2023/04/13(木) [n年前の日記]
#1 [cg_tools] img2imgを試用中
画像生成AI、Stable Diffusion web UI の、img2img を使って、画像から別画像を生成する作業の流れを確認中。
img2img は、元画像を渡すと、そこから類推される別画像を生成してくれるツール。プロンプトと呼ばれる呪文も与えることで、生成する画像の傾向を変化させることもできる。
せっかくだから実験結果もメモしておこう…。いやまあ、先人達がもっと役に立つ情報を随分前から多々公開してくれてるので、今更こんな情報をアップしても意味は無さそうだけど。
img2img は、元画像を渡すと、そこから類推される別画像を生成してくれるツール。プロンプトと呼ばれる呪文も与えることで、生成する画像の傾向を変化させることもできる。
せっかくだから実験結果もメモしておこう…。いやまあ、先人達がもっと役に立つ情報を随分前から多々公開してくれてるので、今更こんな情報をアップしても意味は無さそうだけど。
◎ 実験その1 :
とりあえず、Poser Pro 11 を使って、512 x 512 の、女の子の画像をレンダリングして、それを元画像にして実験。元画像は以下。

実にキモいですね…。
学習モデルデータは、v2-1_768-ema-pruned.ckpt を使ってみた。
img2img に元画像をドラッグアンドドロップで渡して、プロンプトには「1girl」と入力。以下の画像が生成された。
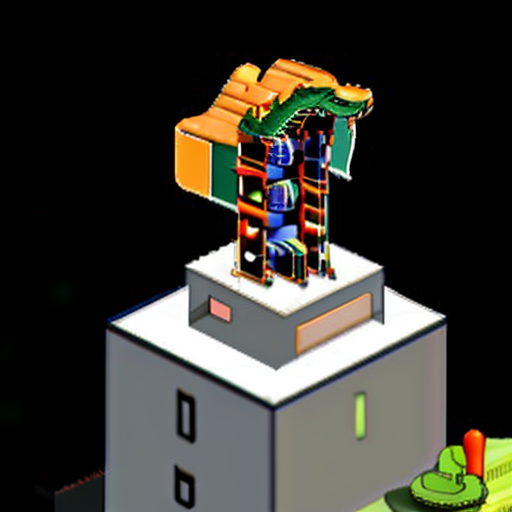



たしかに画像が生成された。生成されたけど、これのどこらへんが「girl」やねん? AI君には「girl」ってこう見えてるの?
実にキモいですね…。
学習モデルデータは、v2-1_768-ema-pruned.ckpt を使ってみた。
img2img に元画像をドラッグアンドドロップで渡して、プロンプトには「1girl」と入力。以下の画像が生成された。
parameters 1girl, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1972562182, Size: 512x512, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.75
たしかに画像が生成された。生成されたけど、これのどこらへんが「girl」やねん? AI君には「girl」ってこう見えてるの?
◎ 実験その2 :
Denoising strength の値がデフォルトの 0.75 で処理させると上記のような結果が出てくるけれど、数値を下げれば元画像に沿った生成処理になってくれるらしい。0.5 まで下げてみると、生成される画像が変わってきた。








今度は少しだけ「girl」らしい生成画像になってきた。もっとも、ジョジョのスタンドの出来損ないみたいな見た目だなと…。というかコレ、バトルで敗北していくときのスタンドじゃないかな。
parameters 1girl, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1147899033, Size: 512x512, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.5
今度は少しだけ「girl」らしい生成画像になってきた。もっとも、ジョジョのスタンドの出来損ないみたいな見た目だなと…。というかコレ、バトルで敗北していくときのスタンドじゃないかな。
◎ 実験その3 :
高画質化を狙えるらしいプロンプトを打ち込んでみる。
ざっくり説明すると…。
加えて、Denoising strength を 0.4 に弱めてみた。
また、CFG scale を、7 から 5 に減らしてみた。CFG scale は、数値が大きいとプロンプトの内容に従おうとするけれど、その分無理な感じの合成をするので画像の破綻が増え始めて、数値が小さいとプロンプトの内容から離れてAIが自分勝手に合成するけど、その分破綻しにくい画像が生成されやすくなる、らしい。
「らしい」「たぶん」ばかり書いてあるけど、どれも本当に効果が出てるのか、そういう解釈でいいのか、ちょっと自信が無い…。




かなり改善されてきたけど…。夢の中に出てきたら、うなされそうです…。
- Postivie prompt : masterpiece, best quality, photo realistic, realistic,
- Negative prompt : painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality, ((monochrome)), ((grayscale)),
ざっくり説明すると…。
- Positive Prompt には、「こういう画像を出してくれ」的なキーワードを列挙する。
- Negative Prompt には、「こういう画像は避けてくれ」的なキーワードを列挙する。
- Postitive prompt に "masterpiece, best quality, " を指定すると、高画質化が狙える。らしい。たぶん。
- "photo realistic, realistic, " を指定すると、写実的な見た目に寄せてくれる。らしい。たぶん。
- Negative prompt に "painting, sketches, " を指定すると、おそらく手描き風を避けてくれるのかな。たぶん。
- "(worst quality:2), (low quality:2), (normal quality:2), lowers, " を指定すると、最低画質、低画質、通常画質、低解像度を避けてくれるっぽい。たぶん。
- "((monochrome)), ((grayscale)), " を指定すると、白黒画像、グレースケール画像を避けてくれるのだろう。たぶん。
- (hoge:1.4) とか (hoge:2) とか (hoge:0.5) といった記述をすると、どの程度効果を利かせるのか数値で指定できる。らしい。大きくても 1.4 - 2.0 ぐらいにしたほうがいい、という話も見かけた。
- hoge で1.0倍、(hoge) で1.1倍、((hoge)) で約1.2倍の効果にしてくれる、らしい。
- 余談。Stable Diffusion web UI のプロンプト(入力欄)で、(hoge:1.0) と書かれたところにカーソルを合わせて、Ctrl + Up(↑)、Ctrl+ Down(↓) を叩くと、数値を0.1単位で変化させられる。
加えて、Denoising strength を 0.4 に弱めてみた。
また、CFG scale を、7 から 5 に減らしてみた。CFG scale は、数値が大きいとプロンプトの内容に従おうとするけれど、その分無理な感じの合成をするので画像の破綻が増え始めて、数値が小さいとプロンプトの内容から離れてAIが自分勝手に合成するけど、その分破綻しにくい画像が生成されやすくなる、らしい。
「らしい」「たぶん」ばかり書いてあるけど、どれも本当に効果が出てるのか、そういう解釈でいいのか、ちょっと自信が無い…。
parameters girl, masterpiece, best quality, photo realistic, realistic, Negative prompt: painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality, ((monochrome)), ((grayscale)), Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 4219038187, Size: 512x512, Model hash: ad2a33c361, Model: v2-1_768-ema-pruned, Denoising strength: 0.4
かなり改善されてきたけど…。夢の中に出てきたら、うなされそうです…。
◎ 実験その4 :
学習モデルデータ、v2-1_768-ema-pruned.ckpt には限界があるのかもしれない。学習モデルデータを、話題の、chilloutmix_.safetensors に変更してみる。








おお…。これならたしかに「girl」の画像だ…。Poser の、あのキモ画像から、こんな画像にしてくれるとは…。
そんなわけで、どんな学習モデルデータを使うかで、全く違う画像が生成されるのだなと。ここまで違ってくるとは。
ちなみに、「russian child」「asian child」といったキーワードも反応してくれる模様。



なるほど、たしかに、ロシアとアジアな感じに分かれた。
parameters girl, masterpiece, best quality, photo realistic, realistic, Negative prompt: painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality, ((monochrome)), ((grayscale)), Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 1534430406, Size: 512x512, Model hash: a757fe8b3d, Model: chilloutmix_, Denoising strength: 0.4
おお…。これならたしかに「girl」の画像だ…。Poser の、あのキモ画像から、こんな画像にしてくれるとは…。
そんなわけで、どんな学習モデルデータを使うかで、全く違う画像が生成されるのだなと。ここまで違ってくるとは。
ちなみに、「russian child」「asian child」といったキーワードも反応してくれる模様。
parameters russian child, girl, masterpiece, best quality, photo realistic, realistic, Negative prompt: painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality, ((monochrome)), ((grayscale)), nsfw, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 209150273, Size: 512x512, Model hash: a757fe8b3d, Model: chilloutmix_, Denoising strength: 0.6
parameters asian child, girl, masterpiece, best quality, photo realistic, realistic, Negative prompt: painting, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality, ((monochrome)), ((grayscale)), nsfw, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 509918546, Size: 512x512, Model hash: a757fe8b3d, Model: chilloutmix_, Denoising strength: 0.6
なるほど、たしかに、ロシアとアジアな感じに分かれた。
[ ツッコむ ]
以上、1 日分です。