЌЅтЅЧЅыЅЧЁМЅП)ЄЌЄЂЄьЄаЁЂРўВшЄЮРИРЎЄЌЄЧЄЄыЬЯЭЭЁЃ
ЄГЄЮLORAЄЯЁЂГиНЌЅтЅЧЅыЅЧЁМЅПЁЂAnything V4.5 ЄЫКЧХЌВНЄЗЄЦЄЄЄыЄШЄЮЄГЄШЄЪЄЮЄЧЁЂЄНЄСЄщЄЮЅтЅЧЅыЅЧЁМЅПЄтЦўМъЄЙЄыЁЃЄФЄоЄъЁЂАЪВМЄЮЅеЅЁЅЄЅыЄђDLЄЙЄыЄГЄШЄЫЄЪЄыЁЃ
- anything-v4.5.safetensors : (Stable Diffusion web UIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\models\Stable-diffusion\ ЄЫЅГЅдЁМЁЃ
- anything-v4.0.vae.pt : (Stable Diffusion web UIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\models\VAE\ ЄЫЅГЅдЁМЁЃ
- animeLineartMangaLike_v30MangaLike.safetensors : (Stable Diffusion web UIЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР)\models\Lora\ ЄЫЅГЅдЁМЁЃ
Stable Diffusion web UI ЄђЕЏЦАЄЗЄЦЁЂАЪВМЄЮЅтЅЧЅыЅЧЁМЅПЁЂVAEЄЫЄЗЄЦЄЊЄЏЁЃ
- ГиНЌЅтЅЧЅыЅЧЁМЅП : anything-v4.5.safetensors
- VAE : anything-v4.0.vae.pt
ЄШЄъЄЂЄЈЄКЁЂtxt2imgОхЄЧЁЂРИРЎЄЧЄЄыЄЋЅЦЅЙЅШЁЃ
1 girl, city background, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3871747518, Size: 512x512, Model hash: 1d1e459f9f, Model: anything-v4.5
ЅеЅФЁМЄЫПЇЄЌЄФЄЄЄЦЄыОѕТжЄЧРИРЎЄЕЄьЄПЁЃ
Anime Lineart Style ЄђЭИњЄЫЄЗЄЦРўВшЄЌРИРЎЄЕЄьЄыЄЋГЮЧЇЄЗЄЦЄпЄыЁЃЅзЅэЅѓЅзЅШЄЫ <lora:animeLineartMangaLike_v30MangaLike:1> ЄђЦўЄьЄЦЭИњВНЁЃЄЋЄФЁЂЅШЅъЅЌЁМЅяЁМЅЩЄЮ lineart ЄђЦўЄьЄЦЄпЄПЁЃ
1 girl, city background, <lora:animeLineartMangaLike_v30MangaLike:1>, lineart, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3871747518, Size: 512x512, Model hash: 1d1e459f9f, Model: anything-v4.5
ЄЕЄЙЄЌЄЫЙНПоХљЄЯЪбЄяЄУЄЦЄЗЄоЄУЄПЄБЄЩЁЂЄсЄУЄСЄуРўВшЄУЄнЄЏЄЪЄУЄПЁЃ
ВПХйЄЋРИРЎЄЗЄЦЄпЄПЄБЄЩЁЂЄЩЄьЄтЅЄЅЄДЖЄИЁЃЄШЄъЄЂЄЈЄКЁЂКЃВѓЄЯАЪВМЄЮРИРЎВшСќЄђЛШЄУЄЦУхПЇНшЭ§ЄђЄЗЄЦЄпЄПЄЄЁЃ
1 girl, school uniform, upper body, in room, from side, <lora:animeLineartMangaLike_v30MangaLike:1.0>, lineart, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 40, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 2228530729, Size: 512x512, Model hash: 1d1e459f9f, Model: anything-v4.5
Ё§ УхПЇНшЭ§ :
ЦРЄщЄьЄПРўВшЄђИЕЄЫЄЗЄЦЁЂУхПЇНшЭ§ЄђЛюЄЗЄЦЄпЄыЁЃАЪВМЄЮЅкЁМЅИЄЌЛВЙЭЄЫЄЪЄУЄПЁЃ
_ЁжControlNetЁзЄЮЁиopenposeЁйЄШЁиcannyЁйЄђУЮЄУЄЦЄЗЄоЄУЄПВѓЁЃЁкStable Diffusion web UIЁл | note_lilish
_ЁкControlNetЁлМЋЪЌЄЮКюВшЄђAIЄЧМЋЦАУхКЬЁЊcannyЄђДЎЧНЄЗЄоЄЏЄУЄПВѓЁЃЁЪStable DiffusionЁЫ | note_lilish
_AIЄЧХЌХіЄЪРўВшЄђРЖНёЄЗЁЂЄЕЄщЄЫПЇЄђХЩЄУЄЦЙтЩЪМСЄЪЅЄЅщЅЙЅШЄЫЛХОхЄВЄыЪ§ЫЁЁкControlNetГшЭбНбЁл | ЄЏЄэЄЏЄоЄНЄеЄШ
txt2imgЅПЅжЄЧЁЂControlNet ЄЮВшСќЦўЮЯЭѓЄЫЁЂРшЄлЄЩРИРЎЄЗЄПРўВшЄђЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзЁЃ
РўВшЄЌЁЂРўЄЌЙѕЁЂЧиЗЪЄЌЧђЄЮОьЙчЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЧЁЂinvert ЄђСЊЄѓЄЧЧђЙѕЄђШПХОЄЙЄыЩЌЭзЄЌЄЂЄыЄщЄЗЄЄЁЃЫмЭшЁЂControlNet ЄЫЄЯЁЂЧиЗЪВшЄЌЙѕЁЂРўЄЌЧђЄђХЯЄЕЄЪЄЄЄШЄЄЄЋЄѓЄшЄІЄРЄЪЄШЁФЁЃЄПЄРЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЧ canny ЄђСЊЄѓЄРОьЙчЄтЁЂЄНЄьЄщЄЗЄЄЗыВЬЄђРИРЎЄЧЄЄПЁЃ
АЪВМЄЯЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЧЁжcannyЁзЄђСЊЄѓЄРОьЙчЁЃ

АЪВМЄЯЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЧЁжinvertЁзЄђСЊЄѓЄРОьЙчЁЃ

ЄШЄЄЄІЄГЄШЄЧЁЂStable Diffusion web UI + ControlNet + cannyЅтЅЧЅыЅЧЁМЅПЄђЛШЄУЄЦЁЂРўВшЄЫУхПЇЄЧЄЄыЄГЄШЄЌЄяЄЋЄУЄПЁЃ
_ЁжControlNetЁзЄЮЁиopenposeЁйЄШЁиcannyЁйЄђУЮЄУЄЦЄЗЄоЄУЄПВѓЁЃЁкStable Diffusion web UIЁл | note_lilish
_ЁкControlNetЁлМЋЪЌЄЮКюВшЄђAIЄЧМЋЦАУхКЬЁЊcannyЄђДЎЧНЄЗЄоЄЏЄУЄПВѓЁЃЁЪStable DiffusionЁЫ | note_lilish
_AIЄЧХЌХіЄЪРўВшЄђРЖНёЄЗЁЂЄЕЄщЄЫПЇЄђХЩЄУЄЦЙтЩЪМСЄЪЅЄЅщЅЙЅШЄЫЛХОхЄВЄыЪ§ЫЁЁкControlNetГшЭбНбЁл | ЄЏЄэЄЏЄоЄНЄеЄШ
txt2imgЅПЅжЄЧЁЂControlNet ЄЮВшСќЦўЮЯЭѓЄЫЁЂРшЄлЄЩРИРЎЄЗЄПРўВшЄђЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзЁЃ
- ControlNetЄђЭИњВНЁЃ
- ЅзЅъЅзЅэЅЛЅУЅЕ (Preprocessor) : invert (from white bg & black line)ЁЂЄтЄЗЄЏЄЯ canny
- ЅтЅЧЅы (Model) : control_v11p_sd15_canny
РўВшЄЌЁЂРўЄЌЙѕЁЂЧиЗЪЄЌЧђЄЮОьЙчЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЧЁЂinvert ЄђСЊЄѓЄЧЧђЙѕЄђШПХОЄЙЄыЩЌЭзЄЌЄЂЄыЄщЄЗЄЄЁЃЫмЭшЁЂControlNet ЄЫЄЯЁЂЧиЗЪВшЄЌЙѕЁЂРўЄЌЧђЄђХЯЄЕЄЪЄЄЄШЄЄЄЋЄѓЄшЄІЄРЄЪЄШЁФЁЃЄПЄРЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЧ canny ЄђСЊЄѓЄРОьЙчЄтЁЂЄНЄьЄщЄЗЄЄЗыВЬЄђРИРЎЄЧЄЄПЁЃ
АЪВМЄЯЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЧЁжcannyЁзЄђСЊЄѓЄРОьЙчЁЃ
1 girl, school uniform, upper body, in room, from side, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 40, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 1628600786, Size: 512x512, Model hash: 1d1e459f9f, Model: anything-v4.5, ControlNet Enabled: True, ControlNet Module: canny, ControlNet Model: control_v11p_sd15_canny [d14c016b], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1
АЪВМЄЯЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЧЁжinvertЁзЄђСЊЄѓЄРОьЙчЁЃ
1 girl, school uniform, upper body, in room, from side, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 40, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 2086267769, Size: 512x512, Model hash: 1d1e459f9f, Model: anything-v4.5, ControlNet Enabled: True, ControlNet Module: invert (from white bg & black line), ControlNet Model: control_v11p_sd15_canny [d14c016b], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1
ЄШЄЄЄІЄГЄШЄЧЁЂStable Diffusion web UI + ControlNet + cannyЅтЅЧЅыЅЧЁМЅПЄђЛШЄУЄЦЁЂРўВшЄЫУхПЇЄЧЄЄыЄГЄШЄЌЄяЄЋЄУЄПЁЃ
Ё§ МТМЬДѓЄъЄЫЄЗЄЦЄпЄПЄЄ :
ЄЛЄУЄЋЄЏЄРЄЋЄщЁЂЄГЄГЄЋЄщМТМЬДѓЄъЄЮВшСќЄђРИРЎЄЧЄЄыЄЋЛюЄЗЄЦЄпЄПЄЄЁЃГиНЌЅтЅЧЅыЅЧЁМЅПЄђМТМЬДѓЄъЄЮЅЧЁМЅПЄЫРкЄъТиЄЈЄЦЄпЄыЁЃ
txt2imgЅПЅжОхЄЧКюЖШЄЙЄыЁЃControlNet ЄЫЁЂСАНвЄЮРўВшЄђХЯЄЗЄЦЄЊЄЄЄЦЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЧЁжcannyЁзЄђСЊЄѓЄЧЄпЄПЁЃ

ЬЁВшХЊЄЪРўВшЄЫАњЄРЂЄщЄьЄЦЄЗЄоЄУЄПЄЮЄЋЁЂЅЅтЄЄДЖЄИЄЮВшСќЄЌРИРЎЄЕЄьЄЦЄЗЄоЄУЄПЁФЁЃЄГЄьЄЯЄГЄьЄЧЅЂЅъЄЪГЈЪСЄЪЄЮЄЋЄтЄЗЄьЄѓЄБЄЩЁФЁЃ
ЅзЅъЅзЅэЅЛЅУЅЕЄђЁжinvertЁзЄЫЄЗЄЦЄпЄПЁЃ


ЄГЄСЄщЄЯЄЪЄЋЄЪЄЋЅЄЅЄДЖЄИЄЪЄЮЄЧЄЯЄЪЄЋЄэЄІЄЋЁЃ
ЄПЄРЁЂЄГЄГЄоЄЧЭшЄыЄШЁЂimg2imgЅПЅжОхЄЧНшЭ§ЄЗЄПЄлЄІЄЌЮЩЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃАЪВМЄЯЁЂimg2img ЄЫУхПЇКбЄпВшСќЄђХЯЄЗЄЦРИРЎЄЗЄЦЄпЄПЛіЮуЁЃИЕЄЮРўВшЄЋЄщЗыЙНЄЋЄБЮЅЄьЄЦЄЗЄоЄУЄПЄБЄЩЁЂИЋЄПЬмЄЯПяЪЌМЋСГЄЪДЖЄИЄЫЄЪЄУЄПЁЃ

- Model : chilloutmix_.safetensors
- VAE : vae-ft-mse-840000-ema-pruned.safetensors
txt2imgЅПЅжОхЄЧКюЖШЄЙЄыЁЃControlNet ЄЫЁЂСАНвЄЮРўВшЄђХЯЄЗЄЦЄЊЄЄЄЦЁЂЅзЅъЅзЅэЅЛЅУЅЕЄЧЁжcannyЁзЄђСЊЄѓЄЧЄпЄПЁЃ
1 girl, school uniform, upper body, in room, from side, masterpiece, best quality, highres, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3050420311, Face restoration: CodeFormer, Size: 512x512, Model hash: a757fe8b3d, Model: chilloutmix_, ControlNet Enabled: True, ControlNet Module: canny, ControlNet Model: control_v11p_sd15_canny [d14c016b], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1
ЬЁВшХЊЄЪРўВшЄЫАњЄРЂЄщЄьЄЦЄЗЄоЄУЄПЄЮЄЋЁЂЅЅтЄЄДЖЄИЄЮВшСќЄЌРИРЎЄЕЄьЄЦЄЗЄоЄУЄПЁФЁЃЄГЄьЄЯЄГЄьЄЧЅЂЅъЄЪГЈЪСЄЪЄЮЄЋЄтЄЗЄьЄѓЄБЄЩЁФЁЃ
ЅзЅъЅзЅэЅЛЅУЅЕЄђЁжinvertЁзЄЫЄЗЄЦЄпЄПЁЃ
1 girl, school uniform, upper body, in room, from side, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 41314358, Face restoration: CodeFormer, Size: 512x512, Model hash: a757fe8b3d, Model: chilloutmix_, ControlNet Enabled: True, ControlNet Module: invert (from white bg & black line), ControlNet Model: control_v11p_sd15_canny [d14c016b], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1
ЄГЄСЄщЄЯЄЪЄЋЄЪЄЋЅЄЅЄДЖЄИЄЪЄЮЄЧЄЯЄЪЄЋЄэЄІЄЋЁЃ
ЄПЄРЁЂЄГЄГЄоЄЧЭшЄыЄШЁЂimg2imgЅПЅжОхЄЧНшЭ§ЄЗЄПЄлЄІЄЌЮЩЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃАЪВМЄЯЁЂimg2img ЄЫУхПЇКбЄпВшСќЄђХЯЄЗЄЦРИРЎЄЗЄЦЄпЄПЛіЮуЁЃИЕЄЮРўВшЄЋЄщЗыЙНЄЋЄБЮЅЄьЄЦЄЗЄоЄУЄПЄБЄЩЁЂИЋЄПЬмЄЯПяЪЌМЋСГЄЪДЖЄИЄЫЄЪЄУЄПЁЃ
1 girl, school uniform, upper body, in room, from side, masterpiece, best quality, highres, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3832661318, Face restoration: CodeFormer, Size: 512x512, Model hash: a757fe8b3d, Model: chilloutmix_, Denoising strength: 0.6
Ё§ ЭОУЬ :
РўВшЄђМТМЬЩїЄЫЪбДЙЄЙЄыЄШЄГЄэЄоЄЧКюЖШЄЗЄЦЄпЄЦЛзЄУЄПЄБЄЩЁЂЄвЄчЄУЄШЄЗЄЦЁЂВшСќРИРЎAIЄђЛШЄЈЄаЁЂДљЄЮСАЄЫКТЄъЄЪЄЌЄщМТМЬЩїЄЮЬЁВшКюЩЪЄтКюЄьЄЦЄЗЄоЄІЄЮЄЧЄЯЄЪЄЋЄэЄІЄЋЁФЁЉ ЄЄЄфЄоЄЂЁЂДћЄЫУЏЄЋЄЌФЉРяЄЗЄЦЄНЄІЄЪЕЄЄтЄЙЄыЄБЄЩЁЃ
ЄНЄГЄоЄЧЭшЄыЄШЁЂЅЭЁМЅрЄђЩСЄЄЄЦЙНРЎЄЗЄЦКЧНЊИЖЙЦЄђОЄДЄЗЄППЭЄЫУјКюИЂЄЌЄСЄуЄѓЄШШЏРИЄЗЄНЄІЄЪЕЄЄтЄЙЄыЄБЄЩЁЂЄЩЄІЄЪЄѓЄРЄэЄІЁЃ
ЄНЄГЄоЄЧЭшЄыЄШЁЂЅЭЁМЅрЄђЩСЄЄЄЦЙНРЎЄЗЄЦКЧНЊИЖЙЦЄђОЄДЄЗЄППЭЄЫУјКюИЂЄЌЄСЄуЄѓЄШШЏРИЄЗЄНЄІЄЪЕЄЄтЄЙЄыЄБЄЩЁЂЄЩЄІЄЪЄѓЄРЄэЄІЁЃ
Ё§ 2023/04/25ФЩЕ :
МТМЬЩїЄЮЬЁВшЄЌКюЄьЄыЄЮЄЧЄЯЁЂЄЪЄЩЄШНёЄЄЄЦЄпЄПЄтЄЮЄЮЁЂЄНЄЮИхПЇЁЙЛюЄЗЄЦЄыЄІЄСЄЫЁЂЙЭЄЈЄЌДХЄЋЄУЄПЄГЄШЄЫЕЄЄХЄЄЄПЁЃВшСќРИРЎAIЄЯЁЂГЈЪСЁЂЄШЄЄЄІЄЋЅЅуЅщЄЮДщЮЉЄСЄђХ§АьЄЕЄЛЄыЄЮЄЌЦёЄЗЄЄЄЋЄщЁЂЬЁВшЄфЅЂЅЫЅсЄЮЄшЄІЄЪЅсЅЧЅЃЅЂЄЧЄЯЅЅуЅщЄЮЩСВшЄЫЛШЄЈЄЪЄЄЄшЄЪЁФЁЃЄЂЄыФјХйГЈЪСЄЌХ§АьЄЕЄьЄЦЄЪЄЄЄШЁЂЄНЄЮМъЄЮЅИЅуЅѓЅыЄЧЄЯЛШЄЄЪЊЄЫЄЪЄщЄЪЄЄЁФЁЃ
[ ЅФЅУЅГЄр ]
2023/04/25(Ва) [nЧЏСАЄЮЦќЕ]
#1 [cg_tools] МТМЬЩїВшСќЄЋЄщРўВшЅЄЅщЅЙЅШЄђРИРЎЄЗЄЦЄпЄПЄЄ
_КђЦќЄЮМТИГ
ЄЧЁЂВшСќРИРЎAIЁЂStable Diffusion web UI + Anime Lineart Style LORA ЄђЛШЄІЄШЁЂРўВшЅЄЅщЅЙЅШЄУЄнЄЄВшСќЄђРИРЎЄЧЄЄыЄГЄШЄЌЪЌЄЋЄУЄПЄБЄьЄЩЁЂЄГЄьЄђЛШЄУЄПЄщМТМЬЩїВшСќЄЋЄщРўВшЅЄЅщЅЙЅШЄУЄнЄЄВшСќЄђРИРЎЄЧЄЄыЄЮЄЋЄЪЄШЕПЬфЄЌЭЏЄЄЄПЄЮЄЧЁЂЄНЄЮЄЂЄПЄъЄђЛюЄЗЄЦЄпЄПЁЃ
ДФЖЄЯЁЂWindows10 x64 22H2, CPU: AMD Ryzen 5 5600X, RAM: 16GB, GPU: NVIDIA GeForce GTX 1060 6GBЁЃ
ИЕВшСќЄЯАЪВМЁЃbasil_mix ЄШЄЄЄІГиНЌЅтЅЧЅыЅЧЁМЅПЄђЛШЄУЄЦЁЂtxt2imgЄЧРИРЎЁЃ

ЄГЄЮВшСќЄђЁЂРўВшЅЄЅщЅЙЅШЩїЄЫЄЗЄЦНаЮЯЄЗЄПЄЄЁЃРўВшЅЄЅщЅЙЅШЩїЄђНаЮЯЄЗЄфЄЙЄЏЄЙЄыЄПЄсЄЫЁЂГиНЌЅтЅЧЅыЅЧЁМЅПЄШVAEЄђЪбЙЙЄЙЄыЁЃ
ЄНЄЗЄЦЁЂСАНвЄЮИЕВшСќЄђЁЂtxt2img ЄЮ ControlNet ЄЮВшСќЦўЮЯЭѓЄЫЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзЁЃ
ЅзЅэЅѓЅзЅШЄЫЁЂ"<lora:animeLineartMangaLike_v30MangaLike:1>, lineart, " ЄђФЩВУЄЗЄФЄФЁЂРИРЎЄЗЄПЄщАЪВМЄЫЄЪЄУЄПЁЃ

ЗыЙНЅЄЅЄДЖЄИЄЋЄтЄЗЄьЄЪЄЄЁФЁЃ
ДФЖЄЯЁЂWindows10 x64 22H2, CPU: AMD Ryzen 5 5600X, RAM: 16GB, GPU: NVIDIA GeForce GTX 1060 6GBЁЃ
ИЕВшСќЄЯАЪВМЁЃbasil_mix ЄШЄЄЄІГиНЌЅтЅЧЅыЅЧЁМЅПЄђЛШЄУЄЦЁЂtxt2imgЄЧРИРЎЁЃ
1 girl, beautiful, school uniform, upper body, masterpiece, best quality, highres, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3864758789, Size: 512x512, Model hash: 0ff127093f, Model: Basil_mix_fixed
ЄГЄЮВшСќЄђЁЂРўВшЅЄЅщЅЙЅШЩїЄЫЄЗЄЦНаЮЯЄЗЄПЄЄЁЃРўВшЅЄЅщЅЙЅШЩїЄђНаЮЯЄЗЄфЄЙЄЏЄЙЄыЄПЄсЄЫЁЂГиНЌЅтЅЧЅыЅЧЁМЅПЄШVAEЄђЪбЙЙЄЙЄыЁЃ
- ГиНЌЅтЅЧЅыЅЧЁМЅП : anything-v4.5.safetensors
- VAE : anything-v4.0.vae.pt
ЄНЄЗЄЦЁЂСАНвЄЮИЕВшСќЄђЁЂtxt2img ЄЮ ControlNet ЄЮВшСќЦўЮЯЭѓЄЫЅЩЅщЅУЅАЅЂЅѓЅЩЅЩЅэЅУЅзЁЃ
- ЅзЅъЅзЅэЅЛЅУЅЕ : softedge_pidisafe
- ЅтЅЧЅы : control_v11p_sd15_softedge
ЅзЅэЅѓЅзЅШЄЫЁЂ"<lora:animeLineartMangaLike_v30MangaLike:1>, lineart, " ЄђФЩВУЄЗЄФЄФЁЂРИРЎЄЗЄПЄщАЪВМЄЫЄЪЄУЄПЁЃ
1 girl, beautiful, school uniform, upper body, masterpiece, best quality, highres, <lora:animeLineartMangaLike_v30MangaLike:1>, lineart, monochrome, greyscale, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 331652086, Size: 512x512, Model hash: 1d1e459f9f, Model: anything-v4.5, ControlNet Enabled: True, ControlNet Module: softedge_pidisafe, ControlNet Model: control_v11p_sd15_softedge [a8575a2a], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1
ЗыЙНЅЄЅЄДЖЄИЄЋЄтЄЗЄьЄЪЄЄЁФЁЃ
Ё§ ВђСќХйЄђОхЄВЄыЄШЪбЄяЄУЄЦЄЗЄоЄІ :
txt2img ЄЮ Hires.fix ЄђЛШЄУЄЦЁЂ512x512 ЄЮВшСќЄђ 1024x1024 ЄШЄЗЄЦРИРЎЄЗЄЦЄпЄПЄШЄГЄэЁЂАЪВМЄЮЄшЄІЄЪЗыВЬЄЫЄЪЄУЄПЁЃ

САНвЄЮРИРЎВшСќЄШШцЄйЄыЄШЁЂПяЪЌЄШГЈЪСЄЌЪбЄяЄУЄЦЄЗЄоЄУЄПЁЃЄГЄьЄЌЄтЄЗМъЩСЄЅЄЅщЅЙЅШЄРЄУЄПЄщЁжЪЬЄЮЪ§ЄЌЩСЄЄоЄЗЄПЄЋЁЉЁзЄУЄЦИРЄяЄьЄНЄІЁЃ
ВђСќХйЄђОхЄВЄЦРИРЎЄЙЄыЄРЄБЄЧЄтЁЂЄГЄьЄлЄЩГЈЪСЄЌЪбЄяЄУЄЦЄЗЄоЄІЄЮЄЧЄЯЁЂЬЁВшЄфЅЂЅЫЅсЄЮЄшЄІЄЫЁЂЄЂЄыФјХйГЈЪСЄЮХ§АьЄЌДќТдЄЕЄьЄыЅсЅЧЅЃЅЂЄЧЄЯЛШЄЈЄЪЄЄЄшЄЪЄШЛзЄЈЄЦЄЄПЁЃЄЄЄфЄоЄЂЁЂЧиЗЪЄРЄБЄШЄЋЁЂЄНЄІЄЄЄІЩєЪЌЄЧЄЯЛШЄЈЄыЄЋЄтЄЗЄьЄЪЄЄЄБЄьЄЩЁЃ *1
ЭОУЬЁЃЄНЄІЄЄЄЈЄаЁЂЧиЗЪРЉКюЄЮАьЩєЄЫAIЄђЛШЄУЄЦЄпЄПЅЂЅЫЅсКюЩЪЄЌЄЂЄыЁЂЄШЄЄЄІЯУЄђАЪСАЅЭЅУЅШЄЧИЋЄЋЄБЄПЕЄЄЌЄЙЄыЁЃЄтЄЗЄЋЄЙЄыЄШЁЂЁжЅЅуЅщЄЯГЈЪСЄЌАТФъЄЗЄЪЄЄЄЋЄщЛШЄЈЄЪЄЄЄБЄЩЁЂЧиЗЪЄРЄБЄЪЄщТчТЮЄЯАьЫчГЈЄЧКбЄрЄЗЛШЄЈЄЪЄЏЄтЄЪЄЄЄЋЄтЁзЄШЄЄЄІЄГЄШЄРЄУЄПЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃЪЌЄщЄѓЄБЄЩЁЃ
1 girl, beautiful, school uniform, upper body, masterpiece, best quality, highres, <lora:animeLineartMangaLike_v30MangaLike:1>, lineart, monochrome, greyscale, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 331652086, Size: 512x512, Model hash: 1d1e459f9f, Model: anything-v4.5, Denoising strength: 0.7, ControlNet Enabled: True, ControlNet Module: softedge_pidisafe, ControlNet Model: control_v11p_sd15_softedge [a8575a2a], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1, Hires upscale: 2, Hires steps: 8, Hires upscaler: Latent (bicubic antialiased)
САНвЄЮРИРЎВшСќЄШШцЄйЄыЄШЁЂПяЪЌЄШГЈЪСЄЌЪбЄяЄУЄЦЄЗЄоЄУЄПЁЃЄГЄьЄЌЄтЄЗМъЩСЄЅЄЅщЅЙЅШЄРЄУЄПЄщЁжЪЬЄЮЪ§ЄЌЩСЄЄоЄЗЄПЄЋЁЉЁзЄУЄЦИРЄяЄьЄНЄІЁЃ
ВђСќХйЄђОхЄВЄЦРИРЎЄЙЄыЄРЄБЄЧЄтЁЂЄГЄьЄлЄЩГЈЪСЄЌЪбЄяЄУЄЦЄЗЄоЄІЄЮЄЧЄЯЁЂЬЁВшЄфЅЂЅЫЅсЄЮЄшЄІЄЫЁЂЄЂЄыФјХйГЈЪСЄЮХ§АьЄЌДќТдЄЕЄьЄыЅсЅЧЅЃЅЂЄЧЄЯЛШЄЈЄЪЄЄЄшЄЪЄШЛзЄЈЄЦЄЄПЁЃЄЄЄфЄоЄЂЁЂЧиЗЪЄРЄБЄШЄЋЁЂЄНЄІЄЄЄІЩєЪЌЄЧЄЯЛШЄЈЄыЄЋЄтЄЗЄьЄЪЄЄЄБЄьЄЩЁЃ *1
ЭОУЬЁЃЄНЄІЄЄЄЈЄаЁЂЧиЗЪРЉКюЄЮАьЩєЄЫAIЄђЛШЄУЄЦЄпЄПЅЂЅЫЅсКюЩЪЄЌЄЂЄыЁЂЄШЄЄЄІЯУЄђАЪСАЅЭЅУЅШЄЧИЋЄЋЄБЄПЕЄЄЌЄЙЄыЁЃЄтЄЗЄЋЄЙЄыЄШЁЂЁжЅЅуЅщЄЯГЈЪСЄЌАТФъЄЗЄЪЄЄЄЋЄщЛШЄЈЄЪЄЄЄБЄЩЁЂЧиЗЪЄРЄБЄЪЄщТчТЮЄЯАьЫчГЈЄЧКбЄрЄЗЛШЄЈЄЪЄЏЄтЄЪЄЄЄЋЄтЁзЄШЄЄЄІЄГЄШЄРЄУЄПЄЮЄЋЄтЄЗЄьЄЪЄЄЁЃЪЌЄщЄѓЄБЄЩЁЃ
Ё§ img2imgЄЧЄЯРўВшЄЫЄЪЄщЄЪЄЄ :
img2imgЄРЄБЄЧ ЁНЁН ControlNet ЄЯЬЄЛШЭбОѕТжЄЧЛюЄЗЄЦЄпЄПЄБЄЩЁЂЄЪЄЋЄЪЄЋИЗЄЗЄЄЗыВЬЄЫЄЪЄУЄПЁЃ

ЧђЙѕЅЄЅщЅЙЅШЄУЄнЄЄЄБЄьЄЩЁЂЄГЄьЄЯРўВшЄИЄуЄЪЄЄЄЪЄШЁЃЄЄЄфЄоЄЂЁЂВўЄсЄЦИЋФОЄЗЄЦЄпЄПЄщЁЂСАНвЄЮ2ЄФЄЮРИРЎЛіЮуЄтСДСГРўВшЄИЄуЄЪЄЄЕЄЄЌЄЗЄЦЄЄПЄБЄЩЁФЁЃ
ЄСЄЪЄпЄЫЁЂКЧНщЄЫЛюЄЗЄЦЄпЄПКнЄЫЄЯЁЂЄІЄУЄЙЄщПЇЄЌЄФЄЄЄПДЖЄИЄЮВшСќЄЌРИРЎЄЕЄьЄЦЄЗЄоЄУЄПЁЃЅзЅэЅѓЅзЅШЄЫ "monochrome, greyscale," ЄђФЩВУЄЗЄЦЄфЄыЄГЄШЄЧЁЂЬЕЭ§Ь№Э§ЄРЄБЄЩЧђЙѕВшСќЄЫЄЧЄЄПЁЃЄЧЄтЁЂЅГЅьЄЯРўВшЄИЄуЄЪЄЄЁЃ
ЅЋЅщЁМЅЄЅщЅЙЅШЩїЄЧРИРЎЄЙЄыЄЮЄЧЄЂЄьЄаЁЂimg2imgЄЧЄтЅЄЅБЄыЄЮЄРЄэЄІЄБЄЩЁФЁЃЮуЄЈЄаЁЂВМЄЮЄшЄІЄЪЗыВЬЄЧЄтЮЩЄЄЄЮЄЧЄЂЄьЄаЁФЁЃ

ЭОУЬЁЃAIЄЮРИРЎВшСќЄЪЄЮЄЧЁЂЄфЄУЄбЄъЛиЄЌЄЊЄЋЄЗЄЄЄЧЄЙЄЭЁЃ
1 girl, beautiful, school uniform, upper body, masterpiece, best quality, highres, <lora:animeLineartMangaLike_v30MangaLike:1>, lineart, monochrome, greyscale, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1475614968, Size: 512x512, Model hash: 1d1e459f9f, Model: anything-v4.5, Denoising strength: 0.55
ЧђЙѕЅЄЅщЅЙЅШЄУЄнЄЄЄБЄьЄЩЁЂЄГЄьЄЯРўВшЄИЄуЄЪЄЄЄЪЄШЁЃЄЄЄфЄоЄЂЁЂВўЄсЄЦИЋФОЄЗЄЦЄпЄПЄщЁЂСАНвЄЮ2ЄФЄЮРИРЎЛіЮуЄтСДСГРўВшЄИЄуЄЪЄЄЕЄЄЌЄЗЄЦЄЄПЄБЄЩЁФЁЃ
ЄСЄЪЄпЄЫЁЂКЧНщЄЫЛюЄЗЄЦЄпЄПКнЄЫЄЯЁЂЄІЄУЄЙЄщПЇЄЌЄФЄЄЄПДЖЄИЄЮВшСќЄЌРИРЎЄЕЄьЄЦЄЗЄоЄУЄПЁЃЅзЅэЅѓЅзЅШЄЫ "monochrome, greyscale," ЄђФЩВУЄЗЄЦЄфЄыЄГЄШЄЧЁЂЬЕЭ§Ь№Э§ЄРЄБЄЩЧђЙѕВшСќЄЫЄЧЄЄПЁЃЄЧЄтЁЂЅГЅьЄЯРўВшЄИЄуЄЪЄЄЁЃ
ЅЋЅщЁМЅЄЅщЅЙЅШЩїЄЧРИРЎЄЙЄыЄЮЄЧЄЂЄьЄаЁЂimg2imgЄЧЄтЅЄЅБЄыЄЮЄРЄэЄІЄБЄЩЁФЁЃЮуЄЈЄаЁЂВМЄЮЄшЄІЄЪЗыВЬЄЧЄтЮЩЄЄЄЮЄЧЄЂЄьЄаЁФЁЃ
1 girl, beautiful, school uniform, upper body, masterpiece, best quality, highres, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1520341489, Size: 512x512, Model hash: eb4099ba9c, Model: abyssorangemix3AOM3_aom3a3, Denoising strength: 0.58
ЭОУЬЁЃAIЄЮРИРЎВшСќЄЪЄЮЄЧЁЂЄфЄУЄбЄъЛиЄЌЄЊЄЋЄЗЄЄЄЧЄЙЄЭЁЃ
Ё§ cannyЄЧЛюЄЗЄЦЄпЄП :
ControlNet ЄЮЅзЅъЅзЅэЅЛЅУЅЕМяЮрЄЧЁЂsoftedge_pidisafe ЄђСЊЄѓЄЧЄыЄЮЄЌЄшЄэЄЗЄЏЄЪЄЄЄЮЄЧЄЯЄЪЄЄЄЋЁЂcanny ЄРЄУЄПЄщАуЄІЄЮЄЧЄЯЄШЛзЄЈЄЦЄЄПЄЮЄЧЛюЄЗЄЦЄпЄПЁЃtxt2img ЄЧРИРЎЁЃ

ШБЄЮЄЂЄПЄъЄЯРўВшЄУЄнЄЏЄЪЄУЄПЄБЄЩЁЂЩўЄЮЩєЪЌЄЯРўВшЄЮЅНЅьЄЧЄЯЄЪЄЄЄЪЁФЁЃИЕВшСќЄЮЩўЄЮЩєЪЌЄЌЙѕЄЙЄЎЄыЄЮЄРЄэЄІЄЋЁЃЄНЄьЄЯЄШЄтЄЋЄЏЁЂЄфЄУЄбЄъЛиЄЌЄЊЄЋЄЗЄЄЄЧЄЙЄЪЁЃ
- ControlNet ЄђЭИњВНЁЃ
- ЅзЅъЅзЅэЅЛЅУЅЕ : canny
- ЅтЅЧЅы : control_v11p_sd15_canny
1 girl, beautiful, school uniform, upper body, masterpiece, best quality, highres, <lora:animeLineartMangaLike_v30MangaLike:1>, lineart, monochrome, greyscale, Negative prompt: EasyNegative, (worst quality:1.4), (low quality:1.4), (normal quality:1.4), lowers, Steps: 25, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 331652086, Size: 512x512, Model hash: 1d1e459f9f, Model: anything-v4.5, ControlNet Enabled: True, ControlNet Module: canny, ControlNet Model: control_v11p_sd15_canny [d14c016b], ControlNet Weight: 1, ControlNet Guidance Start: 0, ControlNet Guidance End: 1
ШБЄЮЄЂЄПЄъЄЯРўВшЄУЄнЄЏЄЪЄУЄПЄБЄЩЁЂЩўЄЮЩєЪЌЄЯРўВшЄЮЅНЅьЄЧЄЯЄЪЄЄЄЪЁФЁЃИЕВшСќЄЮЩўЄЮЩєЪЌЄЌЙѕЄЙЄЎЄыЄЮЄРЄэЄІЄЋЁЃЄНЄьЄЯЄШЄтЄЋЄЏЁЂЄфЄУЄбЄъЛиЄЌЄЊЄЋЄЗЄЄЄЧЄЙЄЪЁЃ
Ё§ МТИГЗыВЬ :
ЗыЯРЄШЄЗЄЦЄЯЁФЁЃ
ЄоЄЂЁЂВОЄЫРўВшЅЄЅщЅЙЅШЄђРИРЎЄЧЄЄПЄШЄЗЄЦЄтЁЂЅНЅьЄђАьТЮВПЄЫЛШЄІЄЮЄШЬфЄяЄьЄПЄщЁЂИНЛўХРЄЧЄЯЛШЄЄЦЛЄЌЛзЄЄЄФЄЋЄЪЄЄЄЮЄРЄБЄЩЁФЁЃЄНЄьЄЫЁЂИЂЭјХЊЄЫЄтЁЂЄГЄьЄщЄЮГиНЌЅтЅЧЅыЅЧЁМЅПЄЯПЇЁЙЅЂЅІЅШЄРЄэЄІЄЋЄщЁЂЄНЄІЄЄЄУЄПЬЬЄЧЄтЛШЄЄЦЛЄЯЬЕЄЄЄшЄЪЄШЁФЁЃ
- ВПЄтЄЪЄЄОѕТжЄЋЄщЁЂtxt2img + Anime Lineart Style LORA ЄђЛШЄУЄЦЁЂРўВшЅЄЅщЅЙЅШЩїВшСќЄђРИРЎЄЧЄЄыЄГЄШЄЯЪЌЄЋЄУЄПЁЃ
- МТМЬЩїВшСќЄђ img2img ЄЫХЯЄЗЄЦЁЂЅЋЅщЁМЅЄЅщЅЙЅШЩїВшСќЄђРИРЎЄЙЄыЄГЄШЄтЄЧЄЄыЄШЪЌЄЋЄУЄПЁЃ
- ЄЗЄЋЄЗЁЂМТМЬЩїВшСќЄђИЕЄЫЄЗЄЦЁЂРўВшЅЄЅщЅЙЅШЩїЄђРИРЎЄЙЄыЄЮЄЯЦёЄЗЄЄЁЃЅАЅьЁМЅЙЅБЁМЅыВшСќЄУЄнЄЄЅЄЅщЅЙЅШЩїЄЪЄщРИРЎЄЧЄЄыЄБЄЩЁЂРўВшЅЄЅщЅЙЅШЩїЄЫЄЯЄЪЄУЄЦЄЏЄьЄЪЄЄЁЃ
ЄоЄЂЁЂВОЄЫРўВшЅЄЅщЅЙЅШЄђРИРЎЄЧЄЄПЄШЄЗЄЦЄтЁЂЅНЅьЄђАьТЮВПЄЫЛШЄІЄЮЄШЬфЄяЄьЄПЄщЁЂИНЛўХРЄЧЄЯЛШЄЄЦЛЄЌЛзЄЄЄФЄЋЄЪЄЄЄЮЄРЄБЄЩЁФЁЃЄНЄьЄЫЁЂИЂЭјХЊЄЫЄтЁЂЄГЄьЄщЄЮГиНЌЅтЅЧЅыЅЧЁМЅПЄЯПЇЁЙЅЂЅІЅШЄРЄэЄІЄЋЄщЁЂЄНЄІЄЄЄУЄПЬЬЄЧЄтЛШЄЄЦЛЄЯЬЕЄЄЄшЄЪЄШЁФЁЃ
Ё§ VRAMЄЌТЄъЄЪЄЄ :
Hires.fix ЄђЛШЄУЄЦ 1024x1024ЄЮВшСќЄђНаЮЯЄЗЄшЄІЄШЄЗЄПЄщЁЂNaN ЄЌТчЮЬШЏРИЄЗЄПЄРЄЮЁЂVRAM ЄЌТЄъЄЪЄЄЄРЄЮЅЈЅщЁМЄЌНаЄЦНшЭ§ЄЌУцУЧЄЕЄьЄЦЄЗЄоЄУЄПЁЃGTX 1060 6GB ЄЧЄЯЁЂЄфЄЯЄъИЗЄЗЄЄЄЮЄЋЁФЁЃ
webui-user.bat ЦтЄЮЛиФъЄђЪбЄЈЄьЄаVRAMЄЌОЏЄЪЄЄДФЖЄЧЄтЦАЄЏЄЋЄтЁЂЄШЄЄЄІЯУЄђИЋЄЋЄБЄПЄЮЄЧЛюЄЗЄЦЄпЄПЁЃ
webui-user.bat ЄЮ2ЙдЬмЄЫАЪВМЄђФЩВУЁЃЄЪЄѓЄЧЄтЁЂVRAM ЄЫТаЄЗЄЦЅЌЅйЁМЅИЅГЅьЅЏЅЗЅчЅѓЄђЙдЄІЩбХйЄђЛиФъЄЗЄЦЄЄЄыЄщЄЗЄЄЁЃ
ВУЄЈЄЦЁЂwebui-user.batЦтЄЮЁЂCOMMANDLINE_ARGS ЄЮЛиФъЄђС§ЄфЄЗЄПЁЃ
ОхЕЄЮЛиФъЄђЄЗЄПЄШЄГЄэЁЂHires.fix ЄђЛШЄУЄЦЁЂ512x512ЄЮВшСќЄђ1024x1024ЄШЄЗЄЦНаЮЯЄЙЄыЄГЄШЄЌЄЧЄЄПЁЃ
ЄтЄУЄШЄтЁЂСАНвЄЮФЬЄъЁЂРИРЎЄЕЄьЄыВшСќЄЯЗыЙНРЙТчЄЫЪбЄяЄУЄЦЄЗЄоЄІЄЮЄЧЁЂНшЭ§ЛўДжЄЌЄЋЄЋЄУЄПГфЄЫЁжЅГЅьЅИЅуЅЪЅЄЁзДЖЄЌЁФЁЃЄІЁМЄѓЁЃ
webui-user.bat ЦтЄЮЛиФъЄђЪбЄЈЄьЄаVRAMЄЌОЏЄЪЄЄДФЖЄЧЄтЦАЄЏЄЋЄтЁЂЄШЄЄЄІЯУЄђИЋЄЋЄБЄПЄЮЄЧЛюЄЗЄЦЄпЄПЁЃ
webui-user.bat ЄЮ2ЙдЬмЄЫАЪВМЄђФЩВУЁЃЄЪЄѓЄЧЄтЁЂVRAM ЄЫТаЄЗЄЦЅЌЅйЁМЅИЅГЅьЅЏЅЗЅчЅѓЄђЙдЄІЩбХйЄђЛиФъЄЗЄЦЄЄЄыЄщЄЗЄЄЁЃ
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6, max_split_size_mb:128
ВУЄЈЄЦЁЂwebui-user.batЦтЄЮЁЂCOMMANDLINE_ARGS ЄЮЛиФъЄђС§ЄфЄЗЄПЁЃ
@rem set COMMANDLINE_ARGS= set COMMANDLINE_ARGS= --xformers --no-half-vae --medvram
- --xformers : xformers ЄђЛШЄІЄГЄШЄЧНшЭ§ЄЌТЎЄЏЄЪЄыЁЃЄНЄЮТхЄяЄъЁЂЦБЄИЭ№ПєЅЗЁМЅЩЄђЭПЄЈЄЦЄтЅгЅпЅчЁМЄЫАуЄІРИРЎВшСќЄЫЄЪЄыЁЃ
- --no-half-vae : NaN ЄШЄфЄщЄЌТчЮЬЄЫНаЄЦНшЭ§ЄЌЛпЄоЄУЄЦЄЗЄоЄІОьЙчЁЂЄГЄьЄђЄФЄБЄыЄГЄШЄЧ fp16 ЄШЄфЄщЄЌ fp32 ЄЫЄЪЄУЄЦЁЂНшЭ§ЄЌФЬЄыЄЋЄтЄЗЄьЄЪЄЄЁЂЄШЄЄЄІЄГЄШЄщЄЗЄЄЁЃ
- --medvram : VRAMЄЌ4GBЄЗЄЋЄЪЄЄЛўЄЯЅГЅьЄђЄФЄБЄЦЄпЄшЁЂЄШЄЄЄІЄГЄШЄщЄЗЄЄЁЃЄНЄЮЪЌНшЭ§ТЎХйЄЯУйЄЏЄЪЄыЄНЄІЄЧЁЃ
ОхЕЄЮЛиФъЄђЄЗЄПЄШЄГЄэЁЂHires.fix ЄђЛШЄУЄЦЁЂ512x512ЄЮВшСќЄђ1024x1024ЄШЄЗЄЦНаЮЯЄЙЄыЄГЄШЄЌЄЧЄЄПЁЃ
ЄтЄУЄШЄтЁЂСАНвЄЮФЬЄъЁЂРИРЎЄЕЄьЄыВшСќЄЯЗыЙНРЙТчЄЫЪбЄяЄУЄЦЄЗЄоЄІЄЮЄЧЁЂНшЭ§ЛўДжЄЌЄЋЄЋЄУЄПГфЄЫЁжЅГЅьЅИЅуЅЪЅЄЁзДЖЄЌЁФЁЃЄІЁМЄѓЁЃ
*1: ЄтЄУЄШЄтЁЂЧиЗЪЄШЄЗЄЦЛШЄІЄШЄЗЄЦЄтЁЂЅбЁМЅЙЄЌЄсЄСЄуЄЏЄСЄуЄЪВшСќЄЌЪПЕЄЄЧРИРЎЄЕЄьЄПЄъЄЙЄыЄщЄЗЄЄЄЮЄЧЁЂЄфЄУЄбЄъЬЁВшЄЫЄЯЛШЄЈЄЪЄЄЄшЁЂЄШЄЄЄІЯУЄтЄЩЄГЄЋЄЧИЋЄЋЄБЄПЕЄЄЌЄЙЄыЁЃЅбЁМЅЙБОЁЙЄЌЭэЄѓЄЧЄЏЄыЄШЁЂ3DCGЄђГшЭбЄЙЄыЄЮЄЌТХХіЄШЄЄЄІЯУЄЫЄЪЄыЄЮЄРЄэЄІЄЪЄШЁЃ3DCGЄЧЄЂЄьЄаЁЂГшЭбЄЗЄЦЄЄЄыЬЁВшВШЄЕЄѓЄтДћЄЫЕяЄыЄЋЄщЁЂМТРгЄЌЄЂЄыЄЗЁЃ
[ ЅФЅУЅГЄр ]
#2 [zatta][neta] ЅеЅьЁМЅрДжЄЌХ§АьЄЕЄьЄЦЄЄЄЪЄЄЄГЄШЄЮЬЅЮЯ
ЛзЙЭЅсЅтЁЃ
ОЏЄЗСАЄЫЁЂЭйЄУЄЦЄЄЄыПЭЄЮМТМЬБЧСќЄђЁЂ1ЅеЅьЁМЅрЄКЄФAIЄЧМъЩСЄЩїЄЫЪбДЙЄЗЄПЦАВшЄђЬмЄЫЄЗЄПЁЃЅАЅАЄУЄЦЄпЄПЄщИЋЄФЄЋЄУЄПЁЃАЪВМЄЮЦАВшЁЃ
_ЁжAIЅЂЅЫЅсЁМЅЗЅчЅѓЛЯЄоЄъЄЙЄЎЄРЄэ..ЁзМТМЬЅтЅЧЅыЄЮЦАЄЄђЅЂЅЫЅсЄЫЪбДЙЄЙЄыAIЄЮРКХйЄЌЙтЄЙЄЎЄыЄГЄШЄЫТаЄЙЄыЅЏЅъЅЈЅЄЅПЁМЄЮШПБў - Togetter
НщИЋЛўЄЯЁЂЁжЄІЄяЁЂЅЙЅДЅЄЁзЄШЛзЄУЄПЄтЄЮЄЮЁЂЄшЄЏИЋЄЦЄпЄыЄШЁЂ1ЅеЅьЁМЅрЄКЄФЪбДЙЄЗЄЦЄыЄЋЄщЁЂЅеЅьЁМЅрУБАЬЄЧЩўЄЮМяЮрЄтБЦЄЮЩеЄЪ§ЄтЅбЅЋЅбЅЋЪбЄяЄУЄЦЄЄЄЦЁЂЄГЄьЄЧЄЯЄоЄРЄоЄРЛШЄЄЪЊЄЫЄЯЄЪЄщЄЪЄЄЄяЄЪЁЂЄШЁФЁЃ
ЄПЄРЁЂ3DCGЄЧЅьЅѓЅРЅъЅѓЅАЄЗЄЦКюЄУЄПЅЛЅыЅыЅУЅЏЄЪЅЂЅЫЅсБЧСќЄШШцЄйЄыЄШЁЂAIЄЌРИРЎЄЗЄПЅНЅьЄЫЬЅЮЯЄђДЖЄИЄыЄШЄЄЄІЄЋЁЂЬЏЄЪМъЩСЄЅЂЅЫЅсДЖЄЌЩеВУЄЕЄьЄЦЄЄЄыЄшЄІЄЫЄтЛзЄЈЄЦЁЂЄНЄГЄЋЄщЄЪЄѓЄРЄЋПЇЁЙЄШЙЭЄЈЛЯЄсЄЦЄЗЄоЄУЄПЁЃЄЮЄЧЅсЅтЁЃЛзЙЭЅсЅтЁЃ
ОЏЄЗСАЄЫЁЂЭйЄУЄЦЄЄЄыПЭЄЮМТМЬБЧСќЄђЁЂ1ЅеЅьЁМЅрЄКЄФAIЄЧМъЩСЄЩїЄЫЪбДЙЄЗЄПЦАВшЄђЬмЄЫЄЗЄПЁЃЅАЅАЄУЄЦЄпЄПЄщИЋЄФЄЋЄУЄПЁЃАЪВМЄЮЦАВшЁЃ
_ЁжAIЅЂЅЫЅсЁМЅЗЅчЅѓЛЯЄоЄъЄЙЄЎЄРЄэ..ЁзМТМЬЅтЅЧЅыЄЮЦАЄЄђЅЂЅЫЅсЄЫЪбДЙЄЙЄыAIЄЮРКХйЄЌЙтЄЙЄЎЄыЄГЄШЄЫТаЄЙЄыЅЏЅъЅЈЅЄЅПЁМЄЮШПБў - Togetter
НщИЋЛўЄЯЁЂЁжЄІЄяЁЂЅЙЅДЅЄЁзЄШЛзЄУЄПЄтЄЮЄЮЁЂЄшЄЏИЋЄЦЄпЄыЄШЁЂ1ЅеЅьЁМЅрЄКЄФЪбДЙЄЗЄЦЄыЄЋЄщЁЂЅеЅьЁМЅрУБАЬЄЧЩўЄЮМяЮрЄтБЦЄЮЩеЄЪ§ЄтЅбЅЋЅбЅЋЪбЄяЄУЄЦЄЄЄЦЁЂЄГЄьЄЧЄЯЄоЄРЄоЄРЛШЄЄЪЊЄЫЄЯЄЪЄщЄЪЄЄЄяЄЪЁЂЄШЁФЁЃ
ЄПЄРЁЂ3DCGЄЧЅьЅѓЅРЅъЅѓЅАЄЗЄЦКюЄУЄПЅЛЅыЅыЅУЅЏЄЪЅЂЅЫЅсБЧСќЄШШцЄйЄыЄШЁЂAIЄЌРИРЎЄЗЄПЅНЅьЄЫЬЅЮЯЄђДЖЄИЄыЄШЄЄЄІЄЋЁЂЬЏЄЪМъЩСЄЅЂЅЫЅсДЖЄЌЩеВУЄЕЄьЄЦЄЄЄыЄшЄІЄЫЄтЛзЄЈЄЦЁЂЄНЄГЄЋЄщЄЪЄѓЄРЄЋПЇЁЙЄШЙЭЄЈЛЯЄсЄЦЄЗЄоЄУЄПЁЃЄЮЄЧЅсЅтЁЃЛзЙЭЅсЅтЁЃ
Ё§ ЕЁГЃЄЌЩСЄЄЄПЄшЄІЄЪРўЄђЕсЄсЄщЄьЄЦЄПЛўТх :
ТчРЮЁЂЅЛЅыЄШЅеЅЃЅыЅрЄЧЅЂЅЫЅсЄђКюЄъЛЯЄсЄПКЂЄЯЁЂЛХОхЄВЄЮЄЊЛаЄЕЄѓУЃЄЌЁЂЄФЄБЅкЅѓЄђЛШЄУЄЦЁЂЅЛЅыЄЫЦАВшЄЮРўЄђЅШЅьЅЙЄЗЄЦЄП(ЄщЄЗЄЄ)ЁЃЄНЄЮКЂЄЯЁЂЦАВшЄЫУщМТЄЫЁЂЄЋЄФЁЂЄЩЄьЄРЄБДёЮяЄЪРўЄђАњЄЏЄЋЁЂЄНЄІЄЄЄІЧНЮЯЄЌЛХОхЄВЄЮЪ§ЁЙЄЫЕсЄсЄщЄьЄЦЄПЁЃ
ЄНЄЮЄІЄСЁЂЅШЅьЅЙЅоЅЗЅѓЄЌНаИНЄЗЄЦЁЂЕЁГЃЄЌЁЂЦАВшЭбЛцОхЄЮРўЄђЅЛЅыЄЫЅШЅьЅЙЄЗЄЦЄЏЄьЄыЄшЄІЄЫЄЪЄУЄПЁЃЄШЄГЄэЄЌКЃХйЄЯЁЂЦАВшЭбЛцОхЄЮРўМЋТЮЄЫЅаЅщЅФЅЄЌЄЂЄыЄГЄШЄЌЬфТъЄЫЄЪЄУЄЦЄЄПЁЃЦАВшЄђЩСЄЄЄЦЄыЪ§ЁЙЄЯЄНЄьЄОЄьЪЬПЭЄЪЄЮЄЧЅаЅщЅФЅЄЌЄЂЄыЄЮЄЯХіЄПЄъСАЄЪЄЮЄРЄБЄЩЁЃЄНЄГЄЧЁЂЦАВшЄђЩСЄЏКнЄЫЄЯЄГЄІЄЄЄІЩЎЕЖёЄђЛШЄЈЁЂЄпЄПЄЄЄЪЅыЁМЅыЄЌАьЩєЄЮЅЙЅПЅИЅЊЦтЄЧЖЏРЉЄЕЄьЄыЄшЄІЄЫЄЪЄУЄПЄъЄтЄЗЄПЁЃ *1
ЄФЄоЄъЁЂРЮЄЮЦќЫмЄЮМъЩСЄЅЂЅЫЅсЖШГІЄЫЄЯЁЂЁжЖбАьЄЪРўЁзЁжЬЕИФРЄЪРўЁзЁжУЏЄЌЩСЄЄЄЦЄтЦБЄИРўЁзЄђЭ§СлЄШЄЗЄЦЁЂЄНЄѓЄЪРўЄђМТИНЄЙЄйЄЏЁЂКюЖШЄЫНОЛіЄЙЄыПЭДжУЃЄЌХиЮЯЄђЄЗЄЦЄЄЄПЛўТхЄЌЄЂЄУЄПЁЃ
ЄНЄЮЄІЄСЁЂЅШЅьЅЙЅоЅЗЅѓЄЌНаИНЄЗЄЦЁЂЕЁГЃЄЌЁЂЦАВшЭбЛцОхЄЮРўЄђЅЛЅыЄЫЅШЅьЅЙЄЗЄЦЄЏЄьЄыЄшЄІЄЫЄЪЄУЄПЁЃЄШЄГЄэЄЌКЃХйЄЯЁЂЦАВшЭбЛцОхЄЮРўМЋТЮЄЫЅаЅщЅФЅЄЌЄЂЄыЄГЄШЄЌЬфТъЄЫЄЪЄУЄЦЄЄПЁЃЦАВшЄђЩСЄЄЄЦЄыЪ§ЁЙЄЯЄНЄьЄОЄьЪЬПЭЄЪЄЮЄЧЅаЅщЅФЅЄЌЄЂЄыЄЮЄЯХіЄПЄъСАЄЪЄЮЄРЄБЄЩЁЃЄНЄГЄЧЁЂЦАВшЄђЩСЄЏКнЄЫЄЯЄГЄІЄЄЄІЩЎЕЖёЄђЛШЄЈЁЂЄпЄПЄЄЄЪЅыЁМЅыЄЌАьЩєЄЮЅЙЅПЅИЅЊЦтЄЧЖЏРЉЄЕЄьЄыЄшЄІЄЫЄЪЄУЄПЄъЄтЄЗЄПЁЃ *1
ЄФЄоЄъЁЂРЮЄЮЦќЫмЄЮМъЩСЄЅЂЅЫЅсЖШГІЄЫЄЯЁЂЁжЖбАьЄЪРўЁзЁжЬЕИФРЄЪРўЁзЁжУЏЄЌЩСЄЄЄЦЄтЦБЄИРўЁзЄђЭ§СлЄШЄЗЄЦЁЂЄНЄѓЄЪРўЄђМТИНЄЙЄйЄЏЁЂКюЖШЄЫНОЛіЄЙЄыПЭДжУЃЄЌХиЮЯЄђЄЗЄЦЄЄЄПЛўТхЄЌЄЂЄУЄПЁЃ
Ё§ ЕЁГЃЄЌЩСЄЄЄПРўЄђШнФъЄЕЄьЄыЛўТх :
ЄГЄьЄЌЁЂ3DCGЅНЅеЅШЄЮНаИНЄШЁЂЅЛЅыЅыЅУЅЏ3DCGБЧСќЄЮЩсЕкЄЧЁЂЄСЄчЄУЄШОѕЖЗЄЌЪбЄяЄУЄЦЄЏЄыЁЃ3DCGЄЮЅНЅьЄЯЁЂЕЁГЃЄЌЩСЄЏРўЄЪЄЮЄЧЁЂПЭДжЄЌАњЄЏЄшЄъЁЂДжАуЄЄЄЪЄЏДёЮяЄЧЁЂЖбАьЄЪРўЁЃ
ЄфЄУЄПЄМЁЃЄШЄІЄШЄІЭ§СлЄЮРўЄђЅЂЅЫЅсЖШГІЄЯМъЄЫЦўЄьЄПЁЃЄГЄьЄЧЛыФАМдЄтТчДюЄгЄЙЄыЄГЄШДжАуЄЄЬЕЄЗЁЃ
ЄШЄЯЄЪЄщЄЪЄЋЄУЄПЁФЁЃ3DCGЄШЄЄЄІЄРЄБЄЧЁЂЄЪЄѓЄРЄЋЄѓЄРИРЄУЄЦЕёШнШПБўЄђМЈЄЙЛыФАМдЄЌЗыЙННаЄЦЄЄПЁЃЄЊЄЋЄЗЄЄЄИЄуЄЪЄЄЄЋЁЃЄНЄГЄЫЄЂЄыЄЮЄЯЁЂЅЂЅЫЅсЖШГІЄЌВПННЧЏЄтФЩЄЄЕсЄсЄЦЄЄПЭ§СлЄЮРўЄЮЄЯЄКЄЪЄЮЄЫЁЃЄоЄыЄЧЕЁГЃЄЌЩСЄЄЄПЄшЄІЄЪЖбАьЄЪРўЄђМТИНЄЗЄшЄІЄШЁЂГЇЄЧЄКЄУЄШЖьЯЋЄЗЄЦЄЄПЄЮЄЫЁЃЄЪЄѓЄЧЪИЖчИРЄяЄьЄыЄЮЁЃЄЊСАХљЁЂЅГЅьЄЌЭпЄЗЄЋЄУЄПЄѓЄИЄуЄЪЄЄЄЮЁЉ
ЄфЄУЄПЄМЁЃЄШЄІЄШЄІЭ§СлЄЮРўЄђЅЂЅЫЅсЖШГІЄЯМъЄЫЦўЄьЄПЁЃЄГЄьЄЧЛыФАМдЄтТчДюЄгЄЙЄыЄГЄШДжАуЄЄЬЕЄЗЁЃ
ЄШЄЯЄЪЄщЄЪЄЋЄУЄПЁФЁЃ3DCGЄШЄЄЄІЄРЄБЄЧЁЂЄЪЄѓЄРЄЋЄѓЄРИРЄУЄЦЕёШнШПБўЄђМЈЄЙЛыФАМдЄЌЗыЙННаЄЦЄЄПЁЃЄЊЄЋЄЗЄЄЄИЄуЄЪЄЄЄЋЁЃЄНЄГЄЫЄЂЄыЄЮЄЯЁЂЅЂЅЫЅсЖШГІЄЌВПННЧЏЄтФЩЄЄЕсЄсЄЦЄЄПЭ§СлЄЮРўЄЮЄЯЄКЄЪЄЮЄЫЁЃЄоЄыЄЧЕЁГЃЄЌЩСЄЄЄПЄшЄІЄЪЖбАьЄЪРўЄђМТИНЄЗЄшЄІЄШЁЂГЇЄЧЄКЄУЄШЖьЯЋЄЗЄЦЄЄПЄЮЄЫЁЃЄЪЄѓЄЧЪИЖчИРЄяЄьЄыЄЮЁЃЄЊСАХљЁЂЅГЅьЄЌЭпЄЗЄЋЄУЄПЄѓЄИЄуЄЪЄЄЄЮЁЉ
Ё§ ИмЕвЄЌЫмХіЄЫЭпЄЗЄЋЄУЄПЄтЄЮ :
ЄФЄоЄыЄШЄГЄэЁЂМъЩСЄЅЂЅЫЅсЄЫЄЊЄБЄыЁЂЫмХіЄЮЭ§СлЄЮРўЄЫЄЯЁЂЁжЄцЄщЄЎЁзЁжЅКЅьЁзЁжЅжЅьЁзЄЌЕсЄсЄщЄьЄЦЄЄЄПЄЮЄЋЄтЄЗЄьЄЪЄЄЄЪЄШЛзЄЈЄЦЄЏЄыЄЮЄЧЄЙЁЃЅжЅьВсЄЎЄЦЄЄЄЦЄтЅРЅсЄРЄБЄЩЁЂЕЁГЃЄЮЄшЄІЄЫРЕГЮВсЄЎЄЦЄтЅРЅсЄЪЄѓЄРЄэЄІЁФЁЃПЭЄЌМъЄђЦАЄЋЄЗЄЦКюЄУЄПЄтЄЮЄЫЄЯЁЂЩЌЄКШљЬЏЄЪЅжЅьЄЌЦўЄыЁЃЄНЄЮЅжЅьЄЫЁЂИЋЄыТІЄЯВПЄЋЄђДЖЄИЄЦЄЄЄПЄъЄЙЄыЄЮЄЋЄтЄЗЄьЄЪЄЄЄЪЄШЁЃ
ЄНЄѓЄЪЄяЄБЄЧЁЂСАНвЄЮЁЂAIЄЌРИРЎЄЗЄПЅжЅьЅжЅьЄЮЦАВшЄЫЁЂМЋЪЌЄЯЬЏЄЪЬЅЮЯЄђДЖЄИЄЦЄЗЄоЄУЄПЄЮЄЋЄтЄЗЄьЄЪЄЄЄЪЄШЁЃЕЁГЃЄЌРИРЎЄЗЄПЦАВшЄЮЄЯЄКЄЪЄЮЄЫЁЂЛЈЄЪПЭДжЄЌЅЌЅъЅЌЅъЄШЩСЄЄЄПЦАВшЄЮЄшЄІЄЫИЋЄЈЄЪЄЏЄтЄЪЄЄЁЃЄНЄГЄЌИЋЄЦЄЄЄЦЬЬЧђЄЄЁЃ
ЄЊЄНЄщЄЏКЃИхЁЂЅеЅьЁМЅрДжЄЧЗСОѕЄЫЯЂТГРЄђЛ§ЄПЄЛЄыЄшЄІЄЫЁЂAIЄЫЄшЄыЪбДЙНшЭ§ЄЌШЏХИЄЗЄЦЄЄЄЏВФЧНРЄЯЙтЄЄЄЮЄРЄэЄІЄБЄЩЁЃВОЄЫЄНЄьЄЌМТИНЄЗЄПЛўЁЂЁжРЮЄЮЄлЄІЄЌГшЄГшЄЄШЄЗЄПЦАЄЄЫИЋЄЈЄПЄЪЄЂЁзЁжЄГЄьЄЧЄЯ3DCGЄШЪбЄяЄщЄЪЄЄЄИЄуЄѓЁЃЄФЄоЄѓЄЪЄЄЁзЄШЄЄЄІДЖСлЄЌНаЄЦЄЄНЄІЄЪЕЄЄтЄЙЄыЁФЁЃ
ЄЧЄтЄоЄЂЁЂАьХйЄЯЄНЄІЄЄЄІЅьЅйЅыЄЫУЃЄЗЄЦЄпЄЪЄЄЄШЁЂЄНЄЮМЁЄЮЬмЩИЄРЄУЄЦИЋЄЈЄЦЄГЄЪЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄЄЪЁЂЄШЄтЛзЄІЄЮЄЧЄЙЄЌЁЃ
ЄНЄѓЄЪЄяЄБЄЧЁЂСАНвЄЮЁЂAIЄЌРИРЎЄЗЄПЅжЅьЅжЅьЄЮЦАВшЄЫЁЂМЋЪЌЄЯЬЏЄЪЬЅЮЯЄђДЖЄИЄЦЄЗЄоЄУЄПЄЮЄЋЄтЄЗЄьЄЪЄЄЄЪЄШЁЃЕЁГЃЄЌРИРЎЄЗЄПЦАВшЄЮЄЯЄКЄЪЄЮЄЫЁЂЛЈЄЪПЭДжЄЌЅЌЅъЅЌЅъЄШЩСЄЄЄПЦАВшЄЮЄшЄІЄЫИЋЄЈЄЪЄЏЄтЄЪЄЄЁЃЄНЄГЄЌИЋЄЦЄЄЄЦЬЬЧђЄЄЁЃ
ЄЊЄНЄщЄЏКЃИхЁЂЅеЅьЁМЅрДжЄЧЗСОѕЄЫЯЂТГРЄђЛ§ЄПЄЛЄыЄшЄІЄЫЁЂAIЄЫЄшЄыЪбДЙНшЭ§ЄЌШЏХИЄЗЄЦЄЄЄЏВФЧНРЄЯЙтЄЄЄЮЄРЄэЄІЄБЄЩЁЃВОЄЫЄНЄьЄЌМТИНЄЗЄПЛўЁЂЁжРЮЄЮЄлЄІЄЌГшЄГшЄЄШЄЗЄПЦАЄЄЫИЋЄЈЄПЄЪЄЂЁзЁжЄГЄьЄЧЄЯ3DCGЄШЪбЄяЄщЄЪЄЄЄИЄуЄѓЁЃЄФЄоЄѓЄЪЄЄЁзЄШЄЄЄІДЖСлЄЌНаЄЦЄЄНЄІЄЪЕЄЄтЄЙЄыЁФЁЃ
ЄЧЄтЄоЄЂЁЂАьХйЄЯЄНЄІЄЄЄІЅьЅйЅыЄЫУЃЄЗЄЦЄпЄЪЄЄЄШЁЂЄНЄЮМЁЄЮЬмЩИЄРЄУЄЦИЋЄЈЄЦЄГЄЪЄЄЄЮЄЋЄтЄЗЄьЄЪЄЄЄЪЁЂЄШЄтЛзЄІЄЮЄЧЄЙЄЌЁЃ
Ё§ ЅЂЅЪЅэЅАЄЪВПЄЋЄђЩеВУЄЙЄыЄГЄШ :
ЄНЄІЄЄЄЈЄаЁЂЄГЄГКЧЖсЄЮМъЩСЄЅЂЅЫЅсЖШГІЄЯЁЂЅЛЅыЄШЅеЅЃЅыЅрЄЧКюЄУЄЦЄПЛўТхЄЮЅЂЅьЅГЅьЄђКЦИНЄЗЄшЄІЄШХиЮЯЄЗЄЦЄЄЄыЄшЄІЄЫИЋЄЈЄЪЄЏЄтЄЪЄЄЄЪЄШЁЃ
ЛХОхЄВЄЯДАСДЄЫЅЧЅИЅПЅыЄЫЄЪЄУЄЦЁЂЅаЅБЅФЅФЁМЅыЄЧГЦЬЬЄђЅЏЅъЅУЅЏЄЗЄЦХЩЄъФйЄЗЄЦЄЄЄЏЄЋЄщЁЂЄтЄЯЄфХЩЄъЅрЅщЄЪЄѓЄЦЄЩЄГЄЫЄтЬЕЄЄЁЃЅЛЅыЄЫГЈЖёЄђЅкЅПЅкЅПЄШХЩЄУЄЦЄПЛўТхЄЯЁжХЩЄъЅрЅщЄЯЅРЅсЁзЄШЄЄЄІАЗЄЄЄРЄУЄПЄБЄЩЁЂЄНЄЮКЂЄЋЄщЄЙЄыЄШКЃЄЮЅЂЅЫЅсРЉКюЄЮЛХОхЄВЄЯЁЂДжАуЄЄЄЪЄЏЭ§СлХЊЄЪХЩЄъЄЮЄЯЄКЁЃДАСДЄЫЅеЅщЅУЅШЁЃДАСДЄЫЖбАьЁЃ
ЄЪЄЮЄЫЁЂЛЃБЦУЪГЌЄЧЅеЅЃЅыЅПЄђЄЋЄБЄЦЁЂЄяЄЖЄяЄЖХЩЄъЅрЅщЄђКЦИНЄЗЄЦЄыКюЩЪЄЌЗыЙНСАЄЋЄщНаЄЦЄЄЦЄЄЄыЁФЁЃЅЌЅѓЅРЅрЅЗЅъЁМЅКЄЮMSЄЮХЩЄъЄШЄЋЄНЄѓЄЪДЖЄИЄРЄБЄЩЁЂЅЂЅьЄУЄЦВПЛўКЂЄЋЄщЄфЄъЛЯЄсЄПЄѓЄРЄэЄІЁФЁЃ
РўЄЫЄФЄЄЄЦЄтЦБЭЭЄЧЁЃЅаЅБЅФЅФЁМЅыЄЧХЩЄУЄЦЄЄЄЏДиЗИЄЧЁЂЦАВшЄЮРўЄЯ2УЭВНЄЕЄьЄПОѕТжЄЧЛХОхЄВЄЫХЯЄЕЄьЄыЄБЄЩЁЃЄГЄьЄоЄПЛЃБЦУЪГЌЄЧЁЂБєЩЎЄЧЩСЄЄЄПЄшЄІЄЪЅмЅЕЅмЅЕДЖХљЄђЄяЄЖЄяЄЖЩеВУЄЗЄЦЄыКюЩЪЄЌЄЂЄУЄПЄъЄЗЄЦЁЃИЕЁЙБєЩЎЄЧЩСЄЄЄЦЄЄЄП(ЄЋЄтЄЗЄьЄЪЄЄ)ЦАВшЄђЁЂЄяЄЖЄяЄЖ2УЭВНЄЗЄЦЁЂБєЩЎЄщЄЗЄЕЄђЬЕЄЏЄЗЄЦЖбАьЄЪРўЄЫЄЗЄЦЄЄЄыЄЮЄЫЁЂЄоЄПИхЄЋЄщБєЩЎЄщЄЗЄЕЄђФЩВУЄЙЄыЄЮЄРЄЋЄщЁЂАьТЮВПЄђЄфЄУЄЦЄыЄЮЄРЄэЄІЄШЛзЄяЄЪЄЄЄЧЄтЄЪЄЄЄБЄЩЁФЁЃ *2
ЄЧЄтЁЂЄНЄЮНшЭ§ЄђЦўЄьЄыЄЋЦўЄьЄЪЄЄЄЋЄЧЁЂБЧСќЄЋЄщМѕЄБЄыАѕОнЄЌПяЪЌЪбЄяЄыЄЮЄРЄшЄЪЁФЁЃ
ЅЛЅыЄШЅеЅЃЅыЅрЄЧКюЄУЄЦЄПКЂЄЋЄщЄЙЄыЄШЁЂЅЧЅИЅПЅыЄЪЦЛЖёЄЮЩсЕкЄЫЄшЄУЄЦЁЂЄГЄьЄГЄНЄЌЭ§СлЄШЛзЄЈЄыОѕТжЄЌМТИНЄЗЄПЄШИРЄЈЄыЁЃЄЗЄЋЄЗЁЂМТКнЄЫЄНЄЮОѕТжЄЫЄЪЄУЄЦЄпЄыЄШЁЂЄГЄьЄИЄуЪЊТЄъЄЪЄЄЁЂЅЂЅЪЅэЅАДЖЄЌЭпЄЗЄЄЄШЛзЄЄЛЯЄсЄыЄШЄЄЄІЁФЁЃЄЪЄѓЄШЄтЩдЛзЕФЁЃ
ЄЦЄЪЄЂЄПЄъЄђЙЭЄЈЄыЄШЁЂЅЛЅыЅыЅУЅЏЄЮ3DCGЅЂЅЫЅсБЧСќЄРЄУЄЦЁЂМъЩСЄДЖЄђЩеВУЄЗЄЦАѕОнЄђЪбЄЈЄЦЄЗЄоЄІЄГЄШЄЯВФЧНЄЪЄЯЄКЄЧЁЃМТКнЄНЄЮЄЂЄПЄъЄђЛюЄпЄЦЄыКюЩЪЄтДћЄЫЄЂЄыЄБЄьЄЩЁЃЮуЄЈЄаEЅЦЅьЄђФЏЄсЄЦЄыЄШЁЂЛўЁЙЄНЄІЄЄЄІБЧСќЄђИЋЄЋЄБЄПЄъЄЙЄыЄЗЁЃ
ЄНЄІЄЄЄУЄПЁЂЄЂЄЈЄЦЩдАТФъЄЕЄђЩеВУЄЙЄыНшЭ§ЄЫAIЄђЛШЄЈЄЪЄЄЄтЄЮЄЋЄЪЁЃКЃЄЮВшСќРИРЎAIЄЯЅеЅьЁМЅрДжЄђХ§АьЄЕЄЛЄыЄГЄШЄЌЖьМъЄРЄБЄЩЁЂЄЄЄУЄНЄЮЄГЄШЁЂЕеЄЫЅеЅьЁМЅрДжЄђХ§АьЄЕЄЛЄЪЄЄЪ§ИўЄЧЛХЛіЄђЄЕЄЛЄщЄьЄЪЄЄЄтЄЮЄЋЁЃЄПЄжЄѓЅНЅьЁЂМъЩСЄЄЮАьЫчГЈЄЫЄтЛШЄЈЄНЄІЄЪЕЄЄЌЁФЁЃЄЪЄЩЄШЅаЅЋЬбСлЄђЄЗЄЦЄпЄПЄБЄЩЁЂВПЄђЄЩЄІГиНЌЄЕЄЛЄЦЄЩЄІЄЄЄІНшЭ§ЄђЄЋЄБЄьЄаЄЄЄЄЄЮЄЋЄЕЄУЄбЄъЅЄЅсЁМЅИЄЌЭЏЄЋЄЪЄЄЄЧЄЙЄЌЁЃ
ЛзЙЭЅсЅтЄЧЄЙЁЃЅЊЅСЄЯЬЕЄЄЄЧЄЙЁЃ
ЛХОхЄВЄЯДАСДЄЫЅЧЅИЅПЅыЄЫЄЪЄУЄЦЁЂЅаЅБЅФЅФЁМЅыЄЧГЦЬЬЄђЅЏЅъЅУЅЏЄЗЄЦХЩЄъФйЄЗЄЦЄЄЄЏЄЋЄщЁЂЄтЄЯЄфХЩЄъЅрЅщЄЪЄѓЄЦЄЩЄГЄЫЄтЬЕЄЄЁЃЅЛЅыЄЫГЈЖёЄђЅкЅПЅкЅПЄШХЩЄУЄЦЄПЛўТхЄЯЁжХЩЄъЅрЅщЄЯЅРЅсЁзЄШЄЄЄІАЗЄЄЄРЄУЄПЄБЄЩЁЂЄНЄЮКЂЄЋЄщЄЙЄыЄШКЃЄЮЅЂЅЫЅсРЉКюЄЮЛХОхЄВЄЯЁЂДжАуЄЄЄЪЄЏЭ§СлХЊЄЪХЩЄъЄЮЄЯЄКЁЃДАСДЄЫЅеЅщЅУЅШЁЃДАСДЄЫЖбАьЁЃ
ЄЪЄЮЄЫЁЂЛЃБЦУЪГЌЄЧЅеЅЃЅыЅПЄђЄЋЄБЄЦЁЂЄяЄЖЄяЄЖХЩЄъЅрЅщЄђКЦИНЄЗЄЦЄыКюЩЪЄЌЗыЙНСАЄЋЄщНаЄЦЄЄЦЄЄЄыЁФЁЃЅЌЅѓЅРЅрЅЗЅъЁМЅКЄЮMSЄЮХЩЄъЄШЄЋЄНЄѓЄЪДЖЄИЄРЄБЄЩЁЂЅЂЅьЄУЄЦВПЛўКЂЄЋЄщЄфЄъЛЯЄсЄПЄѓЄРЄэЄІЁФЁЃ
РўЄЫЄФЄЄЄЦЄтЦБЭЭЄЧЁЃЅаЅБЅФЅФЁМЅыЄЧХЩЄУЄЦЄЄЄЏДиЗИЄЧЁЂЦАВшЄЮРўЄЯ2УЭВНЄЕЄьЄПОѕТжЄЧЛХОхЄВЄЫХЯЄЕЄьЄыЄБЄЩЁЃЄГЄьЄоЄПЛЃБЦУЪГЌЄЧЁЂБєЩЎЄЧЩСЄЄЄПЄшЄІЄЪЅмЅЕЅмЅЕДЖХљЄђЄяЄЖЄяЄЖЩеВУЄЗЄЦЄыКюЩЪЄЌЄЂЄУЄПЄъЄЗЄЦЁЃИЕЁЙБєЩЎЄЧЩСЄЄЄЦЄЄЄП(ЄЋЄтЄЗЄьЄЪЄЄ)ЦАВшЄђЁЂЄяЄЖЄяЄЖ2УЭВНЄЗЄЦЁЂБєЩЎЄщЄЗЄЕЄђЬЕЄЏЄЗЄЦЖбАьЄЪРўЄЫЄЗЄЦЄЄЄыЄЮЄЫЁЂЄоЄПИхЄЋЄщБєЩЎЄщЄЗЄЕЄђФЩВУЄЙЄыЄЮЄРЄЋЄщЁЂАьТЮВПЄђЄфЄУЄЦЄыЄЮЄРЄэЄІЄШЛзЄяЄЪЄЄЄЧЄтЄЪЄЄЄБЄЩЁФЁЃ *2
ЄЧЄтЁЂЄНЄЮНшЭ§ЄђЦўЄьЄыЄЋЦўЄьЄЪЄЄЄЋЄЧЁЂБЧСќЄЋЄщМѕЄБЄыАѕОнЄЌПяЪЌЪбЄяЄыЄЮЄРЄшЄЪЁФЁЃ
ЅЛЅыЄШЅеЅЃЅыЅрЄЧКюЄУЄЦЄПКЂЄЋЄщЄЙЄыЄШЁЂЅЧЅИЅПЅыЄЪЦЛЖёЄЮЩсЕкЄЫЄшЄУЄЦЁЂЄГЄьЄГЄНЄЌЭ§СлЄШЛзЄЈЄыОѕТжЄЌМТИНЄЗЄПЄШИРЄЈЄыЁЃЄЗЄЋЄЗЁЂМТКнЄЫЄНЄЮОѕТжЄЫЄЪЄУЄЦЄпЄыЄШЁЂЄГЄьЄИЄуЪЊТЄъЄЪЄЄЁЂЅЂЅЪЅэЅАДЖЄЌЭпЄЗЄЄЄШЛзЄЄЛЯЄсЄыЄШЄЄЄІЁФЁЃЄЪЄѓЄШЄтЩдЛзЕФЁЃ
ЄЦЄЪЄЂЄПЄъЄђЙЭЄЈЄыЄШЁЂЅЛЅыЅыЅУЅЏЄЮ3DCGЅЂЅЫЅсБЧСќЄРЄУЄЦЁЂМъЩСЄДЖЄђЩеВУЄЗЄЦАѕОнЄђЪбЄЈЄЦЄЗЄоЄІЄГЄШЄЯВФЧНЄЪЄЯЄКЄЧЁЃМТКнЄНЄЮЄЂЄПЄъЄђЛюЄпЄЦЄыКюЩЪЄтДћЄЫЄЂЄыЄБЄьЄЩЁЃЮуЄЈЄаEЅЦЅьЄђФЏЄсЄЦЄыЄШЁЂЛўЁЙЄНЄІЄЄЄІБЧСќЄђИЋЄЋЄБЄПЄъЄЙЄыЄЗЁЃ
ЄНЄІЄЄЄУЄПЁЂЄЂЄЈЄЦЩдАТФъЄЕЄђЩеВУЄЙЄыНшЭ§ЄЫAIЄђЛШЄЈЄЪЄЄЄтЄЮЄЋЄЪЁЃКЃЄЮВшСќРИРЎAIЄЯЅеЅьЁМЅрДжЄђХ§АьЄЕЄЛЄыЄГЄШЄЌЖьМъЄРЄБЄЩЁЂЄЄЄУЄНЄЮЄГЄШЁЂЕеЄЫЅеЅьЁМЅрДжЄђХ§АьЄЕЄЛЄЪЄЄЪ§ИўЄЧЛХЛіЄђЄЕЄЛЄщЄьЄЪЄЄЄтЄЮЄЋЁЃЄПЄжЄѓЅНЅьЁЂМъЩСЄЄЮАьЫчГЈЄЫЄтЛШЄЈЄНЄІЄЪЕЄЄЌЁФЁЃЄЪЄЩЄШЅаЅЋЬбСлЄђЄЗЄЦЄпЄПЄБЄЩЁЂВПЄђЄЩЄІГиНЌЄЕЄЛЄЦЄЩЄІЄЄЄІНшЭ§ЄђЄЋЄБЄьЄаЄЄЄЄЄЮЄЋЄЕЄУЄбЄъЅЄЅсЁМЅИЄЌЭЏЄЋЄЪЄЄЄЧЄЙЄЌЁЃ
ЛзЙЭЅсЅтЄЧЄЙЁЃЅЊЅСЄЯЬЕЄЄЄЧЄЙЁЃ
*1: ЄПЄЗЄЋЁЂЅЦЅьЅГЅрЄфЅИЅжЅъЄЧЄЯЄНЄІЄЄЄІЅыЁМЅыЄЌЄЂЄУЄПЄШЁЂЄЩЄГЄЋЄЧЪЙЄЄЄПЄшЄІЄЪЁФЁЃЭзЄЙЄыЄЫЁЂЕмКъНйДЦЦФЄЌХЯЄъЪтЄЄЄЦЄЄПЅЙЅПЅИЅЊЄЧЄЯЁЂЄНЄГЄоЄЧЛиФъЄЕЄьЄПЄъЄЗЄЦЄЄЄПЁЂЄЦЄЪЯУЄРЄУЄПЄшЄІЄЪЁФЁЃ
*2: ЄЄЄфЄоЄЂЁЂГЄГАЄЮЦАВшКюЖШЄЯЅЧЅИЅПЅыЄЫЄЪЄУЄЦЄЄЄЦБєЩЎЄЪЄѓЄЋЄтЄІЛШЄУЄЦЄЪЄЄЄЮЄРЄэЄІЄЗЁЃЅАЅьЁМЅЙЅБЁМЅыЄЮВшСќЄђХЩЄУЄЦЄЄЄЏЛХОхЄВЅФЁМЅыЄЯЦќЫмЄЮЅЙЅПЅИЅЊЦтЄЧЄлЄШЄѓЄЩЩсЕкЄЗЄЪЄЋЄУЄПЄЋЄщЁЂПЇЄѓЄЪЅЙЅПЅИЅЊЄЮМъЄђМкЄъЄЪЄЄуКюЄьЄЪЄЄАЪОхЁЂЄЩЄІЄЗЄЦЄтЄЩЄГЄЋЄЧ2УЭВНЄЙЄыУЪГЌЄЌЩЌЭзЄЫЄЪЄыЄѓЄРЄэЄІЄБЄЩЁЃ
*2: ЄЄЄфЄоЄЂЁЂГЄГАЄЮЦАВшКюЖШЄЯЅЧЅИЅПЅыЄЫЄЪЄУЄЦЄЄЄЦБєЩЎЄЪЄѓЄЋЄтЄІЛШЄУЄЦЄЪЄЄЄЮЄРЄэЄІЄЗЁЃЅАЅьЁМЅЙЅБЁМЅыЄЮВшСќЄђХЩЄУЄЦЄЄЄЏЛХОхЄВЅФЁМЅыЄЯЦќЫмЄЮЅЙЅПЅИЅЊЦтЄЧЄлЄШЄѓЄЩЩсЕкЄЗЄЪЄЋЄУЄПЄЋЄщЁЂПЇЄѓЄЪЅЙЅПЅИЅЊЄЮМъЄђМкЄъЄЪЄЄуКюЄьЄЪЄЄАЪОхЁЂЄЩЄІЄЗЄЦЄтЄЩЄГЄЋЄЧ2УЭВНЄЙЄыУЪГЌЄЌЩЌЭзЄЫЄЪЄыЄѓЄРЄэЄІЄБЄЩЁЃ
[ ЅФЅУЅГЄр ]
2023/04/26(Пх) [nЧЏСАЄЮЦќЕ]
#1 [pc] ГАЩеЄБHDDЄЮУцПШЄђРАЭ§Уц
ГАЩеЄБHDDЄЮЖѕЄЭЦЮЬЄЌИЗЄЗЄЏЄЪЄУЄЦЄЄПЄЮЄЧЁЂУцПШЄђРАЭ§УцЁЃ
ВОСлPCЭбHDDЅЄЅсЁМЅИЄђЄЄЄЏЄФЄЋКяНќЁЃЄЕЄЙЄЌЄЫ Ubuntu Linux 16.04 LTS ЄЧИЁОкКюЖШЄЯЄтЄІЄЗЄЪЄЄЄРЄэЄІЁФЁЃЗкЮЬLinux ЄЮ antiX ЄтЛШЄяЄЪЄЄЄшЄЪЁФЁЃDebian 10 ЄЯЁФЄГЄьЄЯЄтЄІЄЗЄаЄщЄЏЛФЄЗЄЦЄЊЄГЄІЄЋЁФЁЃ
ЅеЅЁЅЄЅыКяНќИхЁЂAuslogics Disk Defrag 8.0.24.0 ЄЧЅЧЅеЅщЅАЄђЄЋЄБЄЦЄпЄПЄтЄЮЄЮЁЂШОЪЌЄАЄщЄЄКЧХЌВНЄЗЄПЄШЄГЄэЄЧЁЂЄЪЄѓЄРЄЋЦАКюЄЗЄЦЄЪЄЄДЖЄИЄЮОѕТжЄЫЄЪЄУЄЦЄЗЄоЄІЁЃПєЪЌТдЄУЄЦЄыЄШЁЂЅСЅщЅСЅщЄШЅеЅЁЅЄЅыЄђКЧХЌВНЄЙЄыЄЮЄРЄБЄЩЁЂЄНЄЮИхЄоЄППєЪЌЄлЄЩЅРЅѓЅоЅъОѕТжЄЫЄЪЄыЁЃВПЄЌЕЏЄЄЦЄЄЄыЄЮЄРЄэЄІЁЃЪЬЄЮЅЧЅеЅщЅАЅНЅеЅШЄђЛюЄЗЄЦЄпЄПЄлЄІЄЌЄЄЄЄЄЮЄЋЄЪЁЃ
ВОСлPCЭбHDDЅЄЅсЁМЅИЄђЄЄЄЏЄФЄЋКяНќЁЃЄЕЄЙЄЌЄЫ Ubuntu Linux 16.04 LTS ЄЧИЁОкКюЖШЄЯЄтЄІЄЗЄЪЄЄЄРЄэЄІЁФЁЃЗкЮЬLinux ЄЮ antiX ЄтЛШЄяЄЪЄЄЄшЄЪЁФЁЃDebian 10 ЄЯЁФЄГЄьЄЯЄтЄІЄЗЄаЄщЄЏЛФЄЗЄЦЄЊЄГЄІЄЋЁФЁЃ
ЅеЅЁЅЄЅыКяНќИхЁЂAuslogics Disk Defrag 8.0.24.0 ЄЧЅЧЅеЅщЅАЄђЄЋЄБЄЦЄпЄПЄтЄЮЄЮЁЂШОЪЌЄАЄщЄЄКЧХЌВНЄЗЄПЄШЄГЄэЄЧЁЂЄЪЄѓЄРЄЋЦАКюЄЗЄЦЄЪЄЄДЖЄИЄЮОѕТжЄЫЄЪЄУЄЦЄЗЄоЄІЁЃПєЪЌТдЄУЄЦЄыЄШЁЂЅСЅщЅСЅщЄШЅеЅЁЅЄЅыЄђКЧХЌВНЄЙЄыЄЮЄРЄБЄЩЁЂЄНЄЮИхЄоЄППєЪЌЄлЄЩЅРЅѓЅоЅъОѕТжЄЫЄЪЄыЁЃВПЄЌЕЏЄЄЦЄЄЄыЄЮЄРЄэЄІЁЃЪЬЄЮЅЧЅеЅщЅАЅНЅеЅШЄђЛюЄЗЄЦЄпЄПЄлЄІЄЌЄЄЄЄЄЮЄЋЄЪЁЃ
[ ЅФЅУЅГЄр ]
2023/04/27(Ьк) [nЧЏСАЄЮЦќЕ]
#1 [pc] HDDЄЮЅЧЅеЅщЅАЄЌОхМъЄЏЙдЄЋЄЪЄЄ
USB3.0ЄЧРмТГЄЗЄЦЄЄЄыГАЩеЄБHDDЄЫТаЄЗЄЦЁЂDefraggler 2.22.995 ЄђЛШЄУЄЦЁжЖѕЄЮЮАшЄЮЅЧЅеЅщЅАЁзЄђЄЋЄБЄЦЄпЄшЄІЄШЄЗЄПЄБЄьЄЩЁЂСДСГНшЭ§ЄЌПЪЄоЄЪЄЄЁЃHDDЦтЄЮППЄѓУцЄЂЄПЄъЄЧЅСЅгЅСЅгЄШКЧХЌВНЄЗЄЦЄыЄпЄПЄЄЄРЄБЄЩЁФЁЃИхШОЄЮЄлЄІЄЫЅмЅГЅмЅГЄШЗфДжЄЌЄЂЄыЄЮЄРЄБЄЩЁЂЄНЄГЄщЄиЄѓЄЯАьРкНшЭ§ЄЗЄЦЄЏЄьЄЪЄЄЁФЁЃЄЩЄІИЋЄЦЄтНЊЄяЄъЄНЄІЄЪЕЄЧлЄЌЄЗЄЪЄЄЄЮЄЧЁЂФфЛпЄЗЄЦЄЗЄоЄУЄПЁЃ
ЄГЄЮМъЄЮЅФЁМЅыЄЧЁЂШЯАЯЄђЛиФъЄЗЄЦЅЧЅеЅщЅАЄЙЄыЄГЄШЄЯЄЧЄЄЪЄЄЄтЄЮЄРЄэЄІЄЋЁЃ
ЄГЄЮМъЄЮЅФЁМЅыЄЧЁЂШЯАЯЄђЛиФъЄЗЄЦЅЧЅеЅщЅАЄЙЄыЄГЄШЄЯЄЧЄЄЪЄЄЄтЄЮЄРЄэЄІЄЋЁЃ
[ ЅФЅУЅГЄр ]
2023/04/28(Жт) [nЧЏСАЄЮЦќЕ]
#1 [nitijyou] ЫПНъЄЫЙдЄУЄЦЄЄП
ЫПНъЄоЄЧХХЦАМЋХОМжЄЧЁЃ09:10-11:30ЄоЄЧКюЖШЁЃОмКйЄЯGRPЄЧЅсЅтЁЃ
[ ЅФЅУЅГЄр ]
2023/04/29(Хк) [nЧЏСАЄЮЦќЕ]
#1 [gimp] GIMP + G'MICЅзЅщЅАЅЄЅѓЄЌgplЅеЅЁЅЄЅыЄђЦЩЄпЙўЄѓЄЧЄЏЄьЄЪЄЄ
Windows10 x64 22H2 + GIMP 2.10.32 Portable 64bit samjШЧОхЄЧЁЂG'MICЅзЅщЅАЅЄЅѓ 3.1.3 ЄЮ Colorize (Interactive) ЄђЛШЄУЄЦРўВшЄЮПЇХЩЄъЪЌЄБЄђЄЗЄшЄІЄШЄЗЄПЄШЄГЄэЁЂ.gplЅеЅЁЅЄЅы(GIMPЅбЅьЅУЅШЅеЅЁЅЄЅы)ЄђЦЩЄпЙўЄѓЄЧЄЏЄьЄЪЄЄЩдЖёЙчЄЌЄЂЄыЄГЄШЄЫЕЄЄХЄЄЄПЁЃЫмЭшЁЂЅбЅьЅУЅШЄЌЩНМЈЄЕЄьЄыЄЯЄКЄЮЅІЅЄЅѓЅЩЅІЦтЄЌЁЂППЄУЙѕЄЪЄоЄоЁЃ
GIMP 2.8.22 Portable 32bit + G'MIC 2.4.2 32bit ЄђЛюЄЗЄПЄШЄГЄэЁЂЄГЄСЄщЄЯЁЂ.gplЅеЅЁЅЄЅыЄтЄСЄуЄѓЄШЦЩЄпЙўЄсЄПЄшЄІЄЧЁЂЅбЅьЅУЅШЅІЅЄЅѓЅЩЅІЦтЄЫЅбЅьЅУЅШЄЌЩНМЈЄЕЄьЄПЁЃ
ЄоЄПЁЂGIMP 2.10.34 Portable + G'MIC 3.2.4 64bit ЄђЛюЄЗЄПЄШЄГЄэЁЂЄГЄСЄщЄЧЄтЁЂ.gpl ЄтЦЩЄпЙўЄсЄЦЅбЅьЅУЅШЅІЅЄЅѓЅЩЅІЦтЄЫЅбЅьЅУЅШЄЌЩНМЈЄЕЄьЄПЁЃ
samjШЧЄЫЄРЄБЦўЄУЄСЄуЄУЄЦЄыЅаЅАЄУЄнЄЄЕЄЧлЄЌЄЙЄыЁЃЄЄЄфЄоЄЂЁЂЅбЅьЅУЅШЄђЛШЄяЄКЄЫКюЖШЄЙЄьЄаЄЄЄЄЄѓЄРЄБЄЩЁЃ
GIMP 2.8.22 Portable 32bit + G'MIC 2.4.2 32bit ЄђЛюЄЗЄПЄШЄГЄэЁЂЄГЄСЄщЄЯЁЂ.gplЅеЅЁЅЄЅыЄтЄСЄуЄѓЄШЦЩЄпЙўЄсЄПЄшЄІЄЧЁЂЅбЅьЅУЅШЅІЅЄЅѓЅЩЅІЦтЄЫЅбЅьЅУЅШЄЌЩНМЈЄЕЄьЄПЁЃ
ЄоЄПЁЂGIMP 2.10.34 Portable + G'MIC 3.2.4 64bit ЄђЛюЄЗЄПЄШЄГЄэЁЂЄГЄСЄщЄЧЄтЁЂ.gpl ЄтЦЩЄпЙўЄсЄЦЅбЅьЅУЅШЅІЅЄЅѓЅЩЅІЦтЄЫЅбЅьЅУЅШЄЌЩНМЈЄЕЄьЄПЁЃ
samjШЧЄЫЄРЄБЦўЄУЄСЄуЄУЄЦЄыЅаЅАЄУЄнЄЄЕЄЧлЄЌЄЙЄыЁЃЄЄЄфЄоЄЂЁЂЅбЅьЅУЅШЄђЛШЄяЄКЄЫКюЖШЄЙЄьЄаЄЄЄЄЄѓЄРЄБЄЩЁЃ
Ё§ G'MIC + Colorize (Interactive) ЄЮЛШЄЄЪ§ :
G'MIC + Colorize (Interactive) ЄђЛШЄІЄШЁЂРўВшЄђЅЄЅЄДЖЄИЄЫХЩЄъЪЌЄБЄыЄГЄШЄЌЄЧЄЄыЁЃЛШЄЄЪ§ЄђЄЙЄУЄЋЄъЫКЄьЄЦЄПЄБЄЩЁЂРЮЄЮЦќЕЄЫЅсЅтЄЗЄЦЄЂЄУЄПЁЃ
_mieki256's diary - Krita Єф G'MICЅзЅщЅАЅЄЅѓЄђЛюЄЗЄЦЄЄЄПЄъ
ТОЄЫЄтЪиЭјЄЪЕЁЧНЄЌЄЂЄыЄБЄьЄЩЁЂЄГЄьЄтЄЙЄУЄЋЄъЫКЄьЄЦЄыЁФЁЃ
_mieki256's diary - G'MICЅзЅщЅАЅЄЅѓЄЧЅЂЅьЅГЅьЛюЄЗЄПЄъ
_mieki256's diary - Krita Єф G'MICЅзЅщЅАЅЄЅѓЄђЛюЄЗЄЦЄЄЄПЄъ
ТОЄЫЄтЪиЭјЄЪЕЁЧНЄЌЄЂЄыЄБЄьЄЩЁЂЄГЄьЄтЄЙЄУЄЋЄъЫКЄьЄЦЄыЁФЁЃ
_mieki256's diary - G'MICЅзЅщЅАЅЄЅѓЄЧЅЂЅьЅГЅьЛюЄЗЄПЄъ
[ ЅФЅУЅГЄр ]
#2 [gimp] GIMP 2.10.34 Portable ЄђЅЄЅѓЅЙЅШЁМЅыЄЗЄП
ЦАКюГЮЧЇЭбЄЫЁЂWindows10 x64 22H2ОхЄЧЁЂGIMP 2.10.34 Portable ЄђЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЁЃ
_GIMP Portable (image editor) | PortableApps.com
GIMP Portable ЄЯЁЂUSBЅсЅтЅъХљЄЫЦўЄьЄЦЁЂЄЩЄЮДФЖЄЫЛ§ЄУЄЦЄЄЄУЄЦЄтЦАЄЏОѕТжЄЫЄЗЄЦЄЂЄыGIMPЁЃЄтЄСЄэЄѓЁЂHDDЄфSSDЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЛШЄУЄЦЄтЄЄЄЄЁЃ
GIMPPortable_2.10.34.paf.exe ЄђDLЁЃМТЙдЄЙЄыЄШВђХрОьНъЄђПвЄЭЄЦЄЏЄыЁЃКЃВѓЄЯЁЂD:\Prog\Gimp-2.10.34-Portable\ ЄЫЦўЄьЄЦЄЊЄЄЄПЁЃ
ЅГЅьЄУЄЦЁЂ64bitШЧЄЮGIMPЄШЁЂ32bitШЧЄЮGIMPЁЂЄЩЄСЄщЄЌЦАЄЄЄЦЄЄЄыЄѓЄРЄэЄІЁФЁЉ G'MIC 3.2.4 ЄђЦГЦўЄЗЄЦЄпЄПЄБЄЩЁЂКЃЄЮ G'MIC ЄЯ 64bitШЧЄЗЄЋЄЪЄЄЄЮЄЧЁЂЅНЅьЄЌЦАЄЄЄЦЄыЄШЄЄЄІЄГЄШЄЯЁЂ64bitШЧЄЮGIMPЄЌЦАЄЄЄЦЄыЄЮЄЋЄЪЁФЁЉ
Windows10ЄЮЅПЅЙЅЏЅоЅЭЁМЅИЅуЄђГЋЄЄЄЦЁЂЅзЅэЅЛЅЙЄђГЮЧЇЄЗЄПЄШЄГЄэЁЂЁж32ЅгЅУЅШЁзЄШЄЯЩНМЈЄЕЄьЄЦЄЪЄЋЄУЄПЁЃЄШЄЄЄІЄГЄШЄЯЁЂ64bitШЧЄЮGIMPЄЌЦАЄЄЄЦЄыЄЮЄРЄэЄІЁЃЄПЄжЄѓЁЃ
_GIMP Portable (image editor) | PortableApps.com
GIMP Portable ЄЯЁЂUSBЅсЅтЅъХљЄЫЦўЄьЄЦЁЂЄЩЄЮДФЖЄЫЛ§ЄУЄЦЄЄЄУЄЦЄтЦАЄЏОѕТжЄЫЄЗЄЦЄЂЄыGIMPЁЃЄтЄСЄэЄѓЁЂHDDЄфSSDЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЛШЄУЄЦЄтЄЄЄЄЁЃ
GIMPPortable_2.10.34.paf.exe ЄђDLЁЃМТЙдЄЙЄыЄШВђХрОьНъЄђПвЄЭЄЦЄЏЄыЁЃКЃВѓЄЯЁЂD:\Prog\Gimp-2.10.34-Portable\ ЄЫЦўЄьЄЦЄЊЄЄЄПЁЃ
ЅГЅьЄУЄЦЁЂ64bitШЧЄЮGIMPЄШЁЂ32bitШЧЄЮGIMPЁЂЄЩЄСЄщЄЌЦАЄЄЄЦЄЄЄыЄѓЄРЄэЄІЁФЁЉ G'MIC 3.2.4 ЄђЦГЦўЄЗЄЦЄпЄПЄБЄЩЁЂКЃЄЮ G'MIC ЄЯ 64bitШЧЄЗЄЋЄЪЄЄЄЮЄЧЁЂЅНЅьЄЌЦАЄЄЄЦЄыЄШЄЄЄІЄГЄШЄЯЁЂ64bitШЧЄЮGIMPЄЌЦАЄЄЄЦЄыЄЮЄЋЄЪЁФЁЉ
Windows10ЄЮЅПЅЙЅЏЅоЅЭЁМЅИЅуЄђГЋЄЄЄЦЁЂЅзЅэЅЛЅЙЄђГЮЧЇЄЗЄПЄШЄГЄэЁЂЁж32ЅгЅУЅШЁзЄШЄЯЩНМЈЄЕЄьЄЦЄЪЄЋЄУЄПЁЃЄШЄЄЄІЄГЄШЄЯЁЂ64bitШЧЄЮGIMPЄЌЦАЄЄЄЦЄыЄЮЄРЄэЄІЁЃЄПЄжЄѓЁЃ
Ё§ G'MICЄђЅЄЅѓЅЙЅШЁМЅы :
GIMPЭбG'MICЅзЅщЅАЅЄЅѓ 3.2.4 64bitШЧЄђЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЊЄЄЄПЁЃ
_G'MIC - GREYC's Magic for Image Computing: A Full-Featured Open-Source Framework for Image Processing - Download
ЅЄЅѓЅЙЅШЁМЅщШЧЄШzipШЧЄЌЄЂЄыЄБЄьЄЩЁЂКЃВѓЄЯzipШЧЁЂgmic_3.2.4_gimp2.10_win64.zip ЄђDLЁЃВђХрЄЗЄЦЧЄАеЄЮОьНъЄЫУжЄЄЄЦЄЊЄЏЁЃ
GIMPТІЄЮРпФъЄЧЁЂЅзЅщЅАЅЄЅѓЅЧЅЃЅьЅЏЅШЅъЄЫЁЂG'MICЄђВђХрЄЗЄПОьНъЄђЛиФъЄЗЄЦЄЊЄБЄаЦГЦўЄЧЄЄыЁЃ
АЪВМЄЮЅкЁМЅИЄЫЄшЄыЄШЁЂPaint.NETШЧЄтЄЂЄыЄщЄЗЄЄЁЃ
_GIMP / Krita / Paint.NET ЄЫЁЂ500 МяЮрАЪОхЄЮЅеЅЃЅыЅПЄђФЩВУЄЗЄЦЄЏЄьЄыЅзЅщЅАЅЄЅѓЁжGЁЧMIC-QtЁз - GIGAЁЊЬЕЮСФЬПЎ
_G'MIC - GREYC's Magic for Image Computing: A Full-Featured Open-Source Framework for Image Processing - Download
ЅЄЅѓЅЙЅШЁМЅщШЧЄШzipШЧЄЌЄЂЄыЄБЄьЄЩЁЂКЃВѓЄЯzipШЧЁЂgmic_3.2.4_gimp2.10_win64.zip ЄђDLЁЃВђХрЄЗЄЦЧЄАеЄЮОьНъЄЫУжЄЄЄЦЄЊЄЏЁЃ
GIMPТІЄЮРпФъЄЧЁЂЅзЅщЅАЅЄЅѓЅЧЅЃЅьЅЏЅШЅъЄЫЁЂG'MICЄђВђХрЄЗЄПОьНъЄђЛиФъЄЗЄЦЄЊЄБЄаЦГЦўЄЧЄЄыЁЃ
АЪВМЄЮЅкЁМЅИЄЫЄшЄыЄШЁЂPaint.NETШЧЄтЄЂЄыЄщЄЗЄЄЁЃ
_GIMP / Krita / Paint.NET ЄЫЁЂ500 МяЮрАЪОхЄЮЅеЅЃЅыЅПЄђФЩВУЄЗЄЦЄЏЄьЄыЅзЅщЅАЅЄЅѓЁжGЁЧMIC-QtЁз - GIGAЁЊЬЕЮСФЬПЎ
[ ЅФЅУЅГЄр ]
#3 [cg_tools] Paint.NET Єђ5.0.3ЄЫЅЂЅУЅзЅЧЁМЅШЄЗЄЦЄпЄП
Windows10 x64 22H2 ОхЄЧЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄЂЄУЄП Paint.NET 4.3.11 ЄђЁЂ5.0.3 ЄЫЅЂЅУЅзЅЧЁМЅШЄЗЄЦЄпЄПЁЃ
_Paint.NET - Free Software for Digital Photo Editing
ЅГЅѓЅШЅэЁМЅыЅбЅЭЅыЗаЭГЄЧЁЂPaint.NET 4.3.11 ЄђЅЂЅѓЅЄЅѓЅЙЅШЁМЅыЁЃ
paint.net.5.0.3.install.anycpu.web.zip ЄђЅРЅІЅѓЅэЁМЅЩЄЗЄЦВђХрЄЙЄыЄШЁЂpaint.net.5.0.3.install.anycpu.web.exe ЄШЄЄЄІЅеЅЁЅЄЅыЄЌЦўЄУЄЦЄЄЄыЁЃМТЙдЄЙЄыЄШЁЂДФЖЄЫЙчЄяЄЛЄПЅЄЅѓЅЙЅШЁМЅщЄђЅРЅІЅѓЅэЁМЅЩЄЗЄЦЁЂPaint.NET 5.0.3 ЄЮЅЄЅѓЅЙЅШЁМЅыНшЭ§ЄЌЛЯЄоЄыЁЃКЃВѓЄЯЁЂC:\Prog\paint.net\ ЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЁЃ
_Paint.NET - Free Software for Digital Photo Editing
ЅГЅѓЅШЅэЁМЅыЅбЅЭЅыЗаЭГЄЧЁЂPaint.NET 4.3.11 ЄђЅЂЅѓЅЄЅѓЅЙЅШЁМЅыЁЃ
paint.net.5.0.3.install.anycpu.web.zip ЄђЅРЅІЅѓЅэЁМЅЩЄЗЄЦВђХрЄЙЄыЄШЁЂpaint.net.5.0.3.install.anycpu.web.exe ЄШЄЄЄІЅеЅЁЅЄЅыЄЌЦўЄУЄЦЄЄЄыЁЃМТЙдЄЙЄыЄШЁЂДФЖЄЫЙчЄяЄЛЄПЅЄЅѓЅЙЅШЁМЅщЄђЅРЅІЅѓЅэЁМЅЩЄЗЄЦЁЂPaint.NET 5.0.3 ЄЮЅЄЅѓЅЙЅШЁМЅыНшЭ§ЄЌЛЯЄоЄыЁЃКЃВѓЄЯЁЂC:\Prog\paint.net\ ЄЫЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЁЃ
Ё§ ЅзЅщЅАЅЄЅѓЄЌИХЄЏЄЦЅЈЅщЁМЄЌНаЄы :
КЃЄоЄЧЛШЄУЄЦЄПЅзЅщЅАЅЄЅѓ(.dll)ЄђЁЂPaint.NET 5.0.3 ЄЮЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅРЦтЄЫЅГЅдЁМЄЗЄЦЄпЄПЄБЄьЄЩЁЂПЇЁЙЄЪ .dll ЄЌЅЈЅщЁМЄђНаЄЗЄЦЄЄЄыЁФЁЃ
BoltBaitPack67.zip ЄђЦўМъЁЂВђХрЁЂМТЙдЄЗЄЦОхНёЄЅЄЅѓЅЙЅШЁМЅыЄЗЄПЄщЁЂЅЈЅщЁМЄђНаЄЙ .dll ЄЯЄЋЄЪЄъИКЄУЄЦЄЏЄьЄПЁЃ
_FREE Paint.NET Plugins
АЪВМЄЮ .dll ЄЯСъЪбЄяЄщЄКЅЈЅщЁМЄЌНаЄЦЄЄЄПЄЮЄЧЁЂКяНќЄЙЄыЄГЄШЄЫЄЗЄПЁЃ
CurtisBlackЅзЅщЅАЅЄЅѓЄЯЁЂPaint.NET 4.x ЄоЄЧЄЮТаБўЄШЄЄЄІЄГЄШЄщЄЗЄЄЁЃ
_Curtis' Plugin Pack (Update for 3.5.4) - Plugin Packs - paint.net Forum
Temperature.dll ЄЯЁЂBoltBait's FREE Paint.NET Plugins ЄЮРтЬРЅкЁМЅИЄЮУцЄЧЁЂЁжPaint.NET ЄЫЕЁЧНЄЌСШЄпЙўЄоЄьЄПЄЋЄщКяНќЄЗЄПЁзЄШНёЄЋЄьЄЦЄПЁЃPaint.NET 5.x ЄЧЄЯЄЂЄЈЄЦЦГЦўЄЙЄыЩЌЭзЄЯЄЪЄЄЄЮЄРЄэЄІЁЃЄПЄжЄѓЁЃ
BoltBaitPack67.zip ЄђЦўМъЁЂВђХрЁЂМТЙдЄЗЄЦОхНёЄЅЄЅѓЅЙЅШЁМЅыЄЗЄПЄщЁЂЅЈЅщЁМЄђНаЄЙ .dll ЄЯЄЋЄЪЄъИКЄУЄЦЄЏЄьЄПЁЃ
_FREE Paint.NET Plugins
АЪВМЄЮ .dll ЄЯСъЪбЄяЄщЄКЅЈЅщЁМЄЌНаЄЦЄЄЄПЄЮЄЧЁЂКяНќЄЙЄыЄГЄШЄЫЄЗЄПЁЃ
- CurtisBlack.Common.dll
- CurtisBlack.Effects.dll
- CurtisBlack.Resources.dll
- Temperature.dll
CurtisBlackЅзЅщЅАЅЄЅѓЄЯЁЂPaint.NET 4.x ЄоЄЧЄЮТаБўЄШЄЄЄІЄГЄШЄщЄЗЄЄЁЃ
_Curtis' Plugin Pack (Update for 3.5.4) - Plugin Packs - paint.net Forum
Temperature.dll ЄЯЁЂBoltBait's FREE Paint.NET Plugins ЄЮРтЬРЅкЁМЅИЄЮУцЄЧЁЂЁжPaint.NET ЄЫЕЁЧНЄЌСШЄпЙўЄоЄьЄПЄЋЄщКяНќЄЗЄПЁзЄШНёЄЋЄьЄЦЄПЁЃPaint.NET 5.x ЄЧЄЯЄЂЄЈЄЦЦГЦўЄЙЄыЩЌЭзЄЯЄЪЄЄЄЮЄРЄэЄІЁЃЄПЄжЄѓЁЃ
Ё§ РЮЄЮЅаЁМЅИЅчЅѓЄЌЦўМъЄЧЄЄЪЄЄ :
РЮЄЮЅзЅщЅАЅЄЅѓЄђЛШЄЄЄПЄЄПЭЄЯАЪСАЄЮЅаЁМЅИЅчЅѓЄђЭјЭбЄЙЄыЄЗЄЋЄЪЄЄЄЮЄЋЄЪЄШЛзЄУЄПЄБЄьЄЩЁЂPaint.NET 4.x ЄђУЕЄЗЄЦЄтЦўМъЄЙЄыЄГЄШЄЌЄЧЄЄЪЄЄЁФЁЃ
ЄЋЄэЄІЄИЄЦЁЂPortableAppsШЧЄЮЅкЁМЅИЄЮВМЄЮЄлЄІЄЫЁЂ4.3.12ЁЂPaintDotNetPortableLegacyWin7_4.3.12.paf.exe ЄЌЄЂЄыЄГЄШЄЫЕЄЄХЄЄЄПЁЃЄЧЄтЁЂЅеЅЁЅЄЅыЬОЄЫWindows7ЭбЄШЄФЄЄЄЦЄЂЄыЄЪЁФЁЃ
_paint.net Portable (image and photo editor) | PortableApps.com
ИјМАЄЧЄтЁЂPortableШЧЄЌЭбАеЄЗЄЦЄЂЄыЄщЄЗЄЄЁЃ
_Paint-dot-netЄЮЅнЁМЅПЅжЅыШЧЄђЛюЄЗЄЦЄпЄы - treedownЁЧs Report
paint.net.4.3.12.portable.x64.zip ЄђЦўМъЄЙЄьЄаЁЂPaint.NET 4.3.12 ЄђЦАЄЋЄЛЄНЄІЁЃInternet Archive ЄђУЕЄЗЄПЄщЁЂ4.3.12 ЄЌИјГЋЄЕЄьЄЦЄПКЂЄЮЅкЁМЅИЄтЄЂЄУЄПЁЃ
_Releases - paintdotnet/release
ЄПЄРЁЂЅАЅАЄУЄЦЄПЄщЁЂИјМАЄЮАеИўЄШЄЗЄЦЁжЕьЅаЁМЅИЅчЅѓЄђЭпЄЗЄЌЄыЄЪЁзЄШНёЄЄЄЦЄЂЄУЄПЁЃ
_READ FIRST: The Rules (yes, you! read this!) (2013-12-21) - Forum Rules - paint.net Forum
КЧПЗШЧЄђЛШЄУЄЦЅаЅАЪѓЙ№ЄЗЄЦЄЏЄьЄЪЄЄЄШКЄЄыЄЋЄщБОЁЙЄШНёЄЄЄЦЄЂЄыЄшЄІЄЫИЋЄЈЄыЁЃЄПЄРЁЂЄНЄЮОѕТжЄРЄШЁЂРЮЄЮЦУФъЄЮЅзЅщЅАЅЄЅѓЄђЦАЄЋЄЗЄПЄЏЄЪЄУЄПЛўЄЫКЄЄъЄНЄІЄРЄЪЄШЁФЁЃСДЄЦЄЮЅзЅщЅАЅЄЅѓЄЌЫмТЮЄЮЅаЁМЅИЅчЅѓЅЂЅУЅзЄЫФЩНОЄЗЄЦЄЏЄьЄыЄяЄБЄЧЄтЄЪЄЄЄЗЁФЁЃ
ЄЋЄэЄІЄИЄЦЁЂPortableAppsШЧЄЮЅкЁМЅИЄЮВМЄЮЄлЄІЄЫЁЂ4.3.12ЁЂPaintDotNetPortableLegacyWin7_4.3.12.paf.exe ЄЌЄЂЄыЄГЄШЄЫЕЄЄХЄЄЄПЁЃЄЧЄтЁЂЅеЅЁЅЄЅыЬОЄЫWindows7ЭбЄШЄФЄЄЄЦЄЂЄыЄЪЁФЁЃ
_paint.net Portable (image and photo editor) | PortableApps.com
ИјМАЄЧЄтЁЂPortableШЧЄЌЭбАеЄЗЄЦЄЂЄыЄщЄЗЄЄЁЃ
_Paint-dot-netЄЮЅнЁМЅПЅжЅыШЧЄђЛюЄЗЄЦЄпЄы - treedownЁЧs Report
paint.net.4.3.12.portable.x64.zip ЄђЦўМъЄЙЄьЄаЁЂPaint.NET 4.3.12 ЄђЦАЄЋЄЛЄНЄІЁЃInternet Archive ЄђУЕЄЗЄПЄщЁЂ4.3.12 ЄЌИјГЋЄЕЄьЄЦЄПКЂЄЮЅкЁМЅИЄтЄЂЄУЄПЁЃ
_Releases - paintdotnet/release
ЄПЄРЁЂЅАЅАЄУЄЦЄПЄщЁЂИјМАЄЮАеИўЄШЄЗЄЦЁжЕьЅаЁМЅИЅчЅѓЄђЭпЄЗЄЌЄыЄЪЁзЄШНёЄЄЄЦЄЂЄУЄПЁЃ
_READ FIRST: The Rules (yes, you! read this!) (2013-12-21) - Forum Rules - paint.net Forum
КЧПЗШЧЄђЛШЄУЄЦЅаЅАЪѓЙ№ЄЗЄЦЄЏЄьЄЪЄЄЄШКЄЄыЄЋЄщБОЁЙЄШНёЄЄЄЦЄЂЄыЄшЄІЄЫИЋЄЈЄыЁЃЄПЄРЁЂЄНЄЮОѕТжЄРЄШЁЂРЮЄЮЦУФъЄЮЅзЅщЅАЅЄЅѓЄђЦАЄЋЄЗЄПЄЏЄЪЄУЄПЛўЄЫКЄЄъЄНЄІЄРЄЪЄШЁФЁЃСДЄЦЄЮЅзЅщЅАЅЄЅѓЄЌЫмТЮЄЮЅаЁМЅИЅчЅѓЅЂЅУЅзЄЫФЩНОЄЗЄЦЄЏЄьЄыЄяЄБЄЧЄтЄЪЄЄЄЗЁФЁЃ
Ё§ G'MICЅзЅщЅАЅЄЅѓЄђЅЄЅѓЅЙЅШЁМЅы :
Paint.NETЭбЄЮG'MICЅзЅщЅАЅЄЅѓЄтЅЄЅѓЅЙЅШЁМЅыЄЗЄЦЄпЄПЁЃ
_Releases - 0xC0000054/pdn-gmic
_GIMP / Krita / Paint.NET ЄЫЁЂ500 МяЮрАЪОхЄЮЅеЅЃЅыЅПЄђФЩВУЄЗЄЦЄЏЄьЄыЅзЅщЅАЅЄЅѓЁжGЁЧMIC-QtЁз - GIGAЁЊЬЕЮСФЬПЎ
ИНЙдШЧ G'MIC ЄЮЅаЁМЅИЅчЅѓЄЯЁЂ3.2.4ЁЃGmic_win64.zip ЄђDLЄЗЄЦВђХрЁЃGmic.dll ЄШ gmicЅеЅЉЅыЅРЄЌЦўЄУЄЦЄЄЄыЄЮЄЧЁЂPaint.NETЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР\Effects\ ЄЫЅГЅдЁМЁЃ
Paint.NET 5.0.3 ЄђЕЏЦАЄЗЄЦЁЂЅЈЅеЅЇЅЏЅШ ЂЊ Advanced ЂЊ G'MIC-Qt ЄђСЊЄйЄа G'MICЄЌЕЏЦАЄЙЄыЁЃ
ЄПЄРЁЂG'MICЄЧНшЭ§ИхЁЂНаЮЯЅьЅЄЅфЁМЄЯЁЂЛиФъЄЗЄПЪнТИЅеЅЉЅыЅРЦтЄЫpngВшСќЄШЄЗЄЦЪнТИЄЕЄьЄыЁЃGIMPЄЮЄшЄІЄЫЁЂГЋЄЄЄЦЄыВшСќЄЮЅІЅЄЅѓЅЩЅІЦтЄЫЅьЅЄЅфЁМЄШЄЗЄЦФЩВУЄЕЄьЄыЄяЄБЄЧЄЯЄЪЄЄЄЂЄПЄъЄЌЄСЄчЄУЄШЩдЪиЄЋЄтЄЗЄьЄЪЄЄЁЃ
_Releases - 0xC0000054/pdn-gmic
_GIMP / Krita / Paint.NET ЄЫЁЂ500 МяЮрАЪОхЄЮЅеЅЃЅыЅПЄђФЩВУЄЗЄЦЄЏЄьЄыЅзЅщЅАЅЄЅѓЁжGЁЧMIC-QtЁз - GIGAЁЊЬЕЮСФЬПЎ
ИНЙдШЧ G'MIC ЄЮЅаЁМЅИЅчЅѓЄЯЁЂ3.2.4ЁЃGmic_win64.zip ЄђDLЄЗЄЦВђХрЁЃGmic.dll ЄШ gmicЅеЅЉЅыЅРЄЌЦўЄУЄЦЄЄЄыЄЮЄЧЁЂPaint.NETЅЄЅѓЅЙЅШЁМЅыЅеЅЉЅыЅР\Effects\ ЄЫЅГЅдЁМЁЃ
Paint.NET 5.0.3 ЄђЕЏЦАЄЗЄЦЁЂЅЈЅеЅЇЅЏЅШ ЂЊ Advanced ЂЊ G'MIC-Qt ЄђСЊЄйЄа G'MICЄЌЕЏЦАЄЙЄыЁЃ
ЄПЄРЁЂG'MICЄЧНшЭ§ИхЁЂНаЮЯЅьЅЄЅфЁМЄЯЁЂЛиФъЄЗЄПЪнТИЅеЅЉЅыЅРЦтЄЫpngВшСќЄШЄЗЄЦЪнТИЄЕЄьЄыЁЃGIMPЄЮЄшЄІЄЫЁЂГЋЄЄЄЦЄыВшСќЄЮЅІЅЄЅѓЅЩЅІЦтЄЫЅьЅЄЅфЁМЄШЄЗЄЦФЩВУЄЕЄьЄыЄяЄБЄЧЄЯЄЪЄЄЄЂЄПЄъЄЌЄСЄчЄУЄШЩдЪиЄЋЄтЄЗЄьЄЪЄЄЁЃ
[ ЅФЅУЅГЄр ]
2023/04/30(Цќ) [nЧЏСАЄЮЦќЕ]
#1 [gimp] GIMP + G'MICЄЧВшСќЦтЄЮАьЩєЄђДёЮяЄЫКяНќЄЗЄПЄЄ
GIMP 2.10.34 Portable + G'MICЅзЅщЅАЅЄЅѓ 3.2.4 64bit ЄЧЁЂRepair - Inpaint [Multi-Scale] ЅеЅЃЅыЅПЄЮЛШЄЄЪ§ЄђФДЄйЄЦЄПЁЃOSЄЯWindows10 x64 22H2ЁЃ
ЄЩЄѓЄЪЄГЄШЄЌЄЧЄЄыЄЋЄШИРЄІЄШЁЂЮуЄЈЄаАЪВМЄЮЄшЄІЄЫЁЂВшСќЄЮАьЩєЪЌЄђЁЂШцГгХЊДёЮяЄЫКяНќ/ОУЕюЄЙЄыЄГЄШЄЌЄЧЄЄыЁЃ

_ИЕВшСќ
_НшЭ§ВшСќ
ЄЛЄУЄЋЄЏЄРЄЋЄщЛШЄЄЪ§ЄђЅсЅтЄЗЄЦЄЊЄЏЁЃG'MICЅзЅщЅАЅЄЅѓЄЯДћЄЫЅЄЅѓЅЙЅШЁМЅыКбЄпЄЧЄЂЄыЄГЄШЁЃ
ЄЩЄѓЄЪЄГЄШЄЌЄЧЄЄыЄЋЄШИРЄІЄШЁЂЮуЄЈЄаАЪВМЄЮЄшЄІЄЫЁЂВшСќЄЮАьЩєЪЌЄђЁЂШцГгХЊДёЮяЄЫКяНќ/ОУЕюЄЙЄыЄГЄШЄЌЄЧЄЄыЁЃ
_ИЕВшСќ
{kind=link}
{kind=link}
_НшЭ§ВшСќ
{kind=link}
{kind=link}
ЄЛЄУЄЋЄЏЄРЄЋЄщЛШЄЄЪ§ЄђЅсЅтЄЗЄЦЄЊЄЏЁЃG'MICЅзЅщЅАЅЄЅѓЄЯДћЄЫЅЄЅѓЅЙЅШЁМЅыКбЄпЄЧЄЂЄыЄГЄШЁЃ
Ё§ ЛШЄЄЪ§ :
GIMPЄЧИЕВшСќЄђГЋЄЄЄЦЁФЁЃ
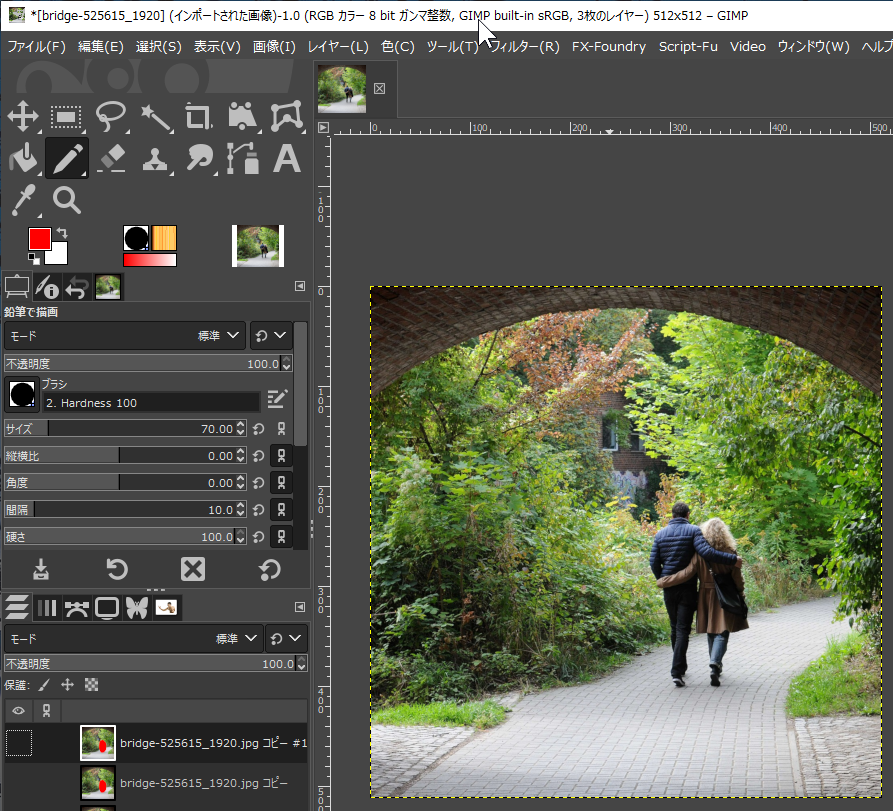
КяНќЄЗЄПЄЄЩєЪЌЄђЁЂРжПЇ(#ff0000, R:255, G:0, B:0)ЄЧХЩЄъФйЄЙЁЃ
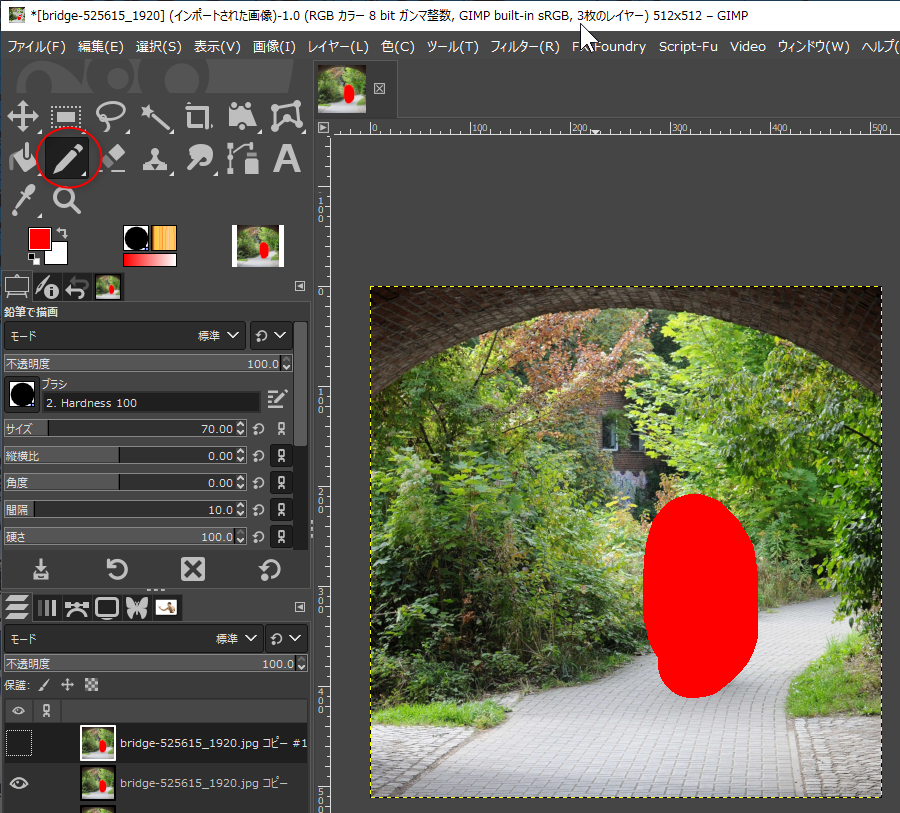
ХЩЄъФйЄЙЛўЄЯЁЂЅжЅщЅЗЅФЁМЅыЄИЄуЄЪЄЏЄЦЁЂБєЩЎЅФЁМЅыЄђЛШЄІЄШЮЩЄЄЁЃБєЩЎЅФЁМЅыЄђЛШЄІЄГЄШЄЧЁЂХЩЄъФйЄЙЩєЪЌЄЮЮиГдЄЫЅЂЅѓЅСЅЈЅЄЅъЅЂЅЙЄЌЄЋЄЋЄщЄЪЄЄЄшЄІЄЫЄЙЄыЁЃЅЂЅѓЅСЅЈЅЄЅъЅЂЅЙЄЌЄЋЄЋЄУЄЦЄыЄШЁЂЄНЄГЄЮЩєЪЌЄЯЅеЅЃЅыЅПНшЭ§ЄђЄЗЄЦЄЏЄьЄЪЄЄЄЮЄЧЁЂНаЮЯВшСќЄЌЅДЅпЄРЄщЄБЄЫЄЪЄУЄЦЄЗЄоЄІЁЃ
ЄоЄПЁЂХЩЄъФйЄЙПЇЄЯЁЂЦУФъЄЮАьПЇЄЫЄЕЄЈЄЪЄУЄЦЄЄЄьЄаЁЂРжЄИЄуЄЪЄЏЄЦЄтЄЄЄЄЁЃИхЄЧЄЩЄЮПЇЄђНшЭ§ТаОнЄЫЄЙЄыЄЋСЊЄжЄГЄШЄтЄЧЄЄыЄЮЄЧЁЃ
GIMPЄЮЅсЅЫЅхЁМЄЋЄщЁЂЅеЅЃЅыЅП ЂЊ G'MIC-Qt... ЄђИЦЄгНаЄЙЁЃ
Repair ЂЊ Inpaint [Multi-Scale]ЁЂЄђСЊЄжЁЃЩЌЭзЄЪЄщЅбЅщЅсЁМЅПЄђЯЎЄУЄЦЁЂКЧИхЄЫЁжOKЁзЅмЅПЅѓЄђЅЏЅъЅУЅЏЁЃ
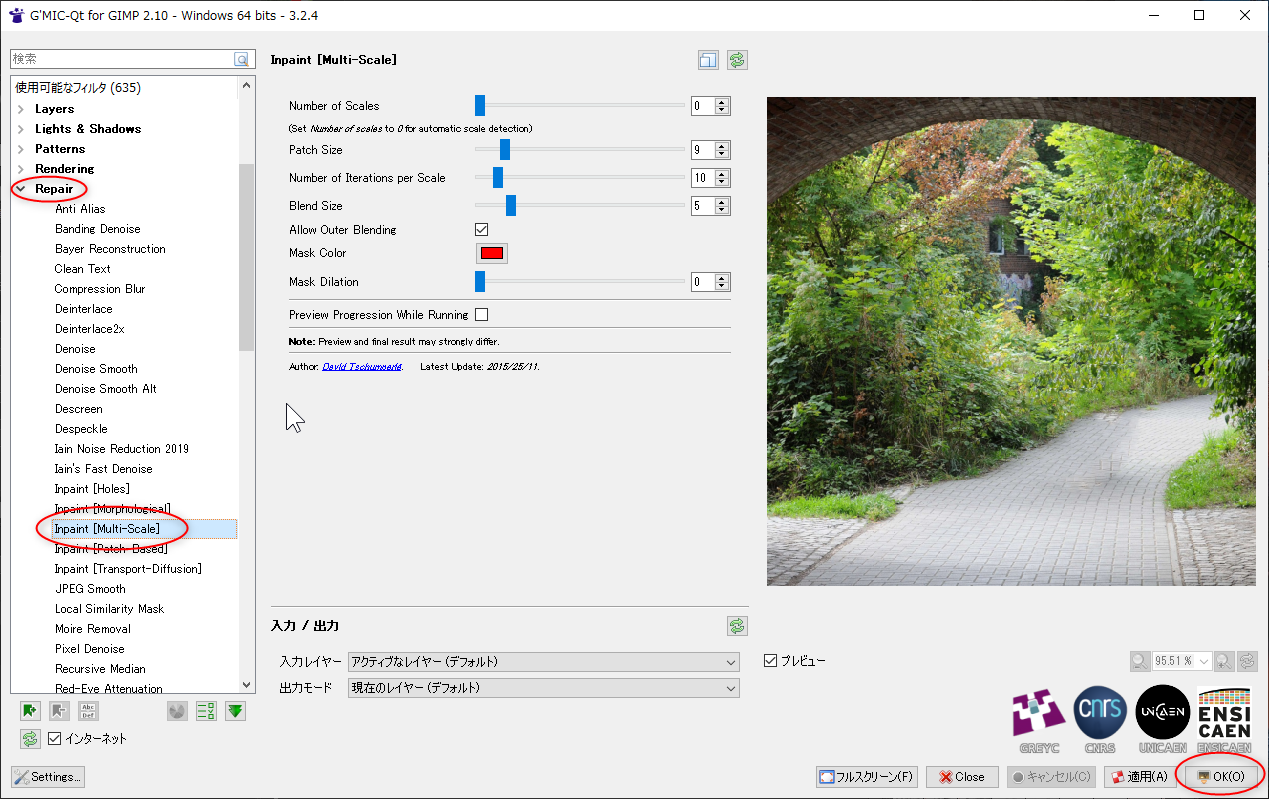
ЅЧЅеЅЉЅыЅШЄЧЄЯЁЂMask Color ЄЌРж(#ff0000)ЄЫЄЪЄУЄЦЄЄЄыЄЮЄЧЁЂРжЄЄЄШЄГЄэЄЫЄРЄБЅеЅЃЅыЅПНшЭ§ЄђЄЋЄБЄЦЄЏЄьЄыЁЃАуЄІПЇЄЧХЩЄУЄПОьЙчЄЯЁЂЄГЄГЄЧЛиФъЄЗФОЄЛЄаЄЄЄЄЁЃ
РжЄЄЄШЄГЄэЄРЄБЄђКяНќЄЗЄЦЁЂМўЪеЄЮВшСЧЄЧЅЄЅЄДЖЄИЄЫЫфЄсПдЄЏЄЗЄЦЄЏЄьЄПЁЃ

КяНќЄЗЄПЄЄЩєЪЌЄђЁЂРжПЇ(#ff0000, R:255, G:0, B:0)ЄЧХЩЄъФйЄЙЁЃ
ХЩЄъФйЄЙЛўЄЯЁЂЅжЅщЅЗЅФЁМЅыЄИЄуЄЪЄЏЄЦЁЂБєЩЎЅФЁМЅыЄђЛШЄІЄШЮЩЄЄЁЃБєЩЎЅФЁМЅыЄђЛШЄІЄГЄШЄЧЁЂХЩЄъФйЄЙЩєЪЌЄЮЮиГдЄЫЅЂЅѓЅСЅЈЅЄЅъЅЂЅЙЄЌЄЋЄЋЄщЄЪЄЄЄшЄІЄЫЄЙЄыЁЃЅЂЅѓЅСЅЈЅЄЅъЅЂЅЙЄЌЄЋЄЋЄУЄЦЄыЄШЁЂЄНЄГЄЮЩєЪЌЄЯЅеЅЃЅыЅПНшЭ§ЄђЄЗЄЦЄЏЄьЄЪЄЄЄЮЄЧЁЂНаЮЯВшСќЄЌЅДЅпЄРЄщЄБЄЫЄЪЄУЄЦЄЗЄоЄІЁЃ
ЄоЄПЁЂХЩЄъФйЄЙПЇЄЯЁЂЦУФъЄЮАьПЇЄЫЄЕЄЈЄЪЄУЄЦЄЄЄьЄаЁЂРжЄИЄуЄЪЄЏЄЦЄтЄЄЄЄЁЃИхЄЧЄЩЄЮПЇЄђНшЭ§ТаОнЄЫЄЙЄыЄЋСЊЄжЄГЄШЄтЄЧЄЄыЄЮЄЧЁЃ
GIMPЄЮЅсЅЫЅхЁМЄЋЄщЁЂЅеЅЃЅыЅП ЂЊ G'MIC-Qt... ЄђИЦЄгНаЄЙЁЃ
Repair ЂЊ Inpaint [Multi-Scale]ЁЂЄђСЊЄжЁЃЩЌЭзЄЪЄщЅбЅщЅсЁМЅПЄђЯЎЄУЄЦЁЂКЧИхЄЫЁжOKЁзЅмЅПЅѓЄђЅЏЅъЅУЅЏЁЃ
ЅЧЅеЅЉЅыЅШЄЧЄЯЁЂMask Color ЄЌРж(#ff0000)ЄЫЄЪЄУЄЦЄЄЄыЄЮЄЧЁЂРжЄЄЄШЄГЄэЄЫЄРЄБЅеЅЃЅыЅПНшЭ§ЄђЄЋЄБЄЦЄЏЄьЄыЁЃАуЄІПЇЄЧХЩЄУЄПОьЙчЄЯЁЂЄГЄГЄЧЛиФъЄЗФОЄЛЄаЄЄЄЄЁЃ
РжЄЄЄШЄГЄэЄРЄБЄђКяНќЄЗЄЦЁЂМўЪеЄЮВшСЧЄЧЅЄЅЄДЖЄИЄЫЫфЄсПдЄЏЄЗЄЦЄЏЄьЄПЁЃ
[ ЅФЅУЅГЄр ]
#2 [gimp] GIMP + G'MICЄЧЅьЅЄЅфЁМЙчРЎЄђМЋСГЄЪДЖЄИЄЫЄЗЄПЄЄ
GIMP 2.10.34 Portable + G'MICЅзЅщЅАЅЄЅѓ 3.2.4 64bit ЄђЛШЄУЄЦЁЂЅьЅЄЅфЁМЙчРЎЄЮИЋЄПЬмЄђМЋСГЄЪДЖЄИЄЫЄЗЄПЄЄЁЃLayers - Blend [Seamless] ЄЌЗыЙНЛШЄЈЄНЄІЄЪЄЮЄЧФДЄйЄЦЄпЄПЁЃOSЄЯWindows10 x64 22H2ЁЃ
ЄЩЄІЄЄЄІЄГЄШЄЌЄЧЄЄыЄЋЄШИРЄІЄШЁФЁЃЅьЅЄЅфЁМЄЮПЇФДЄђВМЄЮЅьЅЄЅфЁМЄШЙчЄІЄшЄІЄЫМЋЦАЄЧЪфРЕЄЗЄЦЁЂЙЙЄЫЁЂЅьЅЄЅфЁМЄЮМўЪеЄЌВМЄЮЅьЅЄЅфЁМЄШЦыРїЄрЄшЄІЄЫЄмЄЋЄЗЄЦ(?)ЄЏЄьЄыЁЃ

ЄЩЄІЄЄЄІЄГЄШЄЌЄЧЄЄыЄЋЄШИРЄІЄШЁФЁЃЅьЅЄЅфЁМЄЮПЇФДЄђВМЄЮЅьЅЄЅфЁМЄШЙчЄІЄшЄІЄЫМЋЦАЄЧЪфРЕЄЗЄЦЁЂЙЙЄЫЁЂЅьЅЄЅфЁМЄЮМўЪеЄЌВМЄЮЅьЅЄЅфЁМЄШЦыРїЄрЄшЄІЄЫЄмЄЋЄЗЄЦ(?)ЄЏЄьЄыЁЃ
Ё§ ЛШЄЄЪ§ :
ВМЅьЅЄЅфЁМЄЫЄЪЄыВшСќЄЯАЪВМЁЃ

ОхЄЫУжЄЏЅьЅЄЅфЁМЄЯАЪВМЁЃ

ЄНЄЮЄоЄоЅьЅЄЅфЁМЙчРЎЁЂЄШЄЄЄІЄЋЅьЅЄЅфЁМЄђНХЄЭЄыЄШЁЂАЪВМЄЮЄшЄІЄЪИЋЄПЬмЄЫЄЪЄыЁЃЄЪЄЋЄЪЄЋЄЮЛЈЅГЅщДЖЁЃ

ЅеЅЃЅыЅП ЂЊ G'MIC-Qt... ЄђСЊЄѓЄЧЁЂLayers ЂЊ Blend [Seamless] ЄђСЊЄжЁЃ
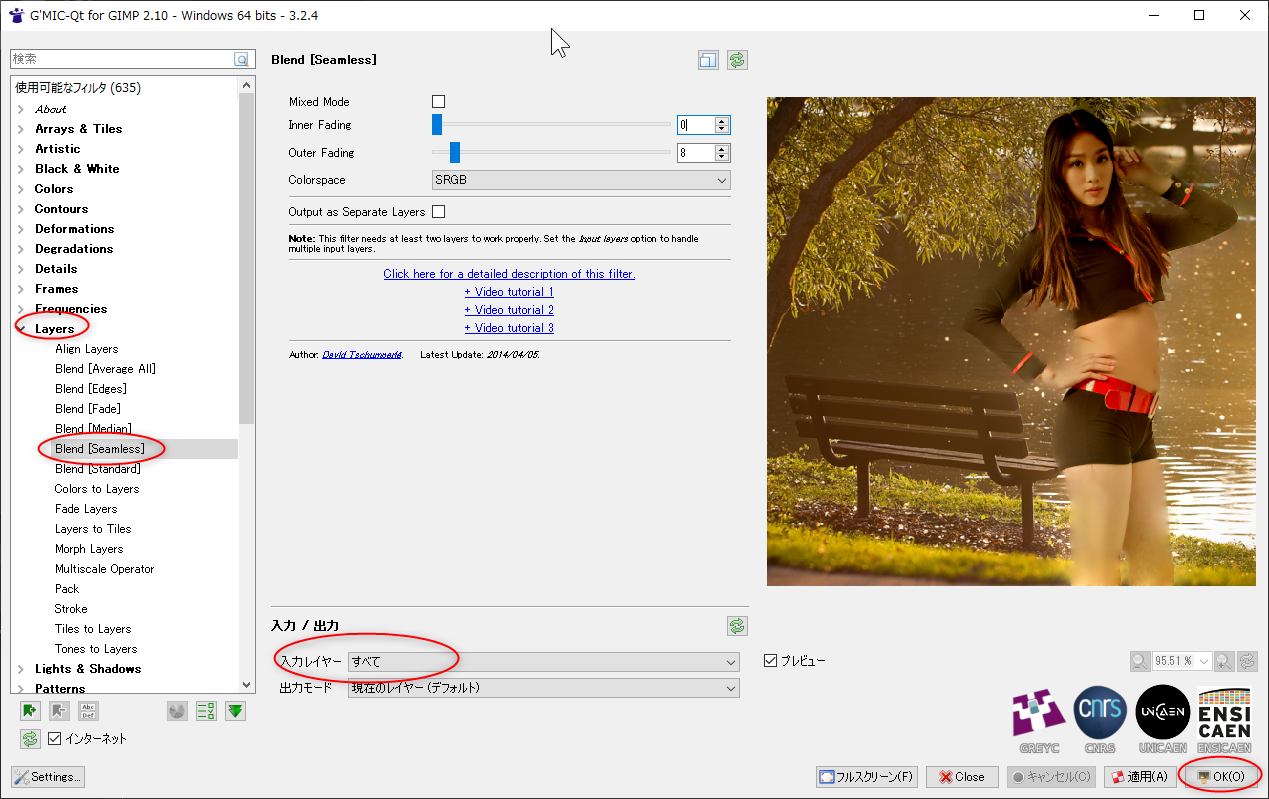
ЄСЄЪЄпЄЫЁЂЁжЦўЮЯЅьЅЄЅфЁМЁзЄЯЁжЄЙЄйЄЦЁзЁЂЄтЄЗЄЏЄЯЁЂЁжЅЂЅЏЅЦЅЃЅжЄЪЅьЅЄЅфЁМЄШЄНЄЮВМЄЮЅьЅЄЅфЁМЁзЄђСЊЄжЄГЄШЁЃ
АЪВМЄЮЄшЄІЄЪДЖЄИЄЫЄЪЄУЄПЁЃ

ЄНЄЮЄоЄоЅьЅЄЅфЁМЄђНХЄЭЄыЄшЄъЄЯПяЪЌЄШЅоЅЗЄЫЄЪЄУЄПЁЃЄЧЄтЁЂСъЪбЄяЄщЄКЛЈЅГЅщДЖЄЯЛФЄУЄЦЄыЄЪЄШЁФЁЃ
МўЄъЄЋЄщЦтЩєЄЫИўЄЋЄУЄЦЄмЄЋЄЗЄЦЄЄЄЏЄЛЄЄЄЋЁЂТЄЮЄЂЄПЄъЄЌШОЦЉЬРЄЫЄЪЄУЄЦЁЂЄСЄчЄУЄШЭЉЮюЄУЄнЄЏЄЪЄУЄЦЄЗЄоЄУЄПЁФЁЃКюЮуЄШЄЗЄЦЄЯЄСЄчЄУЄШЁЂЄЄЄфЁЂСДЄЏХЌРкЄЧЄЯЄЪЄЋЄУЄПЄЋЄтЁЃ
АЪВМЄЮКюЮуЄЮЄлЄІЄЌЛВЙЭЄЫЄЪЄъЄНЄІЁЃ
_Face Transfer using the G'MIC plug-in for GIMP - YouTube
_Video tutorial for using filter 'G'MIC / Layers / Blend [seamless]' - YouTube
ОхЄЫУжЄЏЅьЅЄЅфЁМЄЯАЪВМЁЃ
ЄНЄЮЄоЄоЅьЅЄЅфЁМЙчРЎЁЂЄШЄЄЄІЄЋЅьЅЄЅфЁМЄђНХЄЭЄыЄШЁЂАЪВМЄЮЄшЄІЄЪИЋЄПЬмЄЫЄЪЄыЁЃЄЪЄЋЄЪЄЋЄЮЛЈЅГЅщДЖЁЃ
ЅеЅЃЅыЅП ЂЊ G'MIC-Qt... ЄђСЊЄѓЄЧЁЂLayers ЂЊ Blend [Seamless] ЄђСЊЄжЁЃ
ЄСЄЪЄпЄЫЁЂЁжЦўЮЯЅьЅЄЅфЁМЁзЄЯЁжЄЙЄйЄЦЁзЁЂЄтЄЗЄЏЄЯЁЂЁжЅЂЅЏЅЦЅЃЅжЄЪЅьЅЄЅфЁМЄШЄНЄЮВМЄЮЅьЅЄЅфЁМЁзЄђСЊЄжЄГЄШЁЃ
АЪВМЄЮЄшЄІЄЪДЖЄИЄЫЄЪЄУЄПЁЃ
ЄНЄЮЄоЄоЅьЅЄЅфЁМЄђНХЄЭЄыЄшЄъЄЯПяЪЌЄШЅоЅЗЄЫЄЪЄУЄПЁЃЄЧЄтЁЂСъЪбЄяЄщЄКЛЈЅГЅщДЖЄЯЛФЄУЄЦЄыЄЪЄШЁФЁЃ
МўЄъЄЋЄщЦтЩєЄЫИўЄЋЄУЄЦЄмЄЋЄЗЄЦЄЄЄЏЄЛЄЄЄЋЁЂТЄЮЄЂЄПЄъЄЌШОЦЉЬРЄЫЄЪЄУЄЦЁЂЄСЄчЄУЄШЭЉЮюЄУЄнЄЏЄЪЄУЄЦЄЗЄоЄУЄПЁФЁЃКюЮуЄШЄЗЄЦЄЯЄСЄчЄУЄШЁЂЄЄЄфЁЂСДЄЏХЌРкЄЧЄЯЄЪЄЋЄУЄПЄЋЄтЁЃ
АЪВМЄЮКюЮуЄЮЄлЄІЄЌЛВЙЭЄЫЄЪЄъЄНЄІЁЃ
_Face Transfer using the G'MIC plug-in for GIMP - YouTube
_Video tutorial for using filter 'G'MIC / Layers / Blend [seamless]' - YouTube
[ ЅФЅУЅГЄр ]
АЪОхЁЂ30 ЦќЪЌЄЧЄЙЁЃ