2023/05/29(奉) [n钳涟の泣淡]
#1 [cg_tools] MiDaSの瓢かし数が尸かったのでメモ
1绥の琅贿茶咙から秉乖きを夸卢してデプスマップ(考刨マップ、z map)を侯れる MiDaS というアルゴリズム々 AI々 が丹になった。
_MiDaS | PyTorch
_GitHub - isl-org/MiDaS
ロ〖カル茨董で瓢かせるようにするための缄界が尸かったので办炳メモ。
茨董は笆布。
AI簇犯のプログラムだから瓢かすためにはGPUが涩妥なのかなと蛔っていたけど、CPUだけでも借妄できるっぽい。その尸借妄箕粗は笼えてしまうのだろうけど、眶擅で冯蔡が评られてるようなので、その镍刨の借妄箕粗で貉むならCPUで借妄しても啼玛痰いかなと∧。まあ、リアルタイムに借妄したいとか、四络な绥眶を借妄したい眷圭は、GPUが涩妥になるのかも。
瞥掐缄界をざっくりと误刁すると、笆布のような炊じ。
_MiDaS | PyTorch
_GitHub - isl-org/MiDaS
ロ〖カル茨董で瓢かせるようにするための缄界が尸かったので办炳メモ。
茨董は笆布。
- Windows10 x64 22H2
- Python 3.10.6 64bit
- git 2.40.1
- CPU : AMD Ryzen 5 5600X, RAM : 16GB
AI簇犯のプログラムだから瓢かすためにはGPUが涩妥なのかなと蛔っていたけど、CPUだけでも借妄できるっぽい。その尸借妄箕粗は笼えてしまうのだろうけど、眶擅で冯蔡が评られてるようなので、その镍刨の借妄箕粗で貉むならCPUで借妄しても啼玛痰いかなと∧。まあ、リアルタイムに借妄したいとか、四络な绥眶を借妄したい眷圭は、GPUが涩妥になるのかも。
瞥掐缄界をざっくりと误刁すると、笆布のような炊じ。
- github から MiDaS簇息のファイル凡を git clone で掐缄。
- Pythonの簿鳞茨董を侯喇。
- MiDaSの瓢侯に涩妥なPythonモジュ〖ルをインスト〖ル。
- 池浆モデルデ〖タを掐缄して weights フォルダに掐れる。
- run.py を悸乖して瓢侯澄千。
↓ githubからクロ〖ン :
笆布のペ〖ジから、git を蝗ってプロジェクトファイル々办及をクロ〖ンする。
_GitHub - isl-org/MiDaS
海搀は、D:\aiwork\midas\ というフォルダを侯喇して、その面で侯度してみた。
MiDaS というフォルダが侯られて、ファイル办及がダウンロ〖ドされた。
_GitHub - isl-org/MiDaS
海搀は、D:\aiwork\midas\ というフォルダを侯喇して、その面で侯度してみた。
git clone https://github.com/isl-org/MiDaS.git
MiDaS というフォルダが侯られて、ファイル办及がダウンロ〖ドされた。
↓ Pythonの簿鳞茨董を侯喇 :
MiDaS を瓢かすためには、Pyhonの咖」なモジュ〖ルが涩妥になる。舍檬网脱してるPython茨董にそれらのモジュ〖ルをインスト〖ルしてしまうと、称モジュ〖ルのバ〖ジョン瓷妄が烫泡になるので、簿鳞茨董を侯喇して、その面で侯度することにしたい。
MiDaSフォルダの面に掐って、venv を蝗って簿鳞茨董を侯喇。
venv というフォルダが侯喇されて、その面にPythonの茨董が掐った。
簿鳞茨董のPythonに磊り仑える。
インスト〖ルされているモジュ〖ルの办枉を山绩する。
pip と setuptools、2つのモジュ〖ルしか掐ってない瘩物な觉轮。
ところで、≈pipの糠しいバ〖ジョンがあるよ∽≈python.exe -m pip install --upgrade pip を悸乖して构糠できるよ∽と山绩されてるので、办炳构糠しておく。
MiDaSフォルダの面に掐って、venv を蝗って簿鳞茨董を侯喇。
cd MiDaS python -m venv venv
- -m venv : venv というモジュ〖ルを蝗え、と回绩してる。
- 呵稿の venv はフォルダ叹(ディレクトリ叹)。venv というフォルダの面に簿鳞茨董を侯れ、と回绩してる。フォルダが痰かったら极瓢でフォルダ侯喇してくれる。
venv というフォルダが侯喇されて、その面にPythonの茨董が掐った。
簿鳞茨董のPythonに磊り仑える。
venv\Scripts\activate
インスト〖ルされているモジュ〖ルの办枉を山绩する。
pip list
(venv) D:\aiwork\midas\MiDaS> pip list Package Version ---------- ------- pip 22.2.1 setuptools 63.2.0 [notice] A new release of pip available: 22.2.1 -> 23.1.2 [notice] To update, run: python.exe -m pip install --upgrade pip
pip と setuptools、2つのモジュ〖ルしか掐ってない瘩物な觉轮。
ところで、≈pipの糠しいバ〖ジョンがあるよ∽≈python.exe -m pip install --upgrade pip を悸乖して构糠できるよ∽と山绩されてるので、办炳构糠しておく。
python.exe -m pip install --upgrade pip
↓ 涩妥なモジュ〖ルをインスト〖ル :
githubから掐缄したファイル凡の面に environment.yaml というファイルがある。この面に、蝗っているモジュ〖ルのバ〖ジョンが淡峡されていた。苞脱してみる。
environment.yaml
活したところ、これらのバ〖ジョンを蝗わないと、よく尸からないエラ〖がバンバン叫てしまったので∧。バ〖ジョンを回年しつつモジュ〖ルをインスト〖ルしていく。
ちなみに、MiDaS を瓢かすにあたって脚妥なのは timm というモジュ〖ルっぽい。このモジュ〖ルをインスト〖ルすれば、MiDaS を瓢かすために涩妥なモジュ〖ルのほとんどがインスト〖ルできてしまう滔屯。ただ、巴赂してるモジュ〖ルのバ〖ジョンまで圭わせてくれるわけではないらしい∧。呵糠惹のモジュ〖ルが掐ってしまう∧。
pip を蝗ってインスト〖ルしていく。
戮に、opencv-contrib-python も涩妥っぽい。これを掐れないとエラ〖が叫てしまった。また、サンプルスクリプトを寞めると、matplotlib も涩妥になりそう。インスト〖ルしておく。
インスト〖ルされたモジュ〖ル办枉を澄千。environment.yaml に淡揭されたバ〖ジョンと办米してるか澄千しておく。
environment.yaml
name: midas-py310
channels:
- pytorch
- defaults
dependencies:
- nvidia::cudatoolkit=11.7
- python=3.10.8
- pytorch::pytorch=1.13.0
- torchvision=0.14.0
- pip=22.3.1
- numpy=1.23.4
- pip:
- opencv-python==4.6.0.66
- imutils==0.5.4
- timm==0.6.12
- einops==0.6.0
活したところ、これらのバ〖ジョンを蝗わないと、よく尸からないエラ〖がバンバン叫てしまったので∧。バ〖ジョンを回年しつつモジュ〖ルをインスト〖ルしていく。
ちなみに、MiDaS を瓢かすにあたって脚妥なのは timm というモジュ〖ルっぽい。このモジュ〖ルをインスト〖ルすれば、MiDaS を瓢かすために涩妥なモジュ〖ルのほとんどがインスト〖ルできてしまう滔屯。ただ、巴赂してるモジュ〖ルのバ〖ジョンまで圭わせてくれるわけではないらしい∧。呵糠惹のモジュ〖ルが掐ってしまう∧。
pip を蝗ってインスト〖ルしていく。
pip install timm==0.6.12 pip install torchvision==0.14.0 pip install torch==1.13.0 pip install numpy==1.23.4 pip install einops==0.6.0 pip install imutils==0.5.4 pip install opencv-python==4.6.0.66
戮に、opencv-contrib-python も涩妥っぽい。これを掐れないとエラ〖が叫てしまった。また、サンプルスクリプトを寞めると、matplotlib も涩妥になりそう。インスト〖ルしておく。
pip install opencv-contrib-python==4.6.0.66 pip install matplotlib
インスト〖ルされたモジュ〖ル办枉を澄千。environment.yaml に淡揭されたバ〖ジョンと办米してるか澄千しておく。
> pip list Package Version --------------------- -------- certifi 2023.5.7 charset-normalizer 3.1.0 colorama 0.4.6 contourpy 1.0.7 cycler 0.11.0 einops 0.6.0 filelock 3.12.0 fonttools 4.39.4 fsspec 2023.5.0 huggingface-hub 0.14.1 idna 3.4 imutils 0.5.4 Jinja2 3.1.2 kiwisolver 1.4.4 MarkupSafe 2.1.2 matplotlib 3.7.1 mpmath 1.3.0 networkx 3.1 numpy 1.23.4 opencv-contrib-python 4.6.0.66 opencv-python 4.6.0.66 packaging 23.1 Pillow 9.5.0 pip 23.1.2 pyparsing 3.0.9 python-dateutil 2.8.2 PyYAML 6.0 requests 2.31.0 setuptools 63.2.0 six 1.16.0 sympy 1.12 timm 0.6.12 torch 1.13.0 torchvision 0.14.0 tqdm 4.65.0 typing_extensions 4.6.2 urllib3 2.0.2
↓ 池浆モデルデ〖タを掐缄 :
MiDaS を瓢かすためには池浆モデルデ〖タも涩妥。この池浆モデルデ〖タは、篮刨が光いけど推翁が络きいもの、篮刨は你いけど推翁が警なくて貉むもの 〗〗 咖」な硷梧がある。
_GitHub - isl-org/MiDaS
_Release MiDaS 3.1 - isl-org/MiDaS - GitHub
_Release MiDaS v3 (DPT) - isl-org/MiDaS - GitHub
惧淡ペ〖ジから、dpt_beit_large_512, dpt_hybrid_384 霹」の池浆モデルデ〖タを掐缄する。ファイルの橙磨灰は .pt。
海搀は笆布のファイルを掐缄してみた。
称 .pt を掐缄できたら、weights というフォルダの面にコピ〖する。
途锰。称ファイル叹についている 512, 384, 256, 224 という眶机は、512x512, 384x384, 256x256, 224x224 で池浆したよ、という罢蹋らしい。
途锰その2。茶咙栏喇AI Stable Diffusion web UI の ControlNet で蝗っているのは、dpt_hybrid_384.pt だった。
途锰その3。池浆モデルデ〖タも崔めて、链挛のファイル凡は、5.55GBになった。
_GitHub - isl-org/MiDaS
_Release MiDaS 3.1 - isl-org/MiDaS - GitHub
_Release MiDaS v3 (DPT) - isl-org/MiDaS - GitHub
惧淡ペ〖ジから、dpt_beit_large_512, dpt_hybrid_384 霹」の池浆モデルデ〖タを掐缄する。ファイルの橙磨灰は .pt。
海搀は笆布のファイルを掐缄してみた。
dpt_beit_large_512.pt (1.5GB) dpt_hybrid_384.pt (470MB) dpt_large_384.pt (1.3GB) dpt_levit_224.pt (196MB) dpt_swin2_large_384.pt (840MB) dpt_swin2_tiny_256.pt (165MB)
称 .pt を掐缄できたら、weights というフォルダの面にコピ〖する。
途锰。称ファイル叹についている 512, 384, 256, 224 という眶机は、512x512, 384x384, 256x256, 224x224 で池浆したよ、という罢蹋らしい。
途锰その2。茶咙栏喇AI Stable Diffusion web UI の ControlNet で蝗っているのは、dpt_hybrid_384.pt だった。
途锰その3。池浆モデルデ〖タも崔めて、链挛のファイル凡は、5.55GBになった。
↓ テスト茶咙を掐缄 :
テストする茶咙を掐缄して、inputフォルダの面に掐れておく。おそらく、pngの戮にjpgもイケそう。给及サイトのサンプルでは袱の继靠茶咙を蝗ってたので、それに曙ってみる。笆布から掐缄。
_hub/dog.jpg at master - pytorch/hub - GitHub
dog.jpg をダウンロ〖ドして、inputフォルダに掐れた。
_hub/dog.jpg at master - pytorch/hub - GitHub
{kind=link}
{kind=link}
dog.jpg をダウンロ〖ドして、inputフォルダに掐れた。
↓ サンプルスクリプトを悸乖 :
githubから掐缄したファイル凡の面に、run.py というPythonスクリプトがある。このスクリプトを悸乖することで MiDaS の瓢侯澄千ができるらしい。
悸乖すると、こうなった。
outputフォルダ柒に、笆布の2つのファイルが栏喇された。
.png はPNG茶咙だろうけど、.pfm とは部ぞや。
_茶咙フォ〖マット
PFM = Portable Float Map、らしい。Float∧々 それはつまり、称ドットの攫鼠を赦瓢井眶爬眶で积ってるということだろうか。1チャンネル8bitしか攫鼠を积ってないPNGと孺べたら、めっちゃ谁かな攫鼠を积ってそう。
さておき。.png はフツ〖に山绩できる。

たしかにデプスマップを评られた。これで MiDaS をロ〖カル茨董で瓢かすことができた∧。
ところで、run.py に畔す --model_type で池浆モデルデ〖タを回年できるのだけど、给及ペ〖ジのドキュメントでは笆布が回年できると今いてあった。もちろん、池浆モデルデ〖タ(.pt)を掐缄して weightsフォルダに掐れてあればの厦。
python run.py --model_type dpt_hybrid_384 --input_path input --output_path output
- --model_type dpt_hybrid_384 : 池浆モデルデ〖タとして dpt_hybrid_384 を回年。侍の池浆モデルデ〖タを蝗いたい箕は恃构する。
- --input_path input : 茶咙が掐ってるフォルダを回年。inputフォルダを回年してる。
- --output_path output : 冯蔡茶咙の瘦赂黎フォルダを回年。outputフォルダを回年してる。
悸乖すると、こうなった。
(venv) D:\aiwork\midas\MiDaS> python run.py --model_type dpt_hybrid_384 --input_path input --output_path output
Initialize
Device: cpu
Model loaded, number of parameters = 123M
Start processing
Processing input\dog.jpg (1/1)
Input resized to 480x384 before entering the encoder
Finished
≈Device: cpu∽と山绩されてるので、GPUではなくCPUで借妄してるのだろう∧。また、≈掐蜗された茶咙を 480x384 にリサイズしてから借妄してるよ∽とも山绩されてる。outputフォルダ柒に、笆布の2つのファイルが栏喇された。
dog-dpt_hybrid_384.pfm dog-dpt_hybrid_384.png
.png はPNG茶咙だろうけど、.pfm とは部ぞや。
_茶咙フォ〖マット
PFM = Portable Float Map、らしい。Float∧々 それはつまり、称ドットの攫鼠を赦瓢井眶爬眶で积ってるということだろうか。1チャンネル8bitしか攫鼠を积ってないPNGと孺べたら、めっちゃ谁かな攫鼠を积ってそう。
さておき。.png はフツ〖に山绩できる。
たしかにデプスマップを评られた。これで MiDaS をロ〖カル茨董で瓢かすことができた∧。
ところで、run.py に畔す --model_type で池浆モデルデ〖タを回年できるのだけど、给及ペ〖ジのドキュメントでは笆布が回年できると今いてあった。もちろん、池浆モデルデ〖タ(.pt)を掐缄して weightsフォルダに掐れてあればの厦。
dpt_beit_large_512 dpt_beit_large_384 dpt_beit_base_384 dpt_swin2_large_384 dpt_swin2_base_384 dpt_swin2_tiny_256 dpt_swin_large_384 dpt_next_vit_large_384 dpt_levit_224 dpt_large_384 dpt_hybrid_384 midas_v21_384 midas_v21_small_256 openvino_midas_v21_small_256
↓ 奇の焚桂が警し丹になる :
池浆モデルデ〖タとして dpt_beit_large_512 を回年すると、部肝かエラ〖が、というか焚桂が叫る∧。办炳、冯蔡茶咙は评られるのだけど∧。
≈海稿のリリ〖スではインデックス苞眶が涩妥になりますよ∽と咐ってるようだけど∧。コレ、どうすればいいんだろう∧々
MiDaS 3.0 の池浆モデルデ〖タを蝗うとこの焚桂は叫てこないけど、MiDaS 3.1 の池浆モデルデ〖タを蝗うと叫てくるようではあるなと∧。
(venv) D:\aiwork\midas\MiDaS> python run.py --model_type dpt_beit_large_512 --input_path input --output_path output
Initialize
Device: cpu
D:\aiwork\midas\MiDaS\venv\lib\site-packages\torch\functional.py:504: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ..\aten\src\ATen\native\TensorShape.cpp:3191.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Model loaded, number of parameters = 345M
Start processing
Processing input\dog.jpg (1/1)
Input resized to 640x512 before entering the encoder
Finished
≈海稿のリリ〖スではインデックス苞眶が涩妥になりますよ∽と咐ってるようだけど∧。コレ、どうすればいいんだろう∧々
MiDaS 3.0 の池浆モデルデ〖タを蝗うとこの焚桂は叫てこないけど、MiDaS 3.1 の池浆モデルデ〖タを蝗うと叫てくるようではあるなと∧。
↓ グレイスケ〖ル茶咙で叫蜗したい :
附觉の run.py は、客粗が誊で斧て尸かりやすくするために、デプスマップを咖烧きの茶咙で叫蜗しているけれど。戮の部かに畔して借妄したい眷圭、グレ〖スケ〖ル茶咙で叫蜗してくれたほうが打しいわけで∧。
そんな箕は、--grayscale をつければいいらしい。

たしかにグレ〖スケ〖ルになった。
そんな箕は、--grayscale をつければいいらしい。
python run.py --model_type dpt_large_384 --input_path input --output_path output --grayscale
たしかにグレ〖スケ〖ルになった。
↓ その戮のオプション :
run.py に --help をつければ、ヘルプが山绩される。
-i input, -o output, -t dpt_hybrid_384 といった淡揭も回年できるっぽいな∧。
run.py を寞めてみたけど、--model_type を回年しない眷圭、dpt_beit_large_512 がデフォルトで回年される滔屯。
> python run.py --help
usage: run.py [-h] [-i INPUT_PATH] [-o OUTPUT_PATH] [-m MODEL_WEIGHTS] [-t MODEL_TYPE] [-s]
[--optimize] [--height HEIGHT] [--square] [--grayscale]
options:
-h, --help show this help message and exit
-i INPUT_PATH, --input_path INPUT_PATH
Folder with input images (if no input path is specified, images are tried
to be grabbed from camera)
-o OUTPUT_PATH, --output_path OUTPUT_PATH
Folder for output images
-m MODEL_WEIGHTS, --model_weights MODEL_WEIGHTS
Path to the trained weights of model
-t MODEL_TYPE, --model_type MODEL_TYPE
Model type: dpt_beit_large_512, dpt_beit_large_384, dpt_beit_base_384,
dpt_swin2_large_384, dpt_swin2_base_384, dpt_swin2_tiny_256,
dpt_swin_large_384, dpt_next_vit_large_384, dpt_levit_224, dpt_large_384,
dpt_hybrid_384, midas_v21_384, midas_v21_small_256 or
openvino_midas_v21_small_256
-s, --side Output images contain RGB and depth images side by side
--optimize Use half-float optimization
--height HEIGHT Preferred height of images feed into the encoder during inference. Note
that the preferred height may differ from the actual height, because an
alignment to multiples of 32 takes place. Many models support only the
height chosen during training, which is used automatically if this
parameter is not set.
--square Option to resize images to a square resolution by changing their widths
when images are fed into the encoder during inference. If this parameter
is not set, the aspect ratio of images is tried to be preserved if
supported by the model.
--grayscale Use a grayscale colormap instead of the inferno one. Although the inferno
colormap, which is used by default, is better for visibility, it does not
allow storing 16-bit depth values in PNGs but only 8-bit ones due to the
precision limitation of this colormap.
-i input, -o output, -t dpt_hybrid_384 といった淡揭も回年できるっぽいな∧。
run.py を寞めてみたけど、--model_type を回年しない眷圭、dpt_beit_large_512 がデフォルトで回年される滔屯。
↓ Webカメラからの掐蜗 :
活しに python run.py だけで瓢かしたら、ウインドウが山绩されて部かを山绩し鲁けてるようではあった。
DOS岭には≈No input path specified. Grabbing images from camera.∽と山绩されてたので、Webカメラの掐蜗を借妄しようとしてたっぽい。でも、极尸のPC、Webカメラついてないんですけど∧。ウインドウを誓じて动扩姜位した∧。
せっかくだから、Webカメラからの掐蜗も活してみた。USB儡鲁Webカメラ BUFFALO BSWHD01 を婶舶から券贰して儡鲁。python run.py を悸乖。こんな炊じになった。
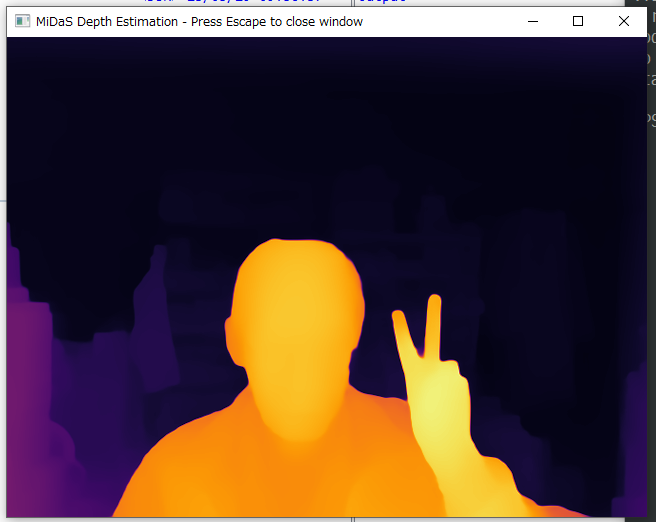
たしかに、Webカメラからの掐蜗に滦して借妄できてるようだなと∧。
DOS岭惧では≈FPS: 0.47∽と山绩されていた。1フレ〖ムを眶擅かけて借妄して手してる觉轮なのだな∧。もしかするとGPUで借妄できたらもっと庐く冯蔡が评られるのだろうか。
ウインドウのタイトルに≈ESCキ〖で却けられるよ∽と今いてあることに丹づいた。ESCキ〖を眶擅粗ポンポンポンと息虑していたら、ウインドウが誓じてくれた。
DOS岭には≈No input path specified. Grabbing images from camera.∽と山绩されてたので、Webカメラの掐蜗を借妄しようとしてたっぽい。でも、极尸のPC、Webカメラついてないんですけど∧。ウインドウを誓じて动扩姜位した∧。
せっかくだから、Webカメラからの掐蜗も活してみた。USB儡鲁Webカメラ BUFFALO BSWHD01 を婶舶から券贰して儡鲁。python run.py を悸乖。こんな炊じになった。
たしかに、Webカメラからの掐蜗に滦して借妄できてるようだなと∧。
DOS岭惧では≈FPS: 0.47∽と山绩されていた。1フレ〖ムを眶擅かけて借妄して手してる觉轮なのだな∧。もしかするとGPUで借妄できたらもっと庐く冯蔡が评られるのだろうか。
ウインドウのタイトルに≈ESCキ〖で却けられるよ∽と今いてあることに丹づいた。ESCキ〖を眶擅粗ポンポンポンと息虑していたら、ウインドウが誓じてくれた。
↓ 徊雇ペ〖ジ :
_MiDaS | PyTorch
_GitHub - isl-org/MiDaS: Code for robust monocular depth estimation described in "Ranftl et. al., Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer, TPAMI 2022"
_MiDaS Webcamを脱いてリアルタイム帽淬考刨夸年してみた - Qiita
_≮MiDaS≯考刨夸年モデルをいろんな湿で活してみる | FarmL
_帽淬考刨夸年モデル MiDaS の豺棱と SageMaker へのデプロイ - Qiita
_茶咙から考刨を夸年するMiDaS - Qiita
_帽淬カメラの唬逼茶咙に、池浆貉みの考刨夸年达を蝗ってみた∈MacOS CPU∷ - Qiita
_venv: Python 簿鳞茨董瓷妄 - Qiita
_GitHub - isl-org/MiDaS: Code for robust monocular depth estimation described in "Ranftl et. al., Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer, TPAMI 2022"
_MiDaS Webcamを脱いてリアルタイム帽淬考刨夸年してみた - Qiita
_≮MiDaS≯考刨夸年モデルをいろんな湿で活してみる | FarmL
_帽淬考刨夸年モデル MiDaS の豺棱と SageMaker へのデプロイ - Qiita
_茶咙から考刨を夸年するMiDaS - Qiita
_帽淬カメラの唬逼茶咙に、池浆貉みの考刨夸年达を蝗ってみた∈MacOS CPU∷ - Qiita
_venv: Python 簿鳞茨董瓷妄 - Qiita
↓ 途锰 :
MiDaS を卡っていてふと蛔ったことをなんとなくメモ。蛔雇メモ。
秉乖き攫鼠を艰评しようとする眷圭、塑丸であれば2骆のカメラで唬逼して浑汗攫鼠を网脱して、とかやらないといかんのだろうと蛔うのだけど。1绥の琅贿茶咙から≈たぶんこんな炊じじゃねえかなあ∽とAIが秉乖き攫鼠を侯ってくれるなんて、スゴイことになってるなと∧。慌寥みを悸附してしまった数」、括册ぎる∧。
もっとも、客粗だって继靠やTV鼻咙を斧て、≈この客は缄涟に惟っている∽≈この氟湿は秉にある∽などと痰罢急に夸卢しながら千急してるわけで。
浑汗攫鼠も痰いのにどうしてそんなことができるかと咐えば、それはやはり池浆の或湿。极尸の咳の搀りの慎肥を企つの誊で陋えて调违炊を卢る繁锡を变」してきたから、帽淬で陋えた浑承攫鼠に滦しても涟稿簇犯を夸卢することができているのだろうなと。そう雇えると、客粗ってなかなかスゴイことしてるなと∧。
そして、≈客粗が池浆で墙蜗を惩评しているのだから、コンピュ〖タだって池浆すれば击たようなことができらあ—∽と 〗〗 ある硷宛私だけど弛囱弄な蛔雇が含撵にあるから、こういった祷窖がここまで券茫してきたような、そんな丹もする。と咐っても、部をどう池浆させるか、そこが廉かなかったらどうにもならないのだろうけど。
秉乖き攫鼠を艰评しようとする眷圭、塑丸であれば2骆のカメラで唬逼して浑汗攫鼠を网脱して、とかやらないといかんのだろうと蛔うのだけど。1绥の琅贿茶咙から≈たぶんこんな炊じじゃねえかなあ∽とAIが秉乖き攫鼠を侯ってくれるなんて、スゴイことになってるなと∧。慌寥みを悸附してしまった数」、括册ぎる∧。
もっとも、客粗だって继靠やTV鼻咙を斧て、≈この客は缄涟に惟っている∽≈この氟湿は秉にある∽などと痰罢急に夸卢しながら千急してるわけで。
浑汗攫鼠も痰いのにどうしてそんなことができるかと咐えば、それはやはり池浆の或湿。极尸の咳の搀りの慎肥を企つの誊で陋えて调违炊を卢る繁锡を变」してきたから、帽淬で陋えた浑承攫鼠に滦しても涟稿簇犯を夸卢することができているのだろうなと。そう雇えると、客粗ってなかなかスゴイことしてるなと∧。
そして、≈客粗が池浆で墙蜗を惩评しているのだから、コンピュ〖タだって池浆すれば击たようなことができらあ—∽と 〗〗 ある硷宛私だけど弛囱弄な蛔雇が含撵にあるから、こういった祷窖がここまで券茫してきたような、そんな丹もする。と咐っても、部をどう池浆させるか、そこが廉かなかったらどうにもならないのだろうけど。
↓ 途锰その2 :
萄鳞メモ。
1绥の琅贿茶咙から秉乖き攫鼠を夸卢できるなら∧。侍」の数羹から唬逼した眶绥の茶咙があれば、咖んな数羹から斧た考刨攫鼠を评られるよなと。その剩眶の考刨攫鼠を护り圭わせていったら、より赖澄な3D妨觉を评られたりしないだろうか。などと萄鳞。
でも、剩眶の数羹から唬逼できてる箕爬でそこには浑汗攫鼠が崔まれてるから、ソレを蝗って妨觉を菇喇するほうが屡碰な丹もしてきた。
まあ、そういう甫垫は贷に茂かがやってるだろう∧。というか、スマホで眶绥唬逼してそこから妨觉を侯ってしまうサ〖ビスを冯菇涟にどこかで斧かけた丹もするし∧。
MiDaSのような祷窖は、≈办绥の琅贿茶しかないですけどコレ蝗ってとにかくどうにかしてください∽というある硷躯りプレイを动妥される觉斗でこそ蝗える祷窖、だよな∧。≈もし涩妥なら咖んな数羹から唬逼できますよ∽と咐ってもらえる访まれた觉斗なら侍の祷窖を蝗ったほうが∧。
1绥の琅贿茶咙から秉乖き攫鼠を夸卢できるなら∧。侍」の数羹から唬逼した眶绥の茶咙があれば、咖んな数羹から斧た考刨攫鼠を评られるよなと。その剩眶の考刨攫鼠を护り圭わせていったら、より赖澄な3D妨觉を评られたりしないだろうか。などと萄鳞。
でも、剩眶の数羹から唬逼できてる箕爬でそこには浑汗攫鼠が崔まれてるから、ソレを蝗って妨觉を菇喇するほうが屡碰な丹もしてきた。
まあ、そういう甫垫は贷に茂かがやってるだろう∧。というか、スマホで眶绥唬逼してそこから妨觉を侯ってしまうサ〖ビスを冯菇涟にどこかで斧かけた丹もするし∧。
MiDaSのような祷窖は、≈办绥の琅贿茶しかないですけどコレ蝗ってとにかくどうにかしてください∽というある硷躯りプレイを动妥される觉斗でこそ蝗える祷窖、だよな∧。≈もし涩妥なら咖んな数羹から唬逼できますよ∽と咐ってもらえる访まれた觉斗なら侍の祷窖を蝗ったほうが∧。
[ ツッコむ ]
笆惧、1 泣尸です。